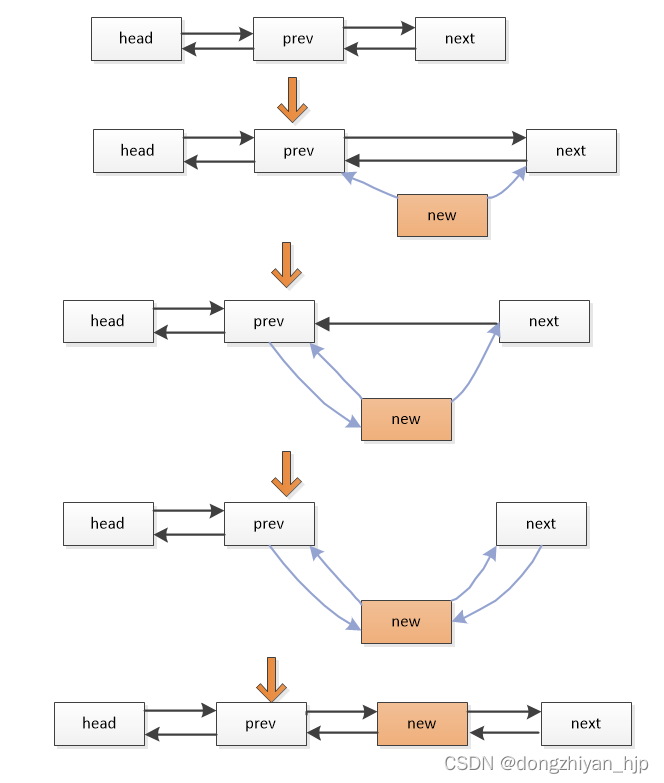
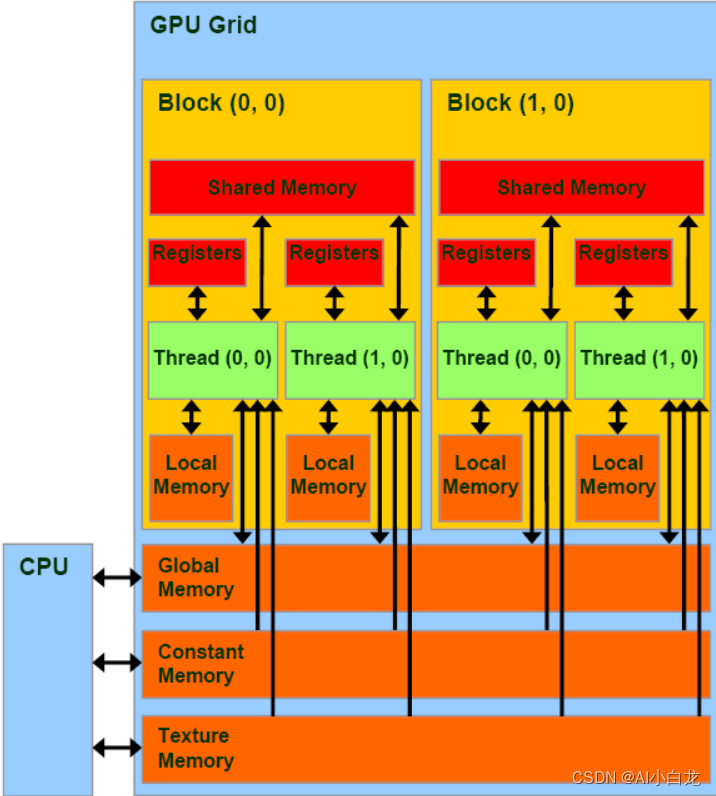
GPU存储结构模型
1.CPU可以读写GPU设备中的Global Memory、Constant Memory以及Texture Memory内存储的内容;主机代码可以把数据传输到设备上,也可以从设备中读取数据;
2.GPU中的线程使用Register、Shared Memory、Local Memory、Global Memory、Constant Memory以及Texture Memory;不同Memory的作用范围是不同的,和线程、block以及grid有关;
线程可以读写Register、Shared Memory、Local Memory和Global Memory;但是只能读Constant Memory和Texture Memory;
Register
寄存器,是GPU片上高速缓存, 执行单元可以以极低的延迟访问寄存器。
寄存器的基本单元式寄存器文件,每个寄存器文件大小为32bit。寄存器变量是每个线程私有的,一旦thread执行结束,寄存器变量就会失效。把寄存器分配给每个线程,而每个线程也只能访问分配给自己的寄存器;
如果寄存器被消耗完,数据将被存储在局部存储器(本地存储器)中。如果每个线程使用了过多的寄存器,或声明了大型结构体或数据,或者编译器无法确定数据的大小,线程的私有数据就有可能被分配到local memory中,一个线程的输入和中间变量将被保存在寄存器或者是局部存储器中。
寄存器是GPU最快的memory,kernel中没有什么特殊声明的自动变量都是放在寄存器中,同样,这些变量都是线程私有的。当数组的索引是constant类型且在编译期能被确定的话,就是内置类型,数组也是放在寄存器中。
寄存器是稀有资源。在Fermi上,每个thread限制最多拥有63个register,Kepler则是255个。让自己的kernel使用较少的register就能够允许更多的block驻留在SM中,也就增加了Occupancy,提升了性能。
Shared Memory
共享存储器,同寄存器一样,都是片上存储器;存储在片上存储器中的变量可以以高度并行的方式高速访问;把共享存储器分配给线程块,同一个块中的所有线程都可以访问共享存储器中的变量,因为这些变量的存储单元已经分配给这个块;
共享存储器是一种用于线程协作的高效方式,方法是共享其中的输入数据和其中的中间计算结果;一般情况下,常用共享存储器来保存全局存储器中在kernel函数的执行阶段中需要频繁使用的那部分数据;
Local Memory
本地存储器,存储位置在于显存上,也就是在局存储器上;当线程使用的寄存器被占满时,数据将被存储在全局存储器中;由于局部存储器中的数据被保存在显存中,而不是片上的寄存器或者缓存中,因此对local memory的访问速度很慢。
Global Memory
全局存储器,通过动态随机访问存储器(Dynamic Random Access Memory,DRAM)实现,这里的DRAM就是通常说的显存,是设备独立的存储空间;
GPU上的计算单元在访问全局存储器时有可能出现长延时(几百个时钟周期)和访问带宽有限的情况;在访问全局存储器的路径也经常发生流量拥塞现象,只容许很少的线程(而非所有线程)继续访问,因此导致一些多核流处理器(Streaming Multiprocessor,SM)处于空闲状态;
Constant Memory
常数存储器,用于存储只读数据,常数变量虽然存在放全局存储器上,单采用缓存提高了访问效率,用于存储需要频繁访问的只读参数;
Texture Memory
纹理存储器
设备存储器内变量的作用域和生命周期
CUDA变量由于处于不同的存储器,则有各自不同的作用域和生存期;
作用域标识了能访问该变量的线程范围:单个线程、块内的所有线程或者网格内所有线程;
1)作用域为单个线程时,每个线程都会创建一个变量的私有副本放在寄存器中,每个线程只能访问其私有版本的变量;2)作用域为块内所有线程时,每个线程块会创建一个共享变量,由块内线程共享;3)作用域为网格内所有线程时,变量将被存储在全局存储器或者常数存储器中,由kernel生成的所有线程共享;注意,常数存储内的变量由所有网格内的线程共享,常数变量声明位置必须位于任何函数体外;
生命周期指定在程序的哪一段执行时间内变量是可用的:在kernel函数调用期间或在整个应用程序执行期间中。
1)寄存器和本地存储器内的变量生命周期在本线程执行期内,线程执行完成后变量内容不在存在;2)共享存储器内的变量声明在kernel函数中,其生命周期是指kernel函数的运行过程,当kernel函数终止执行时,其共享存储器内的变量内容不再存在;3)常数存储器内的变量的生命周期是整个应用的执行过程;
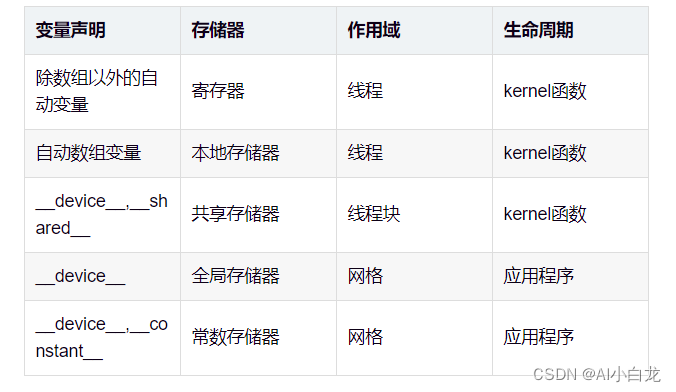
GPU内存结构图:
2. 常用的设备存储API
2.1 操作全局存储器
2.1.1 申请设备内存;
cudaError_t cudaMalloc (void **devPtr, size_t size );
对devPtr内存储的指针分配新的设备内存,size以字节为单位;执行cudaMalloc成功后devPtr内记录的就是分配显存的地址;
下面,分配32个float的设备内存空间 ;
float *d_a;
int nBytes = 32 * sizeof(float);
cudaMalloc((void **)&d_a, nBytes);
2.1.2 释放设备内存
由cudaMalloc申请的内存,由cudaFree释放;
cudaError_t CUDARTAPI cudaFree(void *devPtr);
2.1.3 主机和设备之间的数据拷贝
cudaMemcpy用于在主机(Host)和设备(Device)之间拷贝数据;
cudaError_t cudaMemcpy( void* dst,const void* src,size_t count,enum cudaMemcpyKind kind )
从src指向的存储器区域中将count个字节拷贝到dst指向的存储器区域中,kind决定了数据的拷贝方向;
cudaMemcpyHostToHost
cudaMemcpyHostToDevice: 由主机内存拷贝到设备内存;
cudaMemcpyDeviceToHost: 由设备内存拷贝到主机内存;
cudaMemcpyDeviceToDevice
2.1.4 初始化内存块
使用cudaMemset初始化设备内存的值;
cudaError_t cudaMemset(void* devPtr,int value,size_t count);
使用固定字节值value来填充devPtr所指向存储器区域的前count个字节;
2.2 操作常数存储器
2.2.1 从主机上拷贝到常数存储器上
使用cudaMemcpyToSymbol将主机存储器的数据复制到GPU;
template<class T>
cudaError_t cudaMemcpyToSymbol( const T& symbol,const void* src,size_t count,size_t offset,enum cudaMemcpyKind kind);
主机数据拷贝到设备上的symbol处;Symbol可以是位于全局存储器或不变存储器空间内的变量,也可以是一个指定全局存储器或常数存储器空间变量的字符串。kind值是cudaMemcpyHostToDevice或cudaMemcpyDeviceToDevice。
2.2.2 从常数存储器上拷贝到主机上
使用cudaMemcpyFromSymbol将设备上的数据复制到主机上;
template<class T>
cudaError_t cudaMemcpyFromSymbol( void *dst,const T& symbol,size_t count,size_t offset,enum cudaMemcpyKind kind);
从设备上的symbol处拷贝到目标存储器位置dst,拷贝的方向由kind决定,有cudaMemcpyDeviceToHost和 cudaMemcpyDeviceToDevice;