TensorFlow2的高层封装
- 使用Tensorflow2构建模型的3种方法
- 使用Sequential按层顺序构建模型
- 使用函数式API创建任意结构的模型
- 使用Model子类化创建自定义模型
- 训练模型的3种方法
- 内置fit方法
- 内置train_on_batch方法
- 自定义训练循环
- 使用GPU训练模型
- 使用单GPU训练模型
- 使用多GPU训练模型
- 使用TPU训练模型
- 使用Tensorflow-serving部署模型
- Tensorflow serving模型部署概述
- 准备protobuf模型文件
- 安装Tensorflow serving
- 启动Tensorflow serving服务
- 向API服务发送请求
- 使用Spark-scala调用Tensorflow2训练好的模型
- Spark(scala)调用Tensorflow模型概述
- 准备protobuf模型文件
- 创建Spark(scala)项目,并添加java版本的Tensorflow对应jar包
- 在Spark(scala)项目中的driver端加载Tensorflow模型
- 在Spark(scala)项目中通过RDD在executor上加载Tensorflow模型
- 在Spark(scala)项目中通过DataFrame在executor上加载Tensorflow模型
- 参考资料
TensorFlow2的高层封装模块主要是
tensorflow.keras.models。因此本文主要介绍tf.keras.models相关的内容,包括:
- 模型的构建(Sequential、functional API、Model子类化)
- 模型的训练(内置fit方法,内置train_on_batch方法,自定义训练循环、单GPU训练模型、多GPU训练模型、TPU训练模型)
- 模型的部署(Tensorflow serving部署模型,使用spark(scala)调用tensorflow模型)
使用Tensorflow2构建模型的3种方法
有三种方法可用于构建模型,包括:①使用Sequential按层顺序构建模型,②使用函数式API构建任意结构的模型,③继承Model基类构建自定义模型。
- 对于顺序结构的模型,推荐使用Sequential方法构建;
- 如果模型有多输入或者多输出,或者模型需要共享权重,或者模型具有残差连接等非顺序结构,推荐使用函数式API方式进行构建;
- 如果没有特定需要,避免使用Model子类化的方式构建模型,这种方式虽然灵活性很好,但是容易出错。
以IMDB电影评论的分类问题为例:
数据准备
import numpy as np
import pandas as pd
import tensorflow as tf
from tqdm import tqdm
from tensorflow.keras import *
train_token_path = "../DemoData/imdb/train_token.csv"
test_token_path = "../DemoData/imdb/test_token.csv"
MAX_WORDS = 10000 # 这里进考虑数据集种的前10000个单词
MAX_LEN = 200 # 窗口大小维200个单词
BATCH_SIZE = 20
# 构建数据管道
def parse_line(line):
t = tf.strings.split(line, "\t")
label = tf.reshape(tf.cast(tf.strings.to_number(t[0]), tf.int32), (-1,))
features = tf.cast(tf.strings.to_number(tf.strings.split(t[1], " ")), tf.int32)
return features, label
# 训练数据
ds_train = tf.data.TextLineDataset(filenames=[train_token_path]).map(parse_line,
num_parallel_calls=tf.data.experimental.AUTOTUNE).shuffle(
buffer_size=1000).batch(BATCH_SIZE).prefetch(tf.data.experimental.AUTOTUNE)
# 测试数据
ds_test = tf.data.TextLineDataset(filenames=[test_token_path]).map(parse_line,
num_parallel_calls=tf.data.experimental.AUTOTUNE).shuffle(
buffer_size=1000).batch(BATCH_SIZE).prefetch(tf.data.experimental.AUTOTUNE)
使用Sequential按层顺序构建模型
tf.keras.backend.clear_session()
model = models.Sequential()
model.add(layers.Embedding(MAX_WORDS, 7, input_length=MAX_LEN))
model.add(layers.Conv1D(filters=64, kernel_size=5, activation='relu'))
model.add(layers.MaxPool1D(2))
model.add(layers.Conv1D(filters = 32,kernel_size = 3,activation = "relu"))
model.add(layers.MaxPool1D(2))
model.add(layers.Flatten())
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='Nadam', loss='binary_crossentropy', metrics=['accuracy', 'AUC'])
model.summary()
'''
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 200, 7) 70000
conv1d (Conv1D) (None, 196, 64) 2304
max_pooling1d (MaxPooling1D (None, 98, 64) 0
)
conv1d_1 (Conv1D) (None, 96, 32) 6176
max_pooling1d_1 (MaxPooling (None, 48, 32) 0
1D)
flatten (Flatten) (None, 1536) 0
dense (Dense) (None, 1) 1537
=================================================================
Total params: 80,017
Trainable params: 80,017
Non-trainable params: 0
_________________________________________________________________
'''
模型结构图如下:
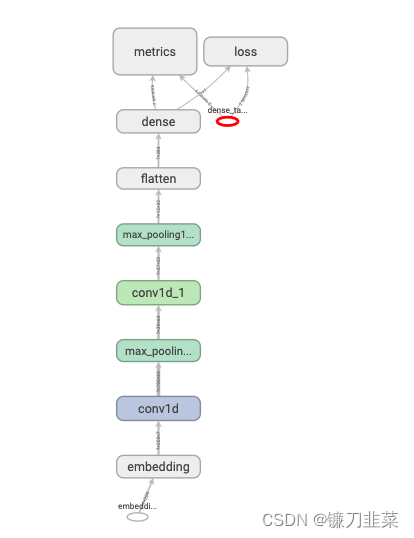
训练模型
import datetime
baselogger = callbacks.BaseLogger(stateful_metrics=["AUC"])
logdir = "../Results/keras_model/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
history = model.fit(ds_train, validation_data=ds_test, epochs=6, callbacks=[baselogger,tensorboard_callback])
出现了kernel重启的情况,如下:
2022-12-30 12:26:53.684641: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-12-30 12:26:54.144462: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1532] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 3985 MB memory: -> device: 0, name: NVIDIA GeForce GTX 1660 Ti, pci bus id: 0000:01:00.0, compute capability: 7.5
2022-12-30 12:26:56.499746: I tensorflow/stream_executor/cuda/cuda_dnn.cc:384] Loaded cuDNN version 8500
[I 12:27:08.460 NotebookApp] KernelRestarter: restarting kernel (1/5), keep random ports
WARNING:root:kernel a0474c58-2973-45c0-8cc1-55db4570dffa restarted
[W 12:27:28.252 NotebookApp] Timeout waiting for kernel_info_reply: e42eccc1-72c7-4743-ad76-7815592caa99
训练结果可视化
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
import matplotlib.pyplot as plt
def plot_metric(history, metric):
train_metrics = history.history[metric]
val_metrics = history.history['val_' + metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation ' + metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_" + metric, 'val_' + metric])
plt.show()
plot_metric(history,"AUC")
使用函数式API创建任意结构的模型
tf.keras.backend.clear_session()
inputs = layers.Input(shape=[MAX_LEN])
X = layers.Embedding(MAX_WORDS, 7)(inputs)
branch1 = layers.SeparableConv1D(64, 3, activation='relu')(X)
branch1 = layers.MaxPool1D(3)(branch1)
branch1 = layers.SeparableConv1D(32, 3, activation='relu')(X)
branch1 = layers.GlobalMaxPool1D()(branch1)
branch2 = layers.SeparableConv1D(64, 5, activation='relu')(X)
branch2 = layers.MaxPool1D(5)(branch2)
branch2 = layers.SeparableConv1D(32,5,activation="relu")(branch2)
branch2 = layers.GlobalMaxPool1D()(branch2)
branch3 = layers.SeparableConv1D(64, 7, activation='relu')(X)
branch3 = layers.MaxPool1D(7)(branch3)
branch3 = layers.SeparableConv1D(32,7,activation="relu")(branch3)
branch3 = layers.GlobalMaxPool1D()(branch3)
concat = layers.Concatenate()([branch1, branch2, branch3])
outputs = layers.Dense(1, activation='sigmoid')(concat)
model = models.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer='Nadam', loss='binary_crossentropy', metrics=['accuracy', 'AUC'])
model.summary()
模型结构图如下:
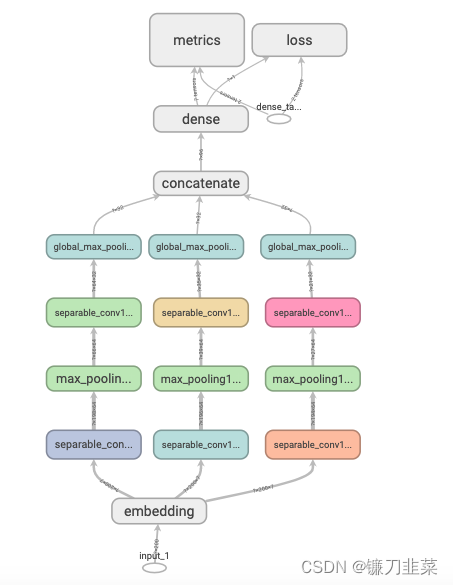
使用Model子类化创建自定义模型
先自定义一个残差模块,作为自定义的Layer:
class ResBlock(layers.Layer):
def __init__(self, kernel_size, **kwargs):
super(ResBlock, self).__init__(**kwargs)
self.kernel_size = kernel_size
def build(self, input_shape):
self.conv1 = layers.Conv1D(filters=64, kernel_size=self.kernel_size, activation='relu', padding='same')
self.conv2 = layers.Conv1D(filters=32, kernel_size=self.kernel_size, activation='relu', padding='same')
self.conv3 = layers.Conv1D(filters=input_shape[-1], kernel_size=self.kernel_size, activation='relu', padding='same')
self.maxpool = layers.MaxPool1D(2)
super(ResBlock, self).build(input_shape) # 相当于设置self.built=True
def call(self, inputs):
x = self.conv1(inputs)
x = self.conv2(x)
x = self.conv3(x)
x = layers.Add()([inputs, x])
x = self.maxpool(x)
return x
# 如果要让自定义的Layer通过Functional API组合成模型时可以序列化,需要自定义get_config
def get_config(self):
config = super(ResBlock, self).get_config()
config.update({'kernel_size':self.kernel_size})
return config
# 测试ResBlock
resblock = ResBlock(kernel_size=3)
resblock.build(input_shape=(None, 200, 7))
resblock.compute_output_shape(input_shape=(None, 200, 7))
'''
TensorShape([None, 100, 7])
'''
自定义模型,实际上也可以使用Sequential或者Functional API:
class ImdbModel(models.Model):
def __init__(self):
super(ImdbModel, self).__init__()
def build(self, input_shape):
self.embedding = layers.Embedding(MAX_WORDS, 7)
self.block1 = ResBlock(7)
self.block2 = ResBlock(5)
self.dense = layers.Dense(1, activation='sigmoid')
super(ImdbModel, self).build(input_shape)
def call(self, x):
x = self.embedding(x)
x = self.block1(x)
x = self.block2(x)
x = layers.Flatten()(x)
x = self.dense(x)
return x
tf.keras.backend.clear_session()
model = ImdbModel()
model.build(input_shape=(None, 200))
model.summary()
model.compile(optimizer='Nadam',loss='binary_crossentropy',metrics=['accuracy','AUC'])
'''
Model: "imdb_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) multiple 70000
res_block (ResBlock) multiple 19143
res_block_1 (ResBlock) multiple 13703
dense (Dense) multiple 351
=================================================================
Total params: 103,197
Trainable params: 103,197
Non-trainable params: 0
_________________________________________________________________
'''
模型结构图:
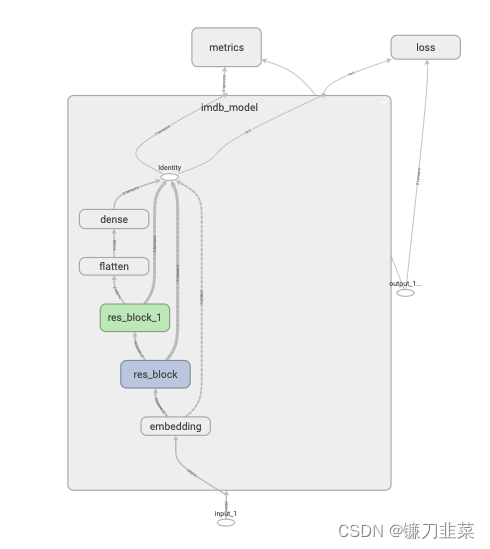
训练模型的3种方法
Tensorflow2中训练模型主要有①内置fit方法,②内置train_on_batch方法以及③自定义训练循环。需要注意的是:fit_generator方法在tf.keras中不推荐使用,其功能已经包含在fit方法中。
数据准备
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras import *
MAX_LEN = 300
BATCH_SIZE = 32
(x_train, y_train), (x_test, y_test) = datasets.reuters.load_data()
x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=MAX_LEN)
x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=MAX_LEN)
MAX_WORDS = x_train.max() + 1
CAT_NUM = y_train.max() + 1
ds_train = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(buffer_size=1000).batch(BATCH_SIZE).prefetch(
tf.data.experimental.AUTOTUNE).cache()
ds_test = tf.data.Dataset.from_tensor_slices((x_test, y_test)).shuffle(buffer_size=1000).batch(BATCH_SIZE).prefetch(
tf.data.experimental.AUTOTUNE).cache()
数据下载失败解决办法:
手动下载数据集(推荐),访问百度云:百度网盘(提取码:3a2u)
只需要将这些文件放到指定位置下就可以调用它们:
指定位置:C:\Users\username\.keras\datasets\ or C:\Users\Administrator\.keras\datasets
内置fit方法
Tensorflow2内置的fit方法支持对numpy array, tf.data.Dataset以及python generator等数据类型进行训练,并且可以通过设置回调函数实现对训练过程的复杂控制逻辑。
创建模型
tf.keras.backend.clear_session()
def create_model():
model = models.Sequential()
model.add(layers.Embedding(MAX_WORDS, 7, input_length=MAX_LEN))
model.add(layers.Conv1D(filters=64, kernel_size=5, activation="relu"))
model.add(layers.MaxPool1D(2))
model.add(layers.Conv1D(filters=32, kernel_size=3, activation="relu"))
model.add(layers.MaxPool1D(2))
model.add(layers.Flatten())
model.add(layers.Dense(CAT_NUM, activation="softmax"))
return model
def compile_model(model):
model.compile(optimizer=optimizers.Nadam(),
loss=losses.SparseCategoricalCrossentropy(),
metrics=[metrics.SparseCategoricalAccuracy(), metrics.SparseTopKCategoricalAccuracy(5)])
return model
model = create_model()
model.summary()
model = compile_model(model)
使用内置fit方法:
history = model.fit(ds_train,validation_data = ds_test,epochs = 10)
内置train_on_batch方法
tf.keras.backend.clear_session()
def create_model():
model = models.Sequential()
model.add(layers.Embedding(MAX_WORDS, 7, input_length=MAX_LEN))
model.add(layers.Conv1D(filters=64, kernel_size=5, activation="relu"))
model.add(layers.MaxPool1D(2))
model.add(layers.Conv1D(filters=32, kernel_size=3, activation="relu"))
model.add(layers.MaxPool1D(2))
model.add(layers.Flatten())
model.add(layers.Dense(CAT_NUM, activation="softmax"))
return model
def compile_model(model):
model.compile(optimizer=optimizers.Nadam(),
loss=losses.SparseCategoricalCrossentropy(),
metrics=[metrics.SparseCategoricalAccuracy(), metrics.SparseTopKCategoricalAccuracy(5)])
return model
model = create_model()
model.summary()
model = compile_model(model)
训练模型
def train_model(model, ds_train, ds_valid, epoches):
for epoch in tf.range(1, epoches + 1):
model.reset_metrics()
# 在后期降低学习率
if epoch == 5:
model.optimizer.lr.assign(model.optimizer.lr / 2.0)
tf.print("Lowering optimizer Learning Rate...\n\n")
for x, y in ds_train:
train_result = model.train_on_batch(x, y)
for x, y in ds_valid:
valid_result = model.test_on_batch(x, y, reset_metrics=False)
if epoch % 1 == 0:
print('======================================================')
tf.print("epoch = ", epoch)
print("train:", dict(zip(model.metrics_names, train_result)))
print("valid:", dict(zip(model.metrics_names, valid_result)))
print("")
train_model(model, ds_train, ds_test, 10)
自定义训练循环
自定义训练循环无需编译模型,直接利用优化器根据损失函数反向传播迭代参数,拥有最高的灵活性。
tf.keras.backend.clear_session()
def create_model():
model = models.Sequential()
model.add(layers.Embedding(MAX_WORDS, 7, input_length=MAX_LEN))
model.add(layers.Conv1D(filters=64, kernel_size=5, activation="relu"))
model.add(layers.MaxPool1D(2))
model.add(layers.Conv1D(filters=32, kernel_size=3, activation="relu"))
model.add(layers.MaxPool1D(2))
model.add(layers.Flatten())
model.add(layers.Dense(CAT_NUM, activation="softmax"))
return (model)
model = create_model()
model.summary()
自定义训练循环:
optimizer = optimizers.Nadam()
loss_func = losses.SparseCategoricalCrossentropy()
train_loss = metrics.Mean(name='train_loss')
train_metric = metrics.SparseCategoricalAccuracy(name='train_accuracy')
valid_loss = metrics.Mean(name='valid_loss')
valid_metric = metrics.SparseCategoricalAccuracy(name='valid_accuracy')
@tf.function
def train_step(model, features, labels):
with tf.GradientTape() as tape:
predictions = model(features, training=True)
loss = loss_func(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss.update_state(loss)
train_metric.update_state(labels, predictions)
@tf.function
def valid_step(model, features, labels):
predictions = model(features)
batch_loss = loss_func(labels, predictions)
valid_loss.update_state(batch_loss)
valid_metric.update_state(labels, predictions)
def train_model(model, ds_train, ds_valid, epochs):
for epoch in tf.range(1, epochs + 1):
for features, labels in ds_train:
train_step(model, features, labels)
for features, labels in ds_valid:
valid_step(model, features, labels)
logs = 'Epoch={},Loss:{},Accuracy:{},Valid Loss:{},Valid Accuracy:{}'
if epoch % 1 == 0:
tf.print('===========================================================')
tf.print(tf.strings.format(logs,(epoch, train_loss.result(), train_metric.result(), valid_loss.result(), valid_metric.result())))
tf.print("")
train_loss.reset_states()
valid_loss.reset_states()
train_metric.reset_states()
valid_metric.reset_states()
train_model(model, ds_train, ds_test, 10)
使用GPU训练模型
深度学习的训练过程常常非常耗时,一个模型训练几个小时是家常便饭,训练几天也是常有的事情,有时候甚至要训练几十天。训练过程的耗时主要来自于两个部分,一部分来自数据准备,另一部分来自参数迭代。
- 当数据准备过程还是模型训练时间的主要瓶颈时,可以使用更多进程来准备数据。
- 当参数迭代过程成为训练时间的主要瓶颈时,通常的方法是应用GPU或者Google的TPU来进行加速。
使用单GPU训练模型
无论是内置fit方法,还是自定义训练循环,从CPU切换成单GPU训练模型都是非常方便的,无需更改任何代码。当存在可用的GPU时,如果不特意指定device,tensorflow会自动优先选择使用GPU来创建张量和执行张量计算。
但是,如果是在公司或者学校实验室的服务器环境,存在多个GPU和多个使用者时,为了不让单个同学的任务占用全部GPU资源导致其他同学无法使用(tensorflow默认获取全部GPU的全部内存资源权限,但实际上只使用一个GPU的部分资源),通常会在开头增加以下几行代码以控制每个任务使用的GPU编号和显存大小,以便其他人也能够同时训练模型。
这里采用Google云端硬盘的实验环境。首先创建一个Colab笔记本,然后设置硬件加速器为GPU:
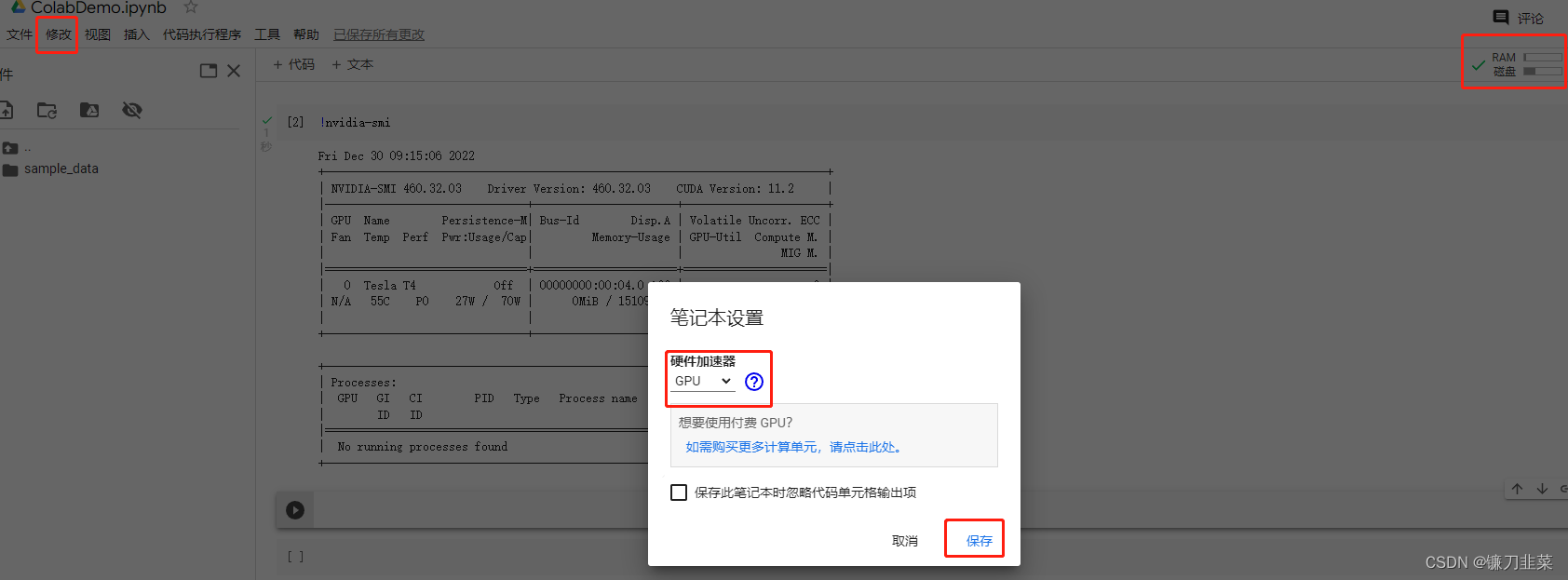
(1)GPU设置

首先比较GPU和CPU计算速度:

(2)数据准备
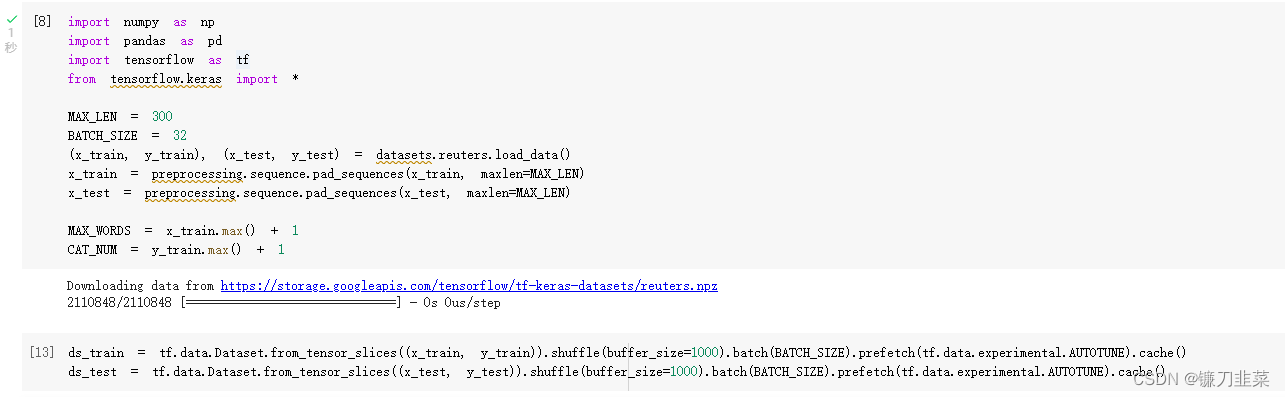
(3)创建模型
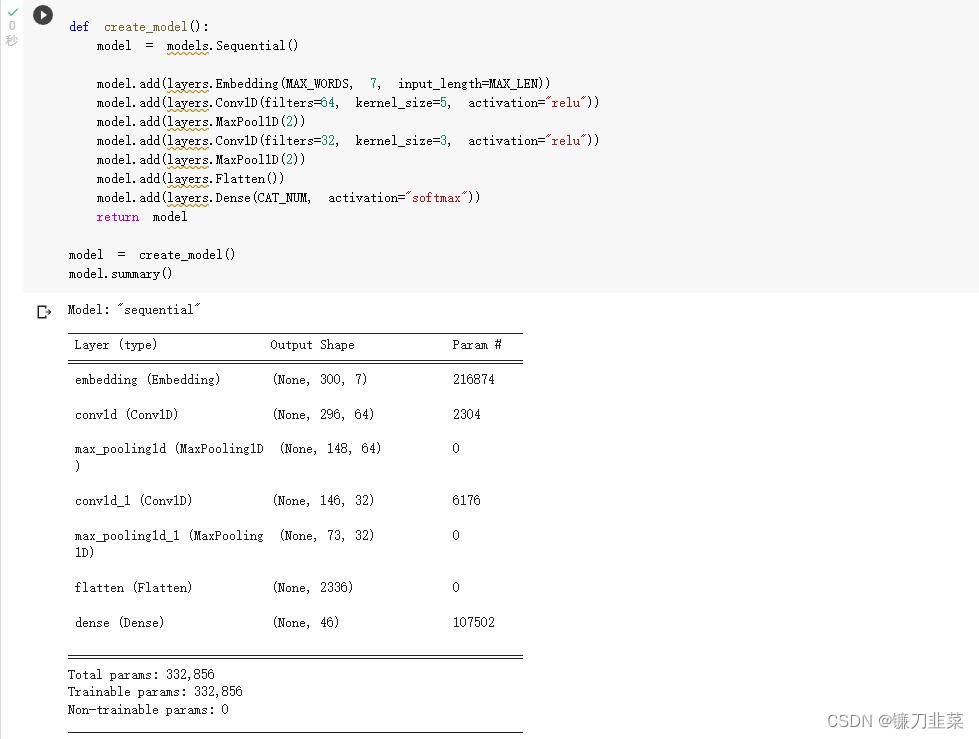
(4)模型训练

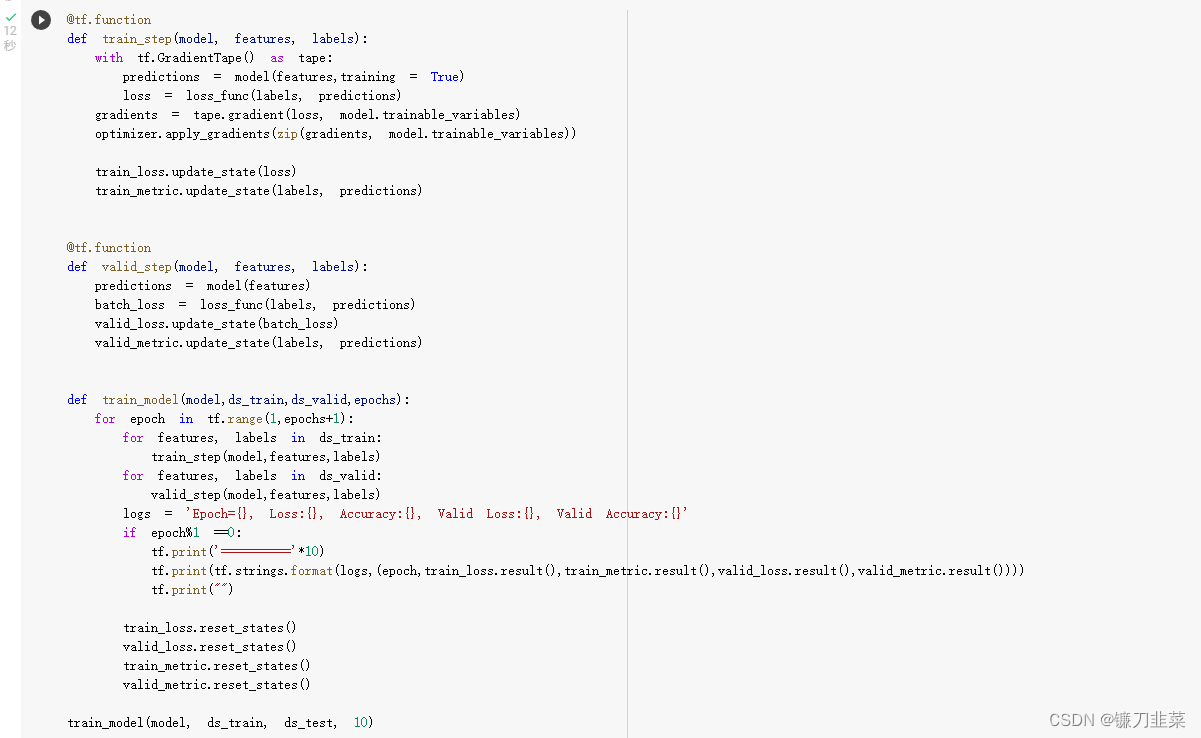
训练结果:

使用多GPU训练模型
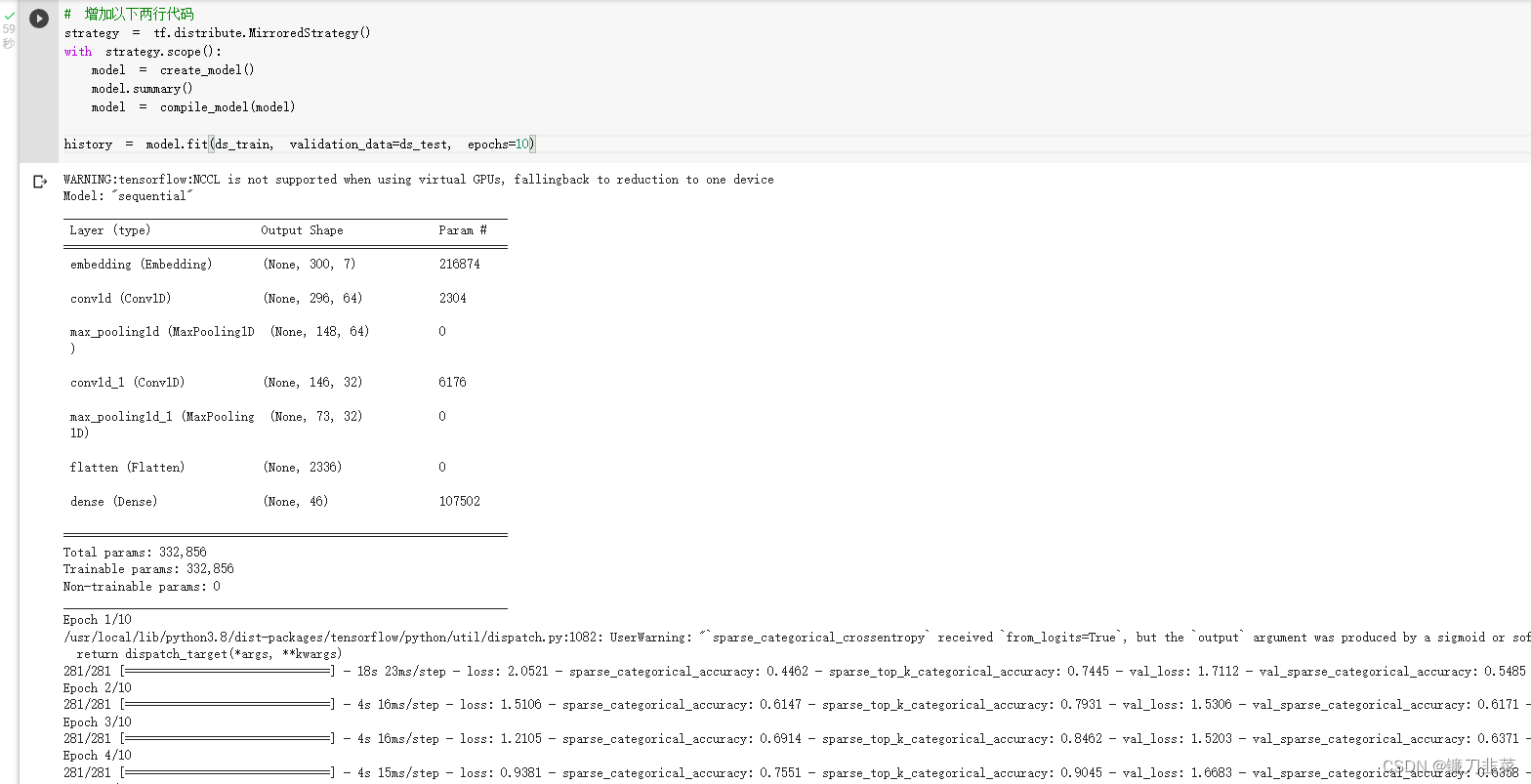
如果使用多GPU训练模型,推荐使用内置fit方法,较为方便,仅需添加2行代码。
MirroredStrategy过程简介:
- 训练开始前,该策略在所有 N 个计算设备上均各复制一份完整的模型;
- 每次训练传入一个批次的数据时,将数据分成N份,分别传入N个计算设备(即数据并行);
- N个计算设备使用本地变量(镜像变量)分别计算自己所获得的部分数据的梯度;
- 使用分布式计算的All-reduce操作,在计算设备间高效交换梯度数据并进行求和,使得最终每个设备都有了所有设备的梯度之和;
- 使用梯度求和的结果更新本地变量(镜像变量);
- 当所有设备均更新本地变量后,进行下一轮训练(即该并行策略是同步的)。
下面同样是基于Google Colab notebook运行。(注意,这里必须是新创建的Colab笔记本,终止其他的Colab笔记本)
创建模型

训练模型
使用TPU训练模型
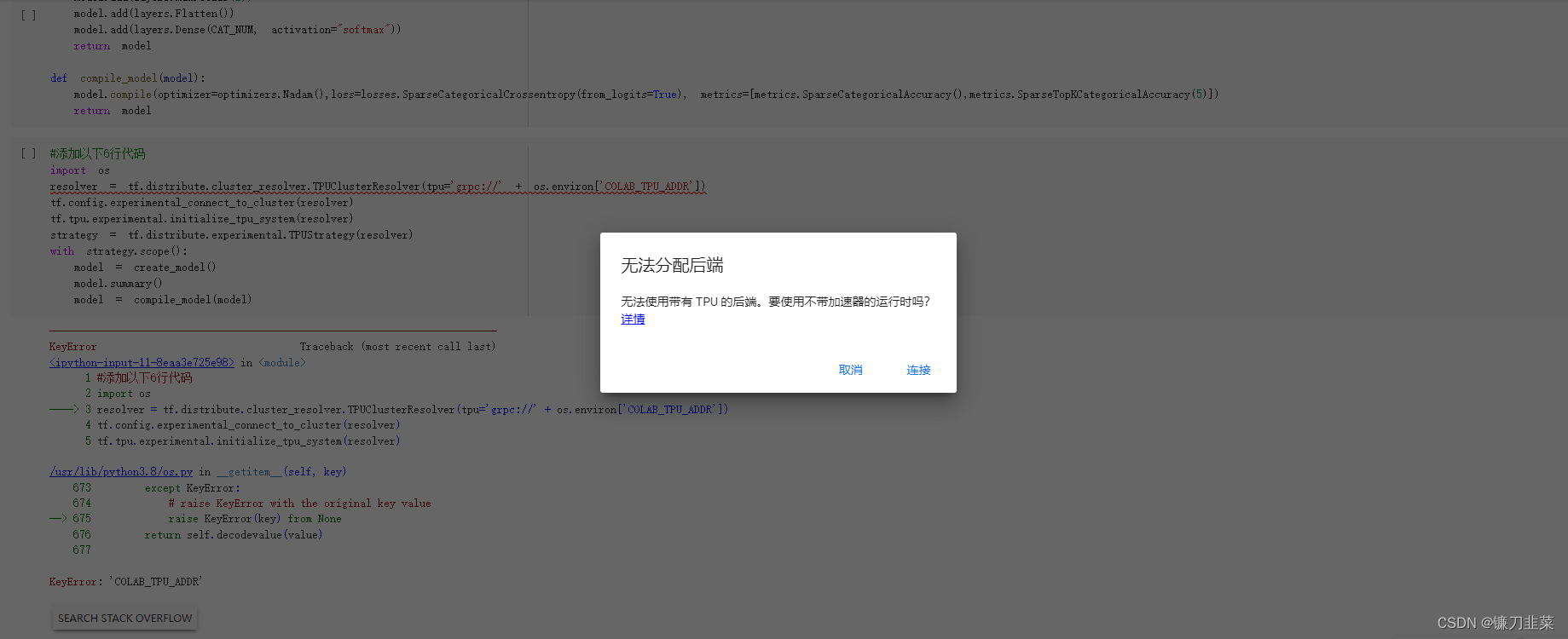
使用Google Colab上的TPU来训练模型,也是非常方便,仅需添加6行代码。
#添加以下6行代码
import os
resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
tf.config.experimental_connect_to_cluster(resolver)
tf.tpu.experimental.initialize_tpu_system(resolver)
strategy = tf.distribute.experimental.TPUStrategy(resolver)
with strategy.scope():
model = create_model()
model.summary()
model = compile_model(model)
但是:
使用Tensorflow-serving部署模型
TensorFlow训练好的模型以tensorflow原生方式保存成protobuf文件后可以用许多方式部署运行。例如:
- 通过
tensorflow-js可以用javascrip脚本加载模型并在浏览器中运行模型。 - 通过
tensorflow-lite可以在移动和嵌入式设备上加载并运行TensorFlow模型。 - 通过
tensorflow-serving可以加载模型后提供网络接口API服务,通过任意编程语言发送网络请求都可以获取模型预测结果。 - 通过
tensorFlow for Java接口,可以在Java或者spark(scala)中调用tensorflow模型进行预测。
这里主要介绍tensorflow serving部署模型、使用spark(scala)调用tensorflow模型的方法。
Tensorflow serving模型部署概述
使用Tensorflow serving部署模型要完成以下几步:
- 准备protobuf模型文件
- 安装tensorflow serving
- 启动tensorflow serving服务
- 向API服务发送请求,获取预测结果。
下面使用Colab笔记本进行实验
import tensorflow as tf
from tensorflow.keras import *
print(tf.__version__)
'''
2.9.2
'''
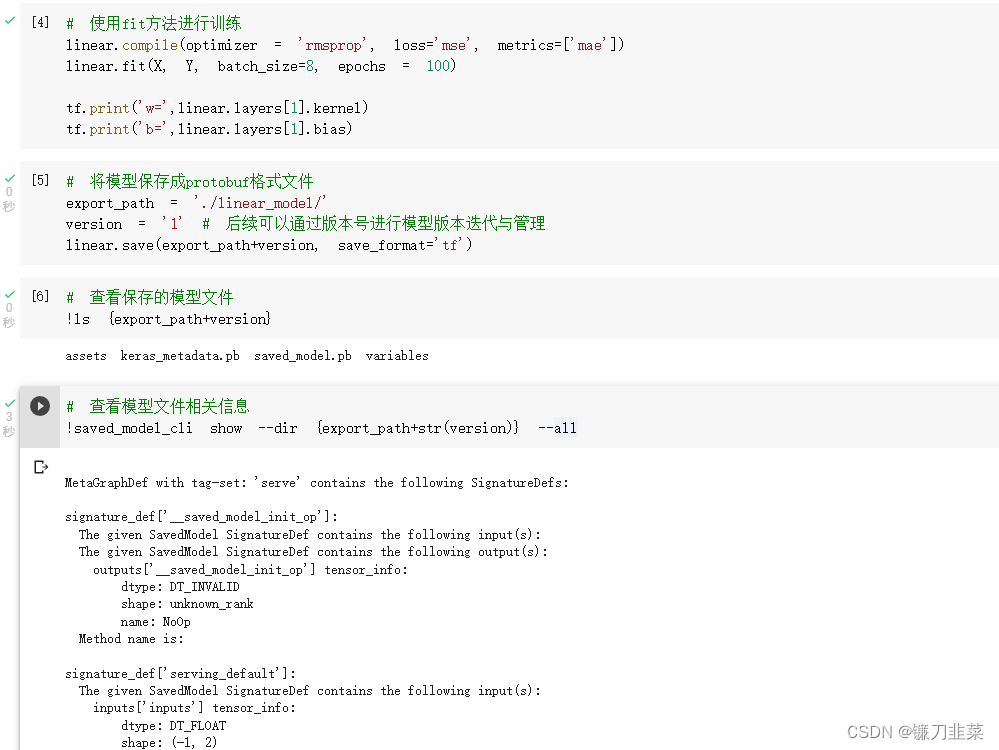
准备protobuf模型文件
这里使用tf.keras训练一个简单的线性回归模型,并保存为protobuf文件。

训练模型,并查看模型相关信息:
安装Tensorflow serving
安装 tensorflow serving 有2种主要方法:①通过Docker镜像安装,②通过apt安装。其中通过Docker镜像安装是最简单,最直接的方法,推荐采用。
Docker可以理解成一种容器,其上面可以给各种不同的程序提供独立的运行环境。一般业务中用到tensorflow的企业都会有运维同学通过Docker 搭建 tensorflow serving,无需算法工程师同学动手安装,以下安装过程仅供参考。
不同操作系统机器上安装Docker的方法如下:
- Windows: https://www.runoob.com/docker/windows-docker-install.html
- MacOs: https://www.runoob.com/docker/macos-docker-install.html
- CentOS: https://www.runoob.com/docker/centos-docker-install.html
安装Docker成功后,使用如下命令加载 tensorflow/serving 镜像到Docker中:
docker pull tensorflow/serving
启动Tensorflow serving服务
!docker run -t --rm -p 8501:8501 \
-v "/Users/..../../data/linear_model/" \
-e MODEL_NAME=linear_model \
tensorflow/serving & >server.log 2>&1
向API服务发送请求
可以使用任何编程语言的http功能发送请求,下面为linux的 curl 命令发送请求,以及Python的requests库发送请求。
(1)使用curl命令发送请求
!curl -d '{"instances": [[1.0, 2.0], [5.0,7.0]]}' -X POST http://localhost:8501/v1/models/linear_model:predict
(2)使用Python的requests库发送请求
import json,requests
data = json.dumps({"signature_name": "serving_default", "instances": [[1.0, 2.0], [5.0,7.0]]})
headers = {"content-type": "application/json"}
json_response = requests.post('http://localhost:8501/v1/models/linear_model:predict', data=data, headers=headers)
predictions = json.loads(json_response.text)["predictions"]
print(predictions)
使用Spark-scala调用Tensorflow2训练好的模型
这一节介绍在Spark中调用训练好的Tensorflow模型进行预测的方法,这就要求开发人员有spark和scala基础。另外,如果使用PySpark,会简单一些,因为只需要在每个executor上用Python加载模型分别预测就可以了。但是在工程上,通常使用Scala版本的Spark。
利用Spark的分布式计算能力,从而可以让训练好的Tensorflow模型在成百上千的机器上分布式并行执行模型推断。
Spark(scala)调用Tensorflow模型概述
使用Spark(scala)中调用Tensorflow模型进行预测需要以下几个步骤:
- 准备protobuf模型文件
- 创建Spark(scala)项目,在项目中添加Java版本的Tensorflow对应的jar包依赖
- 在Spark(scala)项目中的driver端加载Tensorflow模型,并调试成功
- 在Spark(scala)项目中通过RDD在executor上加载Tensorflow模型,并调试成功
- 在Spark(scala)项目中通过DataFrame在executor上加载Tensorflow模型,并调试成功
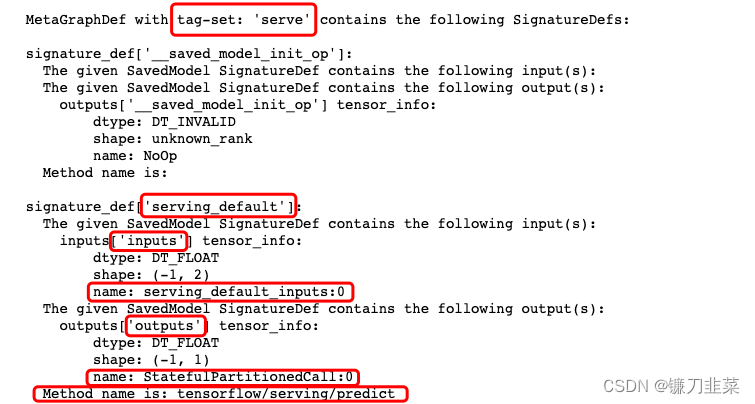
准备protobuf模型文件
同样地,使用tf.keras训练一个简单的线性回归模型,并将其保存为protobuf文件。代码略
其中模型文件信息中这些标红的部分都是后面有可能会用到的。
创建Spark(scala)项目,并添加java版本的Tensorflow对应jar包
如果使用maven管理项目,需要添加如下jar包依赖:
<!-- https://mvnrepository.com/artifact/org.tensorflow/tensorflow -->
<dependency>
<groupId>org.tensorflow</groupId>
<artifactId>tensorflow</artifactId>
<version>1.15.0</version>
</dependency>
也可以从下面网址中直接下载org.tensorflow.tensorflow的jar包,以及其依赖的org.tensorflow.libtensorflow 和 org.tensorflowlibtensorflow_jni的jar包 也放到项目中。
https://mvnrepository.com/artifact/org.tensorflow
在Spark(scala)项目中的driver端加载Tensorflow模型
示例代码在jupyter notebook中进行演示,需要安装toree以支持Spark(scala)。(下面是scala代码)
import scala.collection.mutable.WrappedArray
import org.{tensorflow=>tf}
//注:load函数的第二个参数一般都是“serve”,可以从模型文件相关信息中找到
val bundle = tf.SavedModelBundle.load("../CodeFiles/Tensorflow2/data/linear_model/1","serve")
//注:在java版本的tensorflow中还是类似tensorflow1.0中静态计算图的模式,需要建立Session, 指定feed的数据和fetch的结果, 然后 run.
//注:如果有多个数据需要喂入,可以连续使用多个feed方法
//注:输入必须是float类型
val sess = bundle.session()
val x = tf.Tensor.create(Array(Array(1.0f,2.0f),Array(2.0f,3.0f)))
val y = sess.runner().feed("serving_default_inputs:0", x).fetch("StatefulPartitionedCall:0").run().get(0)
val result = Array.ofDim[Float](y.shape()(0).toInt,y.shape()(1).toInt)
y.copyTo(result)
if(x != null) x.close()
if(y != null) y.close()
if(sess != null) sess.close()
if(bundle != null) bundle.close()
result
输出:
Array(Array(3.019596), Array(3.9878292))
在Spark(scala)项目中通过RDD在executor上加载Tensorflow模型
通过广播机制将Driver端加载的TensorFlow模型传递到各个executor上,并在executor上分布式地调用模型进行推断。
import org.apache.spark.sql.SparkSession
import scala.collection.mutable.WrappedArray
import org.{tensorflow=>tf}
val spark = SparkSession
.builder()
.appName("TfRDD")
.enableHiveSupport()
.getOrCreate()
val sc = spark.sparkContext
//在Driver端加载模型
val bundle = tf.SavedModelBundle.load("../CodeFiles/Tensorflow2/data/linear_model/1","serve")
//利用广播将模型发送到executor上
val broads = sc.broadcast(bundle)
//构造数据集
val rdd_data = sc.makeRDD(List(Array(1.0f,2.0f),Array(3.0f,5.0f),Array(6.0f,7.0f),Array(8.0f,3.0f)))
//通过mapPartitions调用模型进行批量推断
val rdd_result = rdd_data.mapPartitions(iter => {
val arr = iter.toArray
val model = broads.value
val sess = model.session()
val x = tf.Tensor.create(arr)
val y = sess.runner().feed("serving_default_inputs:0", x).fetch("StatefulPartitionedCall:0").run().get(0)
//将预测结果拷贝到相同shape的Float类型的Array中
val result = Array.ofDim[Float](y.shape()(0).toInt,y.shape()(1).toInt)
y.copyTo(result)
result.iterator
})
rdd_result.take(5)
bundle.close
输出如下:
Array(Array(3.019596), Array(3.9264367), Array(7.8607616), Array(15.974984))
在Spark(scala)项目中通过DataFrame在executor上加载Tensorflow模型
除了可以在Spark的RDD数据上调用Tensorflow模型进行分布式推断,也可以在DataFrame数据上调用Tensorflow模型,主要思路是将推断方法注册成为一个SparkSQL函数。
import org.apache.spark.sql.SparkSession
import scala.collection.mutable.WrappedArray
import org.{tensorflow=>tf}
object TfDataFrame extends Serializable{
def main(args:Array[String]):Unit = {
val spark = SparkSession
.builder()
.appName("TfDataFrame")
.enableHiveSupport()
.getOrCreate()
val sc = spark.sparkContext
import spark.implicits._
val bundle = tf.SavedModelBundle
.load("../CodeFiles/Tensorflow2/data/linear_model/1","serve")
val broads = sc.broadcast(bundle)
//构造预测函数,并将其注册成sparkSQL的udf
val tfpredict = (features:WrappedArray[Float]) => {
val bund = broads.value
val sess = bund.session()
val x = tf.Tensor.create(Array(features.toArray))
val y = sess.runner().feed("serving_default_inputs:0", x)
.fetch("StatefulPartitionedCall:0").run().get(0)
val result = Array.ofDim[Float](y.shape()(0).toInt,y.shape()(1).toInt)
y.copyTo(result)
val y_pred = result(0)(0)
y_pred
}
spark.udf.register("tfpredict",tfpredict)
//构造DataFrame数据集,将features放到一列中
val dfdata = sc.parallelize(List(Array(1.0f,2.0f),Array(3.0f,5.0f),Array(7.0f,8.0f))).toDF("features")
dfdata.show
//调用sparkSQL预测函数,增加一个新的列作为y_preds
val dfresult = dfdata.selectExpr("features","tfpredict(features) as y_preds")
dfresult.show
bundle.close
}
}
// 调用上述类
TfDataFrame.main(Array())
输出:
+----------+
| features|
+----------+
|[1.0, 2.0]|
|[3.0, 5.0]|
|[7.0, 8.0]|
+----------+
+----------+---------+
| features| y_preds|
+----------+---------+
|[1.0, 2.0]| 3.019596|
|[3.0, 5.0]|3.9264367|
|[7.0, 8.0]| 8.828995|
+----------+---------+
实际上Tensorflow并不仅仅适合实现神经网络,其底层的计算图语言可以表达各种数值计算过程。利用其丰富的低阶API,可以在Tensorflow2.0上实现任意机器学习模型,结合tf.Module提供的便捷的封装功能,可以将训练好的任意机器学习模型导出成模型文件并在Spark上分布式调用执行。
参考资料
[1] 《Tensorflow:实战Google深度学习框架》
[2] 《30天吃掉那只Tensorflow2》
[3] 用GPU加速Keras模型——Colab免费GPU使用攻略