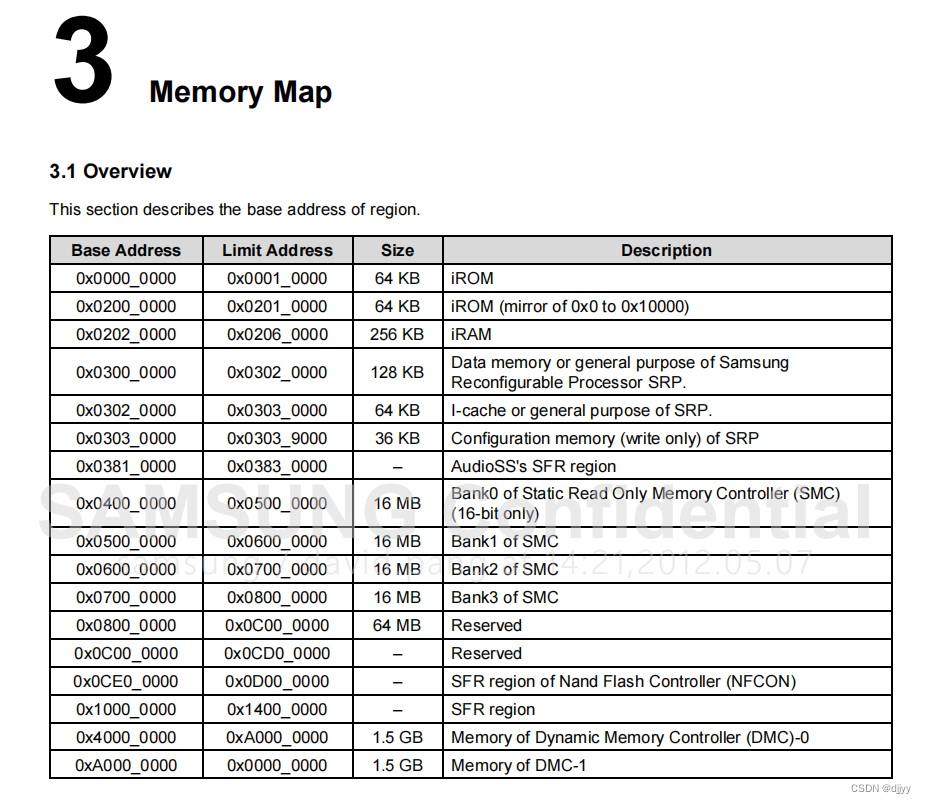
TeachMe: Three-phase learning framework for robotic motion imitation based on interactive teaching and reinforcement learning解析
- 摘要
- 1. 简介
- 2. 相关工作
- 2.1 基于编码器-解码器的架构
- 2.2 强化学习
- 3. 方法
- 3.1 问题表述
- 3.2 NTU-DB
- 3.3 阶段1: 编码器和解码器
- 3.4 阶段2: 基于模拟的强化学习
- 3.5 阶段3: 交互式强化学习
论文链接:https://ieeexplore.ieee.org/document/8956326
论文出处:2019 RO-MAN
论文单位:Korea University of Science and Technology,韩国
摘要
- 动作模仿是机器人的基本沟通技能; 尤其是与人类的非语言互动。
- 由于人与机器人的运动学构型存在差异,确定两种姿态域之间的适当映射具有挑战性。
- 此外,在从人体运动视频中提取3D运动细节(如手腕关节运动)时,技术限制导致运动重定向面临重大挑战。
- 在不同运动域上的显式映射表明了一个相当低效的解决方案。
- 为了解决这些问题,我们提出了一种三阶段强化学习方案,使NAO机器人能够从从视频输入中提取的人体姿态骨架中学习运动。
- 我们的学习计划包括三个阶段:
(1)第一阶段为学习准备
(2)第二阶段是基于模拟的强化学习
(3)第三阶段是基于人在环的强化学习 - 在第一阶段,人类骨骼和机器人运动的嵌入由自动编码器学习。
- 在第二阶段,NAO机器人使用强化学习来学习粗略的模仿技能,该强化学习可以翻译学习到的嵌入。
- 在最后一个阶段,机器人通过基于直接教学的交互式设置奖励来学习前一阶段没有考虑到的运动细节,而不是前一阶段使用的方法。
- 特别值得注意的是,与第二阶段整体模仿所需的大量训练集相比,第三阶段运动细节所需的交互式输入数量相对较少。
- 实验结果表明,该方法有效地提高了对NTU-DB中手势和敬礼动作的模仿能力。
1. 简介
-
根据社会学习理论,人类可以通过观察和模仿他人来学习新的行为。
-
通过这种社会学习技能,人类互动并进行非语言的社会行为,如挥手或鞠躬。
-
同样,对于人类与机器人的非语言社交互动,教会机器人观察和模仿人类的动作是至关重要的。
-
模仿学习是一种长期研究的方法,用于向机器人教授人类动作。
-
机器人教学方法多种多样,包括基于点的直接教学、基于人体运动数据的动态建模和优化的运动重定向、远程操作间接教学和基于虚拟现实的远程操作教学。
-
通过这些精确的动力学建模和基于末端执行器的教学方法,机器人可以有效地完成目标任务。
-
考虑到人-机器人的社会互动,为了在不失去表演者的隐含意义或意图的情况下模仿人类的运动,不仅在末端执行器上,而且在肘关节等其他关节上都应该进行精确的运动重定向。
-
特别是,需要精确的设备或方法来克服由于运动学配置差异而出现的问题,同时教授复杂的运动,如手腕关节运动。
-
因此,在这些情况下,不借助任何外部设备直接操纵机器人手臂来指导机器人的动觉教学是直观有效的,特别是在手腕关节运动的教学中。
-
近年来,许多研究引入深度学习技术来解决具有挑战性的问题。深度学习需要大量的训练数据。然而,收集如此大量的数据成本很高,特别是在机器人应用中。
-
在本研究中,为了利用少量试验的直接教学和深度学习的优势,我们试图对上一步中由模拟器进行深度强化学习训练的策略进行微调。
-
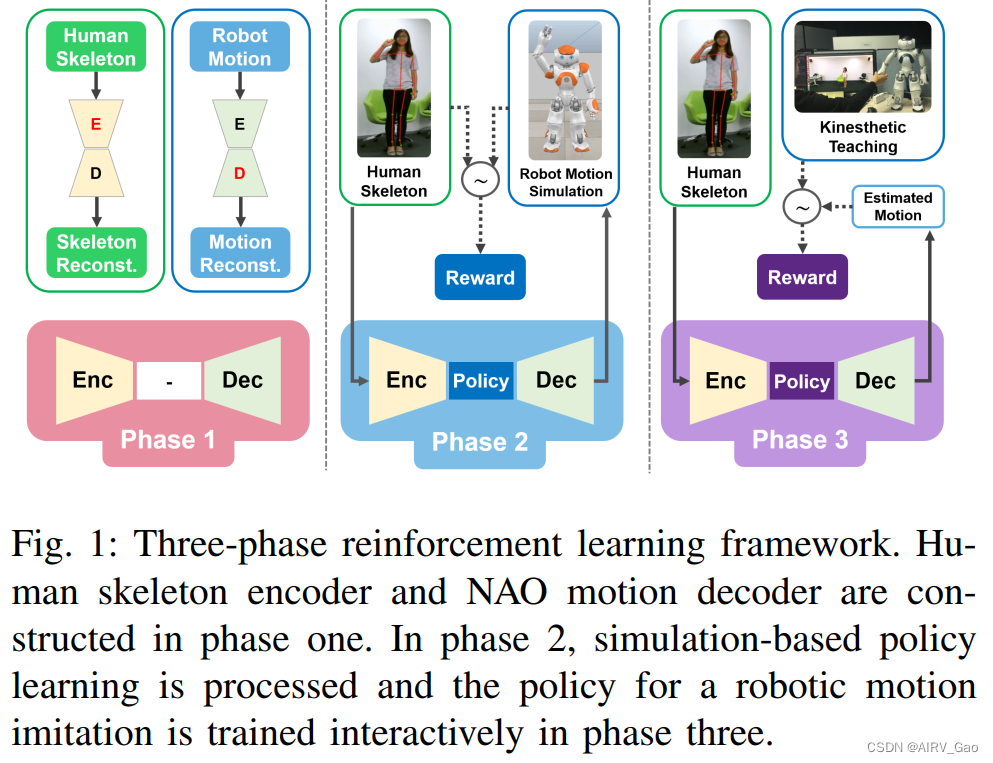
我们将我们的方法称为三阶段强化学习,包括基于模拟的学习和基于人在环的交互式学习方法(图1)。
-
我们的目标是使NAO机器人能够产生与人类骨骼的姿势相匹配的运动,这些动作展示了从NTU-DB数据集获得的挥手和敬礼动作。
-
我们的学习计划包括三个阶段。第一阶段,作为准备步骤,使用骨骼和合成运动数据生成人类和NAO运动的嵌入。
-
在第二阶段,我们使用强化学习确定两个嵌入之间的映射策略。
-
在最后一个阶段,动觉教学是根据第二阶段学到的最优策略逐帧进行的。我们能够学习到上一阶段没有考虑到的细节运动,比如手腕关节的运动,并解决运动学构型差异带来的困难。
-
此外,通过实验,我们证明了模仿技能可以在相对较短的学习时间内得到提高。
-
表1。列出每个学习阶段的模拟和交互式学习方法的使用情况。
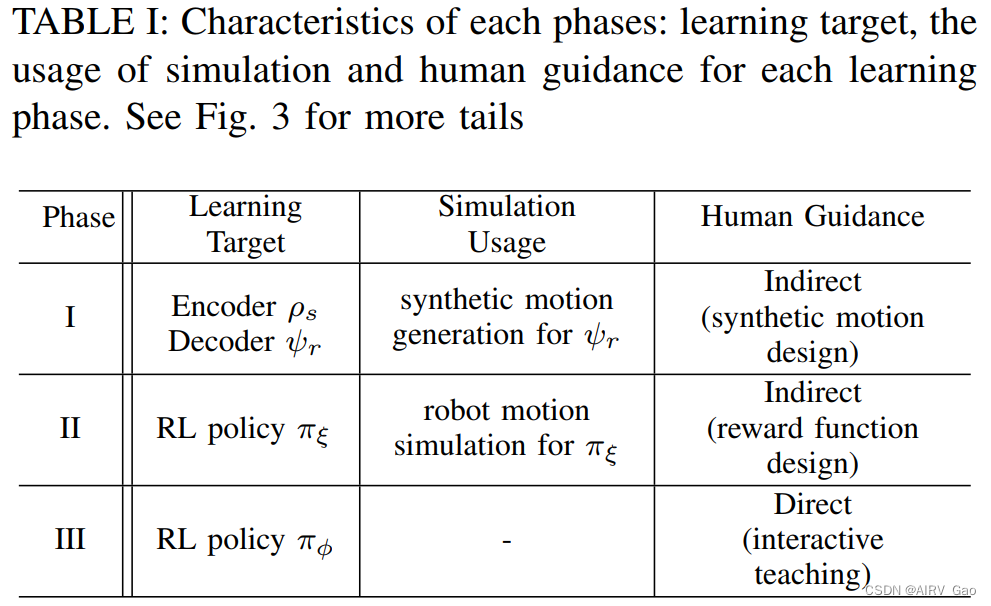
-
综上所述,我们的主要贡献如下:
(1) 将人体运动模拟建模为人体骨骼与机器人运动之间的映射问题,提出了基于用户引导的三阶段框架,并给出了实验结果。据我们所知,这是人类运动模仿的第一个框架,它结合了从合成运动中学习和交互式微调。
(2)我们为机器人生成了一个统一的运动解码器,它包含了我们所有的运动类,并验证了我们的策略可以成功地使用这个集成的机器人运动解码器进行训练。
(3)实验表明,通过少量的交互式教学,可以有效地改进前一阶段的定量训练策略。
2. 相关工作
2.1 基于编码器-解码器的架构
- 编码器-解码器网络架构在最近的几项研究中越来越受欢迎,包括机器人任务、人类运动预测、机器翻译和图像字幕。
- 在我们的研究中,我们尝试使用由**变分自编码器(VAE)**编码的逐帧骨骼数据和机器人运动,让NAO机器人实时模仿人体运动。
- 通过强化学习实现了骨架与机器人姿态之间的运动重定向;此外,使用NTU-DB进行培训和评估。
2.2 强化学习
- 从游戏、机器人到动画,近年来强化学习在各个研究领域得到了广泛的应用。
- 此外,我们的框架不是使用轨迹,而是使用一种最近的强化学习算法——近端策略优化(PPO)算法在逐帧数据上运行。
3. 方法
- 运动模仿学习的主要概念是确定骨架姿态的低维状态表示与NAO之间的映射函数π。
- 如图2所示,两个姿态的运动嵌入具有不同的分布,因此,我们尝试使用强化学习来确定这些姿势之间的运动重定向映射。
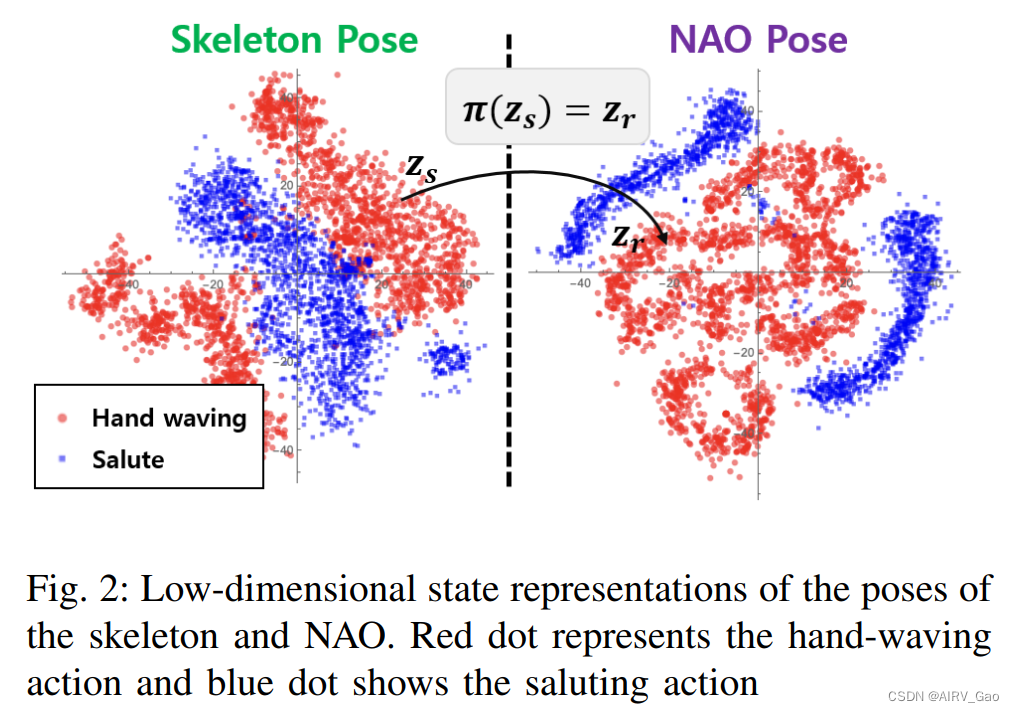
3.1 问题表述
- 从给定时刻 t 的人体姿态图像 D_t 和骨架变换函数 f_s 中,我们定义了人体姿态图像的骨架变换为 x_s = f_s(D_t)。
- ρ_s 为骨架编码器;
- x_s={x1,y1,z1,…,x25,y25,z25} 为骨骼本身。
- z_s = ρ_s(x_s) 是骨架的编码。其中 z_s 是人体姿态D_t图像对应的骨架的低维表示。
- x_r = {θ1, θ2, …, θ10} 为NAO的pose.
- ρ_r 为机器人位姿编码器。
- NAO的pose的低维状态表示为:z_r = ρ_r(x_r)。
- 我们的目标是确定合适的策略 z_r = π(z_s),该策略将姿势从给定的人类姿势的潜在表征 z_s 映射到NAO姿势对应的潜在表征 z_r。
3.2 NTU-DB
- NTU-DB提供的骨架由25个关节组成,每个关节具有x, y, z坐标。
- 由于我们在第二阶段定义了一个关于骨架和NAO的运动学配置的奖励函数,因此需要一个预处理步骤来校准骨架的坐标以使其与NAO的坐标相匹配。
- 最初,骨架的每个关节都是基于躯干关节移动的,并且在躯干和骨盆关节之间创建了一个向量。
- 从矢量中创建正交矢量,然后根据Kinect参考坐标生成方向余弦矩阵(DCM),因为骨架是基于Kinect坐标表示的。
- 使用DCM旋转坐标后,再次旋转到NAO坐标。
- 最后,通过偏航方向校正完成坐标变换。
3.3 阶段1: 编码器和解码器
-
如图3所示,VAE用于学习骨架的低维状态表示和NAO的参考运动。
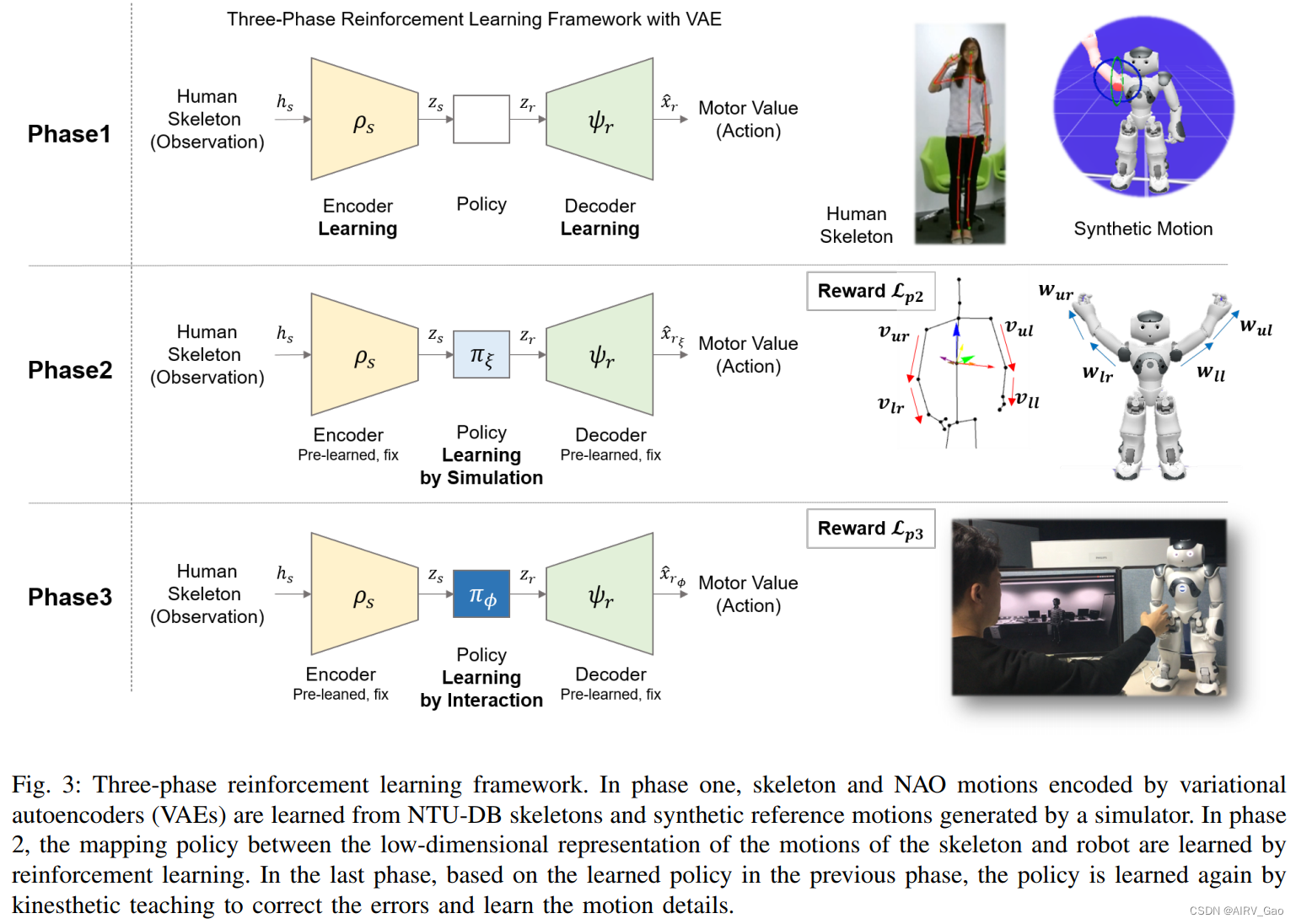
-
在排除误差数据的情况下,用40k帧的挥手动作和32k帧的敬礼动作训练骨架的VAE。
-
图4的左侧显示了骨架的VAE编码器部分的详细结构。
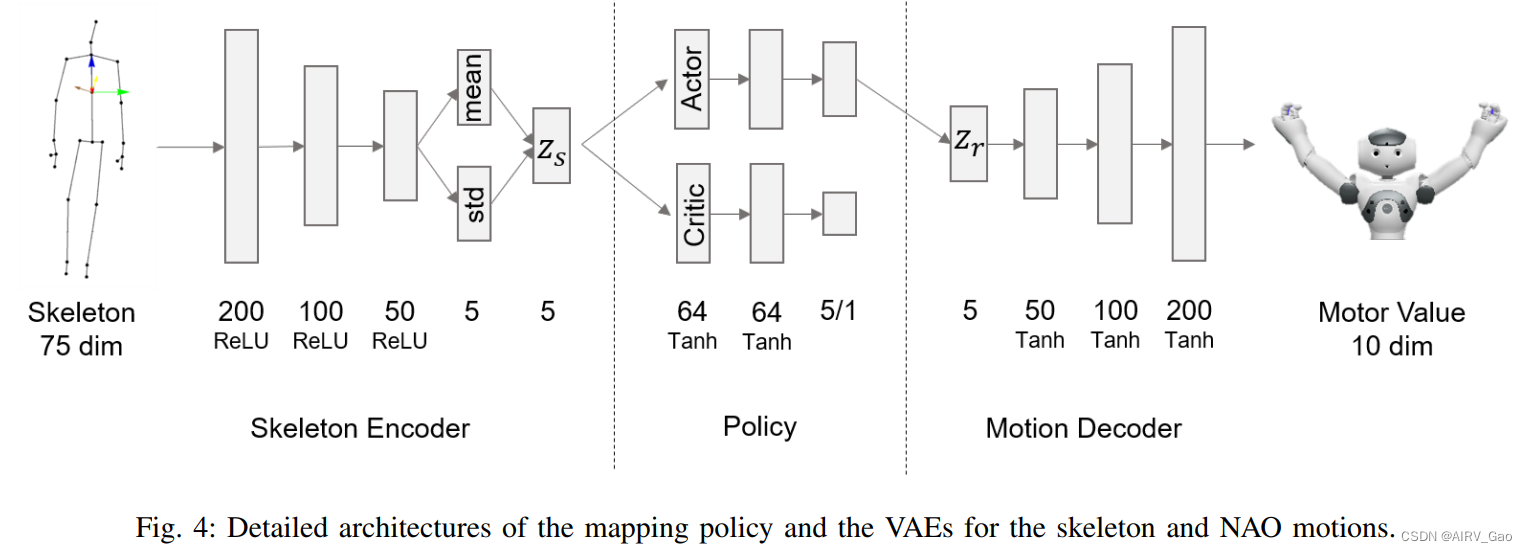
-
骨架编码器 ρ_s 接受75维(25 × 3)的 x_s 的骨架作为输入,利用整流线性单元激活函数对200、100和50的均值和标准差进行采样后,输出一个五维潜在表示向量 z_s。
-
NAO运动的VAE具有与骨架相似的结构,并且在我们的研究中仅使用了解码器 β_r 来从NAO姿态的潜在表示向量 z_r 生成估计的运动值 β_r(z_r) = x_r^ 。
-
NAO运动解码器的详细结构如图4右侧所示。
-
利用机器人运动潜在表示向量 z_r,估计的电机值 x^ r = {θ^ 1, θ^ 2, …, θ^10}, 通过50,100和200层的 Tanh 激活函数输出。
-
电机值,θ^ 1,···,θ^10,对应左臂的五个关节,即肩倾、侧倾、肘部偏航、侧倾、手腕偏航,以及右臂类似的五种运动。
-
为了训练每个动作类的NAO动作解码器,一个名为“Choregraphe”的官方NAO模拟器被用来为每个动作生成几个合成的参考动作帧。
-
在挥手运动中,我们从双臂的四种参考运动模式中,通过噪声添加数据增强创建了20k帧。在敬礼运动中,采用两种参考运动模式和噪声加持数据增强生成10k帧。
3.4 阶段2: 基于模拟的强化学习
- 在第二阶段,我们使用在第一阶段学习到的骨架编码器 ρ_s 和NAO运动解码器 β_r 来训练策略 πξ,该策略πξ可以在骨架和NAO运动嵌入之间适当地映射。
- 策略通过PPO进行训练,PPO是一种最新的强化学习算法。
- 如图4的中心部分所示,该策略由演员(actor)和评论家(critic)网络组成,每个网络都有两个完全连接的层,共64层,具有 Tanh激活功能。
- 一个编码的骨架z_s被输入到演员和评论家网络中,这产生了演员的一个动作,作为NAO动作解码器的输入,以及评论家通过评估学习演员网络的一个值。
- 训练时使用V-REP模拟器进行NAO运动模拟。
- 为了训练策略进行适当的映射,需要设计适当的奖励函数。
- 由于我们的实验选择的所有运动都只使用了手臂,因此我们使用双臂的向量来设计奖励函数,以确保NAO遵循骨骼的姿态。
- 下面的方程表示强化学习阶段2中使用的奖励函数。
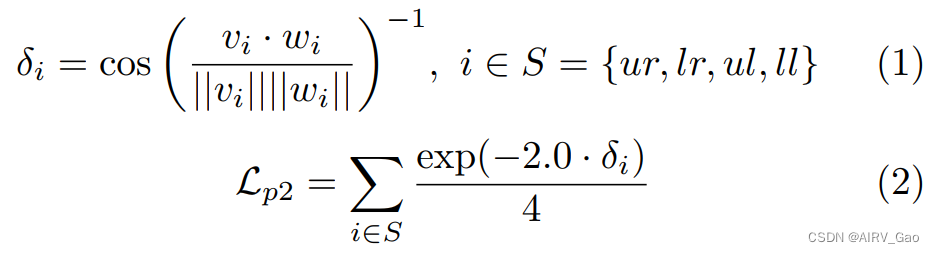
由式(1)计算骨架和NAO臂向量之间的余弦相似度δi。 - 在图3的第二行中,vi和wi分别表示骨架臂向量和NAO臂向量,其中索引 i 表示 S
中臂的右上(ur)、右下(lr)、左上(ul)和左下(ll)部分。 - 然后,δ_i 用于计算奖励函数 L_p2,该函数在0和1之间归一化。为了放大相似误差,将 -2.0乘以δ_i。
- 第2阶段的目标函数为:
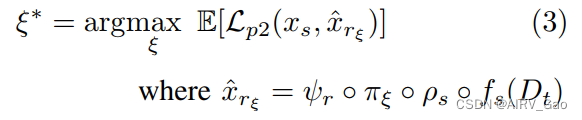
其中阶段2的目标是找到策略 πξ 的最优参数 ξ∗ ,使预期奖励最大化。 - 由骨架编码器ρ_s、πξ策略和NAO运动解码器β_r生成与输入骨架x_s对应的NAO电机估计值x^rξ。
3.5 阶段3: 交互式强化学习
- 在第二阶段,我们使用模拟器和适当设计的奖励函数来训练运动模仿策略。
- 然而,由于自由度不足(每臂5个自由度),NAO不能完全表示笛卡尔空间中每个臂的6个自由度。
- 除此之外,还有一些限制导致模仿学习困难。
- 由于NAO臂的自由度低于骨架,因此具有不同的可操作性,并且在阶段2的奖励函数 L_p2 中没有考虑腕关节运动等细节运动。
- 即使是由f_s制造的骨骼的手腕关节运动也表现出低可靠性,因为它的噪音。
- 由于运动学构型的差异和详细运动学习的困难,阶段2方法显示出明显的局限性。
- 为了克服这些限制,我们在第三阶段引入了人在环教学方法,在训练期间直接与机器人交互来教授动作。
- 在这种方法中,人类观察每个输入的骨架框架,并通过操纵其手臂产生与骨架对应的NAO姿势并将其记录到记忆中。
- 当收集到一定数量的批量大小的训练数据时,通过奖励函数更新策略。
- 下面的等式表示第三阶段的奖励函数。
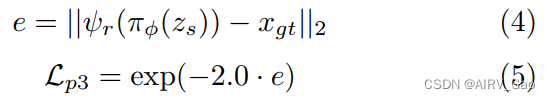
其中误差放大常数设为经验值-2.0。 - 根据第三阶段:z_r = π(z_s) 的策略,将骨架的输入潜表示 z_s 映射到NAO运动的潜表示 z_r。
- 由NAO运动解码器再次解码 z_r 以产生估计的电机值x^r。
- 现在,从式(4)中,计算电机估计值 x^r 与实际电机值 x_gt = {θ1, θ2, …, θ10} 之间的2范数误差,x_gt 是由人手动创造的。
- 利用这个误差,第三阶段的归一化奖励 L_p3 由指数函数和放大常数计算,如式(4)所示。
- 第三阶段的目标函数公式如下:
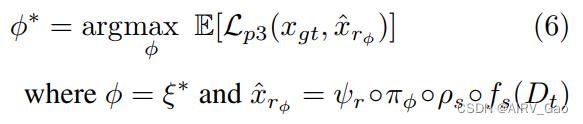
- 阶段2的最优策略参数ξ∗成为阶段3的初始策略参数 φ = ξ∗。
- 现在,第三阶段的目标是确定最优策略参数φ∗,使期望奖励函数 L_p3 最大化。
- 因此,我们观察到在阶段2中执行了粗调优,而在阶段3中执行了微调。