DQN
更新方程
Q θ ( s t , a t ) ← Q θ ( s t , a t ) + α ( r t + γ max a ′ Q θ ( s t + 1 , a ′ ) − Q θ ( s t , a t ) ) Q_\theta(s_t,a_t) \leftarrow Q_\theta(s_t,a_t) + \alpha \left( r_t + \gamma \red{\max_{a'} Q_\theta(s_{t+1},a')} - Q_{\theta}(s_t,a_t)\right) Qθ(st,at)←Qθ(st,at)+α(rt+γmaxa′Qθ(st+1,a′)−Qθ(st,at))
缺点:
- 频繁更新,算法不稳定
- 数据并不满足 i.i.d.
解决方法
- 经验回放
- 双网络结构(评估网络、目标网络)
经验回放
直觉:利用记忆,降低方差,增加稳定性。
做法:训练过程中存储
(
s
,
a
,
r
,
s
′
)
(s,a,r,s')
(s,a,r,s′) 到 buffer,训练的时候均匀/非均匀采样
优先经验回放(PER)
直觉:样本的TD 误差也不同,并且样本数量也不同。
如:打游戏,一般的关卡打小怪,比较容易,TD loss 很小,训练样本也多;最后一关打boss,难度大, TD loss 大,训练样本也少。
因此我们需要调整样本的采样概率,TD loss 大的样本给更大的采样概率,并给较小的学习率。
我们存储数据到 Buffer 的时候,还额外存储一个采样概率
p
t
+
ϵ
p_t +\epsilon
pt+ϵ
p
t
=
∣
δ
t
∣
p_t = |\delta_{t}|
pt=∣δt∣
δ
t
\delta_{t}
δt代表这个样本的TD loss
选中概率
P
(
t
)
=
p
t
α
∑
k
p
k
α
P(t)=\frac{p_t^\alpha}{\sum_k p_k^\alpha}
P(t)=∑kpkαptα
重要性采样调整学习率
ω
t
=
(
N
×
P
(
t
)
)
−
β
max
i
ω
i
\omega_t = \frac{(N\times P(t))^{-\beta}}{\max_i \omega_i}
ωt=maxiωi(N×P(t))−β
双网络结构
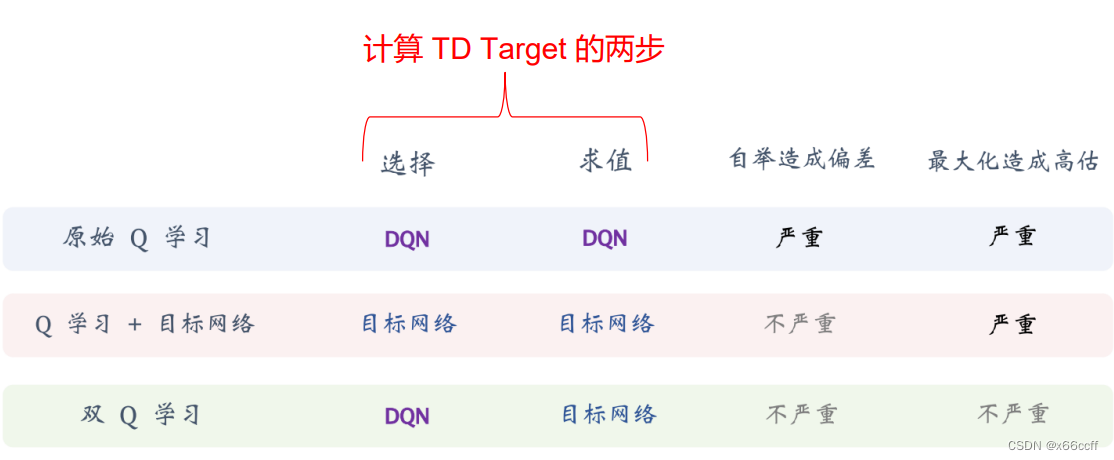
直觉:避免使用自举法,自己评价自己。这样 label 背后的机制在一段时间内总是稳定的,部分解决了DQN的偏差大的问题。
用慢 Q 网络计算 TD target
目标
=
r
t
+
γ
max
a
′
Q
θ
−
(
s
t
+
1
,
a
′
)
目标 = r_t + \gamma \red{\max_{a'} Q_{\theta-}(s_{t+1},a')}
目标=rt+γa′maxQθ−(st+1,a′)
Double DQN
但是使用了双网络(慢Q用来计算 TD target)之后,由于仍然使用 max 操作,会有**过估计的问题,导致算法容易过于自信,**高估 q ∗ ( s , a ) q_*(s,a) q∗(s,a) 的值。因此使用 Double DQN,对 TD target 的 max 重写为 argmax 的形式
DQN(快慢双Q、慢Q计算TD)
y
t
=
r
r
+
γ
Q
θ
−
(
s
t
+
1
,
arg
max
a
′
Q
θ
−
(
s
t
+
1
,
a
′
)
)
y_t = r_r + \gamma \red{Q_{\theta -}(s_{t+1},\arg \max_{a'}\blue{ Q_{\theta -}}(s_{t+1},a'))}
yt=rr+γQθ−(st+1,arga′maxQθ−(st+1,a′))
Double DQN(快慢双Q、慢Q只评估TD值、快Q计算max动作)
y
t
=
r
r
+
γ
Q
θ
−
(
s
t
+
1
,
arg
max
a
′
Q
θ
(
s
t
+
1
,
a
′
)
)
y_t = r_r + \gamma \red{Q_{\theta -}(s_{t+1},\arg \max_{a'}\green{Q_{\theta}}(s_{t+1},a'))}
yt=rr+γQθ−(st+1,arga′maxQθ(st+1,a′))
Dueling DQN
我们继续往 Double DQN 里面引入另外的模型假设,就有可能继续提升模型的性能:
这里的假设/直觉是:
部分环境反馈 Q 可能仅与状态 s 有关,和 a 无关。换句话说:
Q
(
s
,
a
1
)
Q(s,a_1)
Q(s,a1) 和
Q
(
s
,
a
2
)
Q(s,a_2)
Q(s,a2) 之间并不是完全无关的,对于部分反馈,他们之间是正相关的。
例子:
s = 小明考试得 0 分
a1 = 小明不做任何事
a2 = 小明和妈妈说“妈妈我爱你”
Q(s,a1) < 0 这是显然的
Q(s,a2) < 0 也同样有很大可能发生
在上面的例子中,如果我们独立地估计两个值,那么在估计第二个 Q 值的时候,TD loss 会比没有使用 Dueling 大(因为 Dueling 已经可以用 V ( s ) V(s) V(s)作为一个 baseline 估计),因为在这个场景下,Q 很大程度由 s 决定,如果能整体地学习 Q 关于 a 的加权函数,比如说 ∑ a π ( a ∣ s ) Q ( s , a ) \sum_a \pi(a|s) Q(s,a) ∑aπ(a∣s)Q(s,a) ,也就是 V ( s ) V(s) V(s),那么可以预期模型的收敛速度会加快。
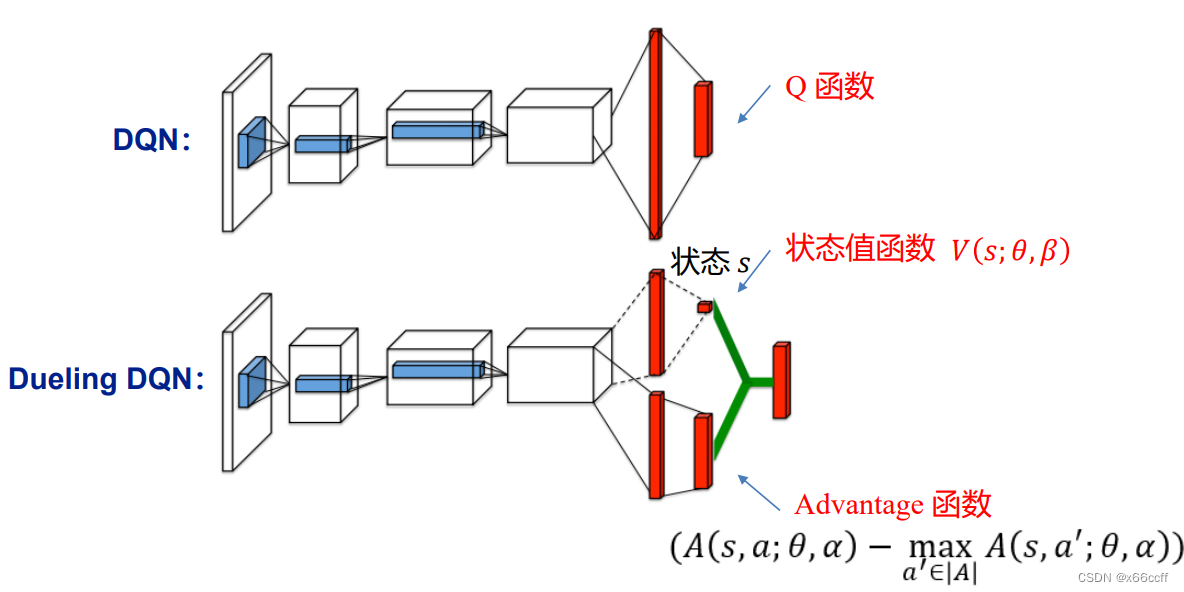
因此,Dueling DQN 使用两个网络,Q被表示为两个网络的输出的和
Q
(
s
,
a
)
=
A
(
s
,
a
)
+
V
(
s
)
Q(s,a) = A(s,a) + V(s)
Q(s,a)=A(s,a)+V(s)
这里
A
A
A 被称作优势函数,
A
A
A 相对于单纯的
Q
Q
Q 更强调动作
a
a
a的好坏,而
V
V
V只关注状态的好坏。
不同的优势函数聚合形式




![[robot_state_publisher-3] Error: Error document empty.](https://img-blog.csdnimg.cn/direct/4e9e6cb7142a449187bf9fb3df9a8178.png)