遍历内核链表是个常规操作,遍历链表过程可能会向链表增加新成员或者从链表剔除老成员,因此遍历链表时一般需要spin lock加锁保护。如果向链表增加新成员或者从链表剔除老成员不经常出现,大部分只是遍历查询链表中成员,此时链表遍历还用spin lock加锁保护,在高并发场景就会造成很大的性能损耗,而rcu可以比较好的解决这个问题。本文主要介绍一次内核开发实践中,用rcu降低了遍历内核链表带来的性能损坏,还总结了rcu使用过程遇到的问题、思考、改进。相信看过本文的同学会加深对rcu的理解。
rcu有时感觉挺简单的,但是用起来又感觉很复杂,尤其是宽限期的判定。先把看过的几篇讲解rcu原理不错的文章贴下:
RCU机制
谢宝友:深入理解RCU之三:概念
谢宝友: 深入理解RCU之五:玩具式实现
Linux RCU机制详解 (透彻)
Linux内核同步 - RCU synchronize原理分析
Linux 内核:RCU机制与使用
本文主要是在内核block层开发时,遇到了一个需要频繁的遍历链表、增加链表成员、删除链表成员的场景。为了避免spin lock加锁带来的性能损失,用rcu正好合适。但是对rcu宽限期的判断一直有很多疑惑,从而尝试用原子变量来判断宽限期,发现应该可以用起来,本文主要记录一下这个开发测试过程。
1:对rcu的简单理解
前文列举的几篇文章已经把rcu讲解挺深入的,这里就说下个人对rcu的一些简单理解。看一段经常出现的rcu演示代码
- struct foo *gbl_foo;
- void foo_read(void)
- {
- rcu_read_lock();
- foo *fp = gbl_foo;
- if ( fp != NULL )
- dosomething(fp->a,fp->b,fp->c);
- rcu_read_unlock();
- }
- void foo_update( foo* new_fp )
- {
- spin_lock(&foo_mutex);
- foo *old_fp = gbl_foo;
- gbl_foo = new_fp;
- spin_unlock(&foo_mutex);
- synchronize_rcu();
- kfee(old_fp);
- }
foo_read()函数是rcu读者执行的,使用gbl_foo这个全局变量。foo_update()是rcu写者执行的,它里边会用new_fp更新gbl_foo,并kfee释放掉老的gbl_fo。foo_read()中的rcu_read_lock()和rcu_read_unlock()用来标记一个rcu读过程的开始和结束,这个读过程就是rcu宽限期。假设此时进程a正执行foo_read(),处于rcu宽限期,而此时进程b正执行foo_update(),用new_fp更新gbl_foo,但是不能立即执行kfee释放老的gbl_foo,因为老的gbl_foo可能正在被进程a使用!于是进程b就先调用synchronize_rcu()函数阻塞,直到所有执行foo_read()的进程都退出rcu宽限期,进程b才会退出synchronize_rcu()函数,然后执行kfee()安全的释放老的gbl_foo。
继续,一般遍历内核链表用的是list_for_each_entry,rcu场景用的是list_for_each_entry_rcu,二者有什么区别呢?看下源码:
- #define list_for_each_entry_rcu(pos, head, member, cond...) \
- for (__list_check_rcu(dummy, ## cond, 0), \
- pos = list_entry_rcu((head)->next, typeof(*pos), member); \
- &pos->member != (head); \
- pos = list_entry_rcu(pos->member.next, typeof(*pos), member))
- #define list_entry_rcu(ptr, type, member) \
- container_of(READ_ONCE(ptr), type, member)
- #define READ_ONCE(x) __READ_ONCE(x, 1)
- #define __READ_ONCE(x, check) \
- ({ \
- union { typeof(x) __val; char __c[1]; } __u; \
- if (check) \
- __read_once_size(&(x), __u.__c, sizeof(x)); \
- else \
- __read_once_size_nocheck(&(x), __u.__c, sizeof(x)); \
- smp_read_barrier_depends(); /* Enforce dependency ordering from x */ \
- __u.__val; \
- })
主要就是获取链表成员改成了list_entry_rcu,它有什么魔力呢?就是在访问链表成员最后,加入了内存屏障,这样避免了cpu cache的干扰,保证得到最新的链表数据,而不是老的。
继续,一般删除链表成员是用list_del,rcu场景是list_del_rcu,看下源码:
- static inline void list_del_rcu(struct list_head *entry)
- {
- __list_del_entry(entry);
- entry->prev = LIST_POISON2;
- }
list_del_rcu相对普通的list_del,只是多了一个entry->prev = LIST_POISON2操作,这样可以保证要删除的链表成员的prev指针无效。举个例子,如果进程1正在list_del_rcu删除链表成员D,它前边和后边的链表成员是prev和 next。此时进程2正在访问链表成员D,则进程2下一次得到的链表成员们要么是D,要么是next,不会有第3中情况,cpu硬件机制保证。如下示意图简单演示list_del_rcu删除链表成员:

我觉得重点是,删除链表成员D,不是一下子全删掉,删除过程D还指向next,只是prev不再指向D了。这样如果有进程正在访问成员D,还能保证该进程通过D找到下一个成员next。而后续的进程再遍历该链表,通过prev找到的下一个链表成员是next。
继续,一般向链表插入新成员是执行list_add,rcu的版本是list_add_rcu,看下源码:
- static inline void list_add_rcu(struct list_head *new, struct list_head *head)
- {
- __list_add_rcu(new, head, head->next);
- }
- static inline void __list_add_rcu(struct list_head *new,
- struct list_head *prev, struct list_head *next)
- {
- if (!__list_add_valid(new, prev, next))
- return;
- new->next = next;
- new->prev = prev;
- rcu_assign_pointer(list_next_rcu(prev), new);
- next->prev = new;
- }
- #define rcu_assign_pointer(p, v) \
- ({ \
- uintptr_t _r_a_p__v = (uintptr_t)(v); \
- rcu_check_sparse(p, __rcu); \
- \
- if (__builtin_constant_p(v) && (_r_a_p__v) == (uintptr_t)NULL) \
- WRITE_ONCE((p), (typeof(p))(_r_a_p__v)); \
- else \
- smp_store_release(&p, RCU_INITIALIZER((typeof(p))_r_a_p__v)); \
- _r_a_p__v; \
- })
这个设计很巧妙,先执行new->next = next和new->prev = prev,令新的链表成员new指向它前后和后边的链表成员prev和next。然后执行rcu_assign_pointer(list_next_rcu(prev), new)令前边的链表成员prev指向new,这个赋值有内存屏障加成,不仅避免了编译器指令乱排序,还避免了cache同步不及时带了的问题。简单说,这个赋值后,前边的链表成员prev立即指向new,并且所有cpu都是这样,避免了多核cpu因cache同步延迟而无法及时得到最新的链表数据。最后执行next->prev = new令后边的链表成员指向new。
这样做的效果是:在把new插入链表prev和next链表成员时,如果有进程正在访问prev链表成员,则该进程得到的下一个链表成员,要么是new,要么是next。不会有第3中情况!要么得到的是老数据,要么得到的是新数据,不会有第3中情况,cpu的硬件机制保证了这种情况。
为了便于理解,如下演示list_add_rcu增加链表成员的示意图:
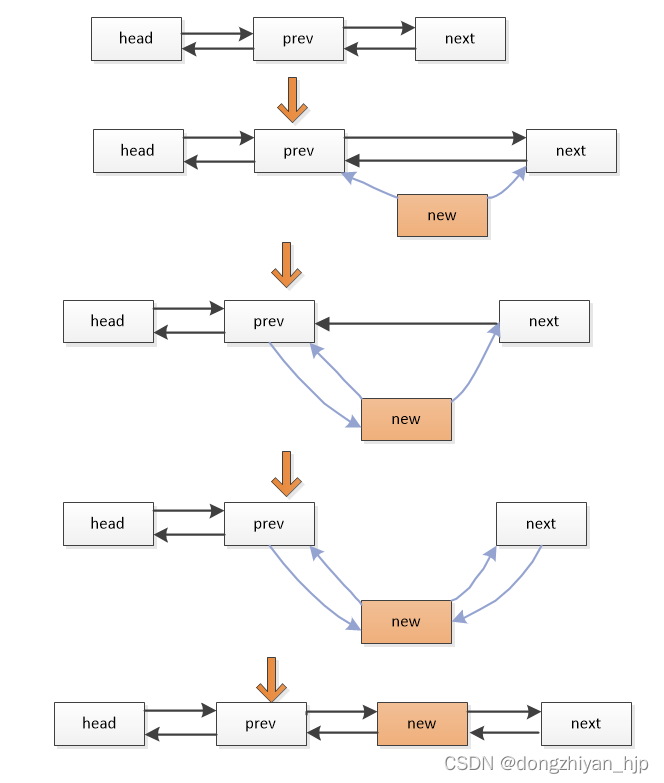
我觉得重点是,在把new添加到链表时,如果有其他进程正访问prev,则它得到的下一个链表成员要么是next,要么是new,不会出现第3种情况。
2:rcu的实战应用
实际场景是:我想统计进程IO派发过程的延迟,分别在IO请求插入IO队列、IO请求派发、IO传输完成记录当前时间点,然后计算IO请求在IO队列的时间(ID 耗时)、IO请求派发后在磁盘驱动的时间(DC耗时),最后每隔1s打印一次进程当前周期派发的IO请求数、最大ID和DC耗时、平均ID和DC耗时,依次评估block层调度器对进程IO传输的影响。
原理并不复杂,这里把相关数据结构和源码贴下
- struct process_io_control{
- int enable;
- spinlock_t process_lock_list;
- struct list_head process_io_control_head;
- struct list_head process_io_control_head_del;//暂时存放delete的process_io_info
- struct task_struct *kernel_thread;
- struct kmem_cache *process_rq_stat_cachep;
- struct kmem_cache *process_io_info_cachep;
- atomic_t read_lock_count;
- };
- struct process_io_info{
- int pid;
- char comm[COMM_LEN];
- //进程有多少个IO请求在传输
- atomic_t rq_count;
- ..........
- u32 max_id_time;//IO请求在IO队列最长的停留时间(进程的)
- u32 max_dc_time;//IO请求在磁盘驱动层的最长耗时(进程的)
- u32 all_id_time;//进程传输的每个IO请求在队列停留时间之和
- u32 all_dc_time;//进程传输的IO请求在磁盘驱动层的耗时之和
- //周期内进程传输完成的IO请求数,每个周期开始时清0,然后进程每传输完成一个IO则加1
- int complete_rq_count;
- struct list_head process_io_info_list;
- struct list_head process_io_info_del;
- int has_deleted;
- spinlock_t io_data_lock;
- }
- struct process_rq_stat{
- struct request *rq;
- //IO请求插入IO队列的时间
- u64 rq_inset_time;
- //IO请求派发的时间
- u64 rq_issue_time;
- u32 id_time;
- u32 dc_time;
- struct process_io_info *p_process_io_info;
- };
进程每次派发IO请求都分配一个struct process_rq_stat结构,里边主要记录IO请求插入IO队列的时间、IO请求派发的时间、ID和DC耗时。每个IO传输的进程都会首先分配一个struct process_io_info结构,主要记录该进程的信息、进程派发的IO的最大ID、最大DC耗时、进程派发IO请求数等等。struct process_io_control是总的控制结构,每个struct process_io_info结构都会添加到struct process_io_control的process_io_control_head链表。
这些数据结构是怎么跟块层联系上呢?如下:
- struct gendisk {
- ..........
- struct process_io_control process_io;
- ..........
- }
- struct request {
- ..........
- struct process_rq_stat *p_process_rq_stat;
- ..........
- }
struct process_io_control 结构内嵌在代表块设备的struct gendisk结构里,struct process_rq_stat *p_process_rq_stat指针内嵌在代表IO请求的struct request结构中,p_process_rq_stat就指向了为每个IO请求分配的struct process_rq_stat结构
下边看下在IO请求插入IO队列、IO请求派发、IO请求传输完成 必须执行的blk_mq_sched_request_inserted、blk_mq_start_request、blk_account_io_done函数里添加的代码:
- void blk_mq_sched_request_inserted(struct request *rq)
- {
- if(rq->rq_disk && rq->rq_disk->process_io.enable){
- struct process_rq_stat *p_process_rq_stat_tmp = NULL;
- struct process_io_info *p_process_io_info_tmp = NULL;
- int find = 0;
- //类似 rcu_read_lock()开始宽限期Grace Period
- atomic_inc(&(rq->rq_disk->process_io.read_lock_count));
- list_for_each_entry_rcu(p_process_io_info_tmp, &(rq->rq_disk->process_io.process_io_control_head), process_io_info_list){
- if(p_process_io_info_tmp->pid == current->pid){
- spin_lock_irq(&(rq->rq_disk->process_io.process_lock_list));
- //has_deleted是1说明该process_rq_info已经被删除了,那就跳出循环重新分配
- if(p_process_io_info_tmp->has_deleted){
- spin_unlock_irq(&(rq->rq_disk->process_io.process_lock_list));
- break;
- }
- else
- { //进程在传输的IO请求数加1
- atomic_inc(&(p_process_io_info_tmp->rq_count));
- }
- spin_unlock_irq(&(rq->rq_disk->process_io.process_lock_list));
- find = 1;
- break;
- }
- }
- //类似 rcu_read_unlock()结束宽限期Grace Period
- atomic_dec(&(rq->rq_disk->process_io.read_lock_count));
- ...................
- //没有找到与进程匹配的process_io_info则针对进程分配新的process_io_info
- if(0 == find){
- p_process_io_info_tmp = kmem_cache_alloc(rq->rq_disk->process_io.process_io_info_cachep,GFP_ATOMIC);
- memset(p_process_io_info_tmp,0,sizeof(struct process_io_info));
- ///进程在传输的IO请求数加1
- atomic_inc(&(p_process_io_info_tmp->rq_count));
- //向process_io_control_head链表插入process_io_info需要加锁,因为同时在print_process_io_info()函数会从 process_io_control_head链表删除process_io_info,同时多个rcu writer,需要加锁
- spin_lock_irq(&(rq->rq_disk->process_io.process_lock_list));
- list_add_rcu(&p_process_io_info_tmp->process_io_info_list,&(rq->rq_disk->process_io.process_io_control_head));
- spin_unlock_irq(&(rq->rq_disk->process_io.process_lock_list));
- }
- //针对本次的IO请求分配process_rq_stat结构
- p_process_rq_stat_tmp = kmem_cache_alloc(rq->rq_disk->process_io.process_rq_stat_cachep,GFP_ATOMIC);
- memset(p_process_rq_stat_tmp,0,sizeof(struct process_rq_stat));
- p_process_io_info_tmp->pid = current->pid;
- strncpy(p_process_io_info_tmp->comm,current->comm,COMM_LEN-1);
- //建立process_rq_stat 与 process_io_info的关系
- p_process_rq_stat_tmp->p_process_io_info = p_process_io_info_tmp;
- //process_rq_stat 记录 IO请求插入IO队列的时间
- p_process_rq_stat_tmp->rq_inset_time = ktime_to_us(ktime_get());
- //IO请求的 rq->p_process_rq_stat 指向新分配的process_rq_stat结构,这就是为该IO请求分配的process_rq_stat结构
- rq->p_process_rq_stat = p_process_rq_stat_tmp;
- return;
- }
- }
blk_mq_sched_request_inserted函数中,先list_for_each_entry_rcu遍历process_io_control_head链表,查看是否有该进程绑定的process_io_info结构,没有的话就要为进程分配一个process_io_info结构,并把process_io_info添加到process_io_control_head链表。process_io_control_head链表保存了每个进行IO传输的进程绑定的process_io_info结构。然后p_process_io_info_tmp->pid = current->pid 和 strncpy(p_process_io_info_tmp->comm,current->comm,COMM_LEN-1)在process_io_info结构记录当前进程的名字和PID,这样就建立了进程和process_io_info的绑定关系。
接着,为当前进程传输的IO请求分配一个process_rq_stat结构,其成员rq_inset_time记录IO请求插入IO队列的时间。接着执行p_process_rq_stat_tmp->p_process_io_info = p_process_io_info_tmp 和 rq->p_process_rq_stat = p_process_rq_stat_tmp,建立代表IO请求的rq、为IO请求分配的process_rq_stat结构、代表进程的process_io_info结构彼此之间的联系。
IO请求派发blk_mq_start_request函数中添加的源码如下:
- void blk_mq_start_request(struct request *rq)
- {
- ...................
- if(rq->rq_disk && rq->rq_disk->process_io.enable && rq->p_process_rq_stat){
- struct process_rq_stat *p_process_rq_stat_tmp = rq->p_process_rq_stat;
- struct process_io_info *p_process_io_info_tmp = rq->p_process_rq_stat->p_process_io_info;
- ................
- //记录IO请求派发的时间
- p_process_rq_stat_tmp->rq_issue_time = ktime_to_us(ktime_get());
- //计算IO请求在IO队列的停留时间
- p_process_rq_stat_tmp->id_time = p_process_rq_stat_tmp->rq_issue_time - p_process_rq_stat_tmp->rq_inset_time;
- }
- }
主要记录IO请求派发时间rq_issue_time,并计算IO请求在IO队列的耗时id_time。IO请求传输执行的函数blk_account_io_done中添加的源码如下:
- void blk_account_io_done(struct request *req, u64 now)
- {
- .................
- if(req->rq_disk && req->rq_disk->process_io.enable && req->p_process_rq_stat){
- struct process_rq_stat *p_process_rq_stat_tmp = req->p_process_rq_stat;
- struct process_io_info *p_process_io_info_tmp = req->p_process_rq_stat->p_process_io_info;
- //计算IO请求的dc时间
- p_process_rq_stat_tmp->dc_time = ktime_to_us(ktime_get()) - p_process_rq_stat_tmp->rq_issue_time;
- spin_lock_irq(&(p_process_io_info_tmp->io_data_lock));
- if(p_process_rq_stat_tmp->id_time > p_process_io_info_tmp->max_id_time){
- //记录最大的id time
- p_process_io_info_tmp->max_id_time = p_process_rq_stat_tmp->id_time;
- }
- if(p_process_rq_stat_tmp->dc_time > p_process_io_info_tmp->max_dc_time){
- //记录最大的dc time
- p_process_io_info_tmp->max_dc_time = p_process_rq_stat_tmp->dc_time;
- }
- //累加进程的IO请求在队列的时间,需加锁保护,因为同时可能执行print_process_io_info函数清0
- p_process_io_info_tmp->all_id_time += p_process_rq_stat_tmp->id_time;
- //累加进程的IO请求在磁盘驱动的时间,需加锁保护,因为同时可能执行print_process_io_info函数清0
- p_process_io_info_tmp->all_dc_time += p_process_rq_stat_tmp->dc_time;
- //进程传输完成的IO请求数加1
- p_process_io_info_tmp->complete_rq_count ++;
- spin_unlock_irq(&(p_process_io_info_tmp->io_data_lock));
- //进程在传输的IO请求数减1
- atomic_dec(&(p_process_io_info_tmp->rq_count));
- ..............
- }
- }
blk_account_io_done函数主要是计算IO请求在磁盘驱动层的耗时dc_time,并计算进程IO传输过程最大的id_time和dc_time耗时。在哪里使用这些采集到的IO信息呢?在print_process_io_info()函数,每1s执行一次,如下:
- void print_process_io_info(struct process_io_control *p_process_io_tmp)
- {
- struct process_io_info *p_process_io_info_tmp = NULL;
- struct process_io_info *p_process_io_info_tmp_copy = NULL;
- //类似 rcu_read_lock()开始宽限期Grace Period
- atomic_inc(&(p_process_io_tmp->read_lock_count));
- list_for_each_entry_rcu(p_process_io_info_tmp, &(p_process_io_tmp->process_io_control_head), process_io_info_list){
- //如果上一个周期内process_io_info绑定的进程有IO传输
- if(p_process_io_info_tmp->complete_rq_count != 0)
- {
- spin_lock_irq(&(p_process_io_info_tmp->io_data_lock));
- //获取该进程在上一个周期传输的IO请求中,最大ID耗时 和 DC耗时
- max_id_time = p_process_io_info_tmp->max_id_time;
- max_dc_time = p_process_io_info_tmp->max_dc_time;
- //计算该进程在上一个周期传输的IO请求中平均ID耗时 和 平均DC耗时
- avg_id_time = p_process_io_info_tmp->all_id_time/p_process_io_info_tmp->complete_rq_count;
- avg_dc_time = p_process_io_info_tmp->all_dc_time/p_process_io_info_tmp->complete_rq_count;
- ...................
- //对该进程传输完成的IO请求数清0
- p_process_io_info_tmp->complete_rq_count = 0;
- spin_unlock_irq(&(p_process_io_info_tmp->io_data_lock));
- }
- //如果上一个周期内process_io_info绑定的进程没有传输IO
- else if(p_process_io_info_tmp->complete_rq_count == 0)
- {
- spin_lock_irq(&(p_process_io_tmp->process_lock_list));
- //再次确保process_io_info绑定的进程当前也没有IO请求在传输
- if(atomic_read(&(p_process_io_info_tmp->rq_count)) == 0){
- //设置process_io_info的delete标记,并把process_io_info从process_io_control_head链表剔除
- p_process_io_info_tmp->has_deleted = 1;
- list_del_rcu(&p_process_io_info_tmp->process_io_info_list);
- }else{
- spin_unlock_irq(&(p_process_io_tmp->process_lock_list));
- continue;
- }
- spin_unlock_irq(&(p_process_io_tmp->process_lock_list));
- //process_io_info从process_io_control_head链表剔除后,再临时添加到process_io_control_head_del链表,下边在合适实际再释放process_io_info结构
- list_add(&p_process_io_info_tmp->process_io_info_del,&(p_process_io_tmp->process_io_control_head_del));
- }
- }
- //类似 rcu_read_unlock()结束宽限期Grace Period
- atomic_dec(&(p_process_io_tmp->read_lock_count));
- while(i ++ < 2)//加锁while循环是一旦 p_process_io_tmp->read_lock_count 不是0,先等等
- {
- //当 read_lock_count 是0,说明process_io_control_head_del上的process_io_info在从process_io_control_head链表剔除后,遍历 process_io_control_head链表的进程都退出了rcu宽限期,可以放心释放process_io_info结构了
- if(atomic_read(&(p_process_io_tmp->read_lock_count)) == 0){
- list_for_each_entry_safe(p_process_io_info_tmp,p_process_io_info_tmp_copy,&(p_process_io_tmp->process_io_control_head_del), process_io_info_del){
- list_del(&p_process_io_info_tmp->process_io_info_del);
- //真正释放process_io_info结构 kmem_cache_free(p_process_io_tmp->process_io_info_cachep,p_process_io_info_tmp);
- }
- break;
- }
- msleep(5);
- }
- }
- //每个1s执行一次 print_process_io_info()
- static int process_rq_stat_thread(void *arg)
- {
- struct process_io_control *p_process_io_tmp = (struct process_io_control *)arg;
- while (!kthread_should_stop()) {
- print_process_io_info(p_process_io_tmp);
- msleep(1000);
- }
- p_process_io_tmp->kernel_thread = NULL;
- return 0;
- }
print_process_io_info函数主要是list_for_each_entry_rcu里遍历process_io_control_head链表,取出每个IO传输进程绑定的process_io_info结构,这个结构记录了该进程IO传输的统计信息,如进程派发的IO请求数complete_rq_count、IO请求在 IO队列最大耗时max_id_time和平均耗时avg_id_time、IO请求的在磁盘驱动层最大耗时max_dc_time 和平均耗时avg_dc_time。list_for_each_entry_rcu循环正是取出这些进程的IO统计信息做处理,源码未贴出,实际是printk只是把这些信息打印出来。
print_process_io_info函数主要是list_for_each_entry_rcu遍历process_io_control_head链表上每个进程的process_io_info结构过程,另一个关键点是:如果进程没有派发IO请求(即else if(p_process_io_info_tmp->complete_rq_count == 0)成立),说明该进程绑定的process_io_info是空闲的,为避免多个空闲process_io_info带来的空间和性能损耗,则执行list_del_rcu(&p_process_io_info_tmp->process_io_info_list)把该进程绑定的process_io_info结构从process_io_control_head链表剔除。但是不能立即执行kmem_cache_free释放这个process_io_info结构,为什么不能立即kmem_cache_free释放这个process_io_info结构呢?因为这个process_io_info结构可能正在被其他进程使用!比如其他进程很大可能正在blk_mq_sched_request_inserted()函数list_for_each_entry_rcu遍历process_io_control_head链表,而正使用这个process_io_info结构。本质就是rcu宽限期还没到!我们这里只是临时把该process_io_info结构再临时添加到process_io_control_head_del链表,等到合适时机再kmem_cache_free。
问题来了,该怎么判断rcu宽限期已经结束了呢?原始判断rcu宽限期的方法要用到rcu_read_lock()、rcu_read_unlock()、synchronize_rcu(),但是由于对rcu宽限期的理解还不深刻,对使用rcu_read_lock()、rcu_read_unlock()判断rcu宽限期的的开始和结束,总觉得是个玄学。于是就想,为什么不自己实现一套rcu宽限期的判断方法呢?
3:rcu宽限期判断的一个改进
想来想去可以用原子变量来判断rcu宽限期的开始和结束,请再看下前文列出的blk_mq_sched_request_inserted和print_process_io_info函数源码,这两个函数都会list_for_each_entry_rcu遍历process_io_control_head链表上的process_io_info结构,blk_mq_sched_request_inserted函数会向process_io_control_head链表增加新的process_io_info结构,print_process_io_info函数会从process_io_control_head链表剔除空闲的process_io_info结构。
这两个函数在list_for_each_entry_rcu遍历process_io_control_head链表上的process_io_info结构那个循环前后,都添加了atomic_inc(&(rq->rq_disk->process_io.read_lock_count)) 和 atomic_dec(&(rq->rq_disk->process_io.read_lock_count)) 这两行代码。没错,二者就跟rcu_read_lock()和rcu_read_unlock()作用一样,用来标记rcu宽限期的开始和结束。在进入rcu宽限期时,令read_lock_count这个原子变量加1。在rcu宽限期结束时,令read_lock_count这个原子变量减1。,read_lock_count原子变量初值是0,如果read_lock_count原子变量是0,说明此时处于rcu宽限期外,可以安全的释放process_io_control_head链表上的process_io_info结构。我们把关键源码再列下:
- void blk_mq_sched_request_inserted(struct request *rq)
- {
- if(rq->rq_disk && rq->rq_disk->process_io.enable){
- struct process_rq_stat *p_process_rq_stat_tmp = NULL;
- struct process_io_info *p_process_io_info_tmp = NULL;
- int find = 0;
- //类似 rcu_read_lock()开始宽限期Grace Period
- atomic_inc(&(rq->rq_disk->process_io.read_lock_count));
- list_for_each_entry_rcu(p_process_io_info_tmp, &(rq->rq_disk->process_io.process_io_control_head), process_io_info_list){
- if(p_process_io_info_tmp->pid == current->pid){
- spin_lock_irq(&(rq->rq_disk->process_io.process_lock_list));
- //has_deleted是1说明该process_rq_stat已经被删除了,那就跳出循环重新分配
- if(p_process_io_info_tmp->has_deleted){
- spin_unlock_irq(&(rq->rq_disk->process_io.process_lock_list));
- break;
- }
- else
- { //进程在传输的IO请求数加1
- atomic_inc(&(p_process_io_info_tmp->rq_count));
- }
- spin_unlock_irq(&(rq->rq_disk->process_io.process_lock_list));
- find = 1;
- break;
- }
- }
- //类似 rcu_read_unlock()结束宽限期Grace Period
- atomic_dec(&(rq->rq_disk->process_io.read_lock_count));
- ...................
- //没有找到与进程匹配的process_io_info则针对进程分配新的process_io_info
- if(0 == find){
- p_process_io_info_tmp = kmem_cache_alloc(rq->rq_disk->process_io.process_io_info_cachep,GFP_ATOMIC);
- memset(p_process_io_info_tmp,0,sizeof(struct process_io_info));
- ///进程在传输的IO请求数加1
- atomic_inc(&(p_process_io_info_tmp->rq_count));
- //向process_io_control_head链表插入process_io_info需要加锁,因为同时在print_process_io_info()函数会从 process_io_control_head链表删除process_io_info,同时多个writer,需要加锁
- spin_lock_irq(&(rq->rq_disk->process_io.process_lock_list));
- list_add_rcu(&p_process_io_info_tmp->process_io_info_list,&(rq->rq_disk->process_io.process_io_control_head));
- spin_unlock_irq(&(rq->rq_disk->process_io.process_lock_list));
- }
- ...................
- return;
- }
- void print_process_io_info(struct process_io_control *p_process_io_tmp)
- {
- struct process_io_info *p_process_io_info_tmp = NULL;
- struct process_io_info *p_process_io_info_tmp_copy = NULL;
- //类似 rcu_read_lock()开始宽限期Grace Period
- atomic_inc(&(p_process_io_tmp->read_lock_count));
- list_for_each_entry_rcu(p_process_io_info_tmp, &(p_process_io_tmp->process_io_control_head), process_io_info_list){
- ..................
- //如果上一个周期内process_io_info绑定的进程没有IO请求传输
- else if(p_process_io_info_tmp->complete_rq_count == 0)
- {
- spin_lock_irq(&(p_process_io_tmp->process_lock_list));
- //确保process_io_info绑定的进程目前也没有IO请求在传输
- if(atomic_read(&(p_process_io_info_tmp->rq_count)) == 0){
- //设置process_io_info的delete标记,并把process_io_info从process_io_control_head链表剔除
- p_process_io_info_tmp->has_deleted = 1;
- list_del_rcu(&p_process_io_info_tmp->process_io_info_list);
- }else{
- spin_unlock_irq(&(p_process_io_tmp->process_lock_list));
- continue;
- }
- spin_unlock_irq(&(p_process_io_tmp->process_lock_list));
- //process_io_info从process_io_control_head链表剔除后,再临时添加到process_io_control_head_del链表,下边再合适实际再释放process_io_info结构
- list_add(&p_process_io_info_tmp->process_io_info_del,&(p_process_io_tmp->process_io_control_head_del));
- }
- }
- //类似 rcu_read_unlock()结束宽限期Grace Period
- atomic_dec(&(p_process_io_tmp->read_lock_count));
- while(i ++ < 2)//加锁while循环是一旦 p_process_io_tmp->read_lock_count 不是0,先等等
- {
- //当 read_lock_count 是0,说明process_io_control_head_del上的process_io_info在从process_io_control_head链表剔除后,遍历 process_io_control_head链表的进程都退出了宽限期,可以放心process_io_info结构释放了
- if(atomic_read(&(p_process_io_tmp->read_lock_count)) == 0){
- list_for_each_entry_safe(p_process_io_info_tmp,p_process_io_info_tmp_copy,&(p_process_io_tmp->process_io_control_head_del), process_io_info_del){
- list_del(&p_process_io_info_tmp->process_io_info_del);
- //真正释放process_io_info结构
- kmem_cache_free(p_process_io_tmp->process_io_info_cachep,p_process_io_info_tmp);
- }
- break;
- }
- msleep(5);
- }
- }
print_process_io_info()函数中,list_for_each_entry_rcu遍历process_io_control_head链表上的process_io_info时,如果该process_io_info对应的进程没有近期没有IO传输,则list_del_rcu(&p_process_io_info_tmp->process_io_info_list)把该process_io_info从process_io_control_head链表中剔除,但是不会立即kmem_cache_free释放该结构,而只是把它暂时再移动到process_io_control_head_del链表。最后,在while(i ++ < 2){…..}中,里边主要判断如果read_lock_count原子变量是0,说明此时rcu宽限期已经结束,就安全的从process_io_control_head_del链表链表中取出已经从process_io_control_head链表上剔除的process_io_info结构, 然后kmem_cache_free释放它。
简单总结一下:在print_process_io_info和blk_mq_sched_request_inserted函数,都会list_for_each_entry_rcu遍历process_io_control_head链表。但是遍历前都要执行atomic_inc(&(rq->rq_disk->process_io.read_lock_count))令read_lock_count原子变量加1,在遍历链表结束后执行atomic_dec(&(rq->rq_disk->process_io.read_lock_count))令read_lock_count原子变量减1。简单说,read_lock_count原子变量初值是0,如果read_lock_count大于0说明有进程正在print_process_io_info或 blk_mq_sched_request_inserted函数中,list_for_each_entry_rcu遍历process_io_control_head链表。此时正处于rcu宽限期,只能从process_io_control_head链表上list_del_rcu剔除链表成员process_io_info,但不能kmem_cache_free释放它。而等read_lock_count原子变量是0,说明此时已经退出了rcu宽限期,就可以确定没有进程在使用刚从链表剔除的process_io_info结构,可安全的kmem_cache_free释放了。
ok,另外需要注意的一点是,rcu允许多个读者,但是如果有多个写者就需要加锁防护。可以看下blk_mq_sched_request_inserted和print_process_io_info函数里有spin lock加锁的地方。首先看下两个函数里list_for_each_entry_rcu遍历process_io_control_head链表的循环里,都有spin_lock_irq(&(rq->rq_disk->process_io.process_lock_list))加锁。这个加锁是为了防止print_process_io_info函数里从链表中删除掉的process_io_info再被blk_mq_sched_request_inserted函数用到。
具体过程解释如下:进程绑定的process_io_info结构的成员rq_count表示该进程正在派发的IO请求数,在IO请求插入IO队列执行blk_mq_sched_request_inserted时加1,在IO请求传输完成时减1。存在这样一种极端情况,进程A执行print_process_io_info函数的list_for_each_entry_rcu遍历process_io_control_head链表,遍历到某个process_io_info的rq_count是0,于是就执行list_del_rcu(&p_process_io_info_tmp->process_io_info_list)把这个process_io_info从链表剔除掉。
而同一个时间点,该process_io_info绑定的进程B正执行blk_mq_sched_request_inserted函数里的list_for_each_entry_rcu,遍历到process_io_control_head链表上的这个process_io_info结构。注意,即便此时进程A在从process_io_control_head链表剔除该process_io_info,但是在剔除前一瞬间,进程B已经在process_io_control_head链表遍历到这个process_io_info了,这种情况完全是有可能的!于是,进程B继续执行blk_mq_sched_request_inserted函数里的if(p_process_io_info_tmp->pid == current->pid),则该if成立,则find = 1。这表示已经为该进程分配了process_io_info结构,就不会分配新的process_io_info结构了。这样就会出问题,进程A在print_process_io_info函数最后回kmem_cache_free释放这个process_io_info结构,而进程B还在使用这个process_io_info结构,十有八九触发内核crash。
出现这个问题的根本原因是,没有一种机制表示process_io_info已经被从链表中剔除了,于是就有了print_process_io_info和blk_mq_sched_request_inserted函数list_for_each_entry_rcu循环里,spin_lock_irq(&(rq->rq_disk->process_io.process_lock_list))加锁,并且为process_io_info结构增加has_deleted成员。
有了这个机制就完美了,还是前文同样的场景。进程A和进程B只有一个进程能抢占process_lock_list锁。如果进程A在print_process_io_info函数的list_for_each_entry_rcu循环首先抢占process_lock_list锁,则执行p_process_io_info_tmp->has_deleted = 1并list_del_rcu(&p_process_io_info_tmp->process_io_info_list)从链表剔除该process_io_info。同一个时间点进程B在blk_mq_sched_request_inserted函数在list_for_each_entry_rcu循环也遍历到了这个process_io_info结构,但是获取process_lock_list锁失败。等进程B得到 process_lock_list锁,此时process_io_info的has_deleted是1,说明这个process_io_info已经被从链表剔除了,则只能重新为进程分配一个新的process_io_info结构了。
如果同一个时间点,是进程B首先在blk_mq_sched_request_inserted函数的list_for_each_entry_rcu循环,首先抢占了process_lock_list锁,则atomic_inc(&(p_process_io_info_tmp->rq_count))令rq_count加1。而同一个时间点,进程A在print_process_io_info函数,在得到process_lock_list锁后,因为rq_count是1则if(atomic_read(&(p_process_io_info_tmp->rq_count)) == 0)不成立,那就不会再把这个process_io_info结构从process_io_control_head链表剔除了。
rcu机制也不能完美保障可以从链表放心大胆剔除链表成员,具体情况需要具体分析!最后一点还需要提下,blk_mq_sched_request_inserted函数里if(0 == find)分支,在把新分配的process_io_info执行list_add_rcu(&p_process_io_info_tmp->process_io_info_list,&(rq->rq_disk->process_io.process_io_control_head))添加到process_io_control_head链表时,也spin_lock_irq(&(rq->rq_disk->process_io.process_lock_list))加了锁。这是因为此时print_process_io_info函数list_for_each_entry_rcu循环里,可能正在从process_io_control_head链表剔除process_io_info结构,这两处都是rcu写者,而多个rcu写者同时操作链表时,是需要加锁的。为什么?
举个例子:blk_mq_sched_request_inserted函数里正执行list_add_rcu(&p_process_io_info_tmp->process_io_info_list,&(rq->rq_disk->process_io.process_io_control_head))向process_io_control_head链表链表头增加一个新的成员,而同时print_process_io_info函数list_for_each_entry_rcu循环里正在process_io_control_head链表删除链表头后的第一个成员。二者是不能同时进行的,一个删除链表第一个成员,一个在向链表第一个成员前添加一个新的成员,没有锁保护,肯定会出错。