前言
知识扩展
早在 2015 年 5 月,Kubernetes 在 Google 上的搜索热度就已经超过了 Mesos 和 Docker Swarm,从那儿之后更是一路飙升,将对手甩开了十几条街,容器编排引擎领域的三足鼎立时代结束。

目前,AWS、Azure、Google、阿里云、腾讯云等主流公有云提供的是基于 Kubernetes 的容器服务;Rancher、CoreOS、IBM、Mirantis、Oracle、Red Hat、VMWare 等无数厂商也在大力研发和推广基于 Kubernetes 的容器 CaaS 或 PaaS 产品。可以说,Kubernetes 是当前容器行业最炙手可热的明星。 Google 的数据中心里运行着超过 20 亿个容器,而且 Google 十年前就开始使用容器技术。最初,Google 开发了一个叫 Borg 的系统(现在命名为 Omega)来调度如此庞大数量的容器和工作负载。在积累了这么多年的经验后,Google 决定重写这个容器管理系统,并将其贡献到开源社区,让全世界都能受益。这个项目就是 Kubernetes。简单的讲,Kubernetes 是 Google Omega 的开源版本。跟很多基础设施领域先有工程实践、后有方法论的发展路线不同,Kubernetes 项目的理论基础则要比工程实践走得靠前得多,这当然要归功于 Google 公司在 2015 年 4 月发布的 Borg 论文了。Borg 系统,一直以来都被誉为 Google 公司内部最强大的"秘密武器"。虽然略显夸张,但这个说法倒不算是吹牛。因为,相比于 Spanner、BigTable 等相对上层的项目,Borg 要承担的责任,是承载 Google 公司整个基础设施的核心依赖。在 Google 公司已经公开发表的基础设施体系论文中,Borg 项目当仁不让地位居整个基础设施技术栈的最底层。 由于这样的定位,Borg 可以说是 Google 最不可能开源的一个项目。而幸运地是,得益于 Docker 项目和容器技术的风靡,它却终于得以以另一种方式与开源社区见面,这个方式就是 Kubernetes 项目。 所以,相比于"小打小闹"的 Docker 公司、"旧瓶装新酒"的 Mesos 社区,Kubernetes 项目从一开始就比较幸运地站上了一个他人难以企及的高度:在它的成长阶段,这个项目每一个核心特性的提出,几乎都脱胎于 Borg/Omega 系统的设计与经验。更重要的是,这些特性在开源社区落地的过程中,又在整个社区的合力之下得到了极大的改进,修复了很多当年遗留在 Borg 体系中的缺陷和问题。 所以,尽管在发布之初被批评是"曲高和寡",但是在逐渐觉察到 Docker 技术栈的"稚嫩"和 Mesos 社区的"老迈"之后,这个社区很快就明白了:k8s 项目在 Borg 体系的指导下,体现出了一种独有的"先进性"与"完备性",而这些特质才是一个基础设施领域开源项目赖以生存的核心价值。
什么是编排
一个正在运行的 Linux 容器,可以分成两部分看待: 1. 容器的静态视图 一组联合挂载在 /var/lib/docker/aufs/mnt 上的 rootfs,这一部分称为"容器镜像"(Container Image) 2. 容器的动态视图 一个由 Namespace+Cgroups 构成的隔离环境,这一部分称为"容器运行时"(Container Runtime) 作为一名开发者,其实并不关心容器运行时的差异。在整个"开发 - 测试 - 发布"的流程中,真正承载着容器信息进行传递的,是容器镜像,而不是容器运行时。这正是容器技术圈在 Docker 项目成功后不久,就迅速走向了"容器编排"这个"上层建筑"的主要原因:作为一家云服务商或者基础设施提供商,我只要能够将用户提交的 Docker 镜像以容器的方式运行起来,就能成为这个非常热闹的容器生态图上的一个承载点,从而将整个容器技术栈上的价值,沉淀在我的这个节点上。 更重要的是,只要从这个承载点向 Docker 镜像制作者和使用者方向回溯,整条路径上的各个服务节点,比如 CI/CD、监控、安全、网络、存储等等,都有可以发挥和盈利的余地。这个逻辑,正是所有云计算提供商如此热衷于容器技术的重要原因:通过容器镜像,它们可以和潜在用户(即,开发者)直接关联起来。 从一个开发者和单一的容器镜像,到无数开发者和庞大的容器集群,容器技术实现了从"容器"到"容器云"的飞跃,标志着它真正得到了市场和生态的认可。这样,容器就从一个开发者手里的小工具,一跃成为了云计算领域的绝对主角;而能够定义容器组织和管理规范的"容器编排"技术,则当仁不让地坐上了容器技术领域的"头把交椅"。 最具代表性的容器编排工具: 1. Docker 公司的 Compose+Swarm 组合 2. Google 与 RedHat 公司共同主导的 Kubernetes 项目
google与k8s
事实并非如此 下回分解 2014 年 6 月,基础设施领域的翘楚 Google 公司突然发力,正式宣告了一个名叫 Kubernetes 项目的诞生。这个项目,不仅挽救了当时的 CoreOS 和 RedHat,还如同当年 Docker 项目的横空出世一样,再一次改变了整个容器市场的格局。这段时间,也正是 Docker 生态创业公司们的春天,大量围绕着 Docker 项目的网络、存储、监控、CI/CD,甚至 UI 项目纷纷出台,也涌现出了很多 Rancher、Tutum 这样在开源与商业上均取得了巨大成功的创业公司。 在 2014~2015 年间,整个容器社区可谓热闹非凡。这令人兴奋的繁荣背后,却浮现出了更多的担忧。这其中最主要的负面情绪,是对 Docker 公司商业化战略的种种顾虑。事实上,很多从业者也都看得明白,Docker 项目此时已经成为 Docker 公司一个商业产品。而开源,只是 Docker 公司吸引开发者群体的一个重要手段。不过这么多年来,开源社区的商业化其实都是类似的思路,无非是高不高调、心不心急的问题罢了。 而真正令大多数人不满意的是,Docker 公司在 Docker 开源项目的发展上,始终保持着绝对的权威和发言权,并在多个场合用实际行动挑战到了其他玩家(比如,CoreOS、RedHat,甚至谷歌和微软)的切身利益。那么,这个时候,大家的不满也就不再是在 GitHub 上发发牢骚这么简单了。 相信很多容器领域的老玩家们都听说过,Docker 项目刚刚兴起时,Google 也开源了一个在内部使用多年、经历过生产环境验证的 Linux 容器:lmctfy(Let Me Container That For You)。然而,面对 Docker 项目的强势崛起,这个对用户没那么友好的 Google 容器项目根本没有招架之力。所以,知难而退的 Google 公司,向 Docker 公司表示了合作的愿望:关停这个项目,和 Docker 公司共同推进一个中立的容器运行时(container runtime)库作为 Docker 项目的核心依赖。不过,Docker 公司并没有认同这个明显会削弱自己地位的提议,还在不久后,自己发布了一个容器运行时库 Libcontainer。这次匆忙的、由一家主导的、并带有战略性考量的重构,成了 Libcontainer 被社区长期诟病代码可读性差、可维护性不强的一个重要原因。 至此,Docker 公司在容器运行时层面上的强硬态度,以及 Docker 项目在高速迭代中表现出来的不稳定和频繁变更的问题,开始让社区叫苦不迭。这种情绪在 2015 年达到了一个高潮,容器领域的其他几位玩家开始商议"切割"Docker 项目的话语权。而"切割"的手段也非常经典,那就是成立一个中立的基金会。于是,2015 年 6 月 22 日,由 Docker 公司牵头,CoreOS、Google、RedHat 等公司共同宣布,Docker 公司将 Libcontainer 捐出,并改名为 RunC 项目,交由一个完全中立的基金会管理,然后以 RunC 为依据,大家共同制定一套容器和镜像的标准和规范。这套标准和规范,就是 OCI( Open Container Initiative )。OCI 的提出,意在将容器运行时和镜像的实现从 Docker 项目中完全剥离出来。这样做,一方面可以改善 Docker 公司在容器技术上一家独大的现状,另一方面也为其他玩家不依赖于 Docker 项目构建各自的平台层能力提供了可能。 不过,OCI 的成立更多的是这些容器玩家出于自身利益进行干涉的一个妥协结果。尽管 Docker 是 OCI 的发起者和创始成员,它却很少在 OCI 的技术推进和标准制定等事务上扮演关键角色,也没有动力去积极地推进这些所谓的标准。这也是迄今为止 OCI 组织效率持续低下的根本原因。OCI 并没能改变 Docker 公司在容器领域一家独大的现状,Google 和 RedHat 等公司于是把第二把武器摆上了台面。 Docker 之所以不担心 OCI 的威胁,原因就在于它的 Docker 项目是容器生态的事实标准,而它所维护的 Docker 社区也足够庞大。可是,一旦这场斗争被转移到容器之上的平台层,或者说 PaaS 层,Docker 公司的竞争优势便立刻捉襟见肘了。在这个领域里,像 Google 和 RedHat 这样的成熟公司,都拥有着深厚的技术积累;而像 CoreOS 这样的创业公司,也拥有像 Etcd 这样被广泛使用的开源基础设施项目。可是 Docker 公司却只有一个 Swarm。 所以这次,Google、RedHat 等开源基础设施领域玩家们,共同牵头发起了一个名为 CNCF(Cloud Native Computing Foundation)的基金会。这个基金会的目的其实很容易理解:它希望,以 Kubernetes 项目为基础,建立一个由开源基础设施领域厂商主导的、按照独立基金会方式运营的平台级社区,来对抗以 Docker 公司为核心的容器商业生态。 为了打造出一个围绕 Kubernetes 项目的"护城河",CNCF 社区就需要至少确保两件事情:Kubernetes 项目必须能够在容器编排领域取得足够大的竞争优势;CNCF 社区必须以 Kubernetes 项目为核心,覆盖足够多的场景。CNCF 社区如何解决 Kubernetes 项目在编排领域的竞争力的问题: 在容器编排领域,Kubernetes 项目需要面对来自 Docker 公司和 Mesos 社区两个方向的压力。Swarm 和 Mesos 实际上分别从两个不同的方向讲出了自己最擅长的故事:Swarm 擅长的是跟 Docker 生态的无缝集成,而 Mesos 擅长的则是大规模集群的调度与管理。 这两个方向,也是大多数人做容器集群管理项目时最容易想到的两个出发点。也正因为如此,Kubernetes 项目如果继续在这两个方向上做文章恐怕就不太明智了。 Kubernetes 选择的应对方式是:Borg k8s 项目大多来自于 Borg 和 Omega 系统的内部特性,这些特性落到 k8s 项目上,就是 Pod、Sidecar 等功能和设计模式。 这就解释了,为什么 Kubernetes 发布后,很多人"抱怨"其设计思想过于"超前"的原因:Kubernetes 项目的基础特性,并不是几个工程师突然"拍脑袋"想出来的东西,而是 Google 公司在容器化基础设施领域多年来实践经验的沉淀与升华。这正是 Kubernetes 项目能够从一开始就避免同 Swarm 和 Mesos 社区同质化的重要手段。 CNCF 接下来的任务是如何把这些先进的思想通过技术手段在开源社区落地,并培育出一个认同这些理念的生态? RedHat 发挥了重要作用。当时,Kubernetes 团队规模很小,能够投入的工程能力十分紧张,这恰恰是 RedHat 的长处。RedHat 更是世界上为数不多、能真正理解开源社区运作和项目研发真谛的合作伙伴。RedHat 与 Google 联盟的成立,不仅保证了 RedHat 在 Kubernetes 项目上的影响力,也正式开启了容器编排领域"三国鼎立"的局面。 Mesos 社区与容器技术的关系,更像是"借势",而不是这个领域真正的参与者和领导者。这个事实,加上它所属的 Apache 社区固有的封闭性,导致了 Mesos 社区虽然技术最为成熟,却在容器编排领域鲜有创新。 一开始,Docker 公司就把应对 Kubernetes 项目的竞争摆在首要位置: 一方面,不断强调"Docker Native"的"重要性"一方面,与 k8s 项目在多个场合进行了直接的碰撞。这次竞争的发展态势,很快就超过了 Docker 公司的预期。 Kubernetes 项目并没有跟 Swarm 项目展开同质化的竞争所以 "Docker Native"的说辞并没有太大的杀伤力相反 k8s 项目让人耳目一新的设计理念和号召力,很快就构建出了一个与众不同的容器编排与管理的生态。 Kubernetes 项目在 GitHub 上的各项指标开始一骑绝尘,将 Swarm 项目远远地甩在了身后。 CNCF 社区如何解决第二个问题: 在已经囊括了容器监控事实标准的 Prometheus 项目后,CNCF 社区迅速在成员项目中添加了 Fluentd、OpenTracing、CNI 等一系列容器生态的知名工具和项目。而在看到了 CNCF 社区对用户表现出来的巨大吸引力之后,大量的公司和创业团队也开始专门针对 CNCF 社区而非 Docker 公司制定推广策略。 2016 年,Docker 公司宣布了一个震惊所有人的计划:放弃现有的 Swarm 项目,将容器编排和集群管理功能全部内置到 Docker 项目当中。Docker 公司意识到了 Swarm 项目目前唯一的竞争优势,就是跟 Docker 项目的无缝集成。那么,如何让这种优势最大化呢?那就是把 Swarm 内置到 Docker 项目当中。从工程角度来看,这种做法的风险很大。内置容器编排、集群管理和负载均衡能力,固然可以使得 Docker 项目的边界直接扩大到一个完整的 PaaS 项目的范畴,但这种变更带来的技术复杂度和维护难度,长远来看对 Docker 项目是不利的。不过,在当时的大环境下,Docker 公司的选择恐怕也带有一丝孤注一掷的意味。 k8s 的应对策略: 是反其道而行之,开始在整个社区推进"民主化"架构,即:从 API 到容器运行时的每一层,Kubernetes 项目都为开发者暴露出了可以扩展的插件机制,鼓励用户通过代码的方式介入到 Kubernetes 项目的每一个阶段。 Kubernetes 项目的这个变革的效果立竿见影,很快在整个容器社区中催生出了大量的、基于 Kubernetes API 和扩展接口的二次创新工作,比如: 目前热度极高的微服务治理项目 Istio;被广泛采用的有状态应用部署框架 Operator;还有像 Rook 这样的开源创业项目,它通过 Kubernetes 的可扩展接口,把 Ceph 这样的重量级产品封装成了简单易用的容器存储插件。 在鼓励二次创新的整体氛围当中,k8s 社区在 2016 年后得到了空前的发展。更重要的是,不同于之前局限于"打包、发布"这样的 PaaS 化路线,这一次容器社区的繁荣,是一次完全以 Kubernetes 项目为核心的"百花争鸣"。面对 Kubernetes 社区的崛起和壮大,Docker 公司也不得不面对自己豪赌失败的现实。但在早前拒绝了微软的天价收购之后,Docker 公司实际上已经没有什么回旋余地,只能选择逐步放弃开源社区而专注于自己的商业化转型。 所以,从 2017 年开始,Docker 公司先是将 Docker 项目的容器运行时部分 Containerd 捐赠给 CNCF 社区,标志着 Docker 项目已经全面升级成为一个 PaaS 平台;紧接着,Docker 公司宣布将 Docker 项目改名为 Moby,然后交给社区自行维护,而 Docker 公司的商业产品将占有 Docker 这个注册商标。 Docker 公司这些举措背后的含义非常明确:它将全面放弃在开源社区同 Kubernetes 生态的竞争,转而专注于自己的商业业务,并且通过将 Docker 项目改名为 Moby 的举动,将原本属于 Docker 社区的用户转化成了自己的客户。2017 年 10 月,Docker 公司出人意料地宣布,将在自己的主打产品 Docker 企业版中内置 Kubernetes 项目,这标志着持续了近两年之久的"编排之争"至此落下帷幕。 2018 年 1 月 30 日,RedHat 宣布斥资 2.5 亿美元收购 CoreOS。 2018 年 3 月 28 日,这一切纷争的始作俑者,Docker 公司的 CTO Solomon Hykes 宣布辞职,曾经纷纷扰扰的容器技术圈子,到此尘埃落定。 容器技术圈子在短短几年里发生了很多变数,但很多事情其实也都在情理之中。就像 Docker 这样一家创业公司,在通过开源社区的运作取得了巨大的成功之后,就不得不面对来自整个云计算产业的竞争和围剿。而这个产业的垄断特性,对于 Docker 这样的技术型创业公司其实天生就不友好。在这种局势下,接受微软的天价收购,在大多数人看来都是一个非常明智和实际的选择。可是 Solomon Hykes 却多少带有一些理想主义的影子,既然不甘于"寄人篱下",那他就必须带领 Docker 公司去对抗来自整个云计算产业的压力。 只不过,Docker 公司最后选择的对抗方式,是将开源项目与商业产品紧密绑定,打造了一个极端封闭的技术生态。而这,其实违背了 Docker 项目与开发者保持亲密关系的初衷。相比之下,Kubernetes 社区,正是以一种更加温和的方式,承接了 Docker 项目的未尽事业,即:以开发者为核心,构建一个相对民主和开放的容器生态。这也是为何,Kubernetes 项目的成功其实是必然的。 很难想象如果 Docker 公司最初选择了跟 Kubernetes 社区合作,如今的容器生态又将会是怎样的一番景象。不过我们可以肯定的是,Docker 公司在过去五年里的风云变幻,以及 Solomon Hykes 本人的传奇经历,都已经在云计算的长河中留下了浓墨重彩的一笔。 总结: 容器技术的兴起源于 PaaS 技术的普及; Docker 公司发布的 Docker 项目具有里程碑式的意义; Docker 项目通过"容器镜像",解决了应用打包这个根本性难题。 容器本身没有价值,有价值的是"容器编排"。也正因为如此,容器技术生态才爆发了一场关于"容器编排"的"战争"。而这次战争,最终以 Kubernetes 项目和 CNCF 社区的胜利而告终。
容器编排之战
一. kubernetes简要概述
Kubernetes 是用于自动部署, 扩展和管理容器化应用程序的开源系统. 它将组成应用程序的容器组合成逻辑单元, 以便于管理和服务发现. Kubernetes 源自Google 15 年生产环境的运维经验, 同时凝聚了社区的最佳创意和实践
在容器化应用的大趋势下, 越来越多的单体应用被划分成了无数个微小的服务, 从之前的裸机部署单体服务到现今使用容器承载服务运行; 容器越来越贴近研发、运维、测试等IT职能部门, 越来越多的人也渐渐转向了云进行开发, 而不再单独强调单体一致性问题; 这一切的功臣就是 — 容器;
其实容器这个产物, 早在Linux内核诞生后就已经有了它, 那时候程序员创建一个容器需要编写代码, 调用Linux内核中的Cgroup 和 NameSpace用作资源限制, 而创建出来的容器所观看到的底层文件系统却是和宿主机是同一套文件系统, 导致在容器中操作文件就相当于更改了宿主机的文件系统, 这就大大暴露了容器的应用性差的特性; 后来横空出世的docker解决了这个问题, docker创造了一个叫做镜像的东西, 并将其进行分层, 使得用户在启动容器的时候将镜像拷贝一份读写层挂载到容器中, 让容器看到的底层文件系统只是镜像中的内容从而避免了上述的问题, 镜像带来的好处远不止这一个, 比如在生产、测试、研发三个环境中总是因为环境不统一造成上线后的应用很快崩溃的局面, 而有了镜像就不需要考虑环境的问题, 因为所有的服务运行在容器中, 而提供给容器运行的底层文件系统是镜像, 只要使用的是同一个镜像那么不管在什么环境中, 都是一样的效果, 这对于运维、测试、研发三类人而言就能彻底的和应用运行环境要考虑的事情甩手拜拜了; 而docker这个引擎又提供了很多易于使用的控制容器的指令, 大大降低了程序员操作的难度, 又提供相应的镜像和存储镜像的公共仓库, 使得容器技术飞速发展起来;
就在容器飞速发展的第五年里, Google发布了容器编排系统 kubernetes, 它解决了容器在多个宿主机间调度的问题, 同时提供可靠的API接口来控制容器的运行, 并时刻保持容器启动的状态, 融合了故障自愈、服务发现等新功能; 从而占领了容器市场的高地; 从此容器圈内又向容器编排发起了猛烈的攻势;
1.1 kubernetes 功能简介
服务发现和负载均衡 Kubernetes 可以使用 DNS 名称或自己的 IP 地址公开容器, 如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量, 从而使部署稳定. 常用的DNS插件为coreDNS, 用作服务发现和集群中容器通讯; 负载均衡器常使用集群内的service资源进行对外暴露服务, 同时也提供ingress插件接口对外暴露服务
存储编排 Kubernetes 允许你自动挂载你选择的存储系统, 例如本地存储、公共云提供商等. 对于集群内部的应用有时会需要持久化数据, 这时容器如果被删除数据也会随之消失, 所以一个稳定的外部存储集群就显得很重要了; 常见的对k8s提供存储能力的集群有: heketi + gluesterfs 、Rook + Ceph、阿里云OSS等, 配合集群内的storageclass可直接向存储集群申请存储空间
自动部署和回滚 你可以使用 Kubernetes 描述已部署容器的所需状态, 它可以以受控的速率将实际状态 更改为期望状态. 例如, 你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器. 控制k8s集群中容器的状态大多数时候都会采用 yaml 资源配置清单的形式, 方便记忆也易于识别
自动完成装箱计算 Kubernetes 允许你指定每个容器所需 CPU 和内存(RAM). 当容器指定了资源请求时, Kubernetes 可以做出更好的决策来管理容器的资源. 这就与Linux操作系统中的资源限额有关系了, 有些容器在接收高并发访问的时候, 往往会无限制的占用宿主机资源, 从而导致其他服务容器争抢不到应有的资源进行运行和服务, 从而导致大面积瘫痪
自我修复 Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的 运行状况检查的容器, 并且在准备好服务之前不将其通告给客户端. 在创建pod的时候, 只有当设置在pod中的探针全部探测正常后才会将pod连接到集群内网络中对外进行服务, 否则将通过监控告警给运维人员; 同样的对于k8s中的容器会受到kubelet和kube-apiserver的双重管理, kubelet上报容器运行状态, api-server向etcd中请求期望状态, 比较后让其达到期望的状态, 从而保证其功能/服务容器永久保持在线
密钥与配置管理 Kubernetes 允许你存储和管理敏感信息, 例如密码、OAuth 令牌和 ssh 密钥. 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置, 也无需在堆栈配置中暴露密钥. 对于无状态应用(exam: nginx)的配置文件, 可以使用k8s中的configmap资源进行存储, 但对于密码和某些私密信息而言就可以使用secret资源进行存储, 从而避免频繁更改和私密信息泄漏的风险
1.2 Kubernetes架构及组件
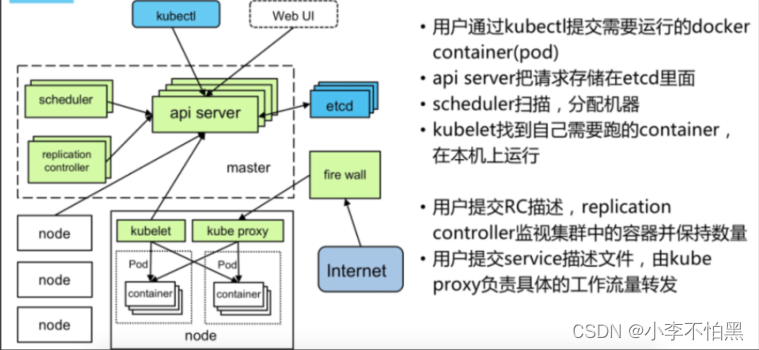
一个 Kubernetes 集群由一组被称作节点的机器组成。这些节点上运行 Kubernetes 所管理的容器化应用。集群具有至少一个工作节点。工作节点托管作为应用负载的组件的 Pod 。控制平面管理集群中的工作节点和 Pod 。 为集群提供故障转移和高可用性,这些控制平面一般跨多主机运行,集群跨多个节点运行。
-
kube-apiserver API 服务器是 Kubernetes 控制面的组件, 该组件公开了 Kubernetes API。 API 服务器是 Kubernetes 控制面的前端。Kubernetes API 服务器的主要实现是 kube-apiserver。 kube-apiserver 设计上考虑了水平伸缩,也就是说,它可通过部署多个实例进行伸缩。 你可以运行 kube-apiserver 的多个实例,并在这些实例之间平衡流量。
-
etcd etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。你的 Kubernetes 集群的 etcd 数据库通常需要有个备份计划。要了解 etcd 更深层次的信息,请参考 etcd 文档。
-
kube-scheduler 控制平面组件,负责监视新创建的、未指定运行节点(node)的 Pods,选择节点让 Pod 在上面运行。调度决策考虑的因素包括单个 Pod 和 Pod 集合的资源需求、硬件/软件/策略约束、亲和性和反亲和性规范、数据位置、工作负载间的干扰和最后时限。
/etc/kubernetes/manifests/kube-scheduler.yaml 中添加参数
--node-monitor-grace-period=10s:该参数指定了 Node 节点的监控宽限期(Grace Period),即在节点变为不可用之前的时间间隔。在这段时间内,调度器不会将 Pod 从该节点上驱逐,以便给应用程序一些时间来完成正在进行的任务并正常关闭。在这个例子中,宽限期为 10 秒。
--node-monitor-period=3s:该参数指定了 Node 节点的监控周期,即调度器检查节点状态的时间间隔。在这个例子中,监控周期为 3 秒。
--node-startup-grace-period=20s:该参数指定了新节点加入集群后的启动宽限期(Grace Period),即在节点完全准备好之前的时间间隔。在这段时间内,调度器不会将 Pod 调度到该节点上,以便给节点一些时间来初始化和准备运行 Pod。在这个例子中,启动宽限期为 20 秒。
--pod-eviction-timeout=10s:该参数指定了 Pod 的驱逐超时时间,即在调度器决定驱逐一个 Pod 之后,等待该 Pod 关闭的时间间隔。如果 Pod 在这段时间内没有正常关闭,调度器将强制终止该 Pod。在这个例子中,驱逐超时时间为 10 秒。
-
kube-controller-manager 运行控制器进程的控制平面组件。从逻辑上讲,每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。这些控制器包括:
-
节点控制器(Node Controller):负责在节点出现故障时进行通知和响应
-
任务控制器(Job controller):监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
-
端点控制器(Endpoints Controller):填充端点(Endpoints)对象(即加入 Service 与 Pod)
-
服务帐户和令牌控制器(Service Account & Token Controllers):为新的命名空间创建默认帐户和 API 访问令牌
-
-
cloud-controller-manager 云控制器管理器是指嵌入特定云的控制逻辑的 控制平面组件。 云控制器管理器使得你可以将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。
cloud-controller-manager仅运行特定于云平台的控制回路。 如果你在自己的环境中运行 Kubernetes,或者在本地计算机中运行学习环境, 所部署的环境中不需要云控制器管理器。与kube-controller-manager类似,cloud-controller-manager将若干逻辑上独立的 控制回路组合到同一个可执行文件中,供你以同一进程的方式运行。 你可以对其执行水平扩容(运行不止一个副本)以提升性能或者增强容错能力。下面的控制器都包含对云平台驱动的依赖:-
节点控制器(Node Controller):用于在节点终止响应后检查云提供商以确定节点是否已被删除
-
路由控制器(Route Controller):用于在底层云基础架构中设置路由
-
服务控制器(Service Controller):用于创建、更新和删除云提供商负载均衡器
-
-
Node 组件: 节点组件在每个节点上运行,维护运行的 Pod 并提供 Kubernetes 运行环境。
-
kubelet 一个在集群中每个节点(node)上运行的代理。 它保证容器(containers)都 运行在 Pod 中。kubelet 接收一组通过各类机制提供给它的 PodSpecs,确保这些 PodSpecs 中描述的容器处于运行状态且健康。 kubelet 不会管理不是由 Kubernetes 创建的容器。
-
kube-proxy kube-proxy 是集群中每个节点上运行的网络代理, 实现 Kubernetes 服务(Service) 概念的一部分。kube-proxy 维护节点上的网络规则。这些网络规则允许从集群内部或外部的网络会话与 Pod 进行网络通信。如果操作系统提供了数据包过滤层并可用的话,kube-proxy 会通过它来实现网络规则。否则, kube-proxy 仅转发流量本身。
-
容器运行时(Container Runtime) 容器运行环境是负责运行容器的软件。Kubernetes 支持容器运行时,例如 Docker、 containerd、CRI-O 以及 Kubernetes CRI (容器运行环境接口) 的其他任何实现。
-
插件(Addons) 插件使用 Kubernetes 资源实现集群功能。 因为这些插件提供集群级别的功能,插件中命名空间域的资源属于
kube-system命名空间。下面描述众多插件中的几种。有关可用插件的完整列表,请参见 插件(Addons)。-
DNS 尽管其他插件都并非严格意义上的必需组件,但几乎所有 Kubernetes 集群都应该 有集群 DNS, 因为很多示例都需要 DNS 服务。集群 DNS 是一个 DNS 服务器,和环境中的其他 DNS 服务器一起工作,它为 Kubernetes 服务提供 DNS 记录。Kubernetes 启动的容器自动将此 DNS 服务器包含在其 DNS 搜索列表中。
-
Web 界面(仪表盘) Dashboard 是 Kubernetes 集群的通用的、基于 Web 的用户界面。 它使用户可以管理集群中运行的应用程序以及集群本身并进行故障排除。
-
容器资源监控 容器资源监控 将关于容器的一些常见的时间序列度量值保存到一个集中的数据库中,并提供用于浏览这些数据的界面。
-
集群层面日志 集群层面日志 机制负责将容器的日志数据 保存到一个集中的日志存储中,该存储能够提供搜索和浏览接口 ELK/Loki+grafana
-
1.3 Kubernetes核心概念
Master
Master节点主要负责资源调度(Scheduler),控制副本(Replication Controller),和提供统一访问集群的入口(API Server)。---核心节点也是管理节点
Node
Node是Kubernetes集群架构中运行Pod的服务节点(亦叫agent或minion)。Node是Kubernetes集群操作的单元,用来承载被分配Pod的运行,是Pod运行的宿主机,由Master管理,并汇报容器状态给Master,当Node节点宕机(NotReady状态)时,该节点上运行的Pod会被自动地转移到其他节点上。
Kubelet组件---Kubelet会从API Server接收Pod的创建请求,启动和停止容器,监控容器运行状态并汇报给Kubernetes API Server。
KuberProxy组件--实现将客户端请求流量转发到内部的pod资源。
Docker Engine(docker)组件,Docker引擎,负责本机的容器创建和管理工作;
Node IP
Node节点的IP地址,是Kubernetes集群中每个节点的物理网卡的IP地址,是真是存在的物理网络,所有属于这个网络的服务器之间都能通过这个网络直接通信;
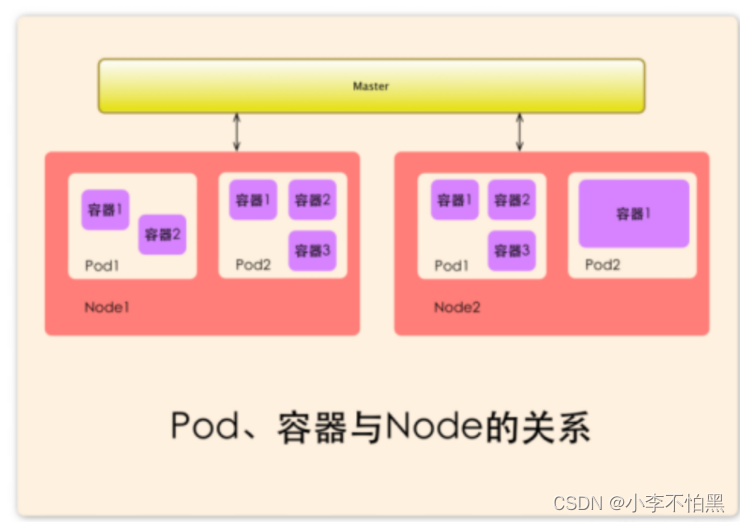
Pod
Pod直译是豆荚,可以把容器想像成豆荚里的豆子,把一个或多个关系紧密的豆子包在一起就是豆荚(一个Pod)。处于同一个Pod中的容器共享同样的存储空间(Volume,卷或存储卷)、网络命名空间IP地址和Port端口。在k8s中我们不会直接操作容器,而是把容器包装成Pod再进行管理
运行于Node节点上,Pod是k8s进行创建、调度和管理的最小单位.一个Pod可以包含一个容器或者多个相关容器。
Pod 就是 k8s 世界里的"应用";而一个应用,可以由多个容器组成。

pause容器
每个Pod中都有一个pause容器,pause容器做为Pod的网络接入点,Pod中其他的容器会使用容器映射模式启动并接入到这个pause容器。
Pod IP
Pod的IP地址,是Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络,位于不同Node上的Pod能够彼此通信,需要通过Pod IP所在的虚拟二层网络进行通信,而真实的TCP流量则是通过Node IP所在的物理网卡流出的。
 资源限制:
资源限制:
每个Pod可以设置限额的计算机资源有CPU和Memory;
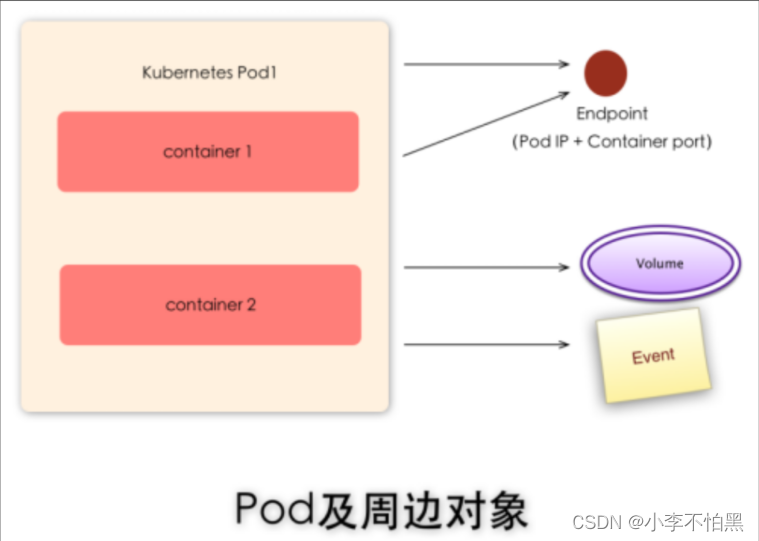
Pod Volume:
Docker Volume对应Kubernetes中的Pod Volume;数间共享数据。
Event
是一个事件记录,记录了事件最早产生的时间、最后重复时间、重复次数、发起者、类型,以及导致此事件的原因等信息。Event通常关联到具体资源对象上,是排查故障的重要参考信息
Endpoint(pod IP+容器Port)
标识服务进程的访问点;
ReplicaSet
确保任何指定的Pod副本数量,并提供声明式更新等功能。
Deployment
Deployment是一个更高层次的API对象,它管理ReplicaSets和Pod,并提供声明式更新等功能。
官方建议使用Deployment管理ReplicaSets,而不是直接使用ReplicaSets,这就意味着可能永远不需要直接操作ReplicaSet对象,因此Deployment将会是使用最频繁的资源对象。
RC-Replication Controller
Replication Controller用来管理Pod的副本,保证集群中存在指定数量的Pod副本。集群中副本的数量大于指定数量,则会停止指定数量之外的多余pod数量,反之,则会启动少于指定数量个数的容器,保证数量不变。Replication Controller是实现弹性伸缩、动态扩容和滚动升级的核心。
Service
Service定义了Pod的逻辑集合和访问该集合的策略,是真实服务的抽象。它有暴露内部服务的端口到外网的能力。Service提供了一个统一的服务访问入口以及服务代理和发现机制,用户不需要了解后台Pod是如何运行。 一个service定义了访问pod的方式,就像单个固定的IP地址和与其相对应的DNS名之间的关系。
service分为两种ip地址: 一种是对内的叫Cluster IP ,一种是对外的叫external ip;
实现对外ip方式分为:
1.NodePort:通过每个 Node 上的 IP 和内部服务暴露出来的静态端口实现暴露服务。 2.LoadBalancer:使用云提供商的负载均衡器. 3.ingress:使用负载均衡软件实现负载均衡,向外部暴露服务。

Cluster IP
Service的IP地址,特性: 专门给集群内部资源访问的。在k8s集群里面部署的容器,用内部的容器可以访问这个ip地址。但是集群外面的机器不能访问。
1.无法被Ping通;
2.Node IP、Pod IP、Cluster IP之间的通信,采用的是Kubernetes自己设计的一种编程方式的特殊的路由规则,与IP路由有很大的不同
Label---标签与Selectors---选择器
Kubernetes中的任意API对象都是通过Label进行标识,Label的实质是一系列的K/V键值对。Label是Replication Controller和Service运行的基础,二者通过Label来进行关联Node上运行的Pod。
比如,你可能创建了一个"tier"和“app”标签,通过Label(tier=frontend, app=myapp)来标记前端Pod容器,使用 Label(tier=backend, app=myapp)标记后台Pod。然后可以使用 Selectors 选择带有特定Label的Pod,并且将 Service 或者 Replication Controller 应用到上面。
一个label是一个被附加到资源上的键/值对,譬如附加到一个Pod上,为它传递一个用户自定的并且可识别的属性。
注:Node、Pod、Replication Controller和Service等都可以看作是一种"资源对象",几乎所有的资源对象都可以通过Kubernetes提供的kubectl工具执行增、删、改、查等操作并将其保存在etcd中持久化存储。
二. 常用镜像库
daocloud的docker镜像库:
daocloud.io/librarydocker-hub的k8s镜像库:
mirrorgooglecontainers
aliyun的k8s镜像库:
registry.cn-hangzhou.aliyuncs.com/google-containers
docker镜像仓库
aliyun的docker镜像库web页面:
https://cr.console.aliyun.com/cn-hangzhou/imagesgoogle的镜像库web页面:
https://console.cloud.google.com/gcr/images/google-containers?project=google-containers
三.集群部署方式
-
方式1. minikube
-
Minikube是一个工具,可以在本地快速运行一个单点的Kubernetes,尝试Kubernetes或日常开发的用户使用。不能用于生产环境。
官方地址:https://kubernetes.io/docs/setup/minikube/
-
方式2. kubeadm
-
Kubeadm也是一个工具,提供kubeadm init和kubeadm join,用于快速部署Kubernetes集群。
官方地址:https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/
-
方式3. 直接使用epel-release yum源,缺点就是版本较低 1.5
-
方式4. 二进制包
四.Kubeadm 方式部署集群
kubeadm部署官方文档
kubeadm部署k8s高可用集群的官方文档
主节点CPU核数必须是 ≥2核且内存要求必须≥2G,否则k8s无法启动
| 主机名 | 地址 | 角色 | 配置 |
|---|---|---|---|
| kube-master | 192.168.58.149 | 主节点 | 2核4G |
| kube-node1 | 192.168.58.150 | 工作节点 | 1核2G |
| kube-node2 | 192.168.58.151 | 工作节点 | 1核2G |
4.1获取镜像
谷歌镜像[由于国内网络原因,无法下载,后续将采用阿里云镜像代替]
docker pull k8s.gcr.io/kube-apiserver:v1.22.0
docker pull k8s.gcr.io/kube-proxy:v1.22.0
docker pull k8s.gcr.io/kube-controller-manager:v1.22.0
docker pull k8s.gcr.io/kube-scheduler:v1.22.0
docker pull k8s.gcr.io/etcd:3.5.0-0
docker pull k8s.gcr.io/pause:3.5
docker pull k8s.gcr.io/coredns/coredns:v1.8.4特别说明
所有机器都必须有镜像
每次部署都会有版本更新,具体版本要求,运行初始化过程失败会有版本提示
kubeadm的版本和镜像的版本必须是对应的
4.2 安装docker[集群]
过程请查看docker安装部分 可以参考:http://t.csdnimg.cn/BsQHx
4.3 阿里仓库下载[集群]
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.22.0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.22.0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.22.0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.22.0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.4
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.0-0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.5
# 下载完了之后需要将aliyun下载下来的所有镜像打成k8s.gcr.io/kube-controller-manager:v1.22.0这样的tag
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.22.0 k8s.gcr.io/kube-controller-manager:v1.22.0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.22.0 k8s.gcr.io/kube-proxy:v1.22.0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.22.0 k8s.gcr.io/kube-apiserver:v1.22.0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.22.0 k8s.gcr.io/kube-scheduler:v1.22.0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.4 k8s.gcr.io/coredns/coredns:v1.8.4
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.0-0 k8s.gcr.io/etcd:3.5.0-0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.5 k8s.gcr.io/pause:3.5
# 可以清理掉aliyun的镜像标签
docker rmi -f `docker images --format {{.Repository}}:{{.Tag}} | grep aliyun`4.4 集群部署[集群]
cat >> /etc/hosts <<EOF
192.168.58.149 kube-master
192.168.58.150 kube-node1
192.168.58.151 kube-node2
EOF
制作本地解析,修改主机名。相互解析4.5 集群环境配置[集群]
1.关闭防火墙:
# systemctl stop firewalld && systemctl disable firewalld
2.禁用SELinux:
# setenforce 0
3.编辑文件/etc/selinux/config,将SELINUX修改为disabled,如下:
# sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux
SELINUX=disabled
4.时间同步
# timedatectl set-timezone Asia/Shanghai
# yum install -y ntpdate
# ntpdate ntp.aliyun.com
5.配置静态ip4.6 关闭系统Swap[集群]
Kubernetes 1.8开始要求关闭系统的Swap,如果不关闭,默认配置下kubelet将无法启动。
-
方法一: 通过kubelet的启动参数--fail-swap-on=false更改这个限制。
-
方法二: 关闭系统的Swap。
1.关闭swap分区
# swapoff -a
修改/etc/fstab文件,注释掉SWAP的自动挂载,使用free -m确认swap已经关闭。
2.注释掉swap分区:
# sed -i 's/.*swap.*/#&/' /etc/fstab
# free -m
total used free shared buff/cache available
Mem: 3935 144 3415 8 375 3518
Swap: 0 0 0
4.7 安装Kubeadm包[集群]
配置官方源[需翻墙]
# cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
EOF
配置阿里云源[本实例中采用这种]
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF所有节点配置:
1.安装依赖包及常用软件包
# yum install -y conntrack ntpdate ntp ipvsadm ipset jq iptables curl sysstat libseccomp wget vim net-tools git iproute lrzsz bash-completion tree bridge-utils unzip bind-utils gcc
2.安装对应版本
# yum install -y kubelet-1.22.0-0.x86_64 kubeadm-1.22.0-0.x86_64 kubectl-1.22.0-0.x86_64
3.加载ipvs相关内核模块
# cat <<EOF > /etc/modules-load.d/ipvs.conf
ip_vs
ip_vs_lc
ip_vs_wlc
ip_vs_rr
ip_vs_wrr
ip_vs_lblc
ip_vs_lblcr
ip_vs_dh
ip_vs_sh
ip_vs_nq
ip_vs_sed
ip_vs_ftp
ip_vs_sh
nf_conntrack_ipv4
ip_tables
ip_set
xt_set
ipt_set
ipt_rpfilter
ipt_REJECT
ipip
EOF
4.配置:
配置转发相关参数,否则可能会出错
# cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
vm.swappiness=0
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
5.使配置生效
# sysctl --system
6.如果net.bridge.bridge-nf-call-iptables报错,加载br_netfilter模块
# modprobe br_netfilter
# modprobe ip_conntrack
# sysctl -p /etc/sysctl.d/k8s.conf
7.查看是否加载成功
# lsmod | grep ip_vs4.8 配置启动kubelet[集群]
1.配置kubelet使用pause镜像
获取docker的cgroups(语法:)
# DOCKER_CGROUPS=$(docker info | grep 'Cgroup' | cut -d' ' -f4)
# echo $DOCKER_CGROUPS
=================================
配置变量:[执行下面两条即可]
[root@kube-master ~]# DOCKER_CGROUPS=`docker info |grep 'Cgroup' | awk ' NR==1 {print $3}'`
[root@kube-master ~]# echo $DOCKER_CGROUPS
cgroupfs
2.配置kubelet的cgroups
# cat >/etc/sysconfig/kubelet<<EOF
KUBELET_EXTRA_ARGS="--cgroup-driver=$DOCKER_CGROUPS --pod-infra-container-image=k8s.gcr.io/pause:3.5"
EOF启动
# systemctl daemon-reload
# systemctl enable kubelet && systemctl restart kubelet
在这里使用 # systemctl status kubelet,你会发现报错误信息;
10月 11 00:26:43 node1 systemd[1]: kubelet.service: main process exited, code=exited, status=255/n/a
10月 11 00:26:43 node1 systemd[1]: Unit kubelet.service entered failed state.
10月 11 00:26:43 node1 systemd[1]: kubelet.service failed.
运行 # journalctl -xefu kubelet 命令查看systemd日志才发现,真正的错误是:
unable to load client CA file /etc/kubernetes/pki/ca.crt: open /etc/kubernetes/pki/ca.crt: no such file or directory
#这个错误在运行kubeadm init 生成CA证书后会被自动解决,此处可先忽略。
#简单地说就是在kubeadm init 之前kubelet会不断重启。4.9 配置master节点[master]
运行初始化过程如下:
[root@kube-master]# kubeadm init --kubernetes-version=v1.22.0 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.58.149
注:
apiserver-advertise-address=192.168.96.10 ---master的ip地址。
--kubernetes-version=v1.22.0 --更具具体版本进行修改
如果报错会有版本提示,那就是有更新新版本了
[init] Using Kubernetes version: v1.22.0
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 18.03.0-ce. Latest validated version: 18.09
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Activating the kubelet service
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kub-k8s-master kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.58.149]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [kub-k8s-master localhost] and IPs [192.168.96.10 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [kub-k8s-master localhost] and IPs [192.168.96.10 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 24.575209 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.16" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node kub-k8s-master as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node kub-k8s-master as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: 93erio.hbn2ti6z50he0lqs
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.58.149:6443 --token 93erio.hbn2ti6z50he0lqs \
--discovery-token-ca-cert-hash sha256:3bc60f06a19bd09f38f3e05e5cff4299011b7110ca3281796668f4edb29a56d9 #需要记住上面记录了完成的初始化输出的内容,根据输出的内容基本上可以看出手动初始化安装一个Kubernetes集群所需要的关键步骤。
其中有以下关键内容:
[kubelet] 生成kubelet的配置文件”/var/lib/kubelet/config.yaml”
[certificates]生成相关的各种证书
[kubeconfig]生成相关的kubeconfig文件
[bootstraptoken]生成token记录下来,后边使用kubeadm join往集群中添加节点时会用到
配置使用kubectl
如下操作在master节点操作
[root@kube-master ~]# rm -rf $HOME/.kube
[root@kube-master ~]# mkdir -p $HOME/.kube
[root@kube-master ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@kube-master ~]# chown $(id -u):$(id -g) $HOME/.kube/config
查看node节点
[root@kube-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
kube-master NotReady master 2m41s v1.22.04.10 配置使用网络插件[master]
# 版本差异 https://projectcalico.docs.tigera.io/archive/v3.22/getting-started/kubernetes/requirements
> 部署calico网络插件
#curl -L https://docs.projectcalico.org/v3.22/manifests/calico.yaml -O
kubectl apply -f calico.yaml
# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-6d9cdcd744-8jt5g 1/1 Running 0 6m50s
kube-system calico-node-rkz4s 1/1 Running 0 6m50s
kube-system coredns-74ff55c5b-bcfzg 1/1 Running 0 52m
kube-system coredns-74ff55c5b-qxl6z 1/1 Running 0 52m
kube-system etcd-kub-k8s-master 1/1 Running 0 53m
kube-system kube-apiserver-kub-k8s-master 1/1 Running 0 53m
kube-system kube-controller-manager-kub-k8s-master 1/1 Running 0 53m
kube-system kube-proxy-gfhkf 1/1 Running 0 52m
kube-system kube-scheduler-kub-k8s-master 1/1 Running 0 53mcalico 与 flannel 的原理:
calico 原理:
基于 BGP 的网络连接:Calico 使用 BGP 协议在 Kubernetes 集群中的节点之间建立网络连接。每个节点运行一个 Calico 代理【daemonset】,该代理负责与其他节点建立 BGP 连接,并将容器的网络流量路由到正确的目的地。
网络策略:Calico 提供了一种灵活的网络策略模型,允许定义容器之间的访问规则。可以使用标签来标识容器,并使用网络策略来控制容器之间的流量。
IP 地址管理:Calico 自动管理 Kubernetes 集群中的 IP 地址分配。它使用 IPIP 隧道技术将容器的 IP 地址映射到节点的 IP 地址,以确保容器之间的通信。
网络隔离:Calico 提供了网络隔离功能,允许将不同的容器和应用程序隔离到不同的网络中。
flannel 原理:
网络覆盖:Flannel 在 Kubernetes 集群中的每个节点上运行一个守护进程,该守护进程使用 VXLAN。
网络配置:Flannel 守护进程负责配置虚拟网络,并将容器的网络流量路由到正确的目的地。
IP 地址分配:Flannel 自动管理 Kubernetes 集群中的 IP 地址分配。它使用 IPAM(IP Address Management)模块来分配 IP 地址,并将它们分配给容器。
网络策略:Flannel 支持网络策略,允许定义容器之间的访问规则。可以使用网络策略来控制容器之间的流量,以确保应用程序的安全性。
4.11 node加入集群[node]
配置node节点加入集群:
# 如果报错则开启ip转发:
# sysctl -w net.ipv4.ip_forward=1
在所有node节点操作,此命令为初始化master成功后返回的结果
# kubeadm join 192.168.58.149:6443 --token 93erio.hbn2ti6z50he0lqs \
--discovery-token-ca-cert-hash sha256:3bc60f06a19bd09f38f3e05e5cff4299011b7110ca3281796668f4edb29a56d94.12 后续检查[master]
各种检测:
1.查看pods:
[root@kub-k8s-master ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-5644d7b6d9-sm8hs 1/1 Running 0 39m
coredns-5644d7b6d9-vddll 1/1 Running 0 39m
etcd-kub-k8s-master 1/1 Running 0 37m
kube-apiserver-kub-k8s-master 1/1 Running 0 38m
kube-controller-manager-kub-k8s-master 1/1 Running 0 38m
kube-flannel-ds-amd64-9wgd8 1/1 Running 0 38m
kube-flannel-ds-amd64-lffc8 1/1 Running 0 2m11s
kube-flannel-ds-amd64-m8kk2 1/1 Running 0 2m2s
kube-proxy-dwq9l 1/1 Running 0 2m2s
kube-proxy-l77lz 1/1 Running 0 2m11s
kube-proxy-sgphs 1/1 Running 0 39m
kube-scheduler-kub-k8s-master 1/1 Running 0 37m
2.查看节点:
[root@kub-k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
kub-k8s-master Ready master 43m v1.22.0
kub-k8s-node1 Ready <none> 6m46s v1.22.0
kub-k8s-node2 Ready <none> 6m37s v1.22.0
到此集群配置完成错误整理
#> 如果集群初始化失败:(每个节点都要执行)
$ kubeadm reset -f; ipvsadm --clear; rm -rf ~/.kube
$ systemctl restart kubelet
#> 如果忘记token值
$ kubeadm token create --print-join-command
$ kubeadm init phase upload-certs --upload-certs五.可视化部署
5.1 官方Dashboard
5.1.1 部署Dashboard
# kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.4.0/aio/deploy/recommended.yaml
# kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard
# 注意将 type: ClusterIP 改为 type: NodePort
# kubectl get svc -A |grep kubernetes-dashboard
kubernetes-dashboard dashboard-metrics-scraper ClusterIP 10.107.179.10 <none> 8000/TCP 38s
kubernetes-dashboard kubernetes-dashboard NodePort 10.110.18.72 <none> 443:32231/TCP 38s5.1.2 创建访问账号
#创建访问账号,准备一个yaml文件; vi dash.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
# kubectl apply -f dash.yaml5.1.3 获取访问令牌
#获取访问令牌
# kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"
eyJhbGciOiJSUzI1NiIsImtpZCI6ImhRa2Q3UDFGempzb3VneVdUS0R0dk50SHlwUHExc0tuT21SOTdWQkczaG8ifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLXBmbGxyIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiJlNDk0MTFhYS0zOTVhLTRkYzUtYmZmYS04MDZiODE3M2VmZWEiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.k3Gd9vRF6gP3Zxy89x14y4I2RCGn232bGLo9A5iEmeMl6BRPdJXZPbwy9fm3OT6ZjVc7LHiRgArczjZuCU3Sis4tIA_24A55h74WQE_JTeiZ5XnSGRknYQRHFSqyBrTaTxgDJb-O-DHol8GQLQjr6gIPzppHc-RhWhUFFNnPVP1nr2MLFBkvIT_qAcbHP6McFf2N6IsYwVFuvyIO77qWcmyFlgSr8a3A0INEJYB2bFPRL82rNc41c0TsUwOguQbJYrDA9lBqVpSff_7Uk_-7ycabZclbZX1HPz2-F59LQW7NWQy7biZw5b25AZaXAG3kL3SDuRRBoMNS92MmDFsVyA5.1.4 浏览器访问
任意节点ip+端口[上面查看到为32231]
url https://192.168.246.216:32231/
使用token登录

5.2 kuboard 部署
[root@kube-master ~]# kubectl apply -f https://addons.kuboard.cn/kuboard/kuboard-v3.yaml
[root@kube-master ~]# kubectl get pod -n kuboard
NAME READY STATUS RESTARTS AGE
kuboard-agent-2-5c54dcb98f-4vqvc 1/1 Running 24 (7m50s ago) 16d
kuboard-agent-747b97fdb7-j42wr 1/1 Running 24 (7m34s ago) 16d
kuboard-etcd-ccdxk 1/1 Running 16 (8m58s ago) 16d
kuboard-etcd-k586q 1/1 Running 16 (8m53s ago) 16d
kuboard-questdb-bd65d6b96-rgx4x 1/1 Running 10 (8m53s ago) 16d
kuboard-v3-5fc46b5557-zwnsf 1/1 Running 12 (8m53s ago) 16d
[root@kube-master ~]# kubectl get svc -n kuboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kuboard-v3 NodePort 10.96.25.125 <none> 80:30080/TCP,10081:30081/TCP,10081:30081/UDP 16d用户名:admin 密码:Kuboard123

5.3 kubesphere 部署
官方文档:
在 Kubernetes 上最小化安装 KubeSphere

# 运行安装
[root@kube-master ~]# kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.4.0/kubesphere-installer.yaml
[root@kube-master ~]# kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.4.0/cluster-configuration.yaml
# 查看日志
[root@kube-master ~]# kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l 'app in (ks-install, ks-installer)' -o jsonpath='{.items[0].metadata.name}') -f
卸载kubesphere
[root@kube-master ~]# curl https://raw.githubusercontent.com/kubesphere/ks-installer/release-3.4/scripts/kubesphere-delete.sh | sh5.4 rainbond 部署
rainbond :https://www.rainbond.com/
[root@kube-master ~]# curl -o install.sh https://get.rainbond.com && bash ./install.sh
RO
[root@kube-master ~]# helm repo add rainbond https://openchart.goodrain.com/goodrain/rainbond
[root@kube-master ~]# helm repo update
[root@kube-master ~]# kubectl create namespace rbd-system卸载
如果是基于helm创建的rainbond
[root@kube-master ~]# helm uninstall rainbond -n rbd-system
如果是基于官方脚本创建的rainbond
# Delete PVC
[root@kube-master ~]# kubectl get pvc -n rbd-system | grep -v NAME | awk '{print $1}' | xargs kubectl delete pvc -n rbd-system
# Delete PV
[root@kube-master ~]# kubectl get pv | grep rbd-system | grep -v NAME | awk '{print $1}' | xargs kubectl delete pv
# Delete CRD
[root@kube-master ~]# kubectl delete crd componentdefinitions.rainbond.io \
helmapps.rainbond.io \
rainbondclusters.rainbond.io \
rainbondpackages.rainbond.io \
rainbondvolumes.rainbond.io \
rbdcomponents.rainbond.io \
servicemonitors.monitoring.coreos.com \
thirdcomponents.rainbond.io \
rbdabilities.rainbond.io \
rbdplugins.rainbond.io \
servicemeshclasses.rainbond.io \
servicemeshes.rainbond.io \
-n rbd-system
# Delete NAMESPACE
[root@kube-master ~]# kubectl delete ns rbd-system以上便是 Kubernetes 容器编排的介绍和软件安装内容。