目录标题
- 前言
- 有关函数的几个性质介绍
- 可变参数的用法介绍
- 可变参数的一个注意事项
- 可变参数的底层原理
- va_list
- va_end
- va_start
- va_arg
- _INTSIZEOF
- 可变参数的注意事项
- 日志的实现
- 日志的测试
前言
在上一篇文章中我们介绍了TCP协议有关的函数,大致就是服务端先通过listen函数将自己的套接字设置为监听状态,然后客户端通过connect函数向对应的服务端发起链接请求,最后服务端使用accept函数接收客户端发送过来的链接请求并通过返回值来进行通信,那么这就是TCP协议通信的大致过程,因为上面的每一个函数调用都有可能会出现问题,所以在出现问题的时候我们都是直接朝屏幕上进行打印比如说:create socket error,bind error等等等,但是问题也是分等级的啊,如果这样无脑的朝屏幕上进行打印的话肯定会影响到程序的使用体验所以我们可以对问题进行分类,并且将不同程度的问题输出到不同的文件当中,这样未来想要查找问题的时候就只需要打开指定的文件即可,那么我们将程序问题分为以下几种:
#define DEBUG 0
#define NORMAL 1
#define WARNING 2
#define ERROR 3
#define FATAL 4
数字越大表示出现的问题越严重,DEBUG( 0 )和NOEMAL( 1 )基本上就表示没什么问题,WARNING(3)就表示稍微有点问题但是不影响程序的正常运行,ERROR就表示当前的比较严重会影响程序的正常运行,FATAL就表示当前的问题是非常致命的会造成严重的后果,有了分类还不够因为一个系统下会存在多个进程,每个进程都可能会发送问题,那我们怎么知道当前这个问题是属于哪个时间段哪个进程发送的呢?所以在发送报错消息的时候我们往往是会添加一些系统信息的,比如说时间搓和进程pid等等,有了这些信息之后我们就可以知道当前问题是谁发送的,该问题属于哪一个等级,最后就可以添加问题的内容,所以我们这里可以创建一个函数来专门完成这个错误发送的功能,该函数的声明如下:
void logMessage(int level, const char *format)
发送数据的格式就是下面这样:
[日志等级] [时间戳/时间] [pid] [messge]
[WARNING] [2023-05-11 18:09:08] [123] [创建socket失败]
但是有时候问题的内容是需要添加一些变量的值就好比printf函数一样,那么这个时候就存在一个问题我们怎么知道使用者会传递什么类型的参数呢?我们怎么知道参数的个数是多少呢?所以这里就得在函数当中添加可变参数列表,也就是在参数声明的末尾添加三个点:
void logMessage(int level, const char *format, ...)
这样我们就可以传递任意类型任意数量的参数就好比下面这样:
logMessage(WARNING,"创建socket失败 sokcet:%d,%f,%c",-1,3.14,c);
那么这就是我们要实现的logMessage函数的功能,在一个程序中调用该函数就可以向指定的位置打印该程序在运行过程中的信息,我们把这里的信息所组成的集合称之为日志。因为大多数同学在次之前并没有了解可变参数的原理和用法,所以在实现logMessage函数之前我们先来介绍一下可变参数。
有关函数的几个性质介绍
第一个性质:如果函数没有形式参数,也可以给函数传递参数,比如说下面的代码:
void print()
{
printf("当前函数不需要传递参数");
}
int main()
{
int a = 10;
int b = 20;
int c = 30;
print(a,b,c);
return 0;
}
程序在运行的时候是不会出现问题的:

第二个性质:在c语言中只要发生了函数调用并且传递了参数就必定会形成临时变量,这里依然用上面的代码来举例子,对其进行反汇编就可以看到下面这样的内容:
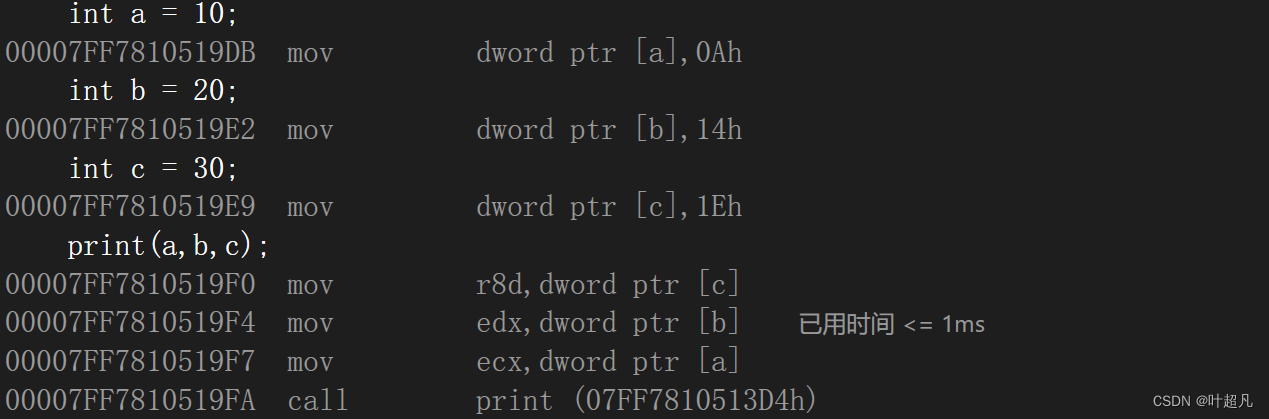
可以看到在使用指令call调用print函数之前先用move指令进行了赋值操作,因为不同版本的编译器看到的效果不太一样,这里没有看到push指令的压栈操作但是不妨碍传递参数就必定形成临时变量的结论,其次大家不难发现这里在传递参数的时候是以c b a的顺序来进行传递,但是在函数调用中参数传递的顺序却是a,b,c所以这里就可以得到函数调用的第三个性质:临时拷贝是以从右往左的顺序形成的,那么这就是函数调用有关的三个性质。
可变参数的用法介绍
这里通过一段代码来带着大家理解可变参数的使用方法:
#include<stdio.h>
#include<Windows.h>
//num表示可变参数的个数
int FindMax(int num, ...)
{
va_list arg;
va_start(arg, num);
//创建变量记录当前最大值
int max = va_arg(arg, int);
for (int i = 0; i < num - 1; i++)
{
int cur = va_arg(arg, int);
if (max < cur)
{
max = cur;
}
}
va_end(arg);
return max;
}
int main()
{
int max = FindMax(5, 101, 32, 324, 178, 78);
printf("最大的值为:%d", max);
return 0;
}
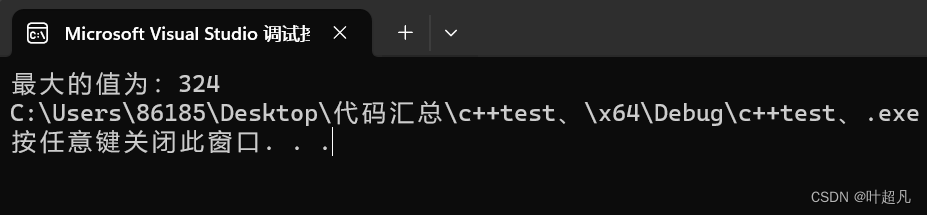
首先该函数实现的功能就是在一定数量的可变参数中找到最大值,程序的运行结果如下:
对于这段代码大家可能就对这几点感到困惑:va_list,va_start,va_arg,va_end,首先这几个东西都是与
可变参数有关的宏,va_list本质上就是一个char类型的指针,用它创建变量arg指向可变参数中的变量
typedef char* va_list;
因为当前函数的参数分为固定参数和可变参数,而传递参数又是从右向左进行传递的,函数的栈帧又是从下往上进行生长的所以我们当前需要一个功能让arg指向可变参数部分,那么宏va_start就是负责实现该功能
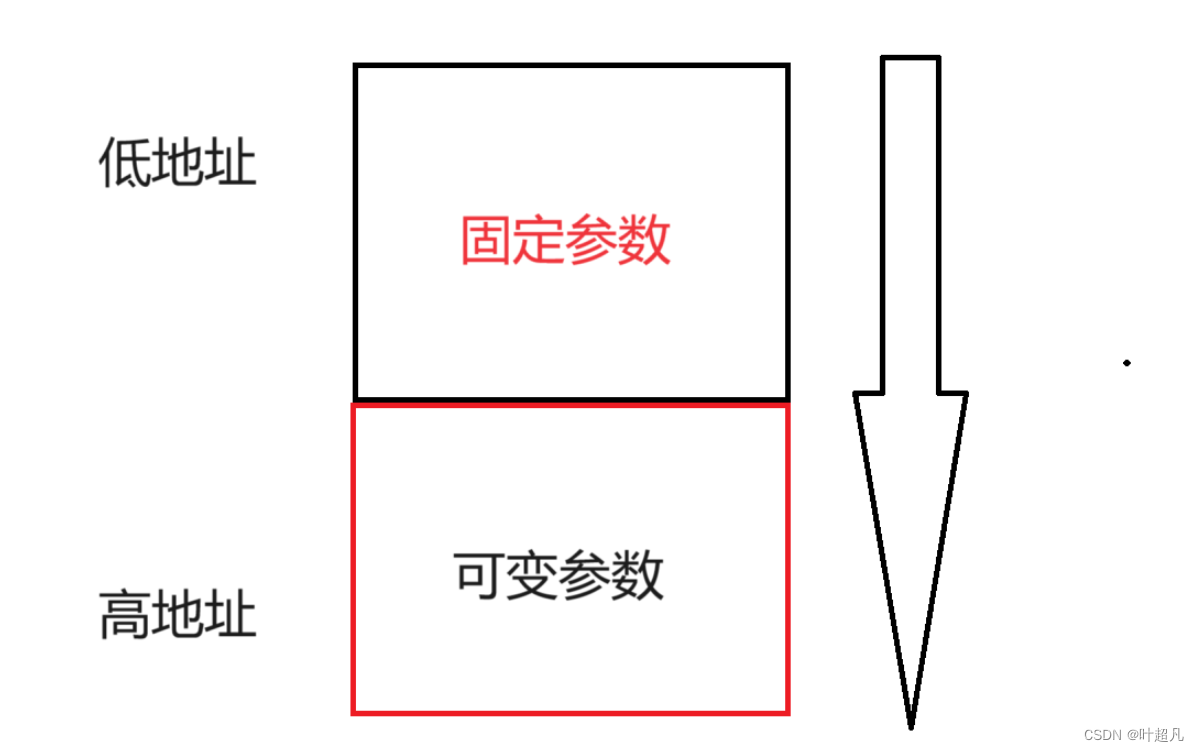
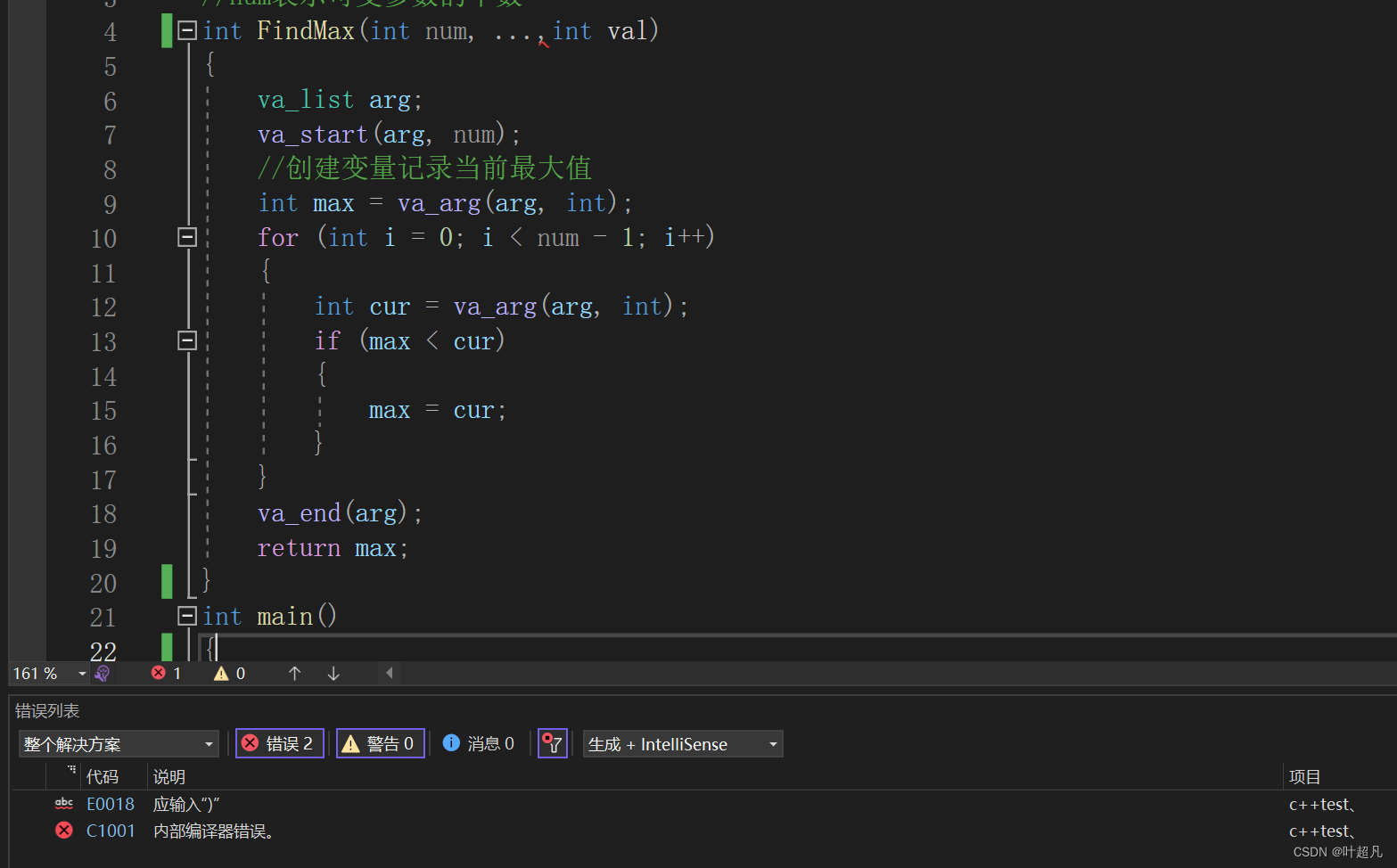
但是va_start也不知道可变参数的起始位置在哪?所以我们得把紧挨着可变参数的固定参数传递给va_start,因为参数的传递是连续的,所以他就可以根据该参数的地址和该参数的类型找到第一个可变参数的地址,然后就可以随水推舟再根据可变参数的类型和地址找到其他可变参数,那么这就是va_start的功能(初始化va_list定义的变量)以及为什么上面的代码将固定参数num传递给va_start的原因,这里大家可能会有疑问:如果图片是下面这样该如何传递紧挨着的固定参数呢?
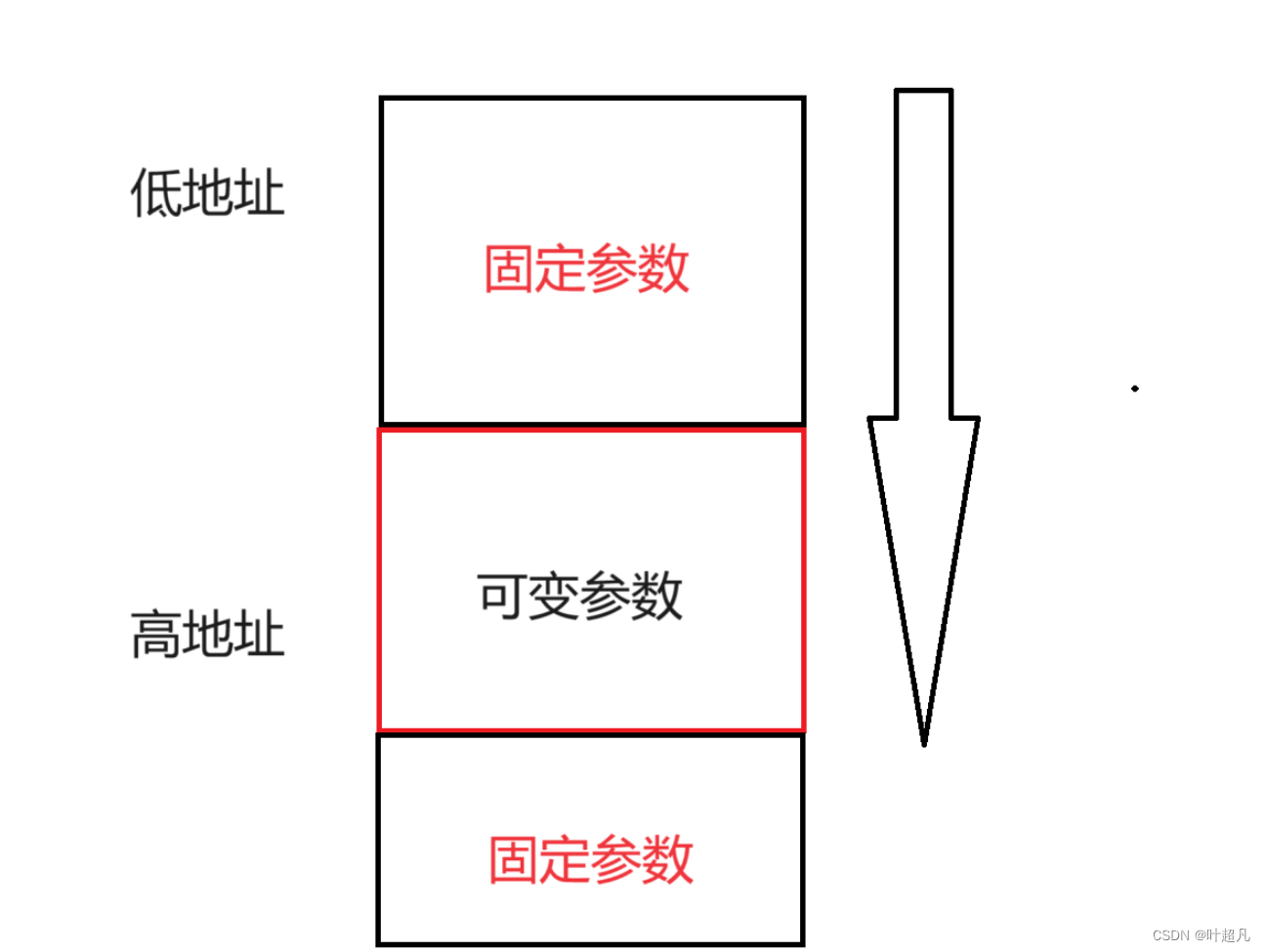
我们可以在尝试一下然后就可以发现这里是直接报错的,可变参数列表的右边是不能添加固定参数的
找到了可变参数我们就可以读取可变参数的内容以及向下找到其他的可变参数,那么这里就可以用到宏va_arg,他就可以返回当前arg指针指向的内容以及帮助arg指针找到下一个可变参数,使用这个宏的时候得传递当前指针指向的数据类型,因为我们传递的都是int类型参数所以第二个参数就填int,最后一个arg_end就是用来将指针变量arg置空,那么这就是与可变参数有关的4个宏的作用,通过上面的介绍大家应该能够知道可变参数基本的使用方法。
可变参数的一个注意事项
我们将传递的参数类型修改成char类型而不改变va_arg会不会出现什么问题呢?比如说下面的代码:
#include<stdio.h>
#include<Windows.h>
//num表示可变参数的个数
int FindMax(int num, ...)
{
va_list arg;
va_start(arg, num);
//创建变量记录当前最大值
int max = va_arg(arg, int);
for (int i = 0; i < num - 1; i++)
{
int cur = va_arg(arg, int);
if (max < cur)
{
max = cur;
}
}
va_end(arg);
return max;
}
int main()
{
char a = 'a';
char b = 'b';
char c = 'c';
char d = 'd';
char e = 'e';
char max = FindMax(5,a,b,c,d,e);
printf("最大的值为:%c", max);
return 0;
}
代码的运行结果如下:
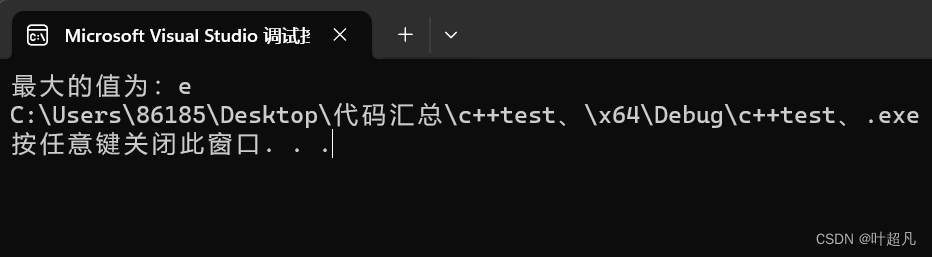
可以看到当前是没有出现问题的,那这是为什么呢?为什么我们传递char类型的参数以int类型的方式进行读取却不会出现问题呢?原因很简答因为可变参数在传递的过程中会发生以4字节为倍数的向上整形提升,如果你传递的参数大小为1字节那么在传参的时候就会自动提升到4个字节,如果你传递的参数大小为2个字节那么在传参的时候也会自动的提升到4个字节,如果你传递的参数大小为6个字节那么在传参的时候就会自动的提升到8个字节以此类推,这也是为什么我们上面传递char类型的数据以int的方式进行读取却没有出错的原因,这里我们还有两个方法来进行验证首先就是查看可变参数传递时的汇编指令:

上面传递int类型时是采用move指令但是这里采用的确实movsx指令,movsx是x86汇编语言中的一种指令,用于将一个有符号数扩展到一个更大的寄存器中。它的作用是将一个有符号数从一个小的寄存器或内存位置移动到一个大的寄存器中,并将高位扩展为符号位。这个指令可以用来处理有符号数的转移,避免出现符号位扩展错误的情况,简单的来说就是整形提升。另外一个方法就是通过内存来进行查看,首先找到参数num对应的地址:
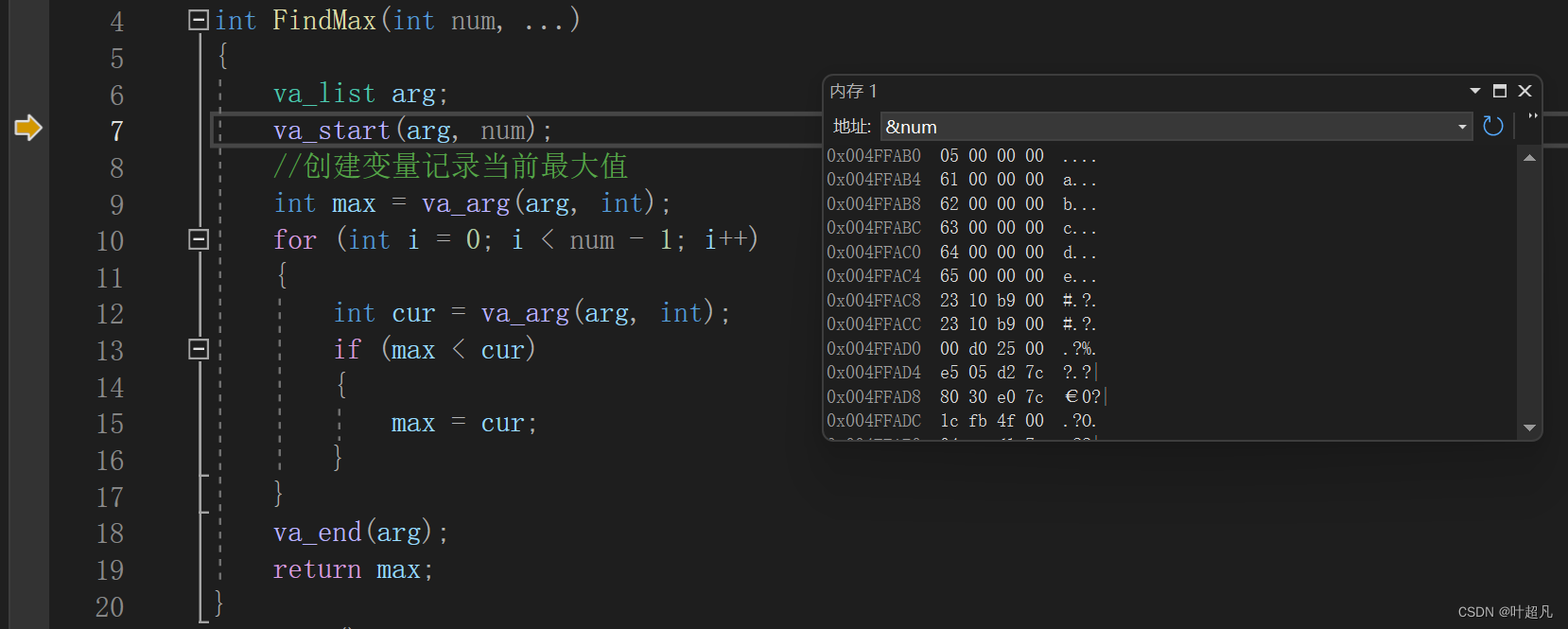
因为参数是从右向左连续传递的上面是低地址下面是高地址,并且这里的内存监视是以4个字节为一行来进行显示,所以004FAB0下面5行就是对应的参数在内存上的数据
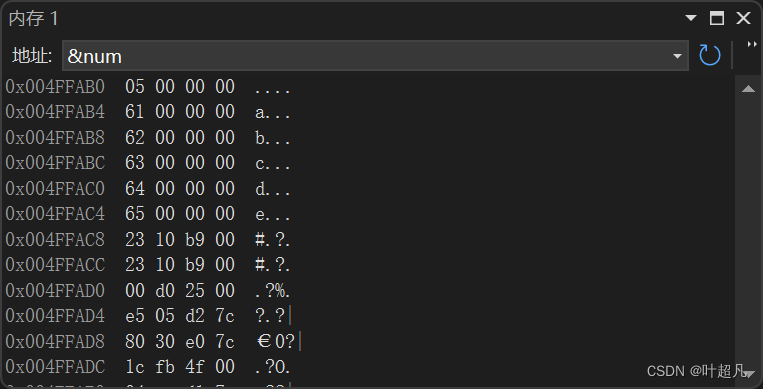
不难发现这5行的内容刚好就是abcde,一行就是4个字节所以这也间接的证明了可变参数在传递的时候会发生整形提升的特点,那如果我们传递char类型数据以char类型为单位进行读取的话,会不会出现问题呢?这里我们可以通过下面的代码来尝试一下:
void test(int num, ...)
{
va_list arg;
va_start(arg, num);
for (int i = 0; i < num; i++)
{
int cur = va_arg(arg, char);
printf("%c ", cur);
}
}
int main()
{
char a = 'a';
char b = 'b';
char c = 'c';
char d = 'd';
char e = 'e';
test(5,a,b,c,d,e);
return 0;
}
代码的运行结果如下:
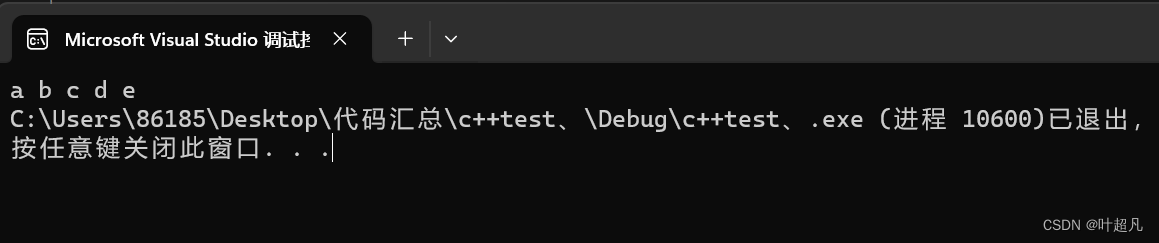
答案是没有问题的,因为va_arg也会对你传递过来的类型进行整形提升,这里我们在可变参数的底层原理给大家讲解,那么这就是可变参数的使用方法和特性。
可变参数的底层原理
va_list
va_list的作用就是创建一个char类型的指针用来指向可变参数,他的底层起始就是char的重命名

va_end
va_end的作用就是将va_list创建的变量的值置为空,我们来看看这个宏的定义如何:

底层是__crt_va_end,这个东西也是一个宏我们再来看看他的定义:

ap是一个char类型的指针,那么这里的意思就是将数字0强制类型转换为char*类型然后再赋值给指针ap,也就是将指针ap置为空的意思。
va_start
va_start的作用就是初始化指针让其指向可变参数的第一个参数,该参数的底层如下:

底层套了一个宏__crt_va_start,该宏的定义如下:

可以看到__crt_va_start的在底层又套了一个宏__crt_va_start_a,该宏的定义如下:

__crt_va_start_a依靠两个宏来实现,第一个AARESSOF的作用就是提取参数的地址
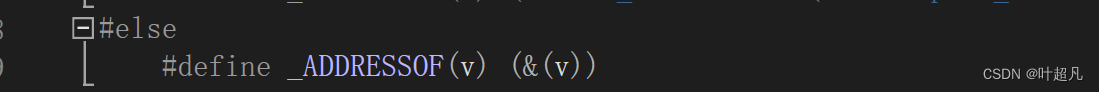
第二个_INTSIZEOF的作用就是计算类型或者变量整形提升之后创建变量所占的空间大小,如果n的类型为char那么这个宏计算的结果就是4,具体是如何计算的我们后面再说
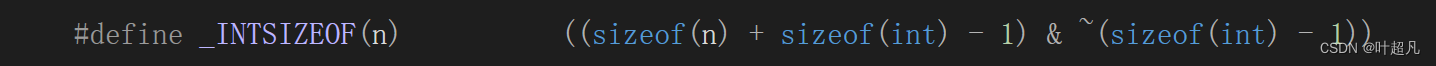
知道了这两个宏的作用我们再来看__crt_va_start_a的底层意思就是先获取固定参数的地址,然后再获取固定参数所占的地址大小,最后将两个值相加的结果赋值给ap即可,这样ap就指向了可变参数的第一个参数,我们可以通过图片再来理解理解:
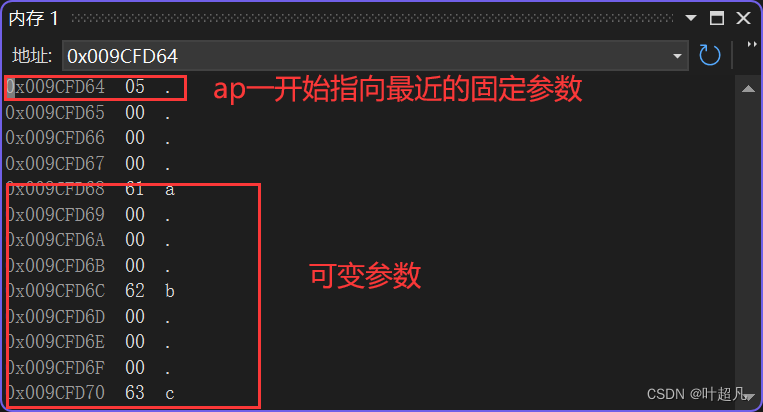
因为最近的变量的类型为int所以_INTSIZEOF计算得到的结果就是4,009CFD64加上4之后得到的结果就刚好是009CFD68也就是可变参数第一个参数的地址,然后将该地址赋值给ap图片就变成下面这样:
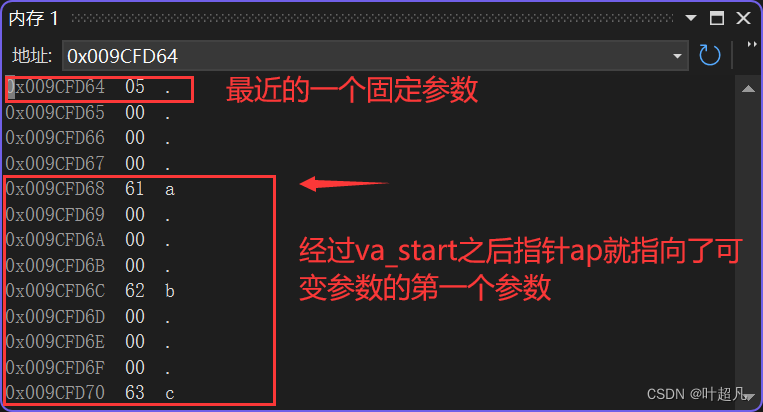
这就是初始化的作用和原理。
va_arg
va_arg的作用就是根据你传递过来的类型获取指针指向的空间内容并将指针向后移动类型对应的大小,比如说一开始指针指向的内容如下:
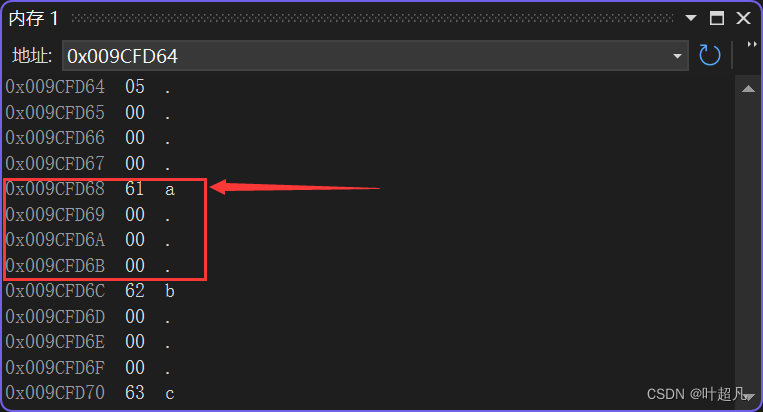
传递的类型为int的话,va_arg的作用获取方括号中的内容并将指针指向方括号下面的62,那么图片就变成下面这样:
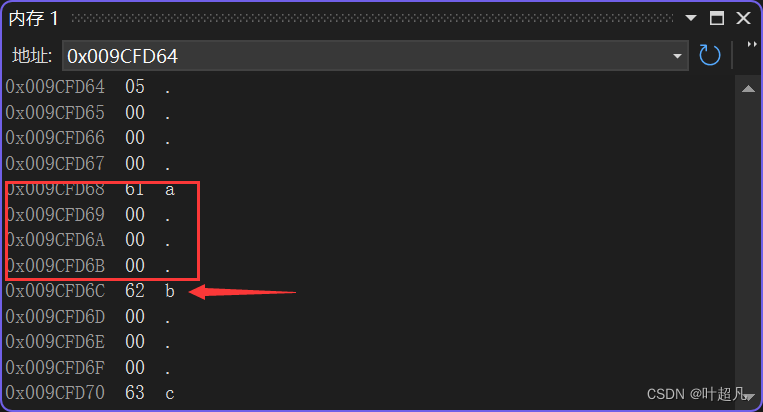
va_arg的底层如下:

再转换一下便可以看到真正的底层:

这里的结构比较复杂首先执行的运算是:(ap += _INTSIZEOF(t),得到结果的就是让指针ap向下移动t类型整形提升后大小的长度,也就是从图片中的a指向了b:
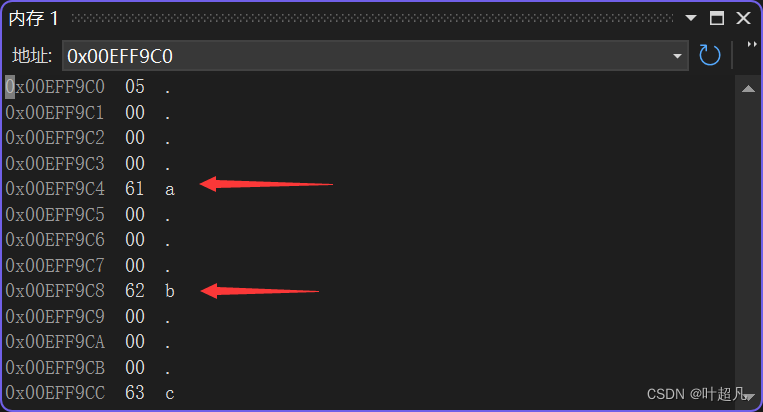
表达式都会返回值,那么上一步的返回值就是b的地址,将这个地址减去_INTSIZEOF(t)就又得到了a的地址,但是指针ap指向的依然是b,将地址a的类型转换成为t*这样就可以得到方括号中的内容而指针ap依然指向的b:
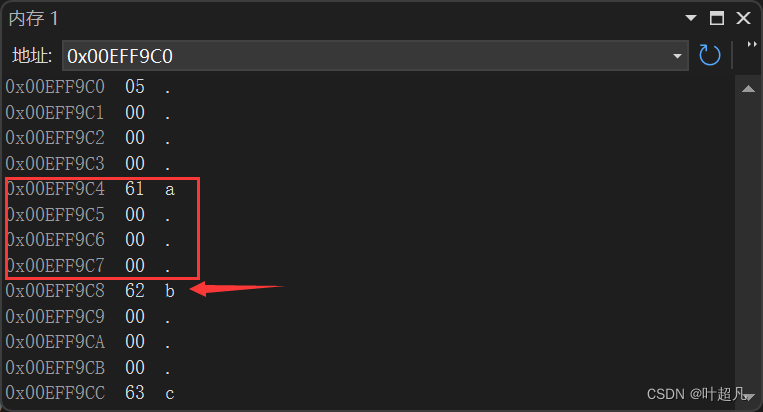
那么这就是va_arg的底层实现。
_INTSIZEOF
_INTSIZEOF的底层如下:
((sizeof(n) + sizeof(int) - 1) & ~(sizeof(int) - 1))
为了后面方便表述我们假设sizeof(n)的值是n(char 1,short 2, int 4)我们在32位平台,vs2013下测试sizeof(int)大小是4,其他情况我们不考虑_INTSIZEOF(n)的意思:计算一个最小数字x,满足 x>=n && x%4==0,其实就是一种4字节对齐的方式比如n是:1,2,3,4对n进行向 sizeof(int) 的最小整数倍取整也就是4,比如n是:5,6,7,8对n进行向 sizeof(int) 的最小整数倍取整就是8,对于这个公式我们有三步理解:
第一步理解:4的倍数
既然是4的最小整数倍取整,那么本质是:x=4*m,m是具体几倍。对7来讲,m就是2,对齐的结果就是8而m具体是多少,取决于n是多少如果n能整除4,那么m就是n/4如果n不能整除4,那么m就是n/4+1
上面是两种情况,如何合并成为一种写法呢?常见做法是 ( n+sizeof(int)-1) )/sizeof(int) -> (n+4-1)/4
如果n能整除4,那么m就是(n+4-1)/4->(n+3)/4, +3的值无意义会因取整自动消除,等价于 n/4如果n不能整除4,那么n=最大能整除4部分+r,1<=r<4 那么m就是 (n+4-1)/4->(能整除4部分+r+3)/4,其中4<=r+3<7 -> 能整除4部分/4 + (r+3)/4 -> n/4+1。
第二步理解:最小4字节对齐数
搞清楚了满足条件最小是几倍问题,那么,计算一个最小数字x,满足 x>=n && x%4==0,就变成了
((n+sizeof(int)-1)/sizeof(int))[最小几倍] * sizeof(int)[单位大小] -> ((n+4-1)/4)*4这样就能求出来4字节对齐的数据了,其实上面的写法,在功能上,已经和源代码中的宏等价了。
第三步理解:理解源代码中的宏
拿出简洁写法:((n+4-1)/4)* 4,设w=n+4-1, 那么表达式可以变化成为 (w/4)*4,而4就是2^2,w/4,不就相当于右移两位吗?,再次*4不就相当左移两位吗?先右移两位再左移两位,最终结果就是最后2个比特位被清空为0!需要这么费劲吗?w & ~3 不香吗?所以简洁版:(n+4-1) & ~(4-1)原码版:( (sizeof(n) + sizeof(int) - 1) & ~(sizeof(int) - 1) ),无需先/,在*。
可变参数的注意事项
第一: 可变参数必须从头到尾逐个访问。如果你在访问了几个可变参数之后想半途终止,这是可以的,但是如果你想一开始就访问参数列表中间的参数那是不行的。
第二: 参数列表中至少有一个命名参数。如果连一个命名参数都没有就无法使用 va_start ,这些宏是无法直接判断实际存在参数的数量,如果想要知道可变参数的个数就可以跟我们上面一样传递一个固定的参数用来表示可变参数的数量或者像printf函数一样根据特殊的标记来判断参数的个数,比如说printf("hello word:%d %c",3.14,c)我们就可以创建一个字符指针p指向文本信息,然后创建一个循环每读取一个字符就进行判断如果不为字符%就直接跳过,如果为%就继续判断下一个字符是否为d是否为f等等等,如果下一个字符为d我们就可以以int形式提取可变参数,如果为f我们就可以以float的形式提取可变参数等等,比如说下面的代码:
va_list start;
va_start(start);
while(*p){
switch(*p)
{
case '%':
p++;
if(*p == 'f') arg = va_arg(start, float);
if(*p == 'd') arg = va_arg(start, int);
...
}
}
va_end(start);
那么通过这样的方式我们也能够判断可变参数个数。
第三: 这些宏无法判断每个参数的是类型,所以我们得自己传递具体的类型。
第四: 如果在va_arg 中指定了错误的类型,那么其后果是不可预测的。
日志的实现
因为宏的本质就是数字
#define LOG_NORMAL "log.txt"//运行正常发送的文件
#define LOG_ERR "log.error"//运行不正常发送的文件
#define DEBUG 0
#define NORMAL 1
#define WARNING 2
#define ERROR 3
#define FATAL 4
所以我们首先得创建一个函数用来将数字转换成为问题等级的字符:
const char * to_levelstr(int level)
{
switch(level)
{
case DEBUG : return "DEBUG";
case NORMAL: return "NORMAL";
case WARNING: return "WARNING";
case ERROR: return "ERROR";
case FATAL: return "FATAL";
default : return nullptr;
}
}
问题内容由问题属性和问题信息组成,所以我们先创建一个缓冲区通过snprintf函数将问题属性输出到缓冲区中:
void logMessage(int level, const char *format, ...)
{
// [日志等级] [时间戳/时间] [pid] [messge]
// [WARNING] [2023-05-11 18:09:08] [123] [创建socket失败]
#define NUM 1024
char logprefix[NUM];
snprintf(logprefix, sizeof(logprefix), "[%s][%ld][pid: %d]",
to_levelstr(level), (long int)time(nullptr), getpid());
}
再创建一个缓冲区用来记录问题信息,因为问题信息存在可变参数所以还得创建一个va_list变量并将其初始化,然后就可以使用vsnprintf函数将文本信息和可变参数以特定的形式输出到缓冲区中,这里的特殊形式就是%d对应的是整形%f对应的是浮点型等等等就和printf函数一样,vsnprintf的参数如下:

第一个参数表示往哪个缓冲区输出,第二个参数表示大小是多少,第三个参数表示输出的内容,第四个参数就是可变参数列表,那么这里的代码如下:
void logMessage(int level, const char *format, ...)
{
// [日志等级] [时间戳/时间] [pid] [messge]
// [WARNING] [2023-05-11 18:09:08] [123] [创建socket失败]
#define NUM 1024
char logprefix[NUM];
snprintf(logprefix, sizeof(logprefix), "[%s][%ld][pid: %d]",
to_levelstr(level), (long int)time(nullptr), getpid());
char logcontent[NUM];
va_list arg;
va_start(arg, format);
vsnprintf(logcontent, sizeof(logcontent), format, arg)
}
;
然后我们就可以根据level的等级选着对应的打开文件,将两个缓冲区的内容按照顺序输出到文件中:
void logMessage(int level, const char *format, ...)
{
#define NUM 1024
char logprefix[NUM];
snprintf(logprefix, sizeof(logprefix), "[%s][%ld][pid: %d]",
to_levelstr(level), (long int)time(nullptr), getpid());
char logcontent[NUM];
va_list arg;
va_start(arg, format);
vsnprintf(logcontent, sizeof(logcontent), format, arg);
// std::cout << logprefix << logcontent << std::endl;
FILE *log = fopen(LOG_NORMAL, "a");
FILE *err = fopen(LOG_ERR, "a");
if(log != nullptr && err != nullptr)
{
FILE *curr = nullptr;
if(level == DEBUG || level == NORMAL || level == WARNING) curr = log;
if(level == ERROR || level == FATAL) curr = err;
if(curr) fprintf(curr, "%s%s\n", logprefix, logcontent);
fclose(log);
fclose(err);
}
那么这就是日志发送函数。
日志的测试
我们可以使用下面的代码来进行测试:
int sock=3;
logMessage(NORMAL, "accept a new link success, get new sock: %d", sock); // ?
logMessage(DEBUG, "accept error, next");
logMessage(WARNING, "accept error, next");
logMessage(FATAL, "accept error, next");
logMessage(NORMAL, "accept error, next");
logMessage(NORMAL, "accept a new link success, get new sock: %d", sock); // ?
logMessage(DEBUG, "accept error, next");
logMessage(WARNING, "accept error, next");
logMessage(FATAL, "accept error, next");
logMessage(NORMAL, "accept error, next");
logMessage(NORMAL, "accept a new link success, get new sock: %d", sock); // ?
logMessage(DEBUG, "accept error, next");
logMessage(WARNING, "accept error, next");
logMessage(FATAL, "accept error, next");
logMessage(NORMAL, "accept error, next");
代码的运行结果如下:

log.error中全是FATAL类型的错误
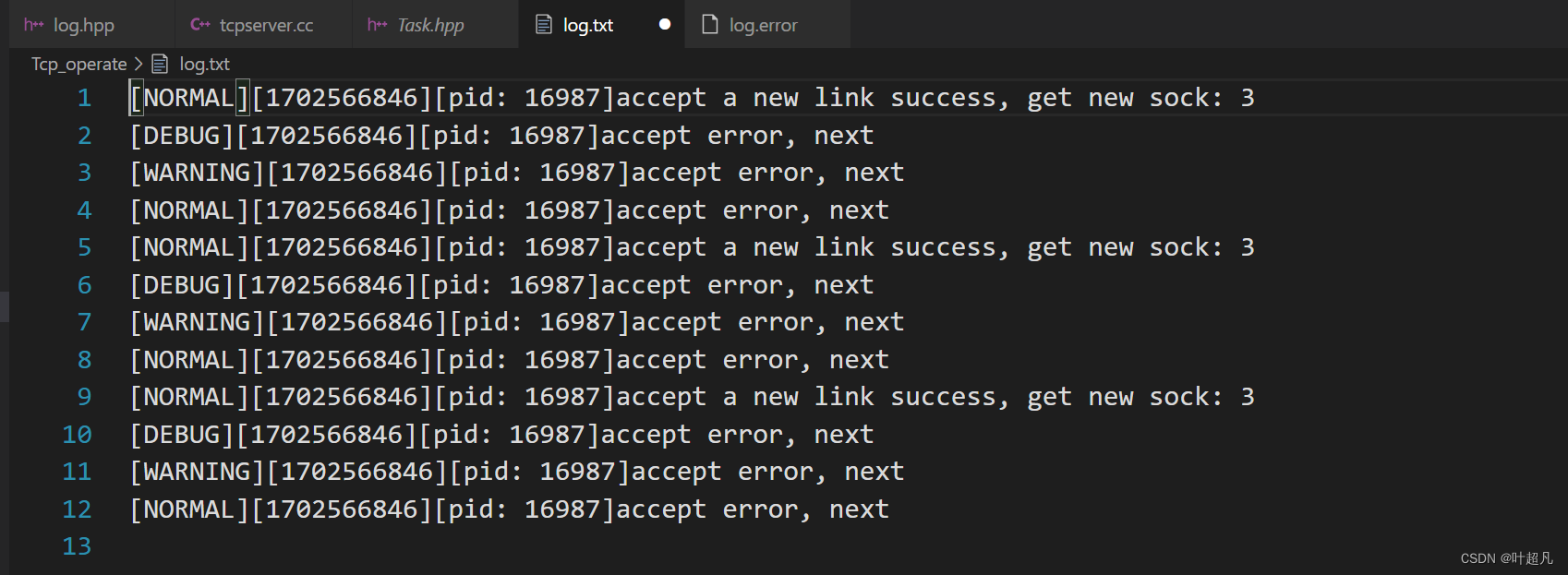
log.txt中全是NORMAL,WARNING,DEBUG类型的错误,那么这就本篇文章的全部内容。





![【单调栈]LeetCode84: 柱状图中最大的矩形](https://img-blog.csdnimg.cn/f95ddae62a4e43a68295601c723f92fb.gif#pic_center)