目录
前言
一、K最近邻(KNN)介绍
二、鸢尾花数据集介绍
三、鸢尾花数据集可视化
四、鸢尾花数据分析
总结
🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。
💡本文由Filotimo__✍️原创,首发于CSDN📚。
📣如需转载,请事先与我联系以获得授权⚠️。
🎁欢迎大家给我点赞👍、收藏⭐️,并在留言区📝与我互动,这些都是我前进的动力!
🌟我的格言:森林草木都有自己认为对的角度🌟。


前言
机器学习是一项快速发展的领域,其中K-最近邻算法(K-Nearest Neighbors,简称KNN)是一个经典且常用的算法,可以用于分类和回归问题。在本文中,我们将介绍如何使用KNN算法来实现鸢尾花种类的预测。
一、K最近邻(KNN)介绍
原理:
KNN算法的核心思想是通过计算样本之间的距离来度量它们的相似性。对于分类任务,当给定一个未知样本时,算法会找到与该样本距离最近的K个已知样本,然后根据这K个已知样本的类别标签来预测未知样本的类别。常见的距离度量方法包括欧氏距离、曼哈顿距离、闵可夫斯基距离等。
使用场景:
KNN算法在许多实际应用中被广泛使用,特别是在以下场景中表现出良好的性能:
1.数据集中类别分布均匀、样本点较为离散的情况下,KNN的效果较好。
2.数据集规模较小的情况下,KNN的计算速度较快。
3.对异常值不敏感,可以处理噪声较多的数据集。
相关术语:
K值:K是KNN算法中的一个超参数,用于指定要考虑的最近邻居的个数。选择合适的K值是KNN算法的重要部分,通常通过交叉验证或网格搜索进行选择。
距离度量:KNN算法使用距离度量来评估样本之间的相似性。常见的距离度量方法有欧氏距离、曼哈顿距离、闵可夫斯基距离等。
预测和决策规则:对于分类任务,KNN算法中常用的决策规则是投票法,即选择K个邻居中出现最频繁的类别作为预测类别。对于回归任务,通常使用K个邻居的平均值来进行预测。
超参数选择:KNN算法中常见的超参数有K值和距离度量方法等。选择合适的超参数对模型的性能和准确度至关重要,常用的方法是通过交叉验证或网格搜索来选择最佳超参数组合。
基本流程:
1.加载数据集,划分为训练集和测试集。
2.根据训练集计算样本之间的距离。
3.选择K值,并找到距离未知样本最近的K个样本。
4.使用投票法或平均值法来预测未知样本的类别或数值。
5.评估模型在测试集上的性能和准确度。
6.根据需要调整超参数K和距离度量方法,并重新训练和评估模型。
优化模型性能:
1.特征选择和特征工程:选择与分类或回归任务相关的有效特征,并对数据进行预处理和归一化处理,以减少特征间的差异性。
2.调整K值:选择合适的K值很重要,若选择较小的K值容易受到噪声干扰,而较大的K值容易忽略局部特征,因此应通过交叉验证等方法选择最佳K值。
3.距离度量方法的选择:根据实际情况选择适当的距离度量方法,如曼哈顿距离适用于处理具有非连续特征的数据,而欧氏距离适用于处理连续特征的数据。
4.数据预处理:对数据进行特征缩放、离群值处理等预处理步骤,以提高模型的鲁棒性和准确性。
5.交叉验证和模型评估:使用交叉验证来评估模型在不同数据集上的泛化能力,以选择最佳的模型。
6.集成学习:考虑使用集成学习方法,如投票集成或基于KNN的Bagging方法来进一步提升KNN算法的性能。
二、鸢尾花数据集介绍
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。
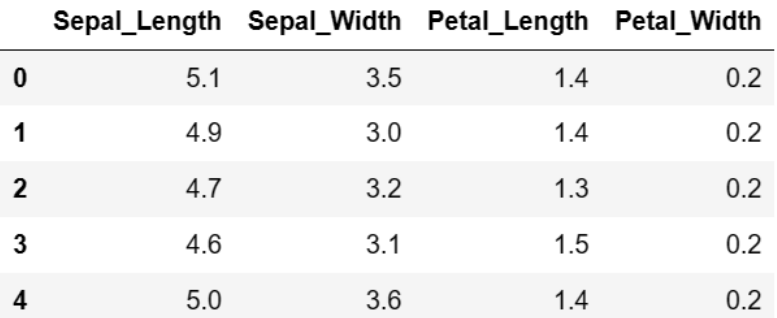
数据集介绍:

数据集样例:
三、鸢尾花数据集可视化
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import load_iris
def iris_plot(data, x_col, y_col):
sns.lmplot(x=x_col, y=y_col, data=data, hue="target", fit_reg=False)
plt.title("鸢尾花数据显示")
plt.show()
# 设置字体为中文黑体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 加载数据集
iris = load_iris()
# 创建数据框
iris_df = pd.DataFrame(data=iris.data, columns=['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'])
iris_df["target"] = iris.target
# 绘制图表
iris_plot(iris_df, 'Sepal_Width', 'Petal_Length')我们使用了 seaborn 库和 matplotlib 库进行绘制。在绘制之前,先加载了鸢尾花数据集,并将其转换为数据框格式。然后定义了一个 iris_plot 函数,用于绘制散点图。最后调用该函数,以花萼宽度和花瓣长度作为 x 轴和 y 轴绘制。也就是将数据集中的样本点按照花瓣长度和花萼宽度两个指标在二维坐标系上进行了展示,并且以不同颜色对应不同类型的鸢尾花。

四、鸢尾花数据分析
import pandas as pd
import joblib
import os
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
iris = load_iris()
X = iris.data
y = iris.target
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
param_grid = {"n_neighbors": [1, 3, 5, 7]}
estimator = KNeighborsClassifier()
grid_search = GridSearchCV(estimator, param_grid=param_grid, cv=5)
grid_search.fit(x_train, y_train)
estimator = grid_search.best_estimator_
if not os.path.exists("./model"):
os.makedirs("./model")
joblib.dump(estimator, "./model/model.pkl")
estimator = joblib.load("./model/model.pkl")
y_pred = estimator.predict(x_test)
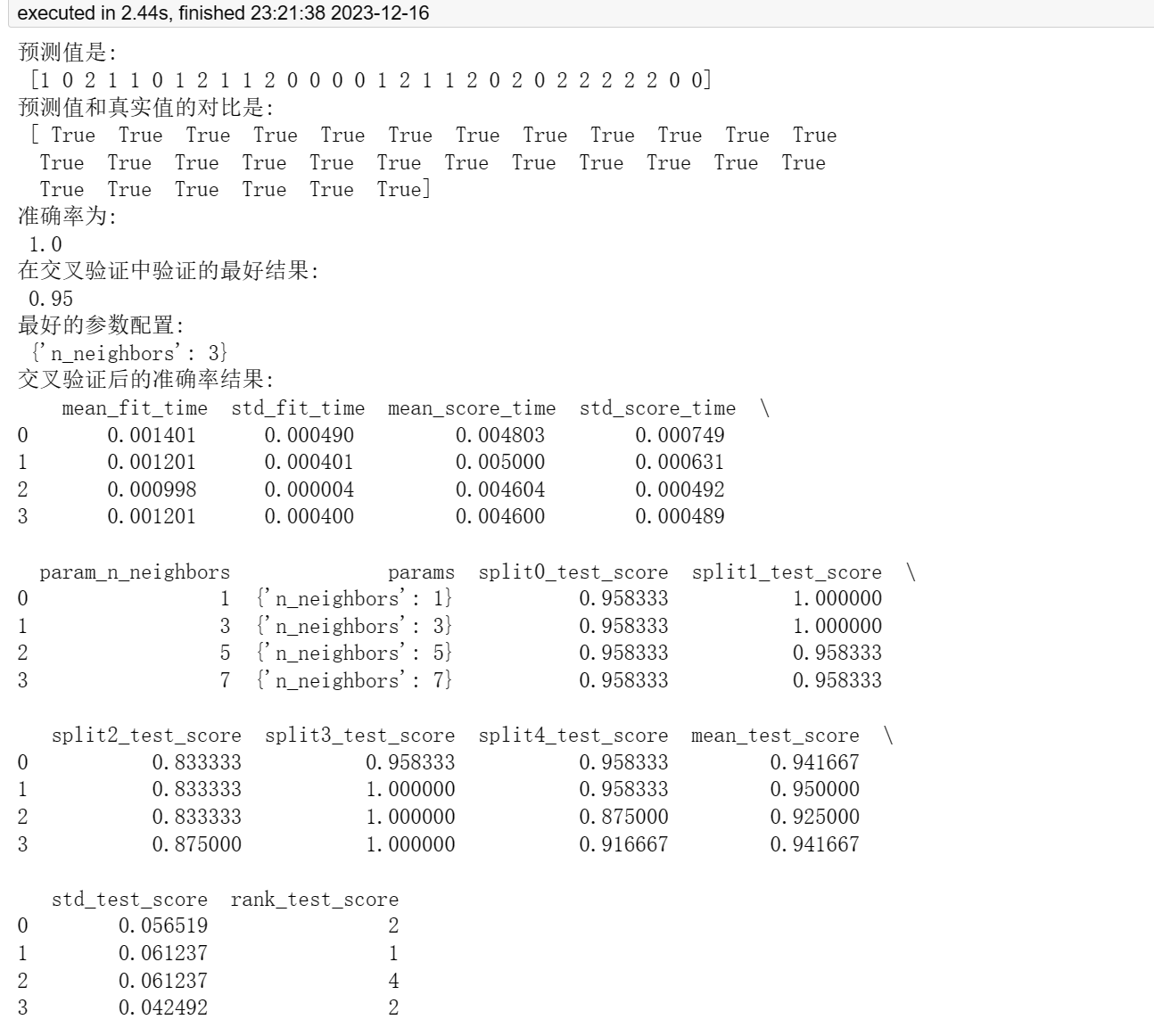
print("预测值是:\n", y_pred)
print("预测值和真实值的对比是:\n", y_pred == y_test)
score = estimator.score(x_test, y_test)
print("准确率为: \n", score)
print("在交叉验证中验证的最好结果:\n", grid_search.best_score_)
print("最好的参数配置:\n", grid_search.best_params_)
cv_results = pd.DataFrame(grid_search.cv_results_)
print("交叉验证后的准确率结果:\n", cv_results)使用 K 最近邻算法对鸢尾花数据集进行分类。
我们主要使用了 pandas、joblib、os、sklearn 中的一些模块和函数。
我们首先加载鸢尾花数据集,然后将数据集分为训练集和测试集。接下来对训练集和测试集进行了特征标准化处理,使用了 StandardScaler 类对数据进行标准化。
然后定义一个参数网格 param_grid,用于指定超参数 n_neighbors 的取值。创建一个 KNeighborsClassifier 估计器,用于训练和预测。通过 GridSearchCV 类对模型进行了交叉验证和参数调优,并选出了最佳的模型估计器。
通过 joblib 模块将最佳的模型保存到./model/model.pkl文件中,并再次加载该模型。
利用这个模型对测试集进行预测,并计算准确率。同时打印了预测值、预测值和真实值的对比结果,交叉验证后的最佳得分和最佳参数配置。
使用 pd.DataFrame 将交叉验证的结果转换为数据框格式,并打印交叉验证后的准确率结果。
我们可以通过这段代码可以了解到如何使用 K 最近邻算法对数据集进行分类,并使用网格搜索和交叉验证对模型进行参数调优。
总结
在本文中,我们学习了如何使用KNN算法来预测鸢尾花的种类。我们首先进行了数据准备和预处理,然后实现了KNN算法,并通过评估指标对模型进行了评估。KNN算法是一种简单而有效的算法,在处理小型数据集和简单分类问题时可以发挥很好的作用。