目录
首选运行位置
数据的本地化级别
谁来负责数据本地化
数据本地化执行流程
调优
代码中的设置方法
首选运行位置

上图红框为RDD的特性五:每个RDD的每个分区都有一组首选运行位置,用于标识RDD的这个分区数据最好能够在哪台主机上运行。通过RDD的首选运行位置可以让RDD的某个分区的计算任务直接在指定的主机上运行,从而实现了移动计算而不是移动数据的目的,减少了网络传输的开销,如Spark中HadoopRDD能够实现家装数据的任务在相应的数据节点上执行。
数据的本地化级别
package org.apache.spark.scheduler
import org.apache.spark.annotation.DeveloperApi
@DeveloperApi
object TaskLocality extends Enumeration {
// Process local is expected to be used ONLY within TaskSetManager for now.
val PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY = Value
type TaskLocality = Value
def isAllowed(constraint: TaskLocality, condition: TaskLocality): Boolean = {
condition <= constraint
}
}
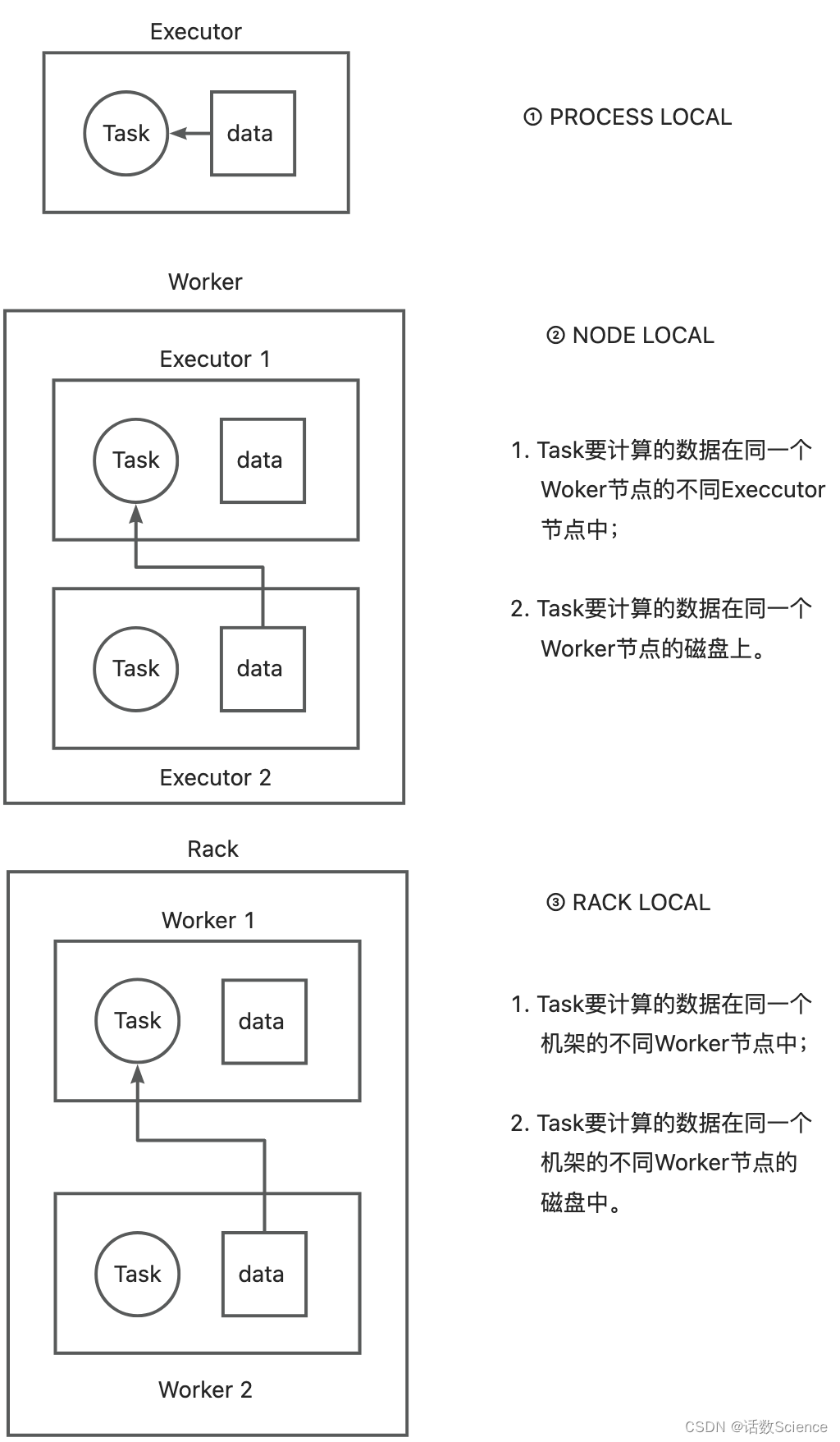
- PROCESS_LOCAL:进程本地化,表示 task 要计算的数据在同一个 Executor 中。
- NODE_LOCAL:节点本地化,速度稍慢,因为数据需要在不同的进程之间传递或从文件中读取。分为两种情况,第一种:task 要计算的数据是在同一个 worker 的不同 Executor 进程中。第二种:task 要计算的数据是在同一个 worker 的磁盘上,或在 HDFS 上恰好有 block 在同一个节点上。如果 Spark 要计算的数据来源于 HDFS 上,那么最好的本地化级别就是 NODE_LOCAL。
- NO_PREF:没有最佳位置,数据从哪访问都一样快,不需要位置优先。比如 Spark SQL 从 Mysql 中读取数据。
- RACK_LOCAL:机架本地化,数据在同一机架的不同节点上。需要通过网络传输数据以及文件 IO,比 NODE_LOCAL 慢。情况一:task 计算的数据在 worker2 的 EXecutor 中。情况二:task 计算的数据在 work2 的磁盘上。
- ANY:跨机架,数据在非同一机架的网络上,速度最慢。
谁来负责数据本地化
val rdd1 = sc.textFile("hdfs://...")
rdd1.cache()
rdd1.map.filter.count()上面这段简单的代码,背后其实做什么很多事情。Driver 的 TaskScheduler 在发送 task 之前,首先应该拿到 rdd1 数据所在的位置,rdd1 封装了这个文件所对应的 block 的位置,DAGScheduler 通过调用 getPrerredLocations() 拿到 partition 所对应的数据的位置,TaskScheduler 根据这些位置来发送相应的 task。
具体的解释:
DAGScheduler 切割Job,划分Stage, 通过调用 submitStage 来提交一个Stage 对应的 tasks,submitStage 会调用 submitMissingTasks, submitMissingTasks 确定每个需要计算的 task 的preferredLocations,通过调用 getPreferrdeLocations() 得到 partition 的优先位置,就是这个 partition 对应的 task 的优先位置,对于要提交到 TaskScheduler 的 TaskSet 中的每一个task,该 task 优先位置与其对应的 partition 对应的优先位置一致。
TaskScheduler 接收到了 TaskSet 后,TaskSchedulerImpl 会为每个 TaskSet 创建一个 TaskSetManager 对象,该对象包含taskSet 所有 tasks,并管理这些 tasks 的执行,其中就包括计算 TaskSetManager 中的 tasks 都有哪些 locality levels,以便在调度和延迟调度 tasks 时发挥作用。
总的来说,Spark 中的数据本地化是由 DAGScheduler 和 TaskScheduler 共同负责的。
数据本地化执行流程

第一步:PROCESS_LOCAL
TaskScheduler 根据数据的位置向数据节点发送 task 任务。如果这个任务在 worker1 的 Executor 中等待了 3 秒。(默认的,可以通过spark.locality.wait 来设置),可以通过 SparkConf() 来修改,重试了 5 次之后,还是无法执行,TaskScheduler 就会降低数据本地化的级别,从 PROCESS_LOCAL 降到 NODE_LOCAL。
第二步:NODE_LOCAL
TaskScheduler 重新发送 task 到 worker1 中的 Executor2 中执行,如果 task 在worker1 的 Executor2 中等待了 3 秒,重试了 5 次,还是无法执行,TaskScheduler 就会降低数据本地化的级别,从 NODE_LOCAL 降到 RACK_LOCAL。
第三步:RACK_LOCAL
TaskScheduler重新发送 task 到 worker2 中的 Executor1 中执行。
第四步:
当 task 分配完成之后,task 会通过所在的 worker 的 Executor 中的 BlockManager 来获取数据。如果 BlockManager 发现自己没有数据,那么它会调用 getRemote() 方法,通过 ConnectionManager 与原 task 所在节点的 BlockManager 中的 ConnectionManager先建立连接,然后通过TransferService(网络传输组件)获取数据,通过网络传输回task所在节点(这时候性能大幅下降,大量的网络IO占用资源),计算后的结果返回给Driver。这一步很像 shuffle 的文件寻址流程。
调优
TaskScheduler在发送task的时候,会根据数据所在的节点发送task,这时候的数据本地化的级别是最高的,如果这个task在这个Executor中等待了3秒,重试发射了5次还是依然无法执行,那么TaskScheduler就会认为这个Executor的计算资源满了,TaskScheduler会降低一级数据本地化的级别,重新发送task到其他的Executor中执行,如果还是依然无法执行,那么继续降低数据本地化的级别...
如果想让每一个 task 都能拿到最好的数据本地化级别,那么调优点就是等待时间加长。注意!如果过度调大等待时间,虽然为每一个 task 都拿到了最好的数据本地化级别,但是我们 job 执行的时间也会随之延长。
官方参数:Configuration - Spark 3.5.0 Documentation
spark.locality.wait | 3s | How long to wait to launch a data-local task before giving up and launching it on a less-local node. The same wait will be used to step through multiple locality levels (process-local, node-local, rack-local and then any). It is also possible to customize the waiting time for each level by setting spark.locality.wait.node, etc. You should increase this setting if your tasks are long and see poor locality, but the default usually works well. | 0.5.0 |
spark.locality.wait.node | spark.locality.wait | Customize the locality wait for node locality. For example, you can set this to 0 to skip node locality and search immediately for rack locality (if your cluster has rack information). | 0.8.0 |
spark.locality.wait.process | spark.locality.wait | Customize the locality wait for process locality. This affects tasks that attempt to access cached data in a particular executor process. | 0.8.0 |
spark.locality.wait.rack | spark.locality.wait | Customize the locality wait for rack locality. | 0.8.0 |
代码中的设置方法
new SparkConf.set("spark.locality.wait","100") //默认3秒