1、TORCH.OPTIM
torch.optim是一个实现各种优化算法的包。大多数常用的方法都已经支持,并且接口足够通用,因此将来也可以轻松集成更复杂的方法
1、如何使用优化器
要使用,torch.optim您必须构造一个优化器对象,该对象将保存当前状态并根据计算的梯度更新参数。
1、如何使用优化器
要构造一个,Optimizer您必须给它一个包含要优化的参数(全部应该是Variables)的可迭代对象。然后,您可以指定优化器特定的选项,例如学习率、权重衰减等。
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr=0.0001)
Optimizer还支持指定每个参数选项。为此,不要传递Variable s 的可迭代对象,而是传递 dict s 的可迭代对象。它们中的每一个都将定义一个单独的参数组,并且应该包含一个params键,其中包含属于它的参数列表。其他键应与优化器接受的关键字参数匹配,并将用作该组的优化选项。
例如,当想要指定每一层的学习率时,这非常有用:
optim.SGD([
{'params': model.base.parameters()},
{'params': model.classifier.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9)
这意味着model.base的参数将使用默认的学习率1e-2, model.classifier的参数将使用学习率1e-3,所有参数将使用动量0.9 。
2、采取优化步骤
所有优化器都实现一个step()更新参数的方法。它可以通过两种方式使用:
optimizer.step()
这是大多数优化器支持的简化版本。一旦使用例如计算梯度函数 backward(),就可以调用该函数。
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
2、Base class
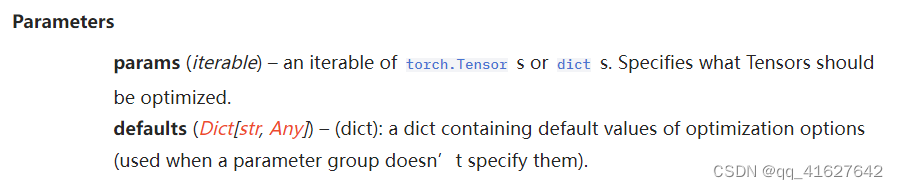
CLASStorch.optim.Optimizer(params, defaults)
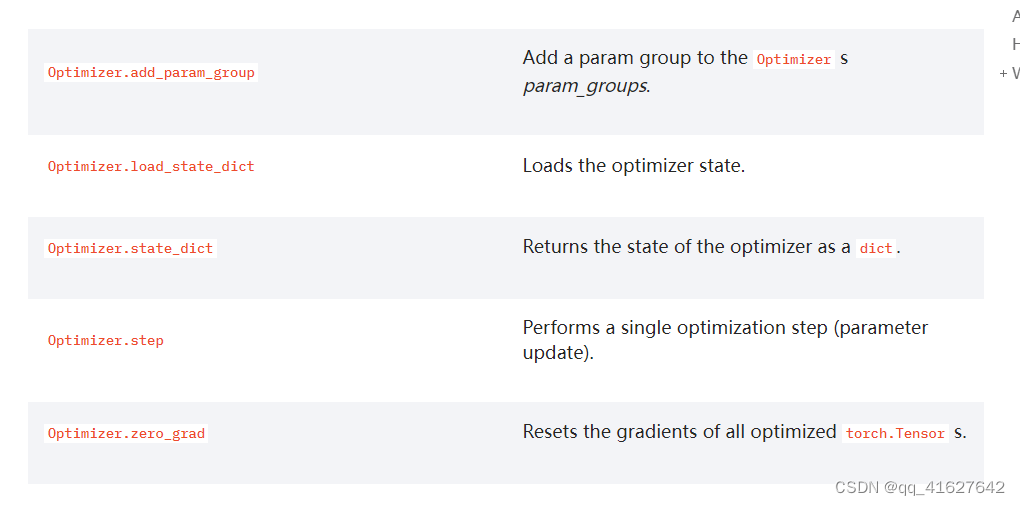
1、Optimizer.zero_grad
Optimizer.zero_grad(set_to_none=True)[source]
Resets the gradients of all optimized torch.Tensor s.
2、Optimizer.state_dict
它包含两个条目:
state:保存当前优化状态的 Dict。其内容在优化器类之间存在差异,但存在一些共同特征。例如,状态是按参数保存的,但参数本身不保存。state是一个将参数 ids 映射到 Dict 的字典,其中状态对应于每个参数。
param_groups:包含所有参数组的列表,其中每个参数组是一个字典。每个参数组包含特定于优化器的元数据,例如学习率和权重衰减,以及组中参数的参数 ID 列表。
注意:参数 ID 可能看起来像索引,但它们只是将状态与 param_group 关联的 ID。当从 state_dict 加载时,优化器将压缩 param_group params(int ID)和优化器param_groups(实际nn.Parameters),以便匹配状态而不需要额外的验证。
返回的状态字典可能类似于:
{
'state': {
0: {'momentum_buffer': tensor(...), ...},
1: {'momentum_buffer': tensor(...), ...},
2: {'momentum_buffer': tensor(...), ...},
3: {'momentum_buffer': tensor(...), ...}
},
'param_groups': [
{
'lr': 0.01,
'weight_decay': 0,
...
'params': [0]
},
{
'lr': 0.001,
'weight_decay': 0.5,
...
'params': [1, 2, 3]
}
]
}
Optimizer.load_state_dict