enumerate()函数是Python内置函数,用于在遍历可迭代对象(如列表、字符串、元组等)时,同时获取索引和对应的元素值。
它的主要作用是在循环过程中方便地获取索引和元素。
下面以两个例子来进行介绍理解。
目录
一、例子1
二、例子2
一、例子1
代码:
list1 = ['语文', '数学', '英语']
# turple = ('语文', '数学', '英语')
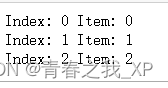
for index, item in enumerate(list1):
print("Index:", index, "Item:", item)结果:

在这个例子中,enumerate()函数返回一个包含索引和对应值的元组。
这样,我们可以在一个循环中同时获取列表的索引和元素,而不需要单独计算索引。
二、例子2
准备数据
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
# 这里,`load_iris()`函数从sklearn库中加载鸢尾花数据集
X = iris.data
Y = iris.target
# 并将数据和目标变量分别存储在X和Y中。
# X表示花瓣长度、花瓣宽度、花萼长度和花萼宽度等特征,Y表示三个品种(setosa,versicolor,virginica)的标签。
# 将X和Y转换为DataFrame
data = pd.DataFrame(X, columns=iris.feature_names)
data['target'] = Y结果:
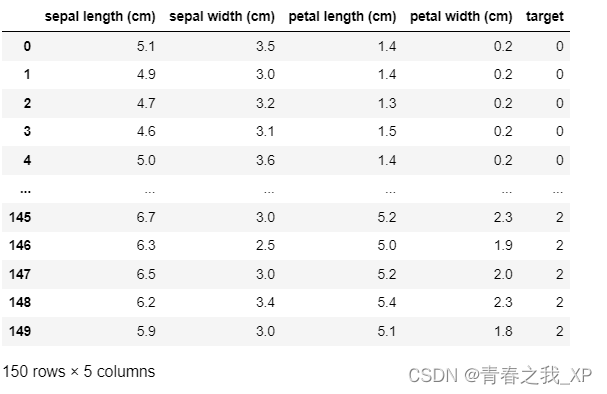
其中有150列,即150各样本,target列有150个值,前50个值为0,中间50个值为1,后50个值为2
体会下面两段代码:
①
for index, item in enumerate(data["target"]):
print("Index:", index, "Item:", item)结果如下:
最终结果返回的是每个样本对应的索引值和元素值
②
for index, item in enumerate(data["target"].unique()):
print("Index:", index, "Item:", item)在这段代码中,`enumerate(data["target"].unique())` 返回的结果,其中包含了索引和对应的唯一值。
请看,索引返回的是0、1、2,并不是其在鸢尾花原数据集的索引
因为,这里的索引是相对于 `data["target"].unique()` 的,而不是原始数据集的索引。
所以,`index` 不会反映原始的索引标签。