开门见山,直奔主题,接续前面的知识点:
【图数据库知识点1|图数据库与关系型数据库的区别?】
【图数据库知识点2 | 图思维方式】
【图数据库知识点3 | 图数据库解决了什么问题?】
【图数据库知识点4 | 图计算与图数据库有什么区别?】
【图数据库知识点5 | 图数据库只存不算?】
【图数据库知识点6 | 如何正确评测图数据库?】
【图数据库知识点7 | 为什么你遇到的图数据库不靠谱?】
我们可以开始讨论一个新的知识点:大数据与图数据之异同。
大数据框架与实践早已深入人心,但是,你对大数据的框架越是熟悉,可能对图数据系统的建设就越为不利!
这个知识点的底层逻辑可能会令(一些)人费解。要搞明白个中原因,先要对大数据的框架、流程、机制有个完整的概念,推荐人民邮电出版社2023年新书《揭秘云计算与大数据》。

大数据框架有很多流派,在此无需赘述。但是,绝大多数大数据框架都会落入下面几种架构选型上:
-
存算分离架构:本质上,这就是为批处理、机器学习模式而生的,效率不高,后面再展开分析。
-
流批一体架构:这个架构新锐的数仓很喜欢用,毕竟流数据听起来就很新奇——不明觉厉。
-
内存加速架构:本质上是上面两种架构的一个自然延展,带来了一些性能上的提升,但是距离真正的实时架构存在差距。
-
存算一体架构:这个架构通常在商业化产品中可见,开源的反而不多,这个点也很有趣,后面展开。
因为开源的大数据框架不但多,而且运维体系相对成熟,所以——非常重要的背景知识——这些框架很容易被图数据库创业者或新玩家拿来白嫖。毕竟,大多数人(99%以上)没有能力独立开发一套新的架构。换言之,即便是在中国,没有(至少)1 亿元 RMB + 5 年(含)以上的迭代开发,一款图数据库根本不可能变得成熟+高效。钱与时间,两者相辅相成,缺一不可。那些刚出来 2—3年就已经什么都有、什么都强的产品,想都不用想,100%是白嫖+抄袭的PPT 创业或是大厂KPI项目。
言归正传,上面归纳的几种架构,映射到图数据库上面的时候,就很自然地会出现这么一种情况:无论你是存算分离还是存算一体化,亦或流批图一体化,单一架构能应对所有的场景吗?
答案是明确的:不可能。单一的架构不可能满足所有的应用场景。
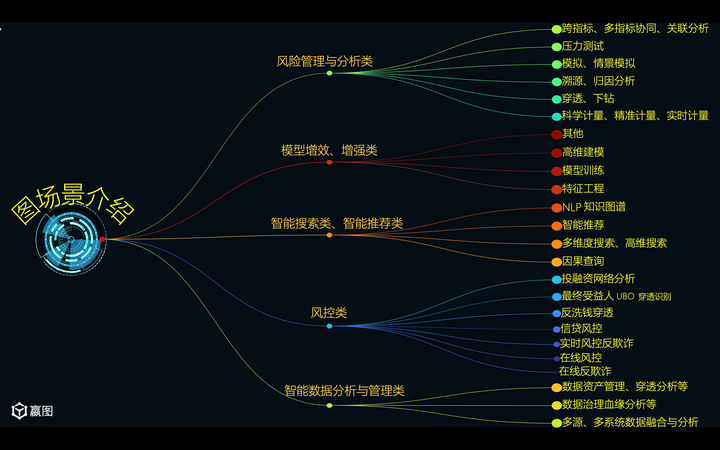
参考上图中的各类场景,我们可以略作对号入座。以存算分离的架构而言,它显然很适合偏重对于时效性要求不高的机器学习类、线下类场景——换言之,就是批处理类场景。存算分离在本质上是分布式的存,但是可能会倾向于以集中式的方式进行计算——这也是存算分离架构的本质,GFS (Google File System) 与 MapReduce这2 篇 20 年前的论文开创了这个领域,而Yahoo!开源的 Hadoop 项目则贡献了完整的HDFS + MR 源代码。今天的存算分离系统,如果不是白嫖 Hadoop,那么就是沿着Hadoop 的技术路线迭代出来的。分布式的存储,当然会让存储(IOPS)的效率变高,然而计算的效率如果还继续分布式,就会变得很低——这个原因有两层:
1. 存储的分布式割裂了数据间的关联关系,因此计算的时候要把分散的数据尽可能向一处归拢!而归拢聚集的过程,必然存在网络传输!当文件或数据块很零碎的时候,传输效率会指数级大打折扣!100Gbps 的效率这个时候还没有 1Gbps 的网卡传输一个大文件高效!通俗一点,就好比车辆不断地在5km/hr启停,始终不能跑到120km/hr高速巡航类似的意思,只不过,更加的dramatic(极端)——这个网络延迟+启停效应会让系统应对图查询(或多表关联)的效率极速变低。
2. 因此,最高效的计算就是把数据尽可能压入(映射过程)到一台高配的服务器的内存里,方便低延迟让CPU 获取数据进行计算。如果这个时候,还是多机计算,效率怎么可能会高过单机的高并发?
这里面又涉及到另一个知识,对于一台服务器的计算能力的低估——大数据框架出现普遍在距今15—20年前,那个时候的CPU 的核数(线程数x1或2),比今天的少了N 倍!而 Hadoop 这种系统,理念上就是用一堆烂机器来做分布式存储,然后凑合着能做数据分析,这个过程并不高效,但是凑合能用。这个系统诞生的历史背景是,Yahoo!内部彼时自研了全套的分布式数据分析系统,基于Linux,甚至把众多的Linux 上原生的很多函数都改造为高并发运行,例如sort 的效率改造后提升了100—1000倍之多——前提是这些数据分析服务器都是当时顶配的服务器(比如 8 核 32GB 内存,注意,当年这就是顶配,而今天,这种配置是垃圾!)。而 Doug Cutting 造Hadoop 则是反其道行之的, 首先它是个边缘项目,其次,他使用的都是其他核心项目废置的低配机器(1—2 核,4GB 内存的水平)。注意,这个里面你应该读出话外之音:Hadoop 并不是 Yahoo!内部的高价值、高优先级系统。这也是为什么它最后被捐献给 Apache Foundation了。我们并不是说 Hadoop 不会高并发(它用的是多服务器并行处理,并非单机上高并发),但是它绝不是一个追求高效的系统。这里面要表达的是:单机100 核的并发计算能力,远超10 台服务器 10 核的并行计算能力,更超越100 台 *1 核的能力—— Again,还是网络交换造成的性能落差——这种性能落差还要大于本地硬盘!这也是存算分离的一个自带特点。但是,我们看到今天中国的数仓和图数据库公司,明摆着的存算分离的架构,各项能力与性能指标却已经上了天了,是不是造假亦或有意误导客户,大家应该心里有数。很多厂家甚至根本就没有并发这一说……如果各位看官看到过中科系的图数据库企业能用ClickHouse + JavaScript 来做图数据库,就明白什么叫做本土特色的软件开发模式了(注:Javascript 天然的是单线程运行)。
需要说明的是,并发有两种。第一种是单个查询的并发,比如环路查询或者多层下钻操作,是否能并发(无论是多线程跑还是多机跑);第二种是多个查询的并发,类似于负载均衡的概念,这个一般都会落在多机上,当然单机上也可以多线程并发。笔者见过奇葩的图数据库选型技术要求是:要保证每个查询都会落在多个服务器节点上,以此来证明是“真”分布式。如上文所述,诸位可以想象,这种分布式的实现得多么低效!每个查询都一定会涉及到网络数据传输,这是分布式系统在计算环节最不愿意看到的。二货们难道不知道,如果来了1 万个类似的查询,那么那几台服务器还不得很快跑死?明明可以像兔子一样极速前进,却非要打折腿当乌龟——这就是所谓的互联网水平分布式带来的科技进步?
国内在技术架构选型上面被互联网们忽悠的都瘸了。当美国同行们试图通过硬件和软件的并发能力来提升算力时候,中国同行们,跟在互联网屁股后面就是一招鲜,我是分布式,我是皇帝数据库,我遥遥领先……尽管很多场景下,所需的数据量并没有很大(千万到亿级的点、边的水平,却一副要处理千亿点边plus的阵仗,很魔幻)。
图数据库里在技术层面上还有个挑战就是如何做数据分片(sharding),这个问题有很多解决方案,但是无论哪种方案,都会降低计算效率。再重申一遍,可能会提升存储(落盘)效率,但是计算效率在很多情况下一定会降低。除非你的查询根本就无关图(离散的查询),那又是另一码事儿了。
图数据的分片方法论:
-
点切:所谓点切就是把一个点与其关联的边分散在多个物理节点上,然后再通过某种 proxy/nameserver 的方式来关联起来,这个过程本质上就引入了更复杂的 lookup/notification/synchronization 机制,所以效率呢?不言而喻。
-
边切:边是一个比顶点复杂得多的数据结构(边天然的就有方向、起点、终点这些必要 meta 数据),因此切边实际上相当于让一条边至少分布在两个服务器节点上……点切与边切都会有各自的特点,前者的践行者(开源者)多一些。无论哪种,遇到的挑战依然是网络延迟、数据交换带来的效率问题!
-
应用决定如何分图:这个相当于按业务场景来构图,然后再决定如何与源数据(数仓比如)对接获取数据——这个和上面两种模式相比,可能是既切点又切边。本质上,所谓分图,就是多图集,一个业务可能对应到多图,多个业务则对应更多的图,基本上是个 M-to-N的对照关系。在多数业务场景中,这种按照业务逻辑与边界来设计图数据建模的方式所获得的效果会优于前两种模式。然而,这种模式遇到喜欢大而全的IT与科技运维部门,就会受到阻挠,again,很魔幻。科技部门就是喜欢一体化运维,全局一张图,妥妥地数仓思维,本质上是懒、怠,阻挠业务发展。
-
虚拟化内外存,但是不分片:国内几乎没有这个领域的尝试,但是海外有从软件或硬件角度来解决这个问题,相当于把多机的内、外存全盘虚拟化,图数据就不再需要考虑分片、分图的问题了——实现了全局一张图。至于效率,提升有限,成本却保证会加倍上涨,这个模式在国内几乎不会看到,不再展开。等经济上行了再说。
还有个知识点,全局一张图:我们知道在数仓时代,有些(金融)机构喊出了全行一张表的概念,实际上这是不可能的。没有人蠢到会用一张大表来表达一切,这是典型的一刀切思维方式。表结构的低维性,注定了一张表的局限性很大很大。这些事为什么数仓不但要分出来好几层(4—5 层),还要无数的中间表、临时表,不一而足。而多表关联,在遇到大数据集时,那真是屋漏偏逢连夜雨,good luck,buddy……那么,图时代,是否全行一张图就能搞定呢?笔者认为,这个也是大忽悠。一张图是不可能放之四海而皆准的。一张图思维是典型的数仓思维。而数仓思维绝对不可能应对比如像在线实时、交互式查询(计算)场景。而且,不同的场景可能会用不同的构图方式,这是由业务特点所导致的需要用不同的数据建模(graph data modeling)所决定的。具体而言,就是点、边、属性都可能会产生转化,以及不同的场景下,还有简单图 vs. 多边图等多种模式,怎么可能能“一张图”完事儿?这也太能忽悠了。读者需要擦亮眼睛,凡是鼓吹全行、全司一张大图的,都是不求甚解的——而且大概率都是从图谱入手来忽悠的,图谱有算力吗?图谱能深度下钻吗?图谱能实时计算不预计算、不缓存、不批处理吗?
前段时间,某国内一线的金融机构采购图数据库系统,6 个存储节点,25 个计算节点,数据规模宣称很大,然而,这个里面我们但凡稍动脑子分析一下:基本上能看出架构上采用了内存映射模式,从6 个存储节点往25 个计算节点映射。这里面6 个节点存200 亿点边,效果那可真是一言难尽。
1. 6个节点对200亿这种存储配置,连高可用都算不上吧——反正就是能分片存下那就是不太可能还有空间做HA高可用?
2. 映射的逻辑,数据就是静态的,更谈不上什么HTAP(TP+AP混搭)。这套架构在本质上和Apache Spark还是一个套路,十几年的老架构了。当然,如果采购方就是要在老路上走,就是 T+1 甚至 T+N的高延迟数据分析,那咱也无话可说。
在后面的知识点中我们会分享为什么映射这个逻辑在有些场景下会非常有问题……稍安勿躁。
最后还有个知识点,普及一下。图数据和大数据的规模一样吗?
答案是:不一样。
我们先假设图数据库和大数据的规模一样,那么,不好意思,您的图系统妥妥得是万亿规模的。很好,这就是目前国内普遍对待图系统的态度。要做系统就是万亿级别的,项目总成本还不能过100 万RMB(甚至 50 万以下)。最好用很多很多低配的机器(反正国内也买不到高配的机器,怎么 low 怎么来)——但是性能指标各项必须顶呱呱。就这,国内的厂家还能在竞标的时候做出:图数据库白送,卖XX 的行为……
现实比小说还魔幻。
言归正传,我们举个例子,数仓或大数据系统里面的数据,99%都是冗余类型的,比如 IOT 数据,都已经到每毫秒采样多少组数据的水平了,每天每组设备都上亿的水平,一年采集的数据百亿规模起,还要存 3 年,多组传感器就是万亿规模。俗话说:Data is new oil, Data is gold... 这些数据难道不得都入图?那不就是万亿规模图吗?
你要是这么用图来分析,那么,很遗憾的告诉你,你这个系统就是 100%的 GIGO 系统。英语补习时间: GIGO = Garbage In, Garbage Out. 中文直译:垃圾进,垃圾出。
以上面的 IOT 场景为例,在图分析里面,你要入图的数据,对于单个传感器而言,无非是平均值、最大、最小值,或者一些其他数学统计值(例如Standard Deviation),这些才更有价值,你的万亿规模纯属障眼法,根本就是心魔。这么压缩后,你的数据恐怕只有百万规模。你是怕规模太小,不好立项吗?你把图系统软件单价提上去不就好了?内卷有意思吗?
所有追求大而全、追求图数仓规模的图数据库系统建设目标的,都违背了实事求是的原则。
写到这里,总觉得应该再说点啥,算了,不说了,都不容易。