本文介绍一些注意力机制的实现,包括MobileVITv1/MobileVITv2/DAT/CrossFormer/MOA。
【深度学习】注意力机制(一)
【深度学习】注意力机制(二)
【深度学习】注意力机制(三)
【深度学习】注意力机制(四)
【深度学习】注意力机制(五)
目录
一、MobileVITv1
二、MobileVITv2
三、DAT(Deformable Attention Transformer)
四、CrossFormer
五、MOA(multi-resolution overlapped attention)
一、MobileVITv1
论文地址:https://arxiv.org/pdf/2110.02178v2.pdf
如下图:

该代码块不能直接使用,有相关依赖,可以参考(代码来源):
import math
from typing import Dict, Optional, Sequence, Tuple, Union
import numpy as np
import torch
from torch import Tensor, nn
from torch.nn import functional as F
from cvnets.layers import ConvLayer2d, get_normalization_layer
from cvnets.modules.base_module import BaseModule
from cvnets.modules.transformer import LinearAttnFFN, TransformerEncoder
class MobileViTBlock(BaseModule):
"""
This class defines the `MobileViT block <https://arxiv.org/abs/2110.02178?context=cs.LG>`_
Args:
opts: command line arguments
in_channels (int): :math:`C_{in}` from an expected input of size :math:`(N, C_{in}, H, W)`
transformer_dim (int): Input dimension to the transformer unit
ffn_dim (int): Dimension of the FFN block
n_transformer_blocks (Optional[int]): Number of transformer blocks. Default: 2
head_dim (Optional[int]): Head dimension in the multi-head attention. Default: 32
attn_dropout (Optional[float]): Dropout in multi-head attention. Default: 0.0
dropout (Optional[float]): Dropout rate. Default: 0.0
ffn_dropout (Optional[float]): Dropout between FFN layers in transformer. Default: 0.0
patch_h (Optional[int]): Patch height for unfolding operation. Default: 8
patch_w (Optional[int]): Patch width for unfolding operation. Default: 8
transformer_norm_layer (Optional[str]): Normalization layer in the transformer block. Default: layer_norm
conv_ksize (Optional[int]): Kernel size to learn local representations in MobileViT block. Default: 3
dilation (Optional[int]): Dilation rate in convolutions. Default: 1
no_fusion (Optional[bool]): Do not combine the input and output feature maps. Default: False
"""
def __init__(
self,
opts,
in_channels: int,
transformer_dim: int,
ffn_dim: int,
n_transformer_blocks: Optional[int] = 2,
head_dim: Optional[int] = 32,
attn_dropout: Optional[float] = 0.0,
dropout: Optional[int] = 0.0,
ffn_dropout: Optional[int] = 0.0,
patch_h: Optional[int] = 8,
patch_w: Optional[int] = 8,
transformer_norm_layer: Optional[str] = "layer_norm",
conv_ksize: Optional[int] = 3,
dilation: Optional[int] = 1,
no_fusion: Optional[bool] = False,
*args,
**kwargs
) -> None:
conv_3x3_in = ConvLayer2d(
opts=opts,
in_channels=in_channels,
out_channels=in_channels,
kernel_size=conv_ksize,
stride=1,
use_norm=True,
use_act=True,
dilation=dilation,
)
conv_1x1_in = ConvLayer2d(
opts=opts,
in_channels=in_channels,
out_channels=transformer_dim,
kernel_size=1,
stride=1,
use_norm=False,
use_act=False,
)
conv_1x1_out = ConvLayer2d(
opts=opts,
in_channels=transformer_dim,
out_channels=in_channels,
kernel_size=1,
stride=1,
use_norm=True,
use_act=True,
)
conv_3x3_out = None
if not no_fusion:
conv_3x3_out = ConvLayer2d(
opts=opts,
in_channels=2 * in_channels,
out_channels=in_channels,
kernel_size=conv_ksize,
stride=1,
use_norm=True,
use_act=True,
)
super().__init__()
self.local_rep = nn.Sequential()
self.local_rep.add_module(name="conv_3x3", module=conv_3x3_in)
self.local_rep.add_module(name="conv_1x1", module=conv_1x1_in)
assert transformer_dim % head_dim == 0
num_heads = transformer_dim // head_dim
global_rep = [
TransformerEncoder(
opts=opts,
embed_dim=transformer_dim,
ffn_latent_dim=ffn_dim,
num_heads=num_heads,
attn_dropout=attn_dropout,
dropout=dropout,
ffn_dropout=ffn_dropout,
transformer_norm_layer=transformer_norm_layer,
)
for _ in range(n_transformer_blocks)
]
global_rep.append(
get_normalization_layer(
opts=opts,
norm_type=transformer_norm_layer,
num_features=transformer_dim,
)
)
self.global_rep = nn.Sequential(*global_rep)
self.conv_proj = conv_1x1_out
self.fusion = conv_3x3_out
self.patch_h = patch_h
self.patch_w = patch_w
self.patch_area = self.patch_w * self.patch_h
self.cnn_in_dim = in_channels
self.cnn_out_dim = transformer_dim
self.n_heads = num_heads
self.ffn_dim = ffn_dim
self.dropout = dropout
self.attn_dropout = attn_dropout
self.ffn_dropout = ffn_dropout
self.dilation = dilation
self.n_blocks = n_transformer_blocks
self.conv_ksize = conv_ksize
def unfolding(self, feature_map: Tensor) -> Tuple[Tensor, Dict]:
patch_w, patch_h = self.patch_w, self.patch_h
patch_area = int(patch_w * patch_h)
batch_size, in_channels, orig_h, orig_w = feature_map.shape
new_h = int(math.ceil(orig_h / self.patch_h) * self.patch_h)
new_w = int(math.ceil(orig_w / self.patch_w) * self.patch_w)
interpolate = False
if new_w != orig_w or new_h != orig_h:
# Note: Padding can be done, but then it needs to be handled in attention function.
feature_map = F.interpolate(
feature_map, size=(new_h, new_w), mode="bilinear", align_corners=False
)
interpolate = True
# number of patches along width and height
num_patch_w = new_w // patch_w # n_w
num_patch_h = new_h // patch_h # n_h
num_patches = num_patch_h * num_patch_w # N
# [B, C, H, W] --> [B * C * n_h, p_h, n_w, p_w]
reshaped_fm = feature_map.reshape(
batch_size * in_channels * num_patch_h, patch_h, num_patch_w, patch_w
)
# [B * C * n_h, p_h, n_w, p_w] --> [B * C * n_h, n_w, p_h, p_w]
transposed_fm = reshaped_fm.transpose(1, 2)
# [B * C * n_h, n_w, p_h, p_w] --> [B, C, N, P] where P = p_h * p_w and N = n_h * n_w
reshaped_fm = transposed_fm.reshape(
batch_size, in_channels, num_patches, patch_area
)
# [B, C, N, P] --> [B, P, N, C]
transposed_fm = reshaped_fm.transpose(1, 3)
# [B, P, N, C] --> [BP, N, C]
patches = transposed_fm.reshape(batch_size * patch_area, num_patches, -1)
info_dict = {
"orig_size": (orig_h, orig_w),
"batch_size": batch_size,
"interpolate": interpolate,
"total_patches": num_patches,
"num_patches_w": num_patch_w,
"num_patches_h": num_patch_h,
}
return patches, info_dict
def folding(self, patches: Tensor, info_dict: Dict) -> Tensor:
n_dim = patches.dim()
assert n_dim == 3, "Tensor should be of shape BPxNxC. Got: {}".format(
patches.shape
)
# [BP, N, C] --> [B, P, N, C]
patches = patches.contiguous().view(
info_dict["batch_size"], self.patch_area, info_dict["total_patches"], -1
)
batch_size, pixels, num_patches, channels = patches.size()
num_patch_h = info_dict["num_patches_h"]
num_patch_w = info_dict["num_patches_w"]
# [B, P, N, C] --> [B, C, N, P]
patches = patches.transpose(1, 3)
# [B, C, N, P] --> [B*C*n_h, n_w, p_h, p_w]
feature_map = patches.reshape(
batch_size * channels * num_patch_h, num_patch_w, self.patch_h, self.patch_w
)
# [B*C*n_h, n_w, p_h, p_w] --> [B*C*n_h, p_h, n_w, p_w]
feature_map = feature_map.transpose(1, 2)
# [B*C*n_h, p_h, n_w, p_w] --> [B, C, H, W]
feature_map = feature_map.reshape(
batch_size, channels, num_patch_h * self.patch_h, num_patch_w * self.patch_w
)
if info_dict["interpolate"]:
feature_map = F.interpolate(
feature_map,
size=info_dict["orig_size"],
mode="bilinear",
align_corners=False,
)
return feature_map
def forward_spatial(self, x: Tensor) -> Tensor:
res = x
fm = self.local_rep(x)
# convert feature map to patches
patches, info_dict = self.unfolding(fm)
# learn global representations
for transformer_layer in self.global_rep:
patches = transformer_layer(patches)
# [B x Patch x Patches x C] --> [B x C x Patches x Patch]
fm = self.folding(patches=patches, info_dict=info_dict)
fm = self.conv_proj(fm)
if self.fusion is not None:
fm = self.fusion(torch.cat((res, fm), dim=1))
return fm
def forward_temporal(
self, x: Tensor, x_prev: Optional[Tensor] = None
) -> Union[Tensor, Tuple[Tensor, Tensor]]:
res = x
fm = self.local_rep(x)
# convert feature map to patches
patches, info_dict = self.unfolding(fm)
# learn global representations
for global_layer in self.global_rep:
if isinstance(global_layer, TransformerEncoder):
patches = global_layer(x=patches, x_prev=x_prev)
else:
patches = global_layer(patches)
# [B x Patch x Patches x C] --> [B x C x Patches x Patch]
fm = self.folding(patches=patches, info_dict=info_dict)
fm = self.conv_proj(fm)
if self.fusion is not None:
fm = self.fusion(torch.cat((res, fm), dim=1))
return fm, patches
def forward(
self, x: Union[Tensor, Tuple[Tensor]], *args, **kwargs
) -> Union[Tensor, Tuple[Tensor, Tensor]]:
if isinstance(x, Tuple) and len(x) == 2:
# for spatio-temporal MobileViT
return self.forward_temporal(x=x[0], x_prev=x[1])
elif isinstance(x, Tensor):
# For image data
return self.forward_spatial(x)
else:
raise NotImplementedError
二、MobileVITv2
论文地址:Separable Self-attention for Mobile Vision Transformers
如下图:
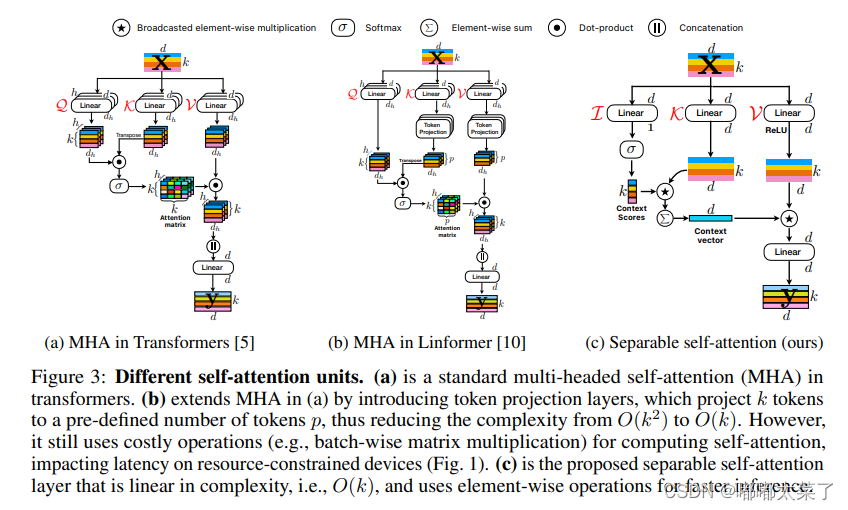
代码不可直接使用,可参考代码来源:
class MobileViTBlockv2(BaseModule):
"""
This class defines the `MobileViTv2 <https://arxiv.org/abs/2206.02680>`_ block
Args:
opts: command line arguments
in_channels (int): :math:`C_{in}` from an expected input of size :math:`(N, C_{in}, H, W)`
attn_unit_dim (int): Input dimension to the attention unit
ffn_multiplier (int): Expand the input dimensions by this factor in FFN. Default is 2.
n_attn_blocks (Optional[int]): Number of attention units. Default: 2
attn_dropout (Optional[float]): Dropout in multi-head attention. Default: 0.0
dropout (Optional[float]): Dropout rate. Default: 0.0
ffn_dropout (Optional[float]): Dropout between FFN layers in transformer. Default: 0.0
patch_h (Optional[int]): Patch height for unfolding operation. Default: 8
patch_w (Optional[int]): Patch width for unfolding operation. Default: 8
conv_ksize (Optional[int]): Kernel size to learn local representations in MobileViT block. Default: 3
dilation (Optional[int]): Dilation rate in convolutions. Default: 1
attn_norm_layer (Optional[str]): Normalization layer in the attention block. Default: layer_norm_2d
"""
def __init__(
self,
opts,
in_channels: int,
attn_unit_dim: int,
ffn_multiplier: Optional[Union[Sequence[Union[int, float]], int, float]] = 2.0,
n_attn_blocks: Optional[int] = 2,
attn_dropout: Optional[float] = 0.0,
dropout: Optional[float] = 0.0,
ffn_dropout: Optional[float] = 0.0,
patch_h: Optional[int] = 8,
patch_w: Optional[int] = 8,
conv_ksize: Optional[int] = 3,
dilation: Optional[int] = 1,
attn_norm_layer: Optional[str] = "layer_norm_2d",
*args,
**kwargs
) -> None:
cnn_out_dim = attn_unit_dim
conv_3x3_in = ConvLayer2d(
opts=opts,
in_channels=in_channels,
out_channels=in_channels,
kernel_size=conv_ksize,
stride=1,
use_norm=True,
use_act=True,
dilation=dilation,
groups=in_channels,
)
conv_1x1_in = ConvLayer2d(
opts=opts,
in_channels=in_channels,
out_channels=cnn_out_dim,
kernel_size=1,
stride=1,
use_norm=False,
use_act=False,
)
super(MobileViTBlockv2, self).__init__()
self.local_rep = nn.Sequential(conv_3x3_in, conv_1x1_in)
self.global_rep, attn_unit_dim = self._build_attn_layer(
opts=opts,
d_model=attn_unit_dim,
ffn_mult=ffn_multiplier,
n_layers=n_attn_blocks,
attn_dropout=attn_dropout,
dropout=dropout,
ffn_dropout=ffn_dropout,
attn_norm_layer=attn_norm_layer,
)
self.conv_proj = ConvLayer2d(
opts=opts,
in_channels=cnn_out_dim,
out_channels=in_channels,
kernel_size=1,
stride=1,
use_norm=True,
use_act=False,
)
self.patch_h = patch_h
self.patch_w = patch_w
self.patch_area = self.patch_w * self.patch_h
self.cnn_in_dim = in_channels
self.cnn_out_dim = cnn_out_dim
self.transformer_in_dim = attn_unit_dim
self.dropout = dropout
self.attn_dropout = attn_dropout
self.ffn_dropout = ffn_dropout
self.n_blocks = n_attn_blocks
self.conv_ksize = conv_ksize
self.enable_coreml_compatible_fn = getattr(
opts, "common.enable_coreml_compatible_module", False
)
if self.enable_coreml_compatible_fn:
# we set persistent to false so that these weights are not part of model's state_dict
self.register_buffer(
name="unfolding_weights",
tensor=self._compute_unfolding_weights(),
persistent=False,
)
def _compute_unfolding_weights(self) -> Tensor:
# [P_h * P_w, P_h * P_w]
weights = torch.eye(self.patch_h * self.patch_w, dtype=torch.float)
# [P_h * P_w, P_h * P_w] --> [P_h * P_w, 1, P_h, P_w]
weights = weights.reshape(
(self.patch_h * self.patch_w, 1, self.patch_h, self.patch_w)
)
# [P_h * P_w, 1, P_h, P_w] --> [P_h * P_w * C, 1, P_h, P_w]
weights = weights.repeat(self.cnn_out_dim, 1, 1, 1)
return weights
def _build_attn_layer(
self,
opts,
d_model: int,
ffn_mult: Union[Sequence, int, float],
n_layers: int,
attn_dropout: float,
dropout: float,
ffn_dropout: float,
attn_norm_layer: str,
*args,
**kwargs
) -> Tuple[nn.Module, int]:
if isinstance(ffn_mult, Sequence) and len(ffn_mult) == 2:
ffn_dims = (
np.linspace(ffn_mult[0], ffn_mult[1], n_layers, dtype=float) * d_model
)
elif isinstance(ffn_mult, Sequence) and len(ffn_mult) == 1:
ffn_dims = [ffn_mult[0] * d_model] * n_layers
elif isinstance(ffn_mult, (int, float)):
ffn_dims = [ffn_mult * d_model] * n_layers
else:
raise NotImplementedError
# ensure that dims are multiple of 16
ffn_dims = [int((d // 16) * 16) for d in ffn_dims]
global_rep = [
LinearAttnFFN(
opts=opts,
embed_dim=d_model,
ffn_latent_dim=ffn_dims[block_idx],
attn_dropout=attn_dropout,
dropout=dropout,
ffn_dropout=ffn_dropout,
norm_layer=attn_norm_layer,
)
for block_idx in range(n_layers)
]
global_rep.append(
get_normalization_layer(
opts=opts, norm_type=attn_norm_layer, num_features=d_model
)
)
return nn.Sequential(*global_rep), d_model
def __repr__(self) -> str:
repr_str = "{}(".format(self.__class__.__name__)
repr_str += "\n\t Local representations"
if isinstance(self.local_rep, nn.Sequential):
for m in self.local_rep:
repr_str += "\n\t\t {}".format(m)
else:
repr_str += "\n\t\t {}".format(self.local_rep)
repr_str += "\n\t Global representations with patch size of {}x{}".format(
self.patch_h,
self.patch_w,
)
if isinstance(self.global_rep, nn.Sequential):
for m in self.global_rep:
repr_str += "\n\t\t {}".format(m)
else:
repr_str += "\n\t\t {}".format(self.global_rep)
if isinstance(self.conv_proj, nn.Sequential):
for m in self.conv_proj:
repr_str += "\n\t\t {}".format(m)
else:
repr_str += "\n\t\t {}".format(self.conv_proj)
repr_str += "\n)"
return repr_str
def unfolding_pytorch(self, feature_map: Tensor) -> Tuple[Tensor, Tuple[int, int]]:
batch_size, in_channels, img_h, img_w = feature_map.shape
# [B, C, H, W] --> [B, C, P, N]
patches = F.unfold(
feature_map,
kernel_size=(self.patch_h, self.patch_w),
stride=(self.patch_h, self.patch_w),
)
patches = patches.reshape(
batch_size, in_channels, self.patch_h * self.patch_w, -1
)
return patches, (img_h, img_w)
def folding_pytorch(self, patches: Tensor, output_size: Tuple[int, int]) -> Tensor:
batch_size, in_dim, patch_size, n_patches = patches.shape
# [B, C, P, N]
patches = patches.reshape(batch_size, in_dim * patch_size, n_patches)
feature_map = F.fold(
patches,
output_size=output_size,
kernel_size=(self.patch_h, self.patch_w),
stride=(self.patch_h, self.patch_w),
)
return feature_map
def unfolding_coreml(self, feature_map: Tensor) -> Tuple[Tensor, Tuple[int, int]]:
# im2col is not implemented in Coreml, so here we hack its implementation using conv2d
# we compute the weights
# [B, C, H, W] --> [B, C, P, N]
batch_size, in_channels, img_h, img_w = feature_map.shape
#
patches = F.conv2d(
feature_map,
self.unfolding_weights,
bias=None,
stride=(self.patch_h, self.patch_w),
padding=0,
dilation=1,
groups=in_channels,
)
patches = patches.reshape(
batch_size, in_channels, self.patch_h * self.patch_w, -1
)
return patches, (img_h, img_w)
def folding_coreml(self, patches: Tensor, output_size: Tuple[int, int]) -> Tensor:
# col2im is not supported on coreml, so tracing fails
# We hack folding function via pixel_shuffle to enable coreml tracing
batch_size, in_dim, patch_size, n_patches = patches.shape
n_patches_h = output_size[0] // self.patch_h
n_patches_w = output_size[1] // self.patch_w
feature_map = patches.reshape(
batch_size, in_dim * self.patch_h * self.patch_w, n_patches_h, n_patches_w
)
assert (
self.patch_h == self.patch_w
), "For Coreml, we need patch_h and patch_w are the same"
feature_map = F.pixel_shuffle(feature_map, upscale_factor=self.patch_h)
return feature_map
def resize_input_if_needed(self, x):
batch_size, in_channels, orig_h, orig_w = x.shape
if orig_h % self.patch_h != 0 or orig_w % self.patch_w != 0:
new_h = int(math.ceil(orig_h / self.patch_h) * self.patch_h)
new_w = int(math.ceil(orig_w / self.patch_w) * self.patch_w)
x = F.interpolate(
x, size=(new_h, new_w), mode="bilinear", align_corners=True
)
return x
def forward_spatial(self, x: Tensor, *args, **kwargs) -> Tensor:
x = self.resize_input_if_needed(x)
fm = self.local_rep(x)
# convert feature map to patches
if self.enable_coreml_compatible_fn:
patches, output_size = self.unfolding_coreml(fm)
else:
patches, output_size = self.unfolding_pytorch(fm)
# learn global representations on all patches
patches = self.global_rep(patches)
# [B x Patch x Patches x C] --> [B x C x Patches x Patch]
if self.enable_coreml_compatible_fn:
fm = self.folding_coreml(patches=patches, output_size=output_size)
else:
fm = self.folding_pytorch(patches=patches, output_size=output_size)
fm = self.conv_proj(fm)
return fm
def forward_temporal(
self, x: Tensor, x_prev: Tensor, *args, **kwargs
) -> Union[Tensor, Tuple[Tensor, Tensor]]:
x = self.resize_input_if_needed(x)
fm = self.local_rep(x)
# convert feature map to patches
if self.enable_coreml_compatible_fn:
patches, output_size = self.unfolding_coreml(fm)
else:
patches, output_size = self.unfolding_pytorch(fm)
# learn global representations
for global_layer in self.global_rep:
if isinstance(global_layer, LinearAttnFFN):
patches = global_layer(x=patches, x_prev=x_prev)
else:
patches = global_layer(patches)
# [B x Patch x Patches x C] --> [B x C x Patches x Patch]
if self.enable_coreml_compatible_fn:
fm = self.folding_coreml(patches=patches, output_size=output_size)
else:
fm = self.folding_pytorch(patches=patches, output_size=output_size)
fm = self.conv_proj(fm)
return fm, patches
def forward(
self, x: Union[Tensor, Tuple[Tensor]], *args, **kwargs
) -> Union[Tensor, Tuple[Tensor, Tensor]]:
if isinstance(x, Tuple) and len(x) == 2:
# for spatio-temporal data (e.g., videos)
return self.forward_temporal(x=x[0], x_prev=x[1])
elif isinstance(x, Tensor):
# for image data
return self.forward_spatial(x)
else:
raise NotImplementedError三、DAT(Deformable Attention Transformer)
论文地址:Vision Transformer with Deformable Attention
如下图:
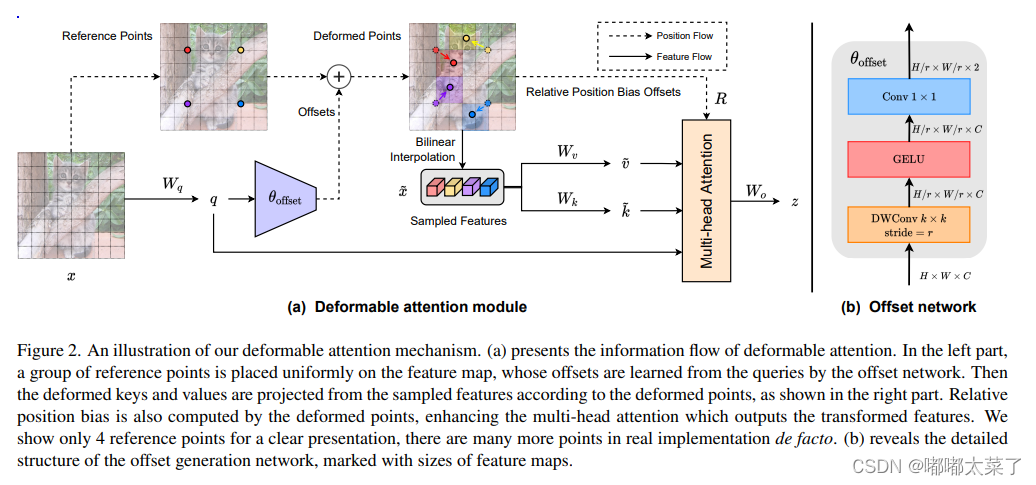
代码如下(代码来源):
class DAttentionBaseline(nn.Module):
def __init__(
self, q_size, kv_size, n_heads, n_head_channels, n_groups,
attn_drop, proj_drop, stride,
offset_range_factor, use_pe, dwc_pe,
no_off, fixed_pe, ksize, log_cpb
):
super().__init__()
self.dwc_pe = dwc_pe
self.n_head_channels = n_head_channels
self.scale = self.n_head_channels ** -0.5
self.n_heads = n_heads
self.q_h, self.q_w = q_size
# self.kv_h, self.kv_w = kv_size
self.kv_h, self.kv_w = self.q_h // stride, self.q_w // stride
self.nc = n_head_channels * n_heads
self.n_groups = n_groups
self.n_group_channels = self.nc // self.n_groups
self.n_group_heads = self.n_heads // self.n_groups
self.use_pe = use_pe
self.fixed_pe = fixed_pe
self.no_off = no_off
self.offset_range_factor = offset_range_factor
self.ksize = ksize
self.log_cpb = log_cpb
self.stride = stride
kk = self.ksize
pad_size = kk // 2 if kk != stride else 0
self.conv_offset = nn.Sequential(
nn.Conv2d(self.n_group_channels, self.n_group_channels, kk, stride, pad_size, groups=self.n_group_channels),
LayerNormProxy(self.n_group_channels),
nn.GELU(),
nn.Conv2d(self.n_group_channels, 2, 1, 1, 0, bias=False)
)
if self.no_off:
for m in self.conv_offset.parameters():
m.requires_grad_(False)
self.proj_q = nn.Conv2d(
self.nc, self.nc,
kernel_size=1, stride=1, padding=0
)
self.proj_k = nn.Conv2d(
self.nc, self.nc,
kernel_size=1, stride=1, padding=0
)
self.proj_v = nn.Conv2d(
self.nc, self.nc,
kernel_size=1, stride=1, padding=0
)
self.proj_out = nn.Conv2d(
self.nc, self.nc,
kernel_size=1, stride=1, padding=0
)
self.proj_drop = nn.Dropout(proj_drop, inplace=True)
self.attn_drop = nn.Dropout(attn_drop, inplace=True)
if self.use_pe and not self.no_off:
if self.dwc_pe:
self.rpe_table = nn.Conv2d(
self.nc, self.nc, kernel_size=3, stride=1, padding=1, groups=self.nc)
elif self.fixed_pe:
self.rpe_table = nn.Parameter(
torch.zeros(self.n_heads, self.q_h * self.q_w, self.kv_h * self.kv_w)
)
trunc_normal_(self.rpe_table, std=0.01)
elif self.log_cpb:
# Borrowed from Swin-V2
self.rpe_table = nn.Sequential(
nn.Linear(2, 32, bias=True),
nn.ReLU(inplace=True),
nn.Linear(32, self.n_group_heads, bias=False)
)
else:
self.rpe_table = nn.Parameter(
torch.zeros(self.n_heads, self.q_h * 2 - 1, self.q_w * 2 - 1)
)
trunc_normal_(self.rpe_table, std=0.01)
else:
self.rpe_table = None
@torch.no_grad()
def _get_ref_points(self, H_key, W_key, B, dtype, device):
ref_y, ref_x = torch.meshgrid(
torch.linspace(0.5, H_key - 0.5, H_key, dtype=dtype, device=device),
torch.linspace(0.5, W_key - 0.5, W_key, dtype=dtype, device=device),
indexing='ij'
)
ref = torch.stack((ref_y, ref_x), -1)
ref[..., 1].div_(W_key - 1.0).mul_(2.0).sub_(1.0)
ref[..., 0].div_(H_key - 1.0).mul_(2.0).sub_(1.0)
ref = ref[None, ...].expand(B * self.n_groups, -1, -1, -1) # B * g H W 2
return ref
@torch.no_grad()
def _get_q_grid(self, H, W, B, dtype, device):
ref_y, ref_x = torch.meshgrid(
torch.arange(0, H, dtype=dtype, device=device),
torch.arange(0, W, dtype=dtype, device=device),
indexing='ij'
)
ref = torch.stack((ref_y, ref_x), -1)
ref[..., 1].div_(W - 1.0).mul_(2.0).sub_(1.0)
ref[..., 0].div_(H - 1.0).mul_(2.0).sub_(1.0)
ref = ref[None, ...].expand(B * self.n_groups, -1, -1, -1) # B * g H W 2
return ref
def forward(self, x):
B, C, H, W = x.size()
dtype, device = x.dtype, x.device
q = self.proj_q(x)
q_off = einops.rearrange(q, 'b (g c) h w -> (b g) c h w', g=self.n_groups, c=self.n_group_channels)
offset = self.conv_offset(q_off).contiguous() # B * g 2 Hg Wg
Hk, Wk = offset.size(2), offset.size(3)
n_sample = Hk * Wk
if self.offset_range_factor >= 0 and not self.no_off:
offset_range = torch.tensor([1.0 / (Hk - 1.0), 1.0 / (Wk - 1.0)], device=device).reshape(1, 2, 1, 1)
offset = offset.tanh().mul(offset_range).mul(self.offset_range_factor)
offset = einops.rearrange(offset, 'b p h w -> b h w p')
reference = self._get_ref_points(Hk, Wk, B, dtype, device)
if self.no_off:
offset = offset.fill_(0.0)
if self.offset_range_factor >= 0:
pos = offset + reference
else:
pos = (offset + reference).clamp(-1., +1.)
if self.no_off:
x_sampled = F.avg_pool2d(x, kernel_size=self.stride, stride=self.stride)
assert x_sampled.size(2) == Hk and x_sampled.size(3) == Wk, f"Size is {x_sampled.size()}"
else:
x_sampled = F.grid_sample(
input=x.reshape(B * self.n_groups, self.n_group_channels, H, W),
grid=pos[..., (1, 0)], # y, x -> x, y
mode='bilinear', align_corners=True) # B * g, Cg, Hg, Wg
x_sampled = x_sampled.reshape(B, C, 1, n_sample)
q = q.reshape(B * self.n_heads, self.n_head_channels, H * W)
k = self.proj_k(x_sampled).reshape(B * self.n_heads, self.n_head_channels, n_sample)
v = self.proj_v(x_sampled).reshape(B * self.n_heads, self.n_head_channels, n_sample)
attn = torch.einsum('b c m, b c n -> b m n', q, k) # B * h, HW, Ns
attn = attn.mul(self.scale)
if self.use_pe and (not self.no_off):
if self.dwc_pe:
residual_lepe = self.rpe_table(q.reshape(B, C, H, W)).reshape(B * self.n_heads, self.n_head_channels, H * W)
elif self.fixed_pe:
rpe_table = self.rpe_table
attn_bias = rpe_table[None, ...].expand(B, -1, -1, -1)
attn = attn + attn_bias.reshape(B * self.n_heads, H * W, n_sample)
elif self.log_cpb:
q_grid = self._get_q_grid(H, W, B, dtype, device)
displacement = (q_grid.reshape(B * self.n_groups, H * W, 2).unsqueeze(2) - pos.reshape(B * self.n_groups, n_sample, 2).unsqueeze(1)).mul(4.0) # d_y, d_x [-8, +8]
displacement = torch.sign(displacement) * torch.log2(torch.abs(displacement) + 1.0) / np.log2(8.0)
attn_bias = self.rpe_table(displacement) # B * g, H * W, n_sample, h_g
attn = attn + einops.rearrange(attn_bias, 'b m n h -> (b h) m n', h=self.n_group_heads)
else:
rpe_table = self.rpe_table
rpe_bias = rpe_table[None, ...].expand(B, -1, -1, -1)
q_grid = self._get_q_grid(H, W, B, dtype, device)
displacement = (q_grid.reshape(B * self.n_groups, H * W, 2).unsqueeze(2) - pos.reshape(B * self.n_groups, n_sample, 2).unsqueeze(1)).mul(0.5)
attn_bias = F.grid_sample(
input=einops.rearrange(rpe_bias, 'b (g c) h w -> (b g) c h w', c=self.n_group_heads, g=self.n_groups),
grid=displacement[..., (1, 0)],
mode='bilinear', align_corners=True) # B * g, h_g, HW, Ns
attn_bias = attn_bias.reshape(B * self.n_heads, H * W, n_sample)
attn = attn + attn_bias
attn = F.softmax(attn, dim=2)
attn = self.attn_drop(attn)
out = torch.einsum('b m n, b c n -> b c m', attn, v)
if self.use_pe and self.dwc_pe:
out = out + residual_lepe
out = out.reshape(B, C, H, W)
y = self.proj_drop(self.proj_out(out))
return y, pos.reshape(B, self.n_groups, Hk, Wk, 2), reference.reshape(B, self.n_groups, Hk, Wk, 2)四、CrossFormer
该论文有好几个模块论文地址:CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION
SDA、LDA、DPB如下图:
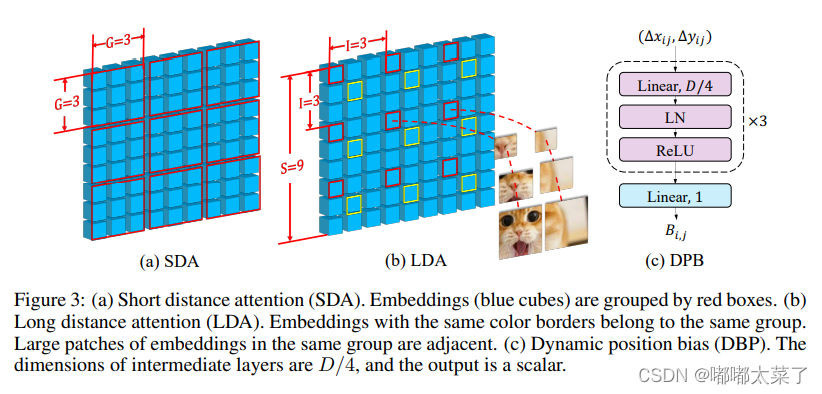
网络结构如下图:
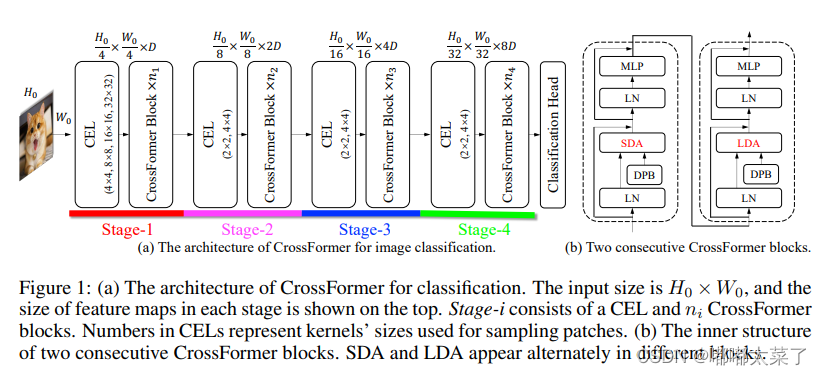
代码如下(代码来源):
import torch
import torch.nn as nn
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class DynamicPosBias(nn.Module):
def __init__(self, dim, num_heads, residual):
super().__init__()
self.residual = residual
self.num_heads = num_heads
self.pos_dim = dim // 4
self.pos_proj = nn.Linear(2, self.pos_dim)
self.pos1 = nn.Sequential(
nn.LayerNorm(self.pos_dim),
nn.ReLU(inplace=True),
nn.Linear(self.pos_dim, self.pos_dim),
)
self.pos2 = nn.Sequential(
nn.LayerNorm(self.pos_dim),
nn.ReLU(inplace=True),
nn.Linear(self.pos_dim, self.pos_dim)
)
self.pos3 = nn.Sequential(
nn.LayerNorm(self.pos_dim),
nn.ReLU(inplace=True),
nn.Linear(self.pos_dim, self.num_heads)
)
def forward(self, biases):
if self.residual:
pos = self.pos_proj(biases) # 2Wh-1 * 2Ww-1, heads
pos = pos + self.pos1(pos)
pos = pos + self.pos2(pos)
pos = self.pos3(pos)
else:
pos = self.pos3(self.pos2(self.pos1(self.pos_proj(biases))))
return pos
def flops(self, N):
flops = N * 2 * self.pos_dim
flops += N * self.pos_dim * self.pos_dim
flops += N * self.pos_dim * self.pos_dim
flops += N * self.pos_dim * self.num_heads
return flops
class Attention(nn.Module):
r""" Multi-head self attention module with dynamic position bias.
Args:
dim (int): Number of input channels.
group_size (tuple[int]): The height and width of the group.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, group_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.,
position_bias=True):
super().__init__()
self.dim = dim
self.group_size = group_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.position_bias = position_bias
if position_bias:
self.pos = DynamicPosBias(self.dim // 4, self.num_heads, residual=False)
# generate mother-set
position_bias_h = torch.arange(1 - self.group_size[0], self.group_size[0])
position_bias_w = torch.arange(1 - self.group_size[1], self.group_size[1])
biases = torch.stack(torch.meshgrid([position_bias_h, position_bias_w])) # 2, 2Wh-1, 2W2-1
biases = biases.flatten(1).transpose(0, 1).float()
self.register_buffer("biases", biases)
# get pair-wise relative position index for each token inside the group
coords_h = torch.arange(self.group_size[0])
coords_w = torch.arange(self.group_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.group_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.group_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.group_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
"""
Args:
x: input features with shape of (num_groups*B, N, C)
mask: (0/-inf) mask with shape of (num_groups, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
if self.position_bias:
pos = self.pos(self.biases) # 2Wh-1 * 2Ww-1, heads
# select position bias
relative_position_bias = pos[self.relative_position_index.view(-1)].view(
self.group_size[0] * self.group_size[1], self.group_size[0] * self.group_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def extra_repr(self) -> str:
return f'dim={self.dim}, group_size={self.group_size}, num_heads={self.num_heads}'
def flops(self, N):
# calculate flops for 1 group with token length of N
flops = 0
# qkv = self.qkv(x)
flops += N * self.dim * 3 * self.dim
# attn = (q @ k.transpose(-2, -1))
flops += self.num_heads * N * (self.dim // self.num_heads) * N
# x = (attn @ v)
flops += self.num_heads * N * N * (self.dim // self.num_heads)
# x = self.proj(x)
flops += N * self.dim * self.dim
if self.position_bias:
flops += self.pos.flops(N)
return flops
class CrossFormerBlock(nn.Module):
r""" CrossFormer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
num_heads (int): Number of attention heads.
group_size (int): Group size.
lsda_flag (int): use SDA or LDA, 0 for SDA and 1 for LDA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, group_size=7, lsda_flag=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm, num_patch_size=1):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.group_size = group_size
self.lsda_flag = lsda_flag
self.mlp_ratio = mlp_ratio
self.num_patch_size = num_patch_size
if min(self.input_resolution) <= self.group_size:
# if group size is larger than input resolution, we don't partition groups
self.lsda_flag = 0
self.group_size = min(self.input_resolution)
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, group_size=to_2tuple(self.group_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
position_bias=True)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size %d, %d, %d" % (L, H, W)
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# group embeddings
G = self.group_size
if self.lsda_flag == 0: # 0 for SDA
x = x.reshape(B, H // G, G, W // G, G, C).permute(0, 1, 3, 2, 4, 5)
else: # 1 for LDA
x = x.reshape(B, G, H // G, G, W // G, C).permute(0, 2, 4, 1, 3, 5)
x = x.reshape(B * H * W // G**2, G**2, C)
# multi-head self-attention
x = self.attn(x, mask=self.attn_mask) # nW*B, G*G, C
# ungroup embeddings
x = x.reshape(B, H // G, W // G, G, G, C)
if self.lsda_flag == 0:
x = x.permute(0, 1, 3, 2, 4, 5).reshape(B, H, W, C)
else:
x = x.permute(0, 3, 1, 4, 2, 5).reshape(B, H, W, C)
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"group_size={self.group_size}, lsda_flag={self.lsda_flag}, mlp_ratio={self.mlp_ratio}"
def flops(self):
flops = 0
H, W = self.input_resolution
# norm1
flops += self.dim * H * W
# LSDA
nW = H * W / self.group_size / self.group_size
flops += nW * self.attn.flops(self.group_size * self.group_size)
# mlp
flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
# norm2
flops += self.dim * H * W
return flops
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm, patch_size=[2], num_input_patch_size=1):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reductions = nn.ModuleList()
self.patch_size = patch_size
self.norm = norm_layer(dim)
for i, ps in enumerate(patch_size):
if i == len(patch_size) - 1:
out_dim = 2 * dim // 2 ** i
else:
out_dim = 2 * dim // 2 ** (i + 1)
stride = 2
padding = (ps - stride) // 2
self.reductions.append(nn.Conv2d(dim, out_dim, kernel_size=ps,
stride=stride, padding=padding))
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = self.norm(x)
x = x.view(B, H, W, C).permute(0, 3, 1, 2)
xs = []
for i in range(len(self.reductions)):
tmp_x = self.reductions[i](x).flatten(2).transpose(1, 2)
xs.append(tmp_x)
x = torch.cat(xs, dim=2)
return x
def extra_repr(self) -> str:
return f"input_resolution={self.input_resolution}, dim={self.dim}"
def flops(self):
H, W = self.input_resolution
flops = H * W * self.dim
for i, ps in enumerate(self.patch_size):
if i == len(self.patch_size) - 1:
out_dim = 2 * self.dim // 2 ** i
else:
out_dim = 2 * self.dim // 2 ** (i + 1)
flops += (H // 2) * (W // 2) * ps * ps * out_dim * self.dim
return flops
class Stage(nn.Module):
""" CrossFormer blocks for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
group_size (int): variable G in the paper, one group has GxG embeddings
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self, dim, input_resolution, depth, num_heads, group_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False,
patch_size_end=[4], num_patch_size=None):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
# build blocks
self.blocks = nn.ModuleList()
for i in range(depth):
lsda_flag = 0 if (i % 2 == 0) else 1
self.blocks.append(CrossFormerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, group_size=group_size,
lsda_flag=lsda_flag,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer,
num_patch_size=num_patch_size))
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer,
patch_size=patch_size_end, num_input_patch_size=num_patch_size)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
def flops(self):
flops = 0
for blk in self.blocks:
flops += blk.flops()
if self.downsample is not None:
flops += self.downsample.flops()
return flops
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: [4].
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=[4], in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
# patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[0] // patch_size[0]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.projs = nn.ModuleList()
for i, ps in enumerate(patch_size):
if i == len(patch_size) - 1:
dim = embed_dim // 2 ** i
else:
dim = embed_dim // 2 ** (i + 1)
stride = patch_size[0]
padding = (ps - patch_size[0]) // 2
self.projs.append(nn.Conv2d(in_chans, dim, kernel_size=ps, stride=stride, padding=padding))
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
xs = []
for i in range(len(self.projs)):
tx = self.projs[i](x).flatten(2).transpose(1, 2)
xs.append(tx) # B Ph*Pw C
x = torch.cat(xs, dim=2)
if self.norm is not None:
x = self.norm(x)
return x
def flops(self):
Ho, Wo = self.patches_resolution
flops = 0
for i, ps in enumerate(self.patch_size):
if i == len(self.patch_size) - 1:
dim = self.embed_dim // 2 ** i
else:
dim = self.embed_dim // 2 ** (i + 1)
flops += Ho * Wo * dim * self.in_chans * (self.patch_size[i] * self.patch_size[i])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops
class CrossFormer(nn.Module):
r""" CrossFormer
A PyTorch impl of : `CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention` -
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each stage.
num_heads (tuple(int)): Number of attention heads in different layers.
group_size (int): Group size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
"""
def __init__(self, img_size=224, patch_size=[4], in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
group_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
use_checkpoint=False, merge_size=[[2], [2], [2]], **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# absolute position embedding
if self.ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
num_patch_sizes = [len(patch_size)] + [len(m) for m in merge_size]
for i_layer in range(self.num_layers):
patch_size_end = merge_size[i_layer] if i_layer < self.num_layers - 1 else None
num_patch_size = num_patch_sizes[i_layer]
layer = Stage(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
group_size=group_size[i_layer],
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint,
patch_size_end=patch_size_end,
num_patch_size=num_patch_size)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def forward_features(self, x):
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def flops(self):
flops = 0
flops += self.patch_embed.flops()
for i, layer in enumerate(self.layers):
flops += layer.flops()
flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers)
flops += self.num_features * self.num_classes
return flops五、MOA(multi-resolution overlapped attention)
论文地址:Aggregating Global Features into Local Vision Transformer
如下图:
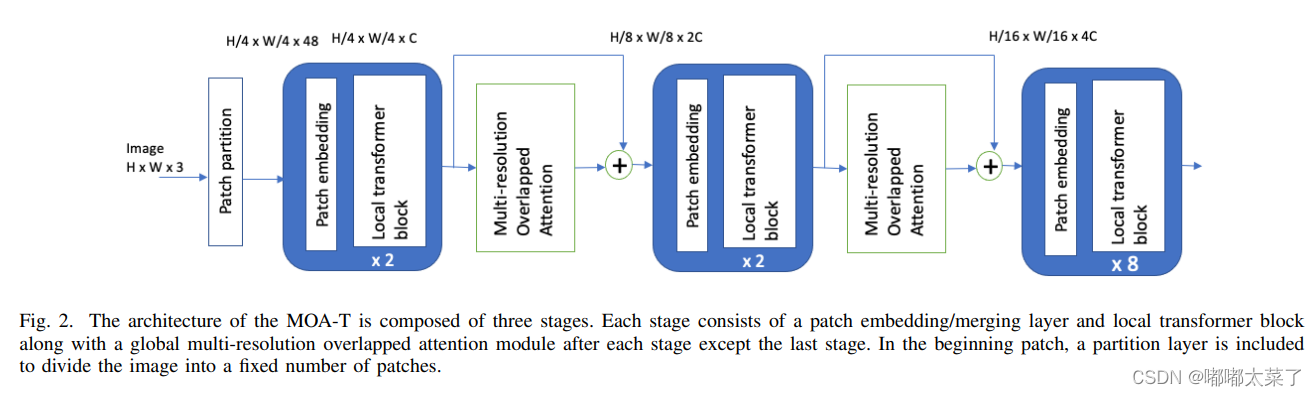
代码如下(代码来源):
# --------------------------------------------------------
# Adopted from Swin Transformer
# Modified by Krushi Patel
# --------------------------------------------------------
import torch
import torch.nn as nn
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from einops.layers.torch import Rearrange, Reduce
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.query_size = self.window_size
self.key_size = self.window_size[0] * 2
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def extra_repr(self) -> str:
#return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
return f'dim={self.dim}, num_heads={self.num_heads}'
def flops(self, N):
# calculate flops for 1 window with token length of N
flops = 0
# qkv = self.qkv(x)
flops += N * self.dim * 3 * self.dim
# attn = (q @ k.transpose(-2, -1))
flops += self.num_heads * N * (self.dim // self.num_heads) * N
# x = (attn @ v)
flops += self.num_heads * N * N * (self.dim // self.num_heads)
# x = self.proj(x)
flops += N * self.dim * self.dim
return flops
class GlobalAttention(nn.Module):
r""" MOA - multi-head self attention (W-MSA) module with relative position bias.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, input_resolution,num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.query_size = self.window_size[0]
self.key_size = self.window_size[0] + 2
h,w = input_resolution
self.seq_len = h//self.query_size
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.reduction = 32
self.pre_conv = nn.Conv2d(dim, int(dim//self.reduction), 1)
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * self.seq_len - 1) * (2 * self.seq_len - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
#print(self.relative_position_bias_table.shape)
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.seq_len)
coords_w = torch.arange(self.seq_len)
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.seq_len - 1 # shift to start from 0
relative_coords[:, :, 1] += self.seq_len - 1
relative_coords[:, :, 0] *= 2 * self.seq_len - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.queryembedding = Rearrange('b c (h p1) (w p2) -> b (p1 p2 c) h w', p1 = self.query_size, p2 = self. query_size)
self.keyembedding = nn.Unfold(kernel_size=(self.key_size, self.key_size), stride = 14, padding=1)
self.query_dim = int(dim//self.reduction) * self.query_size * self.query_size
self.key_dim = int(dim//self.reduction) * self.key_size * self.key_size
self.q = nn.Linear(self.query_dim, self.dim,bias=qkv_bias)
self.kv = nn.Linear(self.key_dim, 2*self.dim,bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim,dim)
self.proj_drop = nn.Dropout(proj_drop)
#trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, H, W):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
#B, H, W, C = x.shape
B,_, C = x.shape
x = x.reshape(-1, C, H, W)
x = self.pre_conv(x)
query = self.queryembedding(x).view(B,-1,self.query_dim)
query = self.q(query)
B,N,C = query.size()
q = query.reshape(B,N,self.num_heads, C//self.num_heads).permute(0,2,1,3)
key = self.keyembedding(x).view(B,-1,self.key_dim)
kv = self.kv(key).reshape(B,N,2,self.num_heads,C//self.num_heads).permute(2,0,3,1,4)
k = kv[0]
v = kv[1]
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.seq_len * self.seq_len, self.seq_len * self.seq_len, -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def extra_repr(self) -> str:
return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
def flops(self, N):
# calculate flops for 1 window with token length of N
flops = 0
# qkv = self.qkv(x)
flops += N * self.dim * 3 * self.dim
# attn = (q @ k.transpose(-2, -1))
flops += self.num_heads * N * (self.dim // self.num_heads) * N
# x = (attn @ v)
flops += self.num_heads * N * N * (self.dim // self.num_heads)
# x = self.proj(x)
flops += N * self.dim * self.dim
return flops
class LocalTransformerBlock(nn.Module):
r""" Local Transformer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.window_size = min(self.input_resolution)
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
x_windows = window_partition(x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
attn_windows = self.attn(x_windows) # nW*B, window_size*window_size, C
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
x = x.view(B, H * W, C)
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"window_size={self.window_size}, mlp_ratio={self.mlp_ratio}"
def flops(self):
flops = 0
H, W = self.input_resolution
# norm1
flops += self.dim * H * W
# W-MSA/SW-MSA
nW = H * W / self.window_size / self.window_size
flops += nW * self.attn.flops(self.window_size * self.window_size)
# mlp
flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
# norm2
flops += self.dim * H * W
return flops
class PatchMerging(nn.Module):
""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
def extra_repr(self) -> str:
return f"input_resolution={self.input_resolution}, dim={self.dim}"
def flops(self):
H, W = self.input_resolution
flops = H * W * self.dim
flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
return flops
class BasicLayer(nn.Module):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, drop_path_global=0., use_checkpoint=False):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
self.window_size = window_size
self.drop_path_gl = DropPath(drop_path_global) if drop_path_global > 0. else nn.Identity()
# build blocks
self.blocks = nn.ModuleList([
LocalTransformerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
# patch merging layer
if downsample is not None:
if min(self.input_resolution) >= self.window_size:
self.glb_attn = GlobalAttention(dim, to_2tuple(window_size), self.input_resolution, num_heads = num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.post_conv = nn.Conv2d(dim, dim, 3, padding=1)
self.norm1 = norm_layer(dim)
self.norm2 = norm_layer(dim)
else:
self.post_conv = None
self.glb_attn = None
self.norm1 = None
self.norm2 = None
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
if min(self.input_resolution) >= self.window_size:
shortcut = x
x = self.norm1(x)
H, W = self.input_resolution
B,_,C = x.size()
no_window = int(H*W/self.window_size**2)
local_attn = x.view(B,no_window,self.window_size, self.window_size,C)
glb_attn = self.glb_attn(x, H, W)
glb_attn = glb_attn.view(B,no_window,1,1,C)
x = torch.add(local_attn, glb_attn).view(B,C,H,W)
x = shortcut.view(B,C,H,W) + self.drop_path_gl(x)
x = self.norm2(x.view(B,H*W,C))
post_conv = self.drop_path_gl(self.post_conv(x.view(B,C,H,W))).view(B, H*W, C)
x = x + post_conv
x = self.downsample(x)
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
def flops(self):
flops = 0
for blk in self.blocks:
flops += blk.flops()
if self.downsample is not None:
flops += self.downsample.flops()
return flops
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
def flops(self):
Ho, Wo = self.patches_resolution
flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops
class MOATransformer(nn.Module):
r""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
use_checkpoint=False, **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# absolute position embedding
if self.ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
dpr_global = [x.item() for x in torch.linspace(0, 0.2, len(depths)-1)]
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
drop_path_global = (dpr_global[i_layer]) if (i_layer < self.num_layers -1) else 0,
use_checkpoint=use_checkpoint)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def forward_features(self, x):
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def flops(self):
flops = 0
flops += self.patch_embed.flops()
for i, layer in enumerate(self.layers):
flops += layer.flops()
flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers)
flops += self.num_features * self.num_classes
return flops