终于可以写MPI了,没想到,刚开始就当头一棒,我按照之前的配置MPI环境,配置完成就报错

好家伙,仔细检查了每一个步骤都没找到问题,上网搜索了一些解决方案,也没有解决。所幸,在配置MPI环境时保存了之前的版本, 又重新配置了MPI环境,还好没问题,不得不说,有时候写代码真的跟玄学一样,但保存备份真的是一个无比好的习惯,赞颂。
目前正在计划实现下面两个阶段

创建网络阶段:主要是神经元的创建和 神经元的连接。
SNN分区阶段:主要是对SNN网络进行分区比如轮询方式,均匀的分配每一个神经元
这两个阶段都在ConnectionManager中实现
// 神经元的邻接表
std::vector<std::vector<int>> global_adjacency;
// 本地的邻接表
std::vector<std::vector<int>> local_adjcency;
//本地的突触集合
std::vector<int> local_node_gids;
//本地神经元集合
std::vector< Neuron* > local_nodes;
//本地突触集合
std::vector< std::vector< Synapse* > > local_synapases;主要是对这些变量进行修改。
目前已经实现了网络的创建阶段,又实现了一个简单的轮询分区阶段
void PartitionManager::perform_partitioning(const std::vector<std::vector<int>>& global_adjacency, std::vector<std::vector<int>>* local_adjacency, std::vector<int>* local_node_gids)
{
partition.resize(global_adjacency.size());
int nPart = kernel().mpi_manager.get_num_processes();
int rank = kernel().mpi_manager.get_rank();
for (int i = 0; i < partition.size(); i++) {
partition[i] = i % nPart;
}
for (int ii = 0; ii < global_adjacency.size(); ii++)
{
if (rank == partition[ii])
{
local_node_gids->push_back(ii);
}
for (int jj = 0; jj < global_adjacency[ii].size(); jj++)
{
//如果与这个节点连接的节点也在该进程
if (partition[global_adjacency[ii][jj]] == rank)
{
(*local_adjacency)[ii].push_back(global_adjacency[ii][jj]);
}
}
}
}我们将分区的数量与进程的数据保持了一致, 创建了如下
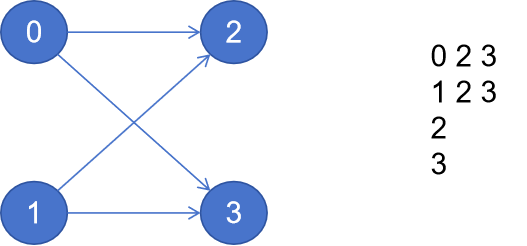
代码执行效果为:

还是很符合预期的。
现在最大的问题是:因为创建SNN网络的时候,种群之间的连接是随机的。如果每个进程都执行一次SNN创建,那么不同进程肯定得到不一样的邻接表。
目前的想法就是设立一个主进程。网络的创建在主进程中实现,然后再分发给其他进程。或者保证每个进程的SNN创建是相同的。
愁人啊