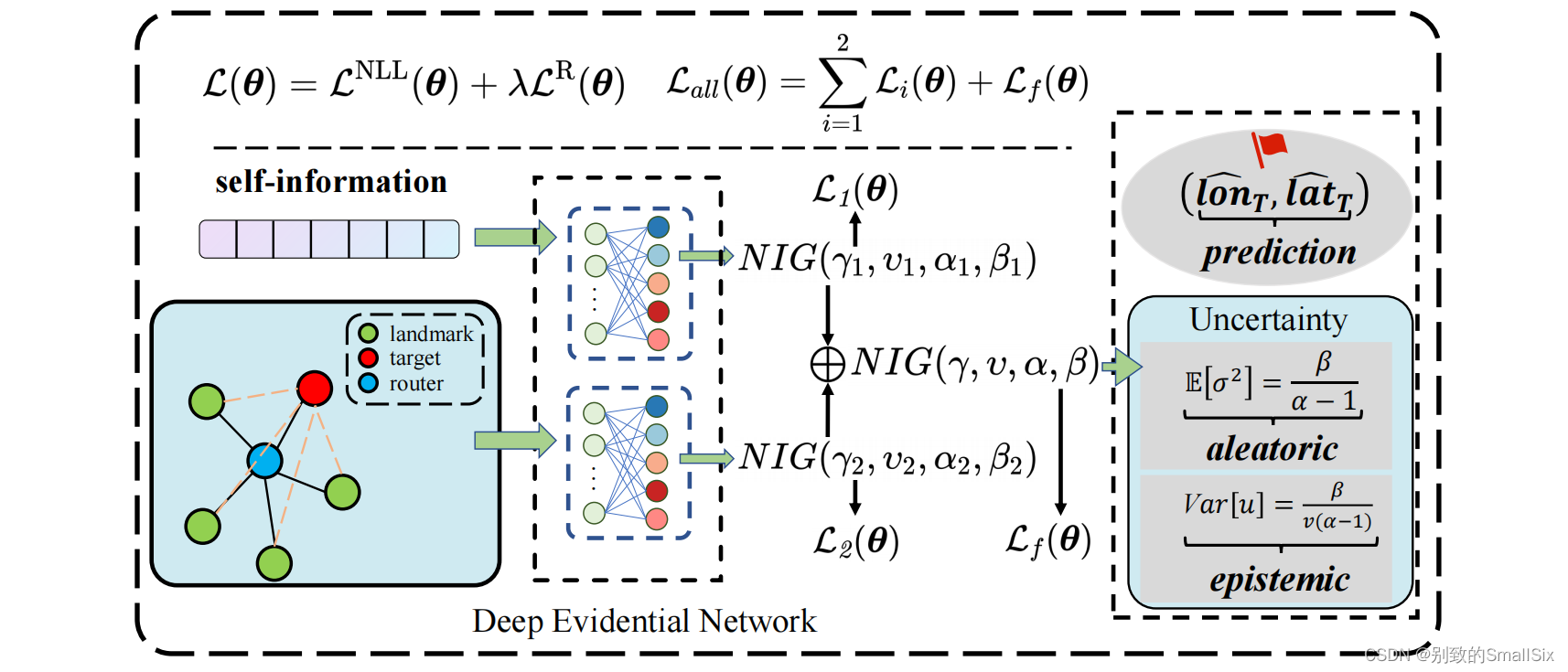
代码链接:https://github.com/ICDM-UESTC/TrustGeo
一、导入模块
import torch
import torch.nn as nn
import torch.nn.functional as F这段代码是一个简单的神经网络的定义,用于深度学习任务。
1、import torch:导入 PyTorch 库,提供张量(tensor)等深度学习操作的支持。
2、import torch.nn as nn:导入 PyTorch 中的神经网络模块,包括定义神经网络层的基本类。
3、import torch.nn.functional as F:导入 PyTorch 中的函数模块,包括一些激活函数、损失函数等。
二、ScaledDotProductAttention类定义(NN模型)
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
def forward(self, q, k, v, mask=None):
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
if mask is not None:
attn = attn.masked_fill(mask == 0, -1e9)
attn = self.dropout(F.softmax(attn, dim=-1))
# attn[attn <= torch.quantile(attn, 0.8)] = 0
# attn = torch.where(attn <= torch.mean(attn)*0.6, torch.full_like(attn, 0), attn)
output = torch.matmul(attn, v)
return output, attn这段代码定义了一个 Scaled Dot-Product Attention 模块,这是 Transformer 模型中注意力机制的一部分。这个模块实现了 Scaled Dot-Product Attention 的计算,是 Transformer 模型中实现自注意力机制的关键组成部分。
分为几个部分展开描述:
(一)__init__()
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)这是一个简单的自注意力(Self-Attention)模块的定义,其中包含了一个温度参数(temperature)和一个注意力丢弃率参数(attn_dropout)。主要用于实现一个简单的自注意力机制,其中包括对输入进行缩放(通过温度参数)以及应用注意力丢弃率。在实际应用中,这样的自注意力机制通常用于图神经网络等任务中,以捕捉输入序列中的重要信息。
1、def __init__(self, temperature, attn_dropout=0.1):这是类的构造函数,用于初始化SimpleAttention类的实例。参数包括temperature和attn_dropout,分别表示温度参数和注意力丢弃率参数。
2、super().__init__():调用父类的构造函数,确保正确地初始化继承自父类的属性。
3、self.temperature = temperature:将输入的temperature参数存储为类的属性,后续在注意力计算中使用。
4、self.dropout = nn.Dropout(attn_dropout):创建了一个 PyTorch 的 nn.Dropout 层,用于在注意力计算中应用丢弃率。attn_dropout 是一个可选参数,默认值为 0.1。
(二)forward()
def forward(self, q, k, v, mask=None):
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
if mask is not None:
attn = attn.masked_fill(mask == 0, -1e9)
attn = self.dropout(F.softmax(attn, dim=-1))
# attn[attn <= torch.quantile(attn, 0.8)] = 0
# attn = torch.where(attn <= torch.mean(attn)*0.6, torch.full_like(attn, 0), attn)
output = torch.matmul(attn, v)
return output, attn这是一个用于执行自注意力机制(Self-Attention)的前向传播函数。函数的整体功能是计算自注意力机制的输出,其中查询(q)、键(k)、值(v)是输入的特征表示。掩码(mask)是一个可选参数,用于屏蔽输入序列中的某些位置。通过计算注意力分数、应用 Softmax 函数和使用 dropout 进行正则化,该函数产生了自注意力的输出和相应的注意力权重。
1、def forward(self, q, k, v, mask=None):定义了前向传播函数,该函数接受查询(q)、键(k)、值(v)以及可选的掩码(mask)作为输入。
2、attn = torch.matmul(q / self.temperature, k.transpose(2, 3)):计算注意力分数。将查询和键进行点积操作,然后除以温度(temperature)以缩放注意力。这里采用了矩阵相乘的形式。
3、if mask is not None: