本专栏主要记录人工智能的应用方面的内容,包括chatGPT、AI绘图等等;
在当今AI的热潮下,不学习AI,就要被AI淘汰;所以欢迎小伙伴加入本专栏和我一起探索AI的应用,通过AI来帮助自己提升生产力;
订阅后可私聊我获取 《从零注册并登录使用ChatGPT》《从零开始使用chatGPT的API;通过chatgpt-next-web部署自己chatGPT web网页;无需翻墙,无需服务器,无需域名;》 两份文档;
采用Conda创建、隔离python虚拟环境,可以解决多应用部署下的环境管理难题;所以本文主要介绍通过Conda的方式在本地部署Stable Diffusion。
文章目录
- 一、Stable Diffusion介绍
- 二、通过Conda本地部署stable diffusion
- 2.1 安装所需依赖环境
- 2.1.1 安装CUDA
- 2.1.2 安装显卡驱动
- 2.1.3 安装Conda
- 2.1.4 安装git工具--gitForWindows
- 2.1.5 检查环境
- 2.2 配置Transformer环境变量
- 2.3 安装SD WebUI
- 2.4 安装SD WebUI过程中遇到的问题
- 三、 参考
一、Stable Diffusion介绍
Stable Diffusion是当下最强大的AI绘画工具;
可本地部署,可切换多种模型,且新的模型和开源库每天都在更新发布,最重要的是免费,没有绘图次数限制;
其是一种基于深度学习的文本到图像生成模型,于2022年发布。它能够根据文本描述生成详细的图像,同时也可以应用于其他任务,例如图生图,生成简短视频等。
Stable Diffusion Web UI是一个基于Web的用户界面,用于使用Stable Diffusion进行图像生成和其他任务。该Web UI由AUTOMATIC1111开发,并开源上传至Github,也是目前使用最多的WebUI版本。Stable Diffusion Web UI提供了易于使用的图形界面,可以帮助用户更直观地了解和使用Stable Diffusion的功能,并在基本不需要编写代码的情况下启动和监视训练过程。
Stable Diffusion 的主要优点:
(1) 免费开源与另外一个主流的AI绘画软件Midjourney相比,它是免费开源的。Midjourney需要登陆Discard上进行使用(国内无法直接链接注册),而且需要付费才能继续使用,最低价格为10美元/月,而SD在B站上有人整理好的免费安装包,无需付费即可下载一键安装。将SD安装到本地后,用户可以随时使用,生成的图片只有自己可以看到,保密性更高。
(2) SD拥有强大的开源模型和插件由于其开源属性,SD拥有许多免费的高质量外接预训练模型和插件。例如,可以提取物体轮廓、人体姿势骨架、图像深度信息的插件Controlnet可以让用户在绘画过程中精确控制人物的动作姿势、手势和画面构图等细节;插件Mov2Mov可以将真实视频进行风格化转换。此外,SD还具备Inpainting和Outpainting功能,可以智能地对图像进行局部修改和扩展,而这些功能目前Midjourney无法实现。
二、通过Conda本地部署stable diffusion
2.1 安装所需依赖环境
2.1.1 安装CUDA
首先去Pytorch官网,点击链接https://pytorch.org/即可跳转;
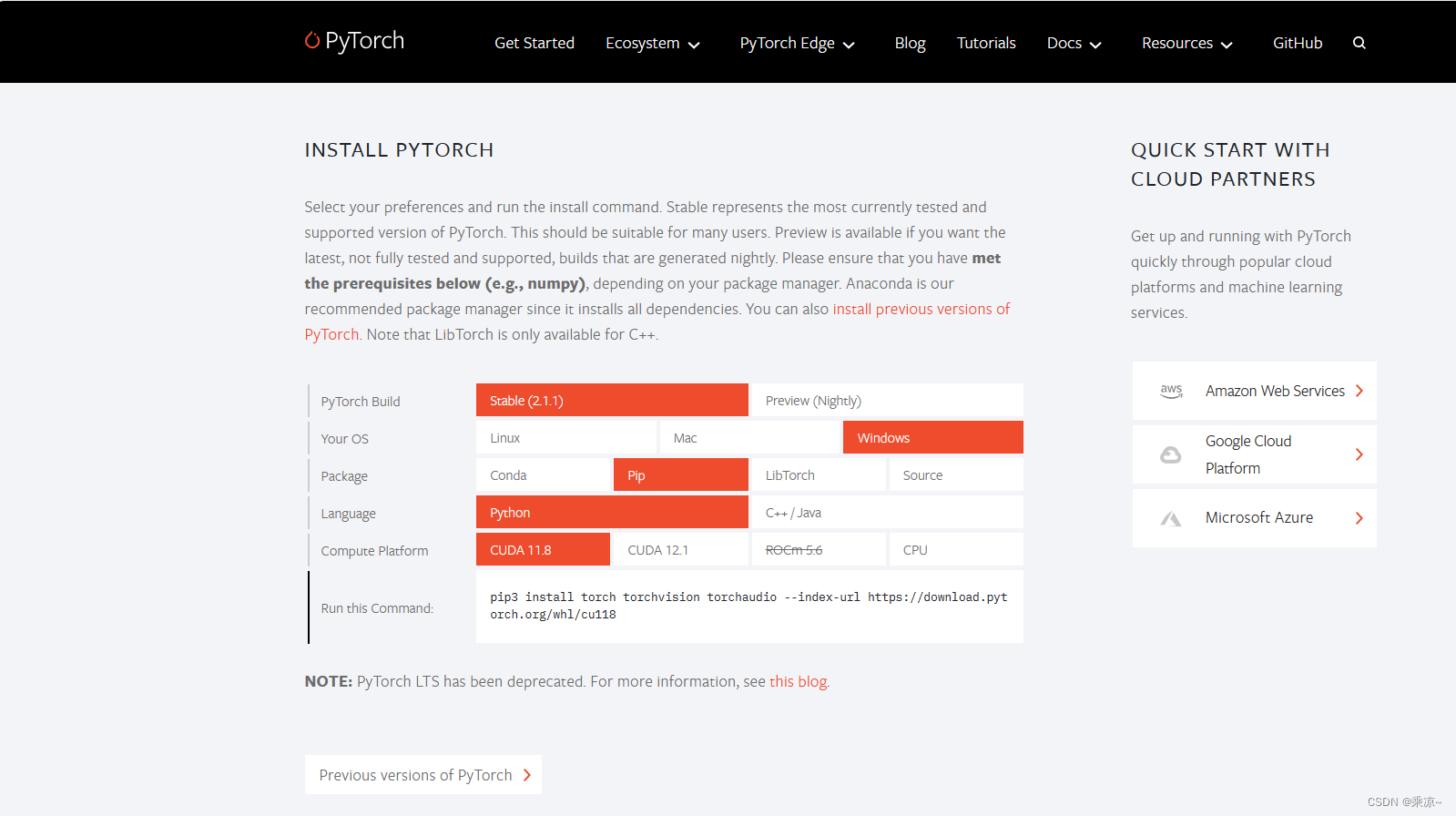
可以看到,它目前支持到CUDA的11.8版本,因此我们需要去下载CUDA 11.8;
【CUDA下载网址】https://developer.nvidia.com/cuda-downloads
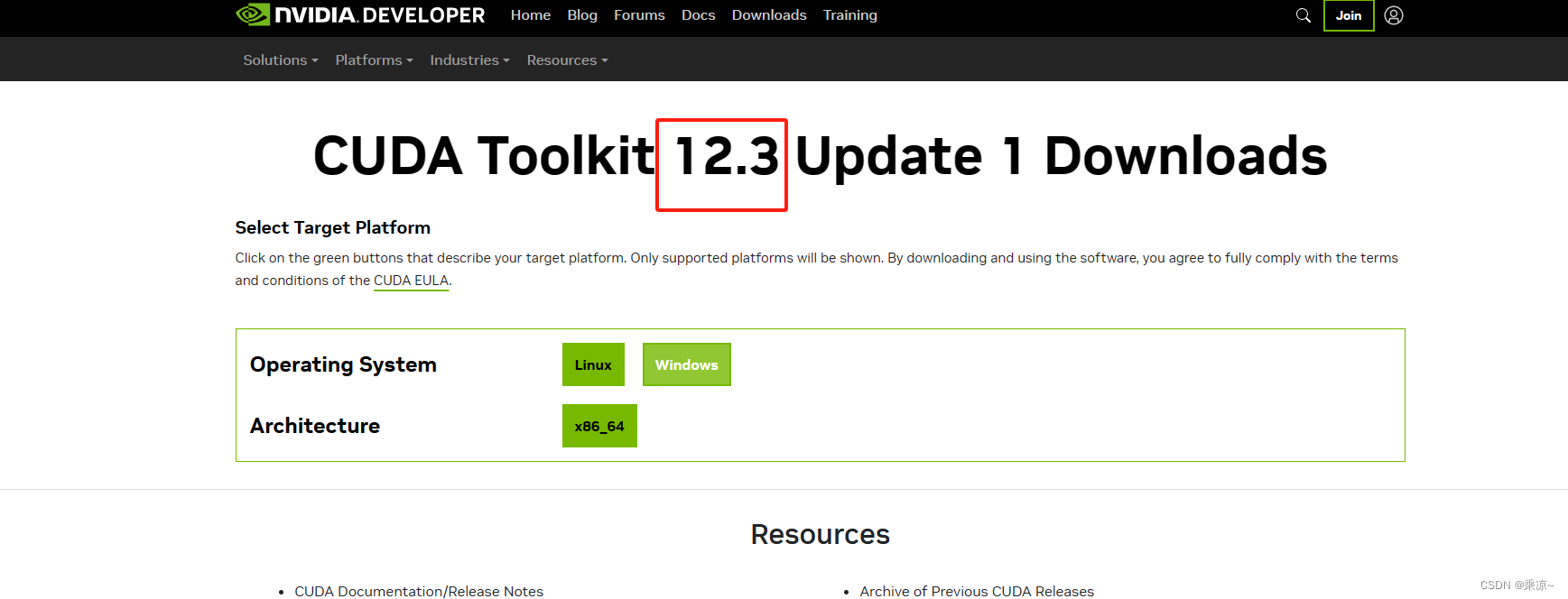
打开后我们可以看到 ,目前已经升级到了12.3这个版本,但是我们需要的下载的是11.8版本,所以需要找到12.1进行下载,如下步骤进行:
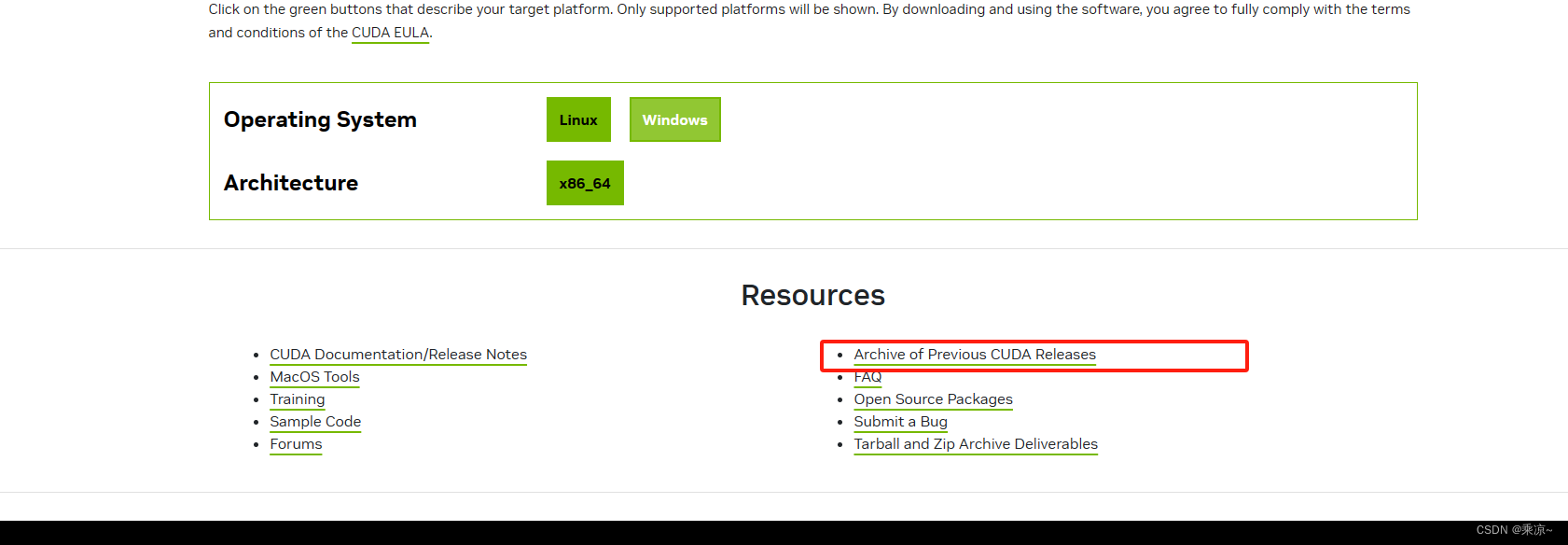
点击上图红框中的按钮,获取以前发布的版本,
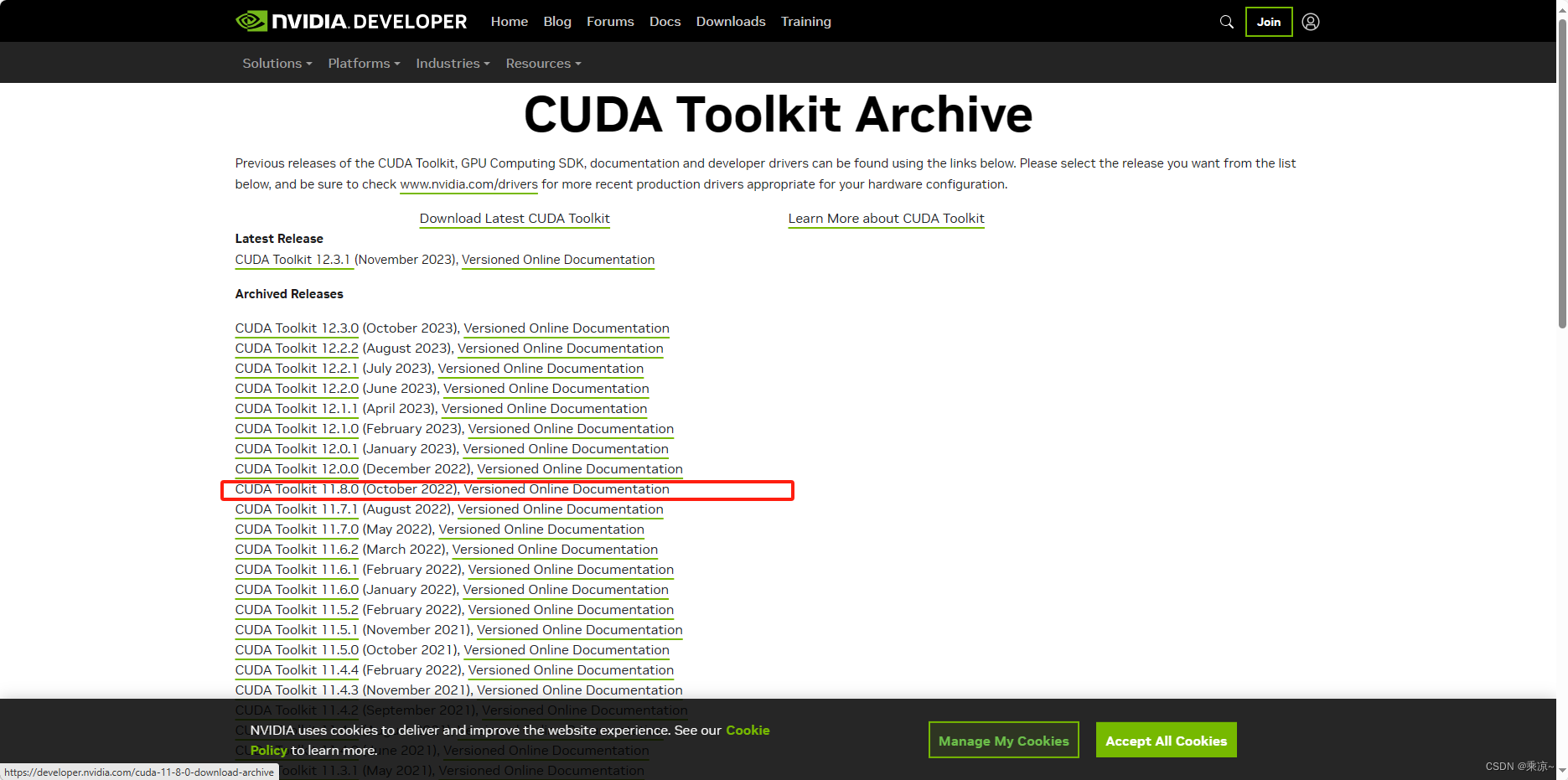
然后以下图片示例进行操作:
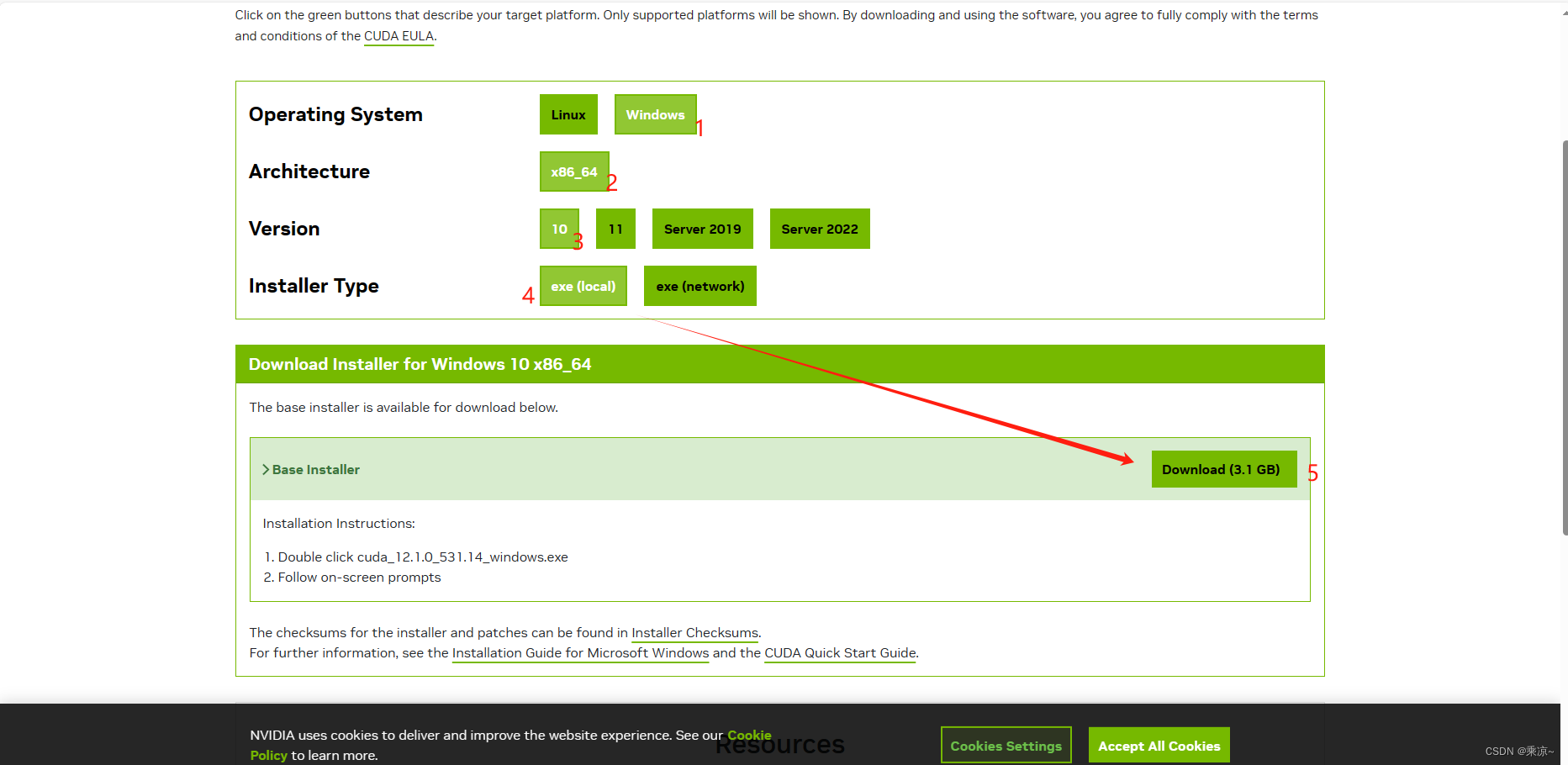
下载完成后,如下图所示,双击打开:

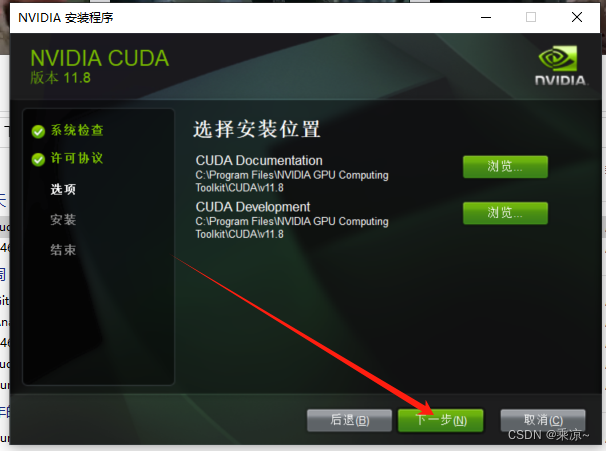
路径选择默认路径即可:
然后选择自定义安装:
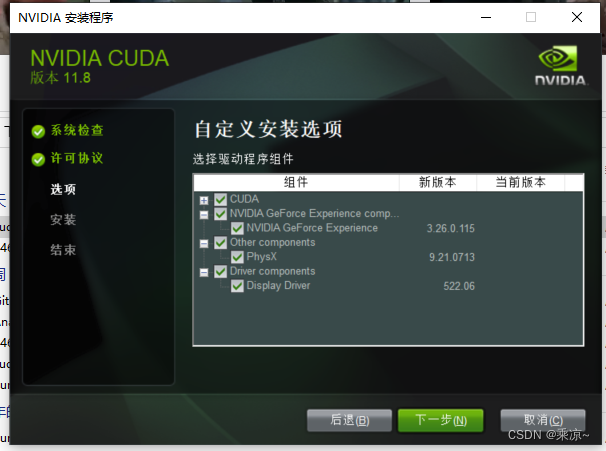
然后等待安装完成即可:
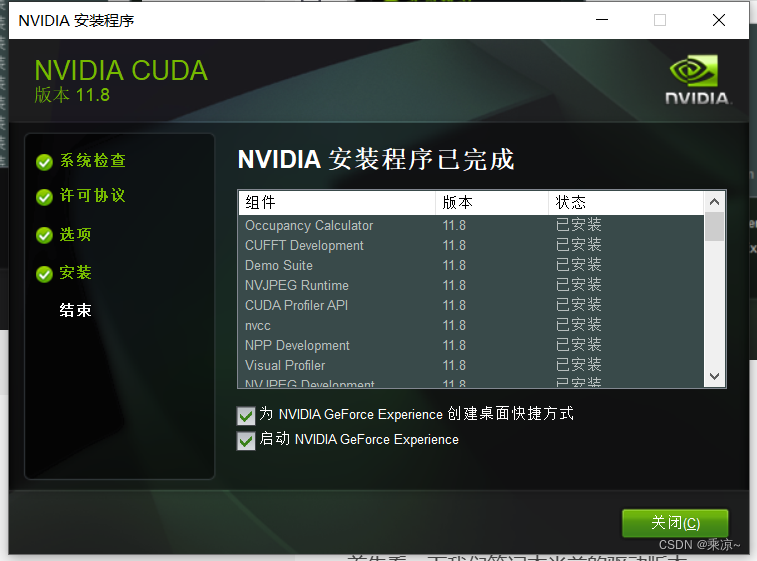
2.1.2 安装显卡驱动
然后我们需要去下载显卡的驱动,
【NVIDIA下载网址】https://www.nvidia.cn
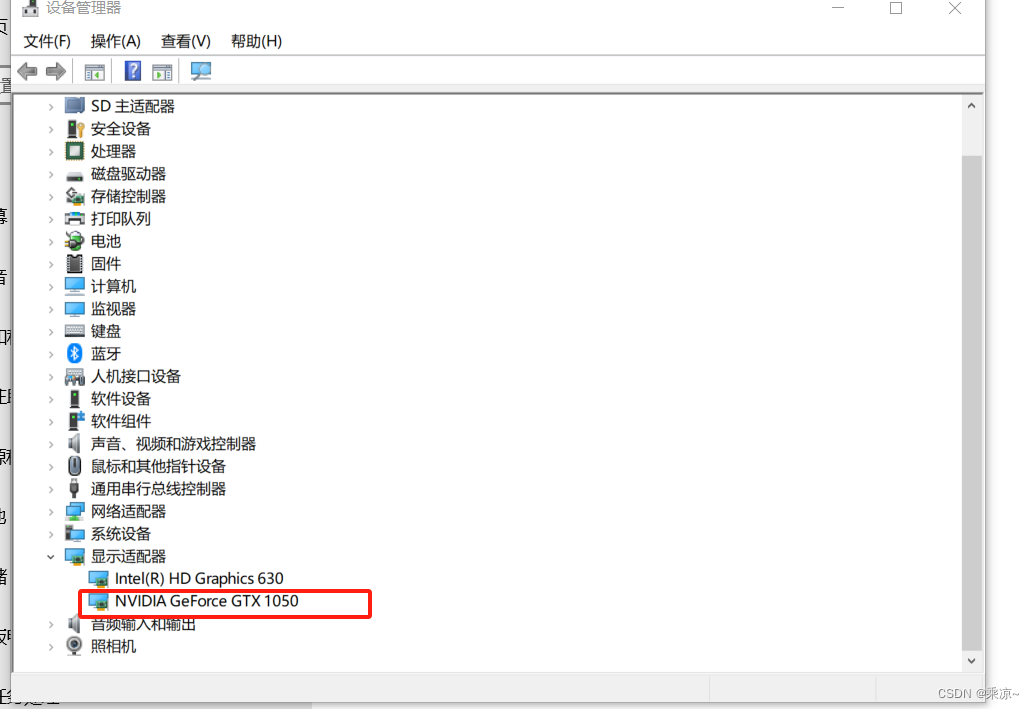
首先看一下我们笔记本当前的驱动版本:
此电脑->右键->属性->设备管理器->显示适配器:
打开后,点击“驱动程序”
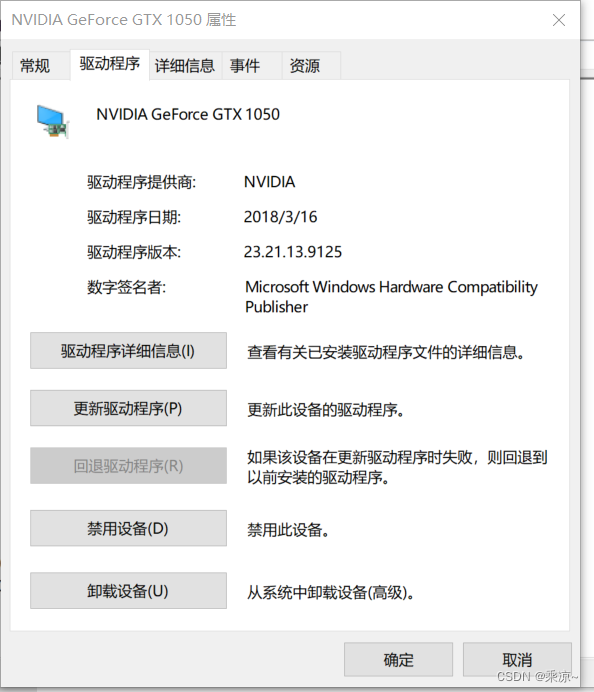
可以看到我的驱动程序是2018年3/16号的,非常古老了,所以我们去下载它的最新版;
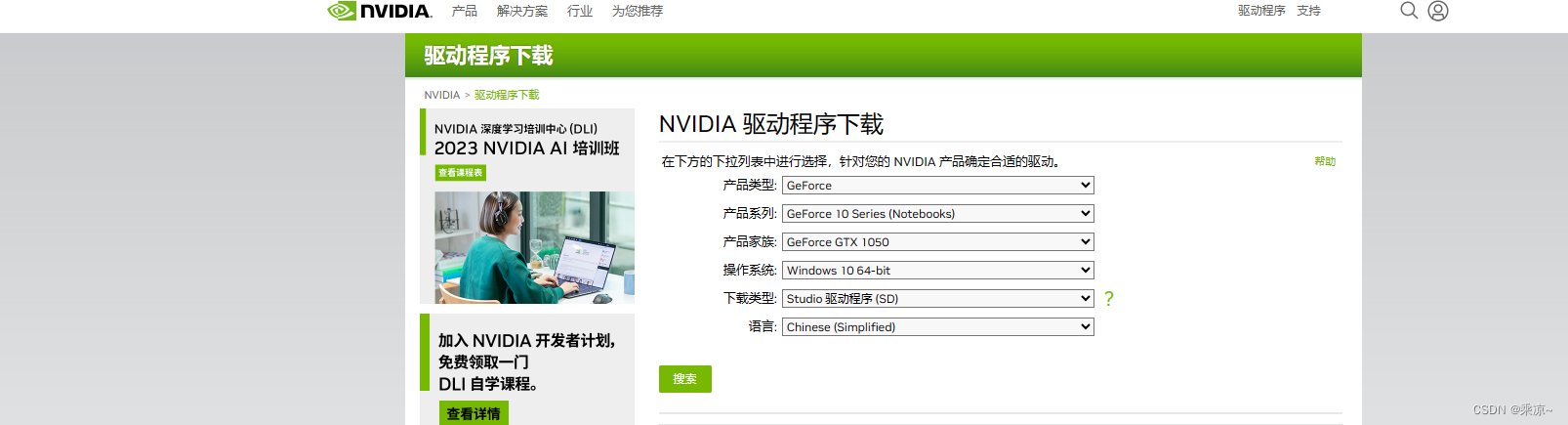
【NVIDIA下载网址】https://www.nvidia.cn

按照你笔记本的实际显卡进行选择:
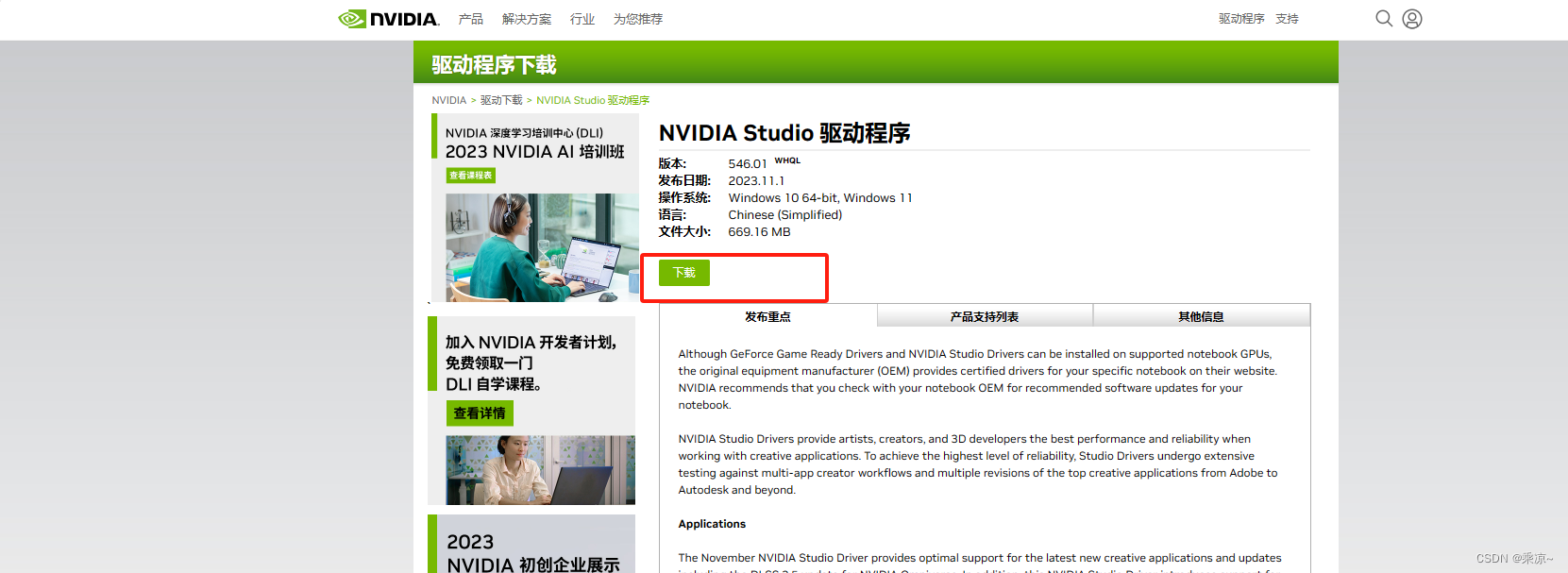
下载完成后如下所示:

双击打开,路径也不用修改:
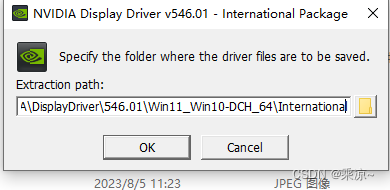
然后选择NVIDIA显卡驱动和GeForce Experience
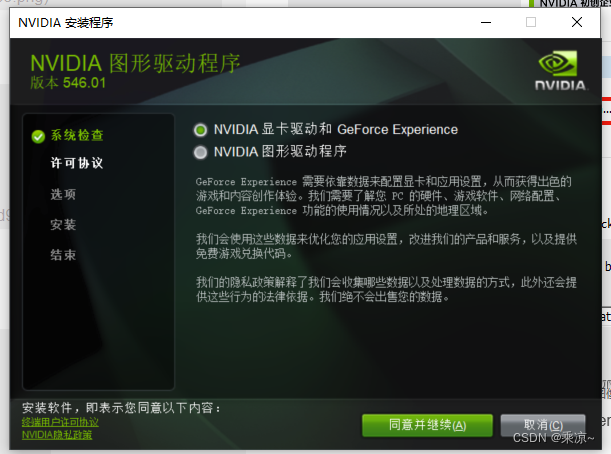
然后选择自定义安装:
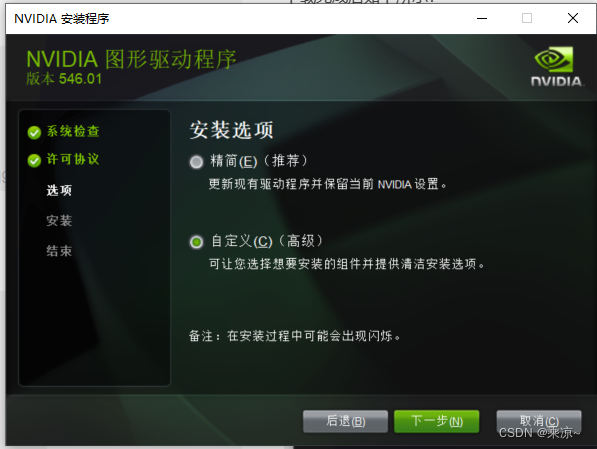
PhysX系统软件可以选择不安装,如果有USBC Driver,也可以选择不安装;
然后勾选执行清洁安装,下一步;等待安装完成即可:
安装完成后关闭即可。
2.1.3 安装Conda
接下来我们安装Conda,Conda是一个Python的包管理工具,什么系统都支持,
【ANACONDA下载网址】https://anaconda.org

直接点击下载即可。下载完成后如下图所示:

双击打开,基本按照给出的默认选项配置,无脑下一步即可:
安装完成后如下图所示:
安装完成后,一般会自己启动一次,通常默认会建立一个叫做Base的环境,如下图:
未来我们的Sable Diffusion会用它自己的环境,所以这里的Base对我们来说暂时不用太关心,直接关掉即可。
2.1.4 安装git工具–gitForWindows
【git工具下载网址】http://gitforwindows.org

直接点击下载即可;下载完成后如下图所示:

双击打开,按照它推荐的功能,基本保持所有的选项都是默认选项,无脑下一步即可。
完成后如下所示:
2.1.5 检查环境
至此,CUDA、NVIDA、ANACONDA以及gitForWindows我们已经安装完成了;
下面检查一下Anaconda Prompt和Conda的安装;
打开开式菜单,在Anaconda3文件夹下,找到Anaconda Prompt,如下图所示:
双击打开:

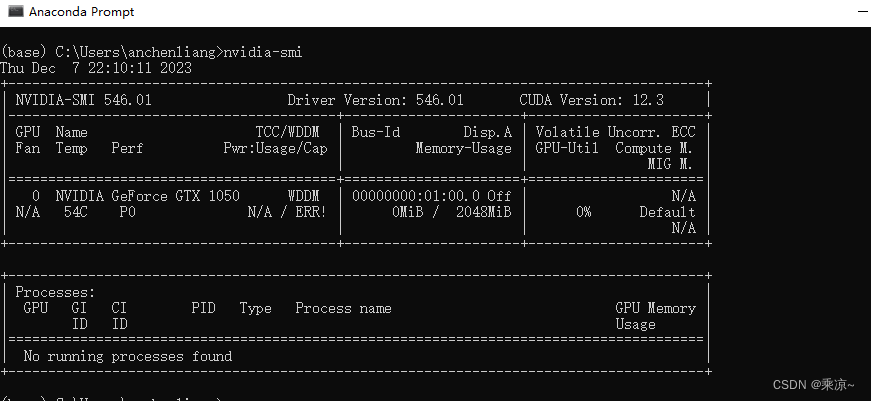
可以看到前面默认有个(base),指的是现在窗口使用的是Base的环境;
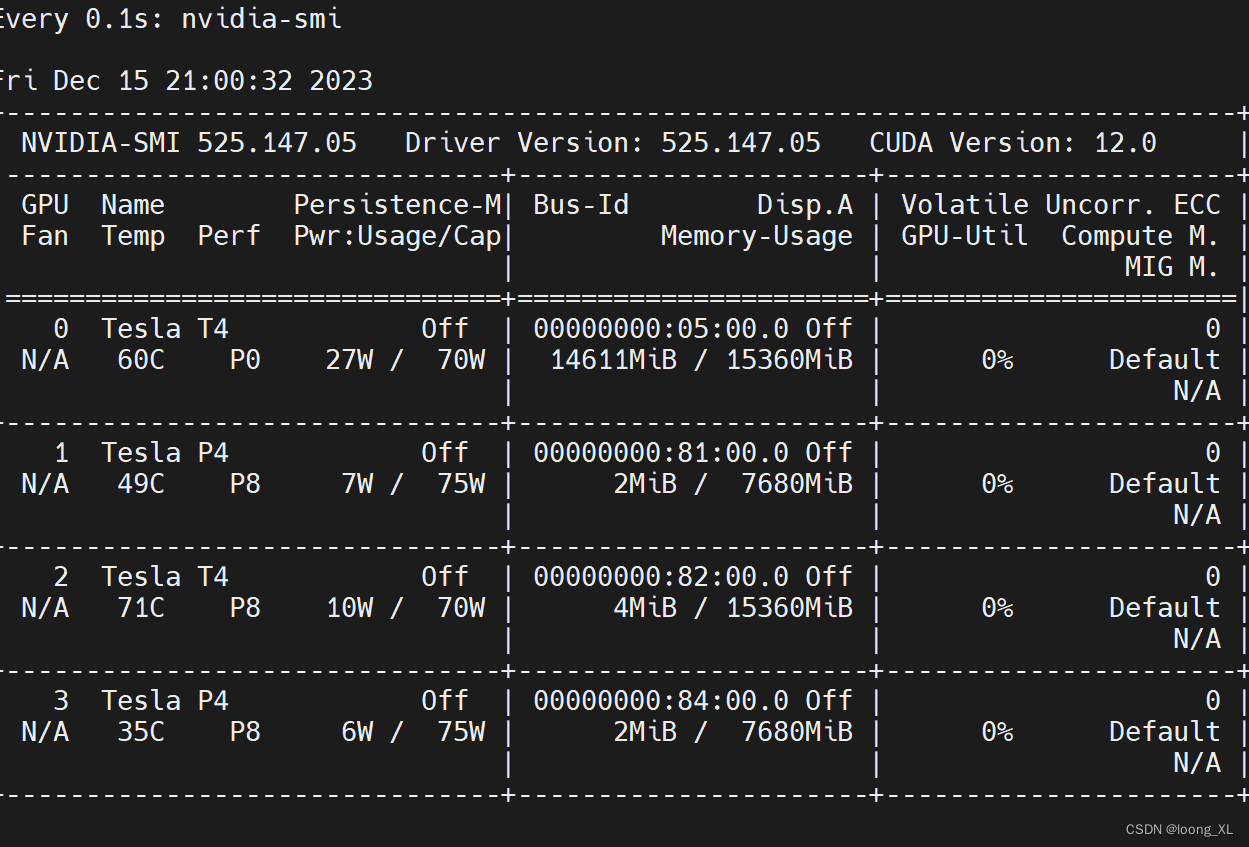
在上面输入nvidia-smi指令,检查一下当前的显卡驱动:
然后输入git指令,会发现git也开始工作了,如下图:
没什么问题。
2.2 配置Transformer环境变量
transformer是一个机器学习的框架,Gradio是它的一个可视化的部署,未来AI工具也都会用到这个工具;
我们现在E盘建立一个空的目录,我起名为transformerCache,用来存放那些大模型的;
该目录的路径为E:\transformerCache
然后点击:
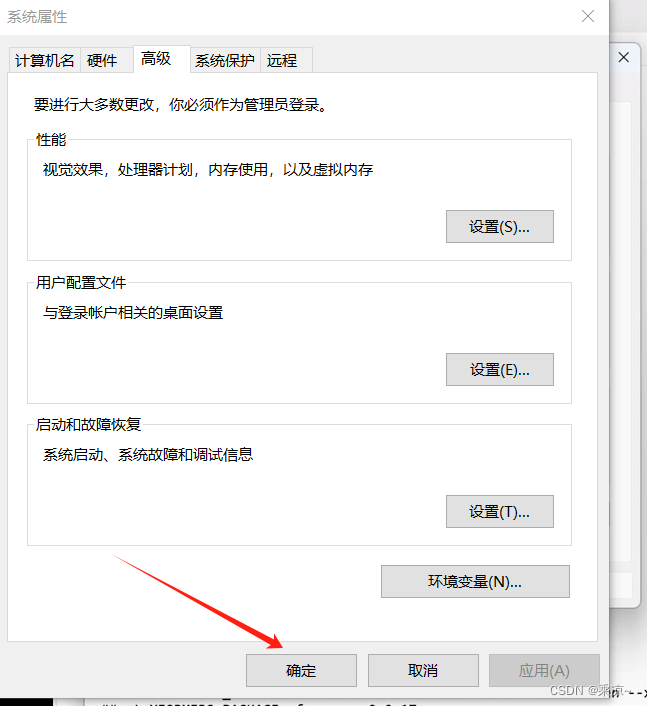
开始菜单->设置->系统->关于->高级系统设置->环境变量->系统变量->新建
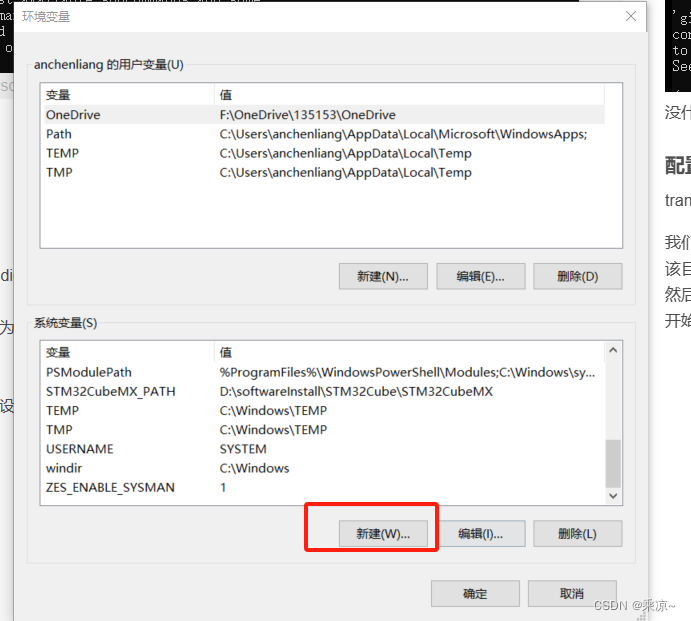
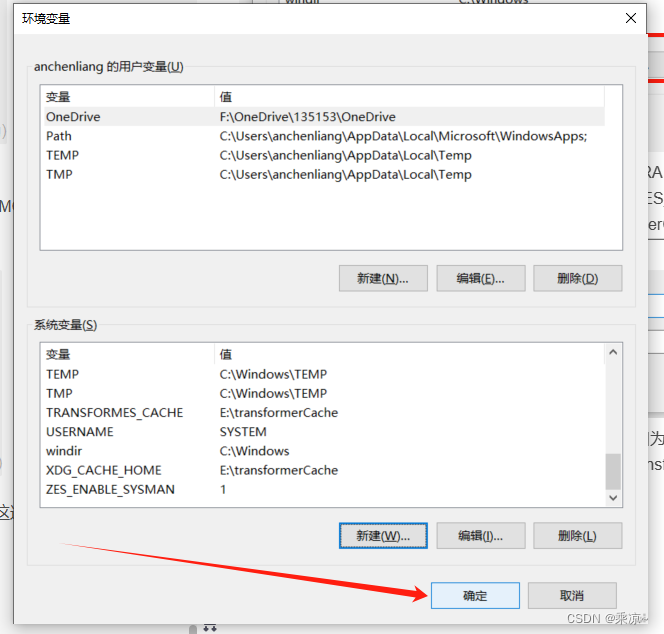
依次添加六个环境变量,变量名分别是PYTORCH_PRETRAINED_BERT_CACHE、PYTORCH_TRANSFORMERS_CACHE、TRANSFORMES_CACHE、XDG_CACHE_HOME、HF_MODULES_CACHE、HUGGINGFACE_HUB_CACHE,变量值均为E:\transformerCache,如下图所示:
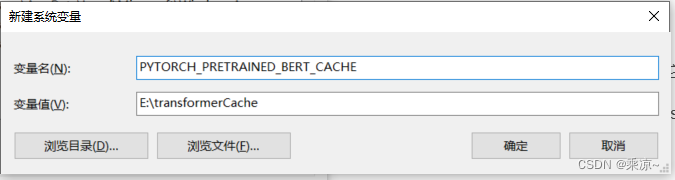
这个cache我们一般建议放在一个比较大一点的硬盘上,因为我们未来会有很多模型,从HavingFace这边去下载回来;会占用很大空间;所以这里我们把所有的环境变量都放在了E:\transformerCache里;
建好以后,点击确定即可:
2.3 安装SD WebUI
在Anaconda Prompt中,切换到E盘,并克隆Stable Diffusion代码到SDWebUI文件夹中,指令如下所示:
e:
dir
cd SDWebUI
dir
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
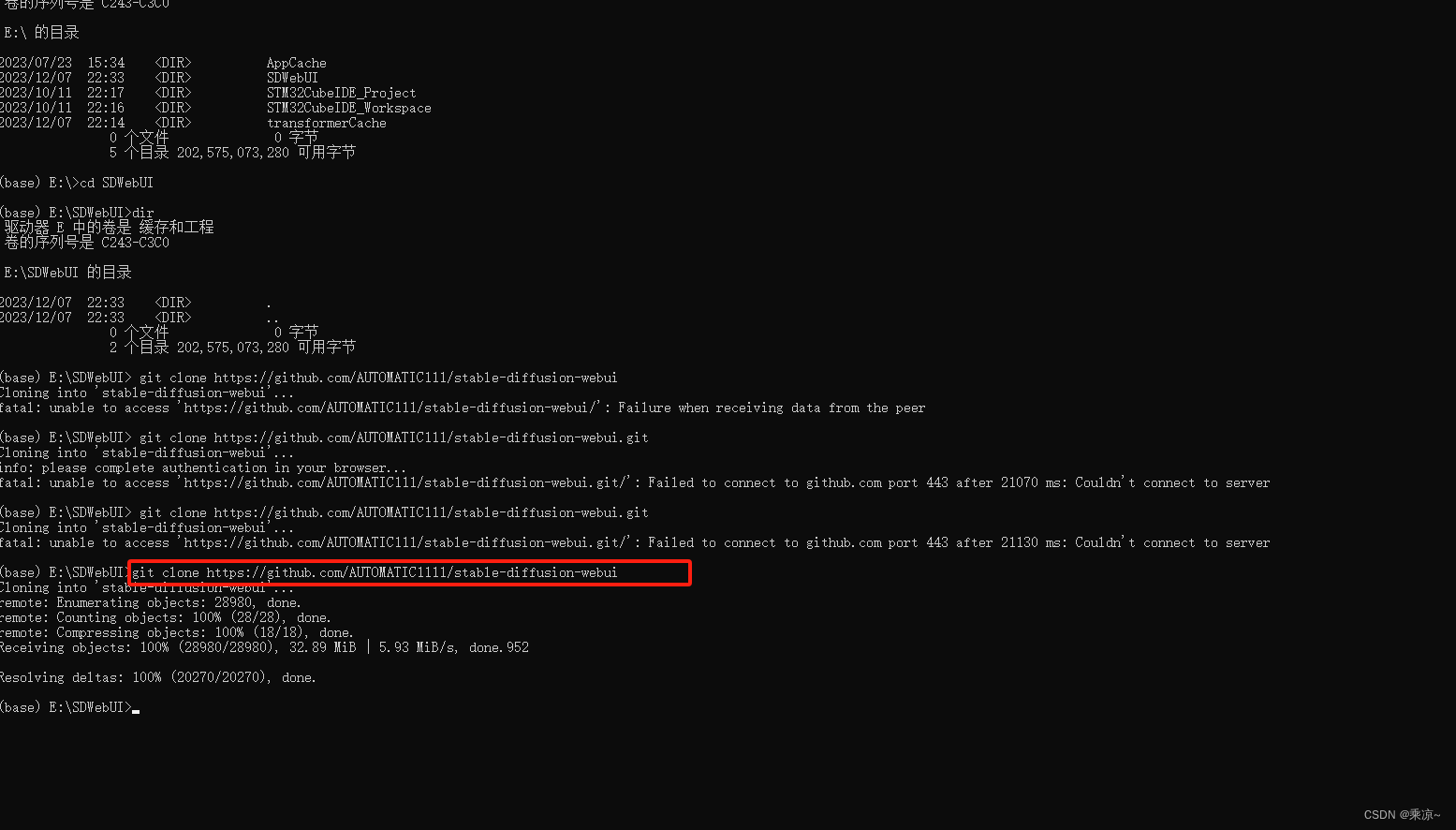
克隆完成后,我们打开stable-diffusion-webui,然后执行webui-user.bat:
cd stable-diffusion-webui
webui-user.bat

首次执行的时候,系统会检查当前的情况,如果没有自己的执行环境,系统会自动调用虚拟环境的命令,去创建一个适用于它自己的这么一个Python环境;所以这个脚本的过程基本是下载配置python环境、依赖包、更新python包管理器、下载所需模型(人脸恢复、嘴唇对齐、反推关键词、放大算法等模型)等等;
如果遇到报错,请去看2.4节;
下载模型中。。。。
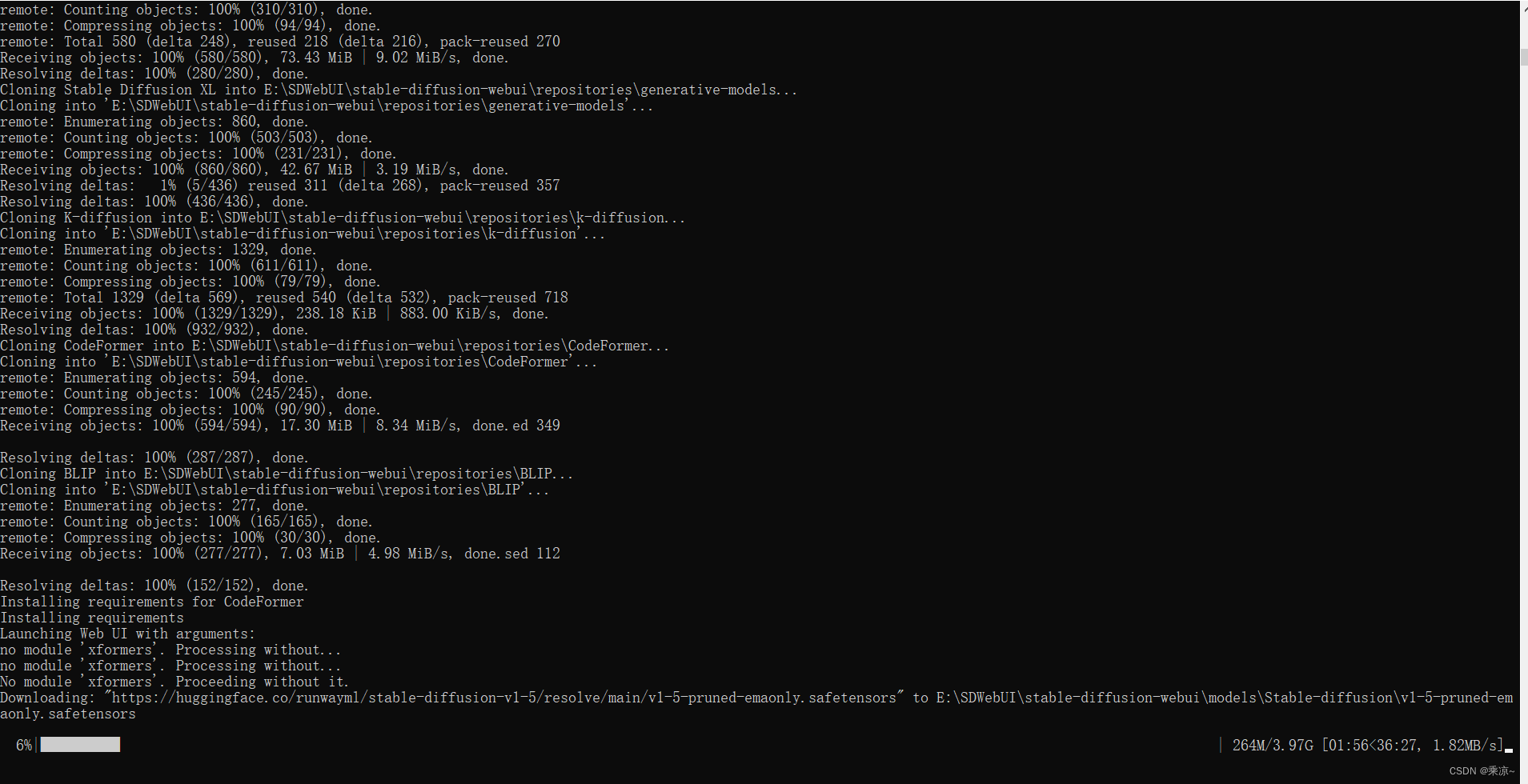
执行过程中需要保持网络环境的稳定;整个过程我是挂着科学上网执行的。
完成后如下图所示:
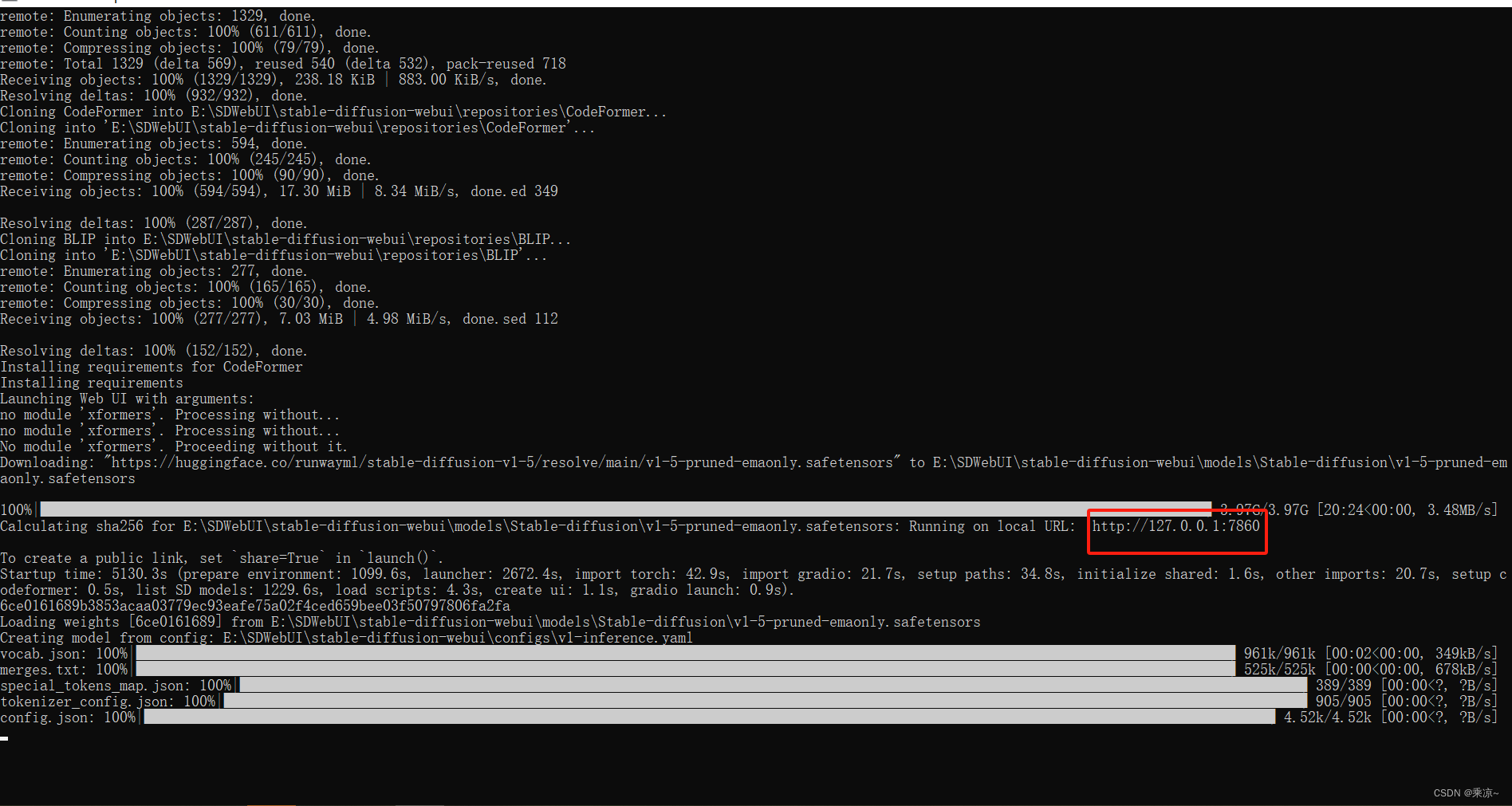
此时我们可以打开127.0.0.1:7860,并随便输入一个参数,来查看一下效果了:
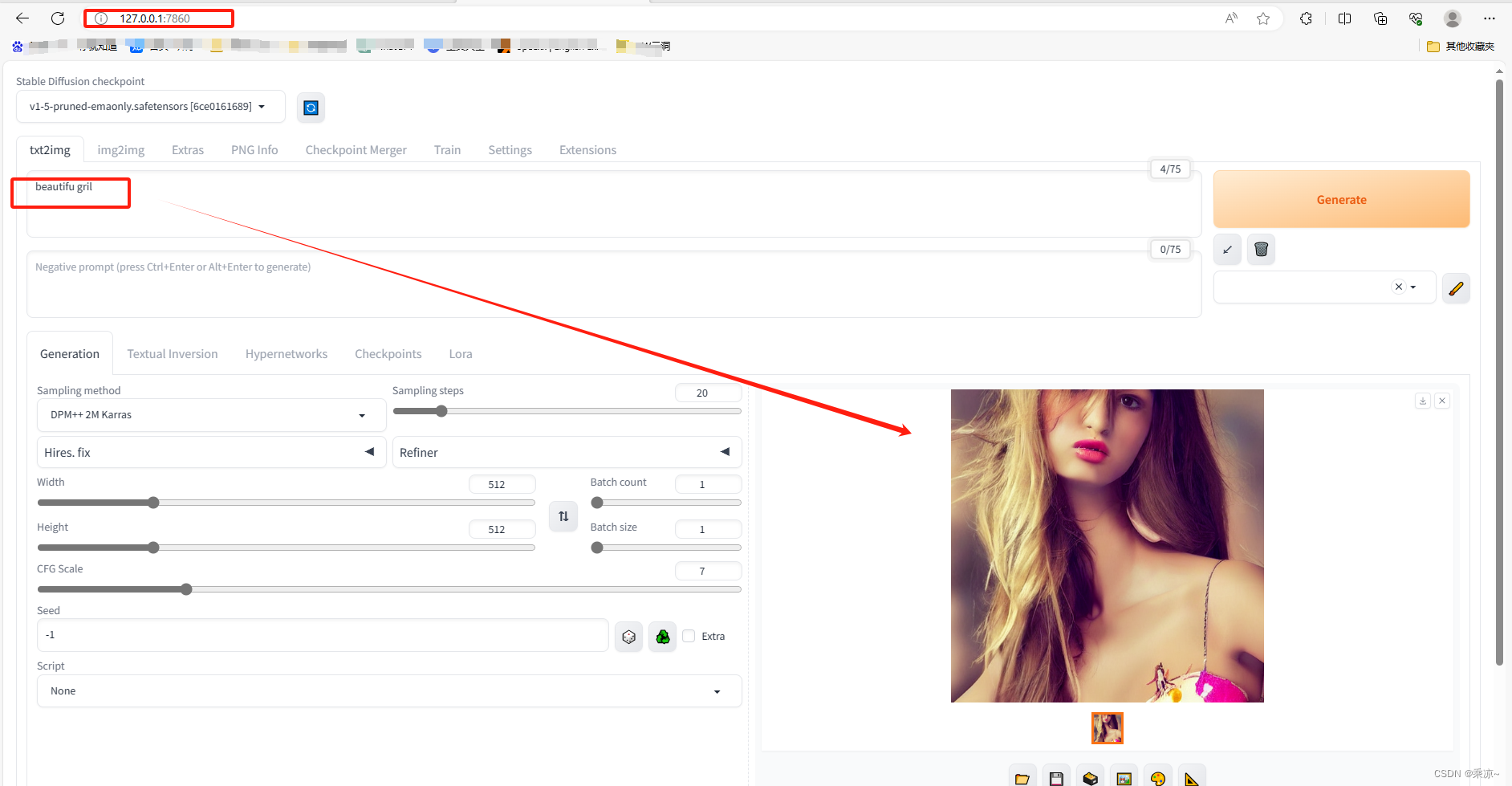
如果能生成图片,说明Web UI搭建成功了;
2.4 安装SD WebUI过程中遇到的问题
执行webui-user.bat的时候遇到报错:
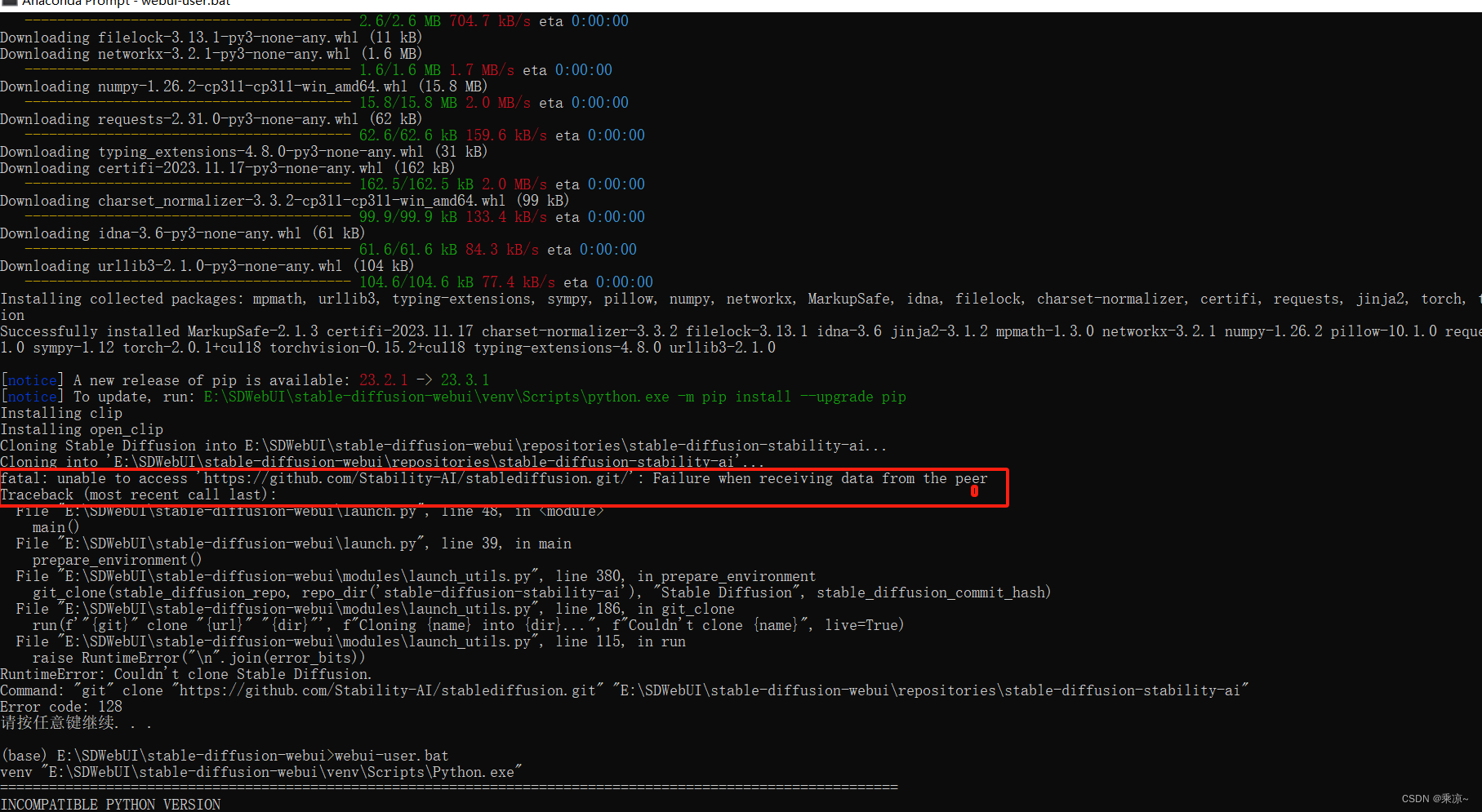
1、fatal: unable to access ‘https://github.com/Stability-AI/stablediffusion.git/’:
fatal: unable to access 'https://github.com/Stability-AI/stablediffusion.git/': Failure when receiving data from the peer
Traceback (most recent call last):
File "E:\SDWebUI\stable-diffusion-webui\launch.py", line 48, in <module>
main()
File "E:\SDWebUI\stable-diffusion-webui\launch.py", line 39, in main
prepare_environment()
File "E:\SDWebUI\stable-diffusion-webui\modules\launch_utils.py", line 380, in prepare_environment
git_clone(stable_diffusion_repo, repo_dir('stable-diffusion-stability-ai'), "Stable Diffusion", stable_diffusion_commit_hash)
File "E:\SDWebUI\stable-diffusion-webui\modules\launch_utils.py", line 186, in git_clone
run(f'"{git}" clone "{url}" "{dir}"', f"Cloning {name} into {dir}...", f"Couldn't clone {name}", live=True)
File "E:\SDWebUI\stable-diffusion-webui\modules\launch_utils.py", line 115, in run
raise RuntimeError("\n".join(error_bits))
RuntimeError: Couldn't clone Stable Diffusion.
Command: "git" clone "https://github.com/Stability-AI/stablediffusion.git" "E:\SDWebUI\stable-diffusion-webui\repositories\stable-diffusion-stability-ai"
Error code: 128
请按任意键继续. . .
解决:
在终端执行:
git config --global --unset http.proxy
git config --global --unset https.proxy
2、RuntimeError: Torch is not able to use GPU; add --skip-torch-cuda-test to COMMANDLINE_ARGS variable to disable this check
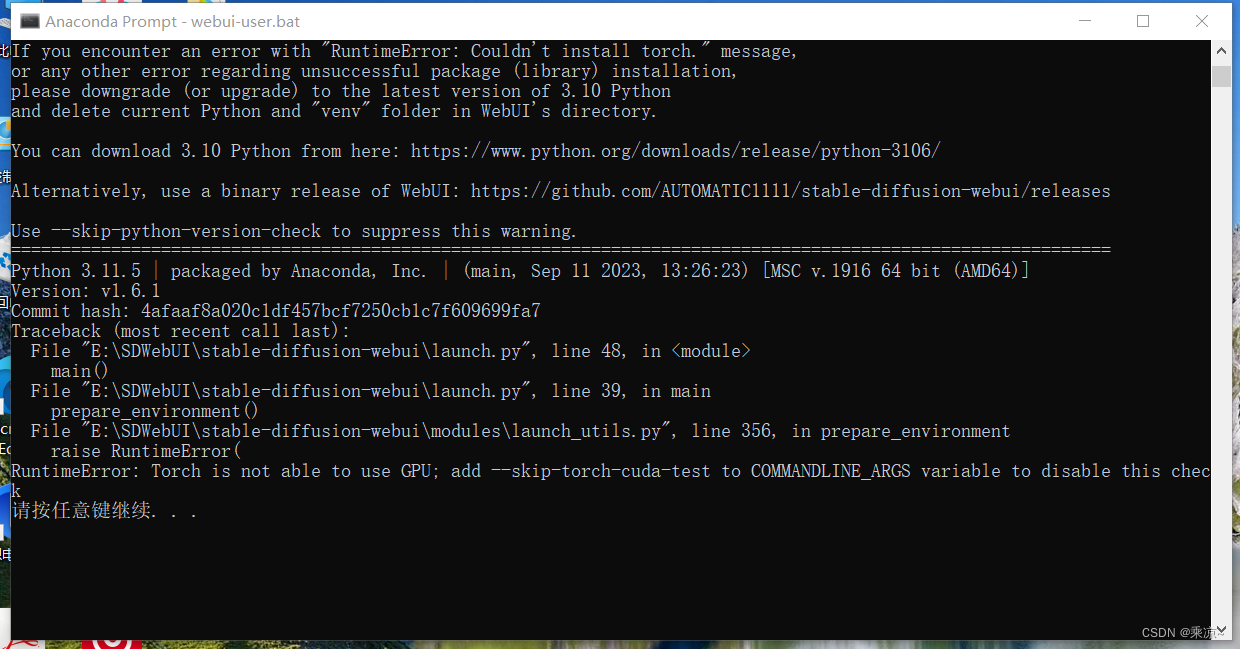
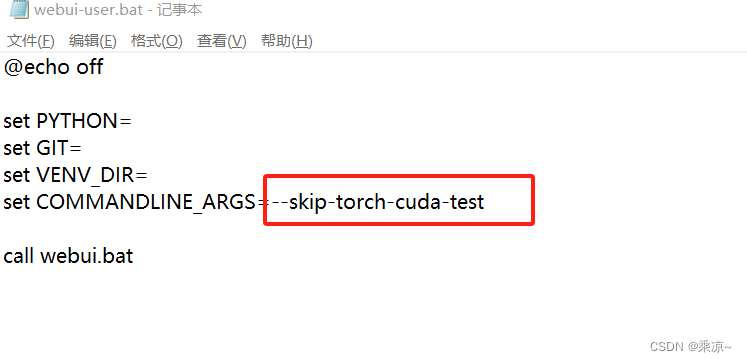
按照它给的提示,打开webui-user.bat脚本,在后面加上--skip-torch-cuda-test:
三、 参考
Stable Diffusion是什么意思?https://www.zhihu.com/question/561527911/answer/3119390120
【Stable Diffusion教程】01如何快速本地部署SD教学方法一:SD-WEBUI(包教包会,小白速来)