- 变形金刚,启动!
Abstract
- 主流序列转录模型基于复杂的循环神经网络和卷积神经网络,包括一个encoder和decoder,同时在这之中使用一个叫注意力机制attention的东西
- 本文提出了一个简单的网络架构,仅仅使用注意力机制,而没有使用神经网络,实验结果表明效果更好
Conclusion
- 首次提出仅使用注意力机制的模型transformer,取代了常规使用编码解码的架构模型,全部换成了multi-head self-attention
- 使用transformer模型训练速度很快,效果也更好
- 未来可用在其他方向
Introduction
- 当前主流使用lstm、rnn等模型
- RNN缺陷在于其为时序模型,在计算第t个词时,必须保证前面 h t − 1 h_{t-1} ht−1个词输入完成,导致时间上无法并行
- 注意力机制已经在RNN中有所使用
- 提出的transformer不再使用循环机制,可以进行并行运算
Background
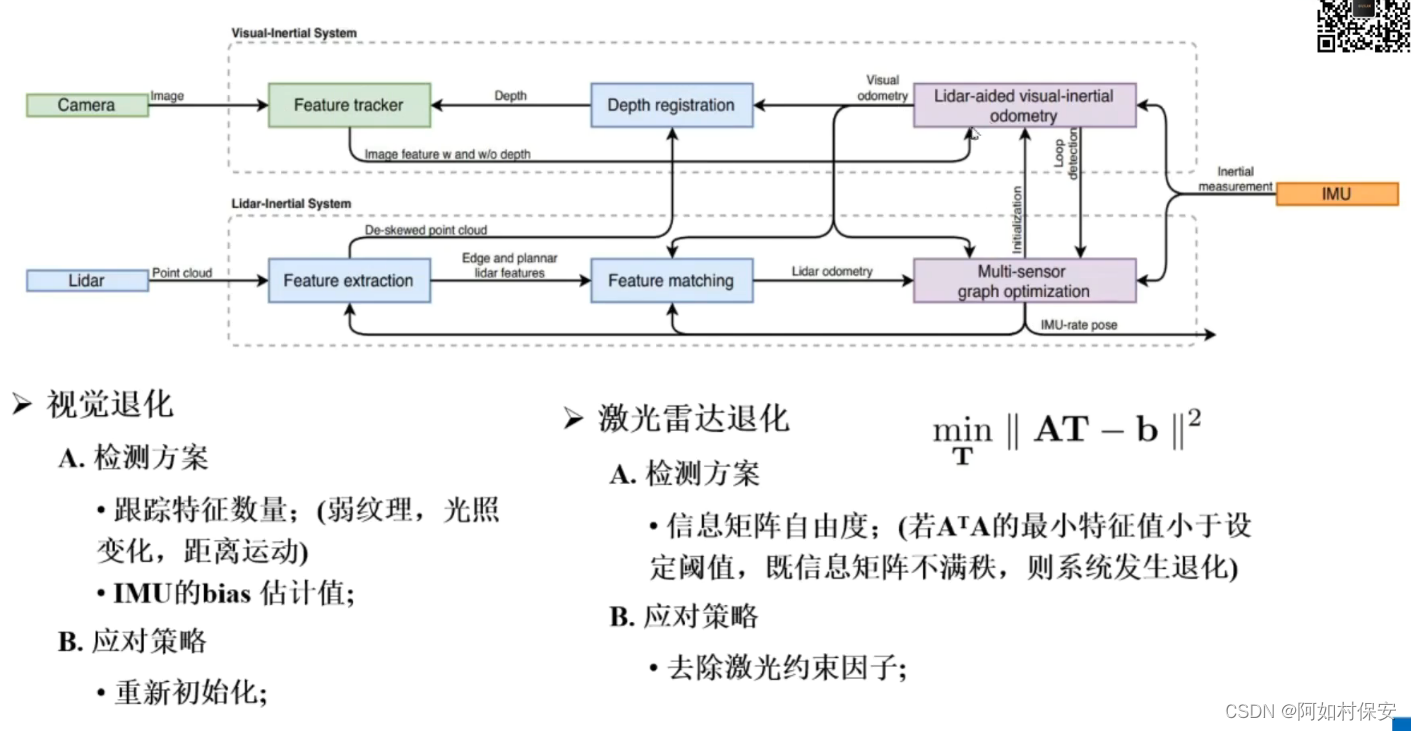
- 一些工作已经使用卷积神经网络替换循环神经网络,然而,对于两个距离较远的像素块需要一层一层的卷积进行处理才能将两个融合在一起,而使用transformer的注意力机制,一次可以看到所有的像素,因此一层就能将整个序列看到,同时,提出了Multi-head attention模拟卷积神经网络多输出通道的效果
- 自注意力机制是一种将单个序列的不同位置联系起来以计算序列表示的机制。
- 端到端网络
- transformer是第一个只依赖于自注意力机制进行encoder、decoder的模型
Model Architecture
- 当前主流的序列模型都是用编码器解码器结构
- 编码器会将输入的一组序列 ( x 1 . . . x n ) (x_1...x_n) (x1...xn)表示成一组 ( z 1 . . . z n ) (z_1...z_n) (z1...zn),每一个对应的是x的向量表示
- 解码器收到z,生成一段长为m的序列,解码时元素是一个一个生成,注意 y 1 . . y t − 1 y_1..y_{t-1} y1..yt−1也是 y t y_t yt的输入,叫做自回归auto-regressive
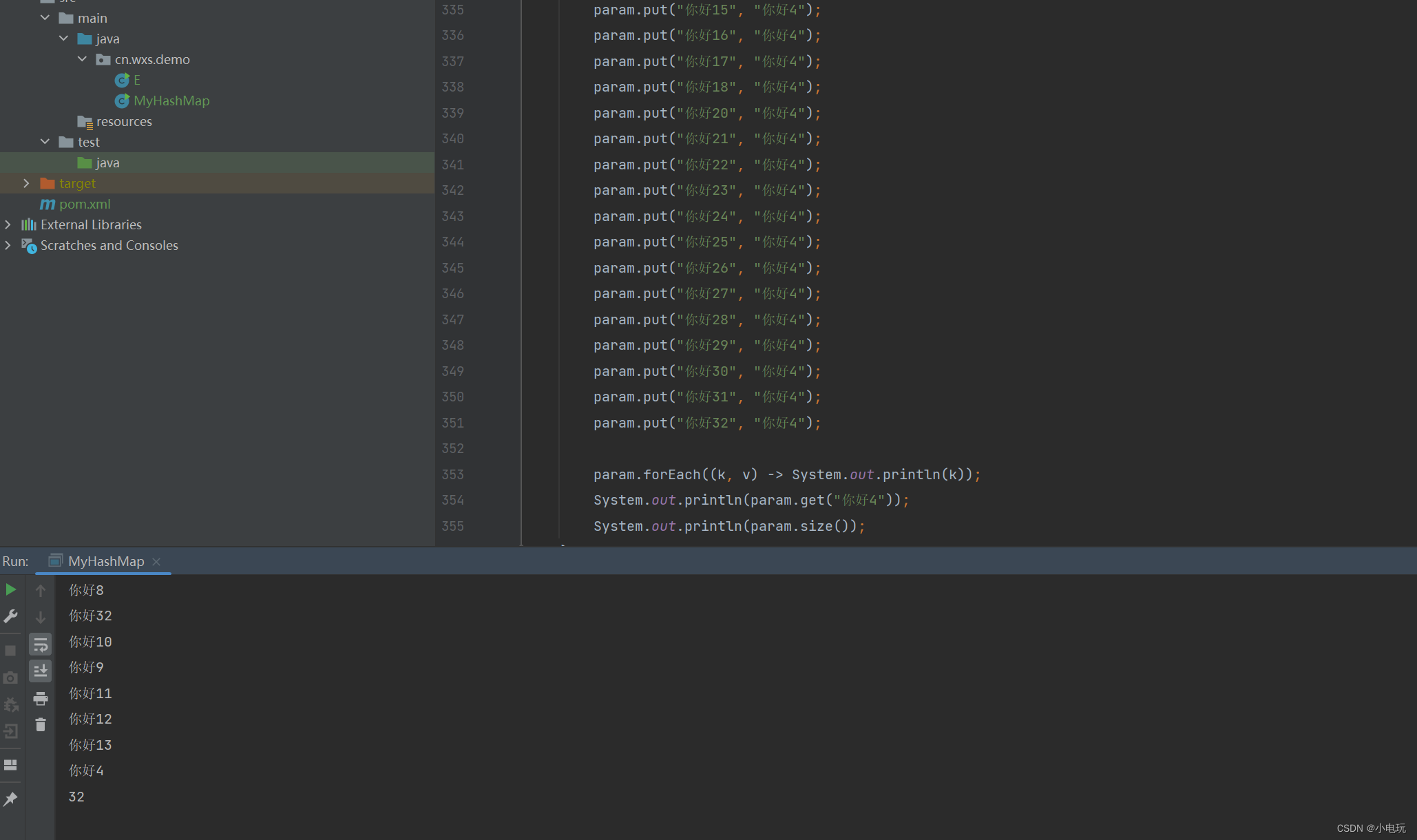
- transformer使用了编码器解码器架构,将堆叠自注意力机制和point-wise全连接层都加入到了编码解码器中
Encoder-Decoder堆叠
-
左侧是encoder由6个堆叠的相同的层构成,可以理解成是N个transformer块,其中每个block由两个子层组成,分别是Multi-head attention和poisition-wise fully connected feed-forward network;类似于MLP,每个子层都有一个残差连接,最后有一个normalization,每一层的的输出维度为512
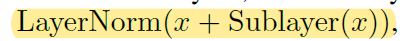
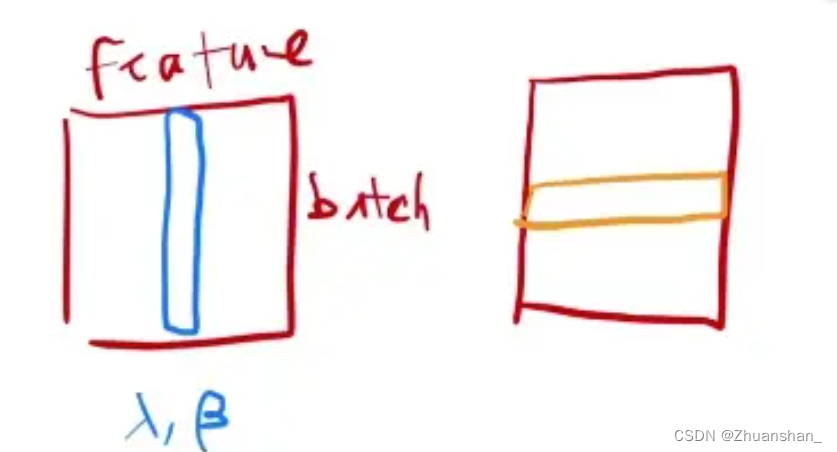
- batchnorm:每次把一列,即每一个特征取出在小的mini-batch内均值变为0,方差变为1
- layernorm:每次对一个样本做normalization,即每一行变为均值为0方差为1
- 可以理解成batchnorm是切出一个特征有多少batch,layernorm是一个batch切出多少feature
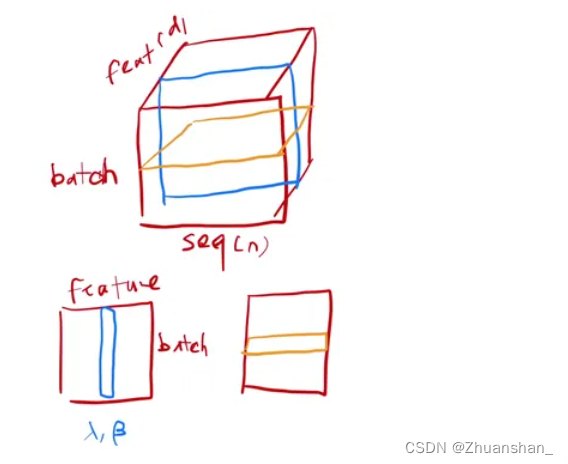
-
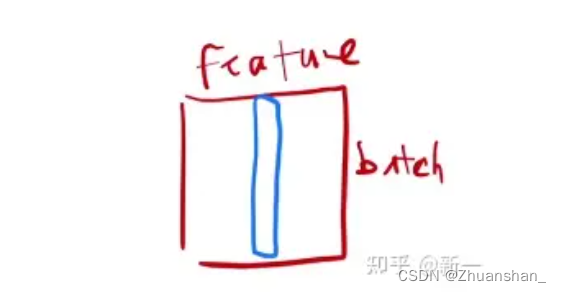
而对语句的输入来说,通常输入为三维,一个词用向量表示(512),sequence是一句话有几个单词,batch是一共有几句话。LayerNorm 更稳定,不管样本长还是短,均值和方差是在每个样本内计算。
-
右侧是解码器,其输入为之前解码器的一些输出作为输入,同样是有N=6个层构成,每个包括三个子层,同样是多头注意力机制,也用了残差连接和layernorm,这里用了一个mask保证在t时刻进行预测时不会看到t时刻之后的输出
Attention
- attention可以理解成将query、key-value对映射成输出的函数,这些都是向量,output 是 value 的一个加权和,因此,输出的维度 == value 的维度。
- query查询,key键,value值。查询来自用户输入,键来自词典库,将查询与键相比较,得到相似度权重,由value可数值化运算
吴恩达attention讲解
模型结构
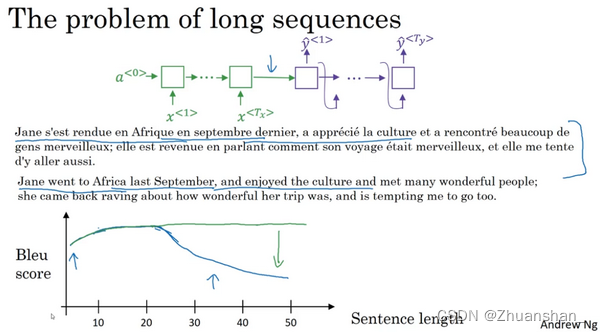
- 像这样给定一个很长的法语句子,在神经网络中,这个绿色的编码器要做的就是读整个句子,然后记忆整个句子,再在感知机中传递(to read in the whole sentence and then memorize the whole sentences and store it in the activations conveyed her)。而对于这个紫色的神经网络,即解码网络(the decoder network)将生成英文翻译。人工翻译并不会通过读整个法语句子,再记忆里面的东西,然后从零开始,机械式地翻译成一个英语句子。而人工翻译,首先会做的可能是先翻译出句子的部分,再看下一部分,并翻译这一部分。看一部分,翻译一部分,一直这样下去。你会通过句子,一点一点地翻译,因为记忆整个的像这样的的句子是非常困难的。
- 在编码解码结构中,会看到它对于短句子效果非常好,于是它会有一个相对高的Bleu分(Bleu score),但是对于长句子而言,比如说大于30或者40词的句子,它的表现就会变差。随着单词数量变化,短的句子会难以翻译,因为很难得到所有词。对于长的句子,效果也不好,因为在神经网络中,记忆非常长句子是非常困难的。
- 你会见识到注意力模型,它翻译得很像人类,一次翻译句子的一部分。而且有了注意力模型,机器翻译系统的表现会一直很好,因为翻译只会翻译句子的一部分,你不会看到有一个巨大的下倾
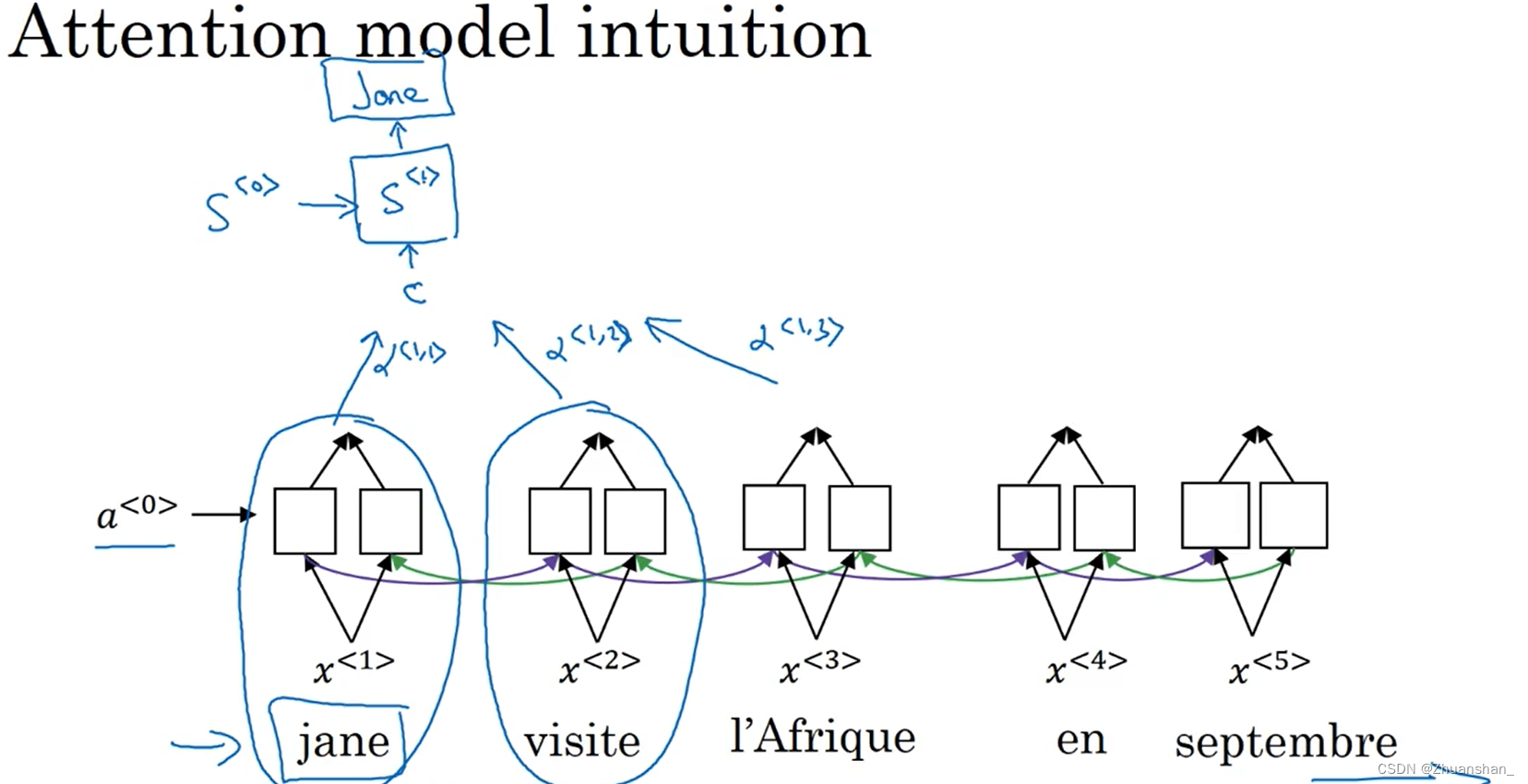
- 我们需要翻译这个句子,需要计算出单词的特征集,这里,使用另一个RNN生成英文翻译,其会计算注意力权重
α
(
1
,
1
)
\alpha^{(1,1)}
α(1,1)表示在
x
1
x^1
x1,即第一个信息处上需要放多少注意力,
α
(
1
,
2
)
\alpha^{(1,2)}
α(1,2)表示在翻译jane这个词时需要花多少注意力权重在第二个词上,同理在第三个单词也是这样,结果标记为C,并传入RNN中。
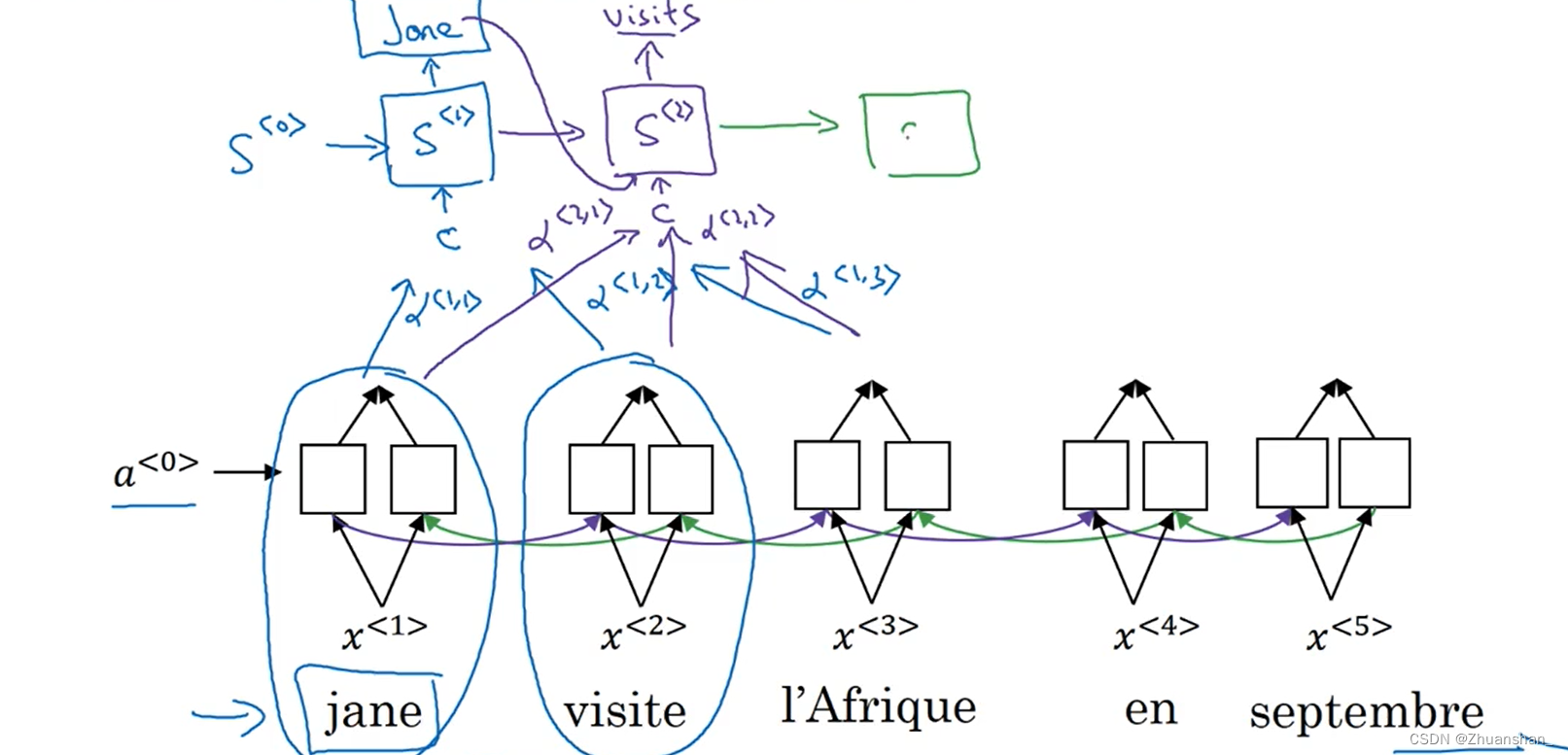
- 在翻译第二个词时也是如此,会计算临近词的注意力权重,并传入到 S ( 2 ) S^{(2)} S(2)中,同时第一个单词的翻译结果也会作为输入传入。
- 因此,一个解码RNN由两个输入组成,一个是上一轮的输出 y < t − 1 > y^{<t-1>} y<t−1>,另一个是注意力上下文 c ( t ) c^{(t)} c(t),两个输入通过拼接的方式一起输入至解码RNN
模型推导

-
翻译过程使用一个单向RNN:
1、每次考虑的所有注意力权重之和等于1
∑ t ′ a < 1 , t ′ > = 1 \sum_{t^{\prime}} a^{<1, t^{\prime}>}=1 t′∑a<1,t′>=1
2、特征步激活值和注意力权重的乘积之和作翻译模型的输入,即上下文 C < i > C^{<i>} C<i>
C < i > = ∑ t " α < 1 , t " > a < t " > C^{<i>}=\sum_{t^"} \alpha^{<1, t^">} a^{<t^">} C<i>=t"∑α<1,t">a<t"> -
α < t , t ′ > \alpha^{<t,t^\prime>} α<t,t′>表示在 t t t处生成输出词时,需要花多少注意力在 t ′ t^\prime t′上
这里看着很拗口,原文献使用 α i j \alpha_{ij} αij,例如 α t , 1 \alpha_{t,1} αt,1表示翻译第t个样本时需要花多少注意力在第一个样本上
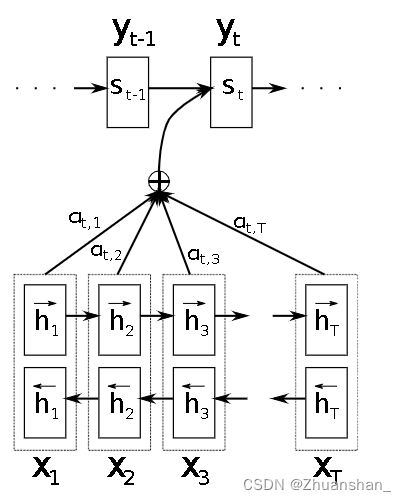
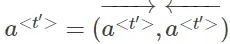
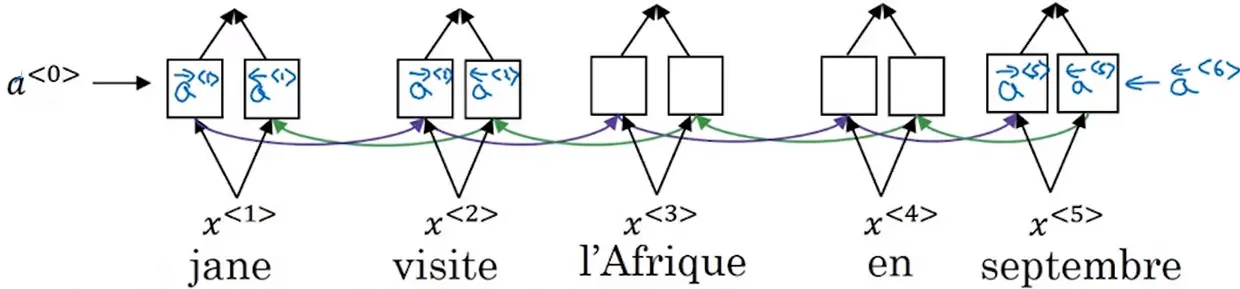
- 表示激活值,左右箭头分别表示前向传播和后向传播的激活值

参考资料
- Transformer论文逐段精读【论文精读】
- Deeplearning.ai深度学习教程中文笔记
- 吴恩达深度学习deeplearning.ai