实时多人在图像中的姿态估计面临着在速度和精度之间实现平衡的重大挑战。尽管两阶段的上下文方法在图像中人数增加时会减慢速度,但现有的单阶段方法往往无法同时实现高精度和实时性能。
本文介绍了RTMO,这是一个单阶段姿态估计框架,通过在YOLO架构中使用双一维 Heatmap 来表示关键点,实现与自上而下方法相当的准确度,同时保持高速度。作者提出了一种动态坐标分类器和一种定制的损失函数,用于 Heatmap 学习,专门针对坐标分类和密集预测模型之间的不兼容性。
RTMO在单阶段姿态估计器中超过了最先进的方法,在COCO上实现了1.1%更高的AP,同时使用相同的基础架构约9倍的速度。作者的最大模型RTMO-l在COCO val2017上达到了74.8%的AP,并在单个V100 GPU上实现了141 FPS,证明了其效率和准确性。
代码和模型:https://github.com/open-mmlab/mmpose/tree/dev-1.x/projects/rtmo
1 Introduction
多人姿态估计(MPPE)在计算机视觉领域中至关重要,应用范围涵盖增强现实到体育分析等领域。实时处理对于需要即时反馈的应用尤其关键,例如为运动员定位提供指导。尽管已经出现了许多实时姿态估计技术,但实现速度与精度之间的平衡仍然具有挑战性。
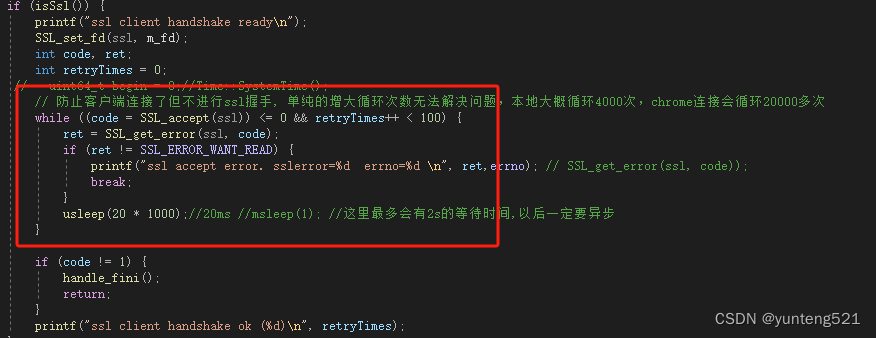
当前实时姿态估计方法可分为两类:自上而下方法(Top-down)和一阶段方法(One-stage)。自上而下方法利用预训练的检测器为目标创建边界框,然后对每个个体进行姿态估计。关键限制在于,它们的推理时间与图像中的人数成正比(参见图1)。另一方面,单阶段方法直接预测图像中所有个体的关键点位置。然而,当前实时单阶段方法在精度方面与自上而下方法相比仍存在差距(参见图1)。这些方法依赖于YOLO架构,直接回归关键点的坐标,这会阻碍性能,因为这种技术类似于使用每个关键点的狄拉克δ分布,忽略了关键点固有的歧义和不确定性。
另一种方法是,坐标分类方法使用双一维 Heatmap 来增加空间分辨率,通过将关键点位置的概率分布在跨越整个图像的两组bin上。这可以提供更准确的目标检测,同时计算成本最小。然而,将坐标分类直接应用于密集预测场景,如单阶段姿态估计,会导致由于图像和每个人占据的区域不同,bin利用率低下。此外,传统的Kullback-Leibler散度(KLD)损失将所有样本视为同等,这在单阶段姿态估计中是不最优的,因为在不同网格中,实例的难度显著不同。
在这项工作中,作者克服了上述挑战,并将坐标分类方法集成到基于YOLO的框架中,从而导致了实时多人单阶段姿态估计模型的开发。RTMO引入了一个动态坐标分类器(DCC),该分类器包括动态bin分配定位到边界框和可学习bin表示。此外,作者提出了一种基于最大似然估计(MLE)的新颖损失函数,以有效地训练坐标 Heatmap 。这种新的损失函数允许学习每个样本的不确定性,自动调整任务难度并平衡硬样本和易样本之间的优化,从而实现更有效和协调的训练。
因此,RTMO实现了与实时自上而下方法相当的准确性,并超过了其他轻量级单阶段方法,如图1所示。此外,RTMO在处理图像中的多个实例时表现出优越的速度,超过了具有相似准确度的自上而下方法。值得注意的是,RTMO-1模型在COCO val2017数据集上达到了74.8%的平均精度(AP),并在NVIDIA V100 GPU上以每秒141帧的速度运行。在CrowdPose基准测试中,RTMO-1实现了73.2%的AP,为单阶段方法创造了新的最先进水平。本工作的关键贡献包括:
-
针对密集预测场景的一种创新坐标分类技术,利用坐标bin进行精确的关键点定位,同时解决实例大小和复杂性带来的挑战。
-
提出一种新的实时单阶段多人姿态估计方法,无缝集成坐标分类与YOLO架构,实现了现有自上而下和单阶段多人姿态估计方法中性能与速度的最佳平衡。
2 Related Works
One-Stage Pose Estimator
受到单阶段目标检测算法进步的启发,一系列单阶段姿态估计方法出现了。这些方法在单次前向传播中执行MPPE,并直接从预定的根位置回归实例特定关键点。替代方法,如PETR和ED-Pose,将姿态估计视为一组预测问题,建立了端到端的全流程框架进行关键点回归。除了回归解决方案外,技术如FCPose, InsPose和CID利用动态卷积或注意力机制生成实例特定 Heatmap 以进行关键点定位。
与两阶段姿态估计方法相比,单阶段方法消除了预处理(例如,对于自上而下方法的人体检测)和后处理(例如,对于自下而上方法的关键点分组)的需要。这导致了两项好处:
-
一致的推理时间,与图像中的实例数量无关;
-
简化了一条 Pipeline ,便于部署和实际应用。
尽管具有这些优势,但现有的单阶段方法在平衡高精度和实时推理方面仍然存在困难。高精度模型[42, 46]通常依赖于资源密集的 Backbone 网络(例如,HRNet或Swin),这使得实时估计变得具有挑战性。相反,实时模型[30, 33]在性能上妥协。作者的模型解决了这一权衡,既提供了高精度,又提供了快速的实时推理。
Coordinate Classification
SimCC和RTMPose都采用了坐标分类进行姿态估计。这些方法根据水平轴和垂直轴上的子像素bin对关键点进行分类,实现空间区分而无需依赖高分辨率特征图。这有效地平衡了准确度和速度。然而,对于密集预测方法,将bin跨越整个图像是不切实际的,因为需要大量bin以减小量化误差,这会导致许多bin对于单个实例是多余的,从而降低效率。DFL在预定义的 Anchor 点周围设置bin,这可能不包括大型实例的关键点,并且对于小型实例可能会导致显著的量化误差。作者的方法根据每个实例的大小分配bin,将它们放置在局部区域内,优化bin利用率,确保覆盖关键点,并最小化量化误差。
Transformer-Enhanced Pose Estimation
基于Transformer的结构在姿态估计中变得无处不在,利用最先进的Transformer Backbone 网络以提高准确性,如ViTPose,或结合Transformer编码器与CNN以捕获空间关系。TokenPose和Poseur证明了基于 Token 的关键点嵌入在 Heatmap 和回归方法中都是有效的,利用视觉线索和解剖学约束。
PETR和ED-Pose将Transformer引入端到端多人在图像中的姿态估计,RTMPose将自注意力与基于SimCC的框架相结合,进行关键点依赖分析,这种方法也被RTMO所采用。虽然位置编码是注意力的标准,作者创新性地将其用于为每个空间bin形成表示向量,以计算bin-keypoint相似性,这有助于提高准确的局部化预测。
3 Methodology
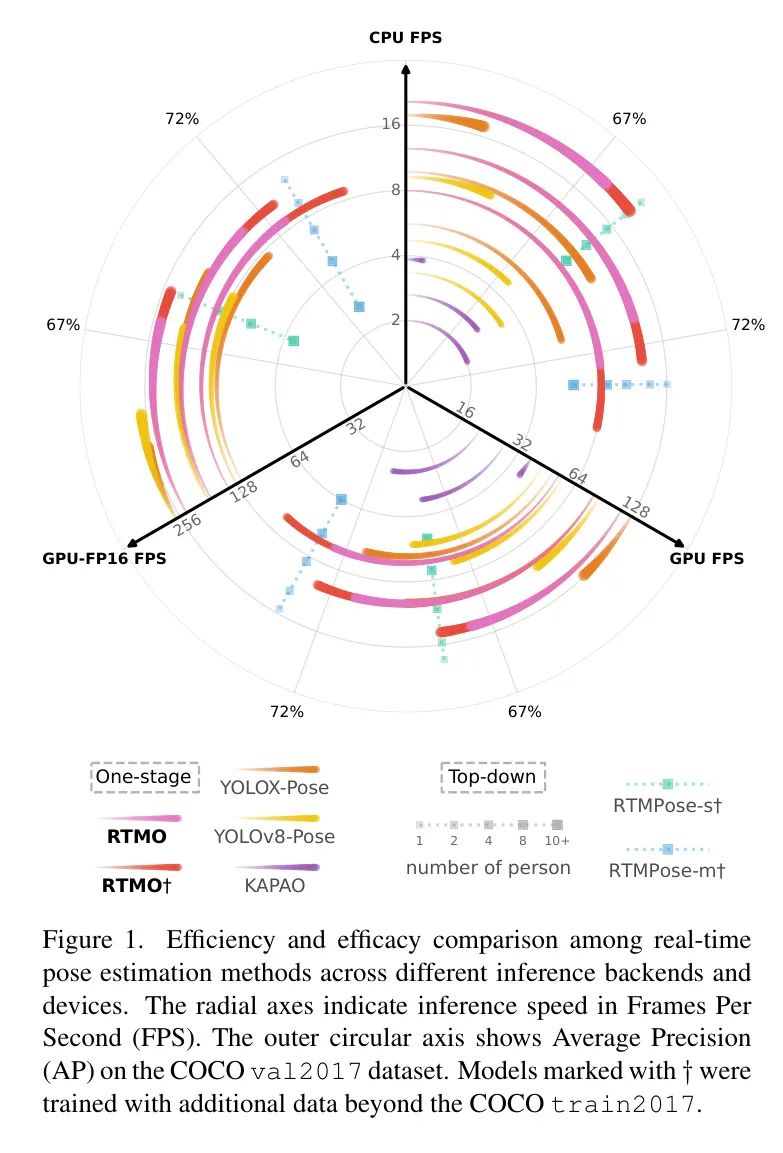
在作者的模型中,作者采用了一种类似于YOLO的架构,如图2所示。 Backbone 网络是CSPDarknet,作者将最后一个三个特征图通过Hybrid Encoder处理,得到具有分别为16和32下采样率的和空间特征。这些特征图中的每个像素对应于原始图像平面上均匀分布的网格单元。网络头利用每个空间 Level 的双卷积块生成每个网格单元的得分和相应的姿态特征。这些姿态特征用于预测边界框、关键点坐标和可见性。
动态坐标分类器通过生成一维 Heatmap 预测的详细过程可以在第3.1节中找到,而基于MLE的 Heatmap 损失则可以在第3.2节中找到。完整的训练和推理过程可以在第3.3节中找到。
Dynamic Coordinate Classifier
每个网格单元与对应的姿态特征包含了关键点相对于网格的位移。以前的工作直接回归这些位移,因此性能较差。作者的研究探讨了将坐标分类与单阶段姿态估计框架集成以提高关键点定位准确性的方法。现有坐标分类方法的一个显著局限性在于它们的静态bin分配策略。为了解决这个问题,作者引入了Dynamic Coordinate Classifier (DCC),该方法在两个一维 Heatmap 中动态分配范围并为bin形成表示,从而有效地解决了密集预测环境中坐标分类的兼容性问题。
动态bin分配
在自上而下的姿态估计器中使用的坐标分类技术将bin分配到整个输入图像。这种方法导致了单阶段方法中的bin浪费,因为每个主体只占据了图像的一小部分。DFL在预定义的 Anchor 点附近设置bin,这可能会遗漏大型实例的关键点,并在小型实例中导致严重的量化误差。DCC通过动态地为每个实例的边界框分配bin来解决这个问题,确保局部覆盖。边界框最初使用点卷积层进行回归,然后通过一个1.25的因子扩展以覆盖所有关键点,即使在不准确的预测情况下也是如此。这些扩展的边界框沿着水平和垂直轴均匀地划分成bin。每个水平bin的x坐标使用以下公式计算:
在这个公式中,和分别表示边界框的左和右边缘,索引从1到变化。y轴的bin也采用类似的方法计算。
动态bin编码
在DCC的背景下,每个bin在网格中的位置随预测的边界框不同而变化。这与以前的方法不同,其中bin坐标是固定的。与这些方法中使用的网格之间共享的bin表示不同,DCC在运行时动态生成定制化的表示。具体来说,作者将每个bin的坐标编码成位置编码,以创建bin特定的表示。作者使用sine位置编码定义如下:
使用全连接层来优化位置编码的适应性,以适应作者的任务,该层应用一个可学习的线性变换,从而优化其在DCC中的有效性。在这里,表示温度,是索引,表示总维度。
DCC的主要目标是准确预测每个bin中关键点出现的概率,这些概率受bin坐标和关键点特征的影响。关键点特征是从姿态特征中提取,并通过RTM-Pose后通过Gated Attention Unit (GAU)模块进行细化,以增强关键点之间的一致性。概率 Heatmap 是通过将每个bin的位置编码与关键点特征相乘,然后通过softmax得到的。
其中是第个关键点的特征向量。
MLE for Coordinate Classification
在分类任务中,通常使用one-hot目标和对数损失。标签平滑,如SimCC和RTMPose中使用的高斯标签平滑,以及KLD,可以提高性能。高斯均值和方差分别设置为标注坐标和预定义参数。目标分布定义为:
值得注意的是,在数学上与带有真实值的高斯误差模型下的标注的似然度相同。这种对称性质是由于高斯分布相对于均值是对称的。将预测的视为的先验,第个关键点的标注似然度为:
最大化这个似然度模型了标注的真实分布。
在实践中,作者使用Laplace分布和负对数似然损失。
其中实例大小归一化了误差,是预测的方差。常数因子被省略,因为它不影响梯度。总的最大似然估计(MLE)损失是。
与KLD不同,作者的MLE损失允许可学习的方差,表示不确定性。这种不确定性学习框架会自动调整各种样本的难度。对于困难的样本,模型预测较大的方差以促进优化。对于简单的样本,它预测较小的方差,有助于提高准确性。采用可学习的方差在KLD中是有问题的 - 模型倾向于预测较大的方差以压缩目标分布,因为这将简化学习。
Training and Inference
训练。作者的模型遵循YOLO类似的结构,采用密集网格预测进行人类检测和姿态估计。区分正负网格对模型至关重要。作者在SimOTA的基础上进行训练,根据网格得分、边界框回归和姿态估计准确性来分配正网格。 Head 得分分支对这些网格进行分类,受到varifocal损失的监督,其中目标得分是预测姿态和每个网格所分配的 GT 之间的目标关键点相似度(OKS)。
正网格标记会产生边界框、关键点坐标和可见性预测。关键点坐标通过DCC计算得到,其他预测来自逐点卷积层。应用的损失包括IoU损失、MLE损失和BCE损失。
鉴于DCC的计算需求,作者实现了一个与YOLO-Pose相似的点卷积层来进行初步坐标回归,以缓解内存问题。这个回归的关键点在SimOTA中充当正网格选择的代理,后来用解码的关键点计算OKS。回归分支的损失是OKS损失。
总损失。
其中超参数和设置为,。
推理。在推理阶段,作者的模型采用0.1的得分阈值和网格过滤器进行非极大值抑制。然后从选定的网格中解码姿态特征,并使用 Heatmap 的积分来推导关键点坐标。这种选择性解码方法最小化了需要处理的特征数量,从而降低了计算成本。
4 Experiments
Settings
数据集
实验主要在COCO2017 Keypoint Detection基准测试上进行,包括约25万个包含17个关键点的实例。在val2017和测试-dev集上与最先进的方法进行了性能比较。为了探索模型性能的极限,训练还扩展到了其他数据集:CrowdPose,AIC,MPII,JHMDB,Halpe,和PoseTrack18。这些标注被转换为COCO格式。RTMO还在CrowdPose基准测试上进行了评估,该测试由于场景复杂(拥挤且受阻碍)而闻名,包括20万张图像和大约8万个包含14个关键点的实例。OKS-based平均精度(AP)作为两个数据集的评估指标。
实现细节
在训练期间,作者采用YOLOX中的图像增强 Pipeline ,包括mosaic增强、随机颜色调整、几何变换和MixUp。训练图像被重新缩放到[480, 800]的大小。对于COCO和CrowdPose数据集,作者将epoch计数分别设置为600和700。训练过程分为两个阶段:第一个阶段涉及使用姿态标注同时训练代理分支和DCC;第二个阶段将代理分支的目标更改为来自DCC解码的姿势。使用AdamW优化器,具有权重衰减为0.05,在Nvidia GeForce RTX 3090 GPU上以batch size 256进行训练。初始学习率分别设置为和,并通过余弦退火衰减到。推理时,图像被重新缩放到640。使用ONNXRuntime在Intel Xeon Gold CPU上测量CPU延迟,在NVIDIA V100 GPU上使用ONNXRuntime和TensorRT以半精度浮点(FP16)格式测试GPU延迟。
#### RTMO Pose被用于比较
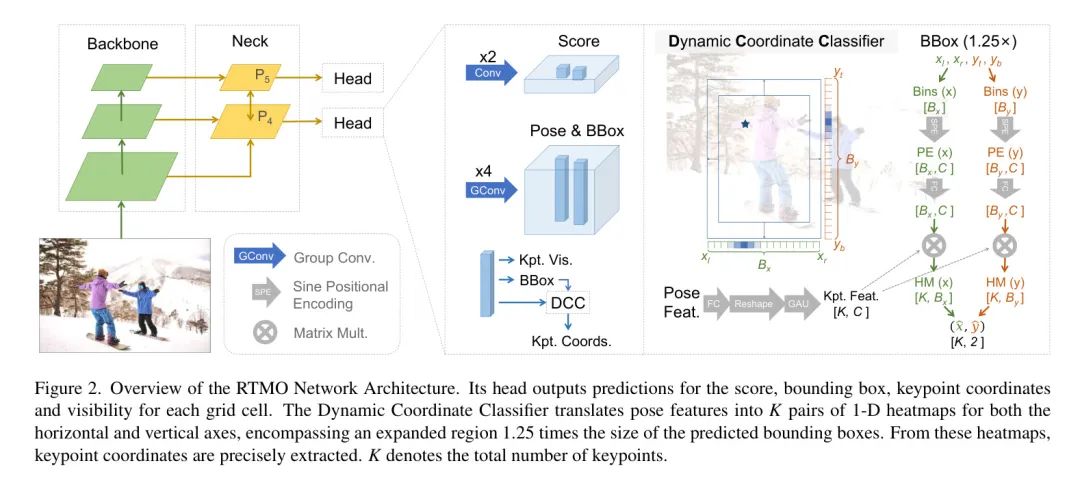
RTMDetno,一个高度高效的目标检测模型,作为自上而下模型的目标检测器。由于自上而下模型在图像中人数增加时会变慢,作者将COCO val2017集按人数划分并相应地评估自上而下模型的速度。如图3所示,RTMO系列在性能和速度上都优于可比轻量级单阶段方法。与自上而下模型相比,RMO-m和RMO-l的准确性与RTMPose-m和RTMPose-l相当,且在图像中人数更多时更快。使用ONNXRuntime,RMO与RTMPose在速度上相当,大约有四个人时。使用TensorRT FP16,RMO在有两或更多人时更快。这证明了RMO在多行人场景中的优势。
重要的是,尽管图像中处理标记的数量随人数变化,推理延迟的差异微乎其微。例如,RMO-l在GPU子集上的延迟比在只有一个人的子集上高约0.1 ms,占总延迟的约0.5%。
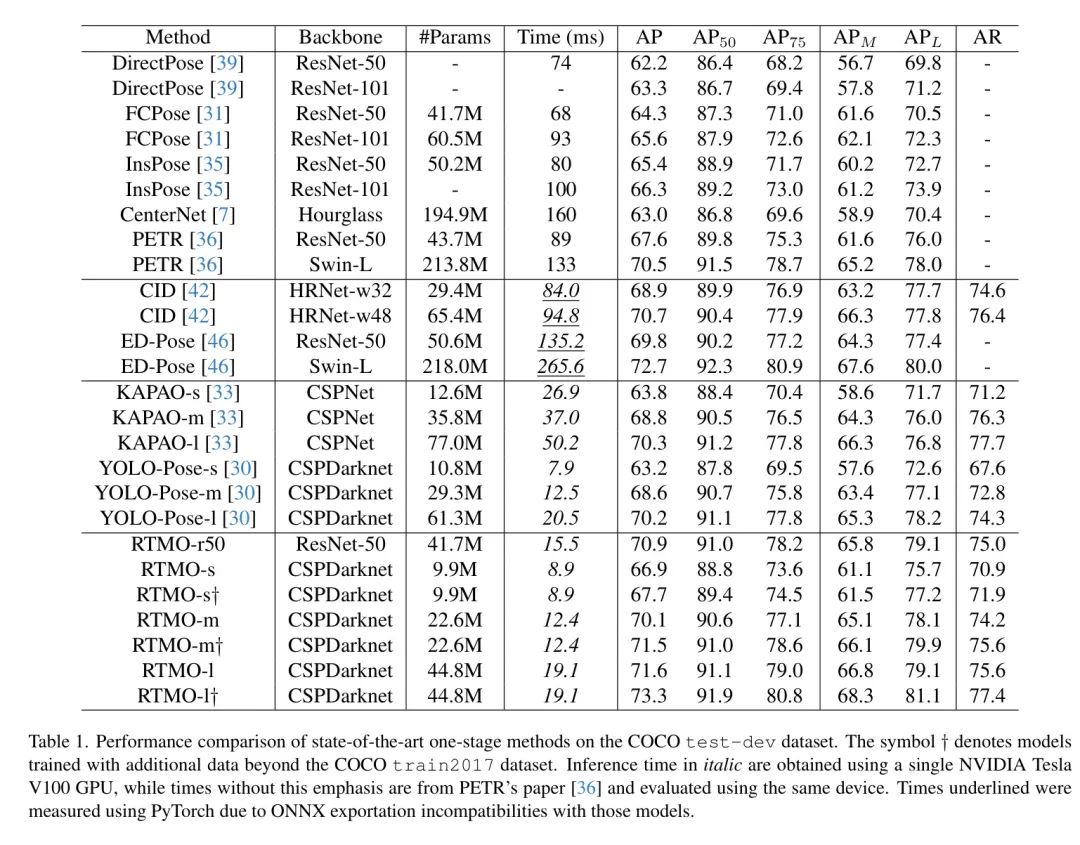
在COCO test-dev上,作者对RTMO与领先的单阶段姿态估计器进行了评估,结果如表1所示。RTMO在速度和精度方面取得了显著的进步。具体来说,RTMO-s使用ResNet-50 Backbone 网络,比PETR快十倍,同时保持相似的准确性。
与轻量级模型KAPAO和YOLO-Pose相比,RTMO在不同的模型大小上始终优于其他模型。当在COCO train2017上进行训练时,RTMO-l在所有测试模型中表现第二好。性能最好的模型是ED-Pose,使用Swin-L Backbone 网络,但非常沉重,不适合部署。使用相同的ResNet-50 Backbone 网络,RTMO-l比ED-Pose提高了1.1%的AP,并且更快。此外,将ED-Pose转移到ONNX格式导致其延迟比PyTorch模型慢约1.5秒/帧。
相比之下,RTMO-l的ONNX模型仅需19.1ms处理一张图像。通过进一步在额外的多人姿态数据集上进行训练,RTMO-l在单阶段姿态估计器中准确度方面最佳。
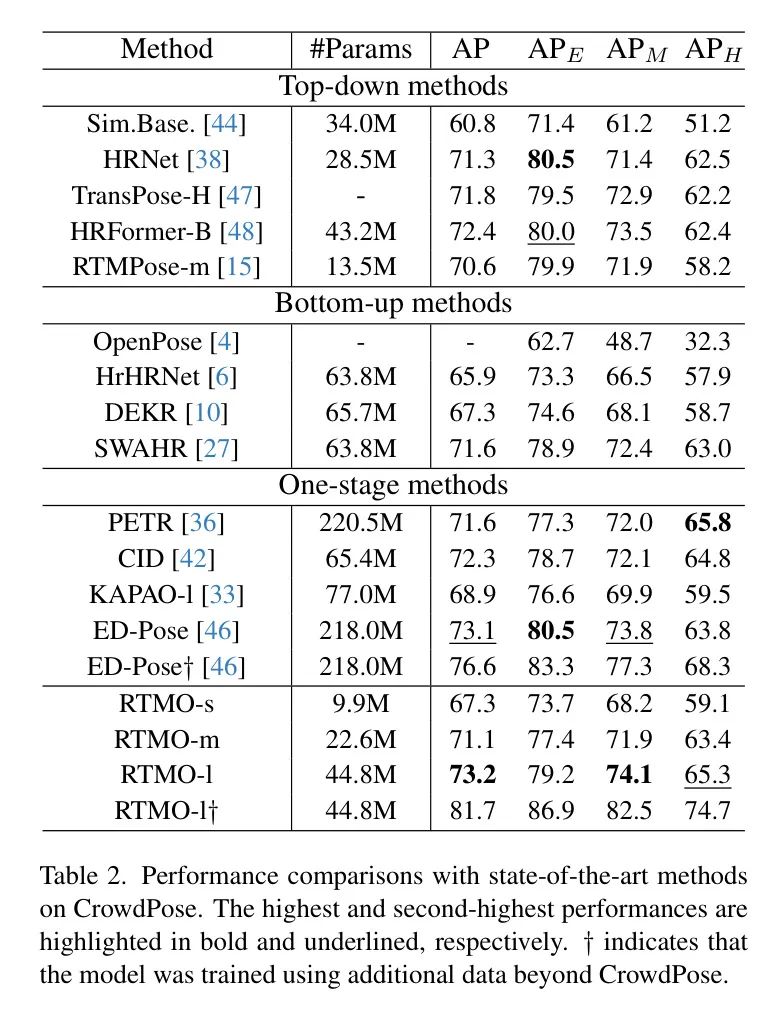
为了评估RTMO在具有挑战性的场景下的性能,作者在CrowdPose基准测试上对其进行了测试,该基准测试的特征是密集人群、重要的人重叠和遮挡。结果如表2所示。在自下而上和单阶段方法中,RTMO-s的准确度与DEKR相当,但仅使用15%的参数。当在CrowdPose数据集上进行训练时,RTMO-l超过了使用Swin-L Backbone 网络的ED-Pose,尽管具有较小的模型大小。
值得注意的是,RTMO-l在中等和困难样本上的性能超过了ED-Pose,表明该模型在具有挑战性的情况下非常有效。此外,通过使用额外的训练数据,RTMO-l达到了最先进的81.7% AP,突显了该模型的能力。
Quantitative Results
RTMO采用坐标分类方法,并在具有挑战性的多行人场景中表现出强大的性能,其中个体相对较小且经常发生遮挡。

图4揭示了在如此困难的情况下,RTMO能够生成空间准确的heatmap,从而为每个关键点提供稳健和上下文敏感的预测。

Ablation Study
分类与回归
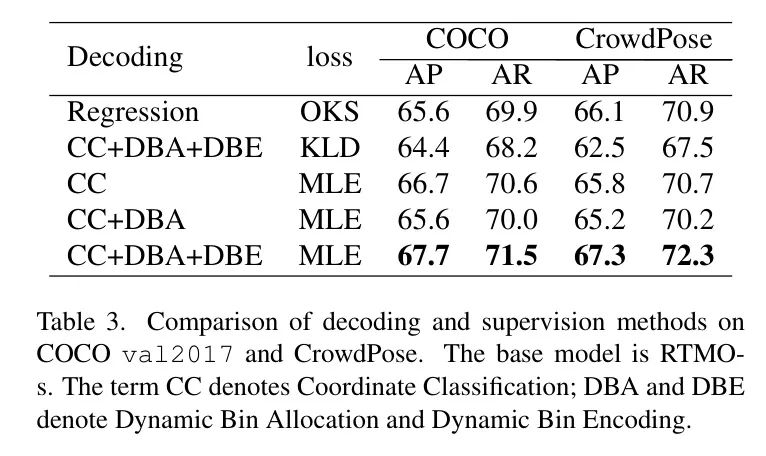
为了评估坐标分类与回归的有效性,作者将模型的1D heatmap生成替换为全连接层进行回归,并使用OKS损失进行监督。表3比较了性能。使用DCC模块和MLE损失,坐标分类在COCO上的回归性能比回归提高了2.1%的AP。
坐标分类的损失
与其他具有坐标分类的姿势估计方法相比,作者的研究认为KLD不适合RTMO。表3中的证据表明,与作者的MLE损失相比,使用KLD的准确度较低。作者将这种改进归因于MLE损失函数中包含可学习的方差,这有助于在硬样本和易样本之间平衡学习。具体来说,在一阶段姿势估计器框架中,每个网格的难度水平不同,并受到多个因素的影响,包括分配给网格的实例姿势和大小,以及网格和实例之间的相对位置。KLD无法考虑这种可变性,因此在这个上下文中效率较低。
坐标分类的动态策略
作者首先采用了一种类似于DFL的静态坐标分类策略,其中每个网格周围的bin在固定范围内分布。这种方法在COCO数据集上优于回归方法,但在CrowdPose上表现不佳。将Dynamic Bin Allocation (DBA)策略引入到这种 Baseline 中,导致两个数据集上的性能均下降。这是合理的,因为每个样本的bin语义在不同样本上不同,且没有相应的表示调整。这个问题通过引入Dynamic Bin Encoding (DBE)得到了解决。
使用DBE,作者的DCC方法在两个数据集上都超过了静态策略的有效性。此外,如果没有动态bin编码(DBE),相邻空间位置的概率可以显著变化,这与相邻空间位置应该具有相似概率的预期相反。相反,结合DBE可以导致更平滑的输出heatmap,表明通过启用能够更好地捕捉相邻位置相似性的表示向量,解码器训练得到了改善。
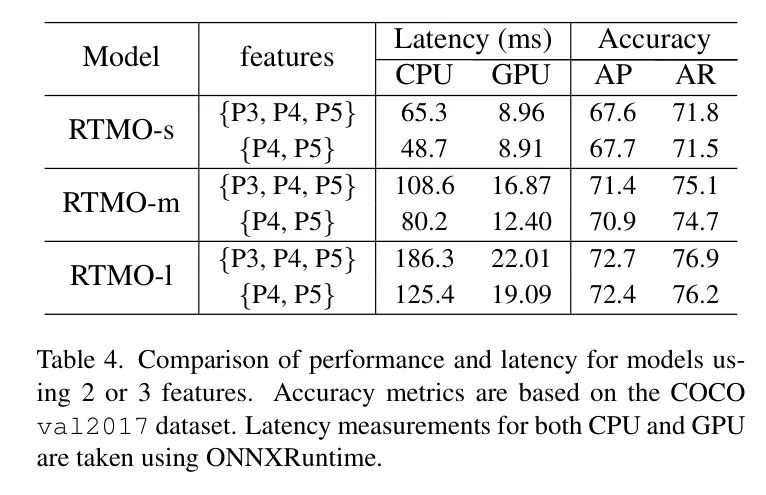
特征图选择。特征金字塔利用多尺度特征检测不同大小实例;较深的特征通常检测较大物体。作者的初始模型受到YOLOX的启发,使用了P3、P4、P5特征,步长分别为8、16和32像素。然而,P3在模型头中贡献了78.5%的FLOPs,而仅占10.7%的正确检测率。为了提高效率,作者关注P4和P5。如表4所示,省略P3导致了速度显著提高,但准确性损失很小,表明仅P4和P5对于多行人姿态估计是有效的。这表明P3在检测较小实例中的作用可以通过剩余特征得到充分补偿。
5 Conclusion
总之,作者的RTMO模型显著提高了单阶段多行人姿态估计中的速度与精度权衡。通过将坐标分类集成到YOLO基于的框架中,作者实现了实时处理和高精度。作者的方法具有动态坐标分类器和基于最大似然估计的损失函数,有效地提高了密集预测模型中的位置精度。这一突破不仅增强了姿态估计,而且为未来在密集预测视觉检测任务方面的进一步发展奠定了坚实的基础。