为优化淘宝带宽成本,我们在网关 SDK(Java)统一使用 ZSTD 替代 GZIP 压缩以获取更高的压缩比,从而得到更小的响应包。具体实现采用官方推荐的 zstd-jni 库。zstd-jni 会调用 zstd 的 c++ 库。

背景
在性能压测和优化过程中,遇到了以下三个问题:
GC 次数不变,但耗时翻倍
进程内存泄漏,极限情况下会出现 OOM Killer 杀掉进程的情况
Netty 堆外内存泄漏(在优化问题 1 时引入)
下面我会从这三个问题展开,分享排查、解决问题的思路和过程。

GC 优化
▐ 【GC 耗时翻倍问题】现象
在我们预期中,使用 ZSTD 压缩,在大包场景下(20KB 以上),不仅能够获得比 GZIP 更高的压缩比;同时压缩性能也应有一定优化,具体优化程度取决于业务特征,但至少不会有性能劣化。
但实际性能压测发现相比于同级别的 Netty GZIP,ZSTD 压缩下,GC 次数不变,但耗时几乎翻倍,导致最终应用表现为几乎无任何性能优化,甚至影响 RT(CMS 下)。
▐ 【GC 耗时翻倍问题】分析
我们的 ZSTD 压缩是通过 JNI 实现,流程是将堆内数据拷贝到堆外压缩,再将拷回堆内。
使用 JNI 会在一定程度上影响 GC 的效率,这是我们已知的,但是耗时翻倍超出了我们的预期。因此我们尝试分析压缩的执行流程。
JDK 22 中通过在 G1 中实现 region pinning 来减少延迟,以在 JNI 执行期间无需禁用 GC,详见 JEP 423: Region Pinning for G1(地址:https://openjdk.org/jeps/423)
相比 GZIP,ZSTD 在单次压缩过程中,多了内存占用:
压缩后数据占用的堆内内存
a.ZSTD 压缩原始数据和压缩后数据分开保存,占用两份内存。而 GZIP 会将压缩后的数据写回到压缩前的 byte 数组,只占用一份内存。
b.除此之外,尤其是在流式 ZSTD 场景下,多个响应复用同一个 OutputStream 以达到最优压缩比,但 OutputStream 里的 buffer 会占用额外的堆内空间。
堆外压缩需要的内存,保存 ZSTD 压缩上下文(保存字典)。
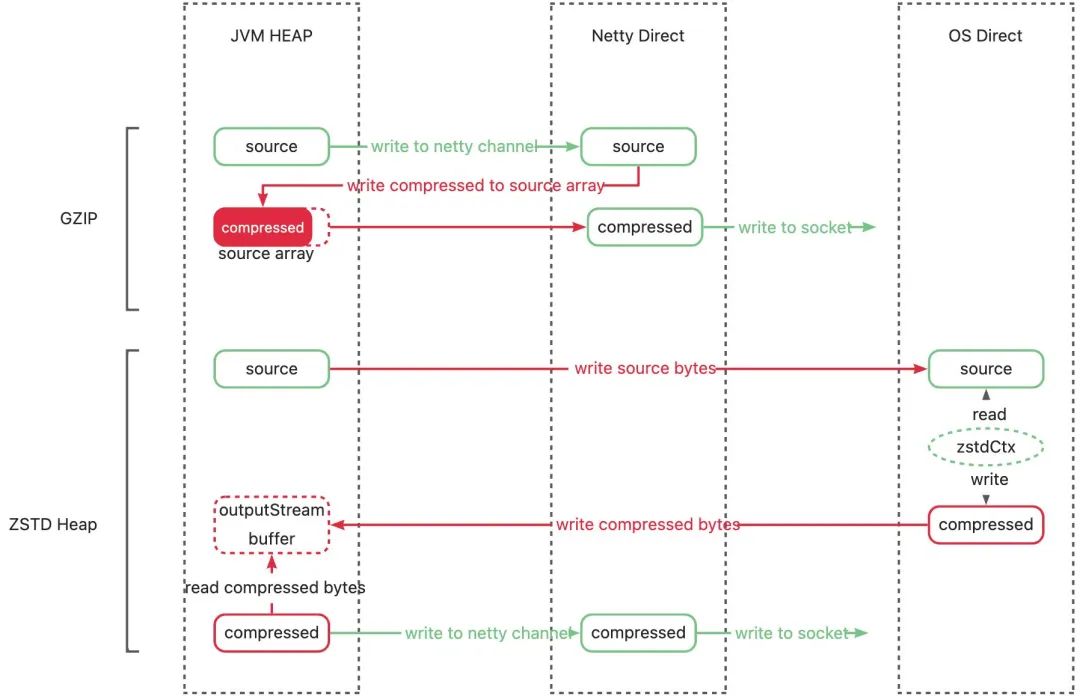
据图分析,可能存在两个问题导致 GC 耗时变长:
不必要的堆内内存占用
不必要的堆内外数据拷贝
▐ 【GC 耗时翻倍问题】解决
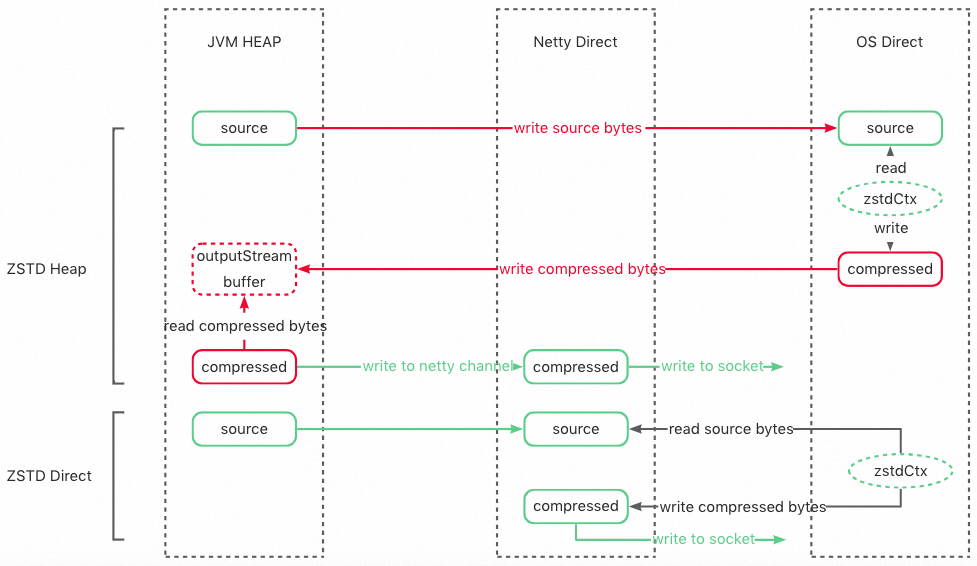
思路:为了能够解决以上两个问题,我们希望能够将原始数据在堆外压缩后直接写出,一方面尽早释放原始数据占用的堆内内存,另一方面减少不必要的堆内外拷贝。
实现:使用 zstd-jni 提供的堆外压缩接口,直接原始数据拷贝到堆外进行压缩,并通过 Netty 直接在堆外写出(流程为上图的 ZSTD Direct)。
▐ 【Finalizer 问题】现象
但是,转堆外压缩后,再次进行压测,发现 GC 并没有如期下降,反而更加频繁,堆内存使用更高。
于是 GC 后 dump 查看堆布局,分析 JVM 堆内存,发现整体堆使用大小 915M/4G,这很不正常,我们的测试应用没有长寿命对象,预期 GC 后,堆大小应该只有几十 M。
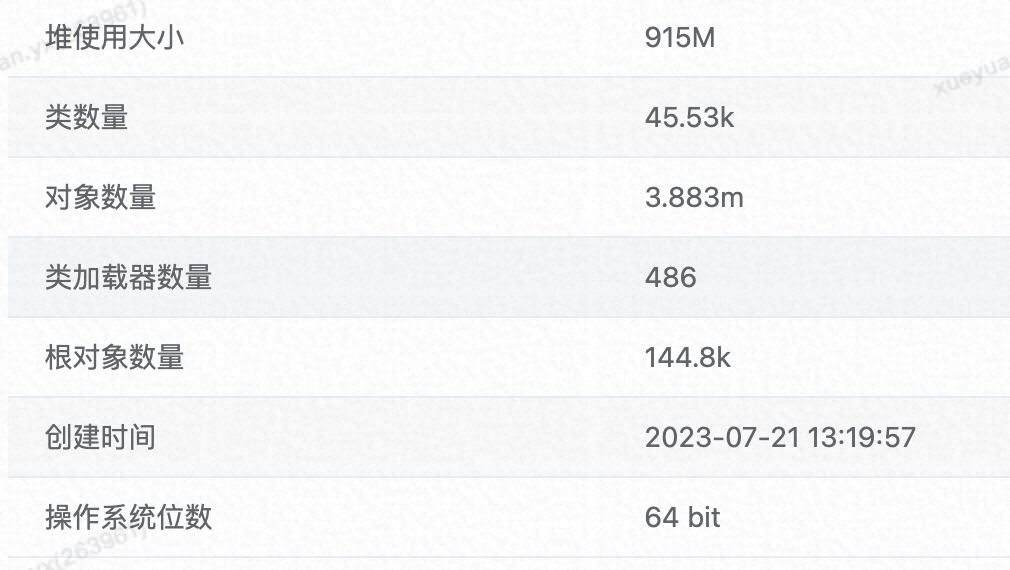
进一步查看堆内对象,发现有大量新增可疑对象:
Finalizer
ZstdJNIDirectByteBufCompressor(压缩实例,JNI 调用入口。)
DefaultInvocation(请求上下文,包含请求和响应的全部信息,为应用大对象。)
他们的引用关系为:
Finalizer -> ZstdJNIDirectByteBufCompressor <-> DefaultInvocation。
其中 ZstdJNIDirectByteBufCompressor 和 DefaultInvocation 有高达 1604 个,占用内存超 704M,占已使用堆内存的 77%,但之前并没有这些对象。

▐ 【Finalizer 问题】分析
哪来这么多 Finalizer 对象,和 GC 耗时增长有什么关系?
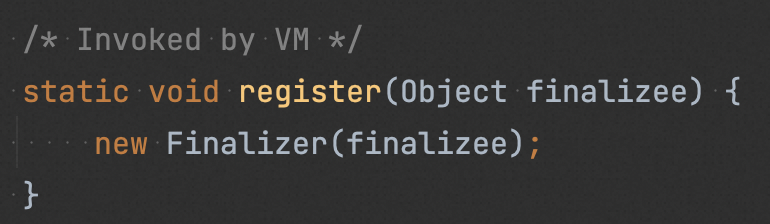
要想知道 Finalizer 对象是什么,我们首先需要了解 JVM 的 finalize() 方法:
finalize() 方法定义在 Object 类中,对于实现了 finalize() 的对象,当垃圾回收器确定该对象没有任何引用时,就会调用其 finalize()。
笔者建议大家尽量避免使用它,因为它并不能等同于 C 和 C++ 语言中的析构函数,而是 Java 刚诞生时为了使传统 C、C++ 程序员更容易接受 Java 所做出的一项妥协。它的运行代价高昂,不确定性大,无法保证各个对象的调用顺序,如今已被官方明确声明为不推荐使用的语法。有些教材中描述它适合做“关闭外部资源”之类的清理性工作,这完全是对 finalize() 方法用途的一种自我安慰。finalize() 能做的所有工作,使用 try-finally 或者其他方式都可以做得更好、 更及时,所以笔者建议大家完全可以忘掉 Java 语言里面的这个方法。
--《深入理解 JVM》
多数同学对 finalize 方法的了解,可能都来自于以上这段话,知道其 “运行代价高昂”,“不推荐使用” ,那它到底会对我们应用产生什么影响?
JVM 是如何执行 finalize() 的?
JVM 在加载类的时候,会去识别该类是否实现了 finalize() ;若是,则标记出该类为“ finalize class”。
在创建 “finalize Class” 对象时,会调用 Finalizer#register(),在该方法中创建一个 Finalizer 对象,Finalizer 对象会引用原始对象,然后将其注册到名为 unfinalized 的全局队列中(保证 Finalizer 对象及其引用的原始对象一直可达,以确保在被 GC 前,其 finalize() 能被执行)。
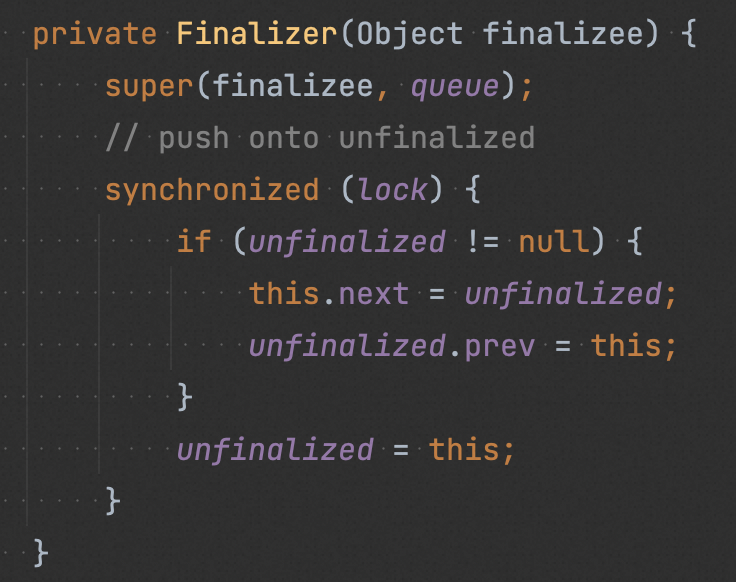
在一次 GC时,JVM 判断原始对象除了 Finalizer 对象引用之外没有其他对象引用之后,就把 Finalizer 对象从 “unfinalized” 队列中取出,加入到 “Finalizer queue” 中。
JVM 在启动时,会启动一个“finalize”线程,该线程会一直从“Finalizer queue”中取出对象,然后执行原始对象中的 finalize()。
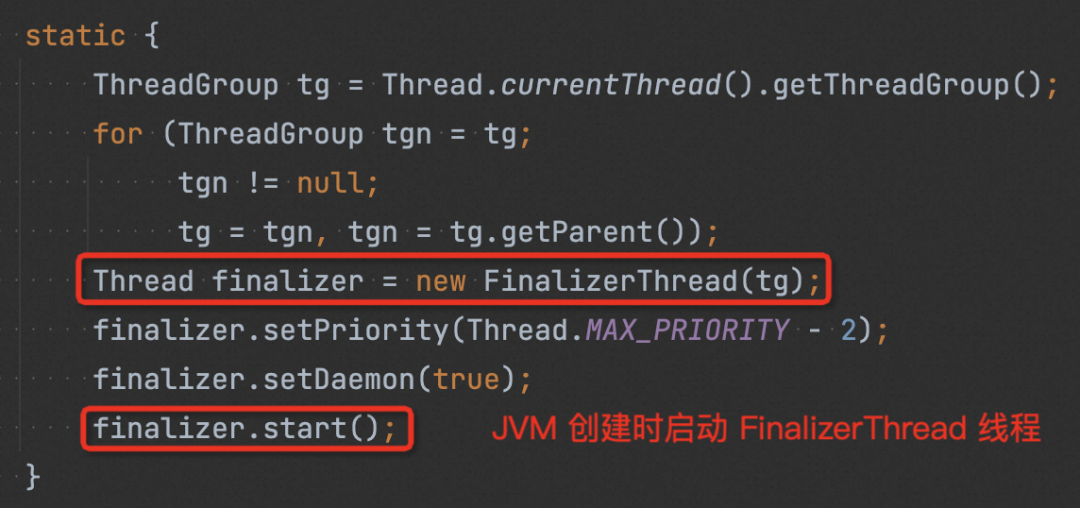
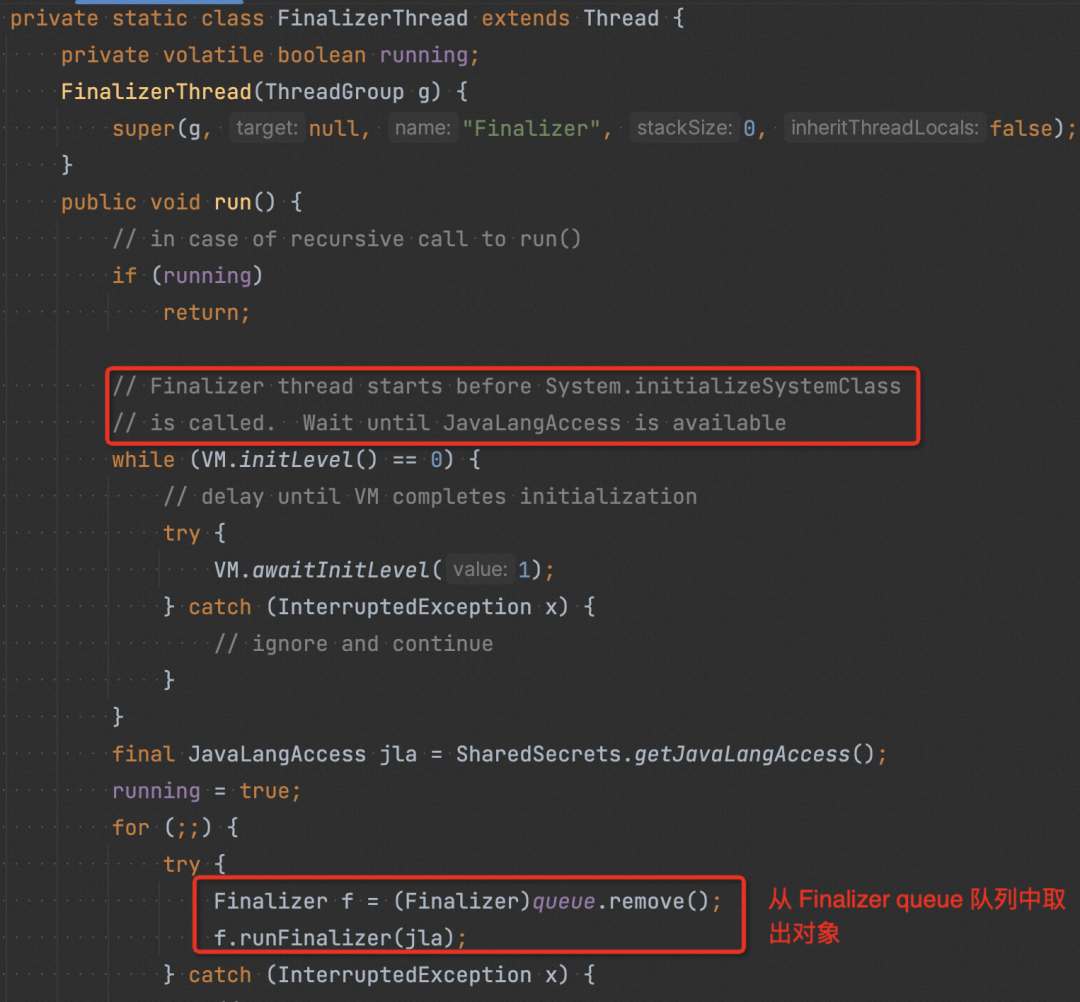
在完成步骤 4 后,Finalizer 对象以及其引用的原始对象,再无其他引用,属于不可达对象,再次 GC 的时候他们将会被回收掉。(如果在 finalize() 使该对象重新可达,再次 GC 该对象不会被回收,即 finalize() 方法是对象逃脱死亡 (GC) 命运的最后一次机会)。
使用 finalize() 带来哪些影响?
创建一个实现 finalize() 的对象时,需要额外创建其 Finalizer 对象并且注册到队列中,因此需要额外的内存空间,且创建时间长于普通对象创建。
相比普通对象,实现 finalize() 的对象生存周期更长,至少需要两次 GC 才可被回收。
在 GC 时需要对实现 finalize() 的对象做特殊处理(比如 Finalizer 对象的出队入队操作等), GC 耗时更长。
因为 finalize 线程优先级比较低,若 CPU 繁忙,可能会导致 “ Finalizer queue” 有积压,在经历多次 YGC 之后原始对象及其 Finalizer 对象就会进入 old 区域,那么这些对象只能等待 FGC 才能被 GC。
总的来说,使用 finalize() 方法本身会加重系统负担、严重影响 GC 并且无法保证 finalize 的调用时机,其应用场景也仅仅是防止资源泄漏,finalize() 能做的所有工作,使用 try-finally 或者其他方式都可以做得更好、 更及时,所以我们还是忘记它的存在吧。
▐ 【Finalizer 问题】解决
最佳实践:
尽可能避免使用 finalize 机制。若实在无法避免,也应尽量避免其引用大对象。
JDK 18 中已经弃用 finalize 机制以在未来版本中删除。详见:Deprecate Finalization for Removal(地址:https://openjdk.org/jeps/421)
在我们的 ZSTD 场景下,由于 zstd-jni 将 finalize() 作为堆外资源的兜底清理手段,因此我们断开其对应用大对象的引用后,耗时翻倍的问题被成功解决。
我们的测试应用单机极限 QPS 较低(300),Finalizer 只要不引用大对象,对 GC 的影响不大;但在更高 QPS 场景下,Finalizer 对 GC 的影响会更加凸显。
我们在另一线上应用使用 ZSTD 压缩,在单机 QPS 1000 时,比起使用 NoFinalizer 的 Zstd Compressor,使用 Finalizer 的 Zstd Compressor GC 耗时涨了近 10 倍。
因此,我们最终决定直接使用 NoFinalizer 的 Zstd Compressor。

Netty ByteBuf 内存泄漏
▐ 现象
为了优化 GC,我们通过 Netty 的 DirectByteBuf 操作堆外内存,直接在堆外压缩并响应。
但在性能压测时,通过 Netty 的内存泄漏检测工具,发现在极限情况下会产生内存泄漏,经过观察,会伴随着以下几种现象:
施压 QPS 达到单机极限,持续有 FGC 产生;
客户端超时主动断连,继续往被关闭的 channel 里写入内容失败,会出现连接已关闭的报错;
Netty 堆外内存满;
▐ 分析
Step 1 泄漏堆栈显示泄漏对象为响应内容的 DirectByteBuf
Step 2 通过增加埋点追溯业务代码中可能的泄漏点,发现在写给 netty ChannelOutboundHandler pipeline 之前,是没有泄漏的。
Step 3 排查聚焦在 netty 的 ChannelOutboundHandler pipeline,排查我们自己实现的 ChannelOutboundHandler 内部也并未有泄漏。
Step 4 进一步分析 netty 内存泄漏检测的堆栈,发现泄漏内存的最后访问点有 netty 框架内部代码,所以猜测泄漏可能是框架执行过程中产生。
Step 5 进一步分析 netty 写出响应的代码。
我们调用 netty 的 AbstractChannel#writeAndFlush(java.lang.Object) 写出内容,会从 pipeline 的最后一个节点执行,最终进入到 next.invokeWriteAndFlush(m, promise)。
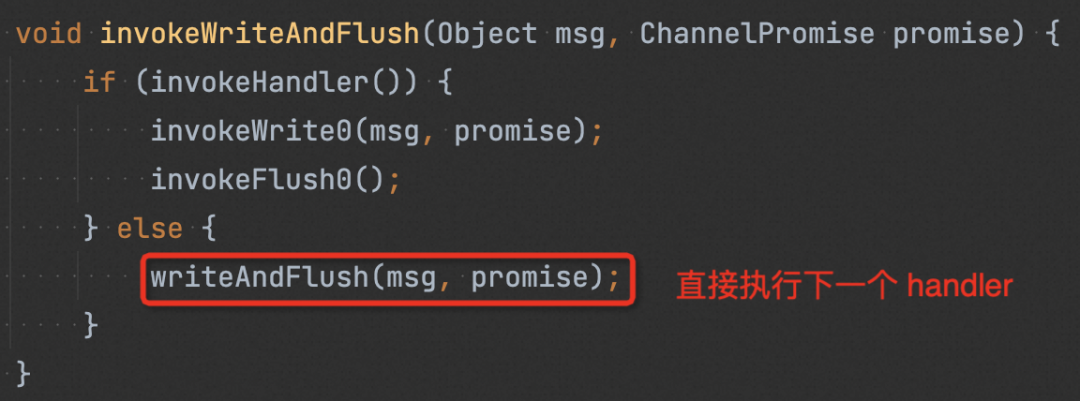
invokeHandler() 会检查 handler 的状态(如下图),确认其是否可被执行。若 handler 被认为不可执行,则会直接尝试执行下一个 handler (如 1 中图)。
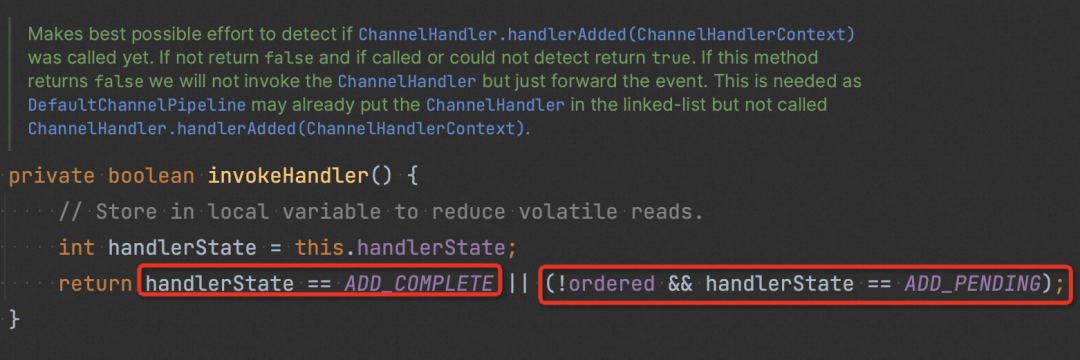
尝试追溯 handlerState 的更新。发现当 channel 被 deregister 后(连接关闭), pipeline 所有中间 handler 的状态都会被置为 REMOVE_COMPLETE,即不可执行,这样后续再写入的消息都不会再进入到这些 handler 里了。(泄漏就是从这里开始)
setRemoved:911, AbstractChannelHandlerContext (io.netty.channel)
callHandlerRemoved:950, AbstractChannelHandlerContext (io.netty.channel)
callHandlerRemoved0:637, DefaultChannelPipeline (io.netty.channel)
destroyDown:876, DefaultChannelPipeline (io.netty.channel)
destroyUp:844, DefaultChannelPipeline (io.netty.channel)
destroy:836, DefaultChannelPipeline (io.netty.channel)
access$700:46, DefaultChannelPipeline (io.netty.channel)
channelUnregistered:1392, DefaultChannelPipeline$HeadContext (io.netty.channel)
invokeChannelUnregistered:198, AbstractChannelHandlerContext (io.netty.channel)
invokeChannelUnregistered:184, AbstractChannelHandlerContext (io.netty.channel)
fireChannelUnregistered:821, DefaultChannelPipeline (io.netty.channel)
run:839, AbstractChannel$AbstractUnsafe$8 (io.netty.channel)
safeExecute$$$capture:164, AbstractEventExecutor (io.netty.util.concurrent)
safeExecute:-1, AbstractEventExecutor (io.netty.util.concurrent)
- Async stack trace
addTask:-1, SingleThreadEventExecutor (io.netty.util.concurrent)
execute:825, SingleThreadEventExecutor (io.netty.util.concurrent)
execute:815, SingleThreadEventExecutor (io.netty.util.concurrent)
invokeLater:1042, AbstractChannel$AbstractUnsafe (io.netty.channel)
deregister:822, AbstractChannel$AbstractUnsafe (io.netty.channel)
fireChannelInactiveAndDeregister:782, AbstractChannel$AbstractUnsafe (io.netty.channel)
close:765, AbstractChannel$AbstractUnsafe (io.netty.channel)
close:620, AbstractChannel$AbstractUnsafe (io.netty.channel)
close:1352, DefaultChannelPipeline$HeadContext (io.netty.channel)
invokeClose:622, AbstractChannelHandlerContext (io.netty.channel)
close:606, AbstractChannelHandlerContext (io.netty.channel)
close:472, AbstractChannelHandlerContext (io.netty.channel)
close:957, DefaultChannelPipeline (io.netty.channel)
close:244, AbstractChannel (io.netty.channel)
close:92, DefaultHttpStream (com.alibaba.xxx.xxx.xxx.inbound.http)
onRequestReceived:111, DefaultHttpStreamTest$getHttpServerRequestListener$1 (com.alibaba.xxx.xxx.xxx.inbound.http)
onHttpRequestReceived:53, HttpServerStreamHandler (com.alibaba.xxx.xxx.xxx.inbound.http.server)
channelRead:44, HttpServerStreamHandler (com.alibaba.xxx.xxx.xxx.inbound.http.server)
invokeChannelRead:379, AbstractChannelHandlerContext (io.netty.channel)
invokeChannelRead:365, AbstractChannelHandlerContext (io.netty.channel)
fireChannelRead:357, AbstractChannelHandlerContext (io.netty.channel)
channelRead:286, IdleStateHandler (io.netty.handler.timeout)
invokeChannelRead:379, AbstractChannelHandlerContext (io.netty.channel)
invokeChannelRead:365, AbstractChannelHandlerContext (io.netty.channel)
fireChannelRead:357, AbstractChannelHandlerContext (io.netty.channel)
channelRead:103, MessageToMessageDecoder (io.netty.handler.codec)
invokeChannelRead:379, AbstractChannelHandlerContext (io.netty.channel)
invokeChannelRead:365, AbstractChannelHandlerContext (io.netty.channel)
fireChannelRead:357, AbstractChannelHandlerContext (io.netty.channel)
channelRead:103, MessageToMessageDecoder (io.netty.handler.codec)
channelRead:111, MessageToMessageCodec (io.netty.handler.codec)
invokeChannelRead:379, AbstractChannelHandlerContext (io.netty.channel)
invokeChannelRead:365, AbstractChannelHandlerContext (io.netty.channel)
fireChannelRead:357, AbstractChannelHandlerContext (io.netty.channel)
channelRead:103, MessageToMessageDecoder (io.netty.handler.codec)
invokeChannelRead:379, AbstractChannelHandlerContext (io.netty.channel)
invokeChannelRead:365, AbstractChannelHandlerContext (io.netty.channel)
fireChannelRead:357, AbstractChannelHandlerContext (io.netty.channel)
fireChannelRead:324, ByteToMessageDecoder (io.netty.handler.codec)
channelRead:296, ByteToMessageDecoder (io.netty.handler.codec)
invokeChannelRead:379, AbstractChannelHandlerContext (io.netty.channel)
invokeChannelRead:365, AbstractChannelHandlerContext (io.netty.channel)
fireChannelRead:357, AbstractChannelHandlerContext (io.netty.channel)
channelRead:1410, DefaultChannelPipeline$HeadContext (io.netty.channel)
invokeChannelRead:379, AbstractChannelHandlerContext (io.netty.channel)
invokeChannelRead:365, AbstractChannelHandlerContext (io.netty.channel)
fireChannelRead:919, DefaultChannelPipeline (io.netty.channel)
read:166, AbstractNioByteChannel$NioByteUnsafe (io.netty.channel.nio)
processSelectedKey:719, NioEventLoop (io.netty.channel.nio)
processSelectedKeysOptimized:655, NioEventLoop (io.netty.channel.nio)
processSelectedKeys:581, NioEventLoop (io.netty.channel.nio)
run:493, NioEventLoop (io.netty.channel.nio)
run:986, SingleThreadEventExecutor$4 (io.netty.util.concurrent)
run:74, ThreadExecutorMap$2 (io.netty.util.internal)
run:748, Thread (java.lang)可以看到 pipeline 中间 handler 被跳过了,其中也包括我们自己实现的 handler。分析下图代码,我们写给 netty pipeline 的 msg 实际是我们自己包装的 HttpObject,是在我们自己实现的 handler 里才转成 netty 的 ReferenceCounted 对象的,由于 handler 被跳过导致该对象并没有被转换成 ReferenceCounted,所以即使 netty 有兜底的 release ,实际并没有产生作用,HttpObject 内部的 ByteBuf 并未真正被释放,此时产生泄漏。
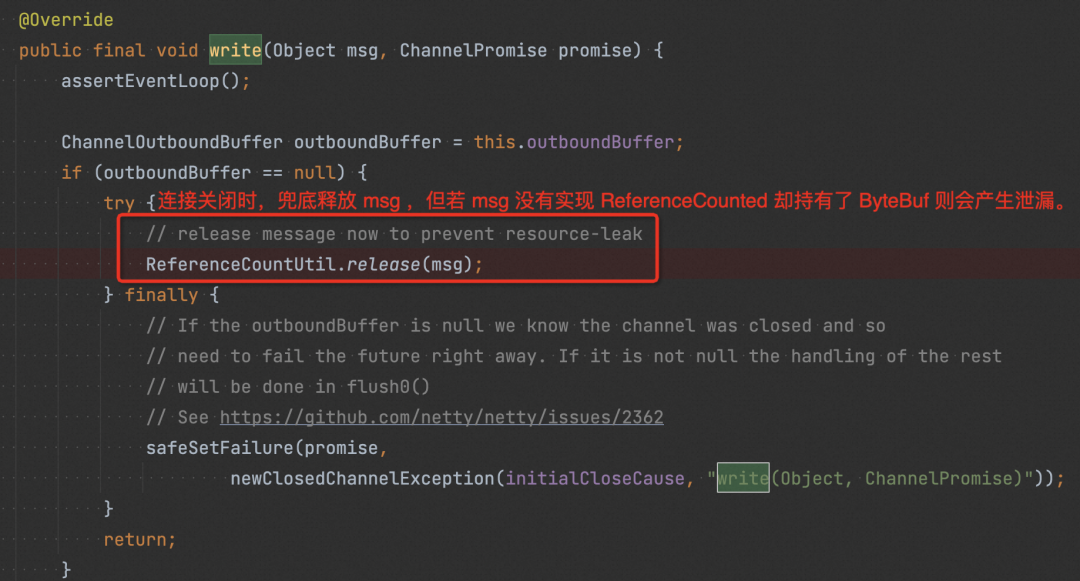
▐ 解决
【最佳实践】在写入 channel 之前,一定要先判断 channel 是否 active 。
【最佳实践】我们写给 netty 的内容,最好是实现了 ReferenceCounted 接口的对象,这样即使 netty 内部出现不预期情况,我们也可以利用 netty 的兜底 release 来释放资源。
控制 ByteBuf 的使用范围。在我们的场景里,可以将压缩的实现下移到 netty 层,但上述 1、2 也同样必须改进才能确保不出问题。
好处:对 ByteBuf 的操作可以收口在传输层,应用层编程难度大大降低。
坏处:考虑到可能存在多个 传输层 (http server) 的实现,压缩逻辑可能需要根据堆内堆外做两份实现,每个 http server 都需要对接。

堆外内存
▐ 现象
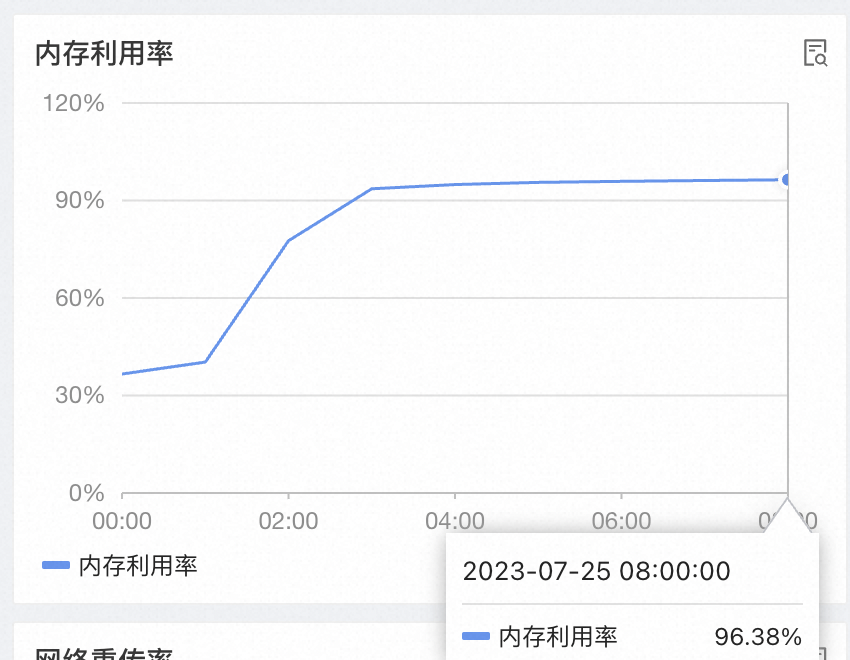
开启 zstd 压缩时:
QPS 增加会导致操作系统内存持续增加,直到 OOM Killer。
在 QPS 调零数十小时后,内存也几乎不会降低。
因此怀疑存在堆外内存泄漏。
▐ 分析
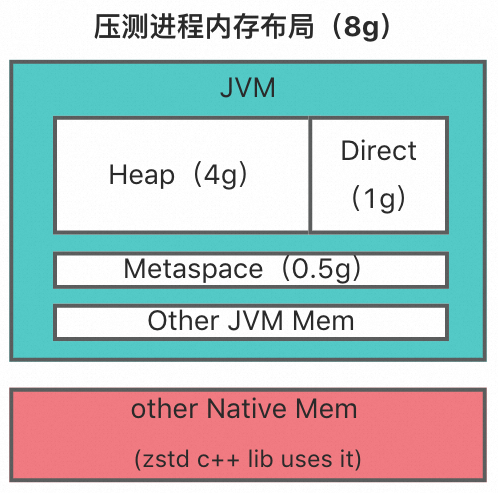
首先,整个应用进程用到的堆外内存分两块:
JVM 堆外内存:在我们的测试应用里,JVM 的堆外内存最大值均为 1g,主要是 netty 使用,即 25%。
zstd 库使用的原生内存:
压缩流程使用原生内存的过程可以简单描述为:创建 zstd ctx 准备压缩 -> 调用 malloc 分配操作系统内存 -> 执行压缩 -> 调用 free 释放内存 -> 释放 zstd ctx。
首先分析源码:
Java 代码:在我们的应用里 zstd ctx 的生命周期为请求级别,且我们通过 Java 埋点确认了请求结束后一定会正确释放。
zstd c++ 代码:zstd 没有额外的内存管理,直接使用 stdlib 的 malloc 和 free 操作内存。在 zstd ctx 创建的时候分配对应的内存块,销毁实例时释放对应的内存块。
理论上不会存在 zstd 相关的内存泄漏
其次,通过对比实验分析:
在未开启 zstd 压缩时,不会出现堆外内存疑似泄漏的问题。而开启 zstd 压缩时,内存会涨到 95%+,远超过 JVM 占用的最大内存。
因此,基本排除 1 的泄漏可能。
接着,分析进程实际内存使用:
使用 jemalloc 对压测到 95% 内存的进程进行内存分析,发现堆外内存主要由 zstd 库持有(其实这个 case 进程内存最终降下来了,但当时未查明原因。)
使用 jemalloc 内存泄漏检测工具,未检测到 zstd 库代码的内存泄漏。
因此,我们认为 zstd 库对内存的操作大概率没有泄漏。
直到最后,我们尝试升级 JDK 版本,重新压测发现 QPS 调零后,内存能够降下来了。而 JDK 版本升级前后的区别在于使用的内存分配器不同:glibc 默认的 ptmalloc vs jemalloc。因此我们怀疑内存泄漏和内存分配器有关。
内存分配器是什么?
内存分配器是用来为应用分配和管理操作系统内存的,分配器从操作系统获取内存再自行管理,具体分配、管理、回收策略取决于内存分配器的具体实现。
我们通常使用的内存分配器,即 malloc/free 函数,由 C 标准库 (libc) 提供的,也被称为动态内存分配器,不同的内存分配器对函数有不同的实现。
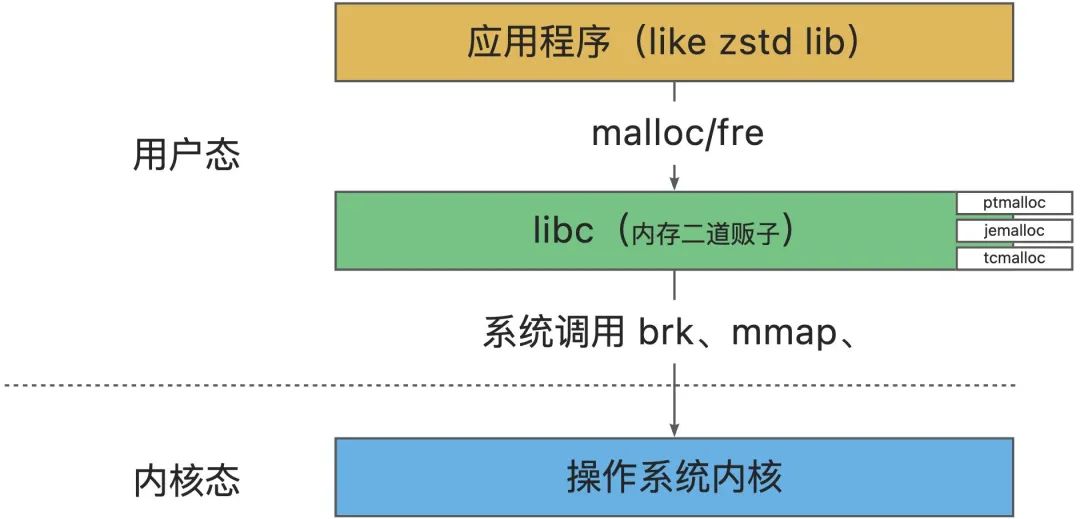
内存分配器的核心思想?
内存分配器的核心是 平衡内存分配的性能和内存使用的效率。前者保证响应快、时间短,后者保证有足够内存可用、不浪费。
内存分配器百家争鸣,但是核心思想都是相似的,只是差在具体的算法和元数据的存储上。内存分配器的核心思想概括起来三条:
内存分配及管理:将内存分为多种固定大小的内存块(Chunk),通过内存块管理和元信息存储策略,使对每个 size class 或大内存区域的访问的性能最优。
内存回收及预测:当用户释放内存时,要能够合并小内存为大内存,根据一些条件,该保留的就保留起来,在下次使用时可以快速的响应。不需要保留时,则释放回系统,避免长期占用。
多线程内存分配:比如通过线程独占内存区间(TLS Thread Local Storage)以降低锁竞争对性能的影响。
几种常见的应用层内存分配器对比
内存分配及管理 | 内存回收及预测 |
链表维护空闲内存块,每次分配时从链首遍历尝试寻找大小合适(但不相等,因此容易产生内存碎片)的空闲内存块,若无,则尝试继续向 OS 申请新内存块(内存扩张,64 位系统下每次申请 64M,Linux 64M 内存块问题就来源于此) |
|
内存管理分为线程 Cache 和中央堆两部分。 为每个线程分配一份线程 Cache,小内存分配从线程 Cache 获取,大内存从中央堆分配。 在需要时从中央堆获取内存补充线程 Cache。 |
|
使用多级大小来优化小块内存的分配;
使用分配区(arena)来维护内存,每个分配区都维护了一系列分页,来提供 small 和 large 的内存分配请求; 每个线程有线程 Cache,且固定选择一个分配区,small 和 large 对象优先从 tcache 分配,其次从线程固定的 arena 分配。 | 从一个分配区分配出去的内存块,在释放的时候一定会回到该分配区。 有两个层面的回收:
|
总的来说,不同的内存分配器有不同的策略,需要根据场景选择:
PTMalloc:是 glibc 默认的内存分配器;存在内存浪费、内存碎片、以及加锁导致的性能问题。
TCMalloc:适合线程的数量、创建,销毁等是动态的场景;在一些内存需求较大的服务(如推荐系统),小内存上限过低,当请求量上来,锁冲突严重,CPU 使用率将指数暴增。
JEMalloc:适合线程的数量、创建、销毁等是静态的(比如线程池)的场景。当 JEMalloc 为了容纳更多的线程时,它会去申请新的 Cache,这会导致出现瞬间的性能剧烈抖动。
▐ 解决
由于测试应用使用的 JDK 版本较低,底层 malloc 实现为 glibc 默认的 ptmalloc,存在内存碎片问题,底层使用 jemalloc 即可解决内存碎片问题。

总结与感想
时刻关注代码对应用性能的影响。比如一些容易被忽略的点,堆内外拷贝操作、长时间引用大对象等。
最好不要用 Finalizer,避免降低 GC 回收效率。
堆外内存使用得当,一定程度上能够优化性能,但要注意由此引发的泄漏风险。
尽量控制堆外内存的使用范围,降低业务层编码难度。
在使用堆外内存时可以需要通过显式约定来尽量降低内存泄漏的风险,比如在代码中明确说明 ByteBuf 的使用原则:
a.谁消费谁释放,如果 A 组件将 ByteBuf 传递给 B 组件,则通常交由 B 组件决定是否释放。
b.如果不希望使用者释放,在传给使用者之前,调用一次 .retain() 方法。
写给 netty 的内容,最好是实现了 ReferenceCounted 接口的对象,这样即使 netty 内部出现不预期情况,我们也可以利用 netty 的兜底 release 来释放资源。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法



![实用篇 | 3D建模中Blender软件的下载及使用[图文详情]](https://img-blog.csdnimg.cn/direct/74d038a46213492fadbd0a6f14dcbab9.png)