diffusers pipeline拆解:理解pipelines、models和schedulers
翻译自:https://huggingface.co/docs/diffusers/using-diffusers/write_own_pipeline v0.24.0
diffusers 设计初衷就是作为一个简单且易用的工具包,来帮助你在自己的使用场景中构建 diffusion 系统。diffusers 的核心是 models 和 schedulers。而 DiffusionPipeline 则将这些组件打包到一起,从而可以简便地使用。在了解其中原理之后,你也可以将这些组件(models 和 schedulers)拆开,来构建适合自己场景的 diffusion 系统。
本文将介绍如何使用 models 和 schedulers 来组建一个 diffusion 系统用作推理生图。我们先从最基础的 DDPMPipeline 开始,然后介绍更复杂、更常用的 StableDiffusionPipeline。
解构DDPMPipeline
以下是 DDPMPipeline 构建和推理的示例:
from diffusers import DDPMPipeline
ddpm = DDPMPipeline.from_pretrained("google/ddpm-cat-256", use_safetensors=True).to("cuda")
image = ddpm(num_inference_steps=25).images[0]
image

这就是 diffusers 中使用 pipeline 进行推理生图的全部步骤了,是不是超级简单!那么,在 pipeline 背后实际上都做了什么呢?我们接下来将 pipeline 拆解开,看一下它具体做了什么事。
我们提到,pipeline 主要的组件是 models 和 schedulers,在上面的 DDPMPipeline 中,就包含了 UNet2DModel 和 DDPMScheduler。该 pipeline 首先产生一个与输出图片尺寸相同的噪声图,在每个时间步(timestep),将噪声图传给 model 来预测噪声残差(noise residual),然后 scheduler 会根据预测出的噪声残差得到一张噪声稍小的图像,如此反复,直到达到预设的最大时间步,就得到了一张高质量生成图像。
我们可以不直接调用 pipeline 的 API,根据下面的步骤自己走一遍 pipeline 做的事情:
加载模型 model 和 scheduler
from diffusers import DDPMScheduler, UNet2DModel
scheduler = DDPMScheduler.from_pretrained("google/ddpm-cat-256")
model = UNet2DModel.from_pretrained("google/ddpm-cat-256", use_safetensors=True).to("cuda")
设置timesteps
scheduler.set_timesteps(50)
scheduler.timesteps
# 输出:
tensor([980, 960, 940, 920, 900, 880, 860, 840, 820, 800, 780, 760, 740, 720,
700, 680, 660, 640, 620, 600, 580, 560, 540, 520, 500, 480, 460, 440,
420, 400, 380, 360, 340, 320, 300, 280, 260, 240, 220, 200, 180, 160,
140, 120, 100, 80, 60, 40, 20, 0])
在对 scheduler 设置好总的去噪步数之后,ddpm scheduler 会创建一组均匀间隔的数组,本例中我们将 temesteps 设置为 50,所以该数组的长度为 50。在进行去噪时,数组中的每个元素对应了一个时间步,在之后不断循环的去噪中,我们在每一步会遍历用到这个数组的元素。
采样随机噪声
采样一个与输出图片尺寸相同的随机噪声:
import torch
sample_size = model.config.sample_size
noise = torch.randn((1, 3, sample_size, sample_size), device="cuda")
实现迭代去噪循环
然后我们写一个循环,来迭代这些时间步。在每个 step,UNet2DModel 都会进行一次 forward,并返回预测的噪声残差。scheduler 的 step 方法接收 噪声残差 noisy_residual 、当前时间步 t 和 input 作为输入,输出前一时间步的噪声稍小的图片。然后该输出会作为下一时间步的模型输入。反复迭代这个过程,直到将 timesteps 迭代完。
input = noise
for t in scheduler.timesteps:
with torch.no_grad():
noisy_residual = model(input, t).sample
previous_noisy_sample = scheduler.step(noisy_residual, t, input).prev_sample
input = previous_noisy_sample
以上就是完整的去噪过程了,你也可以使用类似的方式来实现自己的 diffusion 系统。
-
最后一步我们将去噪输出转换为 pillow 图片,看一下结果:
from PIL import Image import numpy as np image = (input / 2 + 0.5).clamp(0, 1).squeeze() image = (image.permute(1, 2, 0) * 255).round().to(torch.uint8).cpu().numpy() image = Image.fromarray(image) image
以上就是基础的 DDPMPipeline 背后实际做的事情了。首先,初始化 model 和 scheduler,然后为 scheduler 设置最大时间步,创建一个时间步数组,然后我们采样一个随机噪声,循环遍历 timestep,在每个 step,模型会预测出一个噪声残差,scheduler 根据这个噪声残差来生成一个噪声稍小的图片,如此迭代,直到走完所有 step。
接下来我们将看一下更复杂、更强大的 StableDiffusionPipeline,整体的步骤与上面的 DDPMPipeline 类似。
解构StableDiffusionPipeline
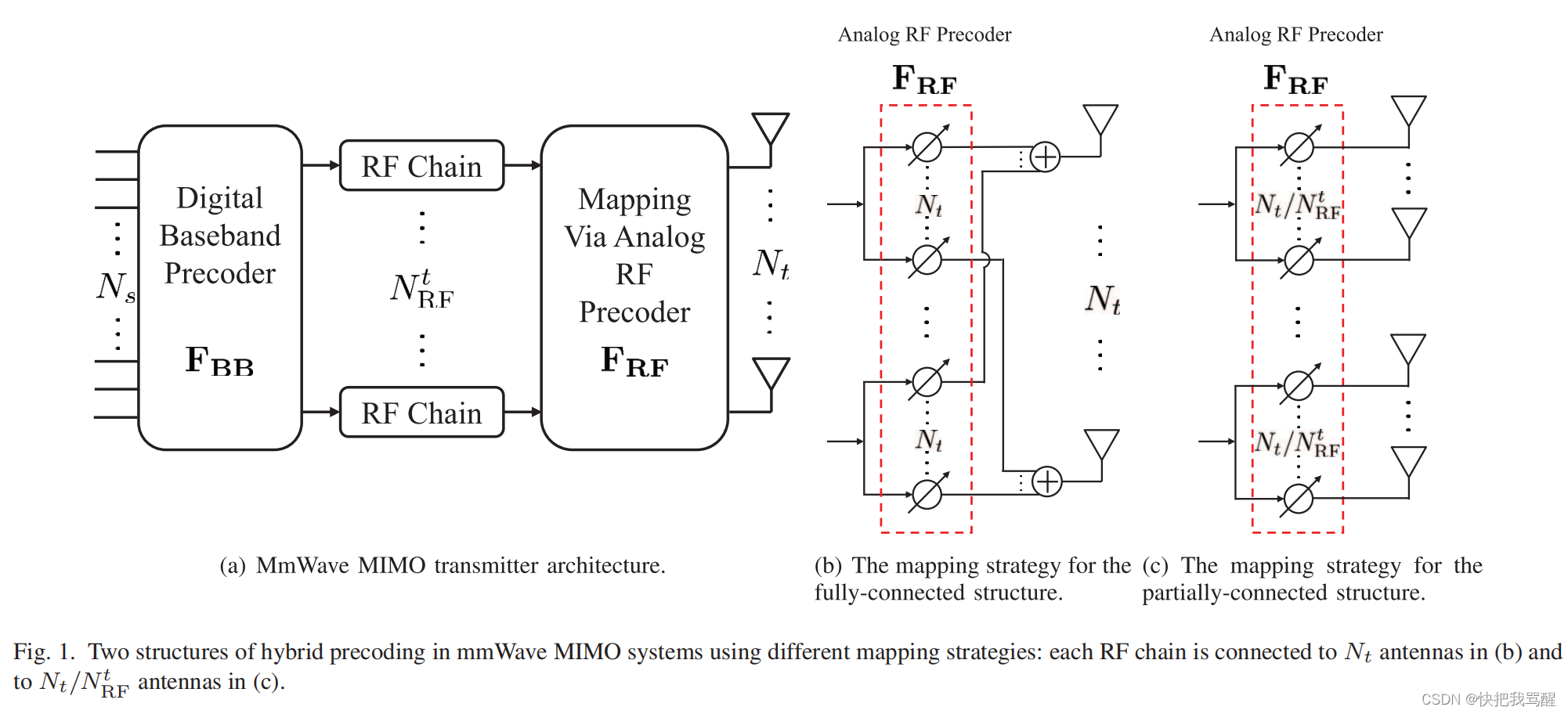
Stable Diffusion 是一种 latent diffusion 的文生图模型。所谓 latent diffusion,指的是其扩散过程是发生在低维度的隐层空间,而非真实的像素空间。这样的模型比较省内存。vae encoder 将图片压缩成一个低维的表示,vae decoder 则负责将压缩特征转换回为真实图片。对于文生图的模型,我们还需要一个 tokenizer 和一个 text encoder 来生成 text embedding,还有,在前面的 DDPMPipeline 中已经提到的 Unet model 和 scheduler。可以看到,Stable Diffusion 已经比 DDPM pipeline 要复杂的多了,它包含了三个独立的预训练模型。
加载模型、设置参数
现在我们先将各个组件通过 from_pretrained 方法加载进来。这里我们先用 SD1.5 的预训练权重,每个组件存放在不同的子目录中:
from PIL import Image
import torch
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae", use_safetensors=True)
tokenizer = CLIPTokenizer.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="tokenizer")
text_encoder = CLIPTextModel.from_pretrained(
"CompVis/stable-diffusion-v1-4", subfolder="text_encoder", use_safetensors=True
)
unet = UNet2DConditionModel.from_pretrained(
"CompVis/stable-diffusion-v1-4", subfolder="unet", use_safetensors=True
)
这里我们使用 UniPCMultistepScheduler 来替换掉默认的 PNDMScheduler。没别的意思,就为了展示一下替换一个其他的 scheduler 组件有多么简单:
from diffusers import UniPCMultistepScheduler
scheduler = UniPCMultistepScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
然后将各个模型放到 cuda 上:
torch_device = "cuda"
vae.to(torch_device)
text_encoder.to(torch_device)
unet.to(torch_device)
配置一些参数:
prompt = ["a photograph of an astronaut riding a horse"] # prompt按自己喜好设置,想生成什么就描述什么
height = 512 # SD 默认高
width = 512 # SD 默认款
num_inference_steps = 25 # 去噪步数
guidance_scale = 7.5 # classifier-free guidance (CFG) scale
generator = torch.manual_seed(0) # 随机种子生成器,用于控制初始的噪声图
batch_size = len(prompt)
其中 guidance_scale 参数表示图片生成过程中考虑 prompt 的权重。
创建 text embedding
接下来,我们来对条件 prompt 进行 tokenize,并通过 text encoder 模型产生文本 embedding:
text_input = tokenizer(
prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt"
)
with torch.no_grad():
text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
我们还需要产生无条件的 text tokens,其完全有 padding token 组成,然后经过 text encoder,得到 uncond_embedding 的 batch_size 和 seq_length 需要与刚刚得到的条件 text embedding 相等。我们将 条件 embedding 和无条件 embedding 拼起来,从而进行并行的 forward:
max_length = text_input.input_ids.shape[-1]
uncond_input = tokenizer([""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt")
uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
采样随机噪声
之前提到,SD 的扩散过程是在低维度的 latent 空间进行的,因此此时采样的随机噪声的尺寸比最终生成图片小。对这个 latent 噪声进行迭代去噪。我们随后会通过 vae decoder 将它解码到真实图片的尺寸,即 512。
vae enoder (在 img2img 中使用, text2img 不需要) 和 vae decoder 分别用于将真实尺寸的图片映射到低维 latent 空间,和将低维 latent 解码为真实图片。由于 vae 有三个降采样层,每次会将图片尺寸缩小一半,从而总共缩小了 2**3=8 倍,因此我们将原图的尺寸缩小 8 倍,得到 latent 空间的噪声尺寸。
# 2 ** (len(vae.config.block_out_channels) - 1) == 8
latents = torch.randn(
(batch_size, unet.config.in_channels, height // 8, width // 8),
generator=generator,
device=torch_device,
)
对图像进行去噪
首先我们要先对噪声进行放缩,乘上一个系数 sigma,这可以提升某些 schedulers 的效果,比如我们刚替换的 UniPCMultistepScheduler:
latents = latents * scheduler.init_noise_sigma
然后,我们写一个循环,将 latent 空间的纯噪声一步步地去噪为关于我们 prompt 的 latent 图。和之前 DDPM 的循环类似,整体上我们要做三件事情:
- 设置 scheduler 的总去噪步数
- 迭代进行这些去噪步
- 在每一步,使用 UNet model 来预测噪声残差,并将其传给 scheduler ,生成出上一步的噪声图片
不同的是,我们这里的 SD 需要做 classifer-guidance generation:
from tqdm.auto import tqdm
scheduler.set_timesteps(num_inference_steps)
for t in tqdm(scheduler.timesteps):
# 我们要做 classifier-guidance generation,所以先扩一下 latent,方便并行推理
latent_model_input = torch.cat([latents] * 2)
latent_model_input = scheduler.scale_model_input(latent_model_input, timestep=t)
# 预测噪声残差
with torch.no_grad():
noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# 进行引导
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# 生成前一步的 x_t -> x_t-1
latents = scheduler.step(noise_pred, t, latents).prev_sample
图片解码
最后一步我们使用 vae decoder 来对去噪之后 latent representation 进行解码生成出真实图片。并转换成 pillow image 查看结果。
# scale and decode the image latents with vae
latents = 1 / 0.18215 * latents
with torch.no_grad():
image = vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1).squeeze()
image = (image.permute(1, 2, 0) * 255).to(torch.uint8).cpu().numpy()
images = (image * 255).round().astype("uint8")
image = Image.fromarray(image)
image

从基础的 DDPMPipeline 到更复杂的 StableDiffusionPipeline,我们了解了如何构建自己的 diffusion 系统。关键就是在迭代去噪循环的视线。主要包含设定 timesteps、遍历 timesteps 并交替使用 UNet model 进行噪声预测和使用 scheduler 进行前一步图的计算。这就是 diffusers 库的设计理念,既可以直接通过封装好的 pipeline 直接生图,也可以用其中的各个组件方便地自己构建 diffusion 系统的 pipeline。
下一步,我们可以:
- 探索其他 diffusers 库中已有的 pipeline,像本文介绍的那样试着自己对其进行结构,并自行从头实现。
- 试着自己构造一个全新的 pipeline 并贡献到 diffusers 库 参考