Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
文章目录
- Flink 系列文章
- 一、Flink的23种算子说明及示例
- 1、maven依赖
- 2、java bean
- 3、map
- 4、flatmap
- 5、Filter
- 6、KeyBy
- 7、Reduce
- 8、Aggregations
- 9、first、distinct、join、outjoin、cross
- 10、Window
- 11、WindowAll
- 12、Window Apply
- 13、Window Reduce
- 14、Aggregations on windows
- 15、Union
- 16、Window Join
- 17、Interval Join
- 18、Window CoGroup
- 19、Connect
- 20、CoMap, CoFlatMap
- 21、Iterate
- 22、Cache
- 23、Split
- 24、Select
- 25、Project
本文主要介绍Flink 的23种常用的operator及以具体可运行示例进行说明,如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。
本专题分为五篇,即:
【flink番外篇】1、flink的23种常用算子介绍及详细示例(1)- map、flatmap和filter
【flink番外篇】1、flink的23种常用算子介绍及详细示例(2)- keyby、reduce和Aggregations
【flink番外篇】1、flink的23种常用算子介绍及详细示例(3)-window、distinct、join等
【flink番外篇】1、flink的23种常用算子介绍及详细示例(4)- union、window join、connect、outputtag、cache、iterator、project
【flink番外篇】1、flink的23种常用算子介绍及详细示例(完整版)
一、Flink的23种算子说明及示例
1、maven依赖
下文中所有示例都是用该maven依赖,除非有特殊说明的情况。
<properties>
<encoding>UTF-8</encoding>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<java.version>1.8</java.version>
<scala.version>2.12</scala.version>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 日志 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.4</version>
</dependency>
</dependencies>
2、java bean
下文所依赖的User如下
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private int id;
private String name;
private String pwd;
private String email;
private int age;
private double balance;
}
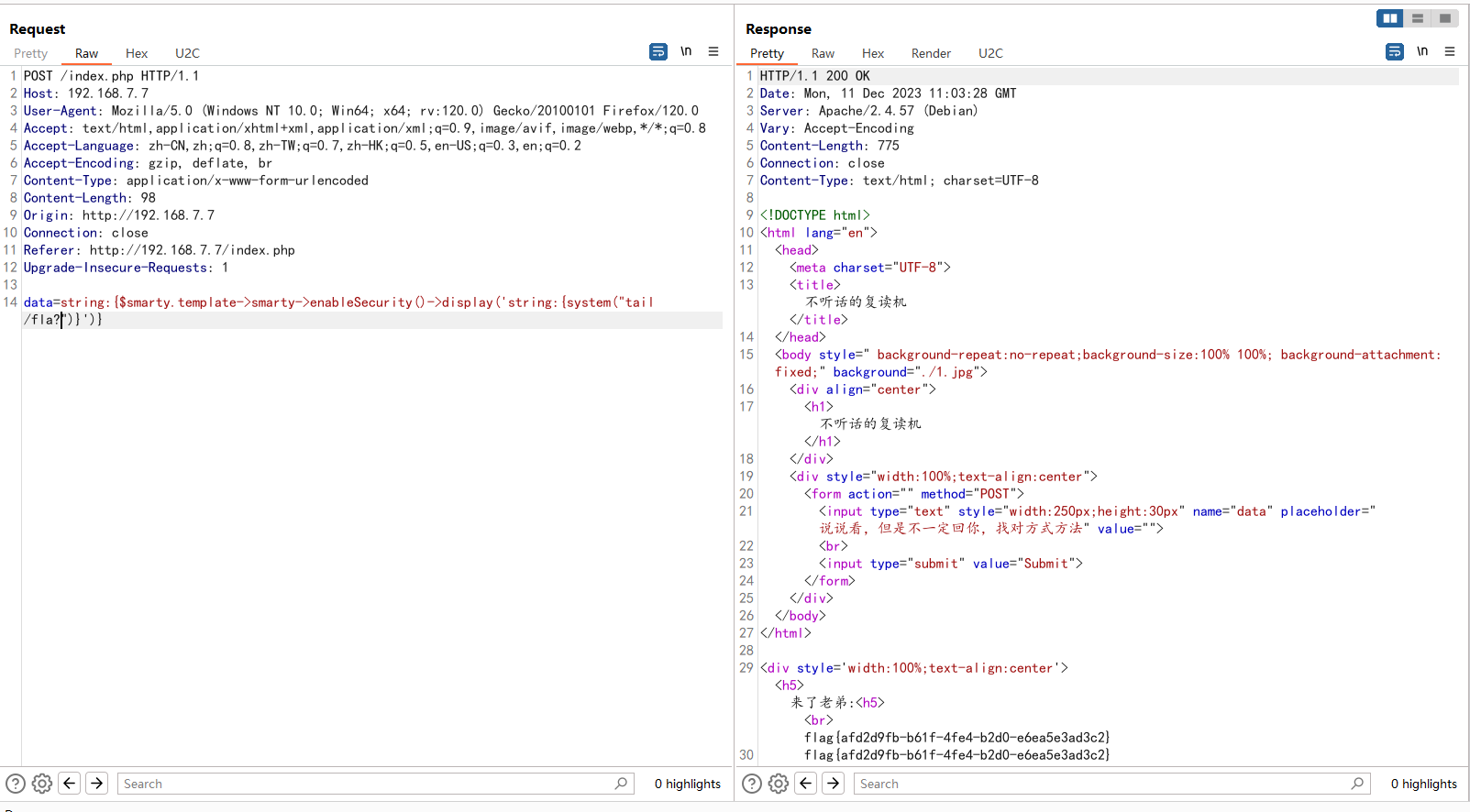
3、map
[DataStream->DataStream]
这是最简单的转换之一,其中输入是一个数据流,输出的也是一个数据流。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.datastreamapi.User;
/**
* @author alanchan
*
*/
public class TestMapDemo {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// source
// transformation
mapFunction5(env);
// sink
// execute
env.execute();
}
// 构造一个list,然后将list中数字乘以2输出,内部匿名类实现
public static void mapFunction1(StreamExecutionEnvironment env) throws Exception {
List<Integer> data = new ArrayList<Integer>();
for (int i = 1; i <= 10; i++) {
data.add(i);
}
DataStreamSource<Integer> source = env.fromCollection(data);
SingleOutputStreamOperator<Integer> sink = source.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer inValue) throws Exception {
return inValue * 2;
}
});
sink.print();
// 9> 12
// 4> 2
// 10> 14
// 8> 10
// 13> 20
// 7> 8
// 12> 18
// 11> 16
// 5> 4
// 6> 6
}
// 构造一个list,然后将list中数字乘以2输出,lambda实现
public static void mapFunction2(StreamExecutionEnvironment env) throws Exception {
List<Integer> data = new ArrayList<Integer>();
for (int i = 1; i <= 10; i++) {
data.add(i);
}
DataStreamSource<Integer> source = env.fromCollection(data);
SingleOutputStreamOperator<Integer> sink = source.map(i -> 2 * i);
sink.print();
// 3> 4
// 4> 6
// 9> 16
// 7> 12
// 10> 18
// 2> 2
// 6> 10
// 5> 8
// 8> 14
// 11> 20
}
// 构造User数据源
public static DataStreamSource<User> source(StreamExecutionEnvironment env) {
DataStreamSource<User> source = env.fromCollection(Arrays.asList(
new User(1, "alan1", "1", "1@1.com", 12, 1000),
new User(2, "alan2", "2", "2@2.com", 19, 200),
new User(3, "alan1", "3", "3@3.com", 28, 1500),
new User(5, "alan1", "5", "5@5.com", 15, 500),
new User(4, "alan2", "4", "4@4.com", 30, 400)
)
);
return source;
}
// lambda实现用户对象的balance×2和age+5功能
public static SingleOutputStreamOperator<User> mapFunction3(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
SingleOutputStreamOperator<User> sink = source.map((MapFunction<User, User>) user -> {
User user2 = user;
user2.setAge(user.getAge() + 5);
user2.setBalance(user.getBalance() * 2);
return user2;
});
sink.print();
// 10> User(id=1, name=alan1, pwd=1, email=1@1.com, age=17, balance=2000.0)
// 14> User(id=4, name=alan2, pwd=4, email=4@4.com, age=35, balance=800.0)
// 11> User(id=2, name=alan2, pwd=2, email=2@2.com, age=24, balance=400.0)
// 12> User(id=3, name=alan1, pwd=3, email=3@3.com, age=33, balance=3000.0)
// 13> User(id=5, name=alan1, pwd=5, email=5@5.com, age=20, balance=1000.0)
return sink;
}
// lambda实现balance*2和age+5后,balance》=2000和age》=20的数据过滤出来
public static SingleOutputStreamOperator<User> mapFunction4(StreamExecutionEnvironment env) throws Exception {
SingleOutputStreamOperator<User> sink = mapFunction3(env).filter(user -> user.getBalance() >= 2000 && user.getAge() >= 20);
sink.print();
// 15> User(id=1, name=alan1, pwd=1, email=1@1.com, age=17, balance=2000.0)
// 1> User(id=3, name=alan1, pwd=3, email=3@3.com, age=33, balance=3000.0)
// 16> User(id=2, name=alan2, pwd=2, email=2@2.com, age=24, balance=400.0)
// 3> User(id=4, name=alan2, pwd=4, email=4@4.com, age=35, balance=800.0)
// 2> User(id=5, name=alan1, pwd=5, email=5@5.com, age=20, balance=1000.0)
// 1> User(id=3, name=alan1, pwd=3, email=3@3.com, age=33, balance=3000.0)
return sink;
}
// lambda实现balance*2和age+5后,balance》=2000和age》=20的数据过滤出来并通过flatmap收集
public static SingleOutputStreamOperator<User> mapFunction5(StreamExecutionEnvironment env) throws Exception {
SingleOutputStreamOperator<User> sink = mapFunction4(env).flatMap((FlatMapFunction<User, User>) (user, out) -> {
if (user.getBalance() >= 3000) {
out.collect(user);
}
}).returns(User.class);
sink.print();
// 8> User(id=5, name=alan1, pwd=5, email=5@5.com, age=20, balance=1000.0)
// 7> User(id=3, name=alan1, pwd=3, email=3@3.com, age=33, balance=3000.0)
// 6> User(id=2, name=alan2, pwd=2, email=2@2.com, age=24, balance=400.0)
// 9> User(id=4, name=alan2, pwd=4, email=4@4.com, age=35, balance=800.0)
// 5> User(id=1, name=alan1, pwd=1, email=1@1.com, age=17, balance=2000.0)
// 7> User(id=3, name=alan1, pwd=3, email=3@3.com, age=33, balance=3000.0)
// 7> User(id=3, name=alan1, pwd=3, email=3@3.com, age=33, balance=3000.0)
return sink;
}
}
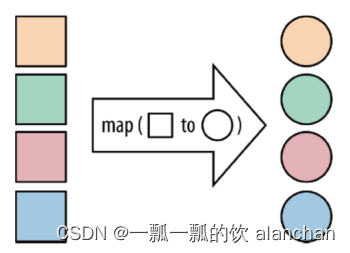
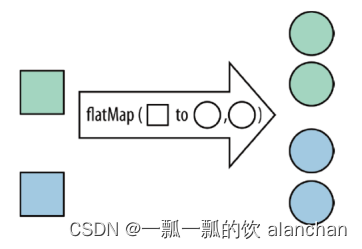
4、flatmap
[DataStream->DataStream]
FlatMap 采用一条记录并输出零个,一个或多个记录。将集合中的每个元素变成一个或多个元素,并返回扁平化之后的结果。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*
*/
public class TestFlatMapDemo {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
flatMapFunction3(env);
env.execute();
}
// 构造User数据源
public static DataStreamSource<String> source(StreamExecutionEnvironment env) {
List<String> info = new ArrayList<>();
info.add("i am alanchan");
info.add("i like hadoop");
info.add("i like flink");
info.add("and you ?");
DataStreamSource<String> dataSource = env.fromCollection(info);
return dataSource;
}
// 将句子以空格进行分割-内部匿名类实现
public static void flatMapFunction1(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<String> source = source(env);
SingleOutputStreamOperator<String> sink = source.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] splits = value.split(" ");
for (String split : splits) {
out.collect(split);
}
}
});
sink.print();
// 11> and
// 10> i
// 8> i
// 9> i
// 8> am
// 10> like
// 11> you
// 10> flink
// 8> alanchan
// 9> like
// 11> ?
// 9> hadoop
}
// lambda实现
public static void flatMapFunction2(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<String> source = source(env);
SingleOutputStreamOperator<String> sink = source.flatMap((FlatMapFunction<String, String>) (input, out) -> {
String[] splits = input.split(" ");
for (String split : splits) {
out.collect(split);
}
}).returns(String.class);
sink.print();
// 6> i
// 8> and
// 8> you
// 8> ?
// 5> i
// 7> i
// 5> am
// 5> alanchan
// 6> like
// 7> like
// 6> hadoop
// 7> flink
}
// lambda实现
public static void flatMapFunction3(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<String> source = source(env);
SingleOutputStreamOperator<String> sink = source.flatMap((String input, Collector<String> out) -> Arrays.stream(input.split(" ")).forEach(out::collect))
.returns(String.class);
sink.print();
// 8> i
// 11> and
// 10> i
// 9> i
// 10> like
// 11> you
// 8> am
// 11> ?
// 10> flink
// 9> like
// 9> hadoop
// 8> alanchan
}
}
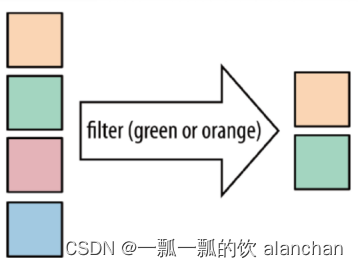
5、Filter
DataStream → DataStream
Filter 函数根据条件判断出结果。按照指定的条件对集合中的元素进行过滤,过滤出返回true/符合条件的元素。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.datastreamapi.User;
/**
* @author alanchan
*
*/
public class TestFilterDemo {
// 构造User数据源
public static DataStreamSource<User> sourceUser(StreamExecutionEnvironment env) {
DataStreamSource<User> source = env.fromCollection(Arrays.asList(
new User(1, "alan1", "1", "1@1.com", 12, 1000),
new User(2, "alan2", "2", "2@2.com", 19, 200),
new User(3, "alan1", "3", "3@3.com", 28, 1500),
new User(5, "alan1", "5", "5@5.com", 15, 500),
new User(4, "alan2", "4", "4@4.com", 30, 400)));
return source;
}
// 构造User数据源
public static DataStreamSource<Integer> sourceList(StreamExecutionEnvironment env) {
List<Integer> data = new ArrayList<Integer>();
for (int i = 1; i <= 10; i++) {
data.add(i);
}
DataStreamSource<Integer> source = env.fromCollection(data);
return source;
}
// 过滤出大于5的数字,内部匿名类
public static void filterFunction1(StreamExecutionEnvironment env) throws Exception {
DataStream<Integer> source = sourceList(env);
SingleOutputStreamOperator<Integer> sink = source.map(new MapFunction<Integer, Integer>() {
public Integer map(Integer value) throws Exception {
return value + 1;
}
}).filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer value) throws Exception {
return value > 5;
}
});
sink.print();
// 1> 10
// 14> 7
// 16> 9
// 13> 6
// 2> 11
// 15> 8
}
// lambda实现
public static void filterFunction2(StreamExecutionEnvironment env) throws Exception {
DataStream<Integer> source = sourceList(env);
SingleOutputStreamOperator<Integer> sink = source.map(i -> i + 1).filter(value -> value > 5);
sink.print();
// 12> 7
// 15> 10
// 11> 6
// 13> 8
// 14> 9
// 16> 11
}
// 查询user id大于3的记录
public static void filterFunction3(StreamExecutionEnvironment env) throws Exception {
DataStream<User> source = sourceUser(env);
SingleOutputStreamOperator<User> sink = source.filter(user -> user.getId() > 3);
sink.print();
// 14> User(id=5, name=alan1, pwd=5, email=5@5.com, age=15, balance=500.0)
// 15> User(id=4, name=alan2, pwd=4, email=4@4.com, age=30, balance=400.0)
}
/**
* @param args
*/
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
filterFunction3(env);
env.execute();
}
}
6、KeyBy
DataStream → KeyedStream
按照指定的key来对流中的数据进行分组
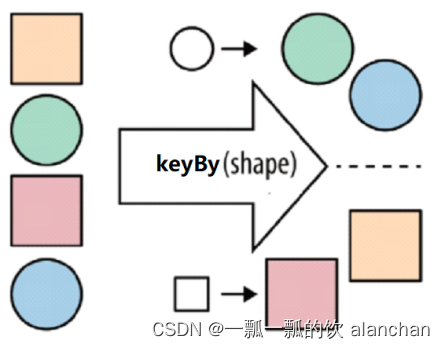
KeyBy 在逻辑上是基于 key 对流进行分区。在内部,它使用 hash 函数对流进行分区。它返回 KeyedDataStream 数据流。将同一Key的数据放到同一个分区。
分区结果和KeyBy下游算子的并行度强相关。如下游算子只有一个并行度,不管怎么分,都会分到一起。
对于POJO类型,KeyBy可以通过keyBy(fieldName)指定字段进行分区。
对于Tuple类型,KeyBy可以通过keyBy(fieldPosition)指定字段进行分区。
对于一般类型,如上,KeyBy可以通过keyBy(new KeySelector {…})指定字段进行分区。
import java.util.Arrays;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.datastreamapi.User;
/**
* @author alanchan
*
*/
public class TestKeyByDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.setParallelism(4);// 设置数据分区数量
keyByFunction6(env);
env.execute();
}
// 构造User数据源
public static DataStreamSource<User> source(StreamExecutionEnvironment env) {
DataStreamSource<User> source = env.fromCollection(Arrays.asList(
new User(1, "alan1", "1", "1@1.com", 12, 1000),
new User(2, "alan2", "2", "2@2.com", 19, 200),
new User(3, "alan1", "3", "3@3.com", 28, 1500),
new User(5, "alan1", "5", "5@5.com", 15, 500),
new User(4, "alan2", "4", "4@4.com", 30, 400)));
return source;
}
// 按照name进行keyby 对于POJO类型,KeyBy可以通过keyBy(fieldName)指定字段进行分区
public static void keyByFunction1(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
KeyedStream<User, String> sink = source.keyBy(new KeySelector<User, String>() {
@Override
public String getKey(User value) throws Exception {
return value.getName();
}
});
sink.map(user -> {
System.out.println("当前线程ID:" + Thread.currentThread().getId() + ",user:" + user.toString());
return user;
});
sink.print();
}
// lambda 对于POJO类型,KeyBy可以通过keyBy(fieldName)指定字段进行分区
public static void keyByFunction2(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
KeyedStream<User, String> sink = source.keyBy(user -> user.getName());
// 演示keyby后的数据输出
sink.map(user -> {
System.out.println("当前线程ID:" + Thread.currentThread().getId() + ",user:" + user.toString());
return user;
});
sink.print();
}
// 对于Tuple类型,KeyBy可以通过keyBy(fieldPosition)指定字段进行分区。lambda
public static void keyByFunction3(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
SingleOutputStreamOperator<Tuple2<String, User>> userTemp = source.map((MapFunction<User, Tuple2<String, User>>) user -> {
return new Tuple2<String, User>(user.getName(), user);
}).returns(Types.TUPLE(Types.STRING, Types.POJO(User.class)));
KeyedStream<Tuple2<String, User>, Tuple> sink = userTemp.keyBy(0);
// 演示keyby后的数据输出
sink.map(user -> {
System.out.println("当前线程ID:" + Thread.currentThread().getId() + ",user:" + user.f1.toString());
return user.f1;
});
sink.print();
}
// 对于Tuple类型,KeyBy可以通过keyBy(fieldPosition)指定字段进行分区。
public static void keyByFunction4(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
SingleOutputStreamOperator<Tuple2<String, User>> userTemp = source.map(new MapFunction<User, Tuple2<String, User>>() {
@Override
public Tuple2<String, User> map(User value) throws Exception {
return new Tuple2<String, User>(value.getName(), value);
}
});
KeyedStream<Tuple2<String, User>, String> sink = userTemp.keyBy(new KeySelector<Tuple2<String, User>, String>() {
@Override
public String getKey(Tuple2<String, User> value) throws Exception {
return value.f0;
}
});
// 演示keyby后的数据输出
sink.map(user -> {
System.out.println("当前线程ID:" + Thread.currentThread().getId() + ",user:" + user.f1.toString());
return user.f1;
});
// sink.map(new MapFunction<Tuple2<String, User>, String>() {
//
// @Override
// public String map(Tuple2<String, User> value) throws Exception {
// System.out.println("当前线程ID:" + Thread.currentThread().getId() + ",user:" + value.f1.toString());
// return null;
// }});
sink.print();
}
// 对于一般类型,如上,KeyBy可以通过keyBy(new KeySelector {...})指定字段进行分区。
// 按照name的前4位进行keyby
public static void keyByFunction5(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
KeyedStream<User, String> sink = source.keyBy(new KeySelector<User, String>() {
@Override
public String getKey(User value) throws Exception {
// String temp = value.getName().substring(0, 4);
return value.getName().substring(0, 4);
}
});
sink.map(user -> {
System.out.println("当前线程ID:" + Thread.currentThread().getId() + ",user:" + user.toString());
return user;
});
sink.print();
}
// 对于一般类型,如上,KeyBy可以通过keyBy(new KeySelector {...})指定字段进行分区。 lambda
// 按照name的前4位进行keyby
public static void keyByFunction6(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
KeyedStream<User, String> sink = source.keyBy(user -> user.getName().substring(0, 4));
sink.map(user -> {
System.out.println("当前线程ID:" + Thread.currentThread().getId() + ",user:" + user.toString());
return user;
});
sink.print();
}
}
7、Reduce
KeyedStream → DataStream
对集合中的元素进行聚合。Reduce 返回单个的结果值,并且 reduce 操作每处理一个元素总是创建一个新值。常用的方法有 average, sum, min, max, count,使用 reduce 方法都可实现。基于ReduceFunction进行滚动聚合,并向下游算子输出每次滚动聚合后的结果。
注意: Reduce会输出每一次滚动聚合的结果。
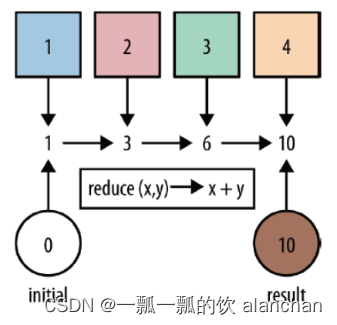
import java.util.Arrays;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.datastreamapi.User;
/**
* @author alanchan
*
*/
public class TestReduceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.setParallelism(4);// 设置数据分区数量
reduceFunction2(env);
env.execute();
}
// 构造User数据源
public static DataStreamSource<User> source(StreamExecutionEnvironment env) {
DataStreamSource<User> source = env.fromCollection(Arrays.asList(
new User(1, "alan1", "1", "1@1.com", 12, 1000),
new User(2, "alan2", "2", "2@2.com", 19, 200),
new User(3, "alan1", "3", "3@3.com", 28, 1500),
new User(5, "alan1", "5", "5@5.com", 15, 500),
new User(4, "alan2", "4", "4@4.com", 30, 400)));
return source;
}
// 按照name进行balance进行sum
public static void reduceFunction1(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
KeyedStream<User, String> keyedStream = source.keyBy(user -> user.getName());
SingleOutputStreamOperator<User> sink = keyedStream.reduce(new ReduceFunction<User>() {
@Override
public User reduce(User value1, User value2) throws Exception {
double balance = value1.getBalance() + value2.getBalance();
return new User(value1.getId(), value1.getName(), "", "", 0, balance);
}
});
//
sink.print();
}
// 按照name进行balance进行sum lambda
public static void reduceFunction2(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
KeyedStream<User, String> userKeyBy = source.keyBy(user -> user.getName());
SingleOutputStreamOperator<User> sink = userKeyBy.reduce((user1, user2) -> {
User user = user1;
user.setBalance(user1.getBalance() + user2.getBalance());
return user;
});
sink.print();
}
}
8、Aggregations
KeyedStream → DataStream
DataStream API 支持各种聚合,例如 min,max,sum 等。 这些函数可以应用于 KeyedStream 以获得 Aggregations 聚合。
Aggregate 对KeyedStream按指定字段滚动聚合并输出每一次滚动聚合后的结果。默认的聚合函数有:sum、min、minBy、max、maxBy。
注意:
max(field)与maxBy(field)的区别: maxBy返回field最大的那条数据;而max则是将最大的field的值赋值给第一条数据并返回第一条数据。同理,min与minBy。
Aggregate聚合算子会滚动输出每一次聚合后的结果
max 和 maxBy 之间的区别在于 max 返回流中的最大值,但 maxBy 返回具有最大值的键, min 和 minBy 同理。
max以第一个比较对象的比较列值进行替换,maxBy是以整个比较对象进行替换。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.datastreamapi.User;
/**
* @author alanchan
*
*/
public class TestAggregationsDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
aggregationsFunction2(env);
env.execute();
}
// 构造User数据源
public static DataStreamSource<User> source(StreamExecutionEnvironment env) {
DataStreamSource<User> source = env.fromCollection(Arrays.asList(
new User(1, "alan1", "1", "1@1.com", 12, 1000),
new User(2, "alan2", "2", "2@2.com", 19, 200),
new User(3, "alan1", "3", "3@3.com", 28, 1500),
new User(5, "alan1", "5", "5@5.com", 15, 500),
new User(4, "alan2", "4", "4@4.com", 30, 400)));
return source;
}
//分组统计sum、max、min、maxby、minby
public static void aggregationsFunction(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
KeyedStream<User, String> userTemp= source.keyBy(user->user.getName());
DataStream sink = null;
//1、根据name进行分区统计balance之和 alan1----2500/alan2----600
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1000.0)
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=2500.0)
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=600.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=3000.0)
sink = userTemp.sum("balance");
//2、根据name进行分区统计balance的max alan1----1500/alan2----400
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1000.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1500.0)
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=400.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1500.0)
sink = userTemp.max("balance");//1@1.com-3000 -- 2@2.com-300
//3、根据name进行分区统计balance的min alan1----500/alan2---200
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1000.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1000.0)
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=500.0)
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
sink = userTemp.min("balance");
//4、根据name进行分区统计balance的maxBy alan2----400/alan1----1500
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// 1> User(id=4, name=alan2, pwd=4, email=4@4.com, age=30, balance=400.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1000.0)
// 16> User(id=3, name=alan1, pwd=3, email=3@3.com, age=28, balance=1500.0)
// 16> User(id=3, name=alan1, pwd=3, email=3@3.com, age=28, balance=1500.0)
sink = userTemp.maxBy("balance");
//5、根据name进行分区统计balance的minBy alan2----200/alan1----500
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1000.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1000.0)
// 16> User(id=5, name=alan1, pwd=5, email=5@5.com, age=15, balance=500.0)
sink = userTemp.minBy("balance");
sink.print();
}
public static void aggregationsFunction2(StreamExecutionEnvironment env) throws Exception {
List list = new ArrayList<Tuple3<Integer, Integer, Integer>>();
list.add(new Tuple3<>(0,3,6));
list.add(new Tuple3<>(0,2,5));
list.add(new Tuple3<>(0,1,6));
list.add(new Tuple3<>(0,4,3));
list.add(new Tuple3<>(1,1,9));
list.add(new Tuple3<>(1,2,8));
list.add(new Tuple3<>(1,3,10));
list.add(new Tuple3<>(1,2,9));
list.add(new Tuple3<>(1,5,7));
DataStreamSource<Tuple3<Integer, Integer, Integer>> source = env.fromCollection(list);
KeyedStream<Tuple3<Integer, Integer, Integer>, Integer> tTemp= source.keyBy(t->t.f0);
DataStream<Tuple3<Integer, Integer, Integer>> sink =null;
//按照分区,以第一个Tuple3的元素为基础进行第三列值比较,如果第三列值小于第一个tuple3的第三列值,则进行第三列值替换,其他的不变
// 12> (0,3,6)
// 11> (1,1,9)
// 11> (1,1,8)
// 12> (0,3,5)
// 11> (1,1,8)
// 12> (0,3,5)
// 11> (1,1,8)
// 12> (0,3,3)
// 11> (1,1,7)
sink = tTemp.min(2);
// 按照数据分区,以第一个tuple3的元素为基础进行第三列值比较,如果第三列值小于第一个tuple3的第三列值,则进行整个tuple3的替换
// 12> (0,3,6)
// 11> (1,1,9)
// 12> (0,2,5)
// 11> (1,2,8)
// 12> (0,2,5)
// 11> (1,2,8)
// 12> (0,4,3)
// 11> (1,2,8)
// 11> (1,5,7)
sink = tTemp.minBy(2);
sink.print();
}
}
9、first、distinct、join、outjoin、cross
具体事例详见例子及结果。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.common.operators.Order;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.datastreamapi.User;
/**
* @author alanchan
*
*/
public class TestFirst_Join_Distinct_OutJoin_CrossDemo {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
joinFunction(env);
env.execute();
}
public static void unionFunction(StreamExecutionEnvironment env) throws Exception {
List<String> info1 = new ArrayList<>();
info1.add("team A");
info1.add("team B");
List<String> info2 = new ArrayList<>();
info2.add("team C");
info2.add("team D");
List<String> info3 = new ArrayList<>();
info3.add("team E");
info3.add("team F");
List<String> info4 = new ArrayList<>();
info4.add("team G");
info4.add("team H");
DataStream<String> source1 = env.fromCollection(info1);
DataStream<String> source2 = env.fromCollection(info2);
DataStream<String> source3 = env.fromCollection(info3);
DataStream<String> source4 = env.fromCollection(info4);
source1.union(source2).union(source3).union(source4).print();
// team A
// team C
// team E
// team G
// team B
// team D
// team F
// team H
}
public static void crossFunction(ExecutionEnvironment env) throws Exception {
// cross,求两个集合的笛卡尔积,得到的结果数为:集合1的条数 乘以 集合2的条数
List<String> info1 = new ArrayList<>();
info1.add("team A");
info1.add("team B");
List<Tuple2<String, Integer>> info2 = new ArrayList<>();
info2.add(new Tuple2("W", 3));
info2.add(new Tuple2("D", 1));
info2.add(new Tuple2("L", 0));
DataSource<String> data1 = env.fromCollection(info1);
DataSource<Tuple2<String, Integer>> data2 = env.fromCollection(info2);
data1.cross(data2).print();
// (team A,(W,3))
// (team A,(D,1))
// (team A,(L,0))
// (team B,(W,3))
// (team B,(D,1))
// (team B,(L,0))
}
public static void outerJoinFunction(ExecutionEnvironment env) throws Exception {
// Outjoin,跟sql语句中的left join,right join,full join意思一样
// leftOuterJoin,跟join一样,但是左边集合的没有关联上的结果也会取出来,没关联上的右边为null
// rightOuterJoin,跟join一样,但是右边集合的没有关联上的结果也会取出来,没关联上的左边为null
// fullOuterJoin,跟join一样,但是两个集合没有关联上的结果也会取出来,没关联上的一边为null
List<Tuple2<Integer, String>> info1 = new ArrayList<>();
info1.add(new Tuple2<>(1, "shenzhen"));
info1.add(new Tuple2<>(2, "guangzhou"));
info1.add(new Tuple2<>(3, "shanghai"));
info1.add(new Tuple2<>(4, "chengdu"));
List<Tuple2<Integer, String>> info2 = new ArrayList<>();
info2.add(new Tuple2<>(1, "深圳"));
info2.add(new Tuple2<>(2, "广州"));
info2.add(new Tuple2<>(3, "上海"));
info2.add(new Tuple2<>(5, "杭州"));
DataSource<Tuple2<Integer, String>> data1 = env.fromCollection(info1);
DataSource<Tuple2<Integer, String>> data2 = env.fromCollection(info2);
// left join
// eft join:7> (1,shenzhen,深圳)
// left join:2> (3,shanghai,上海)
// left join:8> (4,chengdu,未知)
// left join:16> (2,guangzhou,广州)
data1.leftOuterJoin(data2).where(0).equalTo(0).with(new JoinFunction<Tuple2<Integer, String>, Tuple2<Integer, String>, Tuple3<Integer, String, String>>() {
@Override
public Tuple3<Integer, String, String> join(Tuple2<Integer, String> first, Tuple2<Integer, String> second) throws Exception {
Tuple3<Integer, String, String> tuple = new Tuple3();
if (second == null) {
tuple.setField(first.f0, 0);
tuple.setField(first.f1, 1);
tuple.setField("未知", 2);
} else {
// 另外一种赋值方式,和直接用构造函数赋值相同
tuple.setField(first.f0, 0);
tuple.setField(first.f1, 1);
tuple.setField(second.f1, 2);
}
return tuple;
}
}).print("left join");
// right join
// right join:2> (3,shanghai,上海)
// right join:7> (1,shenzhen,深圳)
// right join:15> (5,--,杭州)
// right join:16> (2,guangzhou,广州)
data1.rightOuterJoin(data2).where(0).equalTo(0).with(new JoinFunction<Tuple2<Integer, String>, Tuple2<Integer, String>, Tuple3<Integer, String, String>>() {
@Override
public Tuple3<Integer, String, String> join(Tuple2<Integer, String> first, Tuple2<Integer, String> second) throws Exception {
Tuple3<Integer, String, String> tuple = new Tuple3();
if (first == null) {
tuple.setField(second.f0, 0);
tuple.setField("--", 1);
tuple.setField(second.f1, 2);
} else {
// 另外一种赋值方式,和直接用构造函数赋值相同
tuple.setField(first.f0, 0);
tuple.setField(first.f1, 1);
tuple.setField(second.f1, 2);
}
return tuple;
}
}).print("right join");
// fullOuterJoin
// fullOuterJoin:2> (3,shanghai,上海)
// fullOuterJoin:8> (4,chengdu,--)
// fullOuterJoin:15> (5,--,杭州)
// fullOuterJoin:16> (2,guangzhou,广州)
// fullOuterJoin:7> (1,shenzhen,深圳)
data1.fullOuterJoin(data2).where(0).equalTo(0).with(new JoinFunction<Tuple2<Integer, String>, Tuple2<Integer, String>, Tuple3<Integer, String, String>>() {
@Override
public Tuple3<Integer, String, String> join(Tuple2<Integer, String> first, Tuple2<Integer, String> second) throws Exception {
Tuple3<Integer, String, String> tuple = new Tuple3();
if (second == null) {
tuple.setField(first.f0, 0);
tuple.setField(first.f1, 1);
tuple.setField("--", 2);
} else if (first == null) {
tuple.setField(second.f0, 0);
tuple.setField("--", 1);
tuple.setField(second.f1, 2);
} else {
// 另外一种赋值方式,和直接用构造函数赋值相同
tuple.setField(first.f0, 0);
tuple.setField(first.f1, 1);
tuple.setField(second.f1, 2);
}
return tuple;
}
}).print("fullOuterJoin");
}
public static void joinFunction(ExecutionEnvironment env) throws Exception {
List<Tuple2<Integer, String>> info1 = new ArrayList<>();
info1.add(new Tuple2<>(1, "shenzhen"));
info1.add(new Tuple2<>(2, "guangzhou"));
info1.add(new Tuple2<>(3, "shanghai"));
info1.add(new Tuple2<>(4, "chengdu"));
List<Tuple2<Integer, String>> info2 = new ArrayList<>();
info2.add(new Tuple2<>(1, "深圳"));
info2.add(new Tuple2<>(2, "广州"));
info2.add(new Tuple2<>(3, "上海"));
info2.add(new Tuple2<>(5, "杭州"));
DataSource<Tuple2<Integer, String>> data1 = env.fromCollection(info1);
DataSource<Tuple2<Integer, String>> data2 = env.fromCollection(info2);
//
// join:2> ((3,shanghai),(3,上海))
// join:16> ((2,guangzhou),(2,广州))
// join:7> ((1,shenzhen),(1,深圳))
data1.join(data2).where(0).equalTo(0).print("join");
// join2:2> (3,上海,shanghai)
// join2:7> (1,深圳,shenzhen)
// join2:16> (2,广州,guangzhou)
DataSet<Tuple3<Integer, String, String>> data3 = data1.join(data2).where(0).equalTo(0)
.with(new JoinFunction<Tuple2<Integer, String>, Tuple2<Integer, String>, Tuple3<Integer, String, String>>() {
@Override
public Tuple3<Integer, String, String> join(Tuple2<Integer, String> first, Tuple2<Integer, String> second) throws Exception {
return new Tuple3<Integer, String, String>(first.f0, second.f1, first.f1);
}
});
data3.print("join2");
}
public static void firstFunction(ExecutionEnvironment env) throws Exception {
List<Tuple2<Integer, String>> info = new ArrayList<>();
info.add(new Tuple2(1, "Hadoop"));
info.add(new Tuple2(1, "Spark"));
info.add(new Tuple2(1, "Flink"));
info.add(new Tuple2(2, "Scala"));
info.add(new Tuple2(2, "Java"));
info.add(new Tuple2(2, "Python"));
info.add(new Tuple2(3, "Linux"));
info.add(new Tuple2(3, "Window"));
info.add(new Tuple2(3, "MacOS"));
DataSet<Tuple2<Integer, String>> dataSet = env.fromCollection(info);
// 前几个
// dataSet.first(4).print();
// (1,Hadoop)
// (1,Spark)
// (1,Flink)
// (2,Scala)
// 按照tuple2的第一个元素进行分组,查出每组的前2个
// dataSet.groupBy(0).first(2).print();
// (3,Linux)
// (3,Window)
// (1,Hadoop)
// (1,Spark)
// (2,Scala)
// (2,Java)
// 按照tpule2的第一个元素进行分组,并按照倒序排列,查出每组的前2个
dataSet.groupBy(0).sortGroup(1, Order.DESCENDING).first(2).print();
// (3,Window)
// (3,MacOS)
// (1,Spark)
// (1,Hadoop)
// (2,Scala)
// (2,Python)
}
public static void distinctFunction(ExecutionEnvironment env) throws Exception {
List list = new ArrayList<Tuple3<Integer, Integer, Integer>>();
list.add(new Tuple3<>(0, 3, 6));
list.add(new Tuple3<>(0, 2, 5));
list.add(new Tuple3<>(0, 3, 6));
list.add(new Tuple3<>(1, 1, 9));
list.add(new Tuple3<>(1, 2, 8));
list.add(new Tuple3<>(1, 2, 8));
list.add(new Tuple3<>(1, 3, 9));
DataSet<Tuple3<Integer, Integer, Integer>> source = env.fromCollection(list);
// 去除tuple3中元素完全一样的
source.distinct().print();
// (1,3,9)
// (0,3,6)
// (1,1,9)
// (1,2,8)
// (0,2,5)
// 去除tuple3中第一个元素一样的,只保留第一个
// source.distinct(0).print();
// (1,1,9)
// (0,3,6)
// 去除tuple3中第一个和第三个相同的元素,只保留第一个
// source.distinct(0,2).print();
// (0,3,6)
// (1,1,9)
// (1,2,8)
// (0,2,5)
}
public static void distinctFunction2(ExecutionEnvironment env) throws Exception {
DataSet<User> source = env.fromCollection(Arrays.asList(new User(1, "alan1", "1", "1@1.com", 18, 3000), new User(2, "alan2", "2", "2@2.com", 19, 200),
new User(3, "alan1", "3", "3@3.com", 18, 1000), new User(5, "alan1", "5", "5@5.com", 28, 1500), new User(4, "alan2", "4", "4@4.com", 20, 300)));
// source.distinct("name").print();
// User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// User(id=1, name=alan1, pwd=1, email=1@1.com, age=18, balance=3000.0)
source.distinct("name", "age").print();
// User(id=1, name=alan1, pwd=1, email=1@1.com, age=18, balance=3000.0)
// User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// User(id=5, name=alan1, pwd=5, email=5@5.com, age=28, balance=1500.0)
// User(id=4, name=alan2, pwd=4, email=4@4.com, age=20, balance=300.0)
}
public static void distinctFunction3(ExecutionEnvironment env) throws Exception {
DataSet<User> source = env.fromCollection(Arrays.asList(new User(1, "alan1", "1", "1@1.com", 18, -1000), new User(2, "alan2", "2", "2@2.com", 19, 200),
new User(3, "alan1", "3", "3@3.com", 18, -1000), new User(5, "alan1", "5", "5@5.com", 28, 1500), new User(4, "alan2", "4", "4@4.com", 20, -300)));
// 针对balance增加绝对值去重
source.distinct(new KeySelector<User, Double>() {
@Override
public Double getKey(User value) throws Exception {
return Math.abs(value.getBalance());
}
}).print();
// User(id=5, name=alan1, pwd=5, email=5@5.com, age=28, balance=1500.0)
// User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// User(id=1, name=alan1, pwd=1, email=1@1.com, age=18, balance=-1000.0)
// User(id=4, name=alan2, pwd=4, email=4@4.com, age=20, balance=-300.0)
}
public static void distinctFunction4(ExecutionEnvironment env) throws Exception {
List<String> info = new ArrayList<>();
info.add("Hadoop,Spark");
info.add("Spark,Flink");
info.add("Hadoop,Flink");
info.add("Hadoop,Flink");
DataSet<String> source = env.fromCollection(info);
source.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
System.err.print("come in ");
for (String token : value.split(",")) {
out.collect(token);
}
}
});
source.distinct().print();
}
}
10、Window
KeyedStream → WindowedStream
Window 函数允许按时间或其他条件对现有 KeyedStream 进行分组。 以下是以 10 秒的时间窗口聚合:
inputStream.keyBy(0).window(Time.seconds(10));
Flink 定义数据片段以便(可能)处理无限数据流。 这些切片称为窗口。 此切片有助于通过应用转换处理数据块。 要对流进行窗口化,需要分配一个可以进行分发的键和一个描述要对窗口化流执行哪些转换的函数。要将流切片到窗口,可以使用 Flink 自带的窗口分配器。 我们有选项,如 tumbling windows, sliding windows, global 和 session windows。
具体参考系列文章
6、Flink四大基石之Window详解与详细示例(一)
6、Flink四大基石之Window详解与详细示例(二)
7、Flink四大基石之Time和WaterMaker详解与详细示例(watermaker基本使用、kafka作为数据源的watermaker使用示例以及超出最大允许延迟数据的接收实现)
11、WindowAll
DataStream → AllWindowedStream
windowAll 函数允许对常规数据流进行分组。 通常,这是非并行数据转换,因为它在非分区数据流上运行。
与常规数据流功能类似,也有窗口数据流功能。 唯一的区别是它们处理窗口数据流。 所以窗口缩小就像 Reduce 函数一样,Window fold 就像 Fold 函数一样,并且还有聚合。
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5))); // Last 5 seconds of data
这适用于非并行转换的大多数场景。所有记录都将收集到 windowAll 算子对应的一个任务中。
具体参考系列文章
6、Flink四大基石之Window详解与详细示例(一)
6、Flink四大基石之Window详解与详细示例(二)
7、Flink四大基石之Time和WaterMaker详解与详细示例(watermaker基本使用、kafka作为数据源的watermaker使用示例以及超出最大允许延迟数据的接收实现)
12、Window Apply
WindowedStream → DataStream
AllWindowedStream → DataStream
将通用 function 应用于整个窗口。下面是一个手动对窗口内元素求和的 function。
如果你使用 windowAll 转换,则需要改用 AllWindowFunction。
windowedStream.apply(new WindowFunction<Tuple2<String,Integer>, Integer, Tuple, Window>() {
public void apply (Tuple tuple,
Window window,
Iterable<Tuple2<String, Integer>> values,
Collector<Integer> out) throws Exception {
int sum = 0;
for (value t: values) {
sum += t.f1;
}
out.collect (new Integer(sum));
}
});
// 在 non-keyed 窗口流上应用 AllWindowFunction
allWindowedStream.apply (new AllWindowFunction<Tuple2<String,Integer>, Integer, Window>() {
public void apply (Window window,
Iterable<Tuple2<String, Integer>> values,
Collector<Integer> out) throws Exception {
int sum = 0;
for (value t: values) {
sum += t.f1;
}
out.collect (new Integer(sum));
}
});
13、Window Reduce
WindowedStream → DataStream
对窗口应用 reduce function 并返回 reduce 后的值。
windowedStream.reduce (new ReduceFunction<Tuple2<String,Integer>>() {
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return new Tuple2<String,Integer>(value1.f0, value1.f1 + value2.f1);
}
});
14、Aggregations on windows
WindowedStream → DataStream
聚合窗口的内容。min和minBy之间的区别在于,min返回最小值,而minBy返回该字段中具有最小值的元素(max和maxBy相同)。
windowedStream.sum(0);
windowedStream.sum("key");
windowedStream.min(0);
windowedStream.min("key");
windowedStream.max(0);
windowedStream.max("key");
windowedStream.minBy(0);
windowedStream.minBy("key");
windowedStream.maxBy(0);
windowedStream.maxBy("key");
15、Union
Union 函数将两个或多个数据流结合在一起。 这样就可以并行地组合数据流。 如果我们将一个流与自身组合,那么它会输出每个记录两次。
public static void unionFunction(ExecutionEnvironment env) throws Exception {
//Produces the union of two DataSets, which have to be of the same type. A union of more than two DataSets can be implemented with multiple union calls
List<String> info1 = new ArrayList<>();
info1.add("team A");
info1.add("team B");
List<String> info2 = new ArrayList<>();
info2.add("team C");
info2.add("team D");
List<String> info3 = new ArrayList<>();
info3.add("team E");
info3.add("team F");
List<String> info4 = new ArrayList<>();
info4.add("team G");
info4.add("team H");
DataSet<String> source1 = env.fromCollection(info1);
DataSet<String> source2 = env.fromCollection(info2);
DataSet<String> source3 = env.fromCollection(info3);
DataSet<String> source4 = env.fromCollection(info4);
source1.union(source2).union(source3).union(source4).print();
// team A
// team C
// team E
// team G
// team B
// team D
// team F
// team H
}
16、Window Join
DataStream,DataStream → DataStream
可以通过一些 key 将同一个 window 的两个数据流 join 起来。
在 5 秒的窗口中连接两个流,其中第一个流的第一个属性的连接条件等于另一个流的第二个属性
inputStream.join(inputStream1)
.where(0).equalTo(1)
.window(Time.seconds(5))
.apply (new JoinFunction () {...});
inputStream.join(otherStream)
.where(<key selector>).equalTo(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new JoinFunction () {...});
具体介绍参考文章:
【flink番外篇】2、flink的18种算子window join 和interval join 介绍及详细示例
17、Interval Join
KeyedStream,KeyedStream → DataStream
根据 key 相等并且满足指定的时间范围内(e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound)的条件将分别属于两个 keyed stream 的元素 e1 和 e2 Join 在一起。
// this will join the two streams so that
// key1 == key2 && leftTs - 2 < rightTs < leftTs + 2
keyedStream.intervalJoin(otherKeyedStream)
.between(Time.milliseconds(-2), Time.milliseconds(2)) // lower and upper bound
.upperBoundExclusive(true) // optional
.lowerBoundExclusive(true) // optional
.process(new IntervalJoinFunction() {...});
具体介绍参考文章:
【flink番外篇】2、flink的18种算子window join 和interval join 介绍及详细示例
18、Window CoGroup
DataStream,DataStream → DataStream
根据指定的 key 和窗口将两个数据流组合在一起。
dataStream.coGroup(otherStream)
.where(0).equalTo(1)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new CoGroupFunction () {...});
19、Connect
DataStream,DataStream → ConnectedStreams
connect提供了和union类似的功能,用来连接两个数据流,它与union的区别在于:
- connect只能连接两个数据流,union可以连接多个数据流。
- connect所连接的两个数据流的数据类型可以不一致,union所连接的两个数据流的数据类型必须一致。
两个DataStream经过connect之后被转化为ConnectedStreams,ConnectedStreams会对两个流的数据应用不同的处理方法,且双流之间可以共享状态。
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
/**
* @author alanchan
* union算子可以合并多个同类型的数据流,并生成同类型的数据流,即可以将多个DataStream[T]合并为一个新的DataStream[T]。数据将按照先进先出(First
* In First Out)的模式合并,且不去重。 connect只能连接两个数据流,union可以连接多个数据流。
* connect所连接的两个数据流的数据类型可以不一致,union所连接的两个数据流的数据类型必须一致。
* 两个DataStream经过connect之后被转化为ConnectedStreams,ConnectedStreams会对两个流的数据应用不同的处理方法,且双流之间可以共享状态。
*
*/
public class TestConnectDemo {
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<String> ds1 = env.fromElements("i", "am", "alanchan");
DataStream<String> ds2 = env.fromElements("i", "like", "flink");
DataStream<Long> ds3 = env.fromElements(10L, 20L, 30L);
// transformation
// 注意union能合并同类型
DataStream<String> result1 = ds1.union(ds2);
// union不可以合并不同类,直接出错
// ds1.union(ds3);
// connet可以合并同类型
ConnectedStreams<String, String> result2 = ds1.connect(ds2);
// connet可以合并不同类型
ConnectedStreams<String, Long> result3 = ds1.connect(ds3);
/*
* public interface CoMapFunction<IN1, IN2, OUT> extends Function, Serializable {
* OUT map1(IN1 value) throws Exception;
* OUT map2(IN2 value) throws Exception;
* }
*/
DataStream<String> result = result3.map(new CoMapFunction<String, Long, String>() {
private static final long serialVersionUID = 1L;
@Override
public String map1(String value) throws Exception {
return value + "String";
}
@Override
public String map2(Long value) throws Exception {
return value * 2 + "_Long";
}
});
// sink
result1.print();
// connect之后需要做其他的处理,不能直接输出
// result2.print();
// result3.print();
result.print();
// execute
env.execute();
}
}
20、CoMap, CoFlatMap
ConnectedStreams → DataStream
类似于在连接的数据流上进行 map 和 flatMap。
connectedStreams.map(new CoMapFunction<Integer, String, Boolean>() {
@Override
public Boolean map1(Integer value) {
return true;
}
@Override
public Boolean map2(String value) {
return false;
}
});
connectedStreams.flatMap(new CoFlatMapFunction<Integer, String, String>() {
@Override
public void flatMap1(Integer value, Collector<String> out) {
out.collect(value.toString());
}
@Override
public void flatMap2(String value, Collector<String> out) {
for (String word: value.split(" ")) {
out.collect(word);
}
}
});
21、Iterate
DataStream → IterativeStream → ConnectedStream
通过将一个算子的输出重定向到某个之前的算子来在流中创建“反馈”循环。这对于定义持续更新模型的算法特别有用。下面的代码从一个流开始,并不断地应用迭代自身。大于 0 的元素被发送回反馈通道,其余元素被转发到下游。
IterativeStream<Long> iteration = initialStream.iterate();
DataStream<Long> iterationBody = iteration.map (/*do something*/);
DataStream<Long> feedback = iterationBody.filter(new FilterFunction<Long>(){
@Override
public boolean filter(Long value) throws Exception {
return value > 0;
}
});
iteration.closeWith(feedback);
DataStream<Long> output = iterationBody.filter(new FilterFunction<Long>(){
@Override
public boolean filter(Long value) throws Exception {
return value <= 0;
}
});
22、Cache
DataStream → CachedDataStream
把算子的结果缓存起来。目前只支持批执行模式下运行的作业。算子的结果在算子第一次执行的时候会被缓存起来,之后的 作业中会复用该算子缓存的结果。如果算子的结果丢失了,它会被原来的算子重新计算并缓存。
DataStream<Integer> dataStream = //...
CachedDataStream<Integer> cachedDataStream = dataStream.cache();
cachedDataStream.print(); // Do anything with the cachedDataStream
...
env.execute(); // Execute and create cache.
cachedDataStream.print(); // Consume cached result.
env.execute();
23、Split
此功能根据条件将流拆分为两个或多个流。 当获得混合流并且可能希望单独处理每个数据流时,可以使用此方法。新版本使用OutputTag替代。
SplitStream<Integer> split = inputStream.split(new OutputSelector<Integer>() {
@Override
public Iterable<String> select(Integer value) {
List<String> output = new ArrayList<String>();
if (value % 2 == 0) {
output.add("even");
}
else {
output.add("odd");
}
return output;
}
});
OutputTag示例如下
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
/**
* @author alanchan
*
*/
public class TestOutpuTagAndProcessDemo {
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// Source
DataStreamSource<String> ds = env.fromElements("alanchanchn is my vx", "i like flink", "alanchanchn is my name", "i like kafka too", "alanchanchn is my true vx");
// transformation
// 对流中的数据按照alanchanchn拆分并选择
OutputTag<String> nameTag = new OutputTag<>("alanchanchn", TypeInformation.of(String.class));
OutputTag<String> frameworkTag = new OutputTag<>("framework", TypeInformation.of(String.class));
// public abstract class ProcessFunction<I, O> extends AbstractRichFunction {
//
// private static final long serialVersionUID = 1L;
//
// public abstract void processElement(I value, Context ctx, Collector<O> out) throws Exception;
//
// public void onTimer(long timestamp, OnTimerContext ctx, Collector<O> out) throws Exception {}
//
// public abstract class Context {
//
// public abstract Long timestamp();
//
// public abstract TimerService timerService();
//
// public abstract <X> void output(OutputTag<X> outputTag, X value);
// }
//
// public abstract class OnTimerContext extends Context {
// public abstract TimeDomain timeDomain();
// }
//
// }
SingleOutputStreamOperator<String> result = ds.process(new ProcessFunction<String, String>() {
@Override
public void processElement(String inValue, Context ctx, Collector<String> outValue) throws Exception {
// out收集完的还是放在一起的,ctx可以将数据放到不同的OutputTag
if (inValue.startsWith("alanchanchn")) {
ctx.output(nameTag, inValue);
} else {
ctx.output(frameworkTag, inValue);
}
}
});
DataStream<String> nameResult = result.getSideOutput(nameTag);
DataStream<String> frameworkResult = result.getSideOutput(frameworkTag);
// .sink
System.out.println(nameTag);// OutputTag(Integer, 奇数)
System.out.println(frameworkTag);// OutputTag(Integer, 偶数)
nameResult.print("name->");
frameworkResult.print("framework->");
// OutputTag(String, alanchanchn)
// OutputTag(String, framework)
// framework->> alanchanchn is my vx
// name->> alanchanchn is my name
// framework->> i like flink
// name->> alanchanchn is my true vx
// framework->> i like kafka too
// execute
env.execute();
}
}
24、Select
此功能允许您从拆分流中选择特定流。新版本使用OutputTag替代。
SplitStream<Integer> split;
DataStream<Integer> even = split.select("even");
DataStream<Integer> odd = split.select("odd");
DataStream<Integer> all = split.select("even","odd");
参考上文中spilt中的outputtag示例。
25、Project
Project 函数允许从事件流中选择属性子集,并仅将所选元素发送到下一个处理流。
DataStream<Tuple4<Integer, Double, String, String>> in = // [...]
DataStream<Tuple2<String, String>> out = in.project(3,2);
上述函数从给定记录中选择属性号 2 和 3。 以下是示例输入和输出记录:
(1,10.0,A,B)=> (B,A)
(2,20.0,C,D)=> (D,C)
- 完整示例
import java.util.Arrays;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.tuple.Tuple5;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author alanchan
*
*/
public class TestprojectDemo {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple5<Integer, String, Integer, String,Double>> in = env.fromCollection(Arrays.asList(
Tuple5.of(1, "alan", 17, "alan.chan.chn@163.com", 20d),
Tuple5.of(2, "alanchan", 18, "alan.chan.chn@163.com", 25d),
Tuple5.of(3, "alanchanchn", 19, "alan.chan.chn@163.com", 30d),
Tuple5.of(4, "alan_chan", 18, "alan.chan.chn@163.com", 25d),
Tuple5.of(5, "alan_chan_chn", 20, "alan.chan.chn@163.com", 30d)
));
DataStream<Tuple3<String, Integer,Double>> out = in.project(1, 2,4);
out.print();
// 8> (alan,17,20.0)
// 11> (alan_chan,18,25.0)
// 12> (alan_chan_chn,20,30.0)
// 10> (alanchanchn,19,30.0)
// 9> (alanchan,18,25.0)
env.execute();
}
}
以上,本文主要介绍Flink 的23种常用的operator及以具体可运行示例进行说明,如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本专题分为五篇,即:
【flink番外篇】1、flink的23种常用算子介绍及详细示例(1)- map、flatmap和filter
【flink番外篇】1、flink的23种常用算子介绍及详细示例(2)- keyby、reduce和Aggregations
【flink番外篇】1、flink的23种常用算子介绍及详细示例(3)-window、distinct、join等
【flink番外篇】1、flink的23种常用算子介绍及详细示例(4)- union、window join、connect、outputtag、cache、iterator、project
【flink番外篇】1、flink的23种常用算子介绍及详细示例(完整版)