scrapy处理 post 请求
爬取百度翻译界面
目录
1.创建项目及爬虫文件
2.发送post请求
1.创建项目及爬虫文件
scrapy startproject scrapy_104
scrapy genspider translate fanyi.baidu.com
2.发送请求
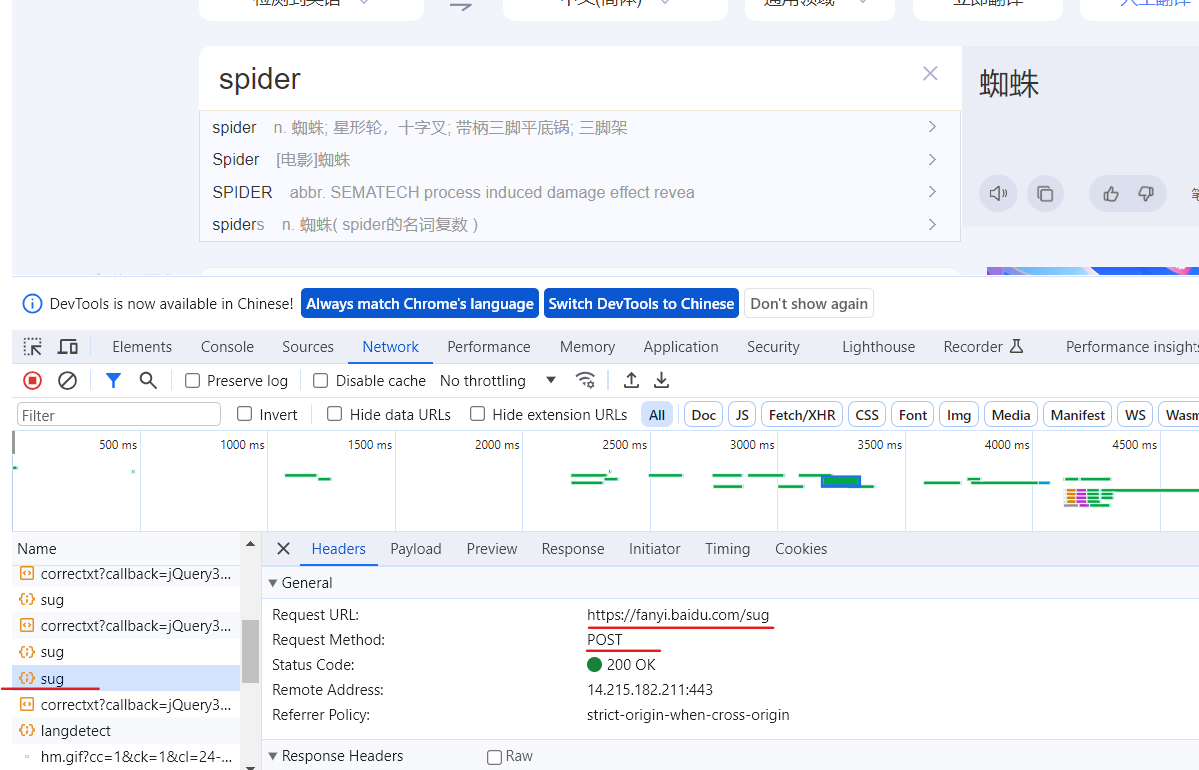
post请求需要传递参数,所以就不能用start_urls和parse函数了,这里使用start_requests函数给url添加参数。
class TranslateSpider(scrapy.Spider):
name = 'translate'
allowed_domains = ['fanyi.baidu.com']
# start_urls = ['http://fanyi.baidu.com/']
def start_requests(self):
url = 'http://fanyi.baidu.com/sug'
data = {
'kw':'spider'
}
yield scrapy.FormRequest(url=url, formdata=data,callback=self.parse_second)
def parse_second(self, response):
content = response.text
# print(content) # 存在编码问题
obj = json.loads(content,encoding='utf-8')
print(obj)这样就获取到了

![壹[1],函数:ReadImage](https://img-blog.csdnimg.cn/direct/f2d632ecfd9d4990b4d6a66dca694ab1.png)