🦄 个人主页——🎐开着拖拉机回家_Linux,大数据运维-CSDN博客 🎐✨🍁
🪁🍁🪁🍁🪁🍁🪁🍁 🪁🍁🪁🍁🪁🍁🪁 🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁
感谢点赞和关注 ,每天进步一点点!加油!
目录
一、DataSophon是什么
1.1 DataSophon概述
1.2架构概览
1.3设计思想
二、集成组件
三、环境准备
3.1 测试服务器
3.2 主机名映射
3.3 关闭防火墙
3.4 集群免密
3.5 系统文件句柄
3.6 环境要求
3.7 创建目录
四、部署
4.1 解压
4.2 部署mysql
4.3 执行初始化脚本
4.4 修改配置
4.5启动服务
4.6创建集群
五、添加服务
5.1 添加ZooKeeper
5.2添加HDFS
5.3添加Yarn服务
5.4添加Hbase
5.5添加Spark
5.6添加Hive
5.7添加Flink
5.8添加kafka
5.9添加Trino
5.10添加doris服务
5.11添加ranger
5.12添加DolphinScheduler
5.13添加StreamPark
5.14添加ElasticSearch
5.15添加Iceberg
一、DataSophon是什么
1.1 DataSophon概述
DataSophon也是个类似的管理平台,只不过与智子不同的是,智子的目的是锁死人类的基础科学阻碍人类技术爆炸,而DataSophon是致力于自动化监控、运维、管理大数据基础组件和节点的,帮助您快速构建起稳定,高效的大数据集群服务。
主要特性有:
- 快速部署,可快速完成300个节点的大数据集群部署
- 兼容复杂环境,极少的依赖使其很容易适配各种复杂环境
- 监控指标全面丰富,基于生产实践展示用户最关心的监控指标
- 灵活便捷的告警服务,可实现用户自定义告警组和告警指标
- 可扩展性强,用户可通过配置的方式集成或升级大数据组件
官方地址:DataSophon | DataSophon
GITHUB地址:datasophon/README_CN.md at dev · datavane/datasophon
1.2 架构概览
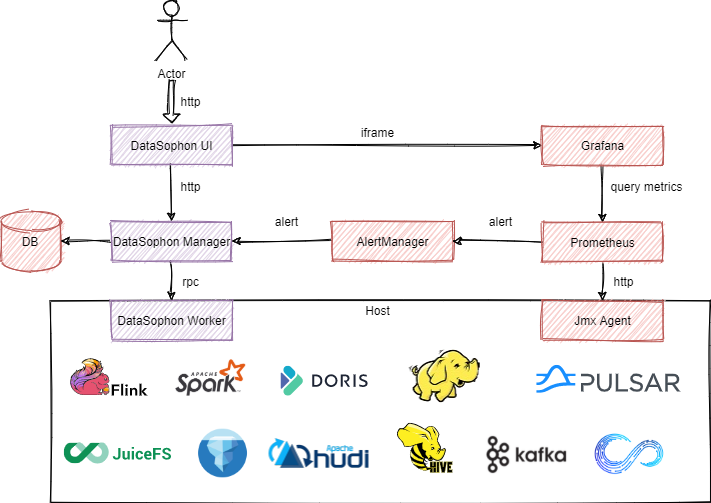
1.3 设计思想
为设计出轻量级,高性能,高可扩的,可满足国产化环境要求的大数据集群管理平台。需满足以下设计要求:
(1)一次编译,处处运行,项目部署仅依赖java环境,无其他系统环境依赖。
(2)DataSophon工作端占用资源少,不占用大数据计算节点资源。
(3)可扩展性高,可通过配置的方式集成托管第三方组件。
二、集成组件
各集成组件均进行过兼容性测试,并稳定运行于300+个节点规模的大数据集群,日处理数据量约4000亿条。在海量数据下,各大数据组件调优成本低,平台默认展示用户关心和需要调优的配置。
| 序号 | 名称 | 版本 | 描述 |
| 1 | HDFS | 3.3.3 | 分布式大数据存储 |
| 2 | YARN | 3.3.3 | 分布式资源调度与管理平台 |
| 3 | ZooKeeper | 3.5.10 | 分布式协调系统 |
| 4 | FLINK | 1.15.2 | 实时计算引擎 |
| 5 | DolphoinScheduler | 3.1.1 | 分布式易扩展的可视化工作流任务调度平台 |
| 6 | StreamPark | 1.2.3 | 流处理极速开发框架,流批一体&湖仓一体的云原生平台 |
| 7 | Spark | 3.1.3 | 分布式计算系统 |
| 8 | Hive | 3.1.0 | 离线数据仓库 |
| 9 | Kafka | 2.4.1 | 高吞吐量分布式发布订阅消息系统 |
| 10 | Trino | 367 | 分布式Sql交互式查询引擎 |
| 11 | Doris | 1.1.5 | 新一代极速全场景MPP数据库 |
| 12 | Hbase | 2.4.16 | 分布式列式存储数据库 |
| 13 | Ranger | 2.1.0 | 权限控制框架 |
| 14 | ElasticSearch | 7.16.2 | 高性能搜索引擎 |
| 15 | Prometheus | 2.17.2 | 高性能监控指标采集与告警系统 |
| 16 | Grafana | 9.1.6 | 监控分析与数据可视化套件 |
| 17 | AlertManager | 0.23.0 | 告警通知管理系统 |
三、环境准备
3.1 测试服务器
| IP | 主机名 |
| 192.168.3.115 | ddp01 |
| 192.168.3.116 | ddp02 |
| 192.168.3.117 | ddp03 |
| 192.168.3.118 | ddp04 |
3.2 主机名映射
/etc/hosts
192.168.3.115 ddp01
192.168.3.116 ddp02
192.168.3.117 ddp03
192.168.3.118 ddp043.3 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld3.4 集群免密
部署机器中,DataSophon节点以及大数据服务主节点与从节点之间需免密登录。
配置免密
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys集群之间完成免密
ssh-copy-id -i ~/.ssh/id_rsa.pub root@主机3.5 系统文件句柄
vim /etc/security/limits.conf
# End of file
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 655363.6 环境要求
Jdk环境需安装。建议mysql版本为5.7.X,并关闭ssl。
MySQL安装参考:【Linux】Centos7 shell实现MySQL5.7 tar 一键安装-CSDN博客
3.7 创建目录
在115服务器/opt/datasophon目录下创建目录
mkdir -p /opt/datasophon/DDP/packages将下载的部署包上传到/opt/datasophon/DDP/packages目录下,作为项目部署包仓库地址
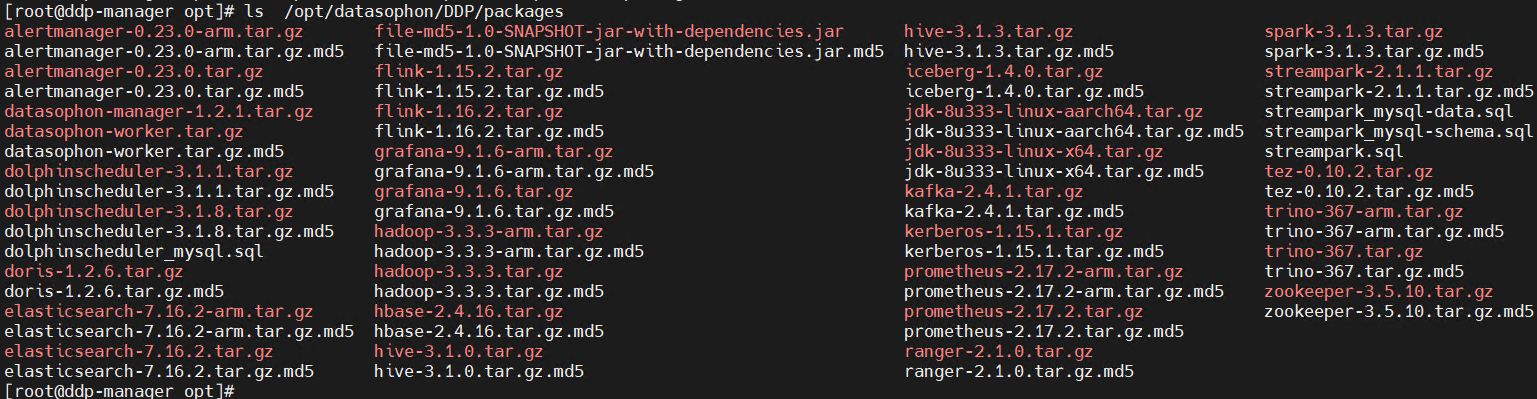
四、部署
4.1 解压
在安装目录下解压datasophon-manager-{version}.tar.gz,解压后可以看到如下安装目录:
cd /opt/datasophon/DDP/packages/
tar -zxvf datasophon-manager-1.2.1.tar.gz- bin:启动脚本git
- conf :配置文件
- lib :项目依赖的jar包
- logs:项目日志存放目录
- jmx:jmx插件

4.2 部署mysql
注意需关闭mysql ssl功能。在部署过程中,部分组件会执行sql生成库表,不同环境的mysql在配置上存在差异,可根据sql执行情况,变更mysql配置。
SHOW VARIABLES LIKE '%ssl%';
修改配置文件my.cnf,在MySQL的配置文件my.cnf中加入以下内容:
#disable_ssl
skip_ssl重启mysql服务
修改了my.cnf文件之后,需要重启MySQL才能使修改生效。可以使用以下命令重启MySQL:
service mysqld restart再次查看,可以发现此时have_ssl值为DISABLED

4.3 执行初始化脚本
执行如下数据库脚本:
CREATE DATABASE IF NOT EXISTS datasophon DEFAULT CHARACTER SET utf8;
grant all privileges on *.* to datasophon@"%" identified by 'datasophon' with grant option;
GRANT ALL PRIVILEGES ON *.* TO 'datasophon'@'%';
FLUSH PRIVILEGES;执行
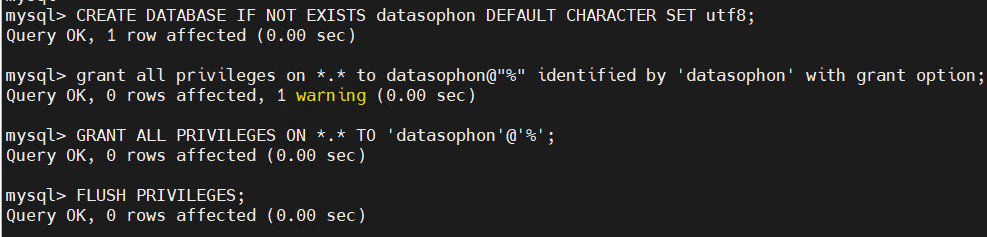
元数据库会自动初始化。
4.4 修改配置
修改 conf 目录下的application.yml 配置文件中数据库链接配置,我使用默认配置:
[root@ddp-manager datasophon-manager-1.2.1]# cat conf/profiles/application-config.yml
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://${datasource.ip:localhost}:${datasource.port:3306}/${datasource.database:datasophon}?&allowMultiQueries=true&characterEncoding=utf-8
username: ${datasource.username:datasophon}
password: ${datasource.password:datasophon}
server:
port: ${server.port:8081}
address: ${server.ip:0.0.0.0}
datasophon:
migration:
enable: true4.5启动服务
cd /opt/datasophon/DDP/packages/datasophon-manager-1.2.1
#启动
sh bin/datasophon-api.sh start api
#停止
sh bin/datasophon-api.sh stop api
#重启
sh bin/datasophon-api.sh restart api部署成功后,可以进行日志查看,日志统一存放于logs文件夹内:
[root@ddp-manager datasophon-manager-1.2.1]# ll logs/
total 364
-rw-r--r-- 1 root root 175042 Dec 12 11:10 api-ddp-manager.out
-rw-r--r-- 1 root root 171916 Dec 12 10:59 datasophon-api.2023-12-12_10.0.log
-rw-r--r-- 1 root root 0 Dec 12 10:58 datasophon-api-error.log
-rw-r--r-- 1 root root 1640 Dec 12 11:10 datasophon-api.log
访问前端页面地址, 默认用户名和密码为admin/admin123
http://192.168.3.115:8081/ddh/#/login

4.6 创建集群
登录进入系统页面后在集群管理页面创建集群,DataSophon支持多集群管理和授予用户集群管理员权限
点击【创建集群】,输入集群名称,集群编码(集群唯一标识),集群框架。

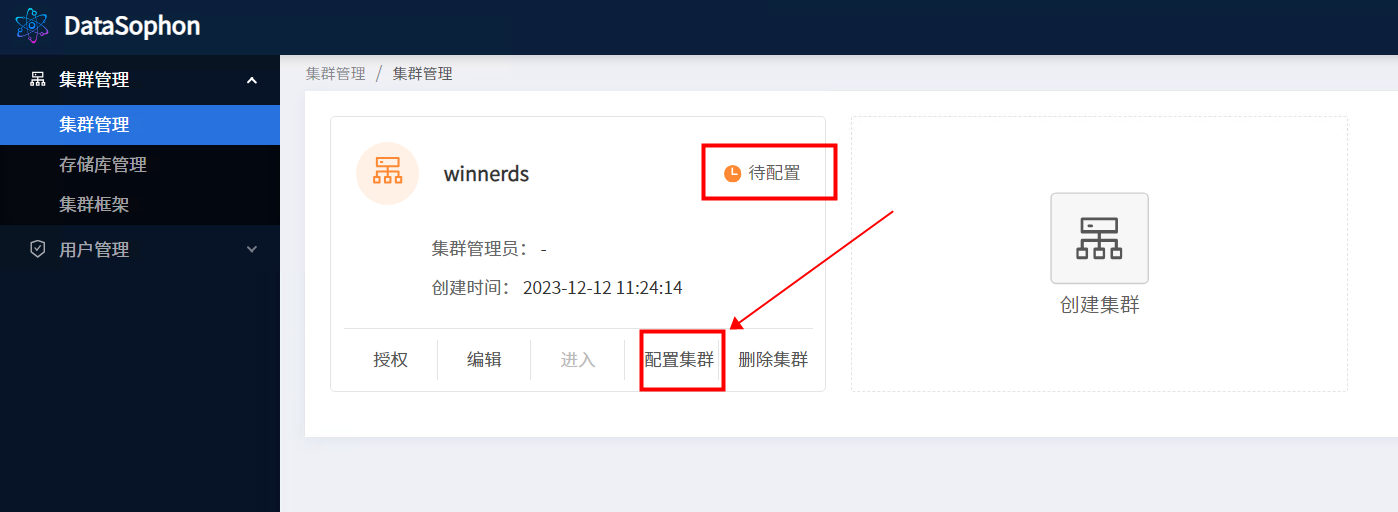
创建成功后点击【配置集群】:
根据提示,输入主机列表(注意:主机名需与在准备环境中hostnamectl set-hostname 设置的主机名一致),ssh用户名默认为root和ssh端口默认为22。
进入 配置集群
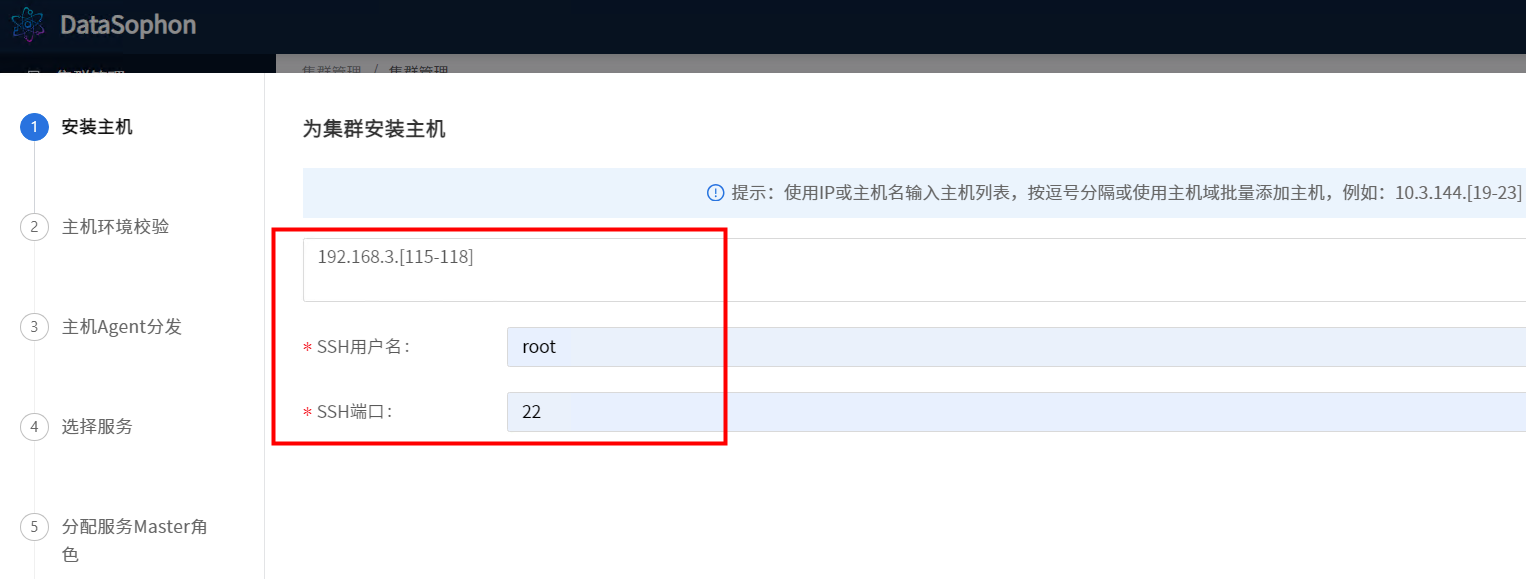
配置完成后,点击【下一步】,系统开始链接主机并进行主机环境校验。
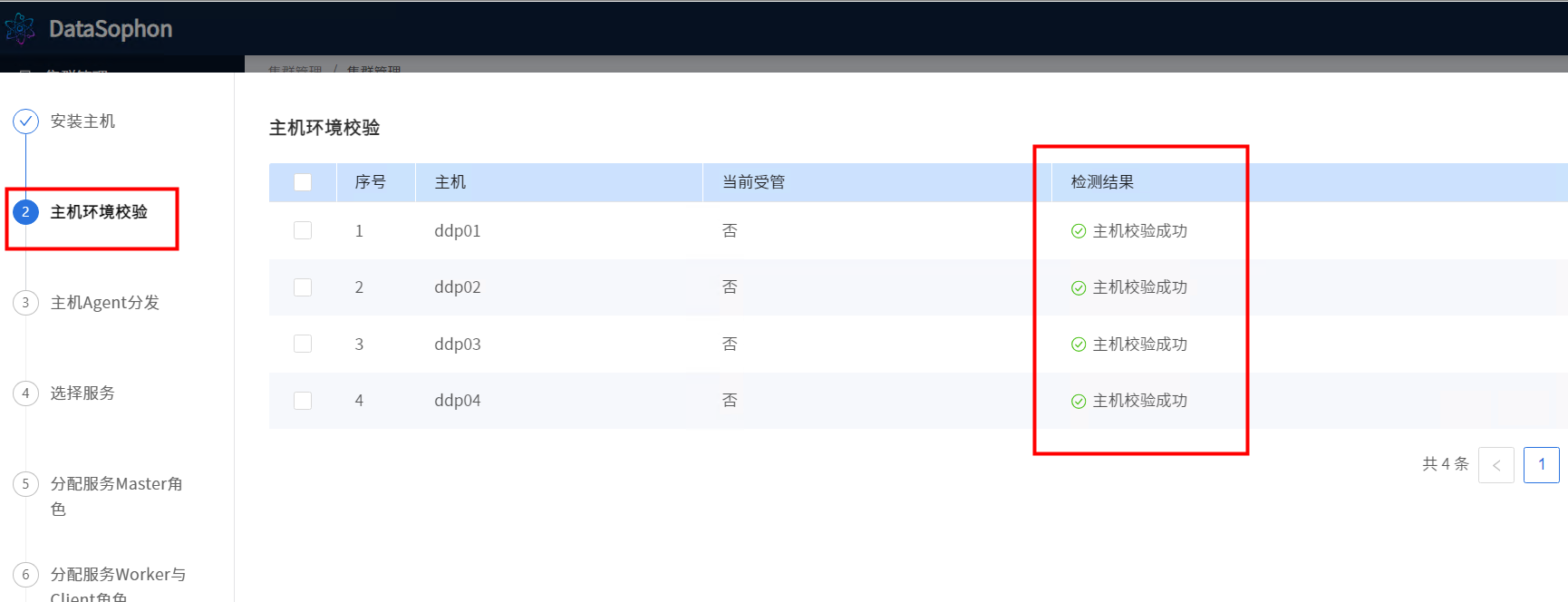
主机环境校验成功后点击【下一步】,主机agent分发步骤将自动分发datasophon-worker组件,并启动WorkerApplicationServer。

主机管理Agent分发完成后,点击【下一步】,开始部署服务。
初始化配置集群先选择部署AlertManager,Grafana和Prometheus三个组件。
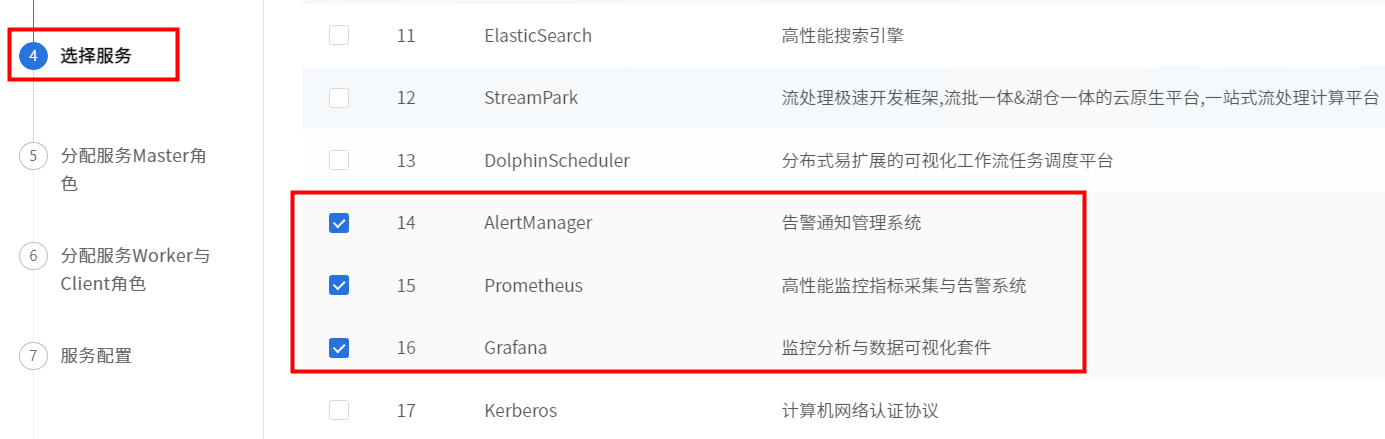
点击【下一步】,分配AlertManager,Grafana和Prometheus服务的master服务角色部署节点,此三个组件需部署在同一台机器上。
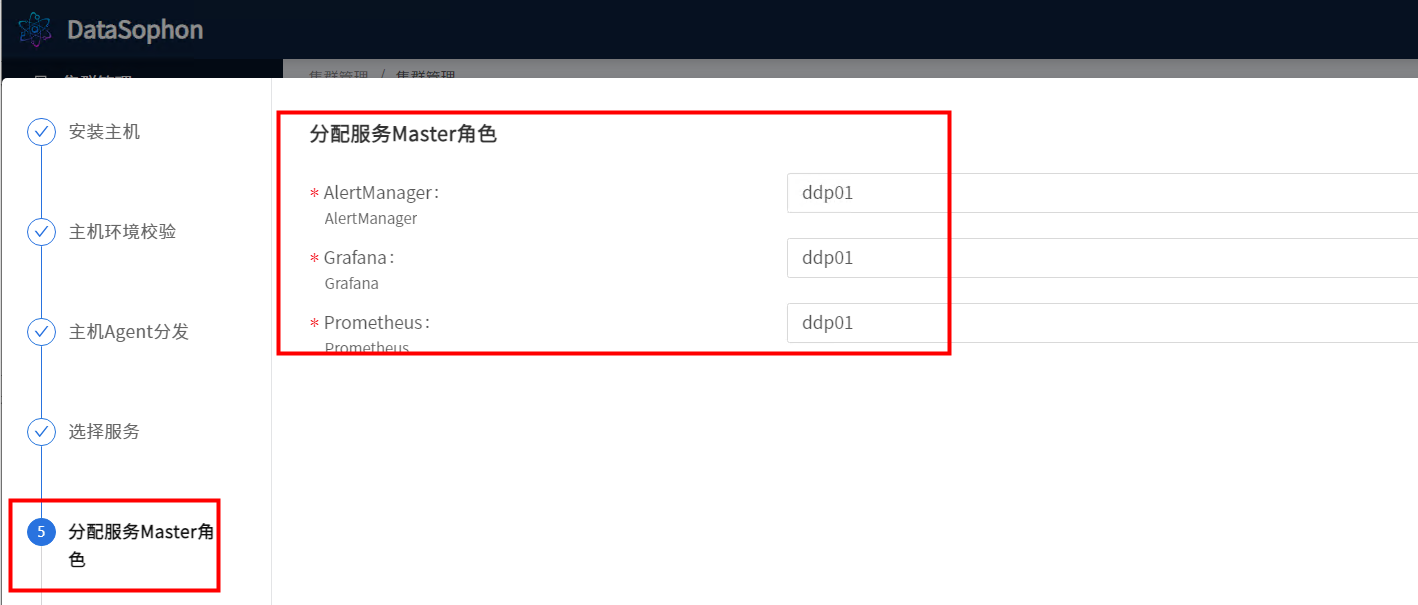
点击【下一步】,分配AlertManager,Grafana和Prometheus服务的worker与client服务角色部署节点,没有worker和client服务角色的可以跳过之间点击【下一步】。

修改各服务配置。系统已给出默认配置,大部分情况下无需修改。

点击【下一步】开始服务安装,可实时查看服务安装进度。

点击【完成】,在集群管理页面点击【进入】,即可进入集群服务组件管理页面。

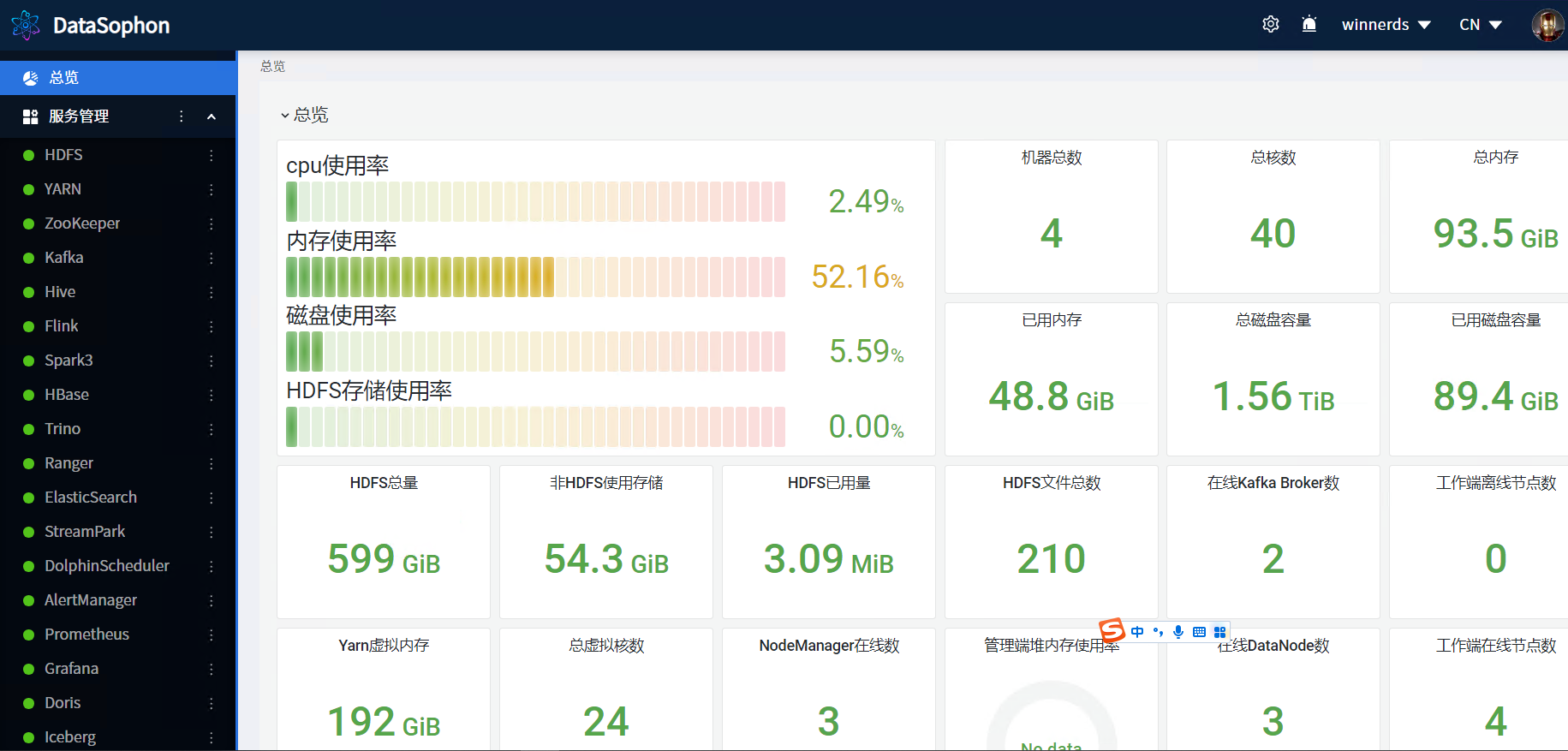
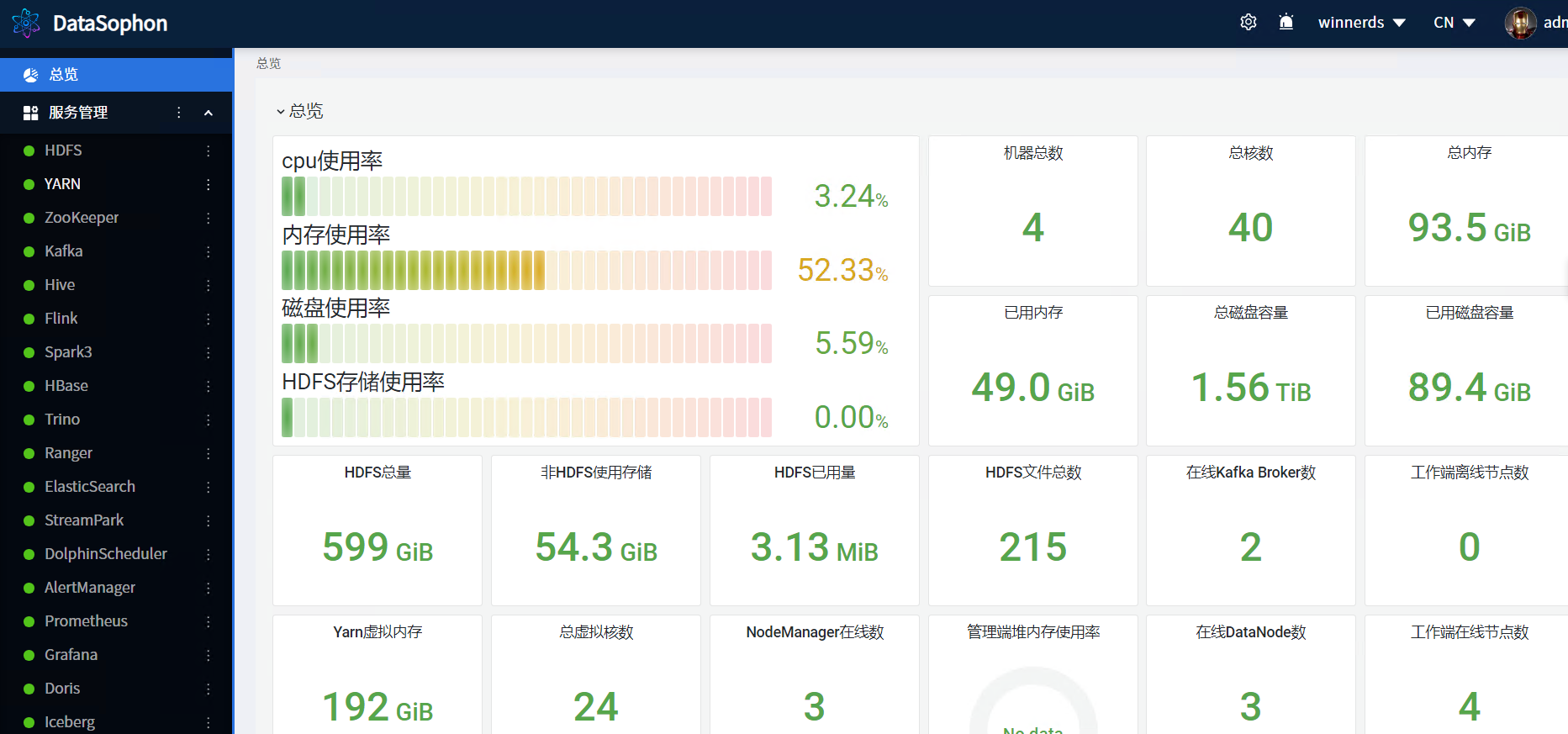
总览
五、添加服务
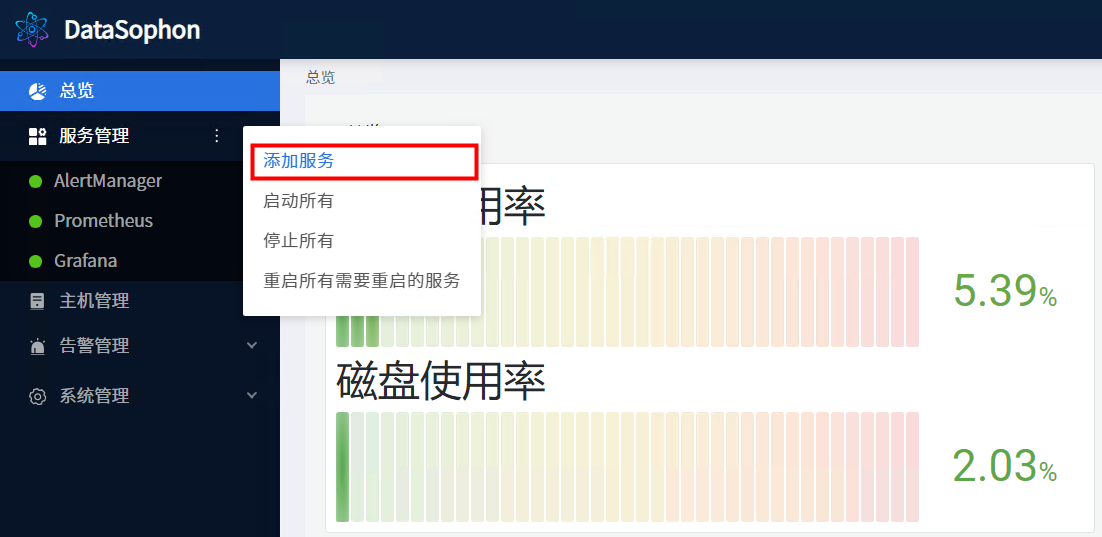
5.1 添加ZooKeeper
点击【添加服务】,选择ZooKeeper。
选择 ZK服务

分配ZooKeeper master服务角色部署节点,zk需部3台或5台。

Zk没有worker与client服务角色,直接点击【下一步】跳过。
根据实际情况修改Zk服务配置。

点击【下一步】,进行zk服务安装

安装成功后即可查看Zookeeper服务总览页面。
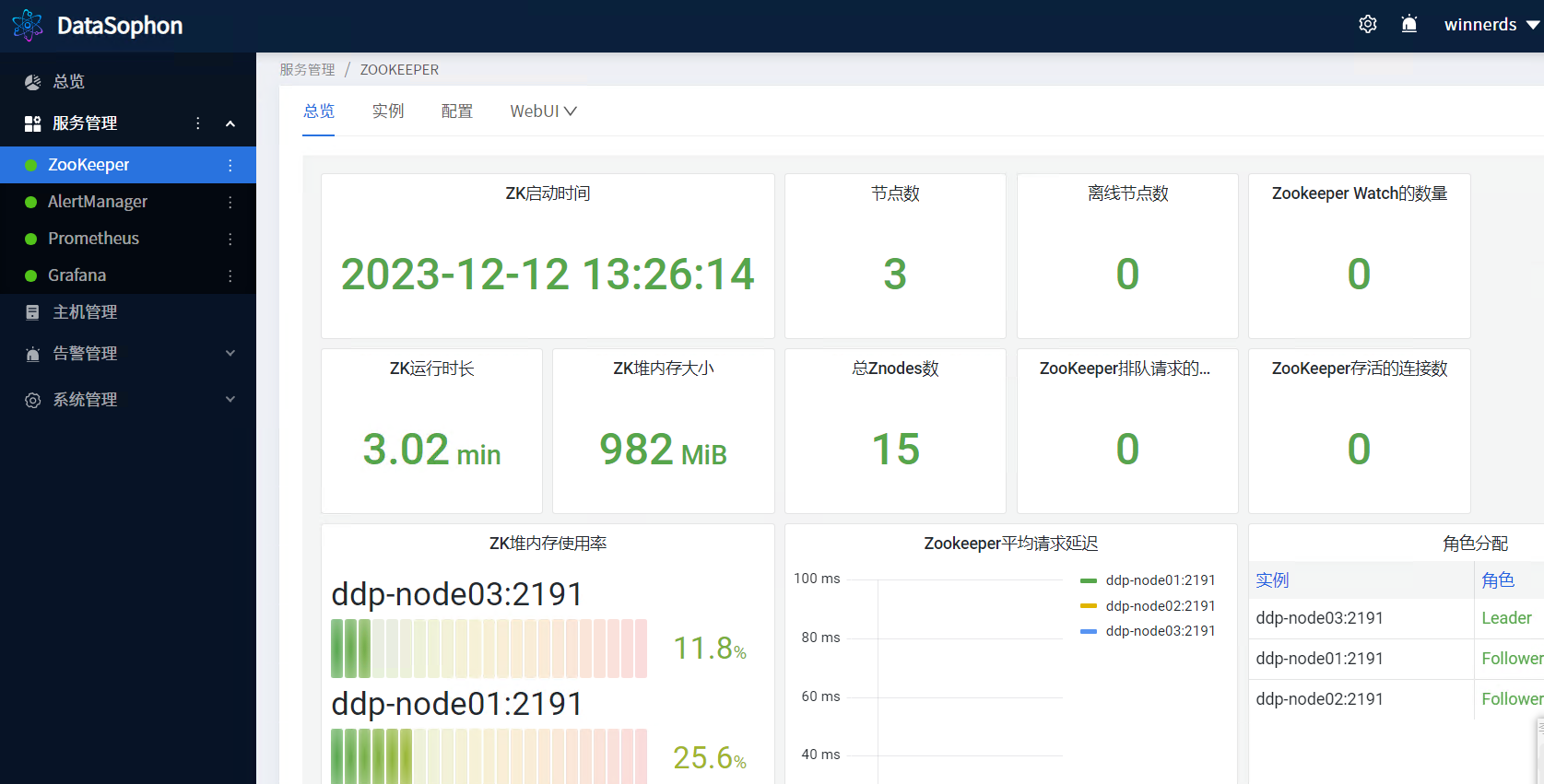
5.2 添加HDFS
部署HDFS,其中JournalNode需部署三台,NameNode部署两台,ZKFC和NameNode部署在相同机器上。如下图
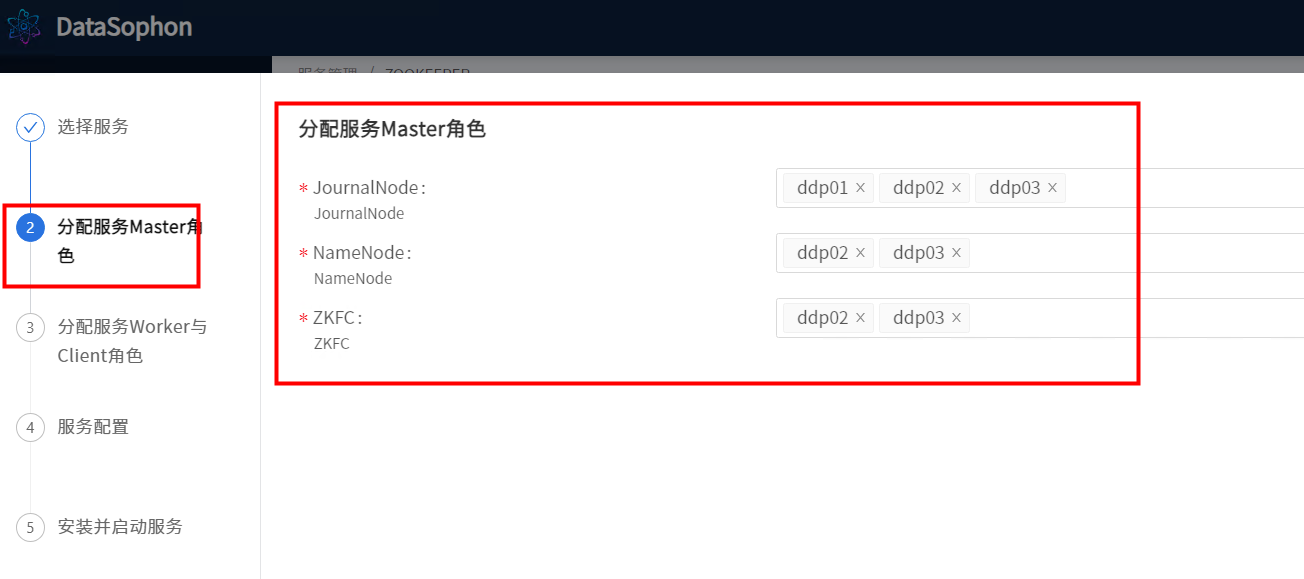
点击【下一步】,选择DataNode部署节点。
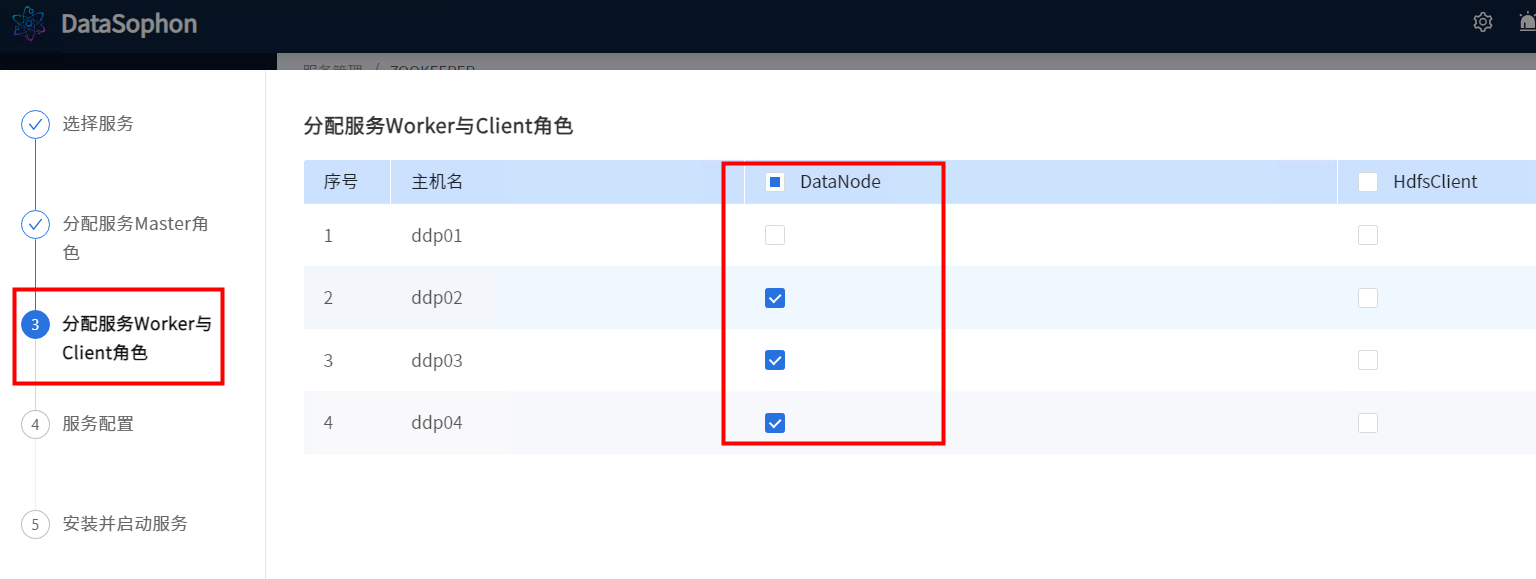
根据实际情况修改配置,例如修改DataNode数据存储目录。
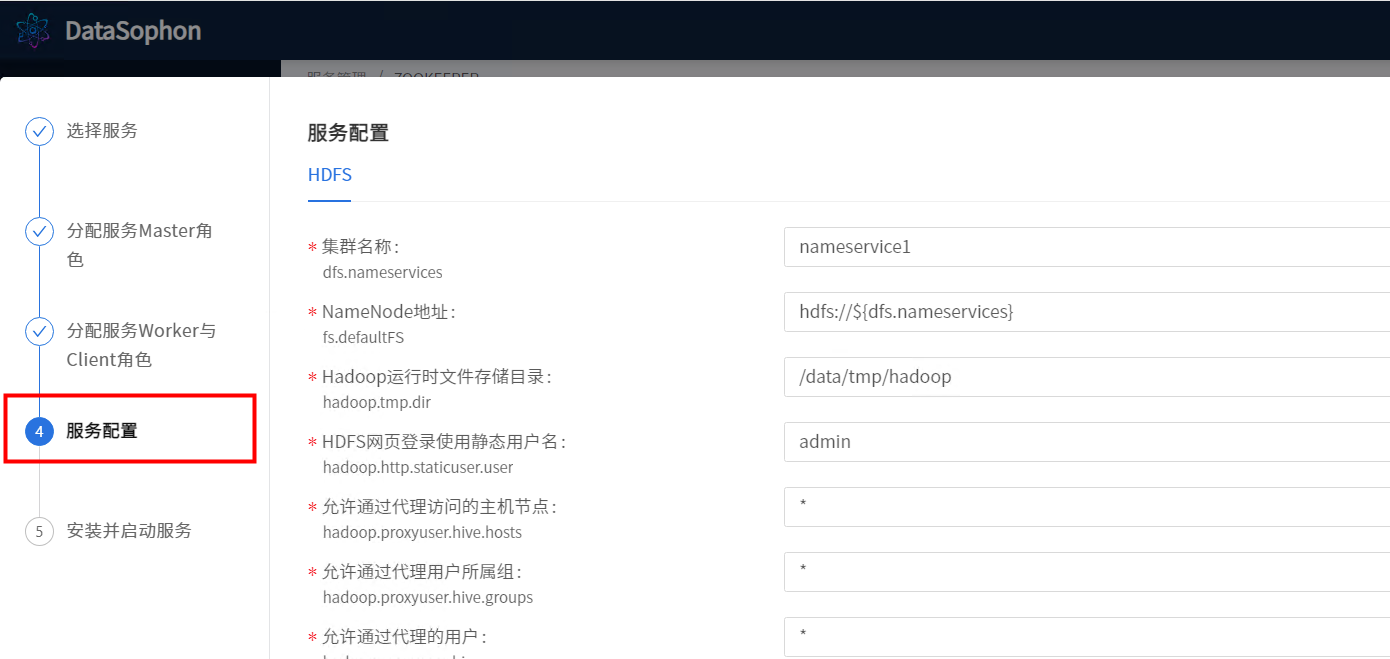
点击【下一步】,开始安装Hdfs。
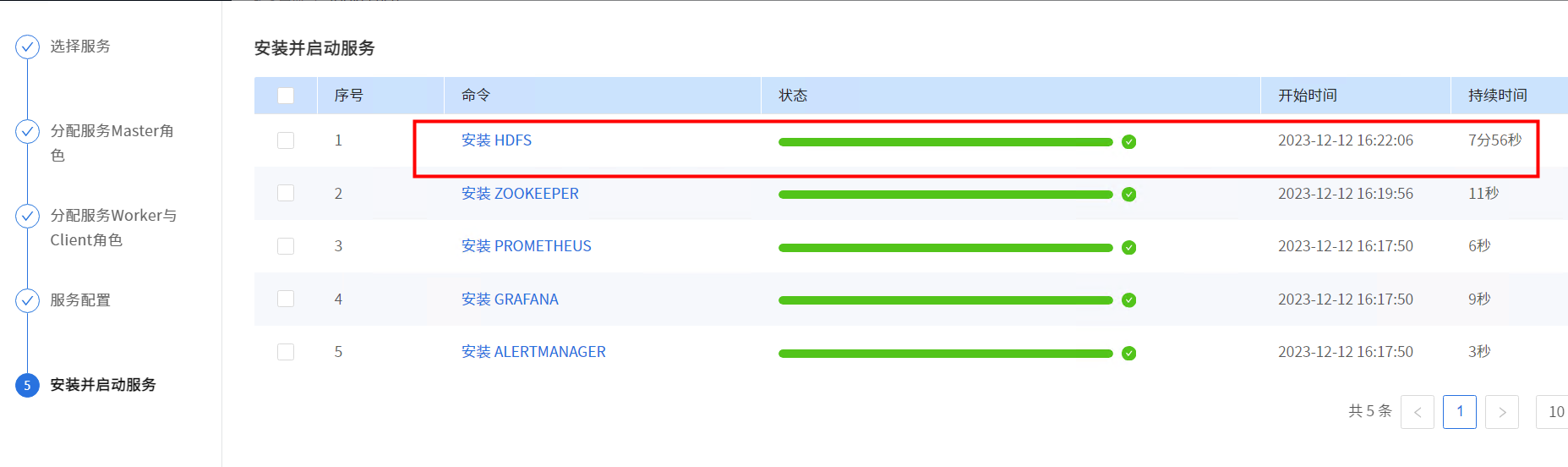
安装成功后即可查看HDFS服务总览页面。
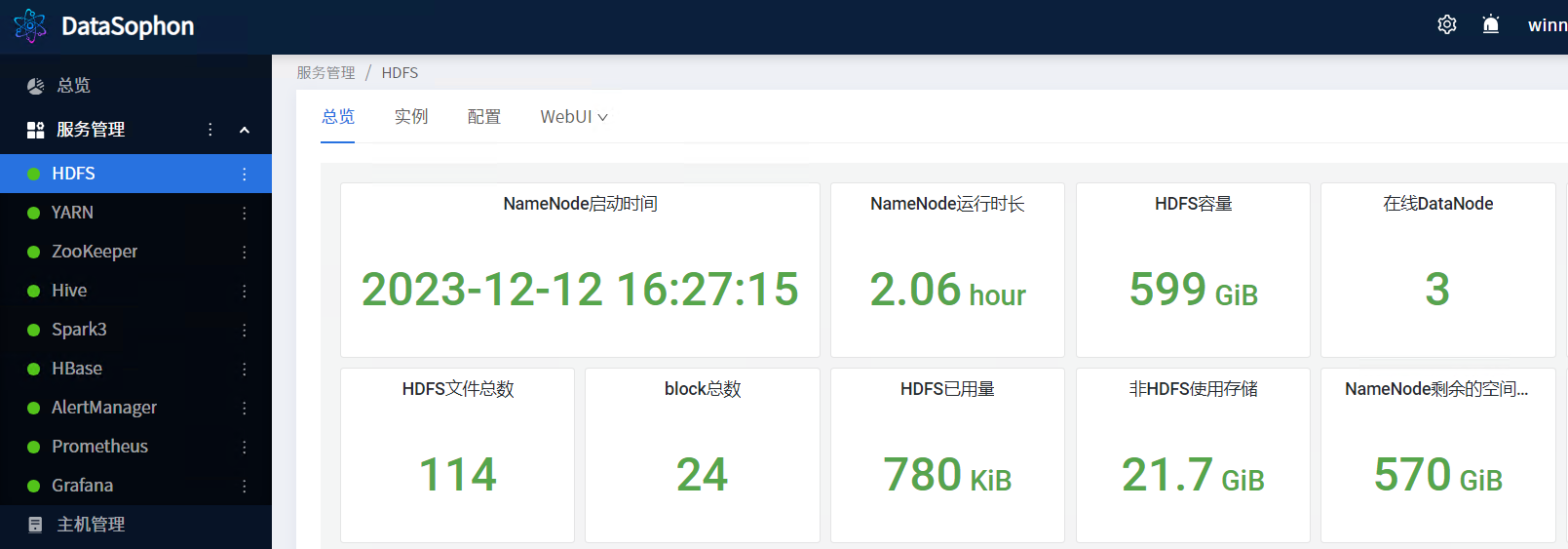
HDFS-WEB页面
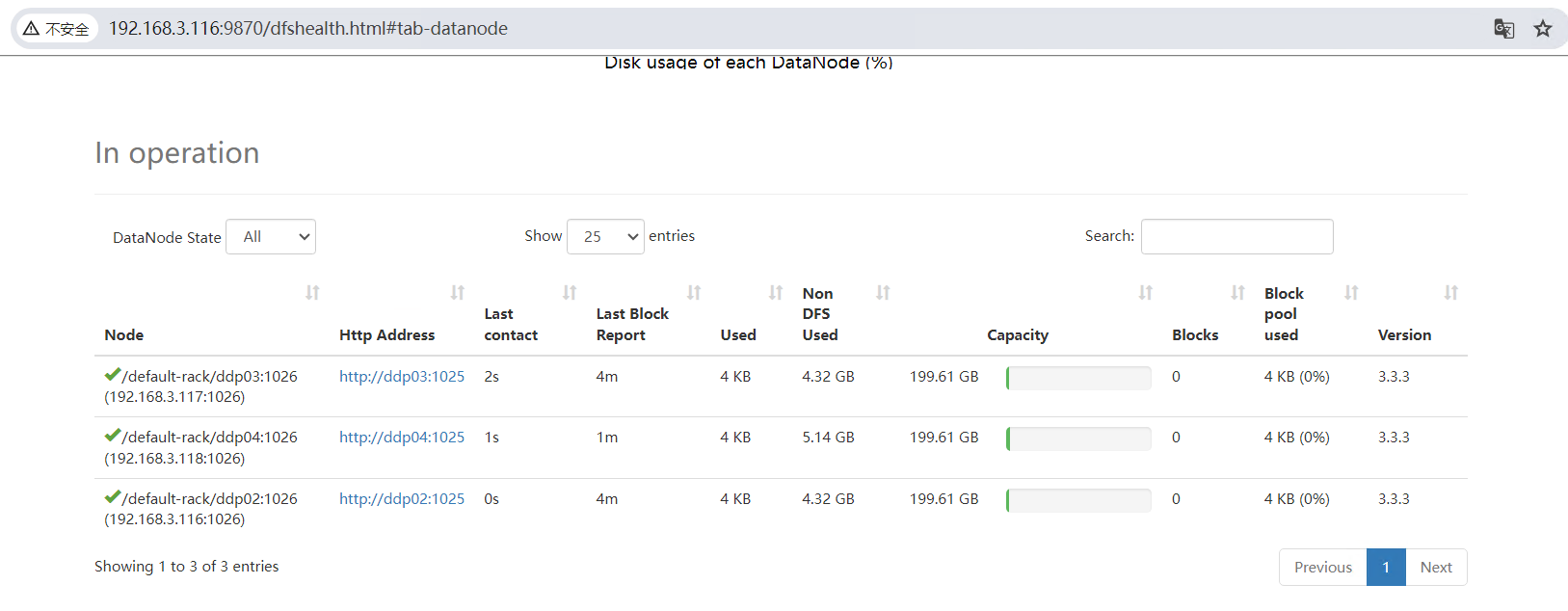
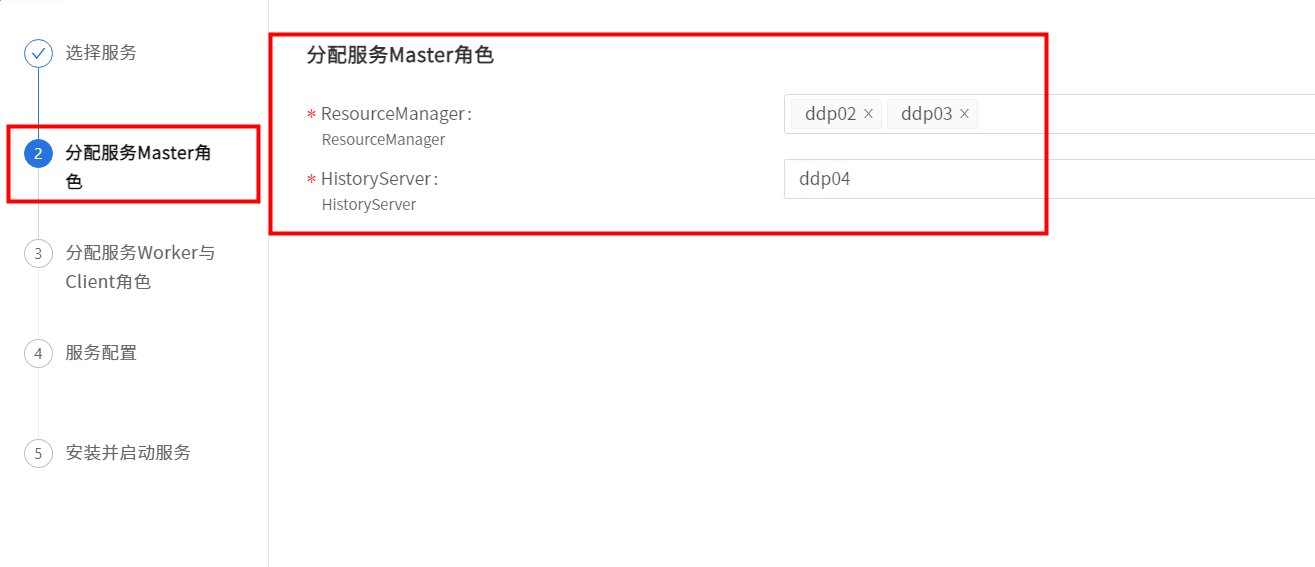
5.3 添加Yarn服务
部署YARN,其中ResourceManager需部署两台作高可用。如下图:
点击【下一步】,选择NodeManager部署节点。

根据实际情况修改配置。
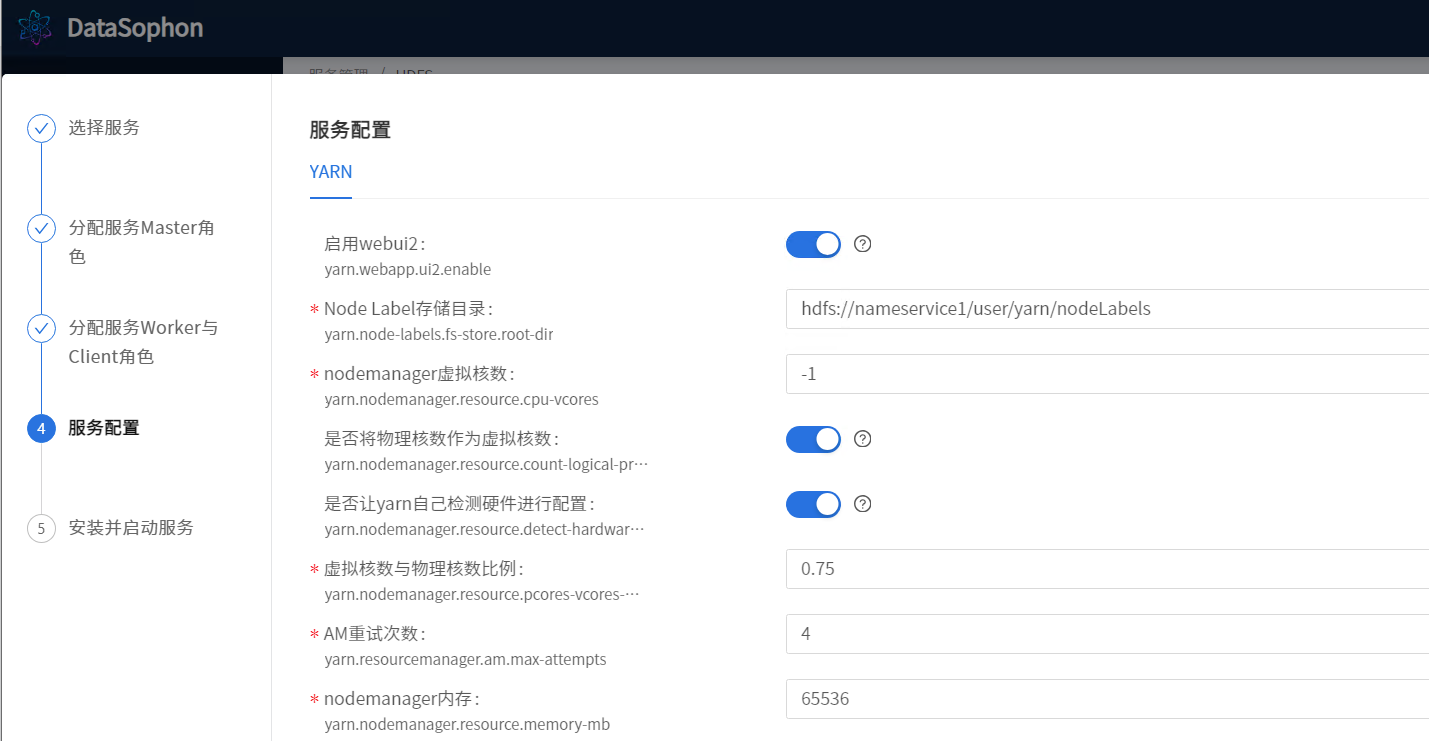
等待安装完成

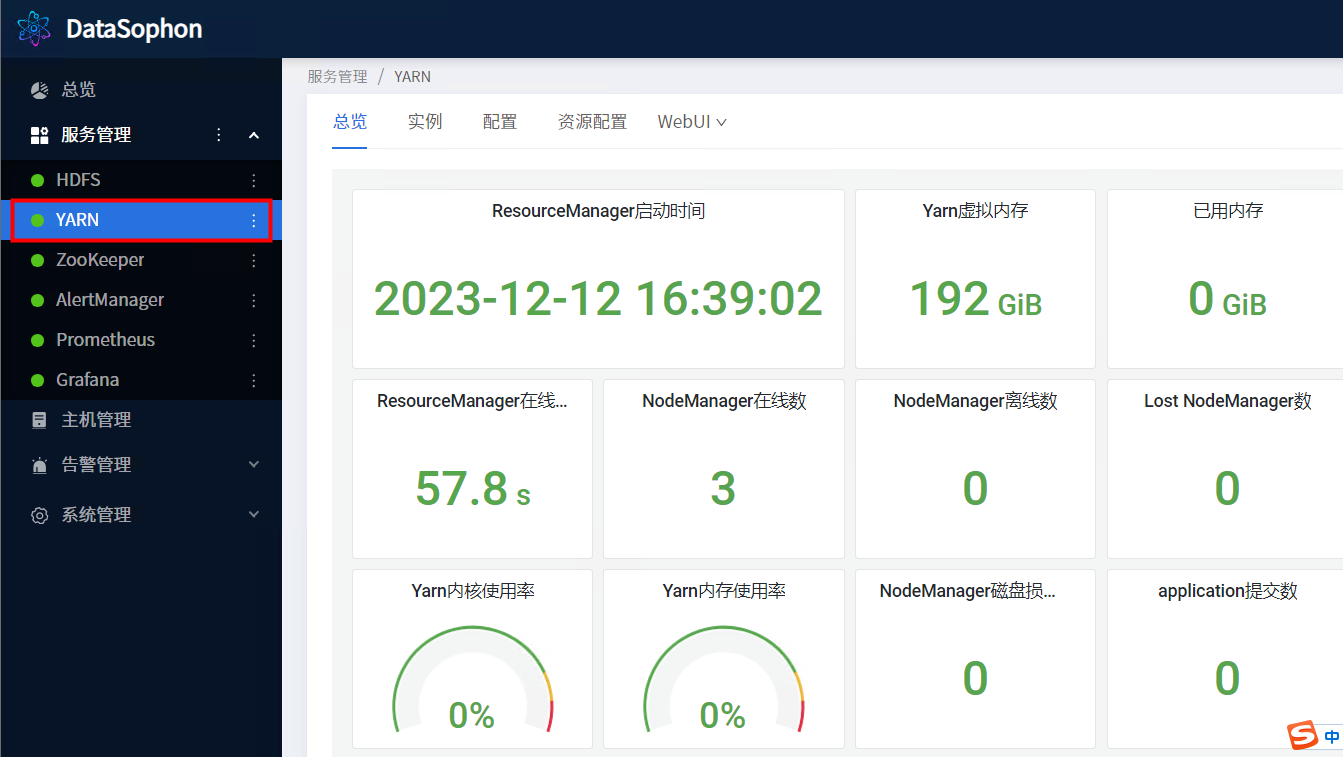
安装成功后,即可查看YARN服务总览页面
5.4 添加Hbase
点击【添加服务】,选择Hbase。
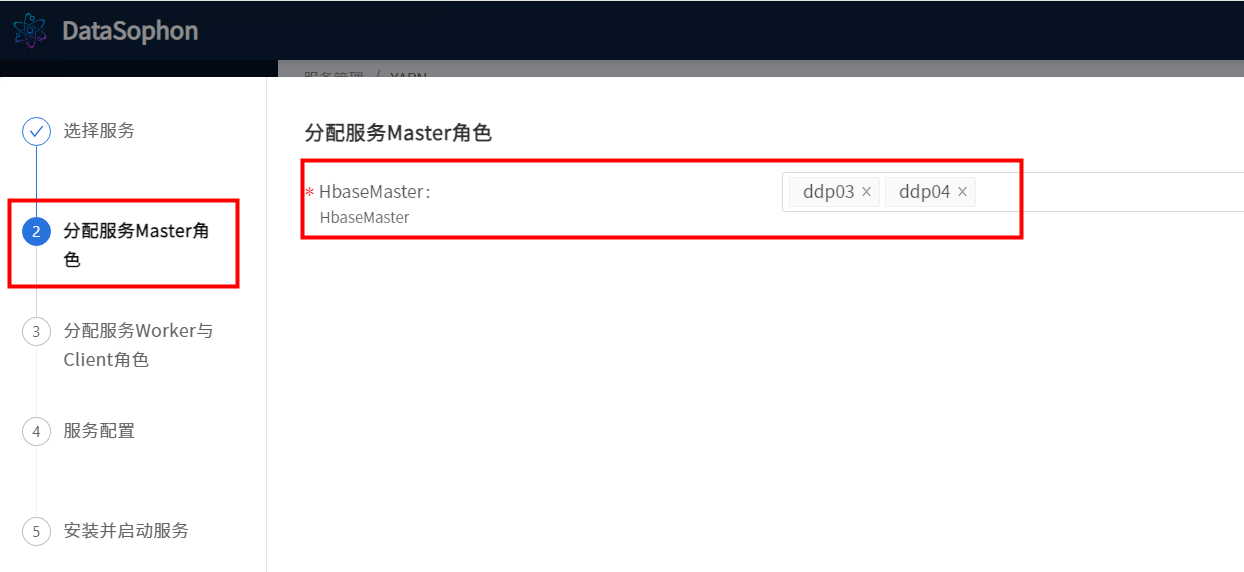
选择RegionServer。

可根据需要修改服务配置。


安装成功后可查看Hbase总览页面。

5.5 添加Spark
选择SPARK3。
Spark没有Master角色,直接点击【下一步】。
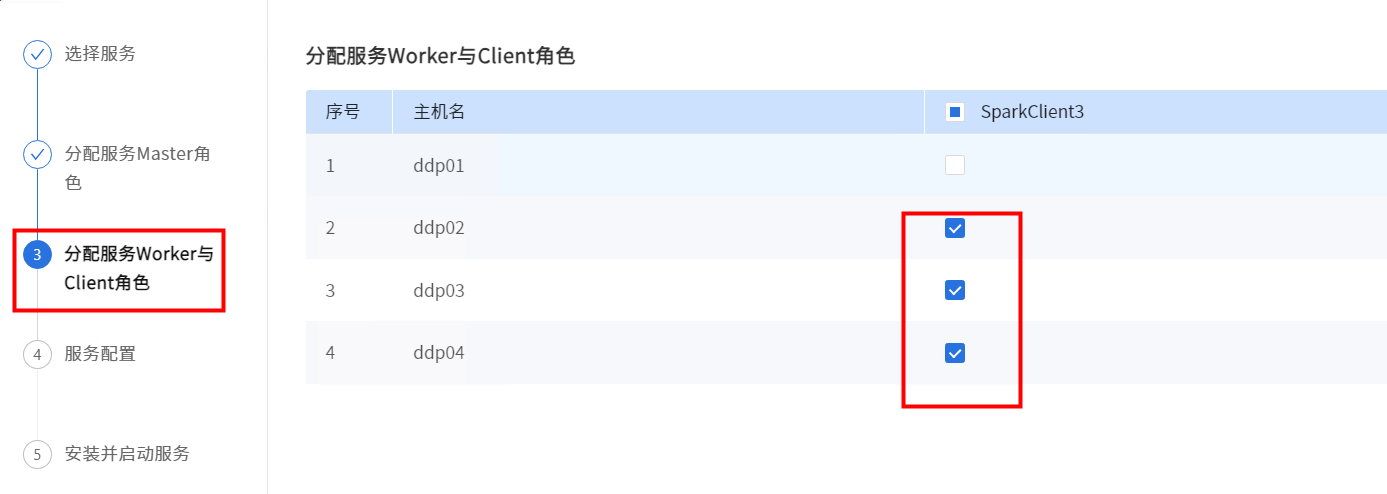
根据实际情况配置

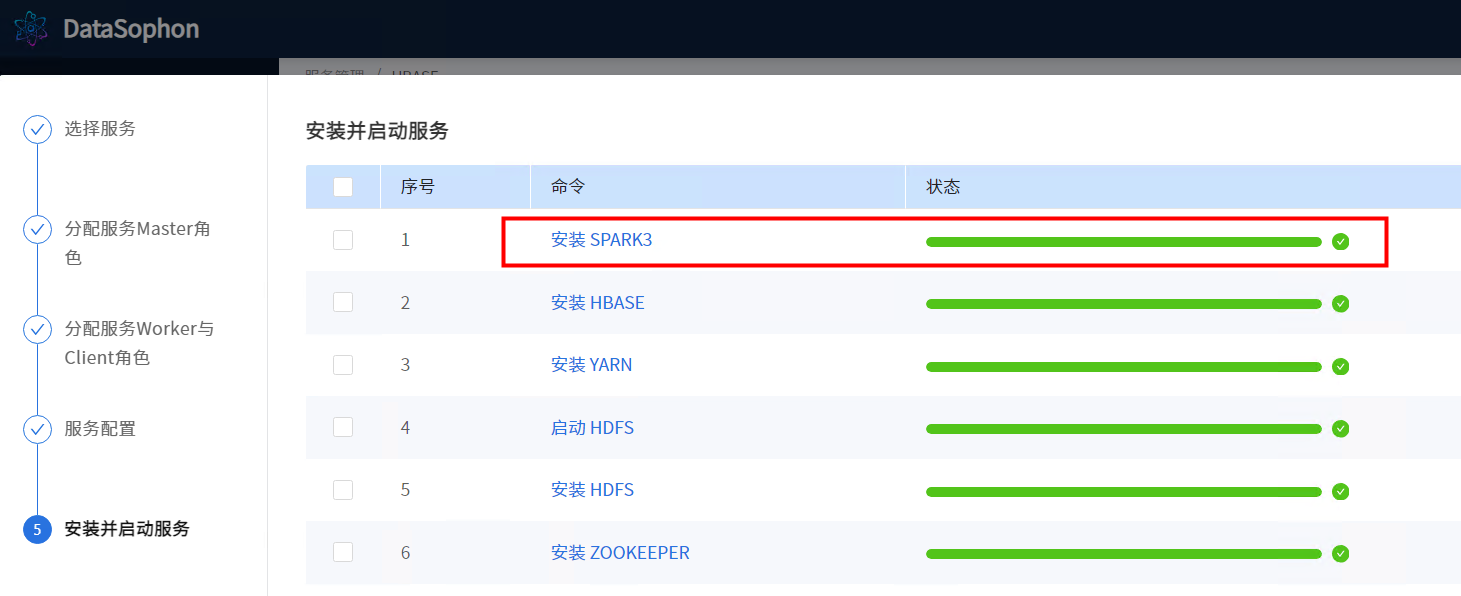
安装完成

5.6 添加Hive
在数据库中创建Hive数据库。
CREATE DATABASE IF NOT EXISTS hive DEFAULT CHARACTER SET utf8;
grant all privileges on *.* to hive@"%" identified by 'hive' with grant option;
GRANT ALL PRIVILEGES ON *.* TO 'hive'@'%';
FLUSH PRIVILEGES;选择需要安装hiveserver2和metastore角色的节点

选择需要安装hiveclient角色的节点
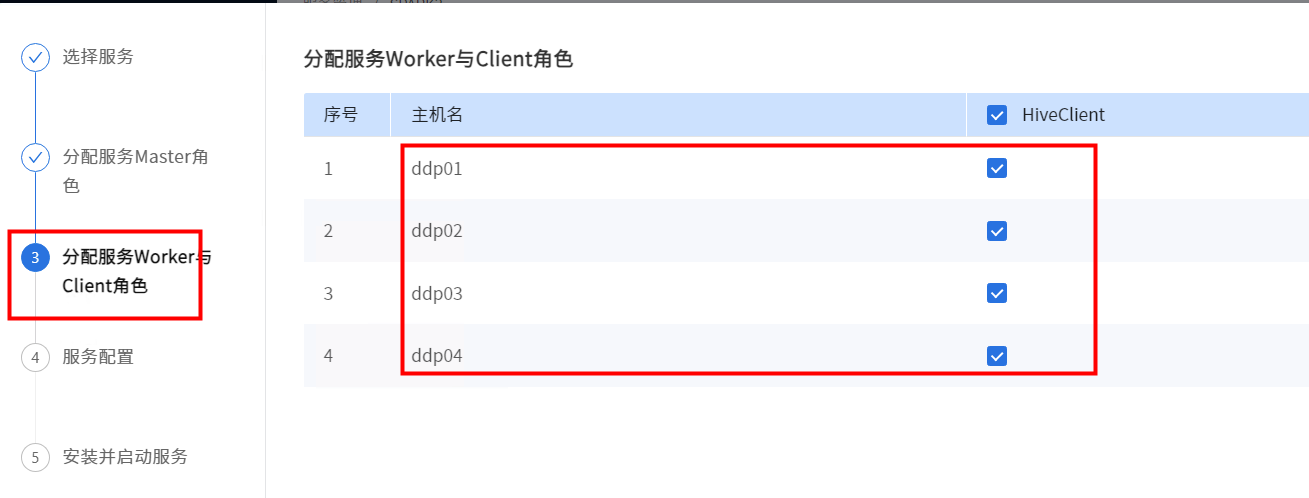
根据实际情况修改配置

等待安装完成,安装成功后即可查看Hive服务总览页面
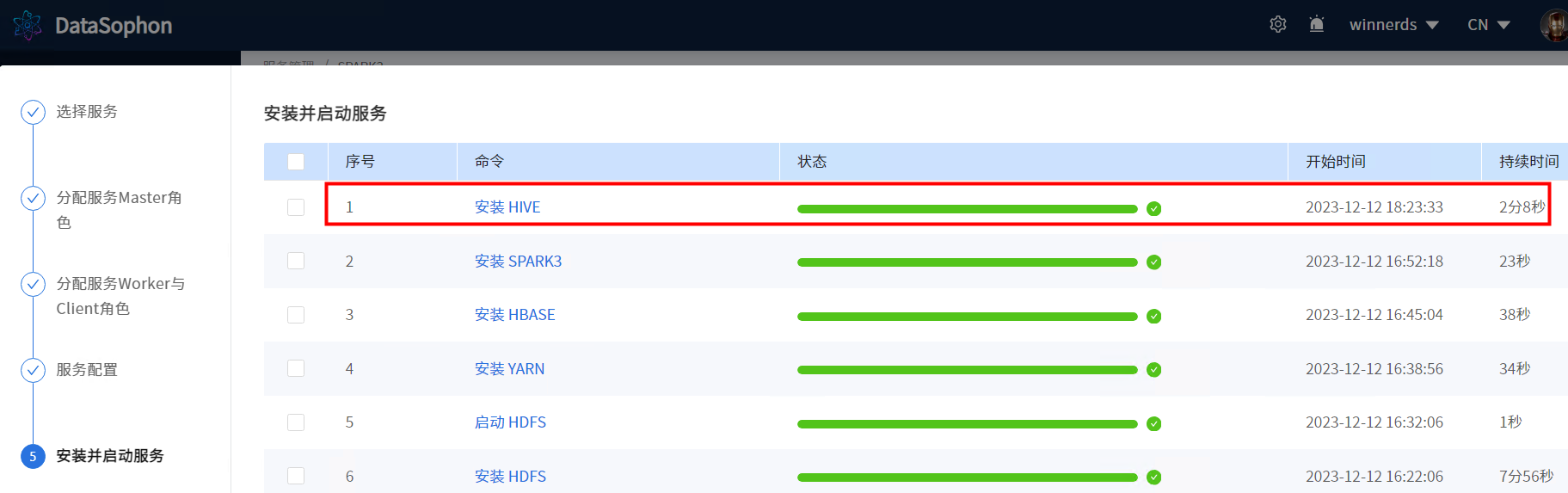
安装成功后可查看Hive总览页面。

5.7添加Flink
点击【添加服务】,选择Flink。

Spark没有Master角色,直接点击【下一步】。
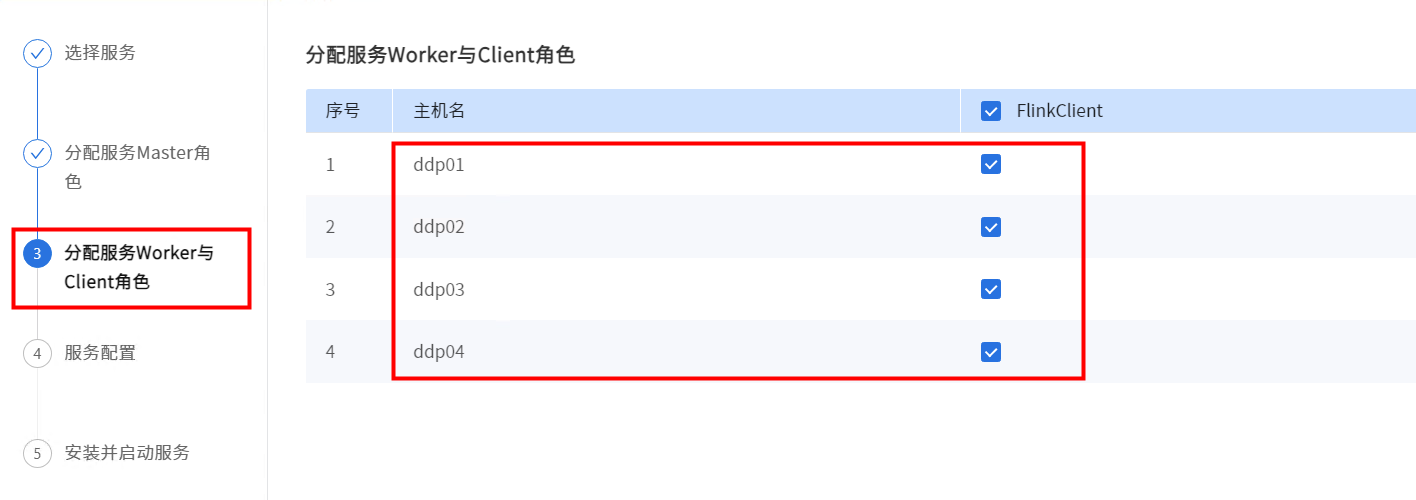
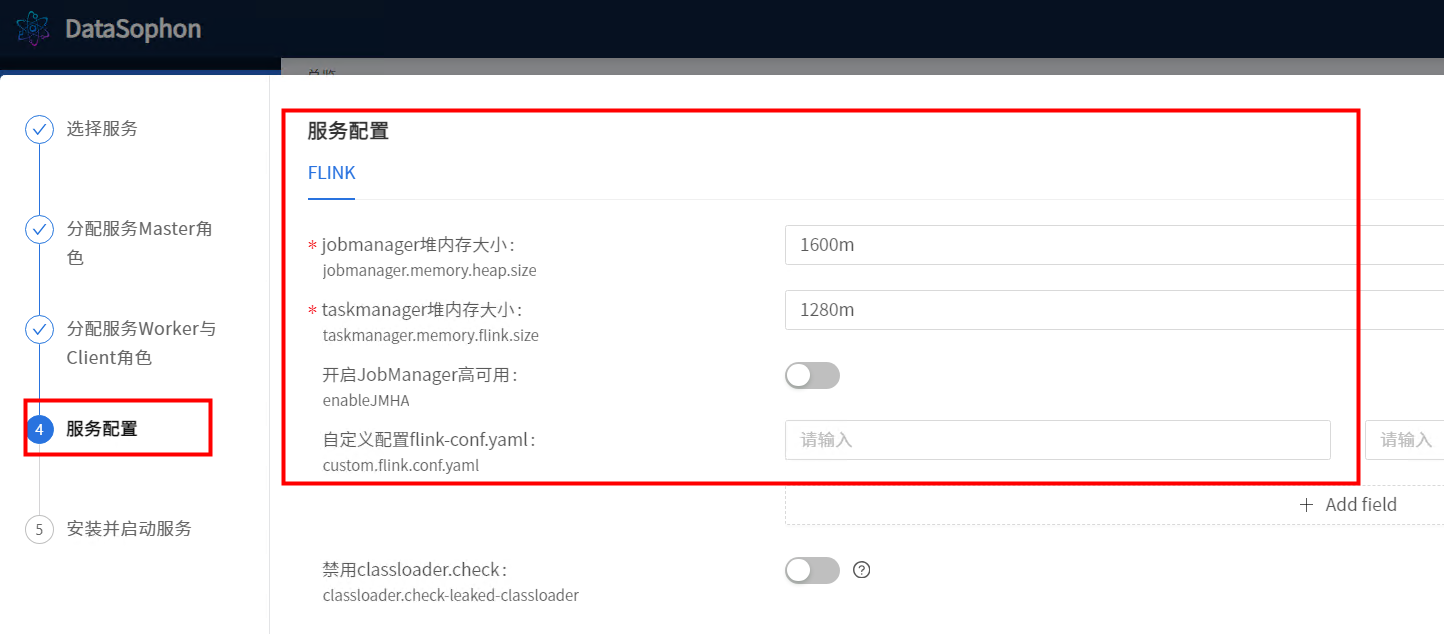
根据实际情况修改Flink服务配置。
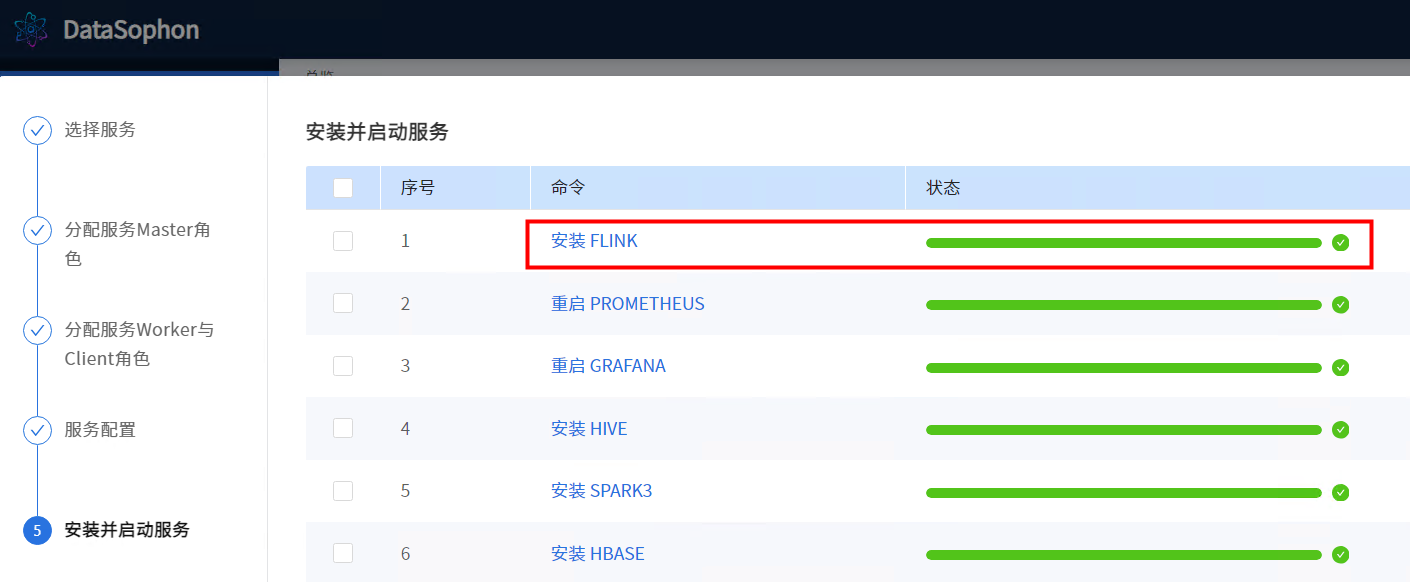
安装成功后即可查看Flink服务总览页面。

5.8 添加kafka
点击【添加服务】,选择kafka。
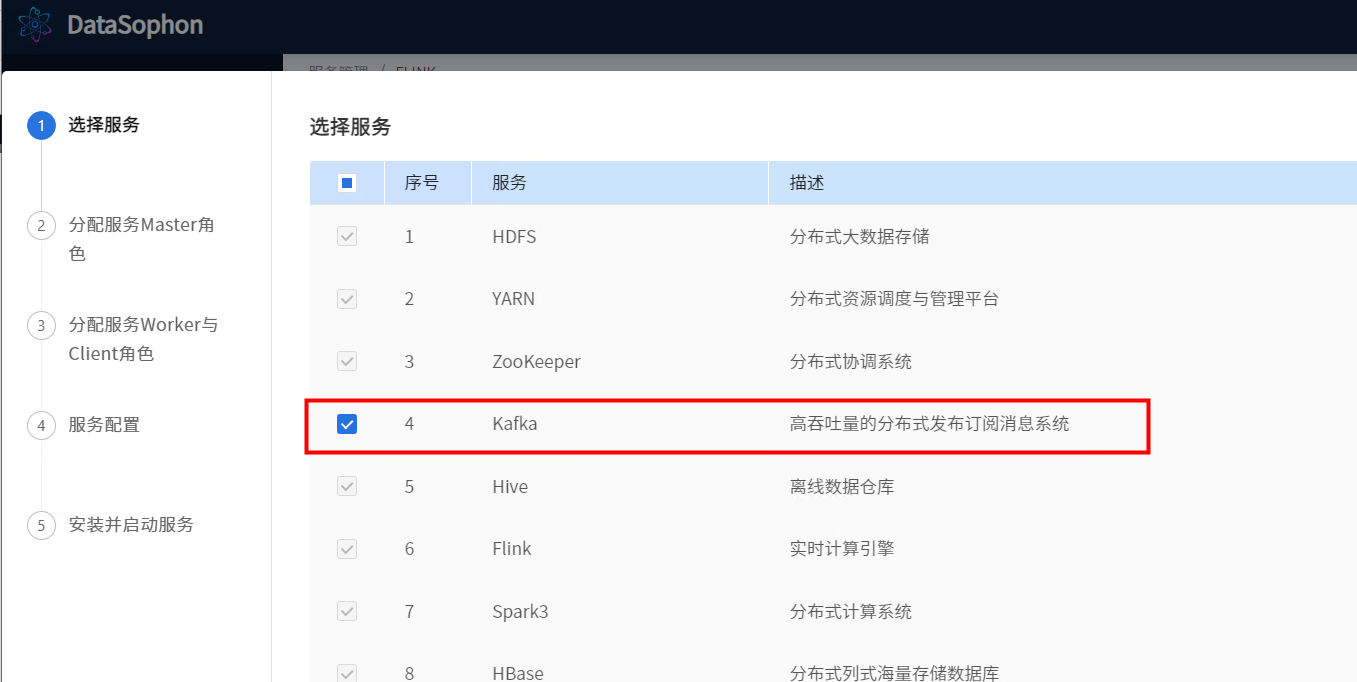
选择安装kafka服务broker角色的节点
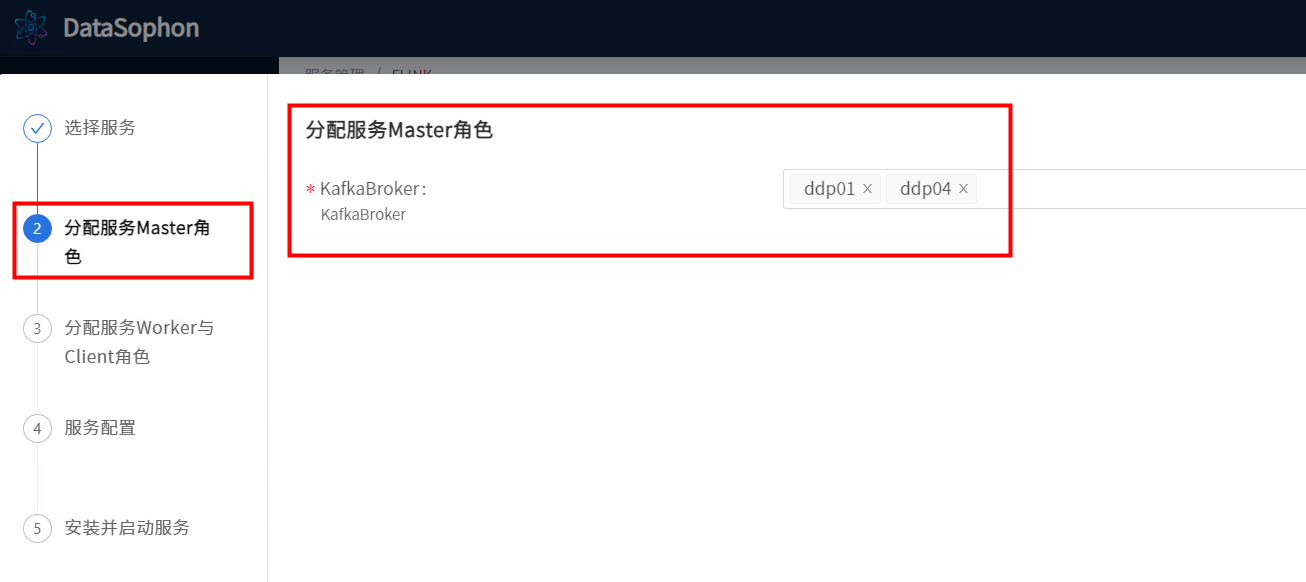
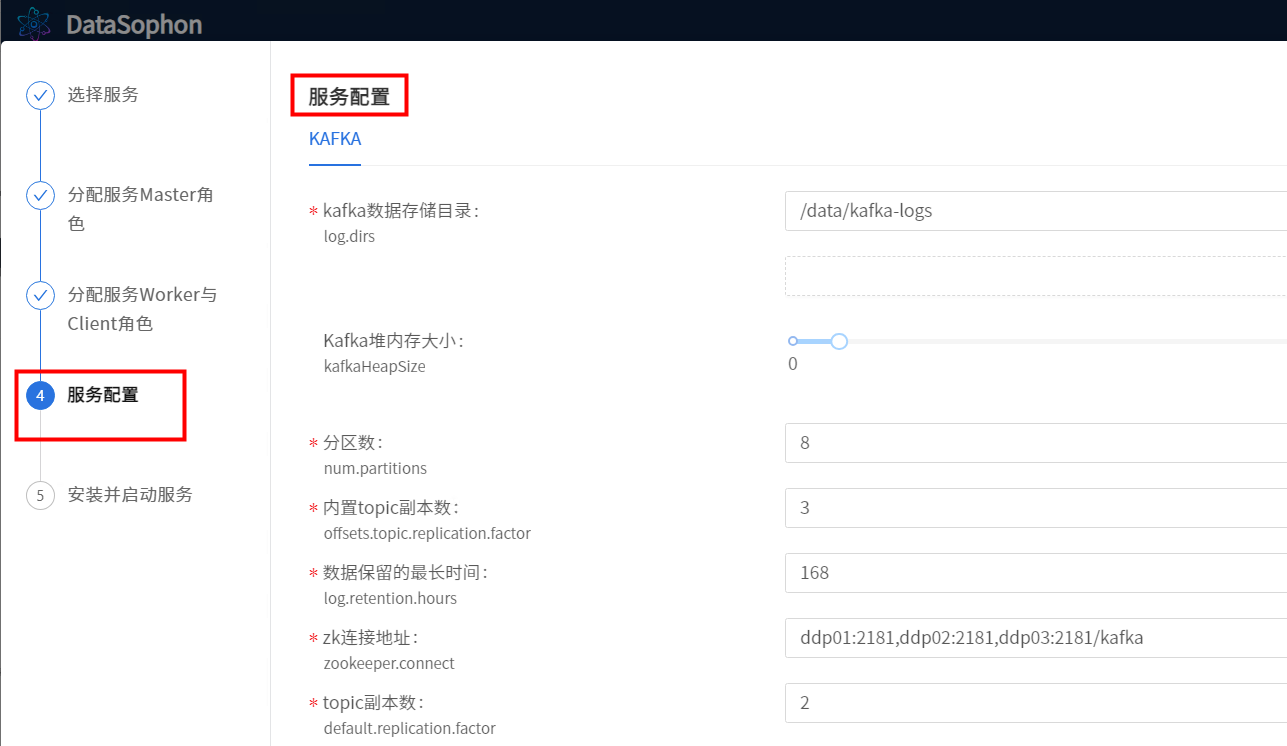
根据实际情况调整Kafka参数。
Kafka安装成功后,即可在Kakfa服务总览页查看Kafka详情。
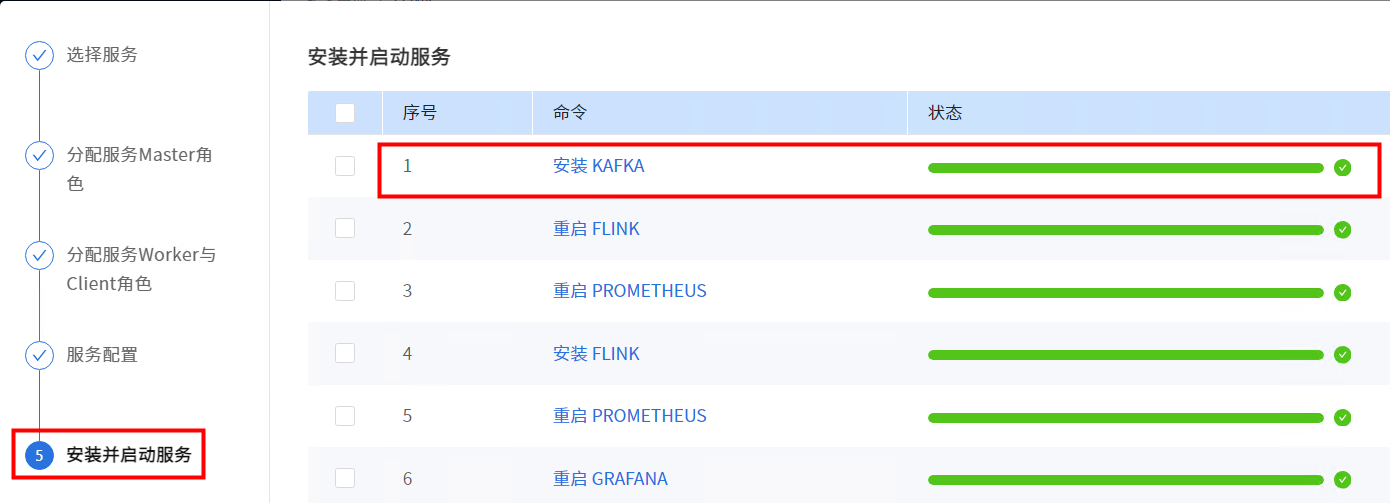
安装成功后可查看Kafka总览页面。

5.9 添加Trino
点击【添加服务】,选择Trino。

选择TrinoCoordinator。
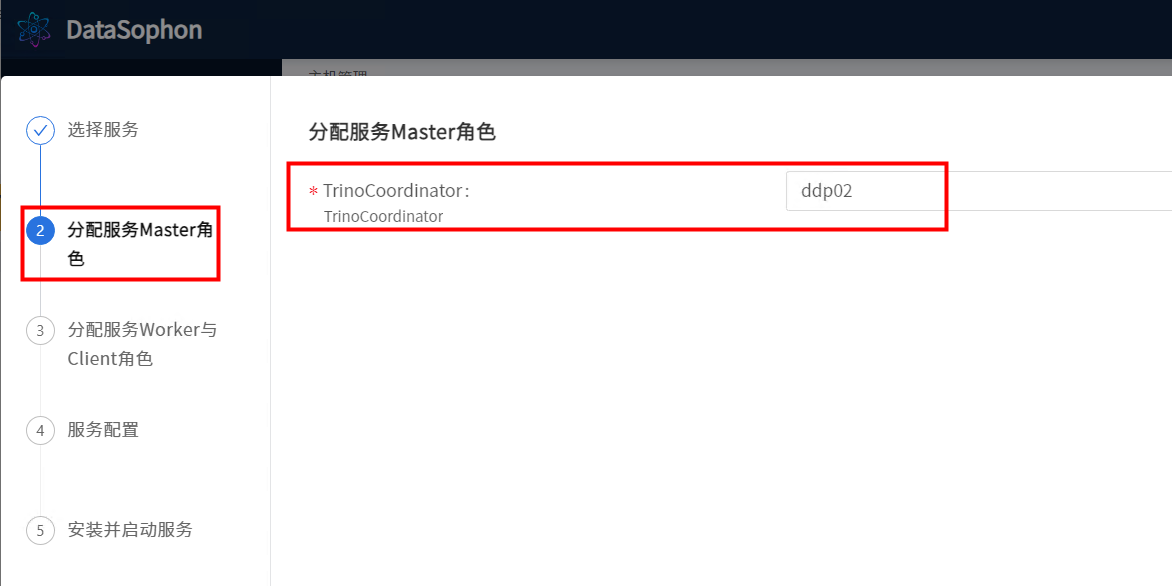
选择TrinoWorker。注意:TrinoCoordinator和TrinoWorker不要部署在同一台机器上。
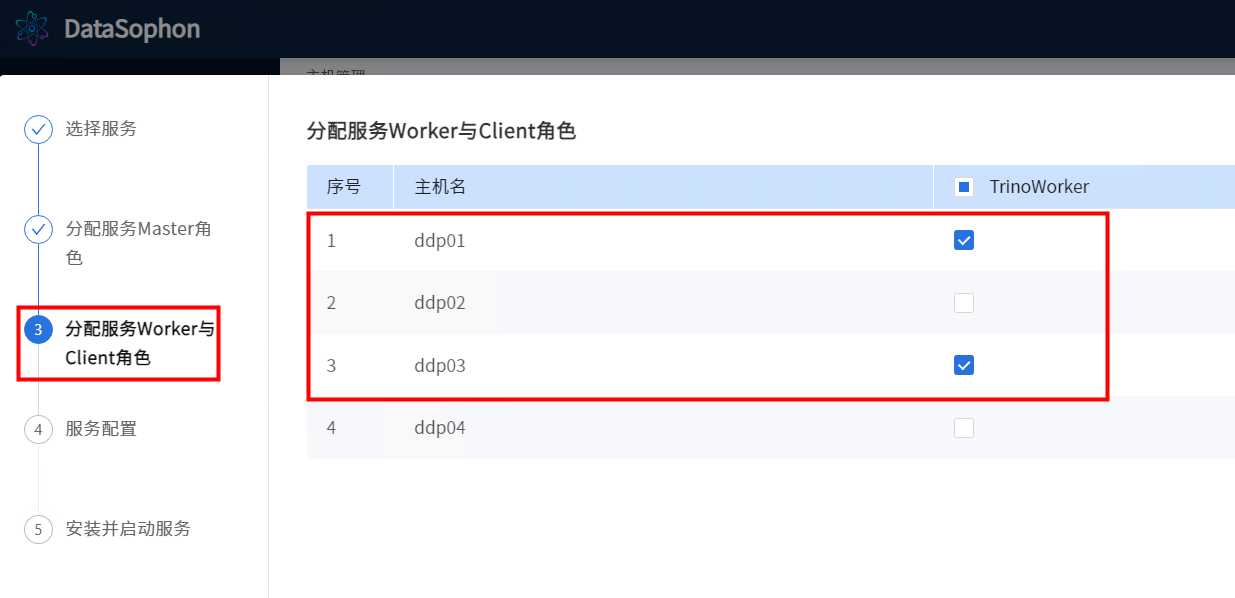
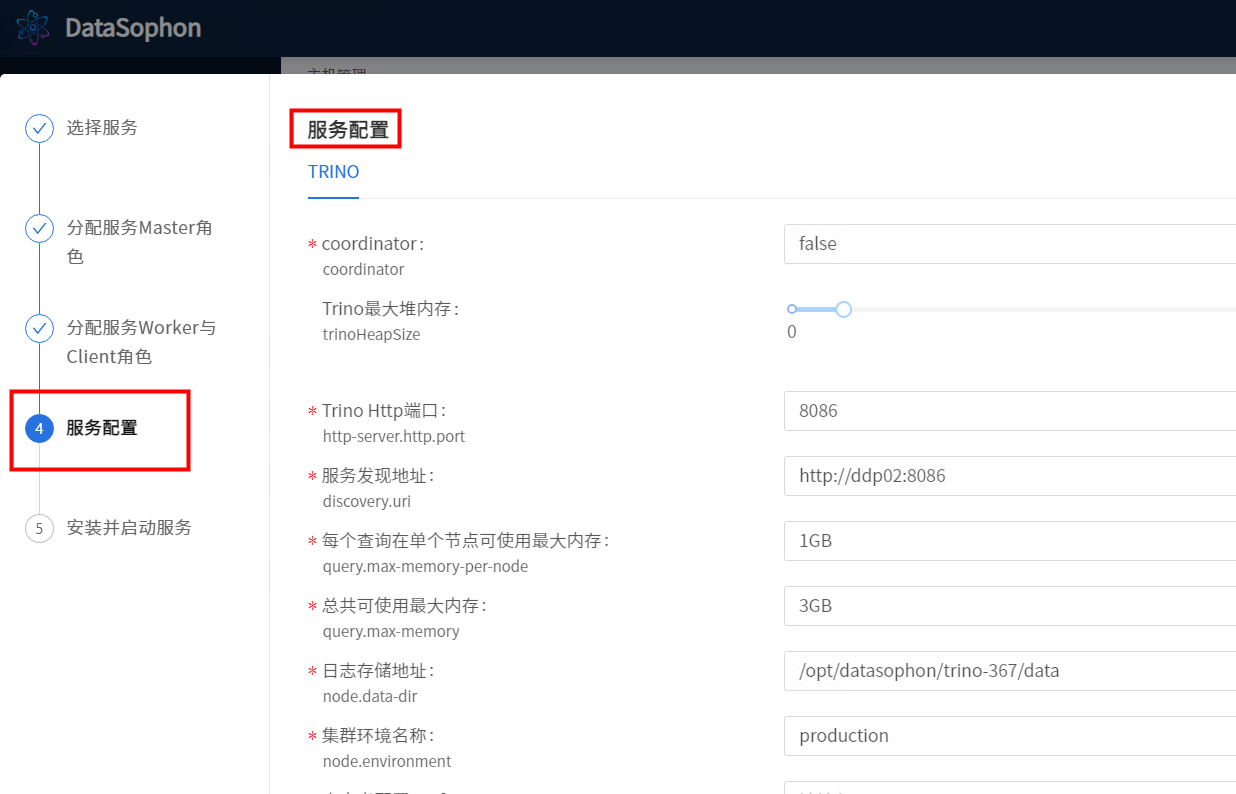
注意"Trino最大堆内存","每个查询在单个节点可使用最大内存"这两个配置,其中"每个查询在单个节点可使用最大内存"不可超过"Trino最大堆内存"的80%,"总共可使用最大内存"为"每个查询在单个节点可使用最大内存"* TrinoWorker数。Trino最大堆内存调整为 6后 正常启动
点击【下一步】,开始安装Trino。
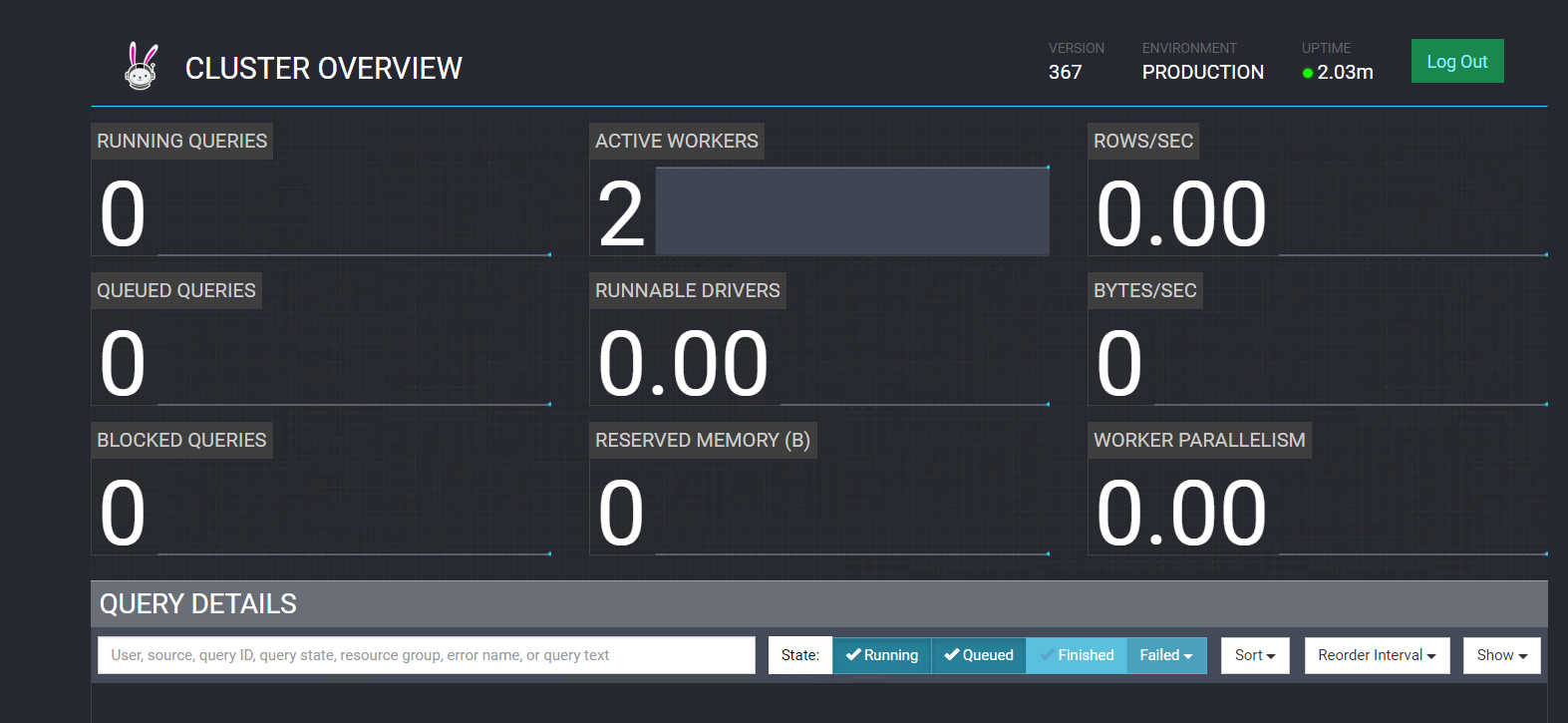
等待安装完成,可以看到Trino总览页面

选择trino的webui,可以访问trino的连接,http://192.168.3.116:8086/ui/
5.10 添加doris服务
点击【添加服务】,选择Doris。
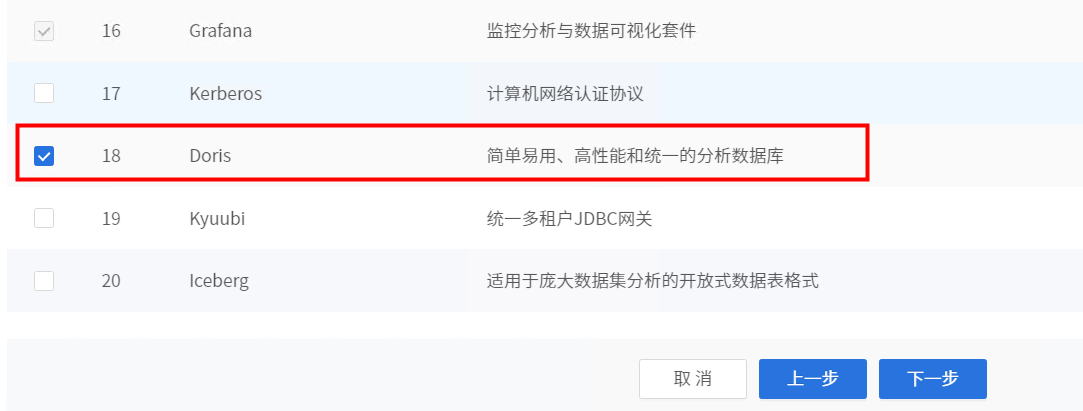
分配FE服务角色部署节点,奇数
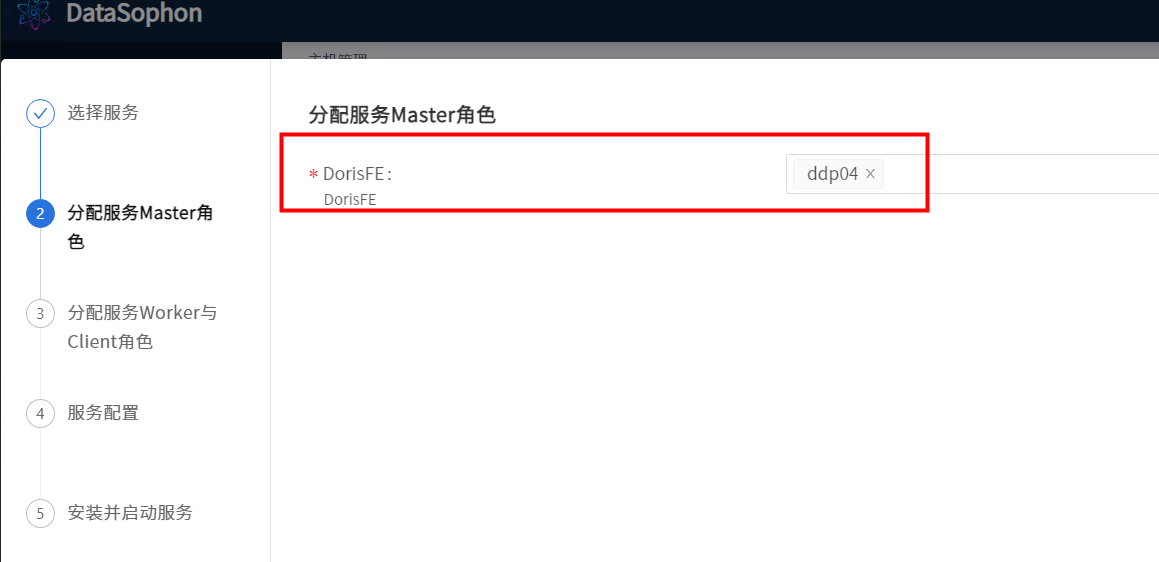
分配DorisBE和DorisFEObserver服务角色部署节点。
警告
DorisFE与DorisFEObserver不能部署在同一台机器上,不然会出现端口冲突。
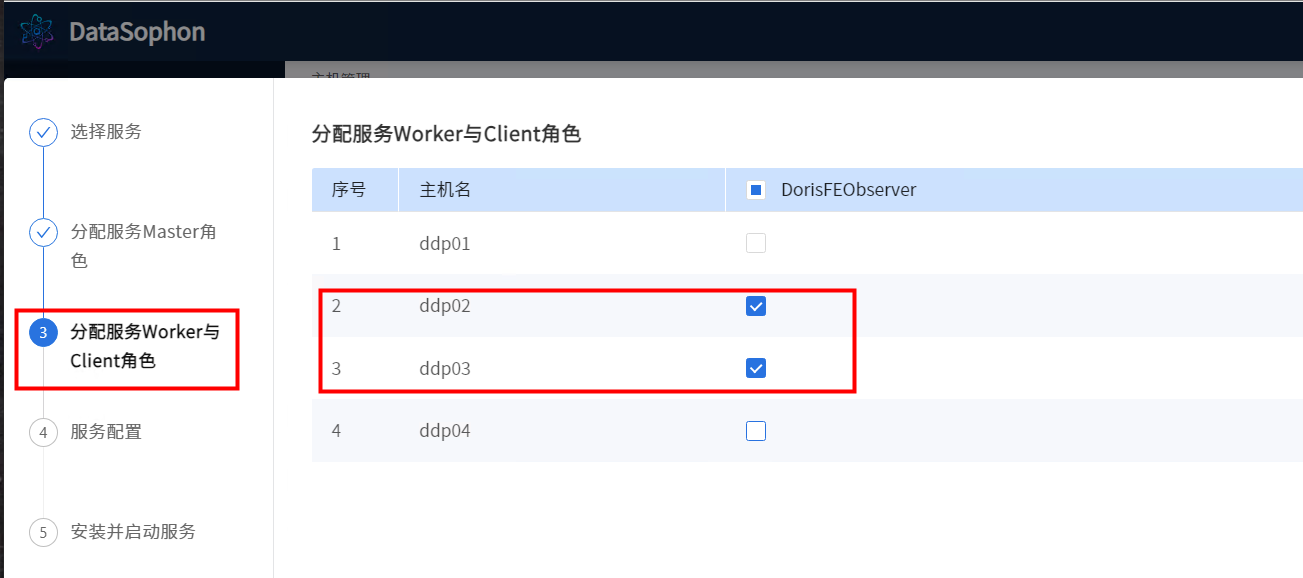
根据需要修改Doris配置,其中FE优先网段和BE优先网段需要配置,如配置成172.31.86.0/24。
安装成功后即可查看Doris服务总览页面。
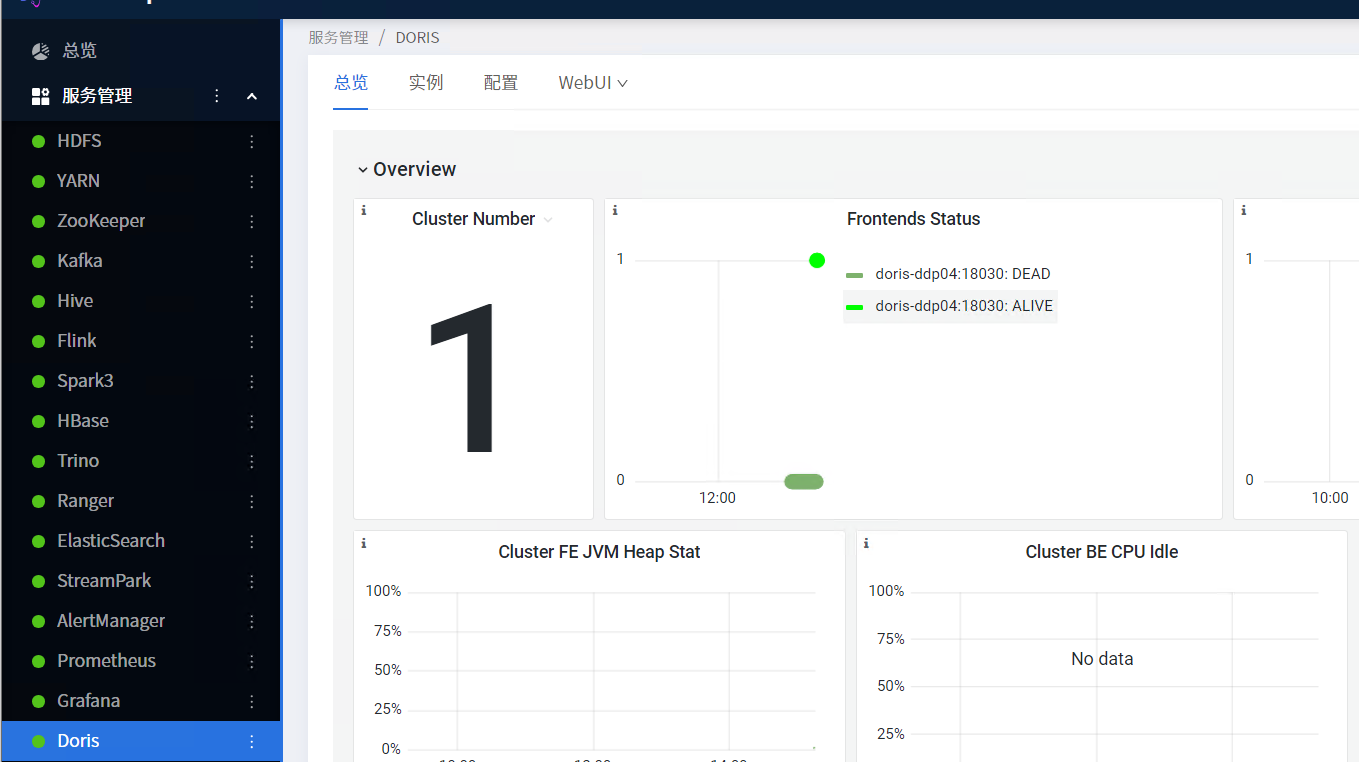
Doris-web页面。

5.11添加ranger
创建ranger数据库
CREATE DATABASE IF NOT EXISTS ranger DEFAULT CHARACTER SET utf8;
grant all privileges on *.* to ranger@"%" identified by 'ranger' with grant option;
GRANT ALL PRIVILEGES ON *.* TO 'ranger'@'%';
FLUSH PRIVILEGES;点击【添加服务】,选择Ranger。

选择RangerAdmin部署节点。

输入数据库root用户密码,数据库地址,Ranger数据用户密码等配置信息。
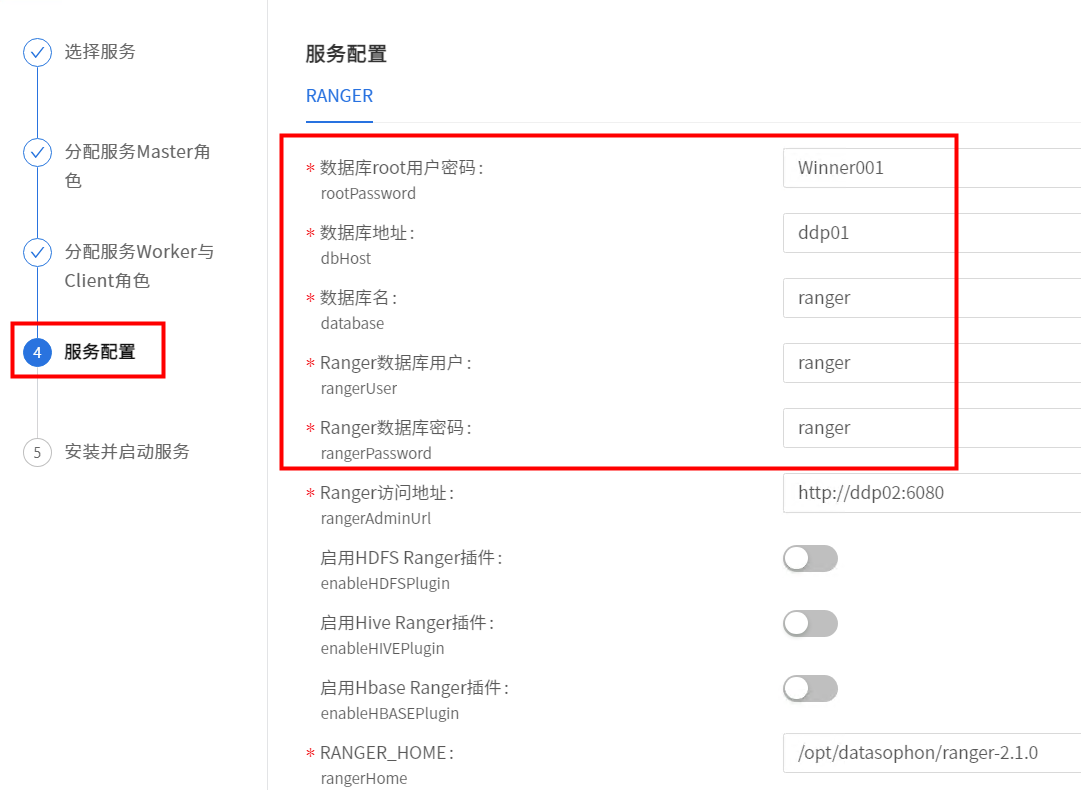
安装成功后即可查看Ranger服务总览页面。

http://192.168.3.116:6080/ admin/admin123

5.12添加DolphinScheduler
初始化DolphinScheduler数据库。
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%' IDENTIFIED BY 'dolphinscheduler';
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'localhost' IDENTIFIED BY 'dolphinscheduler';
flush privileges;执行/opt/datasophon/DDP/packages目录下dolphinscheduler_mysql.sql创建dolphinscheduler数据库表。
添加DolphinScheduler。

分配api-server/alert-server/master-server/worker-server角色

分配Work与Client 角色

根据实际情况,修改DolphinScheduler配置。
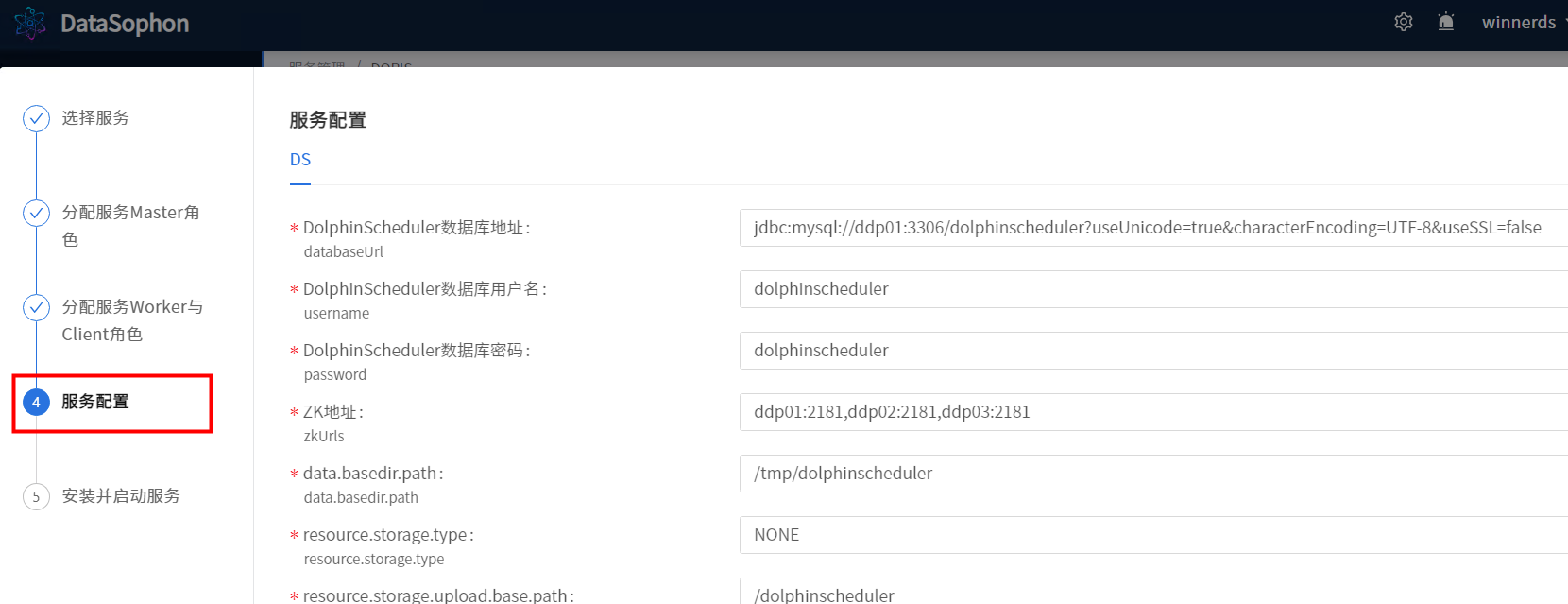
安装成功后即可查看DolphinScheduler服务总览页面。

DolphinScheduler配置页面

5.13添加StreamPark
初始化StreamPark数据库。
CREATE DATABASE streampark DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL PRIVILEGES ON streampark.* TO 'streampark'@'%' IDENTIFIED BY 'streampark';
GRANT ALL PRIVILEGES ON streampark.* TO 'streampark'@'localhost' IDENTIFIED BY 'streampark';
flush privileges;执行/opt/datasophon/DDP/packages目录下streampark.sql创建streampark数据库表。
use streampark;
source /opt/datasophon/DDP/packages/streampark.sql
添加StreamPark。
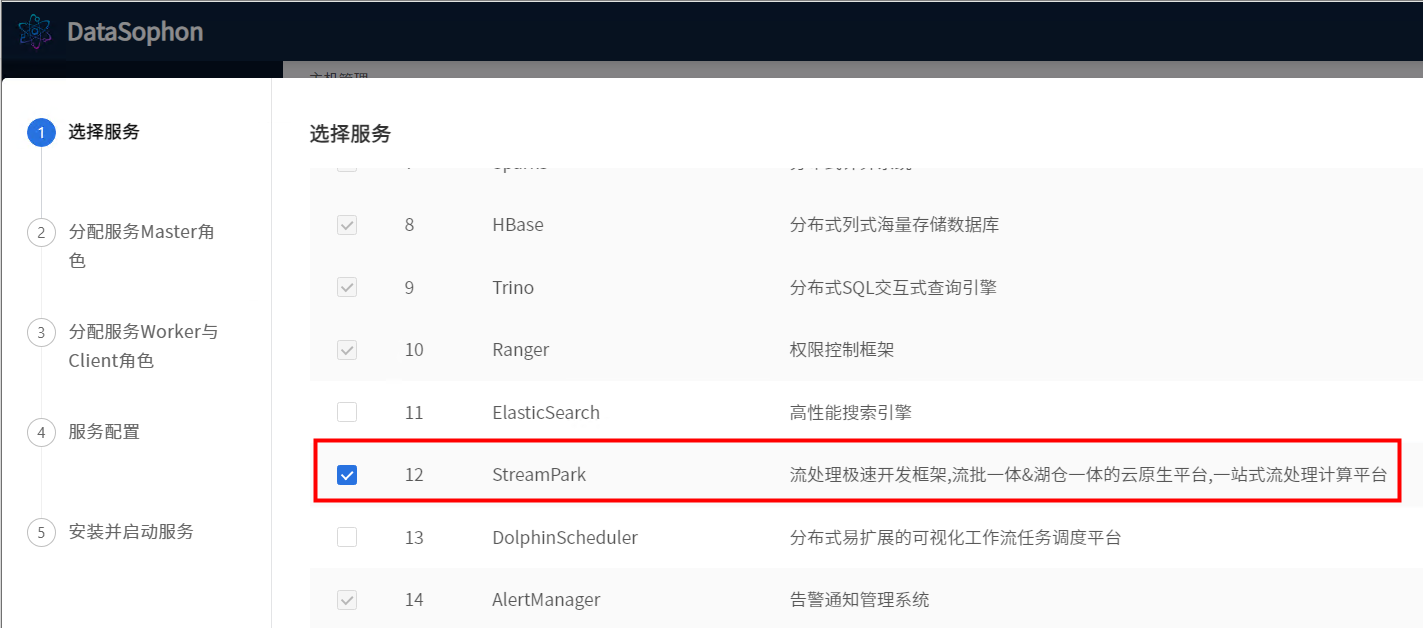
分配streampark角色
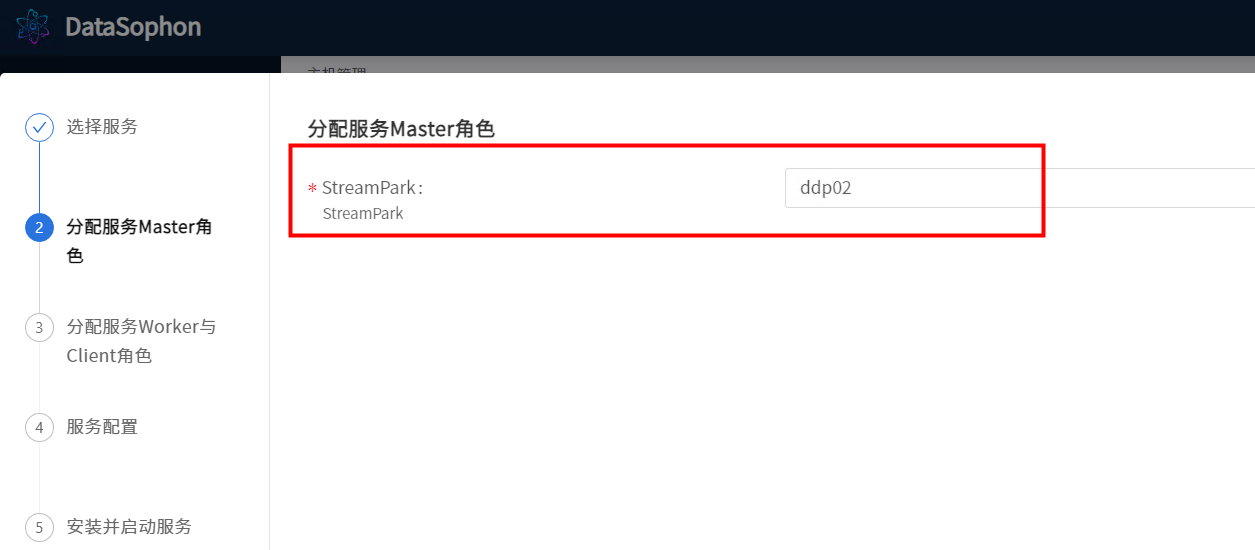
根据实际情况修改配置。

根据实际情况,修改streampark配置。

5.14添加ElasticSearch
点击【添加服务】,选择ES。
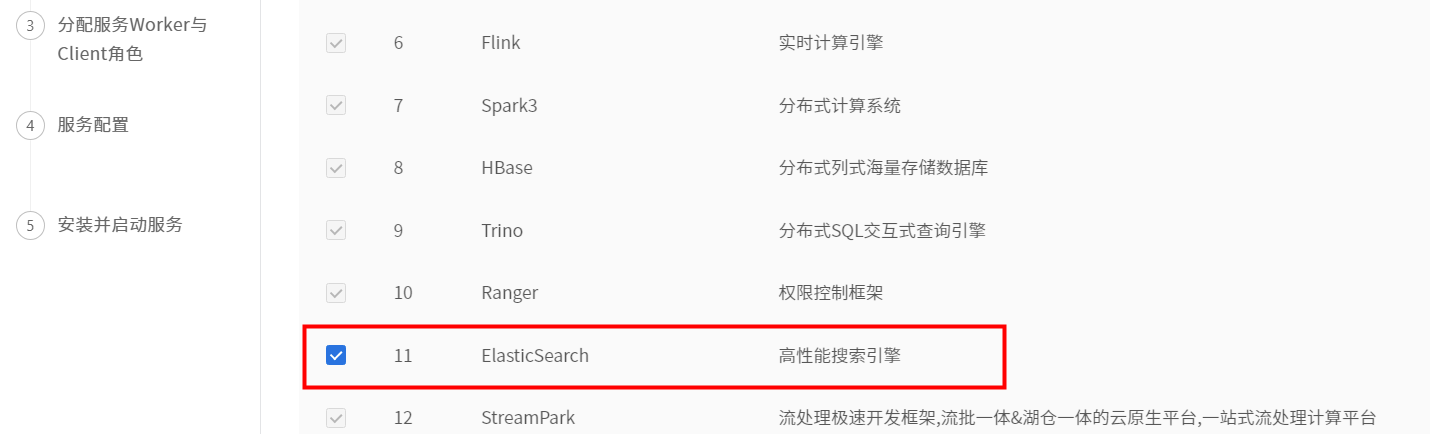
分配服务Master角色
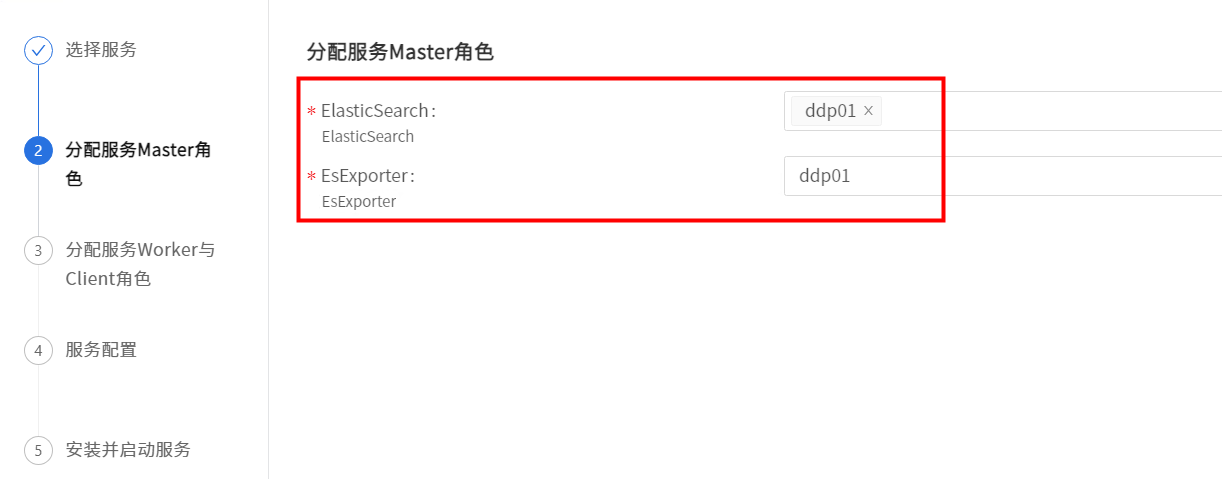
根据实际情况修改配置。

根据实际情况,修改ElasticSearch配置。
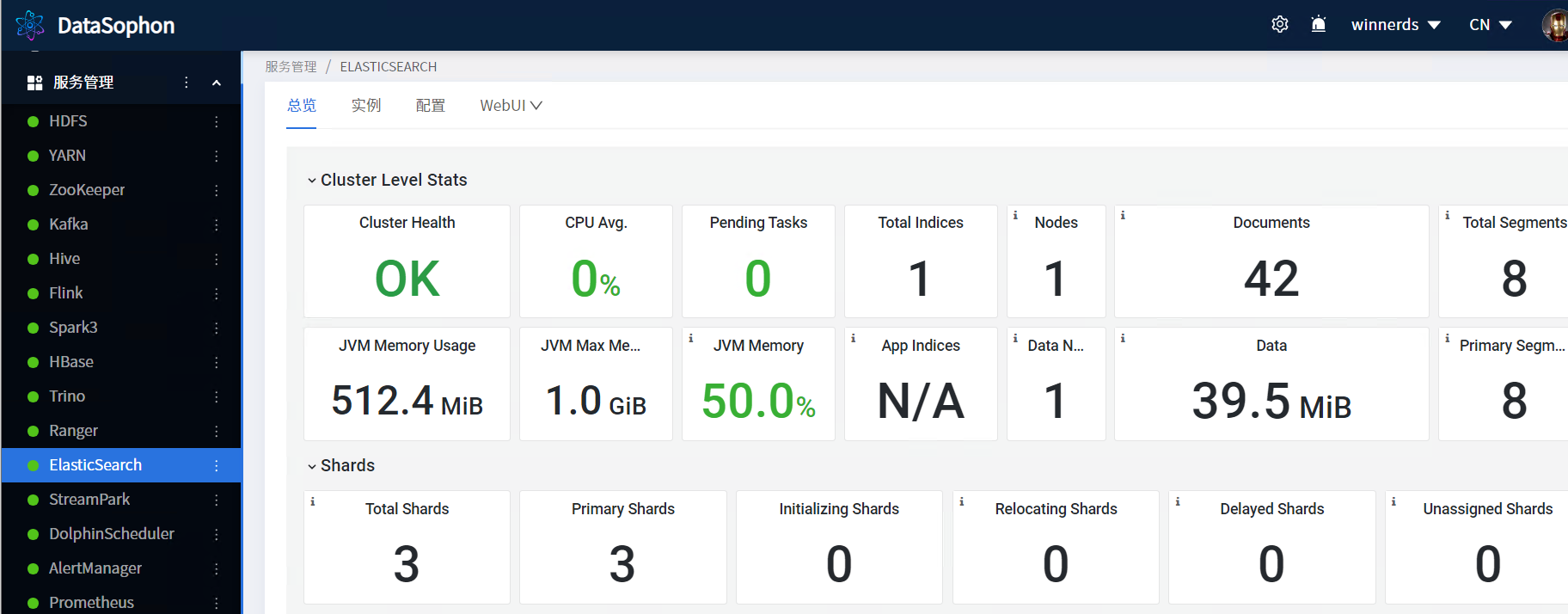
5.15添加Iceberg
点击【添加服务】,选择Iceberg。选择IcebergClient

根据实际情况修改配置。

安装完成

总览