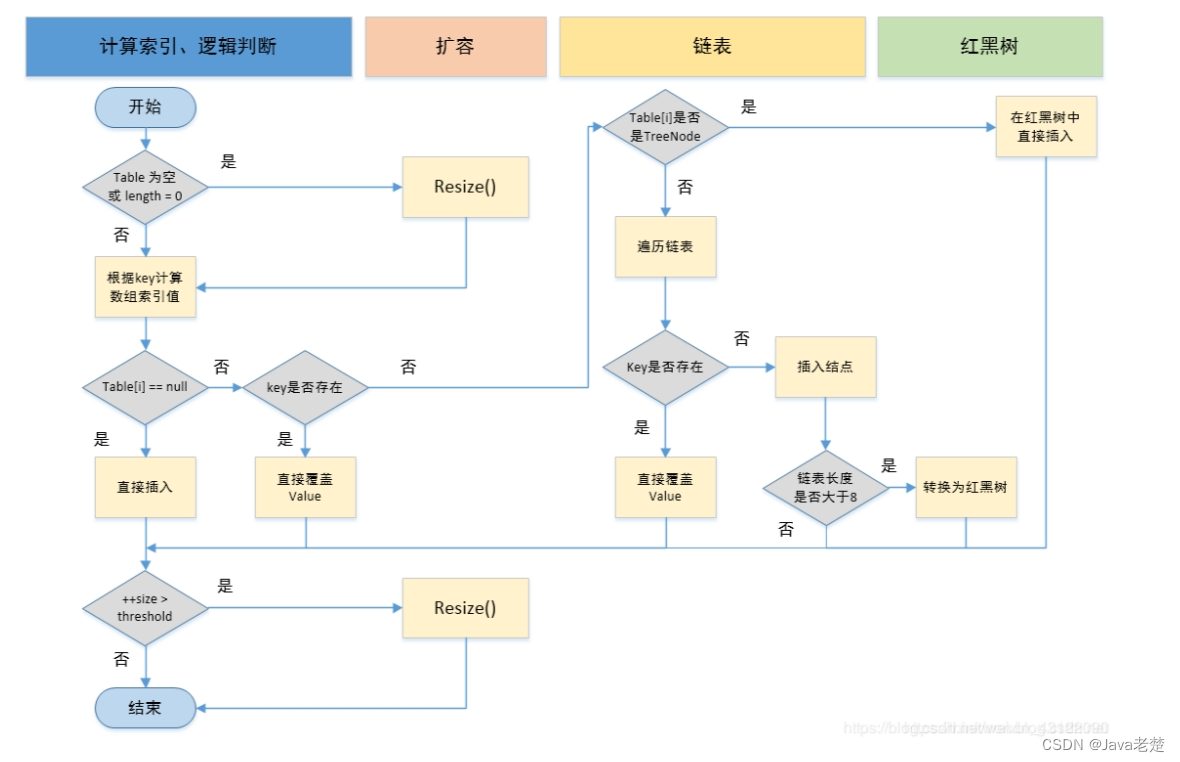
文章目录
- 1、线性回归
- 1.1 一元线性回归及实例
- 1.2 多元线性回归及实例
- 2、逻辑回归
- 2.1 逻辑回归与线性回归的区别
- 2.2 逻辑函数
- 2.3 逻辑回归的概念
- 2.4 损失函数及参数的确定
- 2.6 逻辑回归实例
1、线性回归
回归分析(Regression Analysis)是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,属于监督学习方法。回归分析的方法有很多种,按照变量的个数,可以分为一元回归分析和多元回归分析;按照自变量和因变量之间的关系,可以分为线性回归分析和非线性回归分析。
线性回归的自变量和因变量之间是线性关系,可以采用线性预测函数进行建模。利用回归分析来确定多个变量的依赖关系的方程称为回归方程。如果回归方程所呈现的图形为一条直线,则称为线性回归方程。线性回归(Linear Regression)算法的核心是线性回归方程,通过在输入数据和输出数据之间建立一种直线的相关关系,完成预测的任务,即将输入数据乘以一些常量,经过基本处理就可以得到输出数据。线性回归方程的参数可以有一个或多个,经常用于实际的预测问题,如股票走势预测、商品价格预测等。
由于线性回归能够使用一条直线来描述数据之间的关系,因此假设输入的数据X=(x1,x2,x3,…,xn),则回归方程可以归纳如下:

即y和x之间的关系可以使用一条直线进行表示。
1.1 一元线性回归及实例
在上述回归方程中,若X只有一个数值,回归方程可归纳为y=wX+b,则此时该回归方程为一元线性回归,对于一元线性回归,只需要通过对数据进行拟合,求得参数w和b的取值即可。
实例:
现有某公司出品的电影数据,包括成本和票房两项,单位为千万元,目前有一部电影成本耗费两亿,要求使用一元线性回归预测其票房金额。
| 电影编号 | 成本 | 票房 |
|---|---|---|
| 1 | 6 | 9 |
| 2 | 9 | 12 |
| 3 | 12 | 29 |
| 4 | 14 | 35 |
| 5 | 16 | 59 |
sklearn中的linear_model模块提供了LinearRegression函数用于实现线性回归。
语法格式:
sklearn.linear_model.LinearRegression(fit_intercept = True,normalize = False,copy_x=True,n_jobs=None)
其中fit_intercept表示是否会计算截距,normalize表示在回归前是否进行归一化处理,copy_x表示是否要复制一份数据进行处理,n_jobs为线程数。
对象属性中coef_表示线性回归问题的估计系数,intercept_表示回归方程的截距。
from sklearn import linear_model
import matplotlib.pyplot as plt
#定义函数用于绘制图像
def drawplt():
plt.figure()
plt.title('Cost and Income Of a Film') #标题
plt.xlabel('Cost') #横坐标标题
plt.ylabel('Income') #纵坐标标题
plt.axis([0, 25, 0, 60]) #x轴、y轴范围
plt.grid(True) #显示网格线
X = [[6], [9], [12], [14], [16]]
y = [[9], [12], [29], [35], [59]]
model = linear_model.LinearRegression()
model.fit(X, y) #模型训练
a = model.predict([[20]])
w = model.coef_
b = model.intercept_
print("投资两亿的电影预计票房收入为:{:.2f}千万元".format(model.predict([[20]]) [0][0]))
print("回归模型的系数是:",w)
print("回归模型的截距是:",b)
print("最佳拟合线: y = ",int(b),"+", int(w),"× x" )
drawplt()
#绘制点
plt.plot(X, y, '.')
#绘制直线
plt.plot([0,25],[b,25*w+b])
plt.show()


1.2 多元线性回归及实例
如果在回归方程中,X是一组数值X=(x1,x2,x3,…,xn),那么该回归方程为多元线性回归,多元线性回归方程的求解相较于一元线性回归更加复杂,经常使用最小二乘法等数学方法进行拟合。最小二乘法是一种数学优化方法,也称最小平方法,它通过最小化误差的平方和寻找最佳结果。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。
实例:
现有某公司出品的电影数据,包括成本、广告费用和以及票房三项,单位为千万元,目前有一部电影成本耗费一亿,推广费为三千万,要求使用多元线性回归预测其票房金额。
| 电影编号 | 成本 | 广告费用 | 票房 |
|---|---|---|---|
| 1 | 6 | 1 | 9 |
| 2 | 9 | 3 | 12 |
| 3 | 12 | 2 | 29 |
| 4 | 14 | 3 | 35 |
| 5 | 16 | 4 | 59 |
import numpy as np
from sklearn import datasets,linear_model
x = np.array([[6,1,9],[9,3,12],[12,2,29],
[14,3,35],[16,4,59]])
X = x[:,:-1]
Y = x[:,-1]
print('X:',X)
print('Y:',Y)
# 训练数据
regr = linear_model.LinearRegression()
regr.fit(X,Y)
print('系数(w1,w2)为:',regr.coef_)
print('截距(b)为:',regr.intercept_)
# 预测
y_predict = regr.predict(np.array([[10,3]]))
print('投资一亿,推广3千万的电影票房预测为:',y_predict,'千万')

2、逻辑回归
对于简单的线性相关问题,可以使用线性回归,将数据点拟合成一条直线。线性回归的假设是所有的数据都精确或粗略地分布在这条直线上,因此可以完成基本的预测任条。
有时人们只想知道待判定的数据点位于直线的上边还是下边、左侧还是右侧。以便得知当前数据的归属或类型。针对这项任务,就需要使用逻辑回归这种方式来实现。
2.1 逻辑回归与线性回归的区别
线性回归输出的是一个值,且为连续的,而逻辑回归则将值映射到集合(0,1)中。例如,要通过一个人信用卡欠款的数额预测一个人的还款时长,在预测模型中还款时长的值是连续的,因此,最后的预测结果是一个数值,这类问题就是线性回归能解决的问题。而如果要通过信用卡欠款数额预测还款是按期还是逾期,在预测模型中,结果应该是某种可能性(类别),预测对象属于哪个类别,这样的问题就是逻辑回归能解决的分类问题。所以逻辑回归也叫逻辑分类。也就是说,线性回归经常用来预测一个具体数值,如预测房价、未来的天气情况等。逻辑回归经常用于将事物归类,例如,判断一幅X光片上的肿瘤是良性的还是恶性的,判断一个动物是猫还是狗等。
2.2 逻辑函数
逻辑函数(Logistic)是逻辑回归中重要的一个函数概念,其中的经典函数为Sigmod函数,逻辑函数起源于逻辑模型,该模型也称为Verhulst模型或逻辑增长曲线,是一个早期的人口分布研究模型,由Pierre-Francois Verhulst 在1845年提出,描述系统中人口的增长率和当下的人日数目成正比,还受到系统容量的限制。Logistic 模型是由微分方程形式描述的,求解后可以得到 Logistic 函数。Logistic函数的简单形式为:

其中x的取值范围为正无穷到负无穷,值域为(0,1)。
由于由于Logistic函数的图形外形看起来像S形,因此Logistic函数经常被称为Sigmoid函数(S形函数)。在机器学习中,人们经常把Sigmoid函数和Logistic函数看作同一个函数的两个名称。Sigmoid逻辑函数的图形如下所示。

由上图可以看出,当x趋于正无穷时,函数值趋近于1;当x趋向负无穷时,函数值趋近于0。当x等于0时,y等于0.5,可以使用x等于0处的轴将函数划分,右边大于0.5的判断为1,左边小于0.5的判断为0,就可以完成二分类的判断。
2.3 逻辑回归的概念
逻辑回归(Logistics Regression)是根据现有数据对分类边界线建立回归公式,以此进行分类。逻辑回归在线性回归模型的基础上,通过引入Sigmoid函数,将线性回归的输出值映射到(0,1)。接下来使用阈值将结果转换成0或1,就能够完成两类问题的预测。
首先已知线性回归表达式如下:

将y代入Sigmod函数公式:

可以计算得到逻辑回归方程:

2.4 损失函数及参数的确定
损失是真实模型与假设模型之间差异的度量。机器学习或者统计机器学习常见的损失函数有0-1损失函数、平方损失函数、绝对值损失函数和对数损失函数,逻辑回归中采用的则是对数损失函数。如果损失函数越小,表示模型越好。
对数损失函数也称为对数似然损失函数,是在概率估计上定义的,可用于评估分类器的概率输出,对数损失函数形式如下。

其中P(Y|X)表示被正确分类的概率,损失函数则是对其进行对数取反。概率计算中样本所属类别Y由逻辑回归函数h(y)计算获得,真实样本类别为0或1,假设待确定的参数如下:

可以得到基于对数损失函数的逻辑回归损失函数如下:

将上述表达式进行合并,则可以将单个样本的损失函数描述为:

在这个式子中,当y_i取值为1时,公式取前半段,当y_i取值为0时,公式取后半段,正好将其分理出上述的两个表达式。
在实际计算时,可以选用各个样本分布计算损失值再取平均值,也可以使用全部样本的综合作为损失值。
获得损失函数后,接下来的关键步骤是进行参数的确定,对于逻辑回归来说,较好的参数获取方法是梯度下降法,梯度下降法的思路主要是相对参数赋初值,然后通过改变参数的值,使得参数按照梯度下降的方向逐渐减少,利用这一方式,朝着偏导数的反方向,每次前进一小步,使得损失函数达到预先设置的较小值或满足停止条件时停止此行为。
梯度下降的计算思路具体可以参考神经网络梯度下降计算过程:
十三、机器学习进阶知识:神经网络之反向传播算法(梯度、误差反向传播算法BP)
2.6 逻辑回归实例
逻辑回归的实现主要有两种方式,第一种是使用sklearn库来实现,第二种是采用Python自编写的方式来实现。
sklearn实现逻辑回归鸢尾花分类预测实例
在sklearn中,有三个逻辑回归相关的模块,分别是分别是LogisticRegression、LogisticRegressionCV和 LogisticRegression_path。三者的区别在于:LogisticRegression 需要手动指定正则化系数;LogisticRegressionCV 使用了交叉验证选择正则化系数;LogisticRegression_path只能用来拟合数据,不能用于预测。所以通常使用的是前两个模块 LogisticRegression和LogisticRegressionCV,这两个模块中相关参数的意义也是相同的。
LogisticRegression的语法格式如下:
sklearn.linear_model.LogisticRegression(penalty='l2',dual=False,tol=0.0001,C=1.0,fit_intercept=True,intercept_scaling=1,class_weight=None,random_state=None,solver='warn',max_iter=100,multi_class='warn',verbose=0,warm_start=False,n_jobs=None,l1_ratio=None)
主要参数如下:
tol:收敛阈值。
C:正则化系数。
random_state:整型,伪随机数生成器的种子,用于在混淆数据时使用。
solver:优化算法。取值“liblinear”代表坐标轴下降优化法,“lbfgs”和“newton-cg”分别表示两种拟牛顿优化方法,“sag”是随机梯度下降优化法。
max_iter:int,可选,默认值为100,是求解器收敛的最大迭代次数。
主要属性如下。
classes_:数组型,表示类别,是分类器已知的类的列表。
coef_:数组型,表示特征系数,是决策函数中的特征系数。
intercept_:数组型,表示决策用的截距。
以sklearn库中可导入的鸢尾花数据集为例,对其使用逻辑回归进行分类预测。
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn import metrics
X, y = load_iris(return_X_y=True) #数据集的导入
#将数据集分割成训练集、测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
#使用逻辑回归对训练数据集中的样本特征以及类别标签进行训练
clf=LogisticRegression(random_state=0,solver='lbfgs',multi_class='multinomial').fit(X_train, y_train)
#输出决策函数中的特征系数以及截距
print('coef:\n',clf.coef_)
print('intercept:\n',clf.intercept_ )
#对训练集中的前两个样本进行分类预测
print('predict first two:\n',clf.predict(X_train[:2, :]))
#返回分类器性能决定系数R^2
print('classification score:\n',clf.score(X_train, y_train))
#对测试集样本特征进行类别分类
predict_y = clf.predict(X_test)
#输出分类的性能评估结果
print('classfication report:\n ',metrics.classification_report (y_test,predict_y))

可以看出,在计算结果中,分类器的性能评价结果为0.97,精确率、召回率和f1指数结果均为0.93,分类性能较好。
Python自编写逻辑回归实现信用卡逾期情况类别预测
某银行搜集了用户贷款、收入和信用卡是否逾期三项信息,保存在数据集credit.csv中,使用用户贷款以及收入作为特征数据,是否逾期作为类别,构建一个能够预测信用卡是否逾期的逻辑回归模型,参数采用梯度下降法进行获取,使用绘图的方式记录损失函数的变化情况。(使用Jupyter Notebook编写)
#1、加载数据集
import pandas as pd
df = pd.read_csv("credit.csv", header=0) # 加载数据集
df.head() #查看前5行数据
#2、绘制数据的散点图,查看数据分布情况
from matplotlib import pyplot as plt
plt.figure(figsize=(10, 6))
map_size = {0: 20, 1: 100}
size = list(map(lambda x: map_size[x], df['overdue']))
plt.scatter(df['debt'],df['income'], s=size,c=df['overdue'],marker='v')


#2、模型训练
#定义Sigmoid函数
def sigmoid(z):
sigmoid = 1 / (1 + np.exp(-z))
return sigmoid
#定义对数损失函数
def loss(h, y):
loss = (-y * np.log(h) - (1 - y) * np.log(1 - h)).mean() #取均值
return loss
#定义梯度下降函数
def gradient(X, h, y):
gradient = np.dot(X.T, (h - y)) / y.shape[0]
return gradient
# 逻辑回归过程
def Logistic_Regression(x, y, lr, num_iter):
intercept = np.ones((x.shape[0], 1)) # 初始化截距为 1
x = np.concatenate((intercept, x), axis=1)
w = np.zeros(x.shape[1]) # 初始化参数为 0
for i in range(num_iter): # 梯度下降迭代
z = np.dot(x, w) # 线性函数
h = sigmoid(z) # sigmoid 函数
g = gradient(x, h, y) # 计算梯度
w -= lr * g # 通过学习率 lr 计算步长并执行梯度下降
z = np.dot(x, w) # 更新参数到原线性函数中
h = sigmoid(z) # 计算 sigmoid 函数值
l = loss(h, y) # 计算损失函数值
return l, w # 返回迭代后的梯度和参数
#初始化模型,进行训练
import numpy as np
x = df[['debt','income']].values
y = df['overdue'].values
lr = 0.001 # 学习率
num_iter = 10000 # 迭代次数
# 模型训练
L = Logistic_Regression(x, y, lr, num_iter)
L

上述过程已经将模型训练完成,逻辑回归模型参数已确定,之后显示模型的分类线并测试模型的性能。
#3、绘制模型分类线
plt.figure(figsize=(10, 6))
map_size = {0: 20, 1: 100}
size = list(map(lambda x: map_size[x], df['overdue']))
plt.scatter(df['debt'],df['income'], s=size,c=df['overdue'],marker='v')
x1_min, x1_max = df['debt'].min(), df['debt'].max(),
x2_min, x2_max = df['income'].min(), df['income'].max(),
xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max), np.linspace(x2_min, x2_max))
grid = np.c_[xx1.ravel(), xx2.ravel()]
probs = (np.dot(grid, np.array([L[1][1:3]]).T) + L[1][0]).reshape(xx1.shape)
plt.contour(xx1, xx2, probs, levels=[0], linewidths=1, colors='red');

#4、绘制损失函数变化曲线
def Logistic_Regression(x, y, lr, num_iter):
intercept = np.ones((x.shape[0], 1)) # 初始化截距为 1
x = np.concatenate((intercept, x), axis=1)
w = np.zeros(x.shape[1]) # 初始化参数为 1
l_list = [] # 保存损失函数值
for i in range(num_iter): # 梯度下降迭代
z = np.dot(x, w) # 线性函数
h = sigmoid(z) # sigmoid 函数
g = gradient(x, h, y) # 计算梯度
w -= lr * g # 通过学习率 lr 计算步长并执行梯度下降
z = np.dot(x, w) # 更新参数到原线性函数中
h = sigmoid(z) # 计算 sigmoid 函数值
l = loss(h, y) # 计算损失函数值
l_list.append(l)
return l_list
lr = 0.01 # 学习率
num_iter = 30000 # 迭代次数
l_y = Logistic_Regression(x, y, lr, num_iter) # 训练
# 绘图
plt.figure(figsize=(10, 6))
plt.plot([i for i in range(len(l_y))], l_y)
plt.xlabel("Number of iterations")
plt.ylabel("Loss function")

信用卡逾期预测实例数据集、python文件以及用于Jupyter Notebook的ipynb文件下载链接(包含详细代码解释)