爬取二手车并将数据保存在数据库中
- 查看网页结构分析爬取步骤
- 解密加密信息
- 将密文解密代码:
- 进行爬取:
- 爬取函数
- 写入解密文件函数和获取城市函数
- 解密文件,返回正确字符串函数
- 保存到数据库
- 运行结果
查看网页结构分析爬取步骤
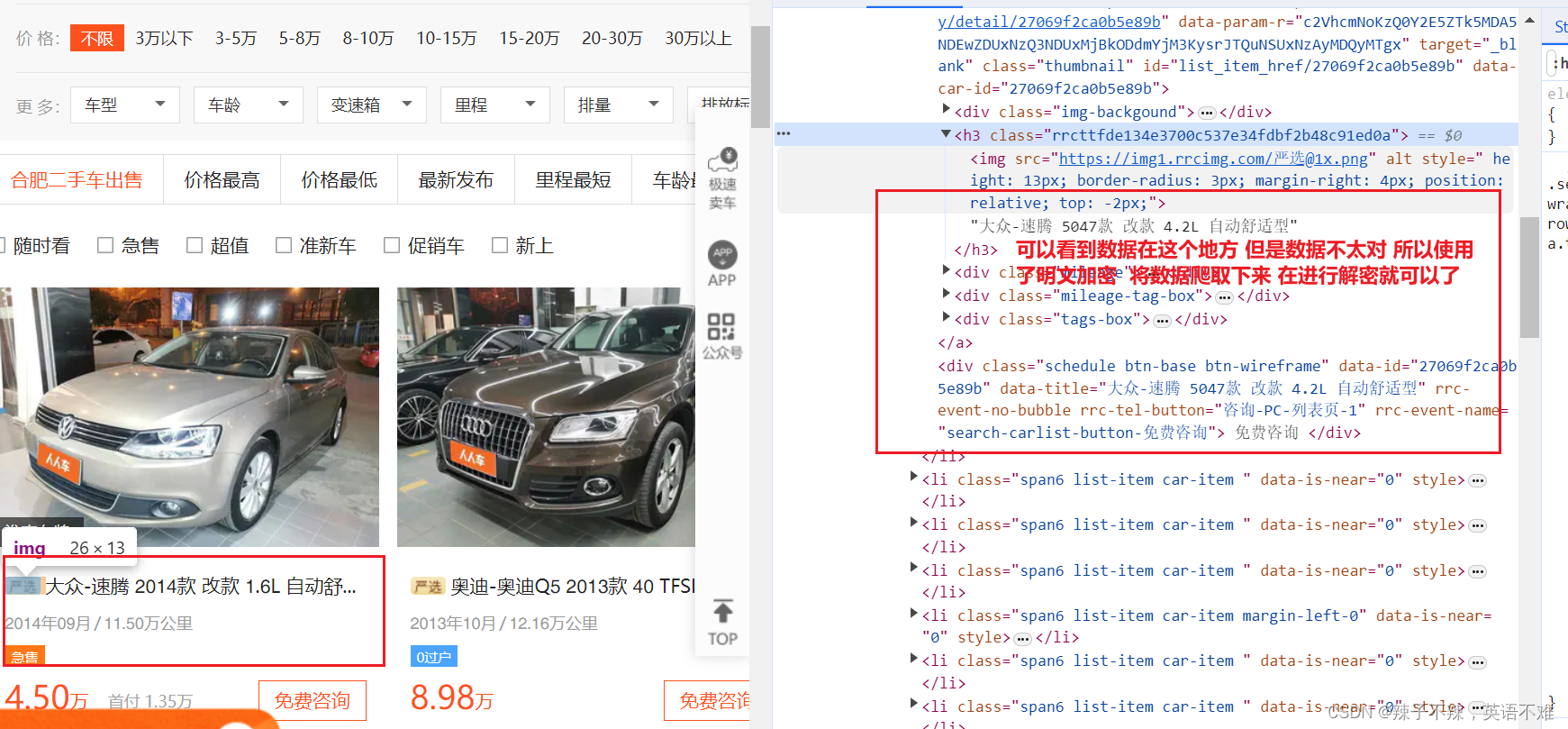
可以看出网页使用了一定的加密
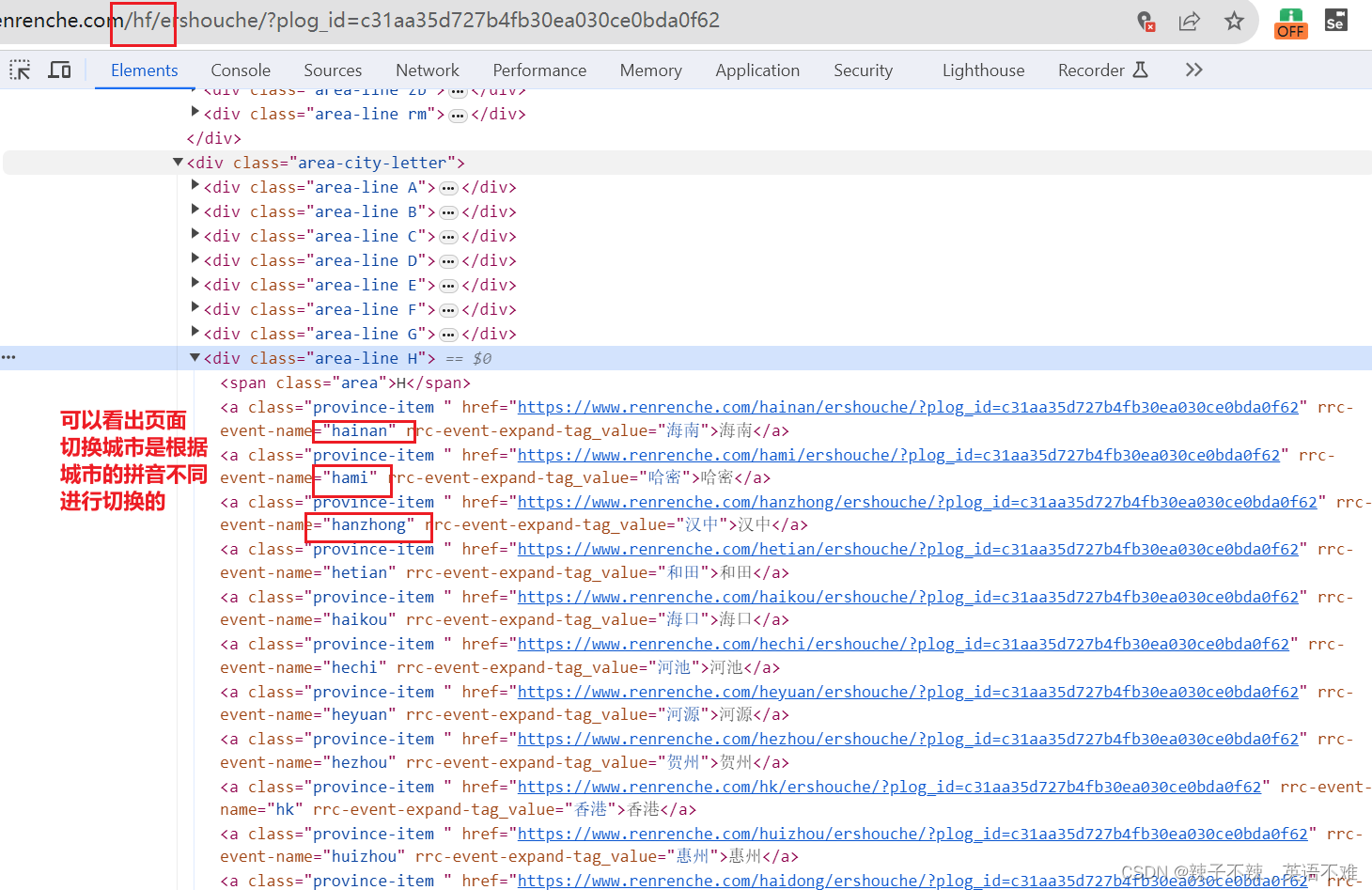
找到城市所在的位置,为之后的城市循环提供方便
解密加密信息
在加密信息的class元素可以看到加密的文件名称

在source下面可以看到此文件 是一个woff文件
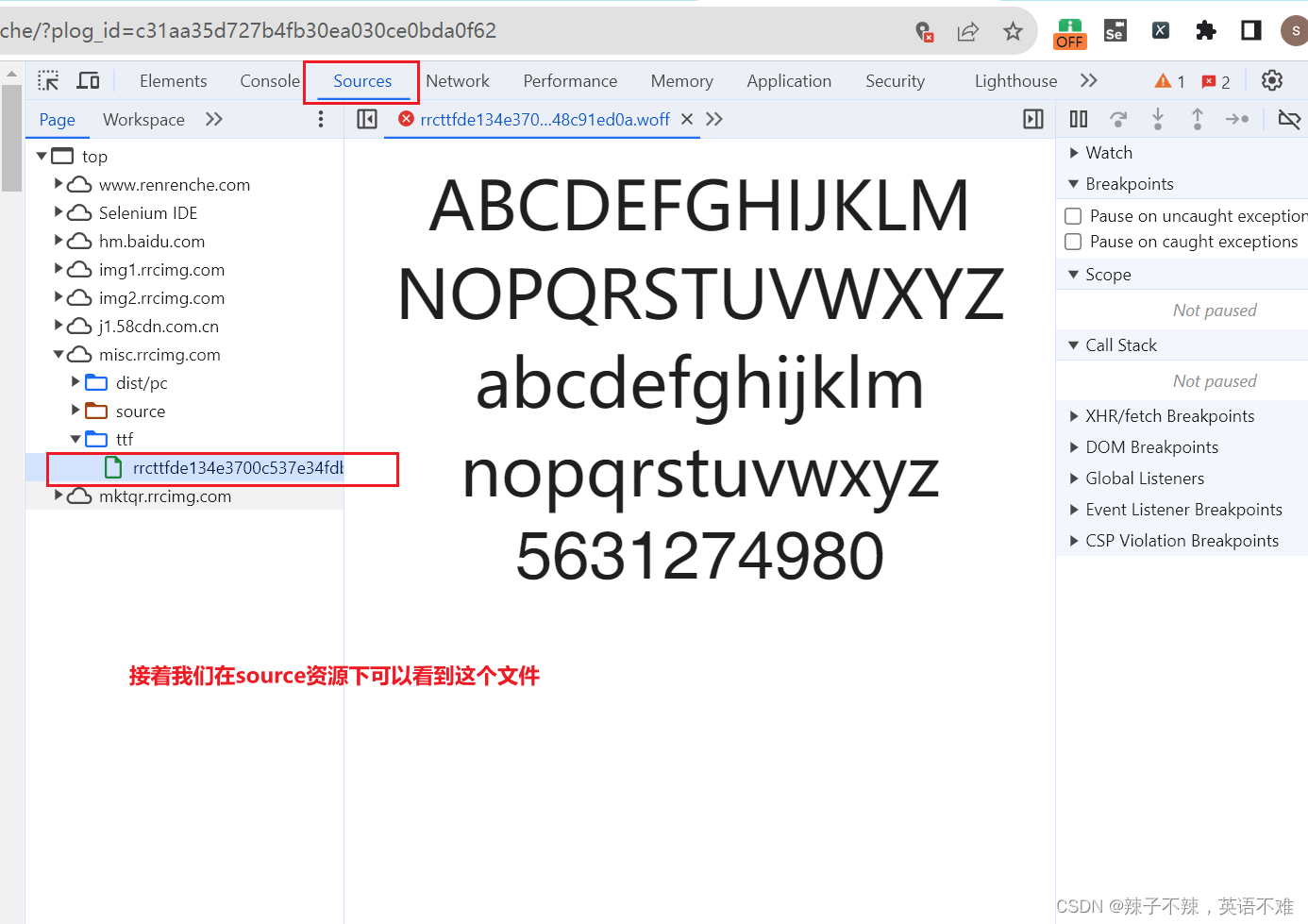
这个woff文件每天都会变化 我们可以在主页中的head下的style下面找到这个woff文件的url链接,此后我们爬取页面时每次都爬一下这个woff文件并且保存下来就可以避免数据错误
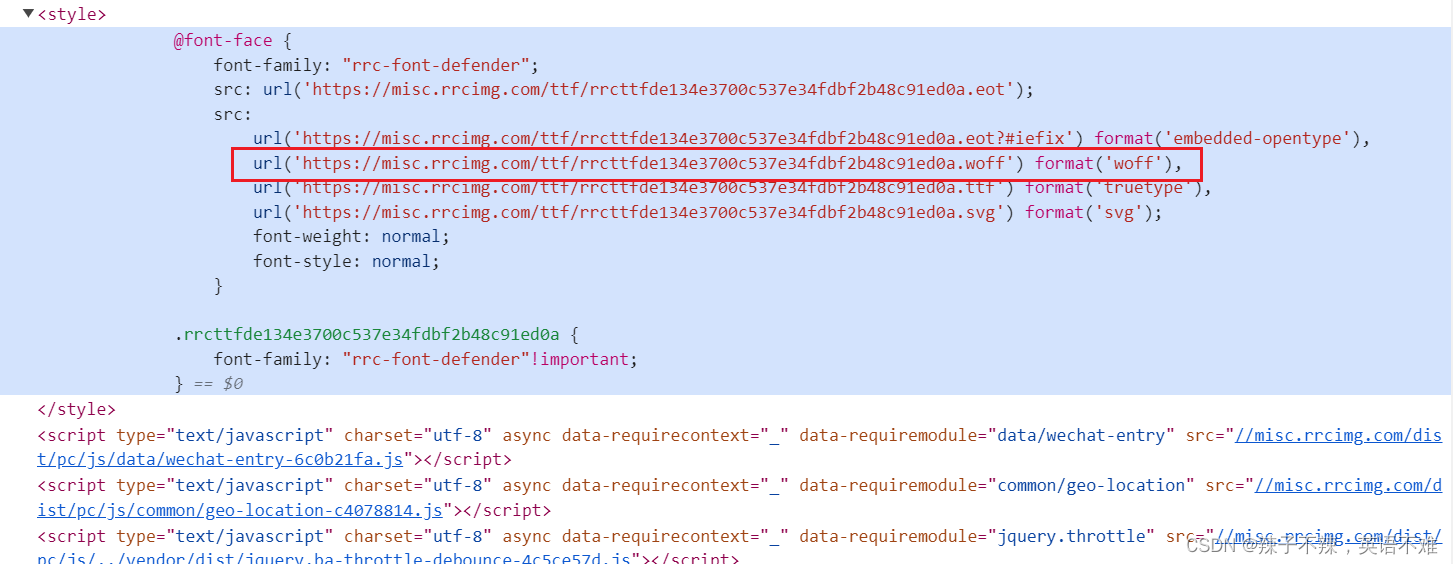
将密文解密代码:
# 读取加密文件进行密令转换
tf = TTFont("./trans.woff")
# 可以打印看一下tf.getGlyphOrder()是什么东西
num_list = tf.getGlyphOrder()[1:]
num_dict = {"zero": 0, "one": 1, "two": 2,
"three": 3, "four": 4, "five": 5,
"six": 6, "seven": 7, "eight": 8,
"nine": 9}
albnum_list = [num_dict[i] for i in num_list]
# 密令转换列表
new_string = ''
for i in old_str:
if i.isdigit():
char = albnum_list.index(int(i))
new_string += str(char)
else:
new_string += i
return new_string
进行爬取:
爬取函数
def spider_data(url,driver,conn,cur):
# 访问汽车信息页面
driver.get(url)
li_list = driver.find_elements(By.XPATH,'//ul[@class = "row-fluid list-row js-car-list"]/li')
print(li_list)
print("开始获取每一个汽车的信息!")
for li in li_list:
# 如果这个页面不为空则进行try
try:
# 找到汽车信息所在的位置
car_info = str_tran(li.find_element(By.XPATH,"a/h3").text)
car_year_mile = li.find_element(By.XPATH, "a/div[@class='mileage']/span").text
car_year = datetime.strptime(str_tran(car_year_mile).split("/")[0],"%Y年%m月").date()
car_mile = re.match('(.*?)万',str_tran(car_year_mile).split("/")[1]).group(1)
car_price_total = li.find_element(By.XPATH, "a/div[@class='tags-box']/div").text
car_price_total = re.match('(.+?)万',car_price_total).group(1)
try: # 如果有首付价格则进行try
car_price_pyment = li.find_element(By.XPATH, "a//div[@class='down-payment']/div").text
except Exception as e: # 没有首付价格 则首付价格等于车价
car_price_pyment = car_price_total
print(car_info,car_year,car_mile,car_price_total,car_price_pyment)
# 保存到数据库中
store_data(car_info,car_year,car_mile,car_price_total,car_price_pyment,conn,cur)
# 页面为空则报告错误 接着下一个汽车信息的爬取
except Exception as e:
print('********************error****************')
print('*********************广告*****************')
写入解密文件函数和获取城市函数
# 获取城市拼音 和 解密的信息列表
def get_city_name(driver):
password_code = []
city_code = []
# 先访问一次页面
driver.get('https://www.renrenche.com/hf/ershouche/p1')
# 找到城市的标签所在位置
div_list = driver.find_elements(By.XPATH,'//div[@class="area-city-letter"]/div')
# 将城市的拼音全部保存到一个列表中
for div in div_list:
a_list = div.find_elements(By.XPATH,'a')
for a in a_list:
city_code.append(a.get_attribute('rrc-event-name'))
# 找到密文所在htm中的位置在style中 获取style标签下的元素内容的方法如下
url_str = driver.find_element(By.XPATH,'//style[1]').get_attribute('textContent')
# 匹配获取woff加密文件的url
woff_url = re.match('[\s\S]+?url\(\'(.*?.woff)\'', url_str).group(1)
# 使用requests请求 将文件用二进制的方式保存下来
response = requests.get(woff_url,headers={'user-agent': fake_useragent.UserAgent().random})
re_cont = response.content
with open('./trans.woff', 'wb') as fp:
fp.write(re_cont)
# 返回城市的拼音
return city_code
解密文件,返回正确字符串函数
# 读取woff文件 然后进行将错误的字符串转化成为正确的字符串
def str_tran(old_str):
# 读取加密文件进行密令转换
tf = TTFont("./trans.woff")
num_list = tf.getGlyphOrder()[1:]
num_dict = {"zero": 0, "one": 1, "two": 2,
"three": 3, "four": 4, "five": 5,
"six": 6, "seven": 7, "eight": 8,
"nine": 9}
albnum_list = [num_dict[i] for i in num_list]
# 密令转换列表
new_string = ''
for i in old_str:
if i.isdigit():
char = albnum_list.index(int(i))
new_string += str(char)
else:
new_string += i
return new_string
保存到数据库
def store_data(car_info,car_year,car_mile,car_price_total,car_price_pyment,conn,cur):
number = 0
insert_sql = f"insert into car_info() values({number},'{car_info}','{car_year}','{car_mile}','{car_price_total}','{car_price_pyment}')"
try:
cur.execute(insert_sql)
except Exception as e:
conn.rollback()
conn.commit()
print("插入数据库完成!")
运行结果
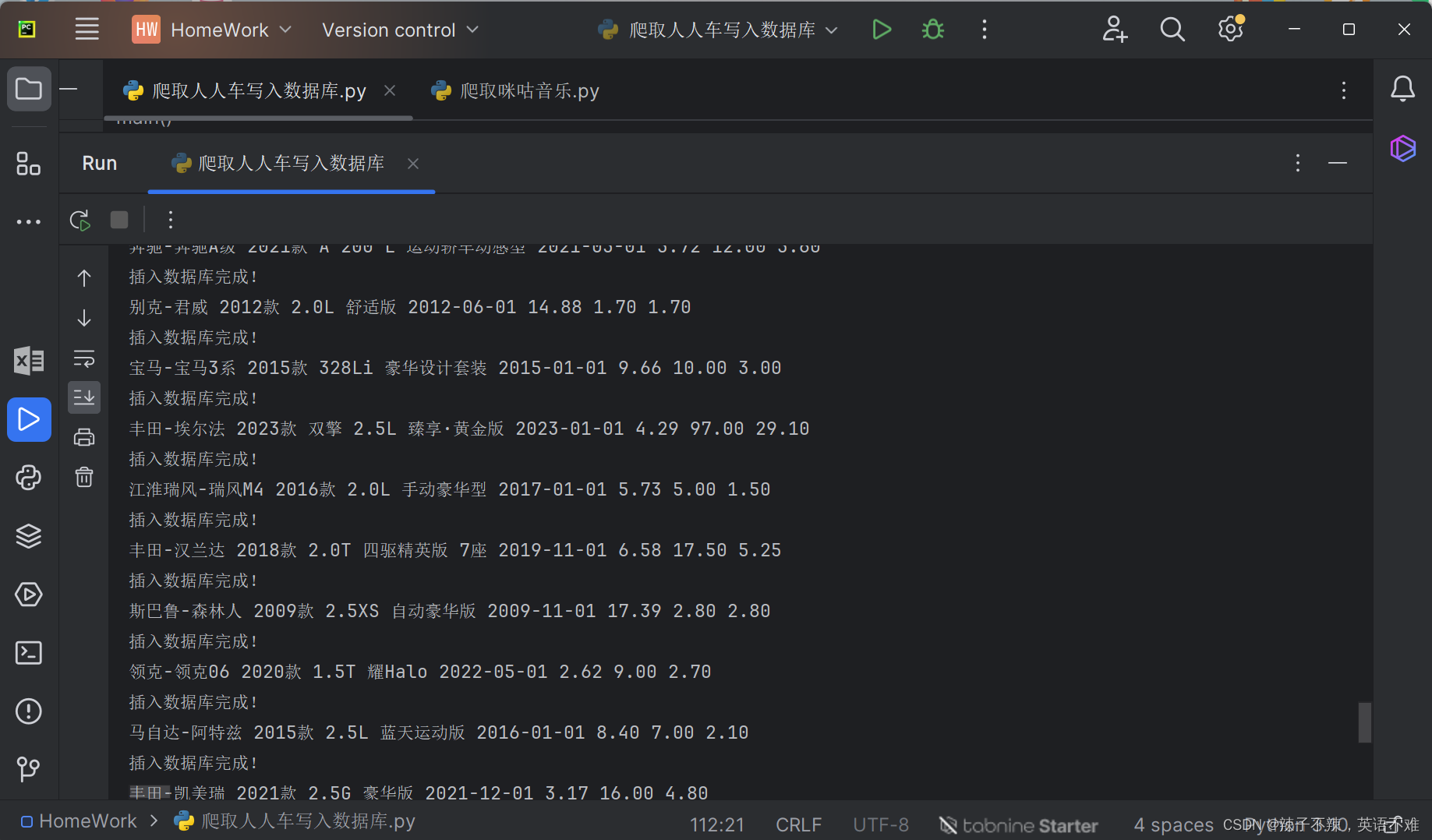
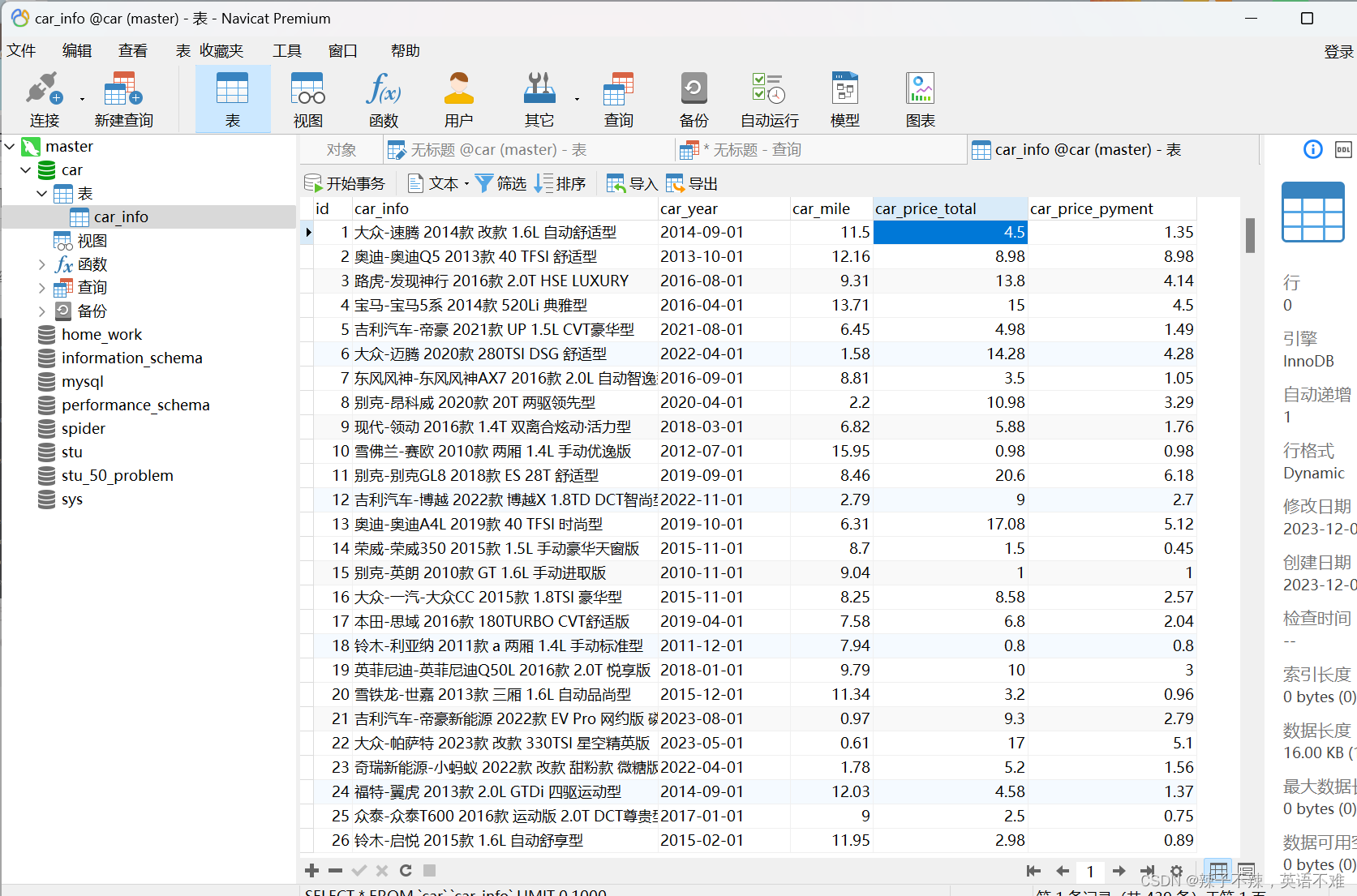



![C++初阶 | [七] (上) string类](https://img-blog.csdnimg.cn/direct/f1733f6ba7354282b4e71ab67d0b49a6.png)