目录
一、线程池的由来
二、线程池的简单介绍
1、ThreadPoolExecutor类
(1)核心线程数和最大线程数:
(2)保持存活时间和存活时间的单位
(3)放任务的队列
(4)线程工厂
(5)拒绝策略
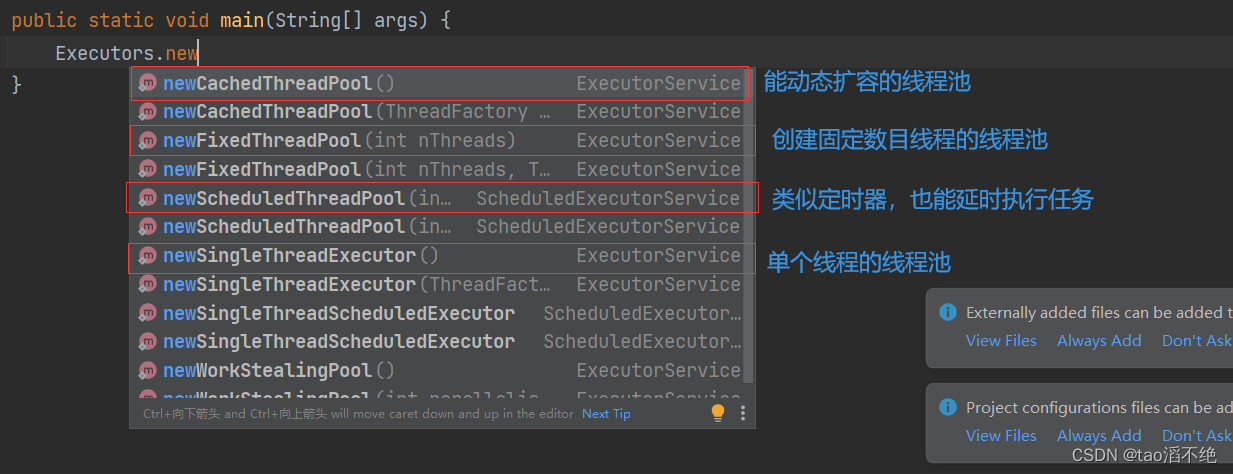
2、Executors类
3、讨论线程池中创建多少线程合适
三、线程池的模拟实现
(1)阻塞队列:存放要执行的任务
(2)submit方法:添加任务的方法,任务添加到队列中
(3)构造方法:指定创建多少个线程,线程在这个构造方法中都创建好了
(4)存放线程的链表:每创建一个线程都放进链表中,这样也能让我们找到某个线程
(5)最终代码( + 测试用例)
都看到这了,点个赞再走吧,谢谢谢谢谢
一、线程池的由来
最开始,进程可以解决并发编程的问题,但是这个代价太大了,于是引入了 “轻量级进程” :线程
线程也能解决并发编程的问题,而且线程的开销比进程要小的多,但是线程如果太多了,创建销毁线程的频率进一步提高,此时的线程创建销毁的开销就不能忽视了。
为了解决上述问题,大佬们给出了两个解决方案:
(1)引入 “轻量级线程”:纤程 / 协程
协程的本质是程序猿在用户态代码中进行调度,不是靠内核的调度器调度的,这样就节省了很多开销;协程是在用户代码中,基于线程封装出来的,可能是N个协程对应1个线程,也可能是N个协程对应M个线程。
(2)引入 “线程池”
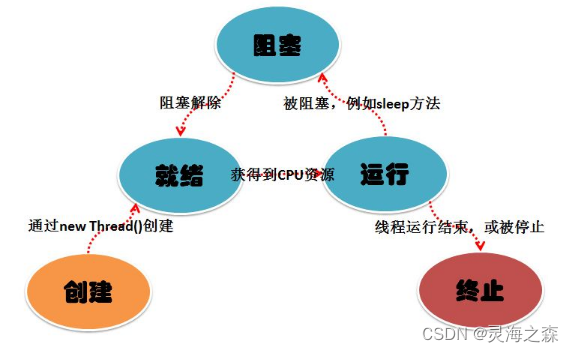
线程池的概念:创建一个线程,这个线程执行完,不会把这个线程给销毁,而是把这个线程放到线程池中,当我们需要用这个线程的时候,再从线程池中拿,不需要的时候,就放在线程池中,并不会销毁它;这样,就省去了频繁的创建销毁线程了。
为啥从线程池中取线程 比 从系统中申请线程的创建更高效呢?
举个栗子:
假设在银行场景中,滑稽老铁要去这个银行办理一个业务,一般银行中大堂有复印机;这时,滑稽老铁没有带身份证复印件,此时滑稽老铁要去搞到身份证复印件,有两个选择,其一选择:把身份证给柜员,让柜员帮滑稽老铁复印,但是这个操作是不可控的,可能这个柜员中途被老板安排了其他活,那这个时候,就不能帮滑稽老铁复印身份证了,要等忙完老板安排的活,再帮滑稽老铁复印身份证;其二选择:滑稽老铁自己去大堂中复印身份证,这样就比较可控了,滑稽老铁可以很快的去到打印机,立马复印出来,再去办理他的业务。如图:

这里的大堂就是用户态,柜台就是内核态,从线程池中取线程,是纯用户态代码(可控) 通过系统申请创建线程,需要内核完成(不可控)
二、线程池的简单介绍
1、ThreadPoolExecutor类
ThreadPoolExecutor参数最多的构造方法,明白了这个构造方法,其他构造方法的参数也就都明白了,如图:

(1)核心线程数和最大线程数:
corePoolSize核心线程数:正式员工线程
maximumPoolSize最大线程数:正式员工线程 + 实习员工线程
举个栗子:一个公司中有10个正式员工,这10个正式员工是不能随便开除的,当这10个正式员工忙不过来的时候,公司为了降低成本,会招聘实习员工,而这几个实习员工是可以随便开除的,当公司稳定一段时间不忙后,就会开除几个实习员工。

(2)保持存活时间和存活时间的单位
KeepAliveTime保持存活时间:实习生线程允许摸鱼的最大时间
unit存活时间的单位:可以是hour 、 min 、 s 、 ms


(3)放任务的队列
和定时器类似,线程池中也可以持有多个任务,要执行的任务,使用Runnable来描述任务。

(4)线程工厂
通过这个工厂类创建线程对象(Thread对象),工厂类里面有方法封装了new Thread的操作,同时给Thread设置了一些属性,我们想要创建线程的时候可以直接使用工厂类的方法创建。
举个栗子:
描述一个点,可以用二维坐标和极坐标来表示:二维坐标:(x,y) 极坐标:(r,α)
这里,通过new一个类来得到一个点,这个类里有两个构造方法,参数分别是(double x,double y),(double r,double α),那么这两个构造方法的参数类型都一样,构成不了重载,如图:
那我们就改方法名不就好了,在使用static修饰,通过不同的方法名获取类,在方法里new一个类,里面设置一些参数,再返回这个类,如图:
这样的的类,就称为工厂类,工厂类里面得到类的方法就称为工厂方法。
总的来说,通过静态方法new了一个对象,在这个静态方法设置不同的属性,构造对象的过程,就称为工厂模式。



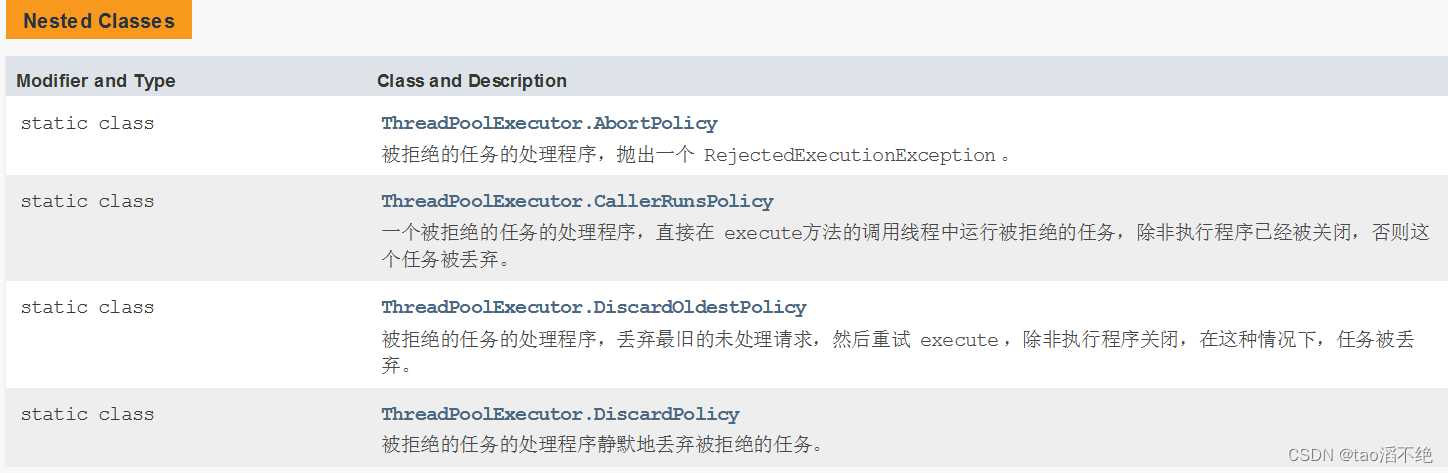
(5)拒绝策略
在线程池中有一个阻塞队列,这个队列容纳线程有上限,如果这个任务队列满了,这时有往再添加任务,会发生啥事?
这就引出了拒绝策略,在线程池中,会有四个拒绝策略,如图:
第一个策略:会直接抛出一个异常,这样,旧的任务执行不了,新的任务也执行不了
第二个策略:把新的任务丢给添加任务队列的线程执行,不给入队列,同时旧的任务依然在执行
第三个策略:把最旧的任务丢弃,添加最新的任务进来
第四个策略:直接把新的任务丢弃了,不执行新的任务,旧的任务会继续执行

2、Executors类
ThreadPoolExecutor类本身使用起来比较复杂,标准库给我们提供了另一个版本:把ThreadPoolExecutor封装了一下,这个类就是Executor类,通过这个类创建出不同的线程池对象,在其内部,已经把ThreadPoolExecutor创建好了,并且设置了一些参数。
Executor的简单使用,其中主要方法有一下4个,如图:
我们创建一个固定线程数目的线程池,再往里添加任务
代码:
public class ThreadPoolTest { public static void main(String[] args) { ExecutorService service = Executors.newFixedThreadPool(4); service.submit(new Runnable() { @Override public void run() { System.out.println("hello word"); } }); } }执行结果:
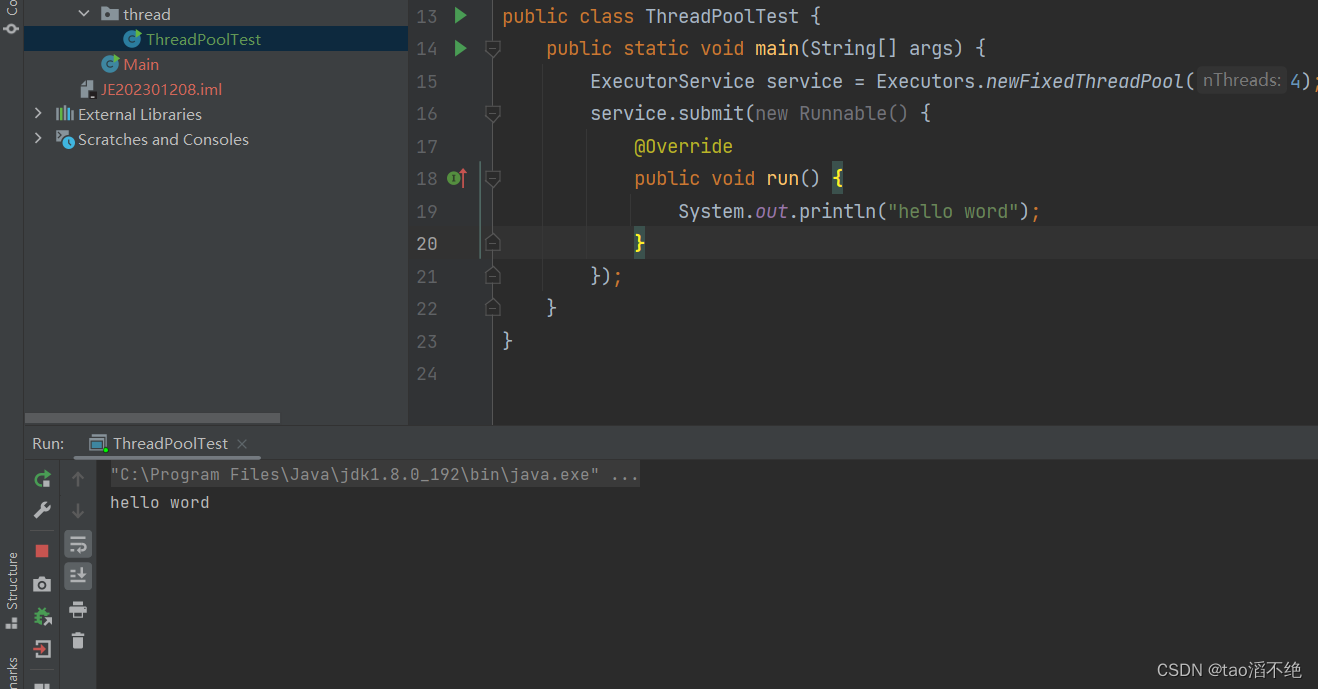
那啥时候使用Executor,啥时候使用ThreadPoolExecutor呢?
网上流传了 阿里巴巴java开发编程规范,里面写了不建议使用Executor,而且一定要使用ThreadPoolExecutor,里面说用ThreadPoolExecutor意味着一切都在掌控之中,可以避免一些不必要的因素;我们可以作为参考,不必奉为金科玉律,他们两各有各的优缺点,这也要以以后入职的公司编程规范为准。
3、讨论线程池中创建多少线程合适
假设一个进程中,所有线程都是cpu密集型,这时每个线程的工作都是在cpu上执行的,此时,线程池中的数目就不应该超过N(cpu的逻辑核心线程数)
如果一个进程中,所有线程都是IO密集型的,这时每个线程的大部分工作都是在等待IO,此时,线程池中的数目就可以远远超过N(cpu的逻辑核心线程数)
上述情况都是极端情况,实际上一个进程中的线程,有cpu密集型的,也有IO密集型的,只是比例不同。由于程序的复杂性,很难直接对线程池进行预估,更准确的做法是通过实验 / 测试的方法,找出合适的线程数目;也就是尝试给线程池设定不同的线程,对不同线程情况线程池执行的效率、性能进行评估,找到合适的线程数目。
三、线程池的模拟实现
模拟线程数目固定的线程池
(1)阻塞队列:存放要执行的任务
代码:
//阻塞队列:存放要执行的任务
private BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(5);(2)submit方法:添加任务的方法,任务添加到队列中
代码:
//提供submit方法,可以添加任务
public void submit(Runnable runnable) throws InterruptedException {
queue.put(runnable);
}(3)构造方法:指定创建多少个线程,线程在这个构造方法中都创建好了
public MyThreadPoolExecutor(int n) {
for (int i = 0; i < n; i++) {
Thread t = new Thread(() -> {
while (true) {
try {
//取出一个任务
Runnable runnable = queue.take();
//执行任务
runnable.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
list.add(t);
}
}解析:线程里面,取出一个任务就执行这个任务,如果队列里没有任务,就会阻塞等待,等有任务,再执行任务,如此循环往复;每创建一个线程,都要放进链表中,也要记得start。
(4)存放线程的链表:每创建一个线程都放进链表中,这样也能让我们找到某个线程
代码:
//存放线程的链表
List<Thread> list = new ArrayList<>();(5)最终代码( + 测试用例)
class MyThreadPoolExecutor {
//存放线程的链表
List<Thread> list = new ArrayList<>();
//阻塞队列:存放要执行的任务
private BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(5);
//提供submit方法,可以添加任务
public void submit(Runnable runnable) throws InterruptedException {
queue.put(runnable);
}
public MyThreadPoolExecutor(int n) {
for (int i = 0; i < n; i++) {
Thread t = new Thread(() -> {
while (true) {
try {
//取出一个任务
Runnable runnable = queue.take();
//执行任务
runnable.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
list.add(t);
}
}
}
public class MyThreadPoolExecutorTest {
public static void main(String[] args) throws InterruptedException {
MyThreadPoolExecutor myThreadPoolExecutor = new MyThreadPoolExecutor(4);
for (int i = 0; i < 1000; i++) {
//变量捕获
int n = i;
myThreadPoolExecutor.submit(new Runnable() {
@Override
public void run() {
System.out.println("执行任务:" + n + ",当前线程:" + Thread.currentThread().getName());
}
});
}
}
}
测试用例:指定线程池的数目为4个线程,添加1000次任务到阻塞队列中,让着4个线程从阻塞队列中拿任务,再执行任务,任务:打印0~1000,并显示是哪个线程打印的;
注意:这里我们打印那里我们不能直接放 i ,这里涉及到变量捕获,不能编译通过,但他们可以在循环里创建一个变量,把 i 的值赋值给这个变量,再打印 n,这样每循环一次,都会创建一个成员变量,这个成员变量也不会变,预期也和我们想要预期效果一样。
执行结果,如图:
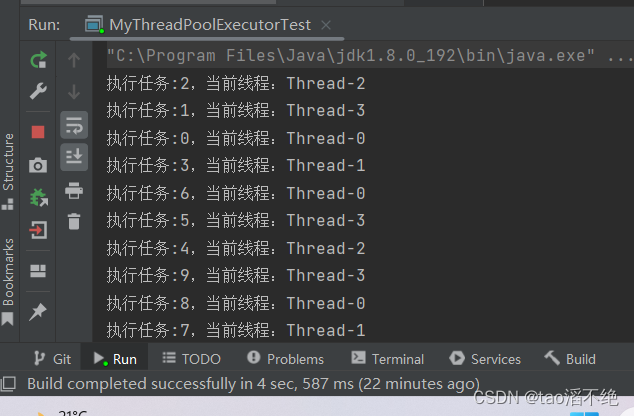
可以看到,并不是顺序打印1~1000的,因为不同线程拿到任务的时机不同,多线程执行的顺序也是随机的。