一.编码
有序集合的编码可以是ziplist或者skiplist。
ziplist编码的有序集合对象使用压缩列表作为底层实现,每一个集合元素使用紧挨在一起的两个压缩列表节点来保存。第一个节点保存元素的成员(member),而第二个元素则保存元素的分值(score)。
127.0.0.1:6379> zadd price 8.5 apple 5.0 banana 6.0 cherry
(integer) 3- 使用ziplist压缩列表编码
如果price键的值对象使用的是ziplist编码,那么这个值的对象和压缩列表如下图:
注意:Redis5.0版本后使用listpack替代了ziplist Redis哈希对象(listpack介绍)-CSDN博客

- 使用skiplist编码
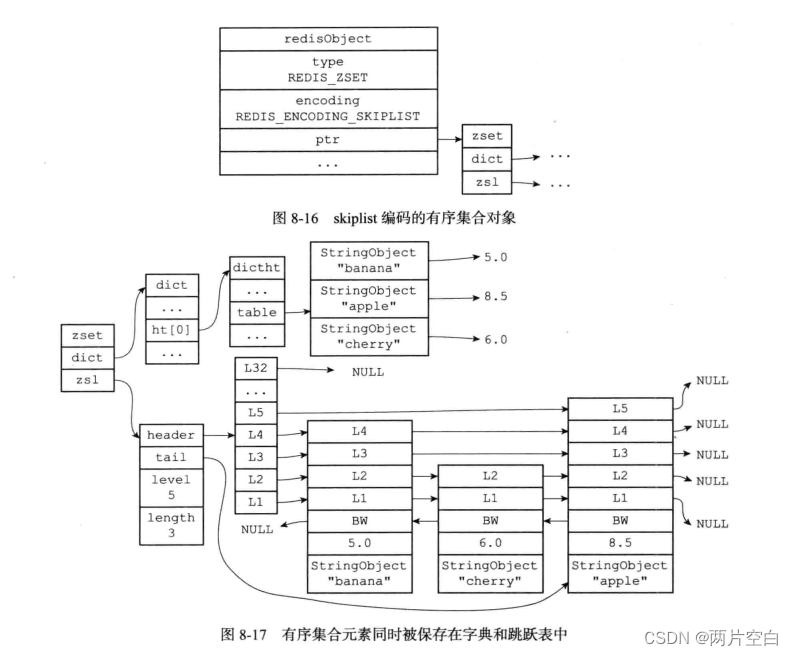
skiplist编码的有序集合对象使用zset结构作为底层实现,一个zset结构同时包含一个字典和一个跳跃表。字典和跳跃表都会使用到。
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;zset结构中的zsl跳跃表按分值从小到大保存了所有集合元素,每一个跳跃表节点保存了一个集合元素:跳跃表的节点的object属性保存了元素的成员,而跳跃表节点的score属性则保存了元素的分值。通过这个跳跃表,程序程序可以对有序集合进行范围查询操作,比如:zrank,zrange等命令就是基于跳跃表的API实现的。
而zset结构中的dict字典为有序集合创建了一个成员到分值的映射,字典中的每一个键值对都保存了一个集合元素:字典中的键保存了元素成员,而字典中的值保存了元素的分值。通过这个字典,程序可以通过O(1)复杂度查找给定成员的分值,zscore命令就是根据这一特性实现的。而很多其他有序集合的命令都是通过这一特性实现的。
有序集合每一个成员都是一个字符串对象,而每一个元素的分值都是一个double类型的浮点数。
虽然zset结构同时使用跳跃表和字典来保存有序集合元素,但这两种数据结构都通过指针来共享相同元素的成员和分值,所以同时使用跳跃表和字典老保存有序集合元素不会产生任何重复成员和分值,也不会因此而浪费额外的内存。
为什么有序集合需要同时使用跳跃表和字典来实现?
在理论上,有序集合可以单独使用字典或者跳跃表来实现。但是,无论是单独使用跳跃表还是字典,在性能上会比同时使用字典和跳跃表有所降低。
如果只使用字典来实现有序集合,虽然可以在O(1)时间复杂度内找到对应成员的分值。但是,因为字典是无序的方式来保存元素。所以在内存执行范围型操作——比如:zrank,zrange等命令时,需要先将字典中的元素按照分值进行排序,完成排序至少需要O(NlogN)时间复杂度,以及额外的O(N)内存空间来保存排序好的元素。
如果只使用跳跃表来实现有序集合,那么跳跃表执行范围型操作的所有优点会保存下来,但是,根据成员查找分值的操作,会从O(1)的时间时间复杂度提高到O(logN)。
所以为了提高效率,有序集合同时使用了跳跃表和字典两种数据结构了实现。
如果上面price键创建使用的时skiplist编码的有序集合对象,那么这个有序结合对象和zset将会如下图所示:
注意:下图为了展示清楚,重复展示了各个成员和分值,但是实际中,字典和跳跃表会共享元素和分值。
二.编码转换
当有序集合同时满足下面两个条件时,对象使用ziplist编码,redis5.0之后使用listpack编码。
- 有序集合保存的元素个数小于128个。
- 有序集合保存的所有元素成员的长度小于64字节。
当面两个的上限值可以通过配置,zset-max-ziplist-entries选项和zset-max-ziplist-value选项来修改。
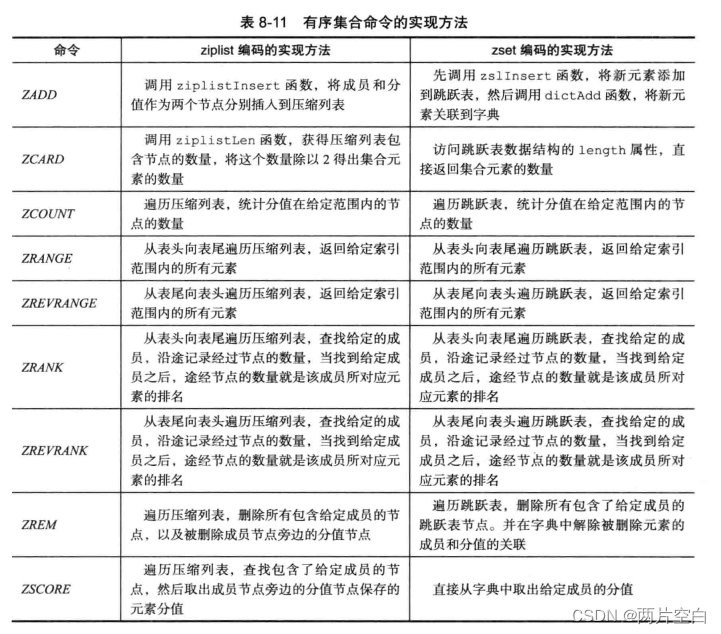
三. 有序集合命令的实现







![[香橙派]Orange pi zero 3命令行配网方法——建立ssh连接——Ubuntu配置WIFI自动连接](https://img-blog.csdnimg.cn/direct/166ea3849fb14a948ea511facbc774de.png)