数据探索:观察数据之间的关系
分别判断 性别(sex)、船舱等级(Pclass)、年龄(Age)、有无父母子女(Parch)、有无兄弟姐妹(SibSp)、票价(Fare) 和 港口(Embarked)等因素和 存活(Survived)之间的关系
In [27]:
sex_survived_cor = train_data[['Sex','Survived']]
sex_survived_cor.groupby('Sex').mean().plot.bar(width=0.1)
Out[27]:
<Axes: xlabel='Sex'>
train_data.loc[:, 'Sex'].value_counts()
Out[28]:
male 577 female 314 Name: Sex, dtype: int64
In [29]:
pclass_survived_cor = train_data[['Pclass','Survived']]
pclass_survived_cor.groupby('Pclass').mean().plot.bar(width=0.2)
Out[29]:
<Axes: xlabel='Pclass'>
parch_df, no_parch_df = train_data[train_data.Parch != 0], train_data[train_data.Parch == 0] prach_no_survived,prach_survived = parch_df['Survived'].value_counts()[:2] noprach_no_survived, noparch_survived = no_parch_df['Survived'].value_counts()[:2] plt.bar(['parch','noparch'],[prach_survived / (prach_no_survived+prach_survived),noparch_survived / (noprach_no_survived+noparch_survived)],width=0.2)
Out[30]:
<BarContainer object of 2 artists>
sibsp_df, no_sibsp_df = train_data[train_data.SibSp != 0], train_data[train_data.SibSp == 0] sibsp_no_survived,sibsp_survived = sibsp_df['Survived'].value_counts()[:2] nosibsp_no_survived,nosibsp_survived = no_sibsp_df['Survived'].value_counts()[:2] plt.bar(['sibsp','nosibsp'],[sibsp_survived/(sibsp_no_survived+sibsp_survived),nosibsp_survived/(nosibsp_no_survived+nosibsp_survived)],width=0.2)
Out[31]:
<BarContainer object of 2 artists>
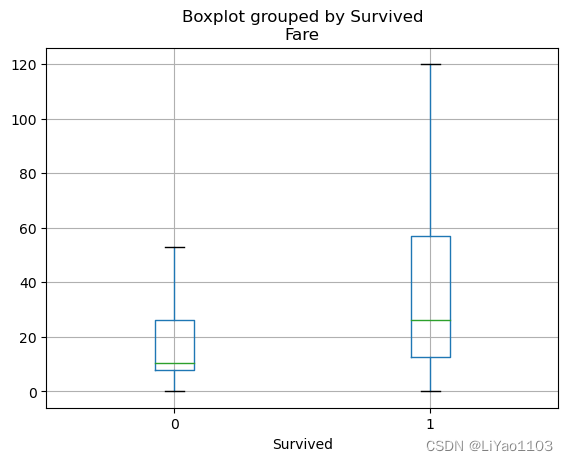
1、观察fare对应的分布情况
2、对于fare和survived的分布情况进行分析
In [32]:
plt.figure(figsize=(10,5)) train_data.Fare.hist(bins=70)
Out[32]:
<Axes: >
fare_df = train_data[['Fare','Survived']] fare_df.boxplot(column='Fare', by='Survived',showfliers=False)
Out[33]:
<Axes: title={'center': 'Fare'}, xlabel='Survived'>
使用皮尔逊相关系数来分析变量之间的关系
模型构建以及模型评价¶
In [42]:
from sklearn import model_selection
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
def top_k_features(X,Y,top_k=6):
# random forest
rfc = RandomForestClassifier(random_state=0)
rf_search_grid = {'n_estimators': [500,1000], 'min_samples_split': [2, 3], 'max_depth': [10,20]}
rf_grid = model_selection.GridSearchCV(rfc, rf_search_grid, n_jobs=25, cv=10, verbose=1)
rf_grid.fit(X, Y)
feature_importance = rf_grid.best_estimator_.feature_importances_
feature_importance_df = pd.DataFrame({'feature':list(X), "importance":feature_importance}).sort_values('importance',ascending=False)
top_k_feature_importance_df = feature_importance_df.head(top_k)['feature']
# decision tree option choice
# dtc = DecisionTreeClassifier(random_state=0)
# dt_search_grid = {'min_samples_split': [2, 3], 'max_depth': [10,20]}
# dt_grid = model_selection.GridSearchCV(dtc, dt_search_grid, n_jobs=25, cv=10, verbose=1)
# dt_grid.fit(X, Y)
# feature_importance = rf_grid.best_estimator_.feature_importances_
# feature_importance_df = pd.DataFrame({'faeture':list(X), "importance":feature_importance}).sort_values('importance',ascending=Falsel)
# top_k_feature_importance_df = feature_importance_df.head(top_k)['feature']
return top_k_feature_importance_df, feature_importance_df
In [43]:
X = train_data.drop(['Survived'],axis=1) Y = train_data['Survived']
In [44]:
top_k_features, feature_importance = top_k_features(X,Y)
Fitting 10 folds for each of 8 candidates, totalling 80 fits
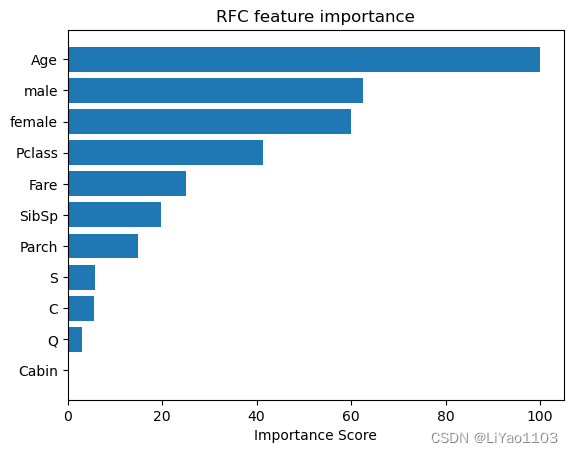
通过随机森林,我们能够得到数据集中的重要特征,并且忽略无关紧要的特征
In [45]:
rf_feature_importance = 100 * (feature_importance.importance / feature_importance.importance.max())
rf_idx = np.where(rf_feature_importance)[0]
pos = np.arange(rf_feature_importance.shape[0])
plt.barh(pos, rf_feature_importance[::-1])
plt.yticks(pos, feature_importance.feature[::-1])
plt.xlabel("Importance Score")
plt.title("RFC feature importance")
Out[45]:
Text(0.5, 1.0, 'RFC feature importance')
模型构建
将上述对 train_data 的分析扩展到整个数据集
常见的方法有 Bagging、Boosting 和 Stacking 这三种
Bagging:就是基于多个基分类器进行加权和投票来得到预测结果
Boosting:每一基学习器是在上一个学习器学习的基础上,会修正上个学习器的错误,像AdaBoost
Stacking:用一个学习器去组合上层的基学习器,因此会产生分层的结构
In [46]:
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn import model_selection from sklearn.model_selection import KFold from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier,RandomForestRegressor from sklearn.svm import SVC from sklearn.preprocessing import StandardScaler
In [47]:
train_data = pd.read_csv(r'../data/1/train.csv') test_data = pd.read_csv(r'../data/1/test.csv')
In [48]:
test_data['Survived'] = 0 concat_data = train_data.append(test_data)
C:\Users\MrHe\AppData\Local\Temp\ipykernel_41864\2851212731.py:2: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead. concat_data = train_data.append(test_data)
In [51]:
# first step concat_data.loc[concat_data.Cabin.notnull(), 'Cabin'] = '1' concat_data.loc[concat_data.Cabin.isnull(), 'Cabin'] = '0' # second step # concat_data.loc[concat_data.Embarked.isnull(),'Embarked'] = concat_data.Embarked.dropna().mode().values # third step embark_dummies = pd.get_dummies(concat_data.Embarked) concat_data = pd.concat([concat_data,embark_dummies],axis=1) # 4 sex_dummies = pd.get_dummies(concat_data.Sex) concat_data = pd.concat([concat_data,sex_dummies],axis=1) # 5 concat_data['Fare'] = concat_data.Fare.fillna(50) concat_df = concat_data[['Age', 'Fare', 'Pclass', 'Survived']] train_df_age = concat_df.loc[concat_data['Age'].notnull()] predict_df_age = concat_df.loc[concat_data['Age'].isnull()] X = train_df_age.values[:, 1:] Y = train_df_age.values[:, 0] regr = RandomForestRegressor(n_estimators=1000, n_jobs=-1) regr.fit(X, Y) predict_ages = regr.predict(predict_df_age.values[:,1:]) concat_data.loc[concat_data.Age.isnull(), 'Age'] = predict_ages # 6 concat_data['Age'] = StandardScaler().fit_transform(concat_data.Age.values.reshape(-1,1)) # 7 concat_data['Fare'] = pd.qcut(concat_data.Fare, 5) concat_data['Fare'] = pd.factorize(concat_data.Fare)[0] # 8 concat_data.drop(['Embarked','Sex','PassengerId',"Name","Ticket"],axis=1,inplace=True)
In [52]:
def top_k_features(X,Y,top_k=6):
# random forest
rfc = RandomForestClassifier(random_state=0)
rf_search_grid = {'n_estimators': [500,1000], 'min_samples_split': [2, 3], 'max_depth': [10,20]}
rf_grid = model_selection.GridSearchCV(rfc, rf_search_grid, n_jobs=25, cv=10, verbose=1)
rf_grid.fit(X, Y)
feature_importance = rf_grid.best_estimator_.feature_importances_
feature_importance_df = pd.DataFrame({'feature':list(X), "importance":feature_importance}).sort_values('importance',ascending=False)
top_k_features = feature_importance_df.head(top_k)['feature']
# decision tree option choice
# dtc = DecisionTreeClassifier(random_state=0)
# dt_search_grid = {'min_samples_split': [2, 3], 'max_depth': [10,20]}
# dt_grid = model_selection.GridSearchCV(dtc, dt_search_grid, n_jobs=25, cv=10, verbose=1)
# dt_grid.fit(X, Y)
# feature_importance = rf_grid.best_estimator_.feature_importances_
# feature_importance_df = pd.DataFrame({'faeture':list(X), "importance":feature_importance}).sort_values('importance',ascending=Falsel)
# top_k_feature_importance_df = feature_importance_df.head(top_k)['feature']
return top_k_features, feature_importance_df
In [53]:
X = concat_data[:len(train_data)].drop(['Survived'],axis=1) Y = concat_data[:len(train_data)]['Survived'] test_X = concat_data[len(train_data):].drop(['Survived'],axis=1) top_k_features, feature_importance_df = top_k_features(X,Y) filter_X, filter_test_X = pd.DataFrame(X[top_k_features]),pd.DataFrame(test_X[top_k_features])
Fitting 10 folds for each of 8 candidates, totalling 80 fits
由于在训练集上面进行训练,为了避免数据的泄露,在这里采用的是 K 折交叉验证进行训练的过程
In [55]:
n_train, n_test = filter_X.shape[0], filter_test_X.shape[0]
kf = KFold(n_splits=10,random_state=0,shuffle=True)
def k_fold_train(clf, x_train, y_train, x_test):
pro_train = np.zeros((n_train,))
pro_test = np.zeros((n_test,))
pro_test_skf = np.empty((10, n_test))
for i, (train_idx, test_idx) in enumerate(kf.split(x_train)):
x_train_sample = x_train[train_idx]
y_train_sample = y_train[train_idx]
x_test_sample = x_train[test_idx]
clf.fit(x_train_sample, y_train_sample)
pro_train[test_idx] = clf.predict(x_test_sample)
pro_test_skf[i,:] = clf.predict(x_test)
pro_test[:] = pro_test_skf.mean(axis=0)
return pro_train.reshape(-1, 1), pro_test.reshape(-1,1)
In [56]:
rfc = RandomForestClassifier(n_estimators=500, warm_start=True, max_features='sqrt',max_depth=6,
min_samples_split=3, min_samples_leaf=2, n_jobs=-1, verbose=0)
dtc = DecisionTreeClassifier(max_depth=6)
svm = SVC(kernel='linear', C=0.025)
这里给大家提供使用 top-k feature 的方法
In [57]:
# 1 X, Y, test_X = X.values, Y.values, test_X.values # 2 # X, Y, test_X = filter_X.values, Y.values, filter_test_X.values
In [58]:
rfc_train, rfc_test = k_fold_train(rfc, X, Y, test_X) dtc_train, dtc_test = k_fold_train(dtc, X, Y, test_X) svm_train, svm_test = k_fold_train(svm, X, Y, test_X)
# 评分矩阵
def score(predictions, labels):
return np.sum([1 if p == a else 0 for p, a in zip(predictions, labels)]) / len(labels)
In [60]:
from sklearn.ensemble import VotingClassifier
vclf = VotingClassifier(estimators=[('rfc', rfc), ('dtc', dtc), ('svm', SVC(kernel='linear', C=0.025, probability=True))], voting='soft',
weights=[1,1,3])
vclf.fit(X, Y)
predictions = vclf.predict(test_X)
In [61]:
labels = pd.read_csv(r'../data/1/label.csv')['Survived'].tolist()
In [62]:
methods = ["random forest", "decision tree", "support vector machine"]
reses = [rfc_test, dtc_test, svm_test]
for method, res in zip(methods, reses):
print("Accuracy: %0.4f [%s]" % (score(np.squeeze(res), labels), method))
Accuracy: 0.8780 [random forest] Accuracy: 0.6603 [decision tree] Accuracy: 1.0000 [support vector machine]
In [63]:
print("Accuracy: %0.4f [%s]" % (score(predictions, labels), "Ensemble model"))
Accuracy: 1.0000 [Ensemble model]