在前面的文章中已经详细介绍了在本机上安装YOLOv5的教程,安装YOLOv5可参考前面的文章YOLOv5训练自己的数据集(超详细)![]() https://blog.csdn.net/qq_40716944/article/details/118188085
https://blog.csdn.net/qq_40716944/article/details/118188085
目录
1、RepVGG原理
1.1 模型定义
1.2 为什么要用VGG式模型
1.3 结构重参数化让VGG再次伟大
2、YOLOv5中加入RepVGG模块
2.1 common.py配置
2.2 yolo.py配置
2.3 创建添加RepVGG模块的YOLOv5的yaml配置文件
3、实验效果对比
3.1 口罩检测数据集
3.2 效果对比
参考文章:
1、RepVGG原理
1.1 模型定义
我们所说的“VGG式”指的是:
- 没有任何分支结构。即通常所说的plain或feed-forward架构。
- 仅使用3x3卷积。
- 仅使用ReLU作为激活函数。
下面用一句话介绍RepVGG模型的基本架构:将20多层3x3卷积堆起来,分成5个stage,每个stage的第一层是stride=2的降采样,每个卷积层用ReLU作为激活函数。
再用一句话介绍RepVGG模型的详细结构:RepVGG-A的5个stage分别有[1, 2, 4, 14, 1]层,RepVGG-B的5个stage分别有[1, 4, 6, 16, 1]层,宽度是[64, 128, 256, 512]的若干倍。这里的倍数是随意指定的诸如1.5、2.5这样的“工整”的数字,没有经过细调。
再用一句话介绍训练设定:ImageNet上120 epochs,不用trick,甚至直接用PyTorch官方示例的训练代码就能训出来!
为什么要设计这种极简模型,这么简单的纯手工设计模型又是如何在ImageNet上达到SOTA水平的呢?
1.2 为什么要用VGG式模型
除了我们相信简单就是美以外,VGG式极简模型至少还有五大现实的优势(详见论文)。
- 3x3卷积非常快。在GPU上,3x3卷积的计算密度(理论运算量除以所用时间)可达1x1和5x5卷积的四倍。
- 单路架构非常快,因为并行度高。同样的计算量,“大而整”的运算效率远超“小而碎”的运算
- 单路架构省内存。例如,ResNet的shortcut虽然不占计算量,却增加了一倍的显存占用
- 单路架构灵活性更好,容易改变各层的宽度(如剪枝)。
- RepVGG主体部分只有一种算子:3x3卷积接ReLU。在设计专用芯片时,给定芯片尺寸或造价,我们可以集成海量的3x3卷积-ReLU计算单元来达到很高的效率。别忘了,单路架构省内存的特性也可以帮我们少做存储单元。
1.3 结构重参数化让VGG再次伟大
相比于各种多分支架构(如ResNet,Inception,DenseNet,各种NAS架构),近年来VGG式模型鲜有关注,主要自然是因为性能差。例如,有研究[1]认为,ResNet性能好的一种解释是ResNet的分支结构(shortcut)产生了一个大量子模型的隐式ensemble(因为每遇到一次分支,总的路径就变成两倍),单路架构显然不具备这种特点。
既然多分支架构是对训练有益的,而我们想要部署的模型是单路架构,我们提出解耦训练时和推理时架构。我们通常使用模型的方式是:
- 训练一个模型
- 部署这个模型
但在这里,我们提出一个新的做法:
- 训练一个多分支模型
- 将多分支模型等价转换为单路模型
- 部署单路模型
这样就可以同时利用多分支模型训练时的优势(性能高)和单路模型推理时的好处(速度快、省内存)。这里的关键显然在于这种多分支模型的构造形式和转换的方式。
我们的实现方式是在训练时,为每一个3x3卷积层添加平行的1x1卷积分支和恒等映射分支,构成一个RepVGG Block。这种设计是借鉴ResNet的做法,区别在于ResNet是每隔两层或三层加一分支,而我们是每层都加。
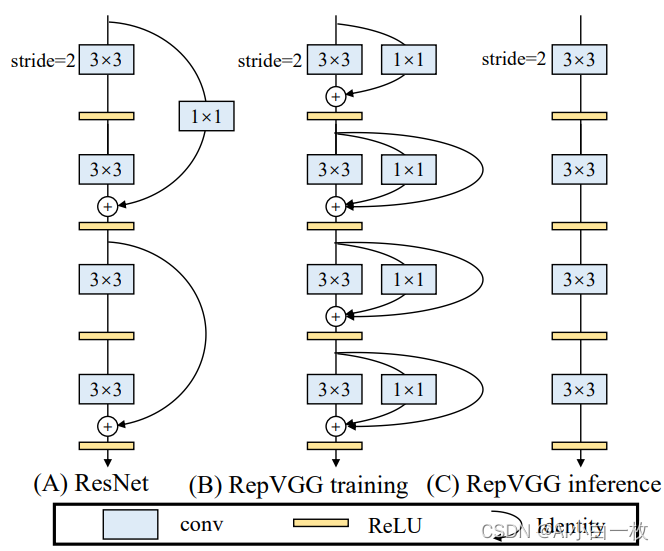
训练完成后,我们对模型做等价转换,得到部署模型。根据卷积的线性(具体来说是可加性),设三个3x3卷积核分别是W1,W2,W3,有 conv(x, W1) + conv(x, W2) + conv(x, W3) = conv(x, W1+W2+W3))。怎样利用这一原理将一个RepVGG Block转换为一个卷积呢?
其实非常简单,因为RepVGG Block中的1x1卷积是相当于一个特殊(卷积核中有很多0)的3x3卷积,而恒等映射是一个特殊(以单位矩阵为卷积核)的1x1卷积,因此也是一个特殊的3x3卷积!我们只需要:把identity转换为1x1卷积,只要构造出一个以单位矩阵为卷积核的1x1卷积即可;把1x1卷积等价转换为3x3卷积,只要用0填充即可。
下图描述了这一转换过程。在这一示例中,输入和输出通道都是2,故3x3卷积的参数是4个3x3矩阵,1x1卷积的参数是一个2x2矩阵。注意三个分支都有BN(batch normalization)层,其参数包括累积得到的均值及标准差和学得的缩放因子及bias。这并不会妨碍转换的可行性,因为推理时的卷积层和其后的BN层可以等价转换为一个带bias的卷积层(也就是通常所谓的“吸BN”)。
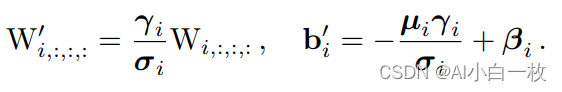
对三分支分别“BN”之后(注意恒等映射可以看成一个“卷积层”,其参数是一个2x2单位矩阵),将得到的1x1卷积核用0给pad成3x3。最后,三分支得到的卷积核和bias分别相加即可。这样,每个RepVGG Block转换前后的输出完全相同,因而训练好的模型可以等价转换为只有3x3卷积的单路模型。
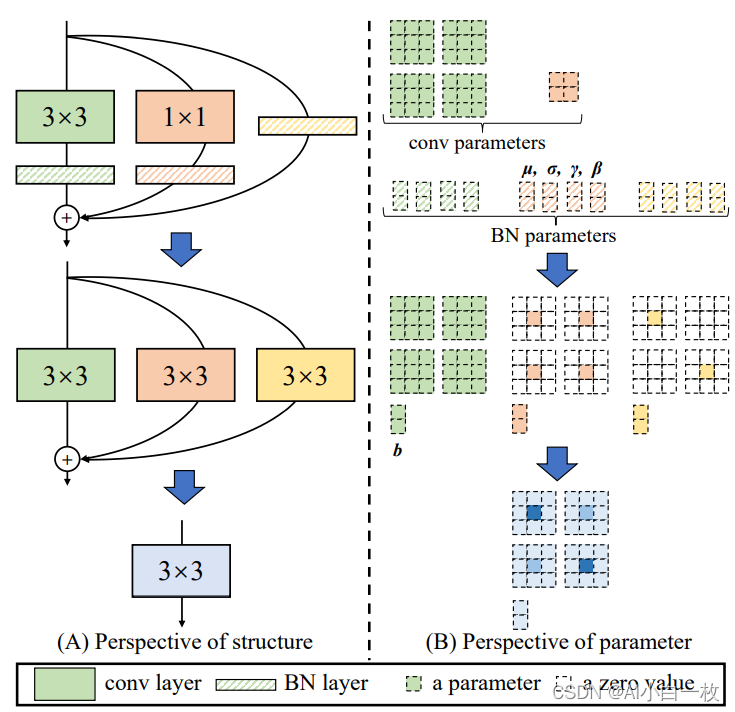
从这一转换过程中,我们看到了“结构重参数化”的实质:训练时的结构对应一组参数,推理时我们想要的结构对应另一组参数;只要能把前者的参数等价转换为后者,就可以将前者的结构等价转换为后者。
2、YOLOv5中加入RepVGG模块
2.1 common.py配置
在yolov5-6.1/models/common.py文件中增加以下模块,直接复制即可。
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups,
bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class RepVGGBlock(nn.Module):
'''RepVGGBlock is a basic rep-style block, including training and deploy status
This code is based on https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
'''
def __init__(self, in_channels, out_channels, kernel_size=3,
stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):
super(RepVGGBlock, self).__init__()
""" Initialization of the class.
Args:
in_channels (int): Number of channels in the input image
out_channels (int): Number of channels produced by the convolution
kernel_size (int or tuple): Size of the convolving kernel
stride (int or tuple, optional): Stride of the convolution. Default: 1
padding (int or tuple, optional): Zero-padding added to both sides of
the input. Default: 1
dilation (int or tuple, optional): Spacing between kernel elements. Default: 1
groups (int, optional): Number of blocked connections from input
channels to output channels. Default: 1
padding_mode (string, optional): Default: 'zeros'
deploy: Whether to be deploy status or training status. Default: False
use_se: Whether to use se. Default: False
"""
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
self.out_channels = out_channels
assert kernel_size == 3
assert padding == 1
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU()
if use_se:
raise NotImplementedError("se block not supported yet")
else:
self.se = nn.Identity()
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True, padding_mode=padding_mode)
else:
self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups)
def forward(self, inputs):
'''Forward process'''
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.se(self.rbr_reparam(inputs)))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels, out_channels=self.rbr_dense.conv.out_channels,
kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,
padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation, groups=self.rbr_dense.conv.groups, bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True2.2 yolo.py配置
然后找到yolov5-6.1/models//yolo.py文件下里的parse_model函数,将类名加入进去,如下所示。
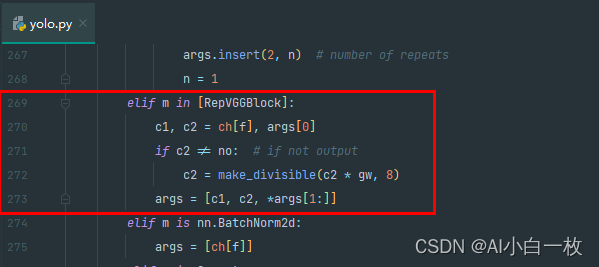
2.3 创建添加RepVGG模块的YOLOv5的yaml配置文件
完成上述两步操作之后,就可以在原有的YOLOv5的yaml配置文件的基础上进行修改,在适当位置添加RepVGG模块或者利用RepVGG模块替换原始yaml配置文件中的一些模块,这里为了能够快速的训练模型,选择YOLOv5s模型进行修改,修改后的yolov5s_repvgg.yaml文件内容如下所示。
# parameters
nc: 2 # number of classes
depth_multiple: 1 # model depth multiple
width_multiple: 1 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, RepVGGBlock, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, RepVGGBlock, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, RepVGGBlock, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, RepVGGBlock, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
3、实验效果对比
3.1 口罩检测数据集
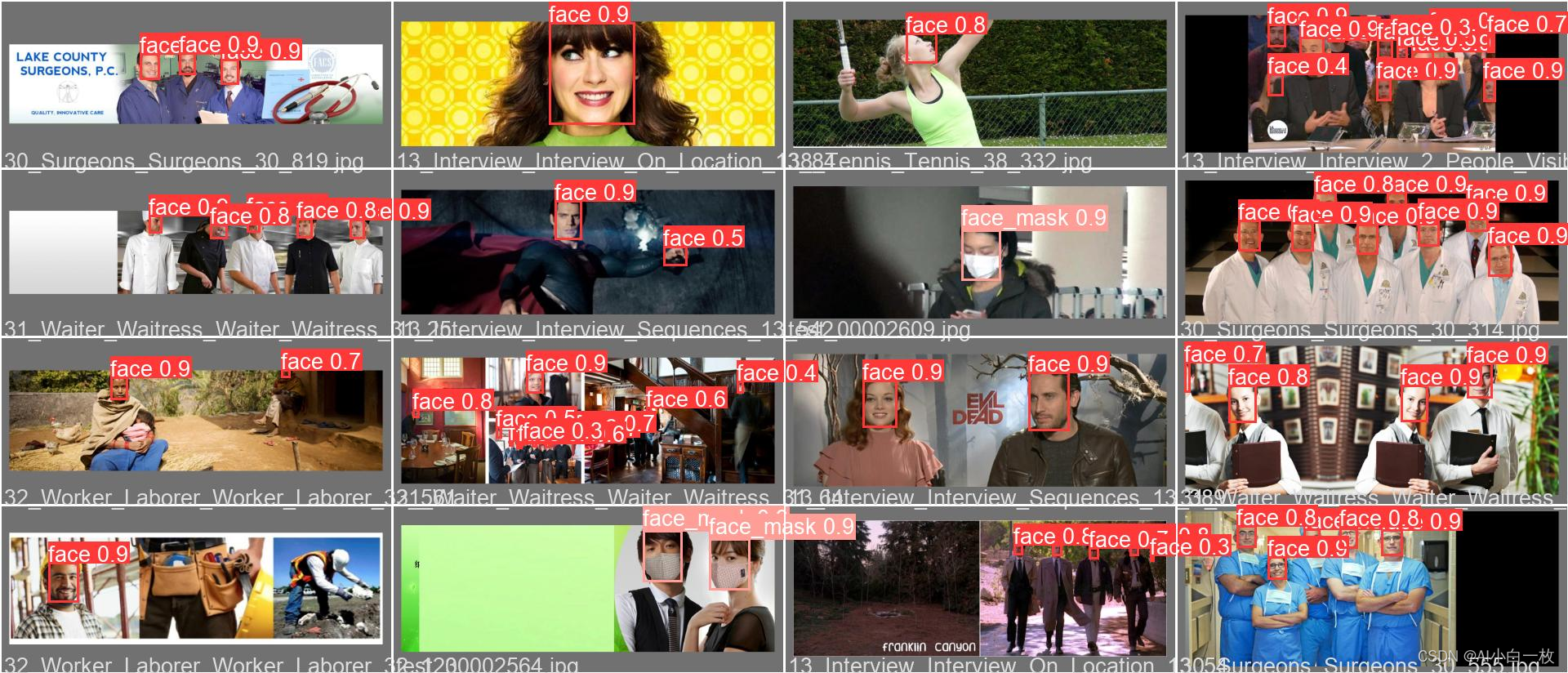
前期收集了口罩检测识别数据集,主要是未佩戴口罩和佩戴口罩两个类别,图片总数在10000张左右,部分图片如下所示。

3.2 效果对比
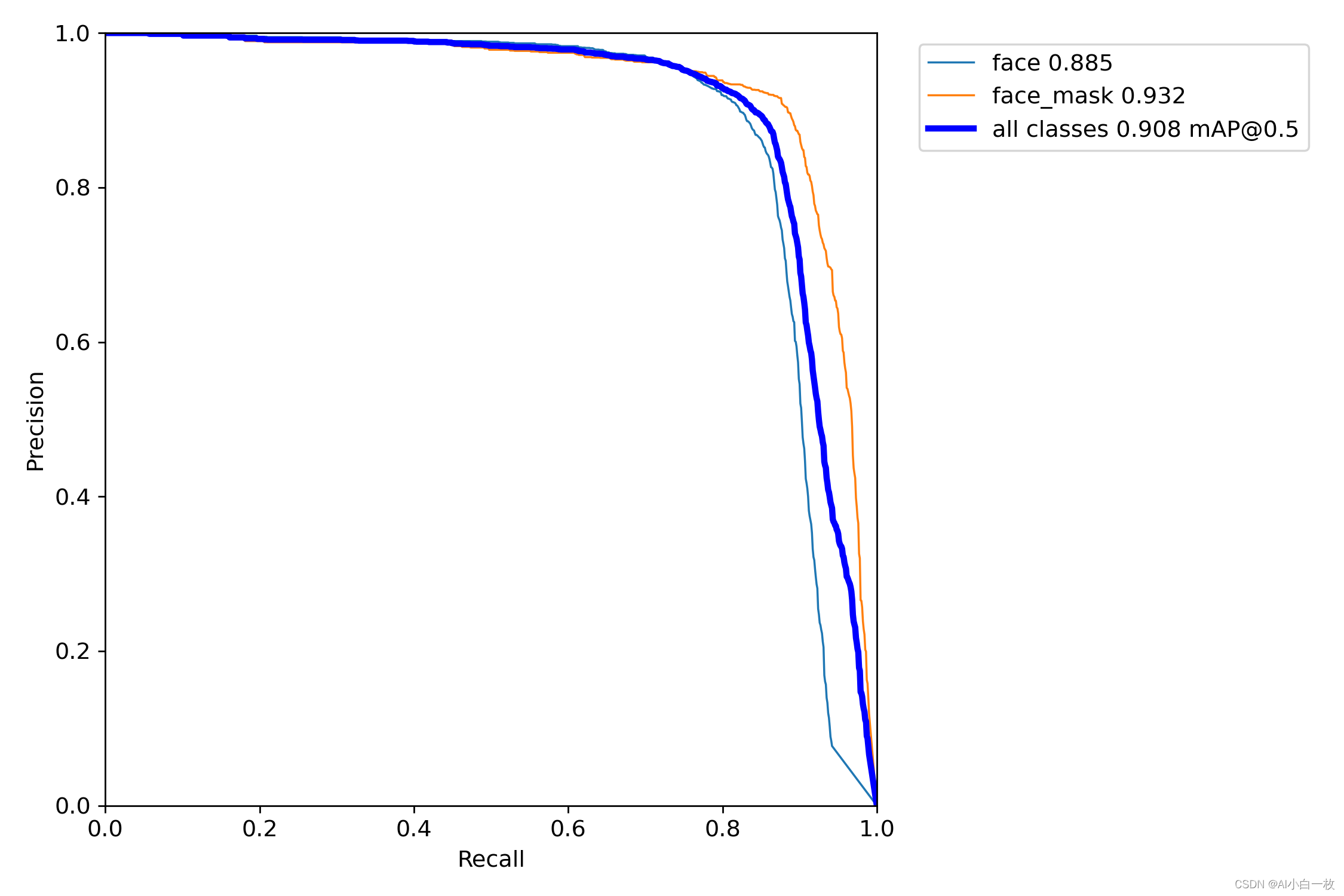
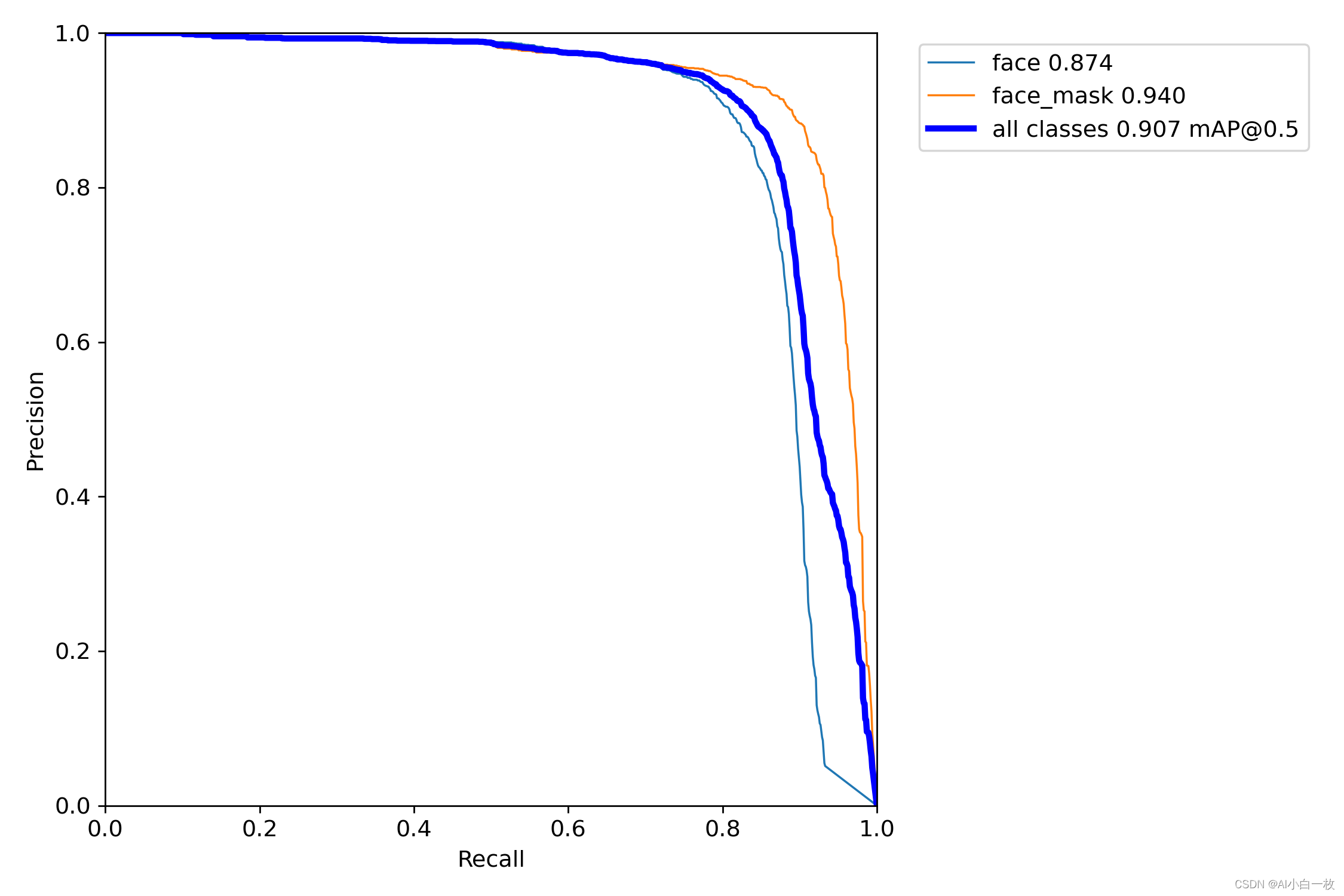
为了对比加入RepVGG模块后YOLOv5算法的效果,选择同样的数据集和实验参数进行算法模型训练和测试,实验参数设置如下。
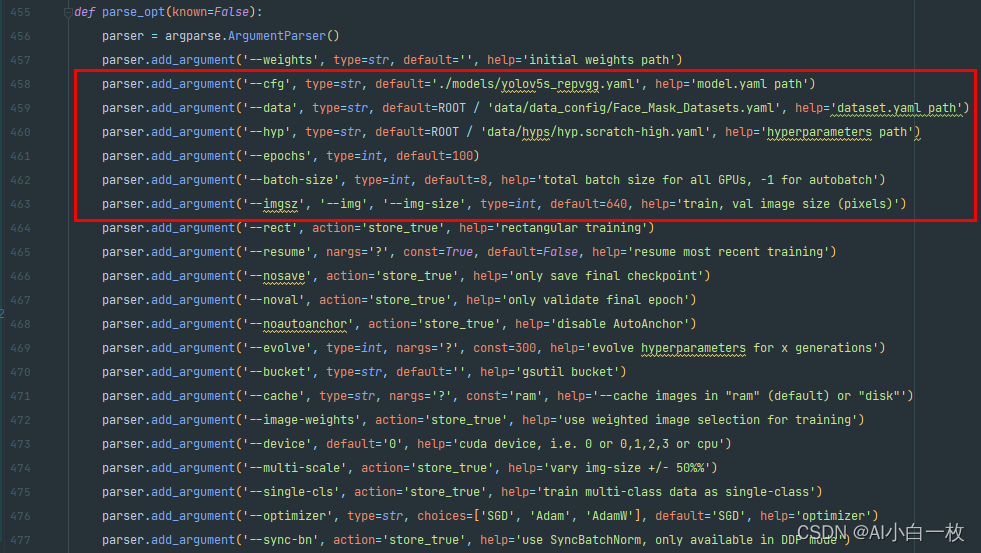
在同样的训练参数和训练集的情况,得到训练后的模型,然后在同样的测试集上进行测试验证,测试集上的测试效果如下表所示,可以看出加入RepVGG模块后的YOLOv5s的效果与原始YOLOv5s的效果基本一致。
| face | face_mask | all | |
| yolov5s | 0.885 | 0.932 | 0.908 |
| yolov5s_repvgg | 0.874 | 0.940 | 0.907 |
对于RepVGG这块有疑问的,可以在评论区提出,或者私信博主。
参考文章:
1、RepVGG:极简架构,SOTA性能,让VGG式模型再次伟大(CVPR-2021) - 知乎
2、https://github.com/ultralytics/yolov5