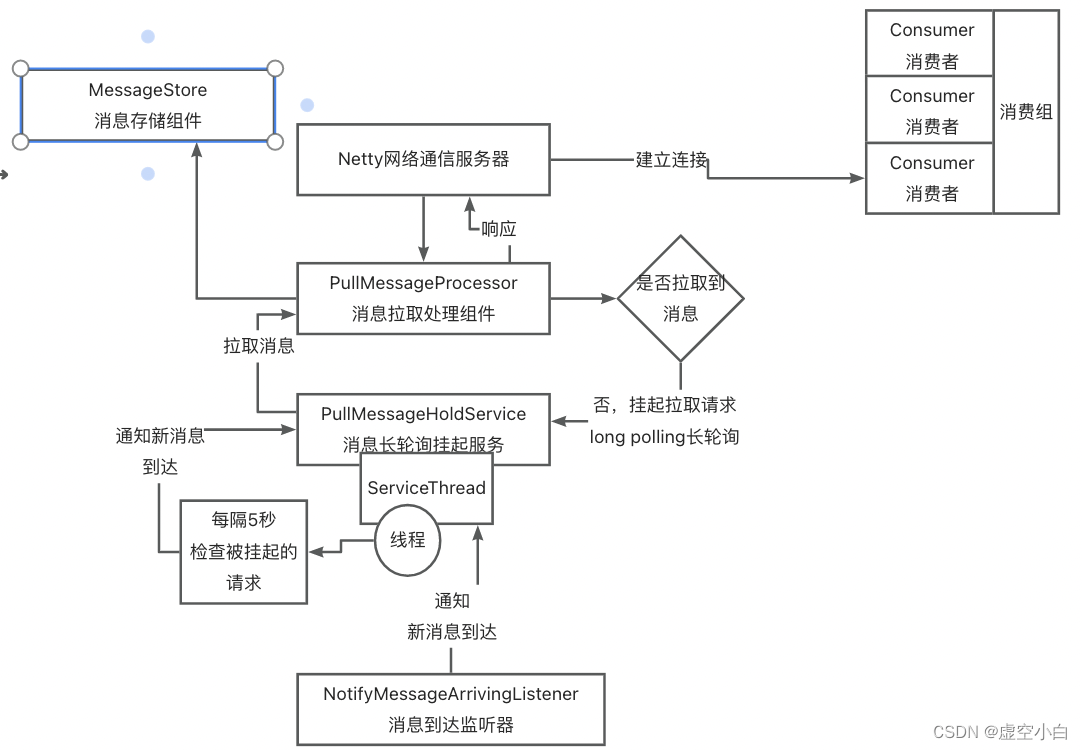
一、前言
AI能自己开发自己或者开发和一个很像自己的东西吗?显然是可以的!因为AI模型的算法,基本就是学习和递归
二、大模型的算法实现例子
本例子就是通过AI模型来写
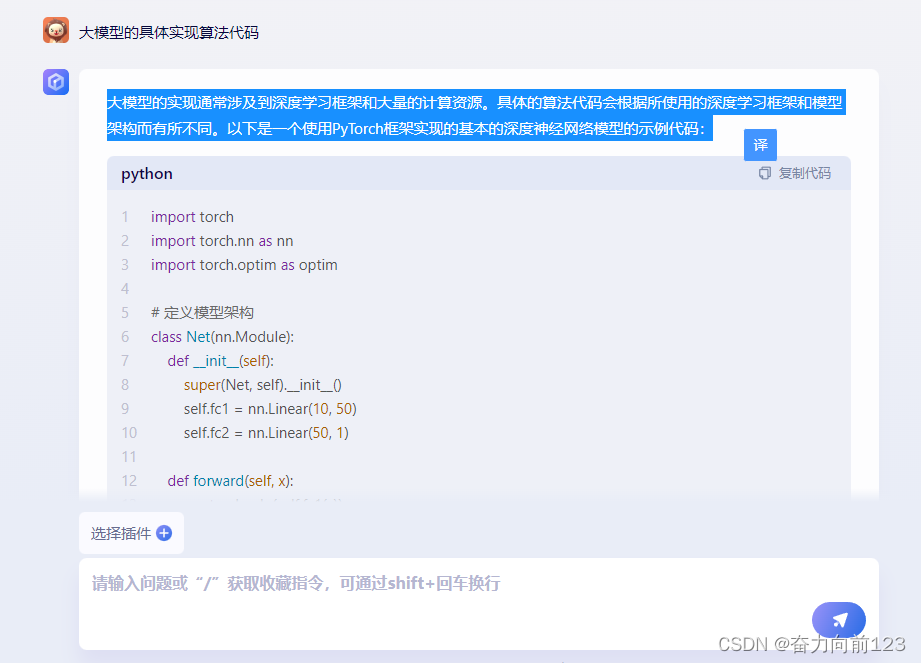
大模型的实现通常涉及到深度学习框架和大量的计算资源。具体的算法代码会根据所使用的深度学习框架和模型架构而有所不同。以下是一个使用PyTorch框架实现的基本的深度神经网络模型的示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义模型架构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(10, 50)
self.fc2 = nn.Linear(50, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 初始化模型和优化器
model = Net()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(100):
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 打印训练信息
if (epoch+1) % 10 == 0:
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))这个示例代码使用了PyTorch框架实现了一个简单的全连接神经网络模型。在实际的大模型实现中,通常会使用更复杂的模型架构、更多的计算资源以及更高级的训练技巧。具体的实现代码会根据所使用的深度学习框架、模型架构和训练技巧而有所不同。
三、开发一个聊天机器人的代码实现
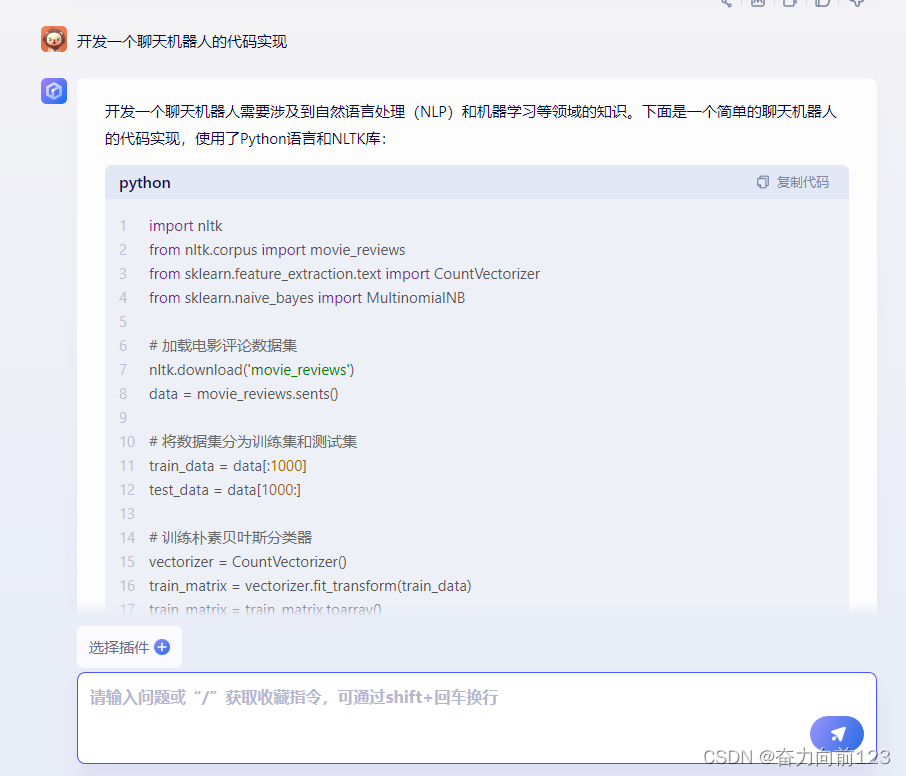
开发一个聊天机器人需要涉及到自然语言处理(NLP)和机器学习等领域的知识。下面是一个简单的聊天机器人的代码实现,使用了Python语言和NLTK库:
import nltk
from nltk.corpus import movie_reviews
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
# 加载电影评论数据集
nltk.download('movie_reviews')
data = movie_reviews.sents()
# 将数据集分为训练集和测试集
train_data = data[:1000]
test_data = data[1000:]
# 训练朴素贝叶斯分类器
vectorizer = CountVectorizer()
train_matrix = vectorizer.fit_transform(train_data)
train_matrix = train_matrix.toarray()
clf = MultinomialNB()
clf.fit(train_matrix, train_data)
# 测试分类器
test_matrix = vectorizer.transform(test_data)
test_matrix = test_matrix.toarray()
predictions = clf.predict(test_matrix)
# 输出分类结果
for i in range(len(predictions)):
print(predictions[i])
print('Positive' if movie_reviews.categories[predictions[i]] == 'pos' else 'Negative')
print('Score: ', clf.class_log_prior_)这个代码实现了一个简单的朴素贝叶斯分类器,用于对电影评论进行分类。它使用了NLTK库中的电影评论数据集,将数据集分为训练集和测试集,然后使用CountVectorizer将文本转换为向量,再使用MultinomialNB训练朴素贝叶斯分类器。最后,使用测试集进行测试,输出分类结果。
四、开发一个特定行业的客服机器人
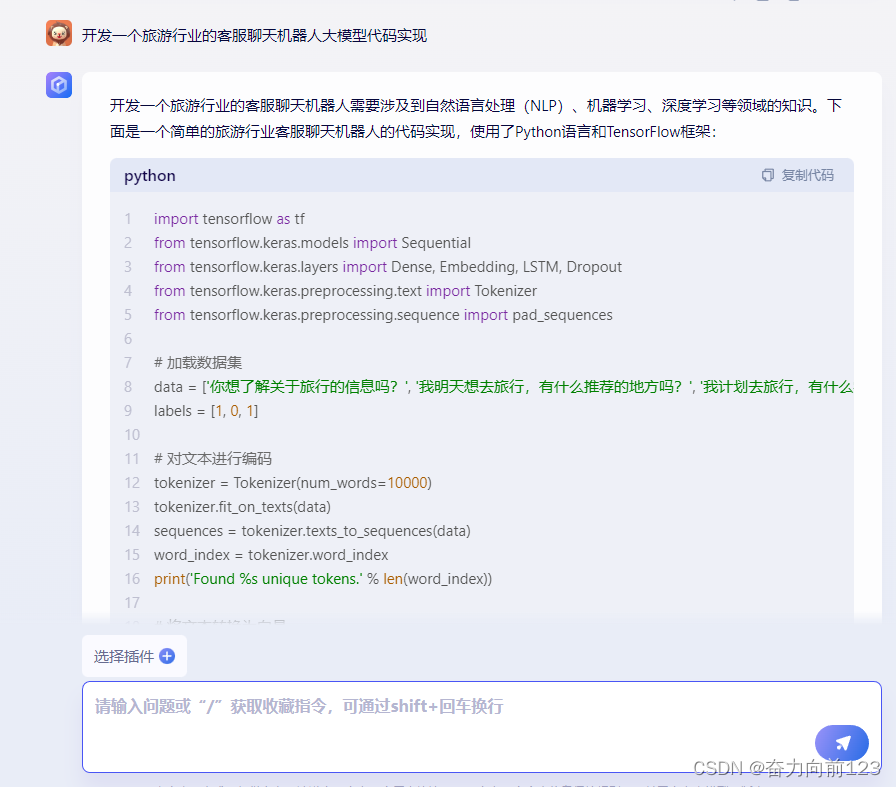
开发一个旅游行业的客服聊天机器人需要涉及到自然语言处理(NLP)、机器学习、深度学习等领域的知识。下面是一个简单的旅游行业客服聊天机器人的代码实现,使用了Python语言和TensorFlow框架:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, LSTM, Dropout
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 加载数据集
data = ['你想了解关于旅行的信息吗?', '我明天想去旅行,有什么推荐的地方吗?', '我计划去旅行,有什么需要注意的事项吗?']
labels = [1, 0, 1]
# 对文本进行编码
tokenizer = Tokenizer(num_words=10000)
tokenizer.fit_on_texts(data)
sequences = tokenizer.texts_to_sequences(data)
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
# 将文本转换为向量
data = pad_sequences(sequences, maxlen=100, padding='post')
labels = tf.keras.utils.to_categorical(labels, num_classes=2)
# 构建模型
model = Sequential()
model.add(Embedding(10000, 16, input_length=100))
model.add(LSTM(32))
model.add(Dropout(0.5))
model.add(Dense(2, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(data, labels, epochs=10, batch_size=32)
# 测试模型
test_data = ['我明天要去旅行,有什么需要准备的吗?']
test_sequences = tokenizer.texts_to_sequences(test_data)
test_data = pad_sequences(test_sequences, maxlen=100, padding='post')
predictions = model.predict(test_data)
print('Predicted:', predictions)这个代码实现了一个简单的旅游行业客服聊天机器人,使用了LSTM神经网络模型。它首先加载数据集并对文本进行编码,然后构建一个包含Embedding层、LSTM层、Dropout层和Dense层的神经网络模型。最后,使用训练集对模型进行训练,并使用测试集进行测试。