🏆引言:深度卷积神经网络在图像识别任务中取得了巨大的成功。然而,将最先进的图像识别网络转移到视频上并非易事,因为每帧评估速度太慢且负担不起。我们提出了一种快速准确的视频识别框架——深度特征流DFF。它只在稀疏关键帧上运行昂贵的卷积网络,并通过流场将其深度特征映射传播到其他帧。它实现了显著的加速,因为流计算相对较快。整个体系结构的端到端训练显著提高了识别精度。深度特征流是灵活和通用的。在目标检测和语义分割两个视频数据集上进行了验证。它极大地推进了视频识别任务的实践。
文章目录
- 模型架构
- 实验
- 代码
模型架构
DFF的流程图
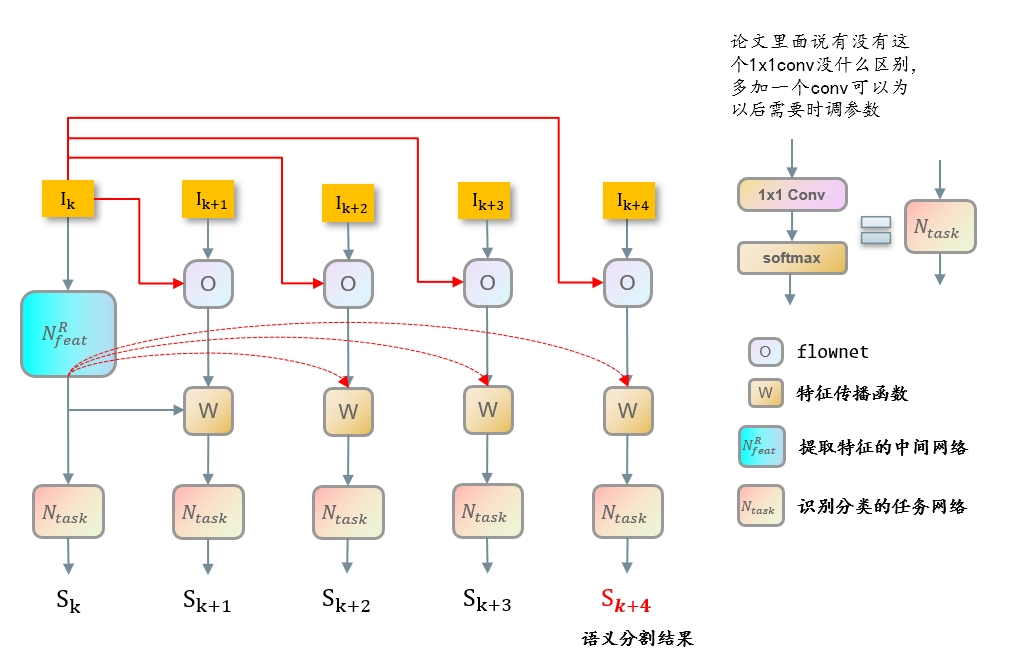
feat网络相当于是pspnet的backbone,然后这个task网络就是pspnet用于预测的head
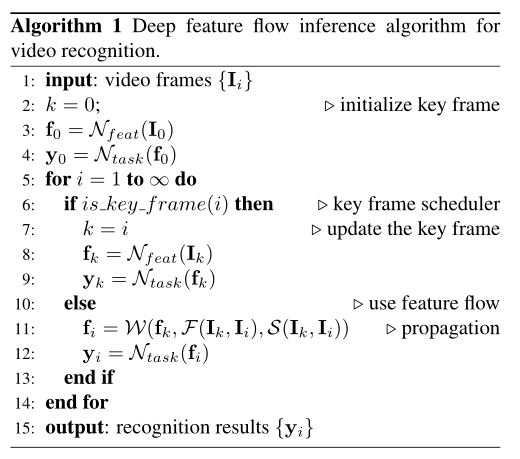
伪代码说明
N f e a t N_{feat} Nfeat
<原文>:我们使用ResNet模型,具体来说,ResNet-50和ResNet-101模型在ImageNet预训练,最后的1000路分类层被丢弃。按照DeepLab进行语义分割,R-FCN进行目标检测的做法,将特征步幅从32缩小到16,以产生更密集的特征图。第一个block的conv5层,步距由2改为1,并且conv5中的所有3×3卷积核上应用空洞卷积,以保持视场(dilation=2)。对conv5追加一个随机初始化的3×3卷积,将特征信道维数降至1024,其中还应用了空洞卷积。生成的1024维特征映射是后续任务的中间特征矩阵 N f e a t N_{feat} Nfeat
feat网络实际上就是一个语义分割模型,作者采用了DeeplabV2,本人采用了pspnet-r101。并且语义分割模型pspnet101已在cityscape数据集上与训练好了。单独的pspnet-r101在cityscape验证集上mIOU=69
dff还有一个scale层,论文里面有说,不过我这里没有加进去,因为scale层容易干扰我后面的实验分析
输入:
gt = [batch_size,1,512,1024]
im_flow_list = [batch_size,3,2,512,1024]
im_seg_list = [batch_size,3,2,512,1024]
输出:
pred.shape = [1,19,64,128]
N t a s k N_{task} Ntask
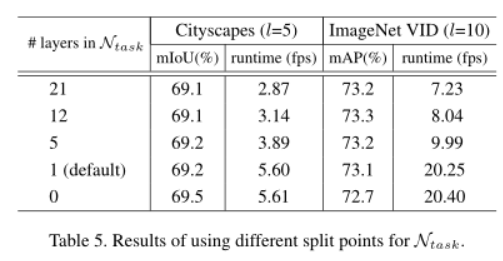
<原文>:在中间特征矩阵上应用随机初始化的1 × 1卷积层,得到(C+1)分图,其中C为类别数,1为背景类别。然后通过softmax层输出逐像素概率。因此,任务网络只有一个可学习的权重层。整体网络架构类似于DeepLab
task是一个分类器,作者采用了task=1*1conv+softmax,作者通过实验发现,有没有这个1*1conv效果差不多,使用0层基本上等同于使用1层,无论是精度还是速度。我们选择1层作为默认值,因为在特征传播之后会留下一些可调参数,这可能更通用。
# net_task = 1*1 Conv + softmax
# 论文里面说有没有这个1x1conv没什么区别,多加一个conv可以为以后需要时调参数,或者说更常规
self.net_task = nn.Conv2d(num_classes, num_classes, kernel_size=1, stride=1, padding=0)
f l o w n e t flownet flownet
使用的是flownet,这里我直接搬用flownet的api。
实验
根据数据集中视频帧率的不同,评估时cityscape分割的关键帧时长l默认为5,ImageNet VID检测的关键帧时长l默认为10
视频语义分割的评价指标使用 mIoU,在计算 mIoU 时,设置了三个传播距 {1,5,9} 来 刻画传播精度, 其中 {1,5,9} 分别表示当前帧与关键帧距离为相邻帧、隔了 4 帧和隔 8 帧。
不过验证时我采用的传播距离固定是5
-
训练时传播距离固定为5
-
训练时传播距离在1-5之间随机采样
-
在每个小批量中,随机抽取一对附近的视频帧 [ I k , I i ] , 0 ≤ i − k ≤ 9 [I_k, I_i] ,0≤i−k≤9 [Ik,Ii],0≤i−k≤9
| dis(传播距离) | 5 | random(1~5) | random(0~9) |
|---|---|---|---|
| mIOU | 60.98 | 60.91 | 60.90 |
可以看到,三者实际上是差不多的。
代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from mmseg.models import build_segmentor
from mmcv.utils import Config
from pspnet import pspnet_res101
from flownet import FlowNets
from warpnet import warp
class DFF(nn.Module):
def __init__(self, num_classes=19, weight_res101=None, weight_flownet=None):
super(DFF, self).__init__()
# reference branch选用pspnet_res50
# TODO(12.26):预训练pspnet-r50模型
self.net_feat = pspnet_res101()
# net_task = 1*1 Conv + softmax
# 论文里面说有没有这个1x1conv没什么区别,多加一个conv可以为以后需要时调参数,或者说更常规
self.net_task = nn.Conv2d(num_classes, num_classes, kernel_size=1, stride=1, padding=0)
# 光流场‘O()’选择FlowNets,预测的光流图
self.flownet = FlowNets()
# 用于传播关键帧到当前帧的可学习函数‘W()’,即将预测的光流图和关键帧的语义分割图进行融合
self.warp = warp()
# 权重初始化
# TODO:将res101 -> res50
self.weight_init(weight_res101, weight_flownet)
# 交叉熵损失函数
# FIXME:ignore_index=255?
self.criterion_semantic = nn.CrossEntropyLoss(ignore_index=255)
def weight_init(self, weight_res101, weight_flownet):
if weight_res101 is not None:
# 加载预训练权重
weight = torch.load(weight_res101, map_location='cpu')
weight = weight['state_dict']
# 加载预训练权重
self.net_feat.model.load_state_dict(weight, False)
# 冻结backdone的参数,仅调整decode_head的参数
self.net_feat.fix_backbone()
if weight_flownet is not None:
weight = torch.load(weight_flownet, map_location='cpu')
self.flownet.load_state_dict(weight, True)
# 为了使得网络中信息更好的流动,每一层输出的方差应该尽量相等
nn.init.xavier_normal_(self.net_task.weight)
self.net_task.bias.data.fill_(0)
print('pretrained weight loaded')
# ---------------------------------Input-----------------------------------------------
# gt = [batch_size,1,512,1024]
# im_flow_list = [batch_size,3,2,512,1024]
# im_seg_list = [batch_size,3,2,512,1024]
# -------------------------------------------------------------------------------------
def forward(self, im_seg_list, im_flow_list, gt=None):
# 输入的视频数据参数值,依次为 bastchsize, 通道, 关键帧间隔时间, 帧高度, 帧宽度
n, c, t, h, w = im_seg_list.shape
# 推理关键帧的语义结果
pred = self.net_feat(im_seg_list[:, :, 0, :, :])
# pred.shape = [1,19,64,128]
# 双线性插值等比放大2倍
pred = F.interpolate(pred, scale_factor=2, mode='bilinear', align_corners=False)
# pred.shape = [1,19.128.256]
# 计算关键帧的光流传播:首先将关键帧和当前帧的tensor在通道处堆叠,然后传入flownet,从而根据关键帧和当前帧计算光流,
flow = self.flownet(torch.cat([im_flow_list[:, :, -1, :, :], im_flow_list[:, :, 0, :, :]], dim=1))
# 将关键帧的pred传入warp(),然后和当前帧的flow继续一个W()函数,输出pred
pred_result = self.warp(pred, flow)
# 将经过warp输出的pred放到task网络里面
pred_result = self.net_task(pred_result)
# 双线性插值放大4倍
pred_result = F.interpolate(pred_result, scale_factor=4, mode='bilinear', align_corners=False)
# pred_result.shape = [1,19,512,1024]
if gt is not None:
loss = self.criterion_semantic(pred_result, gt)
# .unsqueeze(0) 表示,在第一个位置增加维度
loss = loss.unsqueeze(0)
return loss
else:
return pred_result
def evaluate(self, im_seg_list, im_flow_list):
out_list = []
t = im_seg_list.shape[2]
pred = self.net_feat(im_seg_list[:, :, 0, :, :])
# pred.shape = [1,19,64,128]
pred = F.interpolate(pred, scale_factor=2, mode='bilinear', align_corners=False)
# pred.shape = [1,19,128,256]
# 将经过net_feat的关键帧,再经过net_task处理
out = self.net_task(pred)
# 长宽均放大4倍
out = F.interpolate(out, scale_factor=4, mode='bilinear', align_corners=False)
# out.shape = [1,19,512,1024]
# 输入:out.shape = torch.Size([1, 19, 512, 1024])
out = torch.argmax(out, dim=1)
# 输出:out.shape = torch.Size([1, 512, 1024])
out_list.append(out)
# FIXME:eval时也不需要for循环吗?
# 当前帧和关键帧做一个光流估计
flow = self.flownet(torch.cat([im_flow_list[:, :, -1, :, :], im_flow_list[:, :, 0, :, :]], dim=1))
# 扔进‘W()’函数里
pred_result = self.warp(pred, flow)
# 对堆叠结果进行卷积
pred_result = self.net_task(pred_result)
pred_result = F.interpolate(pred_result, scale_factor=4, mode='bilinear', align_corners=False)
# 取最大的可能性结果
out = torch.argmax(pred_result, dim=1)
out_list.append(out)
return out_list
def set_train(self):
self.net_feat.eval()
self.net_feat.model.decode_head.conv_seg.train()
self.net_task.train()
self.flownet.train()
if __name__ == '__main__':
model = DFF(weight_res101=None, weight_flownet=None)
model.cuda().eval()
im_seg_list = torch.rand([1, 3, 5, 512, 1024]).cuda()
im_flow_list = torch.rand([1, 3, 5, 512, 1024]).cuda()
with torch.no_grad():
out_list = model.evaluate(im_seg_list, im_flow_list)
print(len(out_list), out_list[0].shape)