在做机器学习的时候,构建特征变量有很多时候都是文本型的,比如电影分类的时候的电影标题,房价预测的时候房子地址,股吧评论等......都是文本类型的数据。
文本型数据怎么构建特征,它又不是分类变量不能直接独立热编码或者生成虚拟变量。
NLP深度学习领域早就发明了将文本进行向量化的方法,将文本进行词嵌入变为张量。
但是这一般要借助深度学习的框架才能实现,很多同学不懂深度学习,也没时间装框架。
如果不用深度学习领域的方法,只用sklearn库接口,也是可以处理文本的,将文本变为数值型的特征变量,然后再去进行分类回归等监督学习。
本次带来的案例就是做一个股吧情感预测的文本分类模型,自动预测一个股吧评论是正面情感还是负面情感。是一个典型的2分类问题。
数据展示
如图两个文本文件,一个全是正面情感评论,一个是负面情感评论。

一行代表一个样本,即一个评论。文本已经进行过了停用词去除,分词等处理。
如果是原始的文本数据,不知道怎么进行分词操作,可以看我之前这篇文章的前面的文本数据分词操作处理。
Python深度学习14——Keras实现Transformer中文文本十分类
数据读取
导入常用的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['KaiTi'] #指定默认字体 SimHei黑体
plt.rcParams['axes.unicode_minus'] = False #解决保存图像是负号'
按行读取数据,去掉换行符。变为数据框,并且打上相应的标签。
pos_df = pd.DataFrame([line.replace('\n', '') for line in open('positive.txt',encoding='utf-8').readlines()],columns=['text'])
pos_df['label']=1 #正面标签为1
neg_df = pd.DataFrame([line.replace('\n', '') for line in open('negtive.txt',encoding='utf-8').readlines()],columns=['text'])
neg_df['label']=0 #负面标签为0查看正面情感数据
pos_df.head()
查看负面情感数据
neg_df.head() 
将数据进行合并,然后查看不同标签样本的数量
#合并
df = pd.concat([pos_df, neg_df]).reset_index(drop=True)
#标签0和标签1的数量
sns.countplot(x=df['label'])
#显示图像
plt.show()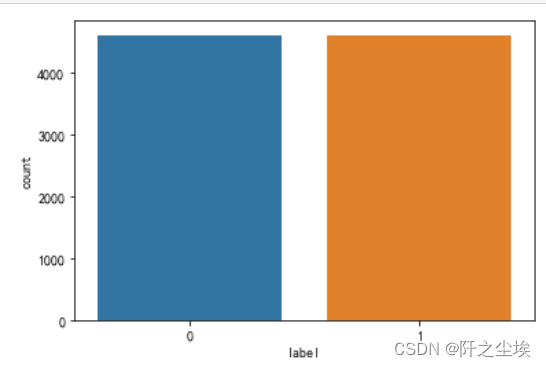
可以看到正面1和负面0都是4000多个样本,很平衡。
词向量化
这里使用TF-idf一种优化了的词频统计向量化的方法,具体原理不多解释,总之就是一种把文本变为数值数据的方法,直接用就行。
取出X和y,对X进行词向量化处理
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
#取出X和y
X = df['text']
y = df['label']
#创建一个TfidfVectorizer的实例
vectorizer = TfidfVectorizer()
#使用Tfidf将文本转化为向量
X = vectorizer.fit_transform(X)
#看看特征形状
X.shape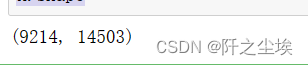
可以看到,X原来是一列文本,现在变成了14503列特征变量,而且都是数值型,可以直接用来建模计算。
查看哪些词语的TF-idf值高:
data1 = {'word': vectorizer.get_feature_names_out(),
'tfidf': X.toarray().sum(axis=0).tolist()}
df1 = pd.DataFrame(data1).sort_values(by="tfidf" ,ascending=False,ignore_index=True)
df1.head(10)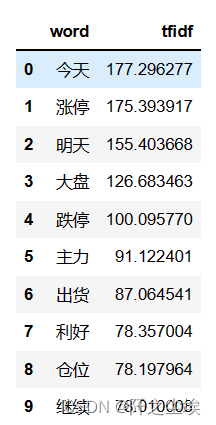
可以简单的理解为TF-idf值越高,这个词汇出现的次数越多,也越重要。可以看到这个股吧评论数据集里面的词汇都是这些‘涨停’,‘大盘’,‘跌停’这些股民常用词汇。
机器学习
划分训练集和测试集
X_train, X_test, y_train, y_test =train_test_split(X,y,test_size=0.2,stratify=y,random_state = 0)
#可以检查一下划分后数据形状
X_train.shape,X_test.shape, y_train.shape, y_test.shape
7371个训练集,1843个测试集。
模型选择
#采用十种模型,对比测试集精度
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import MultinomialNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost.sklearn import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.svm import SVC
from sklearn.neural_network import MLPClassifier生成上面10中模型的实例
#逻辑回归
model1 = LogisticRegression(C=1e10,max_iter=10000)
#朴素贝叶斯
model2 = MultinomialNB()
#K近邻
model3 = KNeighborsClassifier(n_neighbors=50)
#决策树
model4 = DecisionTreeClassifier(random_state=77)
#随机森林
model5= RandomForestClassifier(n_estimators=500, max_features='sqrt',random_state=10)
#梯度提升
model6 = GradientBoostingClassifier(random_state=123)
#极端梯度提升
model7 = XGBClassifier(use_label_encoder=False,eval_metric=['logloss','auc','error'],
objective='binary:logitraw',random_state=0)
#轻量梯度提升
model8 = LGBMClassifier(n_estimators=200,random_state=2)
#支持向量机
model9 = SVC(kernel="rbf", random_state=77)
#神经网络
model10 = MLPClassifier(hidden_layer_sizes=(16,8), random_state=77, max_iter=10000)
model_list=[model1,model2,model3,model4,model5,model6,model7,model8,model9,model10]
model_name=['逻辑回归','朴素贝叶斯','K近邻','决策树','随机森林','梯度提升','极端梯度提升','轻量梯度提升','支持向量机','神经网络']分别进行训练和测试,计算他们在测试集上的准确率
scores=[]
for i in range(len(model_list)):
model_C=model_list[i]
name=model_name[i]
model_C.fit(X_train, y_train)
s=model_C.score(X_test, y_test)
scores.append(s)
print(f'{name}方法在测试集的准确率为{round(s,3)}')
画图查看:
plt.figure(figsize=(7,3),dpi=128)
sns.barplot(y=model_name,x=scores,orient="h")
plt.xlabel('模型准确率')
plt.ylabel('模型名称')
plt.xticks(fontsize=10,rotation=45)
plt.title("不同模型文本分类准确率对比")
plt.show() 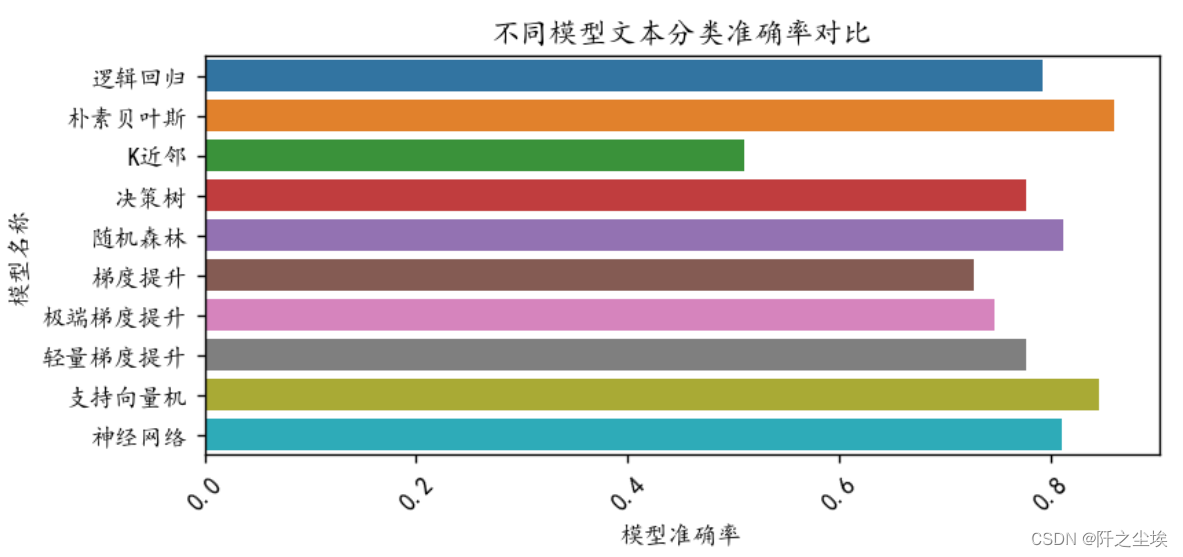
可以看到朴素贝叶斯的准确率最好。事实上这种高度稀疏的数据,朴素贝叶斯的精度都还不错。
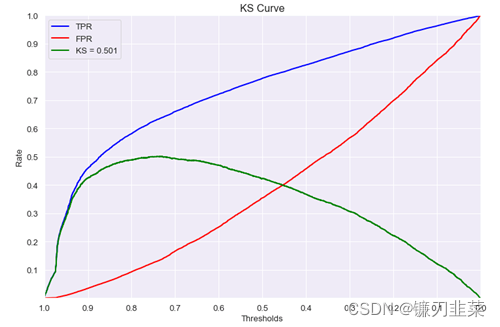
ROC曲线
二分类问题可以画出ROC曲线,计算 对应的AUC值:
from sklearn.metrics import RocCurveDisplay
model=MultinomialNB()
model.fit(X_train, y_train)
RocCurveDisplay.from_estimator(model, X_test, y_test)
x = np.linspace(0, 1, 100)
plt.plot(x, x, 'k--', linewidth=1)
plt.title('ROC Curve (Test Set)')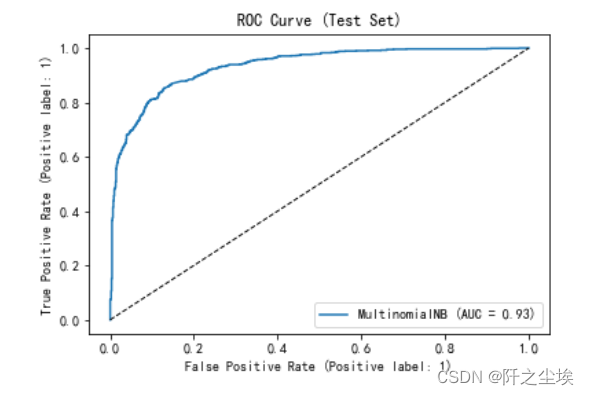
AUC值为0.93,最大为1,说明模型效果很不错。