一、缓存
1、基本知识
(1)缓存是指可以进行高速数据交换的存储器,它先于内存与CPU交换数据,因此速率很快。(from百度)
(2)如果处理器在缓存中找到了所需求的数据项,那么就说明发生了缓存命中;如果没有,则说明发生了缓存缺失。
(3)缓存缺失需要的时间取决于存储器的延迟和带宽。
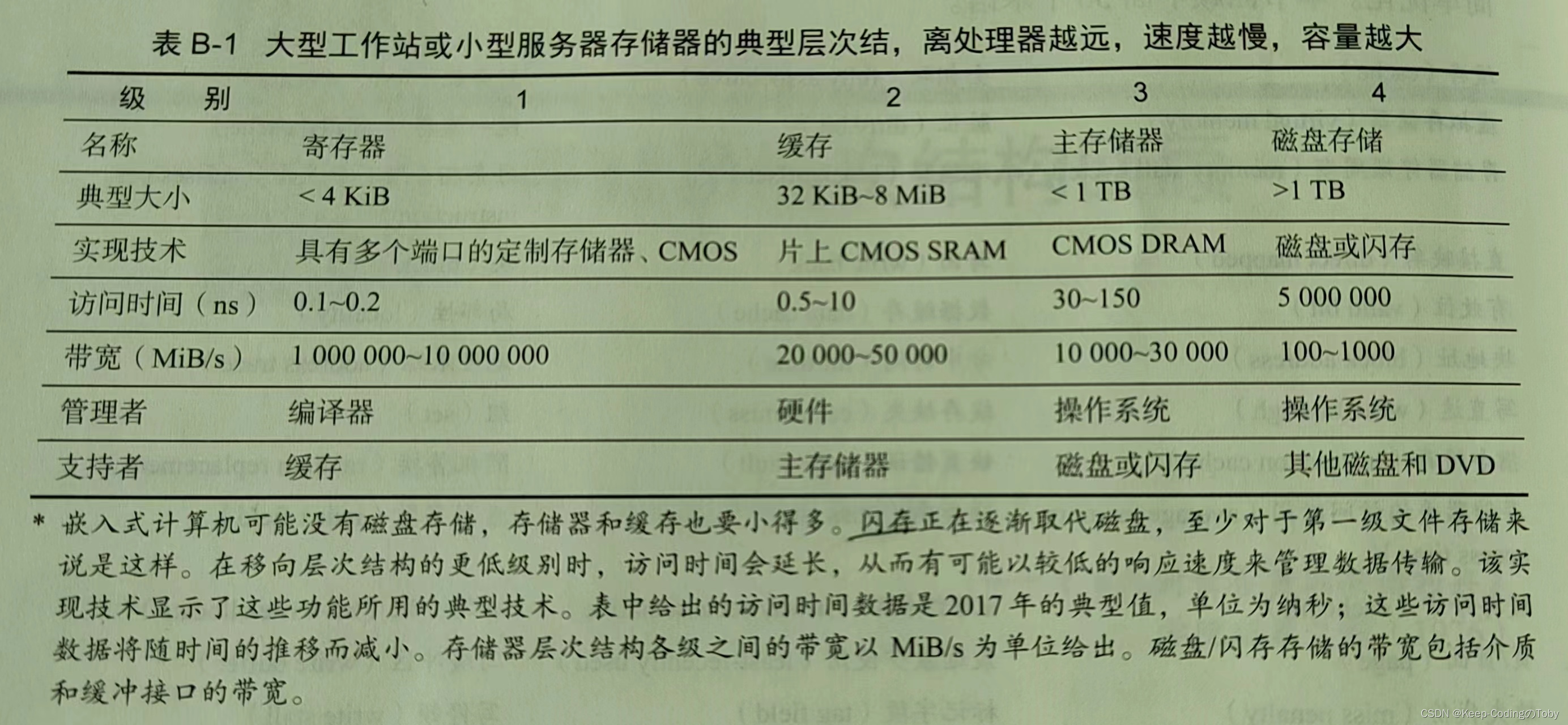
(4)计算机每一级存储器层次结构的大小与访问时间范围。
2、缓存性能
(1)处理器由于等待存储器访问造成了停顿周期数,成为存储器停顿周期。
(2)性能为处理器周期数与存储器停顿周期数之和与时钟周期时间的乘积。
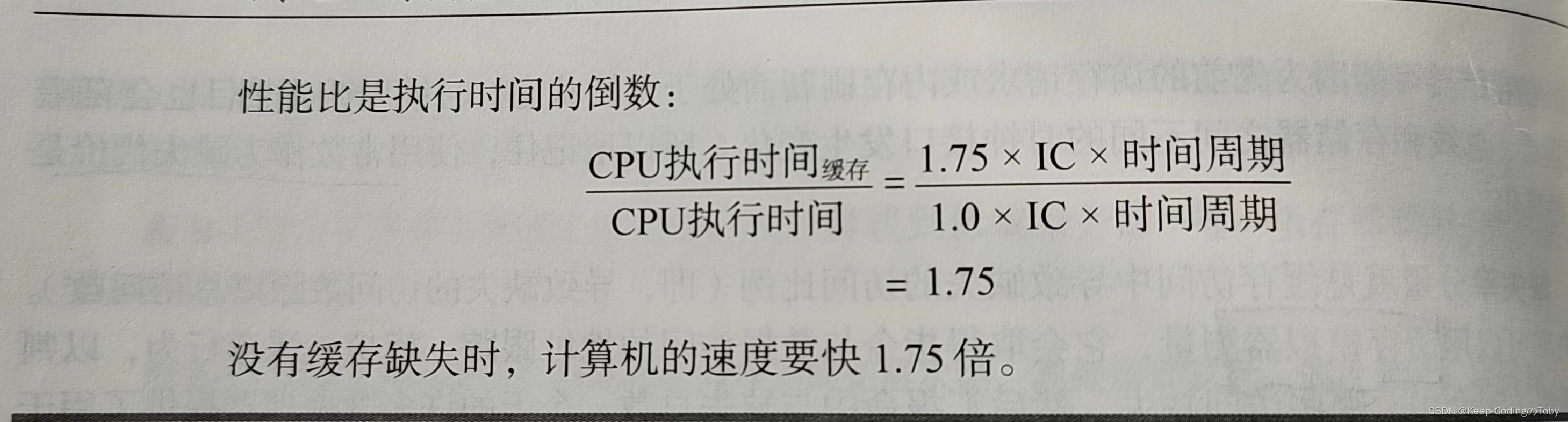
(3)重要公式

解释最后一行:
a、缺失代价:简化后作为一个常数。
b、缺失率:缓存访问中导致缺失的访问比率。(可以用缓存模拟器测量,模拟缓存行为)。
c、IC:指令数(对于支持推测执行的处理器,只计算提交的指令数),可以用相同方式来测量每条指令的存储器访问次数。
这两个公式值得注意:
给伙伴们拍道例题,就知道怎么用公式了:


3、4个存储器层次结构问题
四个问题:
1、一个快可以放在缓存中的什么位置?
(1)每个块只能出现在一个位置:直接映射。映射通常是——(块地址)MOD(缓存中的块数)。
(2)一个块可以在缓存中任意位置:全相联。
(3)如果一个块可以放在存中由有限个位置组成的组(set)内,就说该缓存是组相联的。组就是缓存中的一组块。块首先映射到组,然后这个块可以放在这个组中的任意位置。通常以位选择方式来选定组,即—— (块地址) MOD (缓存中的组数)。
如果组中有n个块,则称该缓存放置为n路组相联。

2、一个块就在缓存中,如何找到它?
缓存中每个块帧上都有一个地址标记,它给出了块地址。每个缓存块的标记包含了用于检测它是否与处理器的块地址相匹配的信息。由于速度非常重要,所以会对所有可能标记进行并行扫描,这是一条规则。
获知缓存块中是否包含有效信息最常见的做法是向标记中添加一个有效位,表明这一项是否包含有效地址。如果没有设置这个位,则此地址无法匹配。图B-2显示了地址是如何划分的。第一次划分是在块地址和块偏移之间,然后将块帧地址进一步分为标记字段和索引字段。块偏移字段从块中选择所需数据,索引字段选择组,标记字段与之比较以便判断是否命中。

尽管可以对标记之外的更多地址位进行对比,但并不需要,原因如下。
(1)不用在对比中使用偏移量,因为对比只是判断整个块是否存在,而只有匹配的块才需要使用偏移。
(2)核对索引是多余的,因为它是用来选择待核对组的。例如,存储在第0组的地址,其索引字段必须为0,否则就不能存储在第0组中;第1组的索引值必须为1,以此类推。这一优化通过缩小缓存标记的存储器宽度来节省硬件和功耗。
如果总缓存大小保持不变,增大相联度将增加每个组中的块数,从而减小索引的大小大标记的大小。也就是说、图B-2中的标记索引边界因为相联度增大而向右移动,右端点是设有索引字段的全相联缓存。
3、在缓存缺失时应当替换哪个块?
当缺失时,缓存控制器必须选择一个将被所需数据替换的块。直接映射布置方式的好处就是简化了硬件判决:只会查看一个块帧,以确定是否命中,而且只有这个块可被替换。对于全相联或组相联布置方式,在缺失时会有许多块可供选择。对于选择替换哪个块,主要有以下3种策略。
(1)随机——为进行均匀分配,候选块是随机选择的。一些系统生成伪随机块编号,以实现可重复的行为,这在调试硬件时特别有用。
(2)最近最少使用(LRU)一为了减小丢弃即将需要的信息的可能性,对数据块的访问会被记录下来。依靠过去来预测未来,被替换的块是未使用时间最久的块。LRU依赖于局部性的一条推论:如果最近用过的块很可能会被再次用到,那么放弃最近最少使用的块是一种不错的选择。
(3)先进先出(FIFO)一因为LRU的计算可能非常复杂,所以这一策略是通过确定最早的块来近似LRU,而不是直接确定LRU。
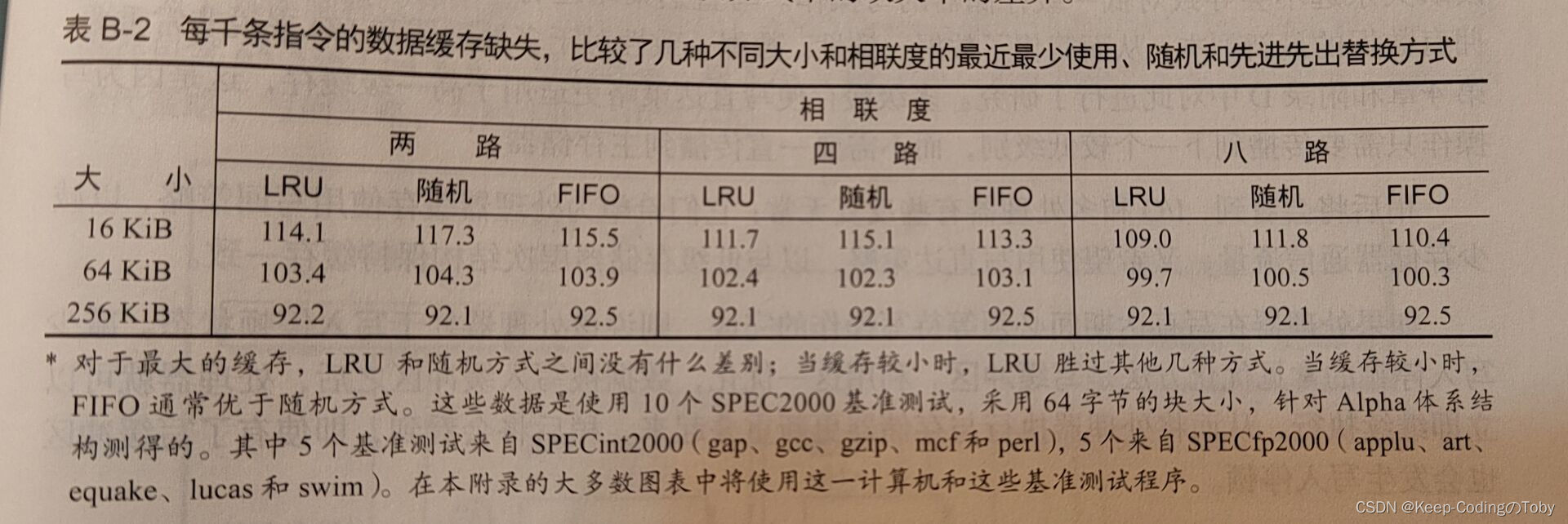
随机替换的一个好处是易于用硬件实现。随着要跟踪块数的增加,LRU的成本也变得越来越高,通常只能采用近似法。一种常见的近似方法(通常称为“伪LRU”) 是为缓存中的每个组设定一组比特,每个比特对应于缓存中的一路[一路就是组相联缓存中的bank;四路组相联缓存中有四路]。在访问一个组中特定的路的时候,需要将这一路对应的比特打开。如果同一个组中所有路的比特都未打开的情况下,这一个组中除了该路的比特都应该关闭。在必须替换一个块时,处理器从相应比特被关闭的路中选择一个块,如果有多种选择,则随机选定。这种方法会给出近似LRU,这是因为自上次组中的所有块被访问之后,被替换块再没有被访间过。表B-2展示了LRU、随机和FIFO这三种替换方式中的缺失率的差异。
4、在写入时发生什么?
大多数处理器缓存访问是读操作。所有指令访问都是读,大多数指令不会向存储器写入数据。RISC-V程序中存储指令占10%,载入指令占26%;总存储器通信流量中,写操作占10%/(100%+26%+10%),大约为7%。在数据缓存通信流量中,写操作占10%/(26%+10%),大约为28%/要加快常见情景的执行速度,就意味着要针对读操作优化缓存,尤其是处理器通常会等待读取的完成,而不会等待写操作。但Amdahla定律(见19节)提醒我们,高性能设计不能忽视写操作的速度。
可以在读取和比对标记的同时从缓存中读取块,只要有了块地址就开始读取块。如果读命中,则立即将块中所需部分传送给处理器。如果读缺失,只需忽略所读值即可。
不能对写操作应用这一优化。要想修改一个块,必须先核对标记,以查看该地址是否命中。由于标记核对不能并行执行,所以写操作需要的时间通常要长于读操作。另一种复杂性在于处理器还指定写入的大小,通常是1~8字节,并且只能改变一个块的相应部分。而读取则与之不同,可以毫无顾虑地访问超出所需的更多字节。
写入策略通常可以用来区分缓存设计。在写入缓存时,有下面两种基本选项。
(1)写直达——信息被写人缓存中的块和低一级存储器中的块。
(2)写回——信息仅被写到缓存中的块。修改后的缓存块仅在被替换时才写到主存储器。
为降低在替换时写回块的频率,通常会使用一种称为脏位的功能。这一状态位表示一个块是脏的(在缓存中经历了修改)还是干净的(未被修改)。如果它是于净的,则在缺失时不会写回该块,因为在低级存储器中可以找到与缓存中相同的信息。
写回和写直达策略都有自己的优势。采用写回策略时,写操作的速度与缓存存储器的速度相同、一个块中的多个写操作只需要对低一级存储器进行一次写入。由于一些写入内容不会进入存储器,所以写回方式使用的存储带宽较少,这使得写回策略对多处理器更具吸引力。由于写回策略对存储器层次结构其余部分及存储器互连的使用少于写直达,所以它还可以节省功耗,对于嵌入式应用程序极具吸引力。
相对于写回策略,写直达策略更容易实现。缓存总是干净的,所以它与写回策略不同,读缺失永远不会导致对低一级存储器的写操作。写直达策略还有一个好处下一级存储器中拥有数据的最新副本,从而简化了数据一致性。数据一致性对于多处理器和来说非常重要,第4章和附录D中对此进行了研究。多级缓存使写直达策略更适用于高一级缓存,这是因为写操作只需要传播到下一个较低级别,而不需要一直传播到主存储器。
如果处理器在写直达期间必须等待写操作的完成,则说该处理器处于写入停顿状态。减少写入停顿的常见优化方法是写缓冲区。利用这一优化,数据被写入缓冲区之后,处理器就可以立即继续执行,从而将处理器执行与存储器更新重叠起来。稍后将会看到,即使有了写缓冲区也会发生写入停顿。
由于在写入时并不需要该项数据,所以在发生写缺失时有以下两种选项。
(1)写分配——在发生写缺失时将该块读到缓存中,随后对其执行写命中操作。在这一很自然的选项中,写缺失与读缺失类似。
(2)非写分配——这显然是一种不太寻常的选项,写缺失不会影响缓存。仅修改低一级存储器中的块。
因此,在采用非写分配策略时,在程序尝试读取块之前,这些块一直在缓存之外,但在采用写分配策略时,即使那些仅被写人的块也会保存在缓存中。