plf::list是一个比std::list性能要好的另外一种实现,根据作者的性能测试:
293% faster insertion
57% faster erasure
17% faster iteration
77% faster sorting
70% faster reversal
91% faster remove/remove_if
63% faster unique
811% faster clear (1147900% for trivially-destructible types)
1248% faster destruction (6350% for trivially-destructible types)
20-24% faster performance overall in ordered use-case benchmarking(insertion, erasure and iteration on the fly and over time)
plf::list几乎可以完全替代std::list, 只有两个小的例外, std::list中的splice有三个接口:
- splice另一个list的全部node,
- splice自己或者其它list的一个node,
- splice自己或者其它list的部分nodes
对于std::list中的第一个接口, plf完全支持; std::list的第二三个接口如下 :
void splice( const_iterator pos, list& other, const_iterator it );splice一个元素, other可以是自己也可以是其他listvoid splice( const_iterator pos, list& other, const_iterator first, const_iterator last);splice多个元素,other可以是自己也可以是其他list
对于上面两个接口,plf::list接口中的other只能是自己(this), 因而plf::list省去了other参数, 只提供了下面两个接口,
void splice(const_iterator position, const_iterator location);void splice( const_iterator pos, const_iterator first, const_iterator last);
这一限制是由plf::list本身的底层实现决定的, plf::list将多个node合并到, 后面会从实现层面作出详细分析。
plf::list的背景
在早期(1980s),CPU的速度和内存的速度几乎相等,当在数据量一定的情况下,算法的复杂度是O(1), 对比O(N)确实很有优势。
随着硬件的发展,CPU的速度越来越快,早期的“一定数据量”,即使用O(N)的时间复杂度去处理,花费的时间也很少,某种程度上接近于O(1)。在这种情况下,CPU从缓存获取数据的能力(fetch data)越来越成为瓶颈,数据的局部性(data locality)越来越重要了。
std::list的insert/erase方法都是O(1)的,但是std::list中的每个元素都是一个单独的node,这就决定std::list的数据局部性不是那么好。
为了获取好的data locality,多数情况下用std::vector都是不错的选择。但是list有其固有的优点,比如插入,删除元素后其它元素的位置不变等,如何创建一个list, 使其具有良好的data locality,同时也支持O(1)的insert/erase?plf::list就是在这样的想法下诞生的。
plf::list的原理
plf::list的核心思想就是提高数据的局部性,实现方法是类vector的内存预分配。也可以说plf::list是一个自带memory pool的list.
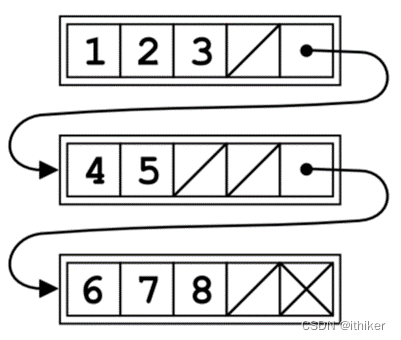
plf::list源码分析
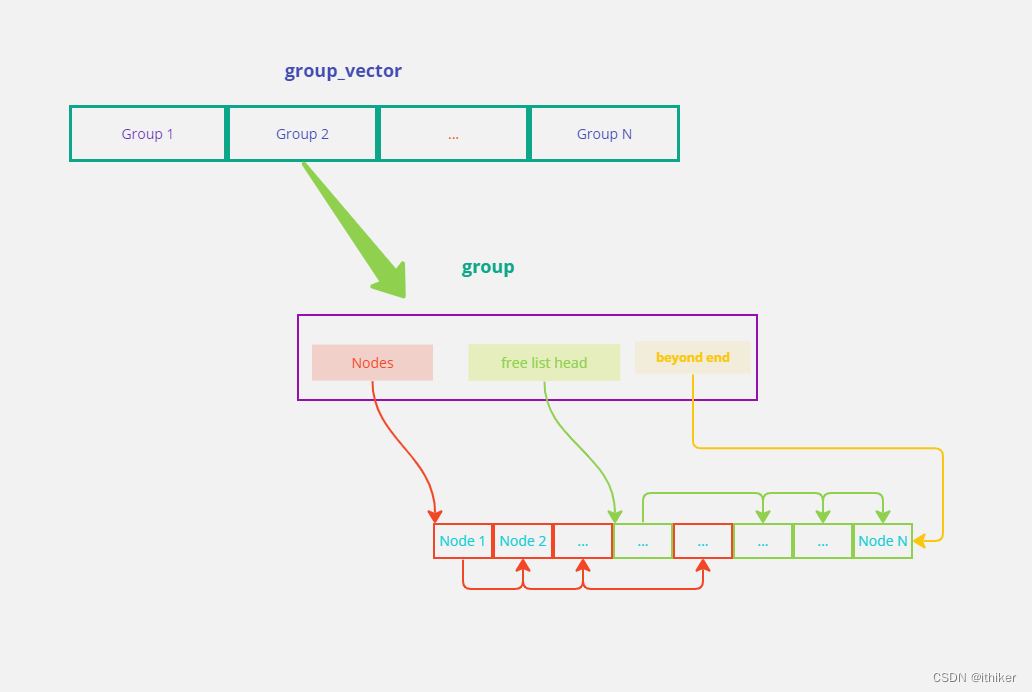
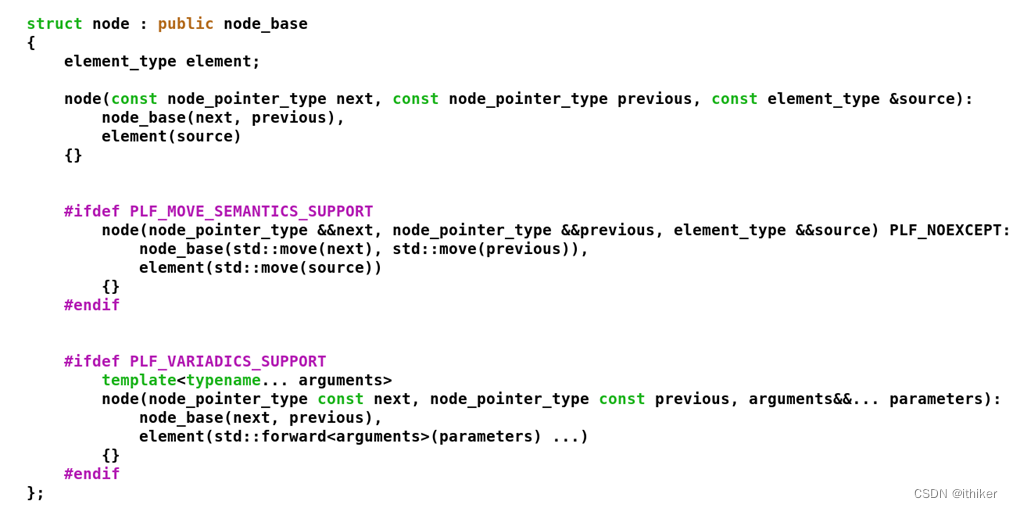
结合上面的示意图, plf::list源码钟最基本的数据单位是node:

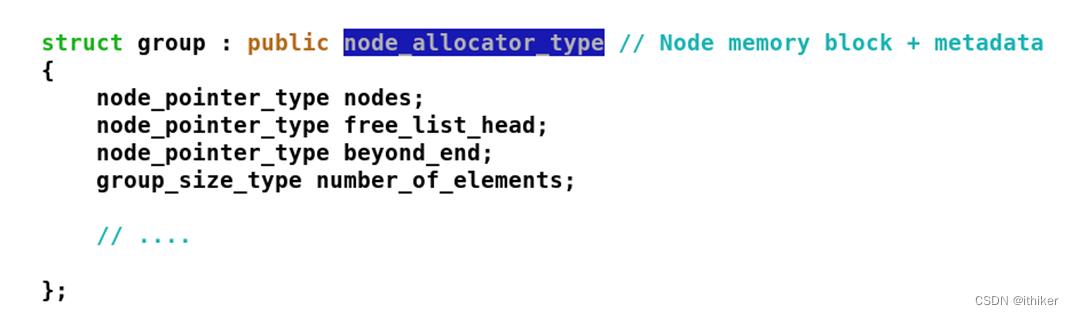
对node进行管理的最基本单位是group:
一系列的group就是一个group_vector:

整个plf::list的内部数据结构就是:

plf::list用示意图就可以如下表示: