es,kibana,ik的下载安装
下载地址
es下载地址:
https://www.elastic.co/cn/downloads/elasticsearch
kibana下载地址:https://www.elastic.co/cn/downloads/kibana
ik中文分词器下载地址:https://github.com/medcl/elasticsearch-analysis-ik备注: 打开比较慢,ie下载要快点。3个版本需完全一致
一、elasticsearh的安装配置
1.elasticsearh的文件准备
1.1 前提是linux已经安装了jdk8或以上版本 解压es:
tar -zxvf elasticsearch-7.9.3-linux-x86_64.tar.gz
1.2 添加非root账号(es启动不能使用root账号):useradd esadmin
1.3 把文件目录归属赋予:chown esadmin -R /home/liaochao
1.4 把es自带的jdk目录改名(改成其他名字只要不叫jdk就行),使用系统安装的jdk
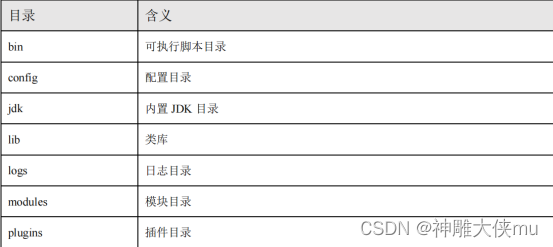
es目录含义:
2.设置服务器的配置
2.1 调整jvm内存大小
编辑:vim /etc/sysctl.conf
添加:vm.max_map_count=655360
查看:sysctl -p2.2 调整用户对资源进行限制
编辑:vim /etc/security/limits.conf
添加:
*soft nofile 65536
*hard nofile 65536注意前面有
*
3.配置elasticsearch.yml
3.1编辑:
vim elasticsearch.yml
# 集群名,节点之间要保持一致
cluster.name: my-application
# 节点名,集群内要唯一
node.name: node-1
# 数据存储目录(需要手动创建和改变归属,授权)
path.data: /home/soft/elasticsearch/elasticsearch-7.9.3/data
# 日志存储目录(需要手动创建和改变归属,授权)
path.logs: /home/soft/elasticsearch/elasticsearch-7.9.3/logs
# 允许访问的ip,0.0.0.0代表允许任意ip访问
network.host: 0.0.0.0
# 设置对外服务的http端口,默认为9200
http.port: 9200
# 设置节点间交互的tcp端口,默认是9300
transport.tcp.port: 9300
# 指定该节点是否有资格被选举成为master,默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master
node.master: true
# 指定该节点是否存储索引数据,默认为true
node.data: true
# 写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["192.168.200.135", "192.168.200.136","192.168.200.137"]
# 初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["192.168.200.135"]
# 设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错
discovery.zen.ping_timeout: 10s
# 是否支持跨域,是:true
http.cors.enabled: true
# “*” 表示支持所有域名
http.cors.allow-origin: "*"
注意:同一集群内,不同节点之间的配置可以仅
node.name: node-1不一样。其他都一样
3.2
注意:上面提到的data和log的目录需手动建立和改变归属
命令:
mkdir -p /home/soft/elasticsearch/elasticsearch-7.9.3/data
命令:mkdir -p /home/soft/elasticsearch/elasticsearch-7.9.3/logs并赋权 命令:
chown eadmin:esadmin -R /home/soft/elasticsearch/elasticsearch-7.9.3/data
chown eadmin:esadmin -R /home/soft/elasticsearch/elasticsearch-7.9.3/logs
4.启动es
在bin目录下,切换到esadmin用户:
su esadmin
执行:./elasticsearch -d
5.访问
在浏览器访问 ip:9200,如果有数据出现则启动正常。(记得防火墙开端口)
二.ik分词器的安装
把ik分词器压缩包上传到
/home/liaochao/es/elasticsearch-7.9.3/plugins/ik
执行解压:unzip elasticsearch-analysis-ik-7.9.3.zip
赋权:chown esadmin:esadmin -R /home/liaochao/es/elasticsearch-7.9.3/plugins/ik
在es的bin目录下执行(如果当前是启动状态那就先停止 kill -9 进程号):./elasticsearch -d
三.安装kibana
安装kibana。 如果es相当于mysql,那么kibana就相当于navcat。
kibana可以安装在linux,也可以就在windows机器上解压启动。 在windows下解压kibana,配置kibana.yml
server.port: 5601
elasticsearch.hosts: ["http://192.168.183.130:9200"]
在bin目录下点击 kibana.bat(目前es还没配置密码,所以无需其他配置)
这样就可以访问 localhost:5601就可以看到操作界面。
找到界面点击左上角,找到Management下面的Dev Tools就能打开控制台界面
验证ik分词器:
#最大分词
GET _analyze
{
"analyzer":"ik_max_word",
"text":"我是中国人"
}
#最小分词
GET _analyze
{
"analyzer":"ik_smart",
"text":"我是中国人"
}
这样就可以看到一句话被分词为多个词条
四.es设置密码(单机版)
4.1 修改elasticsearch.yml
添加:
xpack.security.transport.ssl.enabled: true
xpack.security.enabled: true
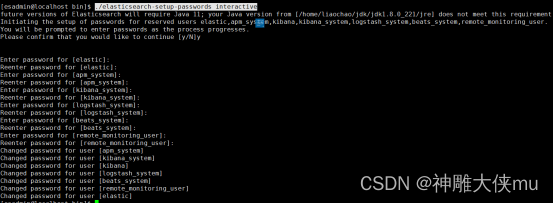
http.cors.allow-headers: "Authorization"4.2. 在es启动状态下,在bin目录(非root账号)执行
./elasticsearch-setup-passwords interactive
然后多次输入密码(方便记忆都输一样的)
注意:
1.如果该es以前设置过密码,那么可以把 数据存储目录 /home/soft/elasticsearch/elasticsearch-7.9.3/data 和 /home/soft/elasticsearch/elasticsearch-7.9.3/logs 目录删干净再重启,再执行上面的设置密码步骤
2.设置密码时es是启动状态
4.3 kibana对应修改
elasticsearch.hosts: ["http://192.168.183.130:9200"]
elasticsearch.username: "elastic"
elasticsearch.password: "420188"
重启kibana再访问 localhost:5601就会要求输入密码
五.es集群设置密码
5.1 现在有两台服务器部署了es,且按上面
3.配置elasticsearch.yml配置了es的文件,且形成了集群。 先把 data和logs目录删干净(如果有文件)
5.2 生成证书
在bin目录下执行./elasticsearch-certutil cert -out config/elastic-certificates.p12 -pass ""
那么他在es的config目录下会生成一个证书,名字叫:elastic-certificates.p12
5.3 把证书复制到每台服务器的config目录
5.4修改每台es的配置文件,添加到elasticsearch.yml末尾
xpack.security.transport.ssl.enabled: true
xpack.security.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /home/liaochao/es/elasticsearch-7.9.3/config/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /home/liaochao/es/elasticsearch-7.9.3/config/elastic-certificates.p12
这里的两个path就是自己的证书所在的文件目录
5.5 启动es(如果是启动状态先停止再启动) ./elasticsearch -d
5.6 设置密码
在其中任意一台上(bin目录下)执行,./elasticsearch-setup-passwords interactive
设置密码—这里与单机版设值密码一致。
5.7 kibana适配集群es带密码
修改kibana.yml
elasticsearch.hosts: ["http://192.168.183.130:9200","http://192.168.183.131:9200"]
elasticsearch.username: "elastic"
elasticsearch.password: "420188"
5.8 重启kiban
访问localhost:5601,在控制台执行
GET /_cat/nodes/ 就可以看到集群的所有节点信息