摘要:
训练数据决定了基础大模型可用的理论信息,模型架构和训练目标决定了可以提取多少信息,计算机系统决定了实际可实现的内容。在数据和模型大小方面,系统是扩展的关键瓶颈,这两者似乎都可以可靠地跟踪能力的改进。在时间和成本方面,为了确保我们能够有效地训练下一代基础大模型,我们将需要协同设计算法、模型、软件和硬件。这种协同设计已经开始以各种形式发生,从精心调整的并行策略到新的架构,如基于检索和混合专家模型。除了训练之外,我们还考虑在基础模型之上部署应用程序所需的条件。
计算机系统是开发基础大模型的最大瓶颈之一。基础大模型通常太大,无法容纳单个加速器(例如,GPU)的主内存,并且需要大量的计算来训练(例如,对于GPT-3, > 1000 petaFLOP/s-days )。此外,随着时间的推移,这些模型可能会变得更大:例如,最先进的语言模型的计算和内存需求在过去三年中增长了三个数量级,并且预计将继续以远快于硬件能力的速度增长(图1)。一旦经过训练,这些大型模型执行推理的成本很高,并且难以在生产应用程序中进行调试、监控和维护。我们认为,基础模型的性能和可用性的进一步进步将需要跨算法、模型、软件和硬件系统进行仔细的协同设计,以及用于编程和部署ML应用程序的新接口。在本节中,我们讨论了在开发和生产大规模基础模型时的关键计算机系统挑战。
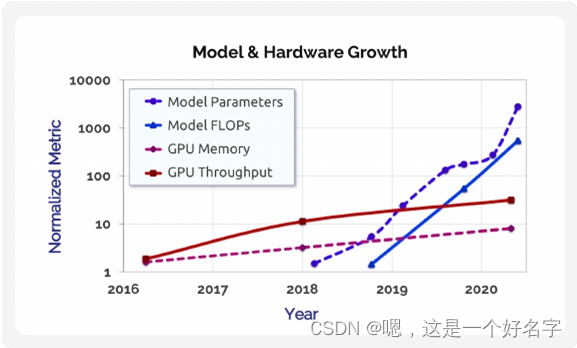
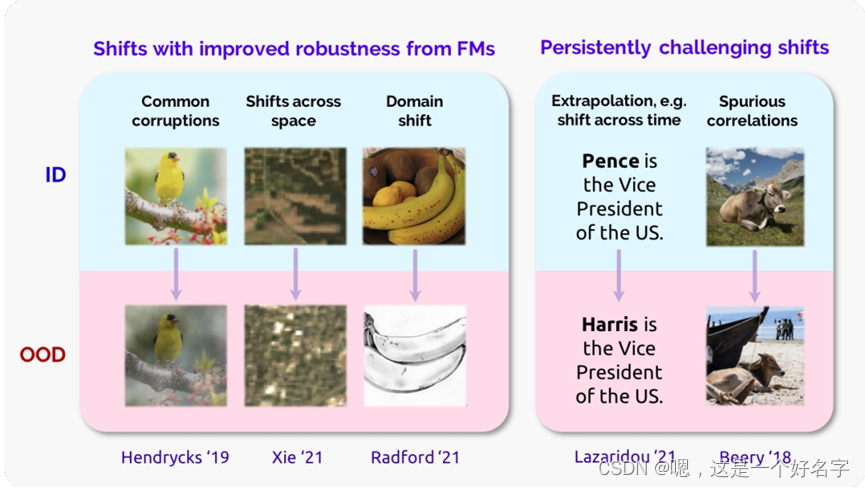
图1所示。图中显示了基于transformer的语言模型的参数数和训练操作数(FLOPs)的增长(蓝色表示),以及NVIDIA P100、V100和A100 gpu的内存容量和峰值设备吞吐量(红色表示)随时间的增长。最先进的语言模型的增长率(每条线的斜率)(大约每年10倍)远远超过硬件计算能力的增长率(大约4年10倍),这激发了对大量加速器之间并行性的需求,以及算法、模型、软件和硬件的协同设计,以推动进一步的进步。参数数量和训练操作次数从相关论文中获得,内存容量和峰值吞吐量从GPU规格表中获得。
1. 通过协同设计提高性能
如今,训练大规模基础模型通常需要定制软件系统,如威震天、深速或Mesh Transformer JAX ,建立在PyTorch、TensorFlow和JAX等标准框架之上。这些软件系统依赖于跨堆栈的许多创新来大规模高效地训练模型:新的并行化维度,如管道parallelism 在保持设备繁忙的同时限制通信,状态分片优化器减少内存使用,即时(JIT)编译器优化计算图,以及优化库如cuDNN和NCCL 。威震天和深速在特定规模上是有效的;例如,威震天可以在具有1万亿个参数的模型上使用大约3000个GPU提取高达现代硬件理论峰值吞吐量的52% 。然而,扩展到具有更多GPU的更大模型仍然具有挑战性,因为现有的并行化策略在更大的GPU数量下会崩溃。数据并行性受限于批大小,管道并行性受限于模型中的层数,以及单个服务器上GPU数量的张量模型并行度。
虽然我们将继续从新硬件中实现性能提升,但大型模型资源需求的增长远远超过了几代硬件的改进。为了促进模型容量的下一个重大飞跃,并使模型质量的进步民主化,协同设计训练算法、模型、软件和硬件将变得越来越重要,因为许多显著提高性能的途径会改变训练计算的语义。例如,以较低精度(如fp16)执行操作可以帮助提高现代硬件的吞吐量(例如,V100和A100 GPU具有用于低精度矩阵乘法的专用张量核心单元),但也会影响优化过程的数值。类似地,利用权值稀疏性可以显著提高训练和推理时间只对模型中的非零进行数学运算,但需要不同的训练算法。协同设计的其他例子包括更有效地映射到硬件的模型架构,新颖的代币化替代方案,专门架构的硬件训练平台,以及放宽权重更新语义的分布式并行化策略。
案例研究:有效的知识表示
作为成功协同设计的具体案例研究,基于检索的模型,如REALM、RAG、ColBERT-QA和RETRO 采用了与简单增加模型参数数量不同的模型设计方法。基于检索的模型不是试图将越来越大的数据集中的隐性知识直接积累到具有数十亿个参数的DNN模型中(如GPT- 3),而是以文本段落的形式存储模型参数之外的知识,以密集的向量表示捕获段落内的知识。然后,这些模型使用可扩展的top-𝑘搜索机制来提取与每个输入相关的知识,同时保持DNN模型本身较小。这种设计提高了模型在生产中的计算效率和可维护性:例如,开发人员可以通过替换文本段落来更新模型的知识,而无需重新训练大型DNN。
基于检索的模型通过利用几个新的跨职能思想取得了有希望的初步结果,包括在训练期间通过检索器反向传播损失(这需要通过由数百万个段落组成的知识存储近似梯度)和建模查询和段落之间的细粒度交互(这需要将计算分解为向量级最近邻搜索操作)。这些技术允许基于检索的模型是准确的和高效,但需要的功能不容易被流行的ML框架和最近邻指数(如FAISS)支持。
2. 自动优化
系统中的另一个重要挑战是自动化跨算法、模型、软件和硬件的优化应用。虽然许多优化和并行化策略是互补的,但识别最有效的优化组合是具有挑战性的,因为联合搜索空间以组合方式增长,优化以非平凡的方式相互作用。基础模型增加了对自动优化的需求,因为在数千个gpu的规模下,手动实验非常昂贵且耗时。
该领域最近的工作集中在以语义保持优化为目标的系统上。特别是,已经提出了自动发现数学等效图替换的系统,通过高级api和低级编译器促进算子图的分布式执行,以及混合配送策略的自动化选择。这些系统已经帮助在工业中部署了许多基础模型。
不幸的是,当组合语义改变优化时,自动优化变得更加困难,因为通常不清楚如何联合建模这些技术的统计影响(例如,需要多少训练迭代才能达到特定的精度?)。因此,我们将需要新的软件工具、库和编译器来自动识别针对时间-精度等综合指标的优化组合。构建这样的工具需要系统和机器学习专家之间的紧密协作。
3. 执行和编程模型
基础模型独特的多任务性质提供了将训练和推理成本分摊到许多应用程序上的机会。特别是,适应等范式意味着在模型实例之间有更多的共享。例如,来自同一预训练模型的两个经过前缀调优的模型可以共享相同的模型“干”,从而减少了存储占用(共享的干只需要存储一次),同时也使得跨前缀调优模型共享和批处理执行成为可能。因此,所使用的特定适应机制为系统优化提供了信息。
应该使用什么编程接口来指定从相同的预训练模型(例如,模型)派生的各种适应模型,这是一个悬而未决的问题 (𝑌和 𝑍是从相同的预训练模型𝑋衍生出来), 或者两个模型的各个组成部分共享参数(例如,两个模型𝐴和𝐵具备相同的网络层)。Ludwig和PyTorch的Module提供了在模型内组合功能的简单方法,但目前没有系统支持跨模型依赖关系。让用户有机会提供注释将允许训练和推理系统更有效地优化和编排计算;如果没有这样的注释,系统将无法看到哪些计算和参数可以跨模型实例共享。模型的“适应历史”(这个特定的模型是从什么模型改编的)也可以用于调试:一个被改编的模型在特定类型的输入上的错误可能源于预训练的模型,指出预训练过程与适应过程中的问题。像PyTorch这样的框架,以及训练基础模型,如HuggingFace Transformers,不允许指定整个模型实例的细粒度血统信息。
构建和维护一个由数千个加速器组成的集群也需要巨大的努力。新的培训范式如Learning@Home 探索利用互联网上的志愿者计算来协同训练基础模型。这种全新的执行模型可以降低任何一个实体的培训成本,但需要跨多个不同领域的协作,如安全性(确保恶意志愿者不能显著改变培训过程)、分布式系统(在志愿者退出时处理容错问题)和众包。
4. 基础模型的产品化
随着社区继续推动基础模型的能力,实现其潜力将需要解决与在生产中部署这些资源密集型模型相关的挑战。这些挑战包括以严格的延迟目标执行模型推理,并确保以自动化的方式监控模型和数据。
对于具有严格成本和延迟约束的应用,蒸馏等模型压缩技术,量化,修剪和稀疏性可以通过转换更大的模型来获得所需的推理时间属性来帮助部署。这些技术最初是为低内存环境(例如,移动电话)中的较小模型(例如,BERT-L)设计的,但现在需要处理数据中心部署中现代基础模型的极端规模。像张量模型并行化(tensor model parallelism) 这样传统上用于训练的并行化技术,也可能有助于减少推理延迟,并且还可以跨gpu提供额外的内存容量来拟合模型的参数。
除了这些实际约束外,基础模型的大小和复杂性以及用于训练它们的数据集的增加也给模型和数据集生命周期管理带来了新的挑战。由于具有大量参数的模型很难由人类手动检查,因此我们需要更好的系统来实现自动数据集管理和模型质量保证。行为测试和模型断言等技术通过为最终应用程序中部署的模型提供类似于单元测试、运行时监控(以测试时间断言的形式)和持续的模型改进(随着新输入的到来)来简化生产中的模型维护。这些工具可以帮助解决公平性和偏见问题,并减少模型错误预测。