目录
一、代码作用(rpn_function.py)
二、代码解析
2.1 RPNHead类
2.2 AnchorsGenerator类
2.2.1 初始化函数__init__
2.2.2 正向传播过程 forward
2.2.3 set_cell_anchors生成anchors模板
2.2.4 generate_anchors生成anchors
2.2.5 cached_grid_anchors
2.2.6 grid_anchors
一、代码作用(rpn_function.py)
如何利用backbone生成的预测特征层来进行目标分数、目标边界框边界的预测以及如何利用AnchorGeneraror生成anchor。
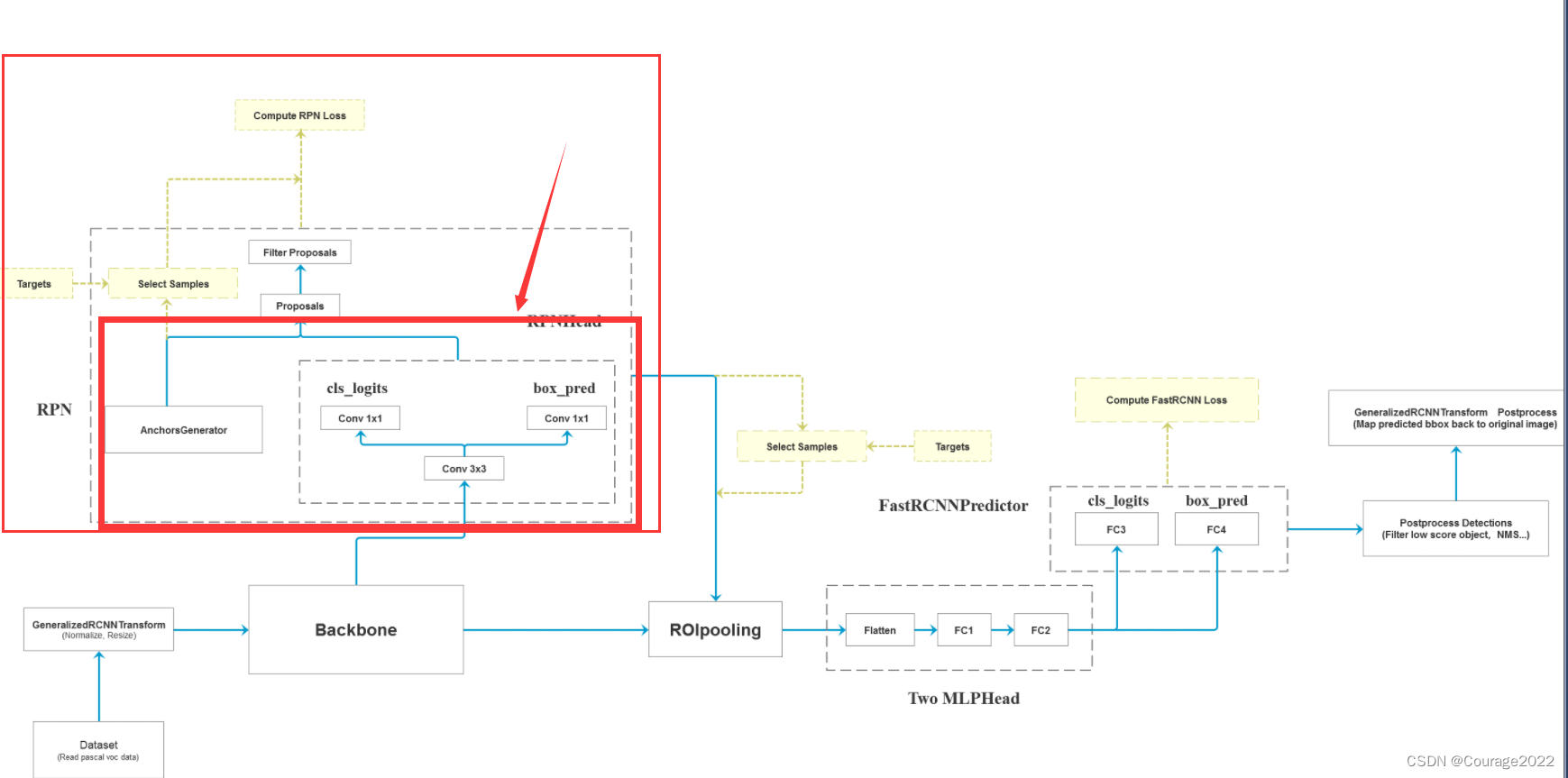
二、代码解析
2.1 RPNHead类
class RPNHead(nn.Module): """ add a RPN head with classification and regression 通过滑动窗口计算预测目标概率与bbox regression参数 Arguments: in_channels: number of channels of the input feature num_anchors: number of anchors to be predicted """ def __init__(self, in_channels, num_anchors): super(RPNHead, self).__init__() #定义三个卷积层 # 3x3 滑动窗口 输入特征矩阵的channel 输出特征矩阵的channel self.conv = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1) # 计算预测的目标分数(这里的目标只是指前景或者背景) self.cls_logits = nn.Conv2d(in_channels, num_anchors, kernel_size=1, stride=1) # 计算预测的目标bbox regression参数 self.bbox_pred = nn.Conv2d(in_channels, num_anchors * 4, kernel_size=1, stride=1) for layer in self.children(): if isinstance(layer, nn.Conv2d): torch.nn.init.normal_(layer.weight, std=0.01) torch.nn.init.constant_(layer.bias, 0) #x是特征矩阵 通过backbone生成的预测特征层 def forward(self, x): # type: (List[Tensor]) -> Tuple[List[Tensor], List[Tensor]] logits = [] bbox_reg = [] for i, feature in enumerate(x): t = F.relu(self.conv(feature)) logits.append(self.cls_logits(t)) bbox_reg.append(self.bbox_pred(t)) return logits, bbox_reg在初始化函数中我们定义三个卷积层:
第一个卷积层conv 的滑动窗口大小是
的,对应着图中的滑动窗口。
输入特征矩阵的channels是我们传入的值,我们令输出的特征矩阵的channels = 输入的特征矩阵的channels,步距和padding均为1。
后面两个卷积层cls_logits、bbox_pred 对应着anchor前景背景分数预测器以及目标回归框的预测器。然后初始化三个卷积层。
我们看看正向传播过程:
输入的
就是我们的特征矩阵(经过backbone所生成的预测特征层),我们遍历每个预测特征层enumerate(x),将每个预测特征层通过
,将输出特征矩阵分别通过目标分数预测器cls_logits和目标边界框预测器bbox_pred,将结果分别添加到logits和bbox_reg列表中。

2.2 AnchorsGenerator类
2.2.1 初始化函数__init__
#anchor 的 scale ... 每个anchor所采用的比例 #tran_mobile_net def __init__(self, sizes=(128, 256, 512), aspect_ratios=(0.5, 1.0, 2.0)): super(AnchorsGenerator, self).__init__() #判断size的元素是否是list/tuple 在train_res50中调用 if not isinstance(sizes[0], (list, tuple)): # TODO change this sizes = tuple((s,) for s in sizes) if not isinstance(aspect_ratios[0], (list, tuple)): aspect_ratios = (aspect_ratios,) * len(sizes) assert len(sizes) == len(aspect_ratios) self.sizes = sizes self.aspect_ratios = aspect_ratios self.cell_anchors = None self._cache = {}我们传入了两个参数,sizes就是anchor的scale,aspect_ratios是每个anchor所采用的不同的比例。
我们看看train_mobilenetv2.py脚本中传入的参数:
def create_model(num_classes): # https://download.pytorch.org/models/vgg16-397923af.pth # 如果使用vgg16的话就下载对应预训练权重并取消下面注释,接着把mobilenetv2模型对应的两行代码注释掉 # vgg_feature = vgg(model_name="vgg16", weights_path="./backbone/vgg16.pth").features # backbone = torch.nn.Sequential(*list(vgg_feature._modules.values())[:-1]) # 删除features中最后一个Maxpool层 # backbone.out_channels = 512 # https://download.pytorch.org/models/mobilenet_v2-b0353104.pth backbone = MobileNetV2(weights_path="./backbone/mobilenet_v2.pth").features backbone.out_channels = 1280 # 设置对应backbone输出特征矩阵的channels anchor_generator = AnchorsGenerator(sizes=((32, 64, 128, 256, 512),), aspect_ratios=((0.5, 1.0, 2.0),)) #有序字典 我们设置图片的key=0 roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'], # 在哪些特征层上进行roi pooling output_size=[7, 7], # roi_pooling输出特征矩阵尺寸 sampling_ratio=2) # 采样率 model = FasterRCNN(backbone=backbone, num_classes=num_classes, rpn_anchor_generator=anchor_generator, box_roi_pool=roi_pooler) return modelsizes传入的是一个tuple类型,其中每个元素又是一个tuple类型
,aspect_ratios传入的也是一个元组
。
我们首先判断sizes里面的元素是不是list或者tuple类型,不满足。
我们接着判断aspect_ratios里面的元素是不是list或者tuple类型,不满足。
判断两元素个数是否相等(都有一个元素),满足。
对于train_res50_fpn.py脚本来说,没有传入AnchorGenerator这个参数的,在搭建时按默认值进行生成,在faster_rcnn_framework.py脚本中:
# 若anchor生成器为空,则自动生成针对resnet50_fpn的anchor生成器 #在五个预测特征层上预测 针对每个预测特征层会使用 if rpn_anchor_generator is None: anchor_sizes = ((32,), (64,), (128,), (256,), (512,)) aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes) rpn_anchor_generator = AnchorsGenerator( anchor_sizes, aspect_ratios )它在搭建时会以默认形式进行生成,anchor_sizes 是tuple类型,tuple的每个元素又是个tuple,每个tuple中只有一个int类型,对应着每个scale,对五个预测特征层进行预测。
最后我们将这些都赋值给我们的类变量。
2.2.2 正向传播过程 forward
def forward(self, image_list, feature_maps): # type: (ImageList, List[Tensor]) -> List[Tensor] # 获取每个预测特征层的尺寸(height, width) grid_sizes = list([feature_map.shape[-2:] for feature_map in feature_maps]) # 获取输入图像的height和width image_size = image_list.tensors.shape[-2:] # 获取变量类型和设备类型 dtype, device = feature_maps[0].dtype, feature_maps[0].device # one step in feature map equate n pixel stride in origin image # 计算特征层上的一步等于原始图像上的步长 # 图像大小 / 特征矩阵大小 strides = [[torch.tensor(image_size[0] // g[0], dtype=torch.int64, device=device), torch.tensor(image_size[1] // g[1], dtype=torch.int64, device=device)] for g in grid_sizes] # 根据提供的sizes和aspect_ratios生成anchors模板 self.set_cell_anchors(dtype, device) #将anchor模板运用到原图上 # 计算/读取所有anchors的坐标信息(这里的anchors信息是映射到原图上的所有anchors信息,不是anchors模板) # 得到的是一个list列表,对应每张预测特征图映射回原图的anchors坐标信息 anchors_over_all_feature_maps = self.cached_grid_anchors(grid_sizes, strides) anchors = torch.jit.annotate(List[List[torch.Tensor]], []) # 遍历一个batch中的每张图像 for i, (image_height, image_width) in enumerate(image_list.image_sizes): anchors_in_image = [] # 遍历每张预测特征图映射回原图的anchors坐标信息 for anchors_per_feature_map in anchors_over_all_feature_maps: anchors_in_image.append(anchors_per_feature_map) anchors.append(anchors_in_image) # 将每一张图像的所有预测特征层的anchors坐标信息拼接在一起 # anchors是个list,每个元素为一张图像的所有anchors信息 anchors = [torch.cat(anchors_per_image) for anchors_per_image in anchors] # Clear the cache in case that memory leaks. self._cache.clear() return anchors我们传入的参数为image_list, feature_maps。image_list就是一个ImageList的类,我们上篇博客中有说,它存储的是我们在预处理中将图片打包成的一个一个batch(每张图片大小相等)和image_size是每张图片缩放后对应的大小。
Faster RCNN网络源码解读(Ⅴ) --- GeneralizedRCNNTransform图像初始化代码解析
https://blog.csdn.net/qq_41694024/article/details/128498697 feature_maps对应着预测特征层的信息,它的类型是List[Tensor]。list元素的个数是预测特征层的个数。
我们用grid_sizes获取每个预测特征层的尺寸(height, width)。
我们用image_size 获取图像的大小信息。
计算特征层上的一步等于原始图像上的步长,方法是遍历grid_sizes(每个预测特征层的长宽),将图像的大小除以特征矩阵的大小得到了一个缩放因子,可以找到原图的每个点对应于特征图的每一个点了。组合成一个list(长,宽)缩放因子存放在stride变量中。
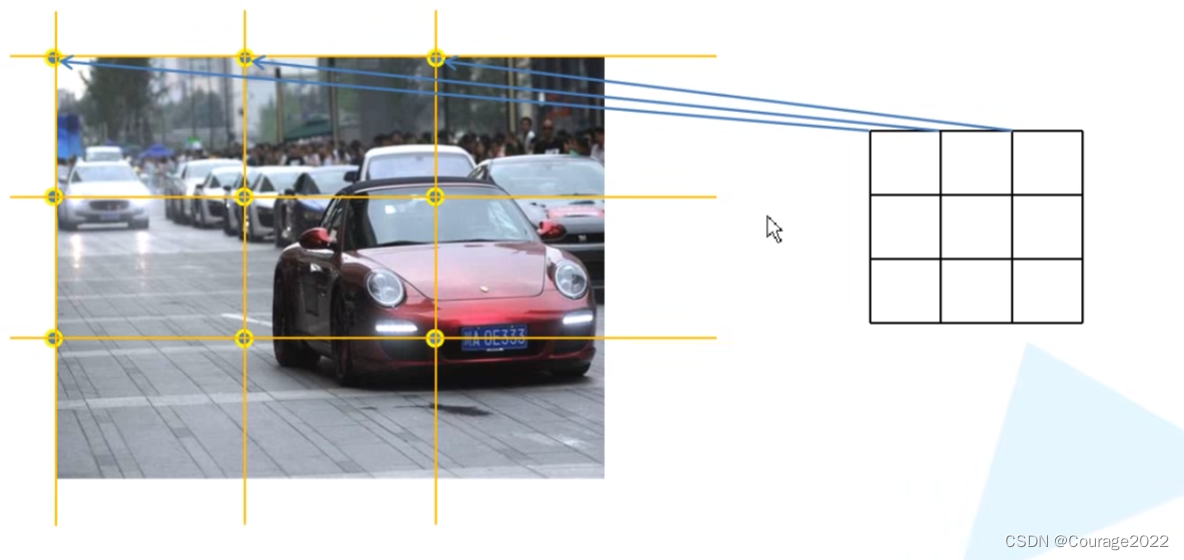
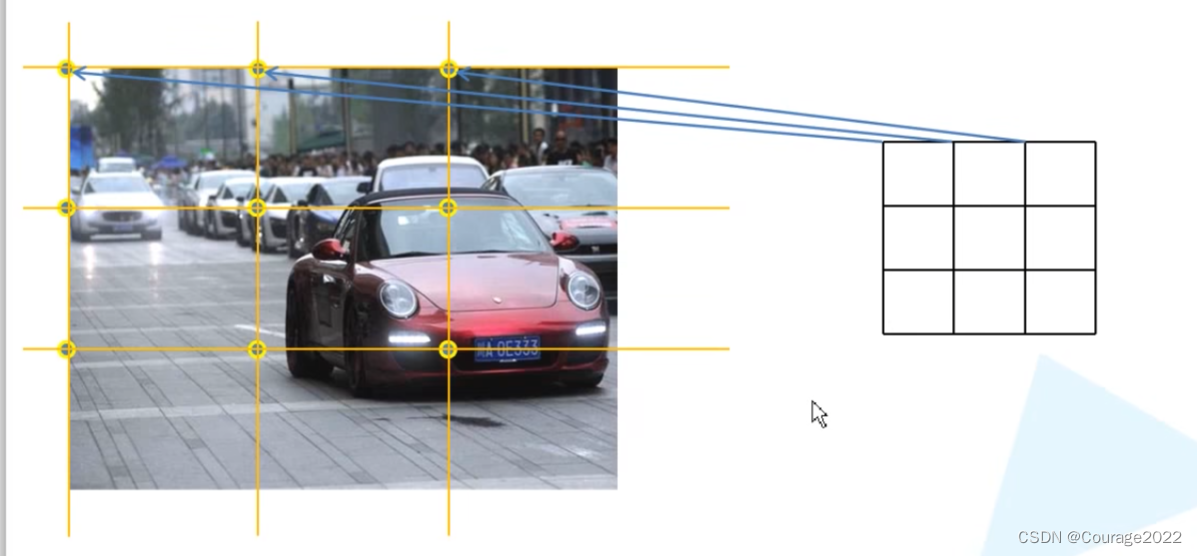
假如我们得到一个3*3的预测特征层,预测特征层的每个cell在原图上是怎么计算呢? 我们将原图均分成三等份。算出尺寸缩放因子即可找到每个坐标。
根据提供的sizes和aspect_ratios生成anchors模板。(2.2.3节)。这里模板的高度宽度对应的都是原图上的尺度。
接下来我们要利用我们的anchors模板利用到原图上,通过cached_grid_anchors实现。(2.2.5节),传入的参数为grid_sizes(每个预测特征层的尺寸)和strides(图像大小 / 特征矩阵大小)。
anchors_over_all_feature_maps 存储的是anchors在原图上的所有坐标信息。
我们遍历batch中的每张图片。
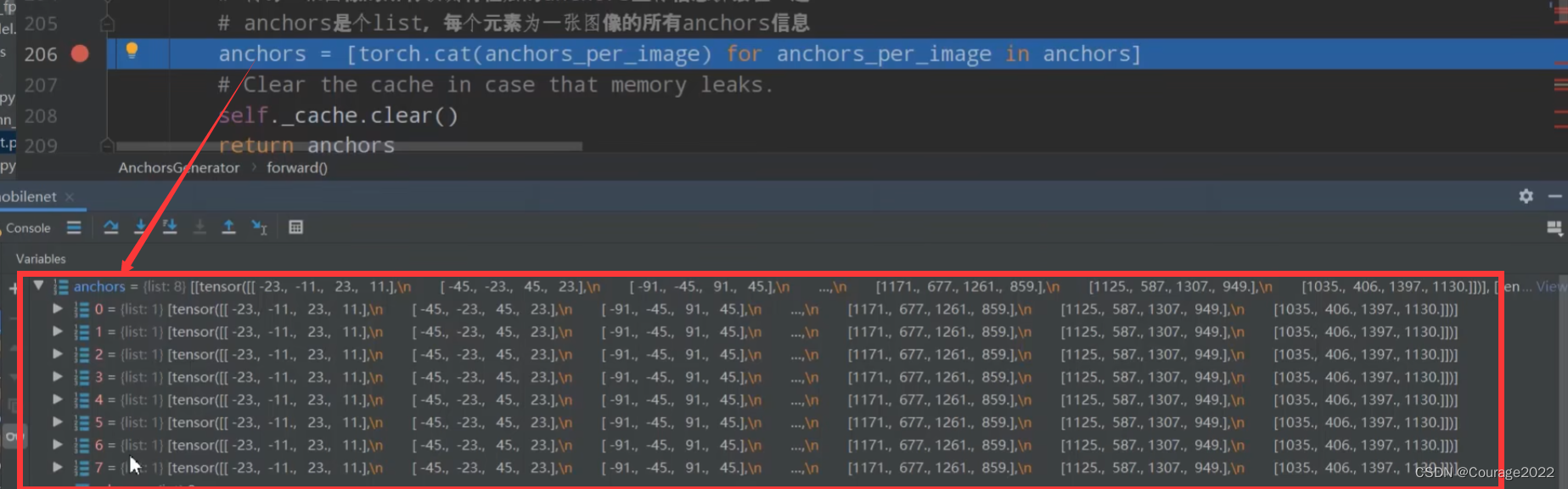
# 遍历一个batch中的每张图像 for i, (image_height, image_width) in enumerate(image_list.image_sizes): anchors_in_image = [] # 遍历每张预测特征图映射回原图的anchors坐标信息 for anchors_per_feature_map in anchors_over_all_feature_maps: anchors_in_image.append(anchors_per_feature_map) anchors.append(anchors_in_image) # 将每一张图像的所有预测特征层的anchors坐标信息拼接在一起 # anchors是个list,每个元素为一张图像的所有anchors信息 anchors = [torch.cat(anchors_per_image) for anchors_per_image in anchors] # Clear the cache in case that memory leaks. self._cache.clear() return anchors
这里anchors一共有八个元素,因为我们的batch大小是8。每个元素中又是一个list,list元素的个数就是每张图片预测特征层的个数。shape为每个预测特征层上生成的anchors的信息。
经过cat之后由list换为tensor了。
返回anchors。

2.2.3 set_cell_anchors生成anchors模板
def set_cell_anchors(self, dtype, device): # type: (torch.dtype, torch.device) -> None #我们类初始化的时候设置为none 第一次调用为空 if self.cell_anchors is not None: cell_anchors = self.cell_anchors assert cell_anchors is not None # suppose that all anchors have the same device # which is a valid assumption in the current state of the codebase if cell_anchors[0].device == device: return # 根据提供的sizes和aspect_ratios生成anchors模板 # anchors模板都是以(0, 0)为中心的anchor cell_anchors = [ #生成anchor self.generate_anchors(sizes, aspect_ratios, dtype, device) #size元素的个数 = 预测特征层的个数 ,有几个特征层就会生成多少个anchor模板,将不同层的anchor组合成一个列表 for sizes, aspect_ratios in zip(self.sizes, self.aspect_ratios) ] #传给类变量 self.cell_anchors = cell_anchors先判断self.cell_anchors类变量是否为空,因为在初始化的时候我们设置其为空,因此执行下面的代码。
通过for循环遍历self.sizes, self.aspect_ratios,传入generate_anchors函数中生成anchors。(2.2.4节)
self.sizes的元素个数就是预测特征层的个数,他有几个预测特征层就会生成几个anchors模板,将不同层的anchors模板组合成一个列表放入cell_anchors变量中。传给类变量self.cell_anchors,其中存放着anchors模板。是[n*4]大小的,以(0,0)为中心,四个坐标是左上角的
坐标及右下角的
2.2.4 generate_anchors生成anchors
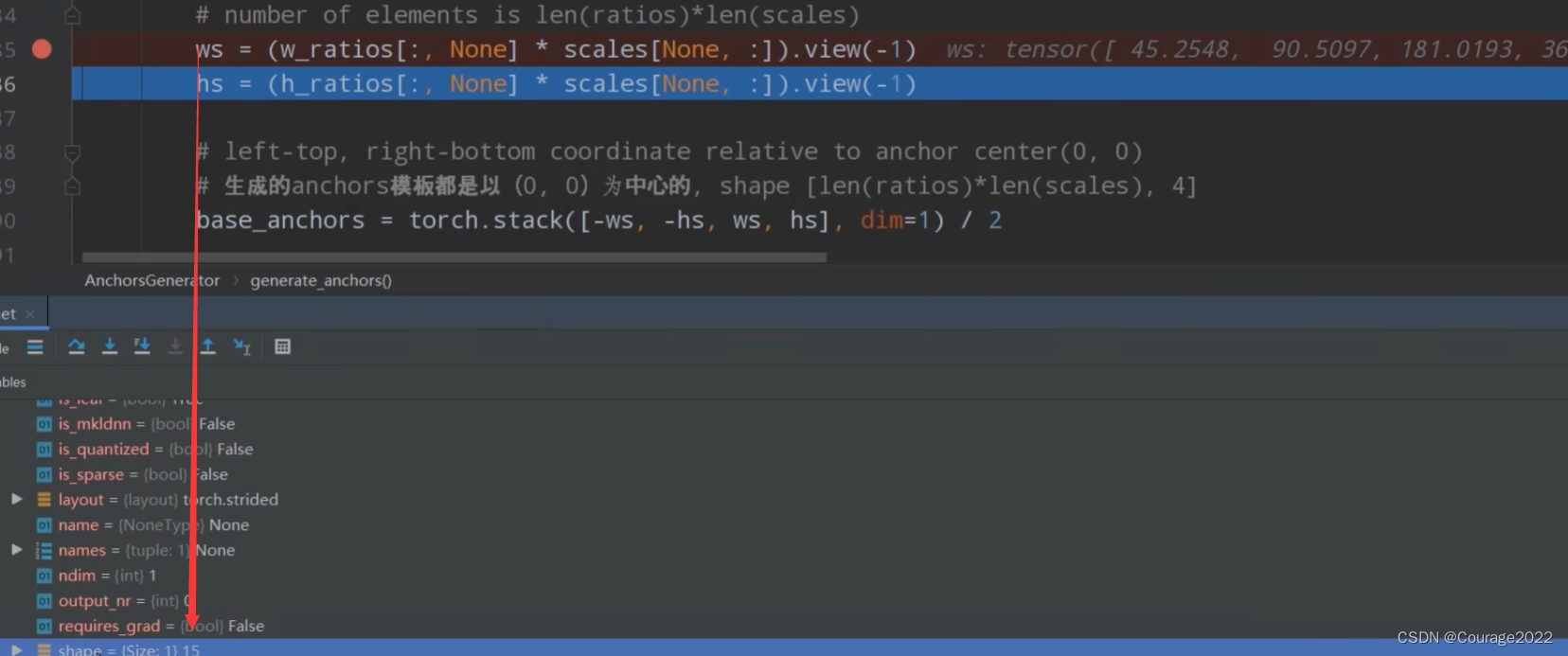
def generate_anchors(self, scales, aspect_ratios, dtype=torch.float32, device=torch.device("cpu")): # type: (List[int], List[float], torch.dtype, torch.device) -> Tensor """ compute anchor sizes Arguments: scales: sqrt(anchor_area) aspect_ratios: h/w ratios dtype: float32 device: cpu/gpu """ scales = torch.as_tensor(scales, dtype=dtype, device=device) aspect_ratios = torch.as_tensor(aspect_ratios, dtype=dtype, device=device) #开根号得到每一个anchor的高度、宽度对应的乘法因子 h_ratios = torch.sqrt(aspect_ratios) w_ratios = 1.0 / h_ratios # [r1, r2, r3]' * [s1, s2, s3] # number of elements is len(ratios)*len(scales) #得到每一个anchor的宽度、高度值 战平 ws = (w_ratios[:, None] * scales[None, :]).view(-1) hs = (h_ratios[:, None] * scales[None, :]).view(-1) # left-top, right-bottom coordinate relative to anchor center(0, 0) # 生成的anchors模板都是以(0, 0)为中心的, shape [len(ratios)*len(scales), 4] base_anchors = torch.stack([-ws, -hs, ws, hs], dim=1) / 2 return base_anchors.round() # round 四舍五入我们得到高度、宽度对应的乘法因子h_ratios 、w_ratios 。
计算每个anchors对应的高度和宽度ws和hs并将其展平处理。
这里有五个scale和三个ratios,会生成十五个anchors。
ws对应着一个向量,其中有15个元素。对应着15个anchors的宽度。
最后以
为中心得到一个anchor的模板,左上角宽度是-宽度/2,y坐标是-高度/2,右下角坐标是高度、宽度除以2。我们再将其在维度为1上进行拼接。
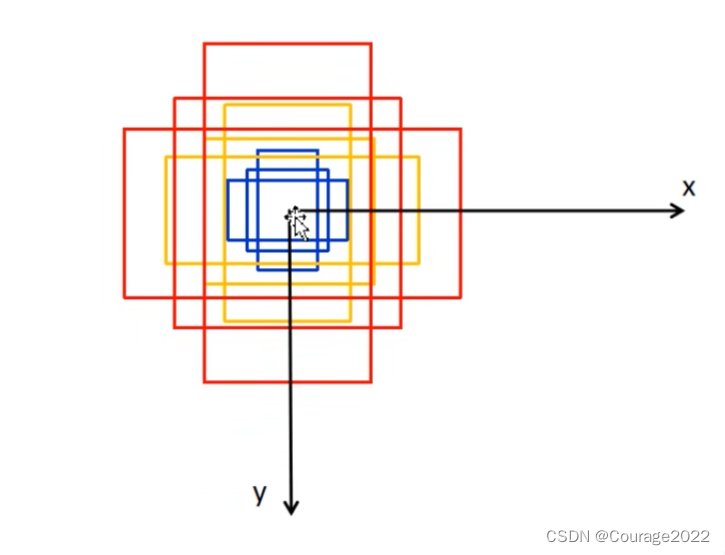
这里的base_anchor就是15*4的tensor, 15个anchor的左上角的坐标及右下角的坐标。
如上图的结构。返回给上层调用。


2.2.5 cached_grid_anchors
def cached_grid_anchors(self, grid_sizes, strides): # type: (List[List[int]], List[List[Tensor]]) -> List[Tensor] """将计算得到的所有anchors信息进行缓存""" key = str(grid_sizes) + str(strides) # self._cache是字典类型 if key in self._cache: return self._cache[key] anchors = self.grid_anchors(grid_sizes, strides) #存放安装好的anchors self._cache[key] = anchors return anchors首先我们将我们的grid_sizes和strides转换成字符形式。由于在初始化函数中我们将self._cache类内变量设为空,因此这句代码不执行。
我们再将grid_sizes, strides传给我们的grid_anchors函数中。(2.2.6节)
我们得到的anchors是所有预测特征层映射回原图上所生成的anchors信息存储在self._cache[key] 这个字典里。字典的key是str(grid_sizes) + str(strides),返回这个anchors。
2.2.6 grid_anchors
# For every combination of (a, (g, s), i) in (self.cell_anchors, zip(grid_sizes, strides), 0:2), # output g[i] anchors that are s[i] distance apart in direction i, with the same dimensions as a. def grid_anchors(self, grid_sizes, strides): # type: (List[List[int]], List[List[Tensor]]) -> List[Tensor] """ anchors position in grid coordinate axis map into origin image 计算预测特征图对应原始图像上的所有anchors的坐标 Args: grid_sizes: 预测特征矩阵的height和width strides: 预测特征矩阵上一步对应原始图像上的步距 """ anchors = [] cell_anchors = self.cell_anchors assert cell_anchors is not None # 遍历每个预测特征层的grid_size,strides和cell_anchors for size, stride, base_anchors in zip(grid_sizes, strides, cell_anchors):. #每一个预测特征层的高度和宽度 grid_height, grid_width = size #每一个预测特征层cell对应原图上的高度和宽度的尺度信息 stride_height, stride_width = stride device = base_anchors.device # For output anchor, compute [x_center, y_center, x_center, y_center] # shape: [grid_width] 对应原图上的x坐标(列) shifts_x = torch.arange(0, grid_width, dtype=torch.float32, device=device) * stride_width # shape: [grid_height] 对应原图上的y坐标(行) shifts_y = torch.arange(0, grid_height, dtype=torch.float32, device=device) * stride_height # 计算预测特征矩阵上每个点对应原图上的坐标(anchors模板的坐标偏移量) # torch.meshgrid函数分别传入行坐标和列坐标,生成网格行坐标矩阵和网格列坐标矩阵 # shape: [grid_height, grid_width] #shift_y 25 shift_x 34个元素 代表当前预测特征层的高度和宽度为35*24 shift_y, shift_x = torch.meshgrid(shifts_y, shifts_x) shift_x = shift_x.reshape(-1) shift_y = shift_y.reshape(-1) # 计算anchors坐标(xmin, ymin, xmax, ymax)在原图上的坐标偏移量 # shape: [grid_width*grid_height, 4] #850*4 850是预测特征层的个数 4是 shifts = torch.stack([shift_x, shift_y, shift_x, shift_y], dim=1) # For every (base anchor, output anchor) pair, # offset each zero-centered base anchor by the center of the output anchor. # 将anchors模板与原图上的坐标偏移量相加得到原图上所有anchors的坐标信息(shape不同时会使用广播机制) 850*15*4 #一共有850个cell 每个cell生成15个anchor shifts_anchor = shifts.view(-1, 1, 4) + base_anchors.view(1, -1, 4) anchors.append(shifts_anchor.reshape(-1, 4)) #12750*4 return anchors # List[Tensor(all_num_anchors, 4)]grid_sizes存放着每个预测特征层的尺寸(高宽)。
strides存放图像大小 / 预测特征层矩阵大小。
我们将之前计算出的anchors模板赋值给cell_anchors变量。
遍历每个预测特征层的grid_size,strides和cell_anchors:
每一个预测特征层的高度和宽度放入变量grid_height, grid_width中。
每一个预测特征层cell对应原图上的高度和宽度的尺度信息stride_height, stride_width
通过torch.arange方法生成一个(0, grid_width)的序列,再将其乘stride_width。
这里就好比我们在长度和宽度上生成一个序列,以右图宽度为例。假设这个cell的宽度为3,它生成的序列就是
,我们知道每个cell对应原图的尺寸 stride_width,我们将
轴坐标。
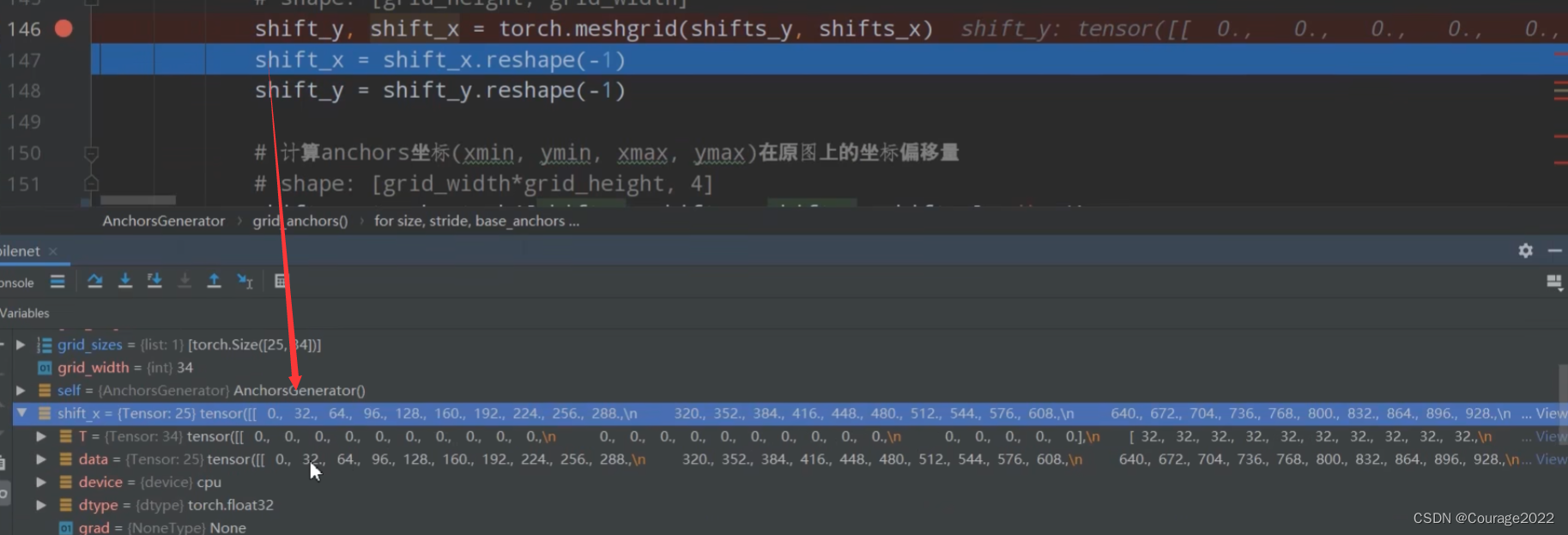
于是shifts_x、shifts_y变量存储着cell的点对应原图上的坐标。
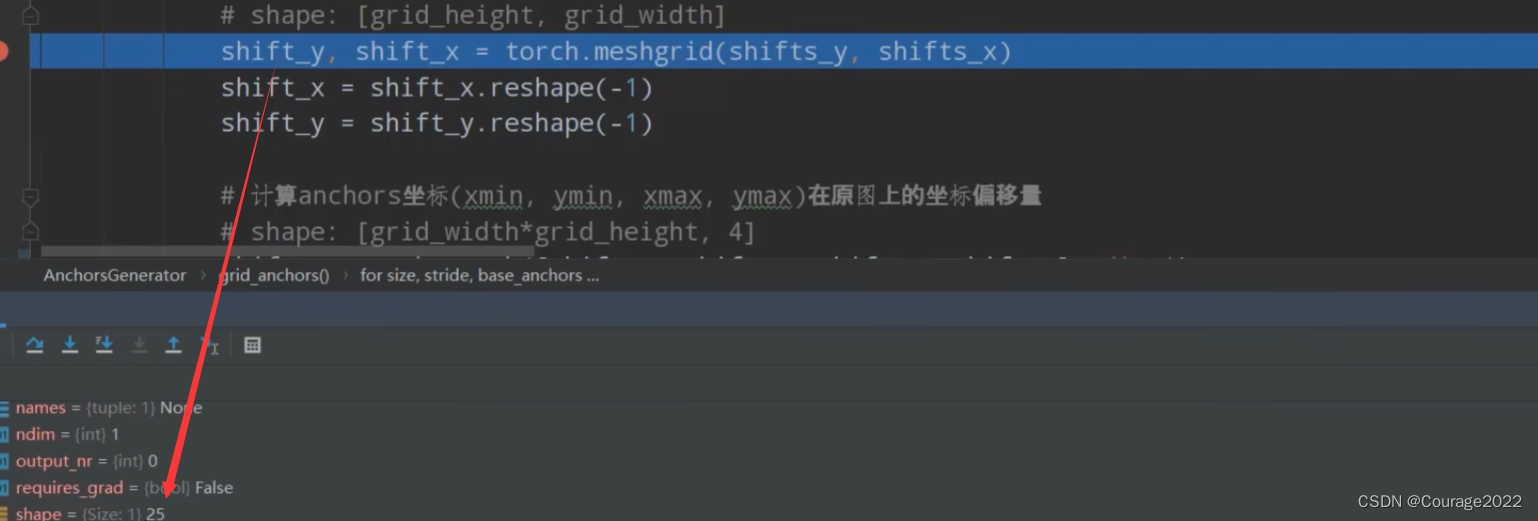
我们再通过torch.meshgrid方法将我们得到的shifts_x、shifts_y得到预测特征层每个点对应原图的一个坐标
shifts_y是一个拥有25个元素的一个向量。
shifts_x是一个拥有34个元素的一个向量。
说明我们的预测特征层的高度和宽度分别对应25和34。
我们最终得到的shifts_x是一个
的向量,对应预测特征层对应的每一个
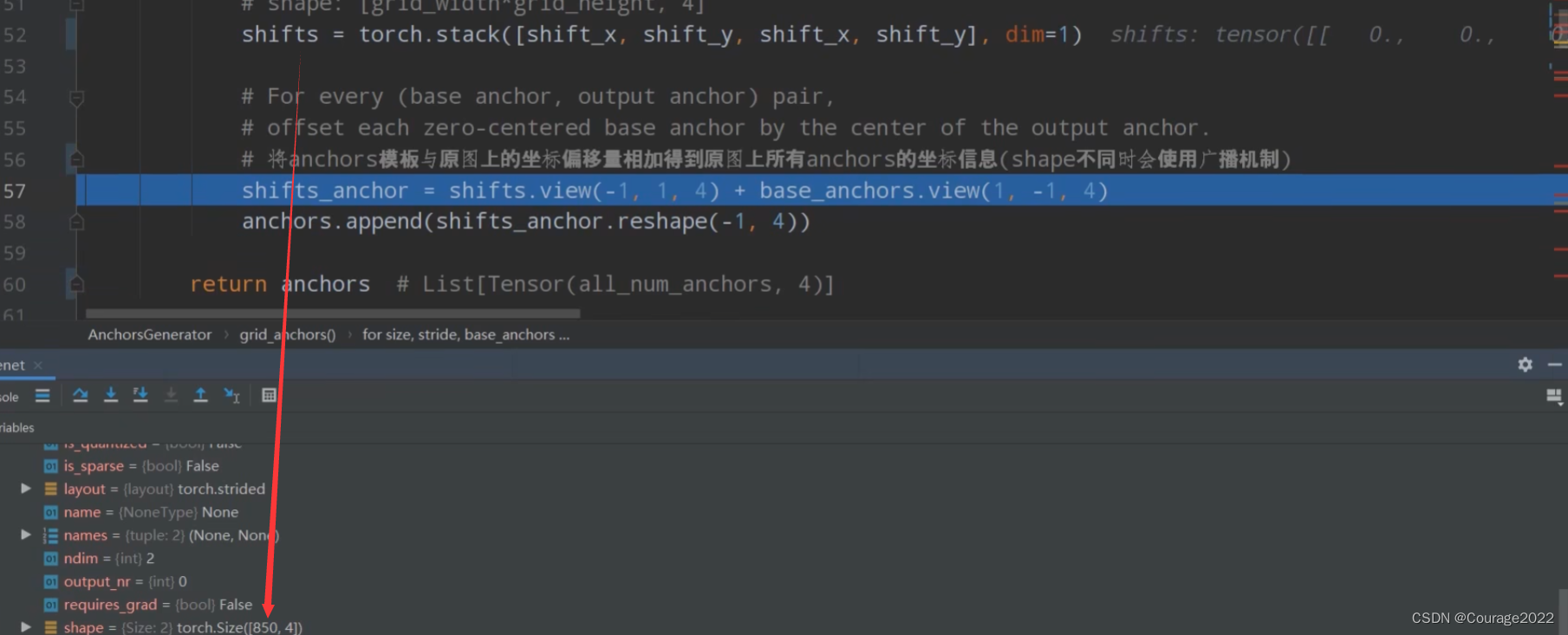
shifts = torch.stack([shift_x, shift_y, shift_x, shift_y], dim=1),在维度1上进行拼接,我们设置断点看看shifts的格式。
是一个[850*4]的向量,对应着预测特征层上的cell个数,4就是左上角坐标和右下角坐标。
我们之前得到了anchors模板,它是以
shifts_anchor = shifts.view(-1, 1, 4) + base_anchors.view(1, -1, 4)
这就是这行代码的作用。
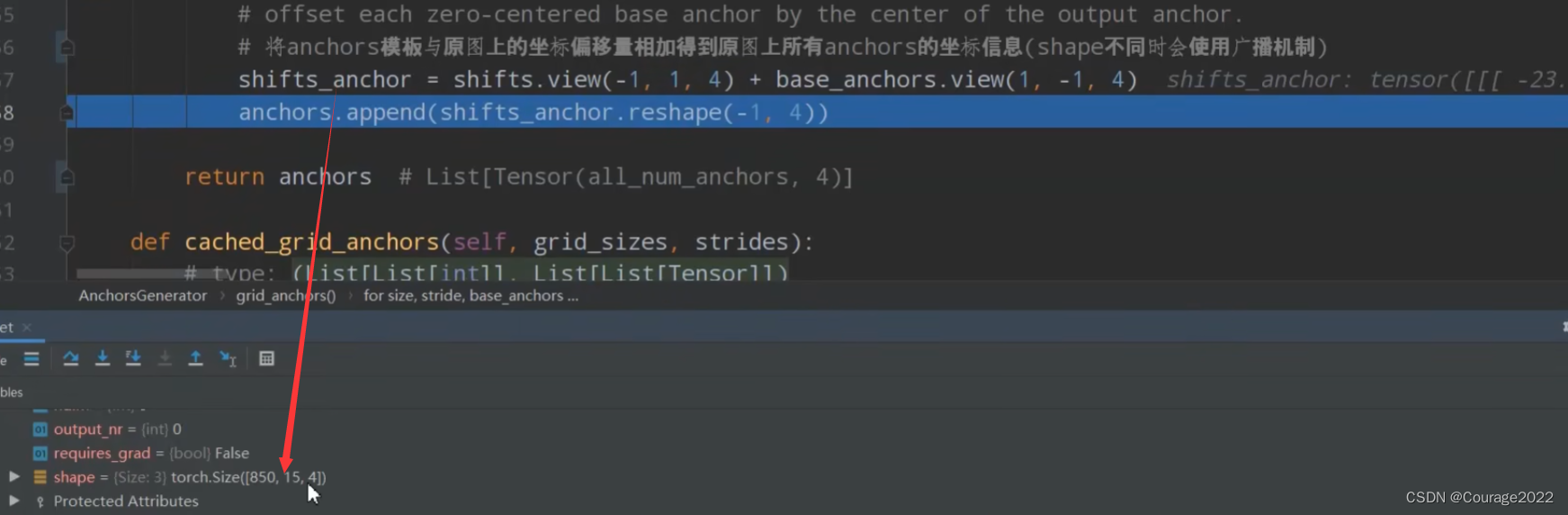
shifts_anchor的shape我们调试如下:
这里的850对应着feature一共有850个cell(
进行reshape处理,最后返回一个列表,列表的元素个数为预测特征层的个数,我们拿mobilenet为例其只有一个预测特征层因此其size为1。
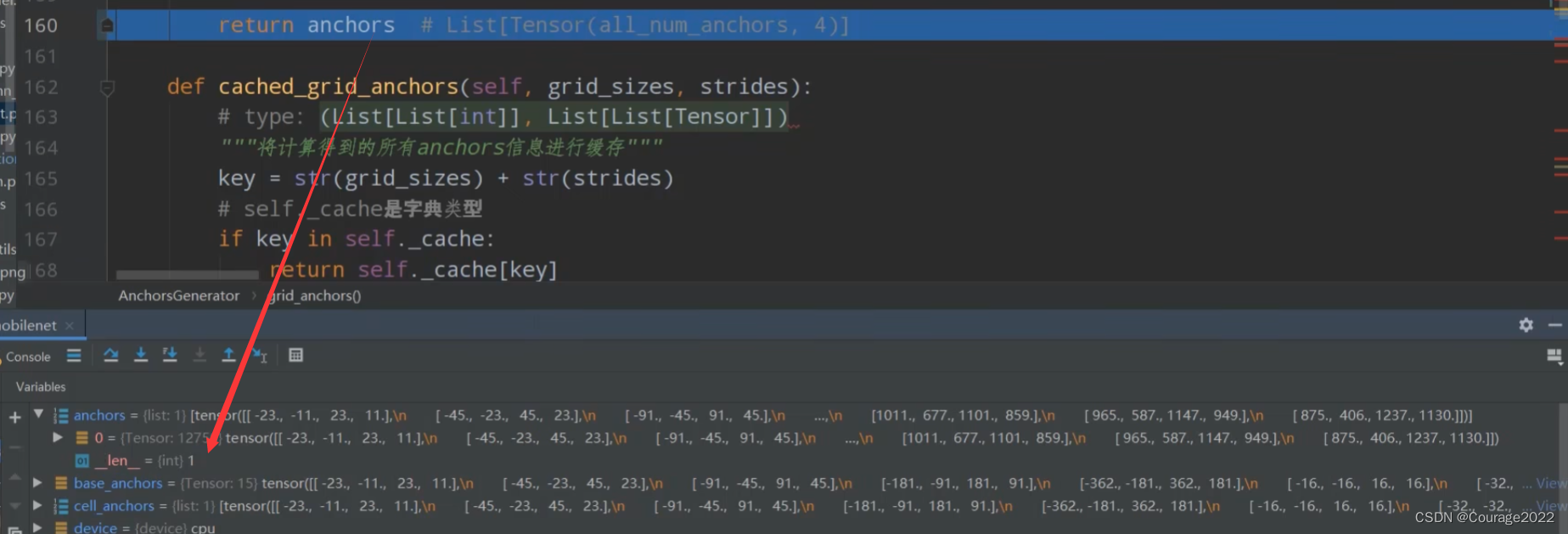
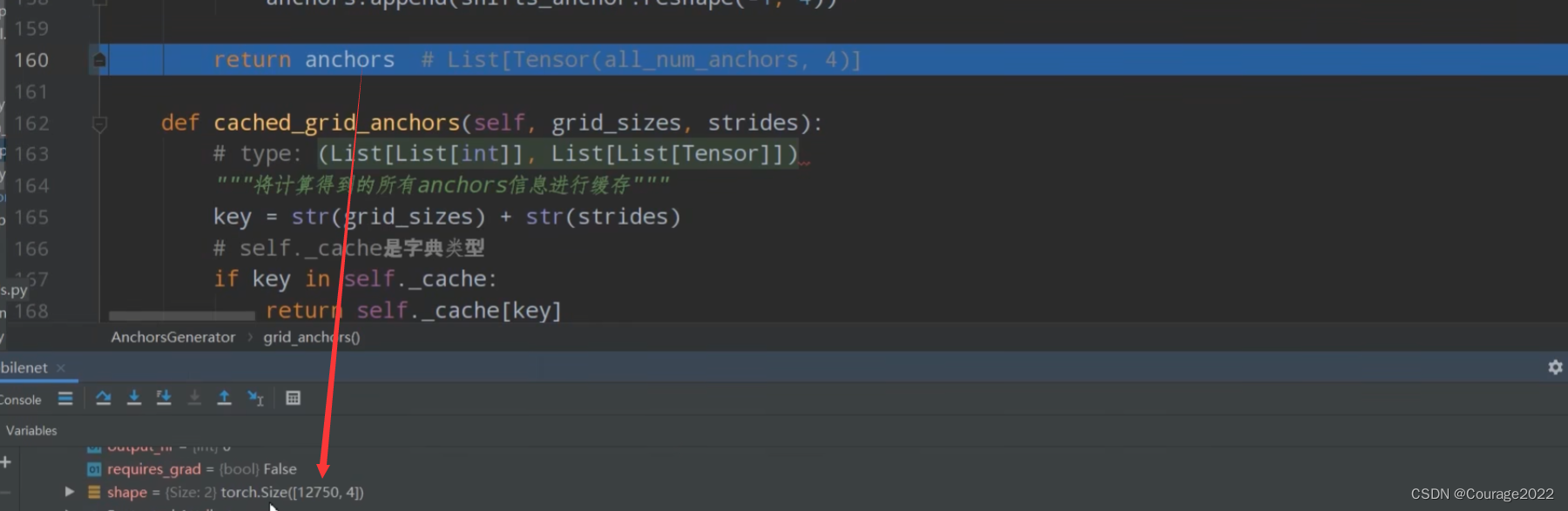
其shape:
其每个元素为每个预测特征层的每个cell映射会原图上生成的所有的anchors的坐标信息。返回这个信息。





![buuctf-misc-[GKCTF 2021]你知道apng吗1](https://img-blog.csdnimg.cn/a53b4ede82b24bc4ac9e0e219518f4b2.png)