一、文本相似度
1. 度量指标:
- 两个文本对象之间的相似度
- 两个文本集合之间的相似度
- 文本对象与集合之间的相似度
2. 样本间的相似度
基于距离的度量:
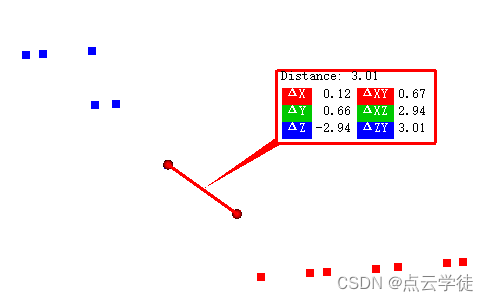
- 欧氏距离
- 曼哈顿距离
- 切比雪夫距离
- 闵可夫斯基距离
- 马氏距离
- 杰卡德距离
基于夹角余弦的度量
公式:
当文本进行了2-范数归一化,余弦相似度与内积相似度是等价的。
距离度量衡量的是空间各个点的绝对距离,与各点的位置(即个体特征维度的数值)直接相关,而余弦相似度衡量的事空间向量的夹角,更多的体现了方向上的差异,而不是位置(距离或长度)。
余弦相似度是文本相似度度量中使用最为广泛的相似度计算方法。
基于分布的度量
前面两种文本相似性度量方法主要针对定义在向量空间模型中的样本,而有时候,文本通过概率分布进行表示,如词项分布、基于PLSA和LDA模型的主题分布等。在这种情况下,可以用统计距离度量两个文本之间的相似度。
Kullback-Leibler(K-L)距离(K-L散度)
在多项分布中,从分布Q到分布P的K-L距离定义为:
K-L散度是非负的,当且仅当两个分布完全相等时取零。它不是对称的。
对称的K-L距离
注:K-L距离常常用于度量两个文本集合之间的相似度,且数据稀疏会让分布刻画时区意义。
杰卡德相似系数
3. 簇间相似度
一个粗通常由多个相似的样本组成。粗剪相似性度量是以各个簇内样本之间的相似性为基础的。假设表示簇
和簇
之间的距离,
表示样本
之间的距离。
最短距离法(single linkage)
最长距离法(complete linkage)
簇平均法(average linkage)
重心法
离差平方和
两个簇中各个样本到两个簇合并后的簇中心之间距离的平方和,相比于合并前各个样本到格子簇中心之间距离平方和的增量:
其中,
4. 样本与簇之间的相似性
样本与簇之间的相似性通常转化为样本之间的相似度或者簇间相似度进行计算。如果用均值向量来表示一个簇,纳秒样本与簇之间的相似性可以转化为样本与均值向量的样本相似性。如果将一个样本视作一个粗,那么就可采用上一种方法进行对量计算。