大家好,这里是七七,今天开始又新开一个专栏,Python学习。这次思考了些许,准备用例子来学习,而不是只通过一大堆道理和书本来学习了。啊对,这次是从0开始学习,因此大佬不用看本文了,小白一起来看看吧。
话不多说,直接开始
一、pandas库
Pandas 是一个数据处理和分析的开源库,用于处理和操作结构化数据。它提供了高性能、易于使用的数据结构,如 DataFrame,用于处理表格化数据。通过 Pandas,你可以轻松地读取和写入各种数据格式(如 CSV、Excel、SQL 数据库等),清洗和转换数据,执行数据计算和聚合操作,以及进行数据可视化。Pandas 还提供了强大的数据索引和选择功能,可以快速高效地操作大型数据集。因此,Pandas 是数据科学和数据分析工作流中常用的工具之一。
二、matplotlib.pylot库
`matplotlib.pyplot` 是一个用于数据可视化的 Python 库,它是 matplotlib 的一个子模块。matplotlib 是一个功能强大的绘图库,提供了各种绘图选项和自定义功能,用于创建各种类型的静态、动态和交互式图表。
`matplotlib.pyplot` 提供了一系列简单的绘图函数,使得绘图变得更加容易和直观。你可以使用 `pyplot` 创建折线图、散点图、柱状图、饼图、直方图等各种常见的图表类型。它还支持对图表进行自定义,可以调整颜色、标签、标题、轴标注等属性,以及添加图例、注释等元素。此外,`pyplot` 还可以与 NumPy 和 Pandas 等库进行无缝集成,便于在图表中展示和处理数据。
总而言之,`matplotlib.pyplot` 是一个用于绘制各类图表的工具,可以帮助你更好地理解和展示数据。它在数据可视化和数据分析中广泛使用,是数据科学领域中重要的工具之一。
三、代码举例学习
代码1
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=[u'simHei']
plt.rcParams['axes.unicode_minus']=False第一行:
引入matplotlib.pyplot库,并起别名叫plt。
第二行:
使用了
rcParams对象来设置 matplotlib 库中的默认字体。其中rcParams是一个字典对象,用于存储和管理 matplotlib 库的默认参数。这些参数可以控制绘图的外观、属性和行为等。在这里,font.sans-serif是其中一个参数,表示无衬线字体的名称或列表。它用于设置图表中的默认字体,如果找不到指定的字体,matplotlib 将使用备用字体进行替代。具体来说,
plt.rcParams['font.sans-serif']=[u'simHei']应该是将默认的 sans-serif 字体名称设置为 “SimHei”,而 “SimHei” 是一种常用的中文无衬线字体,具有良好的可读性和展示效果。这样,当你在图表中添加中文标签和文字时,matplotlib 将使用 “SimHei” 作为默认字体,以确保标签和文字能够正常显示。这个设置适用于绘制中文图表的场景,如果不需要使用中文,可以选择其他的 sans-serif 字体或者使用默认设置即可。
第三行:
plt.rcParams['axes.unicode_minus']=False是在 matplotlib 中设置坐标轴上的负号字符编码使用 Unicode 编码,以免出现显示为方块或其他乱码的情况。负号字符通常用于表示负数或表示范围。在使用 matplotlib 时,如果不将负号转换成 Unicode 编码,则有可能会出现显示异常的情况,例如负号显示为方块或其他符号。这是因为 matplotlib 默认使用的字体不支持负号字符的显示,因此需要手动设置负号的编码格式为 Unicode。
通过将
plt.rcParams['axes.unicode_minus']属性设置为False,可以让 matplotlib 使用 Unicode 编码显示负号字符,从而避免出现负号显示异常的问题。这种设置可以用于绘制包含负数坐标轴或包含负数范围的图表,例如绘制股票数据的 K 线图等。
代码2
csv_file='data/附件 1.csv'
df_1=pd.read_csv(csv_file)
xlsx_file = 'data/附件3.xlsx'
df = pd.read_excel(xlsx_file)这段代码使用了 pandas 库中的 `read_csv()` 函数来读取一个 CSV 文件,并将读取的数据存储在一个 pandas DataFrame 对象中。
具体解释如下:
1. `csv_file='data/附件 1.csv'`:这行代码定义了一个名为 `csv_file` 的变量,并将其赋值为一个包含文件路径的字符串。这里指定的文件路径是 'data/附件 1.csv',其中 'data' 是文件所在的文件夹,'附件 1.csv' 是文件的名称。
2. `df_1=pd.read_csv(csv_file)`:这行代码使用 `pd.read_csv()` 函数读取了指定路径的 CSV 文件,并将读取的数据存储在一个名为 `df_1` 的 pandas DataFrame 对象中。`pd` 是 pandas 的别名,它是导入 pandas 库时常用的别名。通过调用 `read_csv()` 函数并传递文件路径作为参数,可以读取 CSV 文件的内容并将其转换为一个 DataFrame 对象。
经过以上步骤,原始的 CSV 文件的数据就被读取并存储在了 `df_1` 这个 DataFrame 对象中,可以通过该对象进行各种数据分析、处理和可视化操作。
问题:如果只有xlsx文件,怎么改代码呢?
xlsx_file = 'data/附件1.xlsx'
df_1 = pd.read_excel(xlsx_file)在Python中创建一个data文件夹,把附件1.xlsx放入这个文件夹中,改为这段代码就可以了。
代码3
df['日期']=pd.to_datetime(df['日期'])
df['月份']=df['日期'].dt.month-
pd.to_datetime(df['日期'])将 DataFrame 中 “日期” 列的数据类型从字符串转换为日期时间类型,以便后续处理和分析。 -
df['日期'].dt.month将 “日期” 列中的日期时间格式数据的月份部分提取出来,并将提取的结果存储在一个新的“月份”列中。这里使用dt.month方法可以方便地实现将月份信息提取出来,返回的是一个由月份部分组成的 Series 对象。
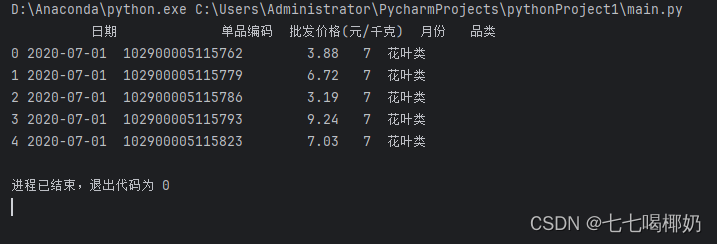
输出如下:
 代码4
代码4
mapping_dict=df_1.set_index('单品编码')['分类名称'].to_dict()
df['品类']=df['单品编号'].map(mapping_dict)使用 set_index() 函数将 DataFrame df_1 的 “单品编码” 列设置为索引,然后使用 to_dict() 函数将索引列 “单品编码” 作为键,“分类名称” 列作为值,创建了一个字典对象 mapping_dict。
接下来,df['单品编号'].map(mapping_dict) 将 DataFrame df 的 “单品编号” 列的值作为键去查找 mapping_dict 字典中对应的值,并将查找结果赋值给 “品类” 列。
这样做的目的是通过 mapping_dict 字典对 “单品编号” 列的值进行映射,将对应的 “分类名称” 值赋给 “品类” 列。
这是输出结果: