点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
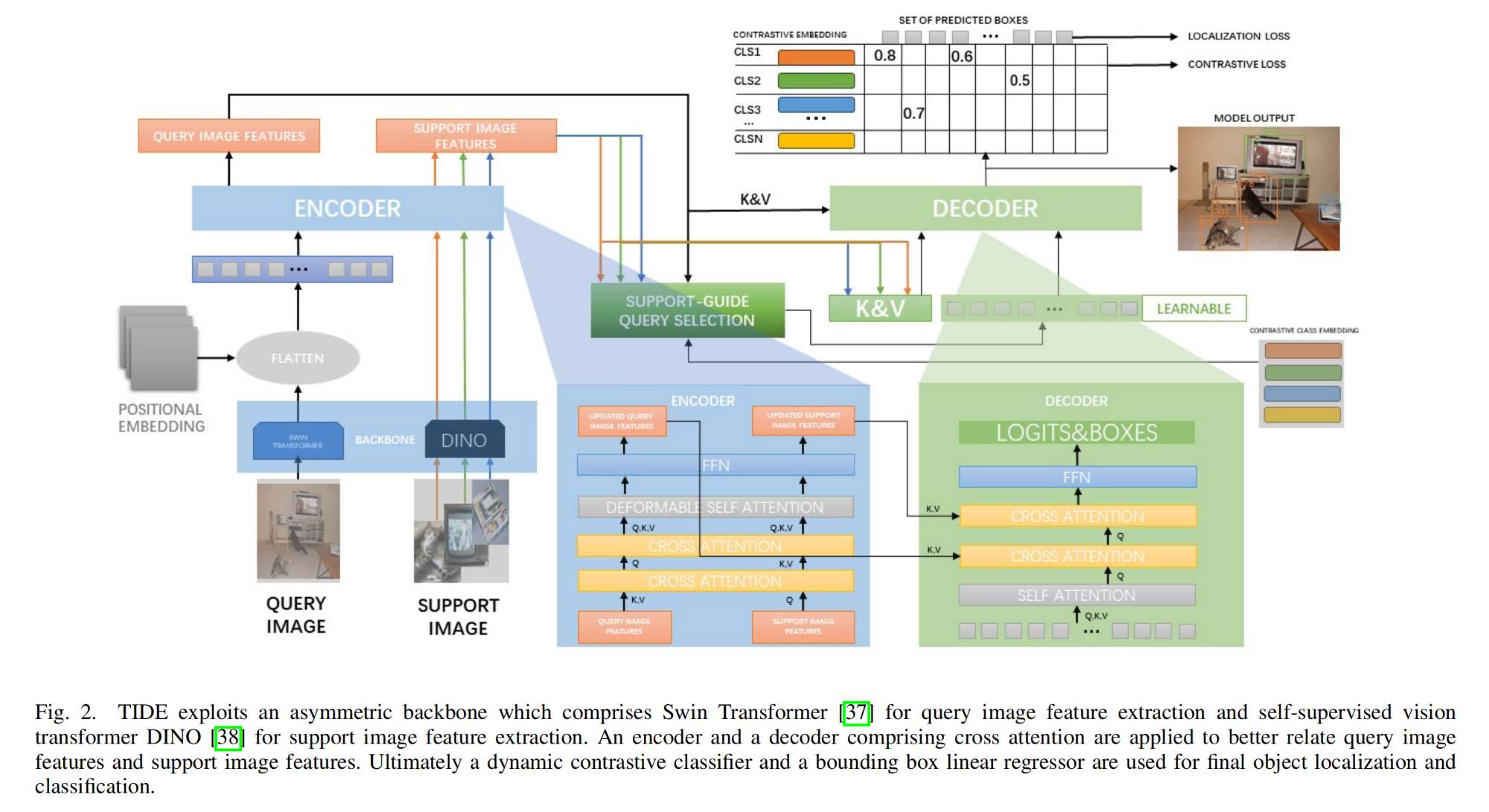
1.【目标检测】TIDE: Test Time Few Shot Object Detection
-
论文地址:https://arxiv.org//pdf/2311.18358
-
开源代码:GitHub - deku-0621/TIDE: FEW SHOT OBJECT DETECTION
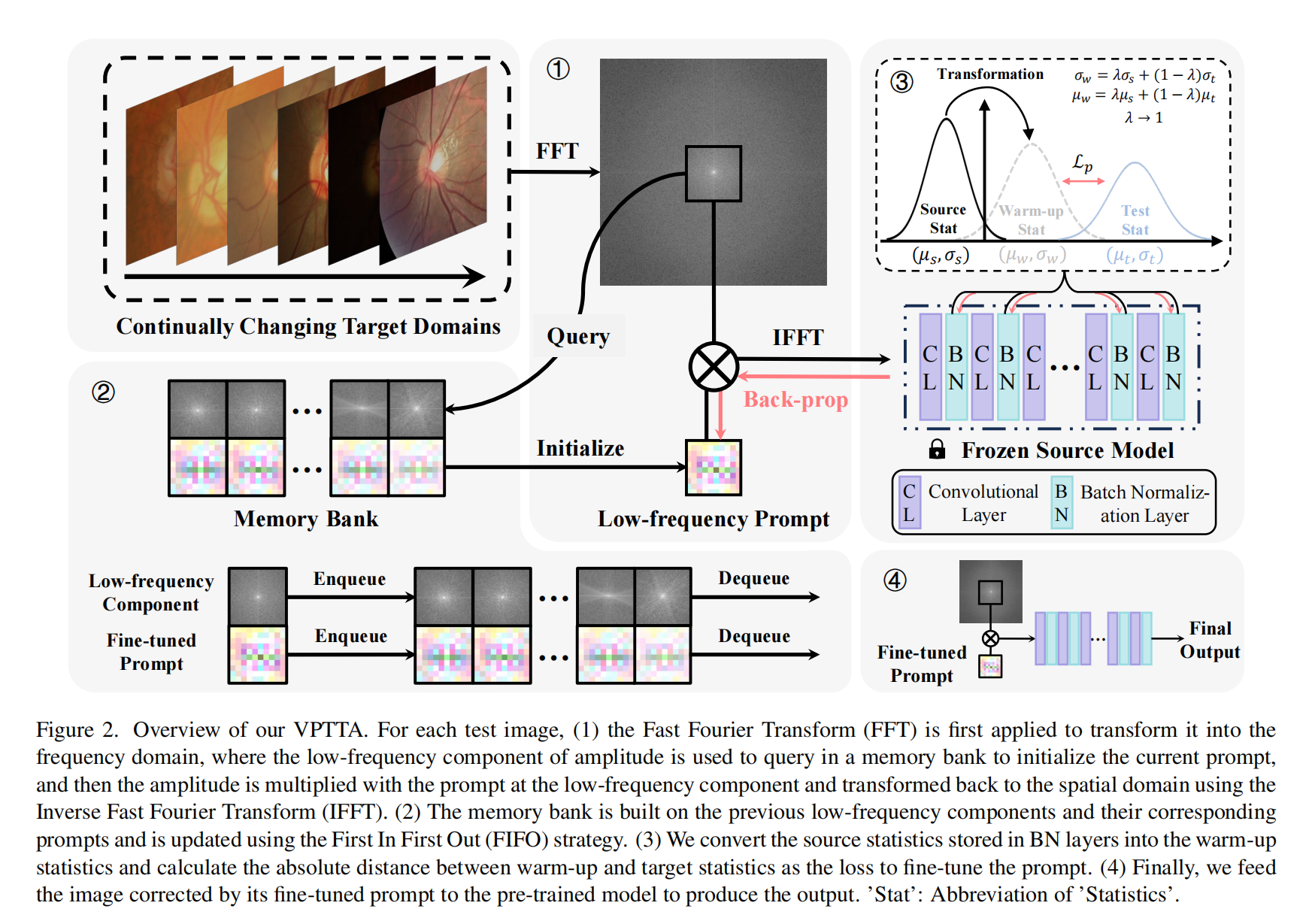
2.【医学图像分割】Each Test Image Deserves A Specific Prompt: Continual Test-Time Adaptation for 2D Medical Image Segmentation
-
论文地址:https://arxiv.org//pdf/2311.18363
-
开源代码(即将开源):GitHub - Chen-Ziyang/VPTTA
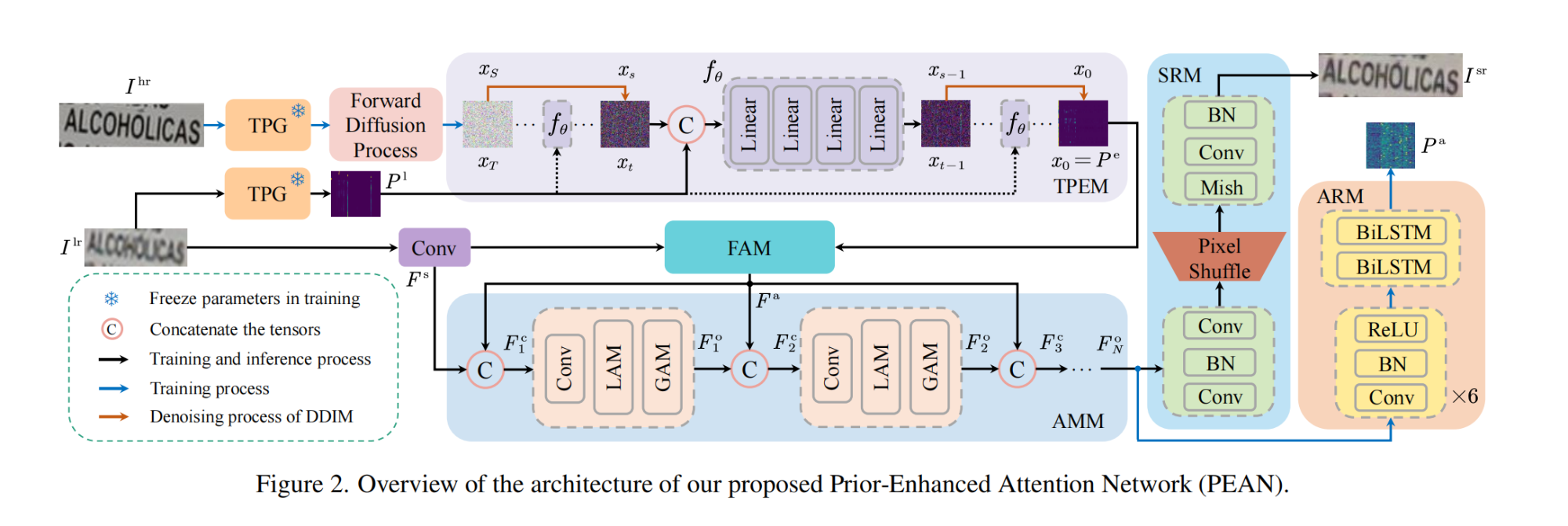
3.【超分辨率重建】PEAN: A Diffusion-based Prior-Enhanced Attention Network for Scene Text Image Super-Resolution
-
论文地址:https://arxiv.org//pdf/2311.17955
-
开源代码(即将开源):GitHub - jdfxzzy/PEAN
4.【动作识别】(NeurIPS2023)CAST: Cross-Attention in Space and Time for Video Action Recognition
-
论文地址:https://arxiv.org//pdf/2311.18825
-
开源代码:GitHub - KHU-VLL/CAST

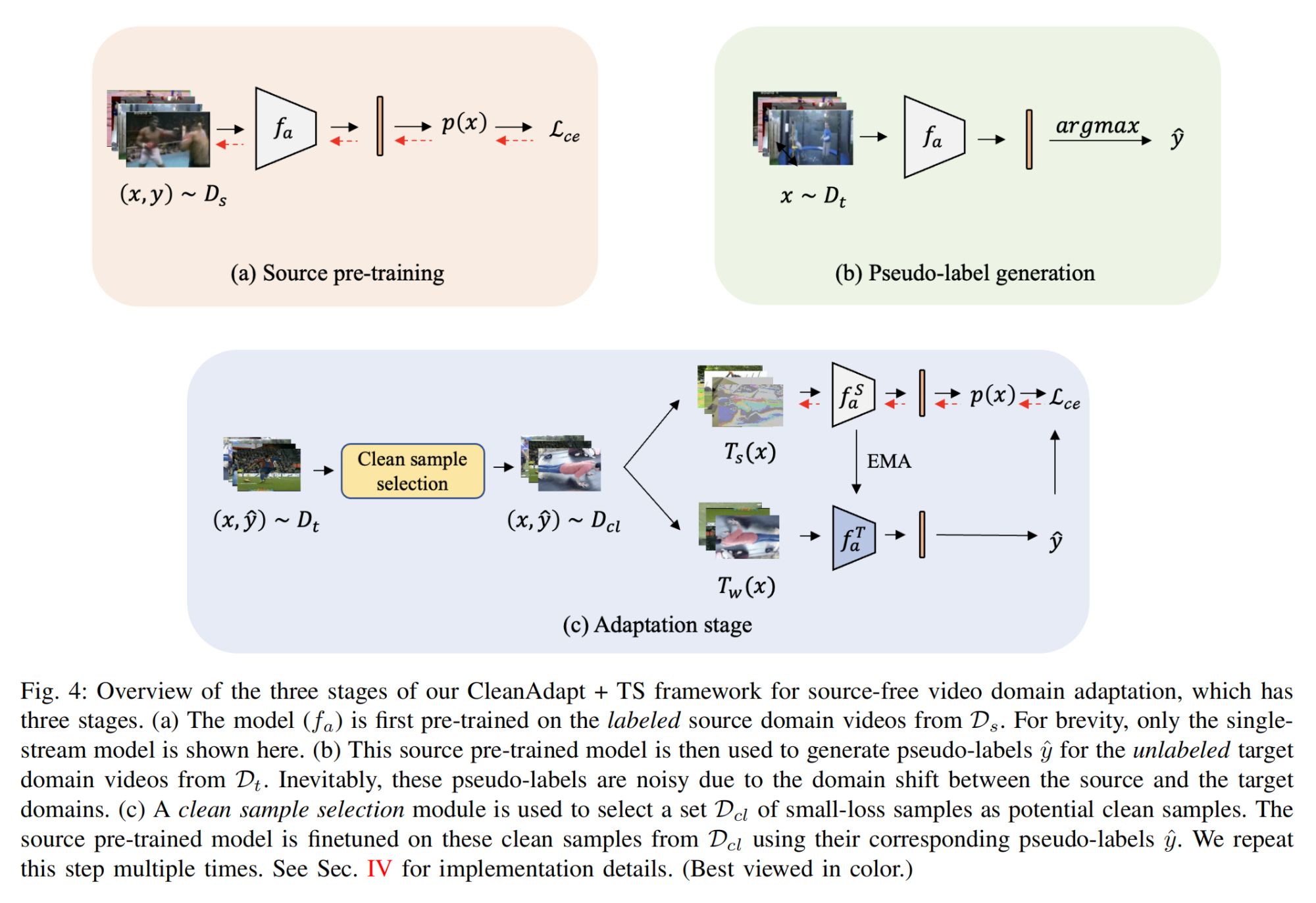
5.【域自适应】Overcoming Label Noise for Source-free Unsupervised Video Domain Adaptation
-
论文地址:https://arxiv.org//pdf/2311.18572
-
工程主页:CleanAdapt
-
开源代码:GitHub - avijit9/CleanAdapt: Code for our Source-free Unsupervised Video Domain Adaptation Paper
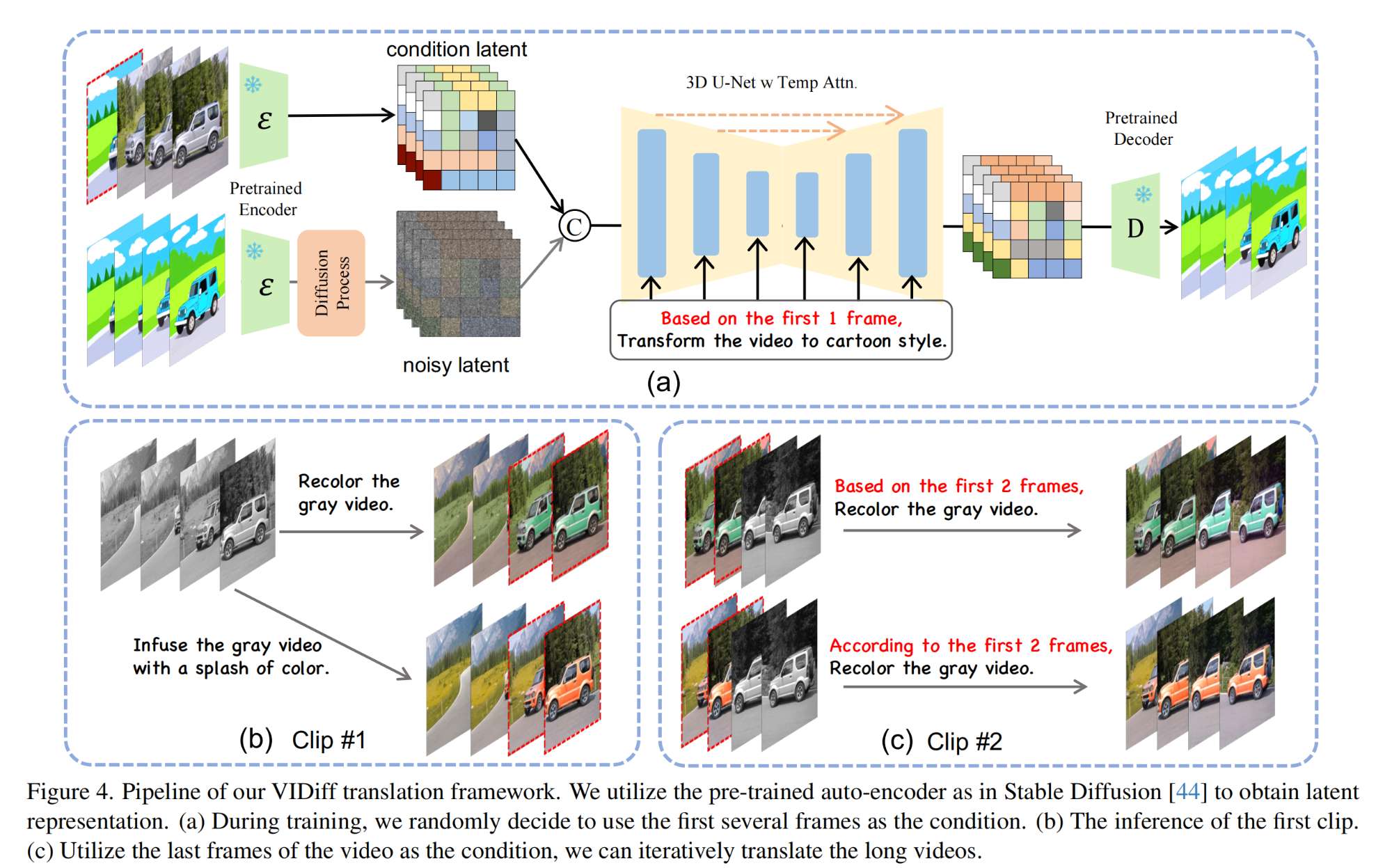
6.【多模态】VIDiff: Translating Videos via Multi-Modal Instructions with Diffusion Models
-
论文地址:https://arxiv.org//pdf/2311.18837
-
工程主页:VIDiff
-
开源代码(即将开源):GitHub - ChenHsing/VIDiff
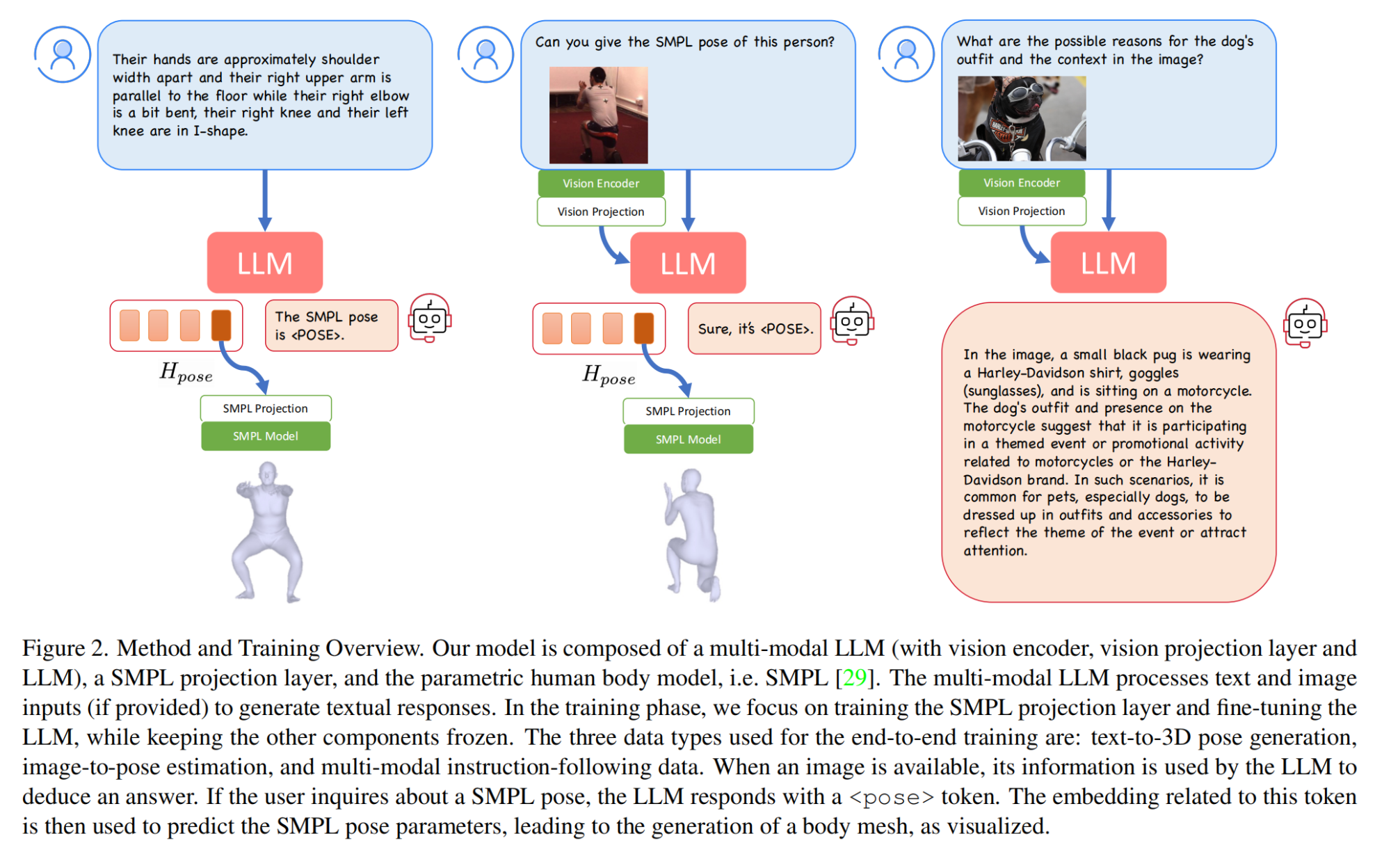
7.【多模态】PoseGPT: Chatting about 3D Human Pose
-
论文地址:https://arxiv.org//pdf/2311.18836
-
工程主页:PoseGPT
-
开源代码(即将开源):GitHub - yfeng95/PoseGPT
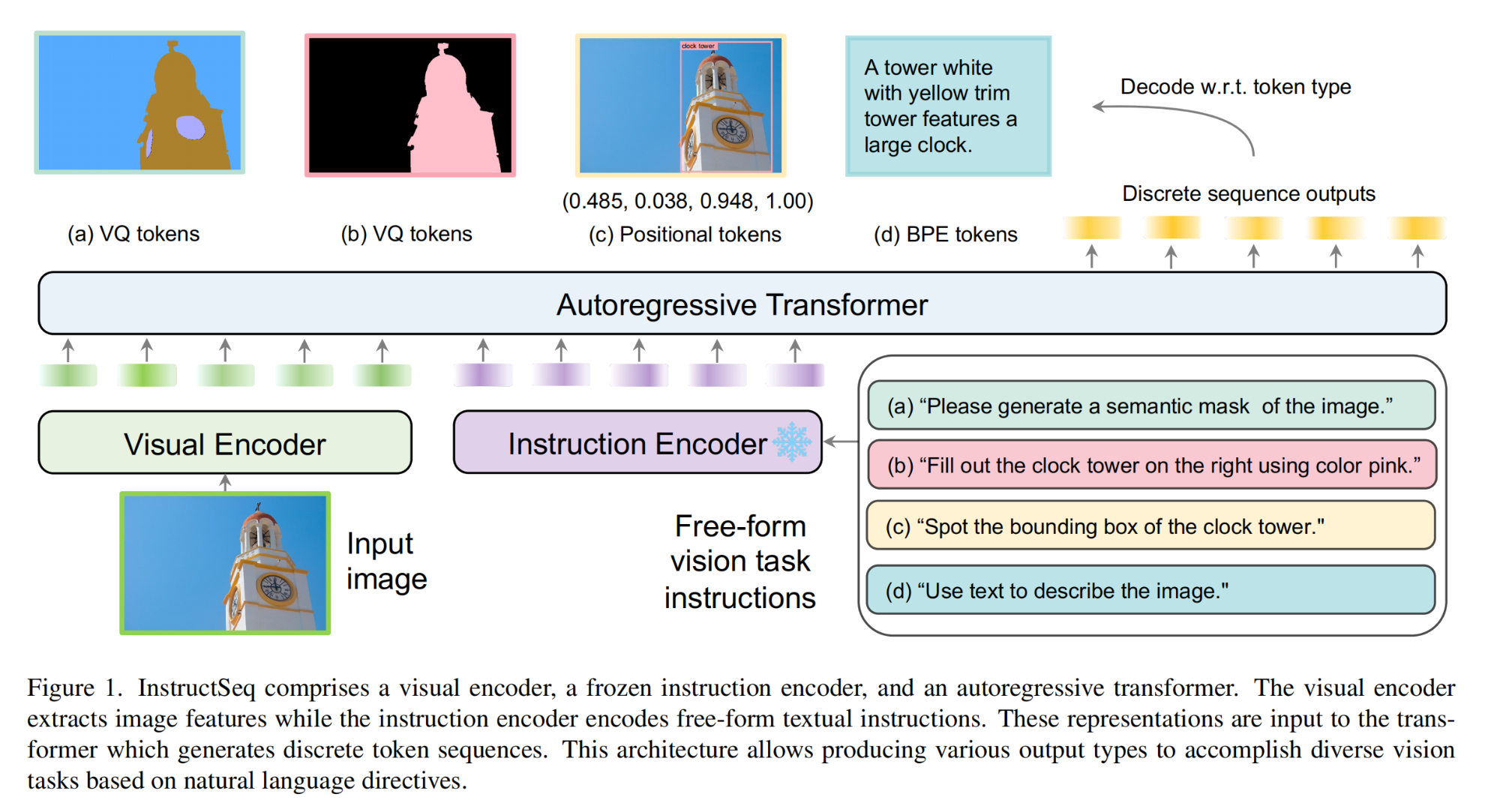
8.【多模态】InstructSeq: Unifying Vision Tasks with Instruction-conditioned Multi-modal Sequence Generation
-
论文地址:https://arxiv.org//pdf/2311.18835
-
开源代码(即将开源):GitHub - rongyaofang/InstructSeq
9.【多模态】ARTV: Auto-Regressive Text-to-Video Generation with Diffusion Models
-
论文地址:https://arxiv.org//pdf/2311.18834
-
工程主页:ART•V: Auto-Regressive Text-to-Video Generation with Diffusion Models
-
开源代码(即将开源):GitHub - WarranWeng/ART.V

10.【多模态】IMMA: Immunizing text-to-image Models against Malicious Adaptation
-
论文地址:https://arxiv.org//pdf/2311.18815
-
开源代码:GitHub - zhengyjzoe/IMMA: Immunizing text-to-image Models against Malicious Adaptation

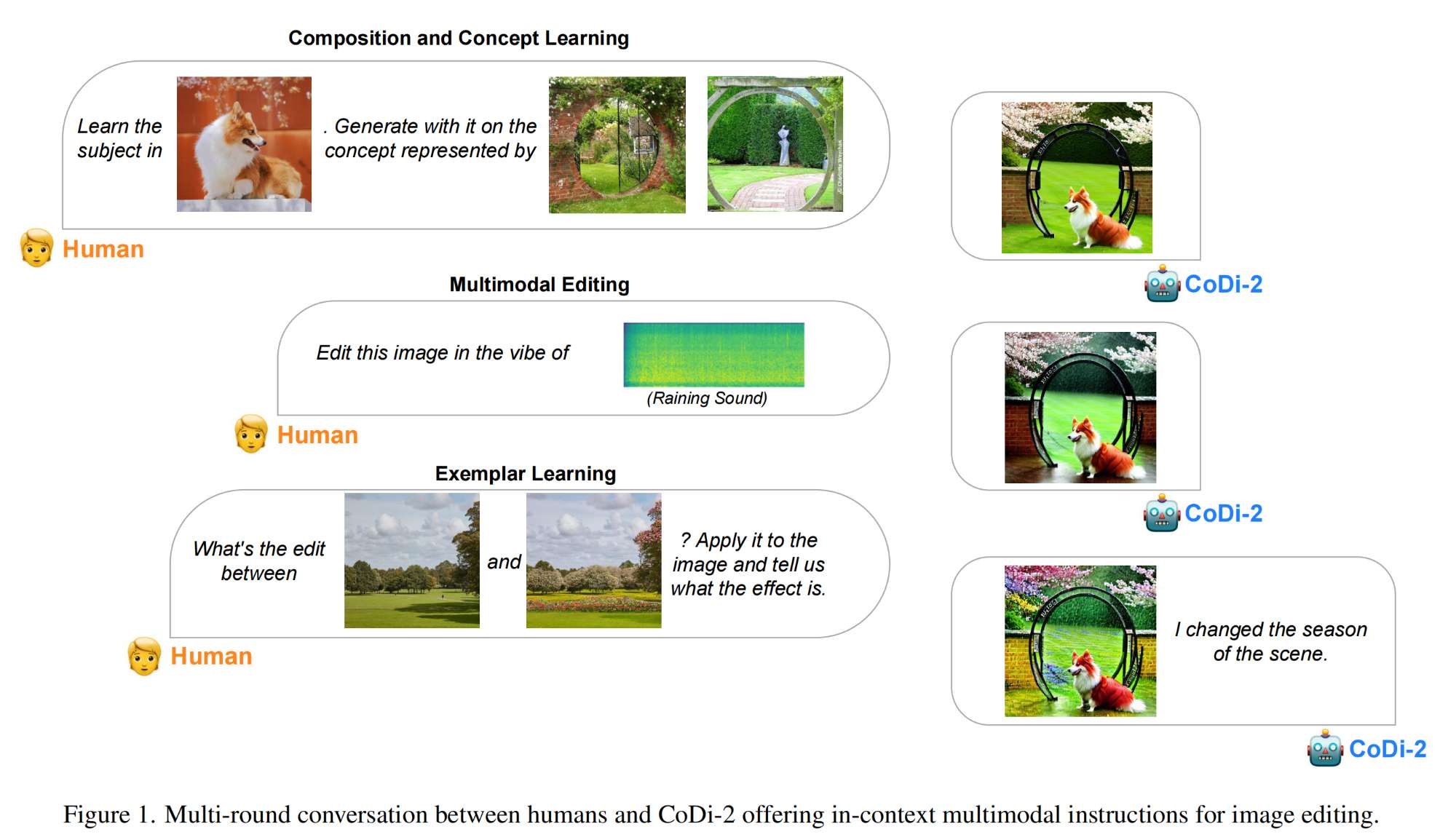
11.【多模态】CoDi-2: In-Context, Interleaved, and Interactive Any-to-Any Generation
-
论文地址:https://arxiv.org//pdf/2311.18775
-
工程主页:CoDi-2: Interleaved and In-Context Any-to-Any Generation
-
开源代码(即将开源):https://github.com/microsoft/i-Code/tree/main/CoDi-2
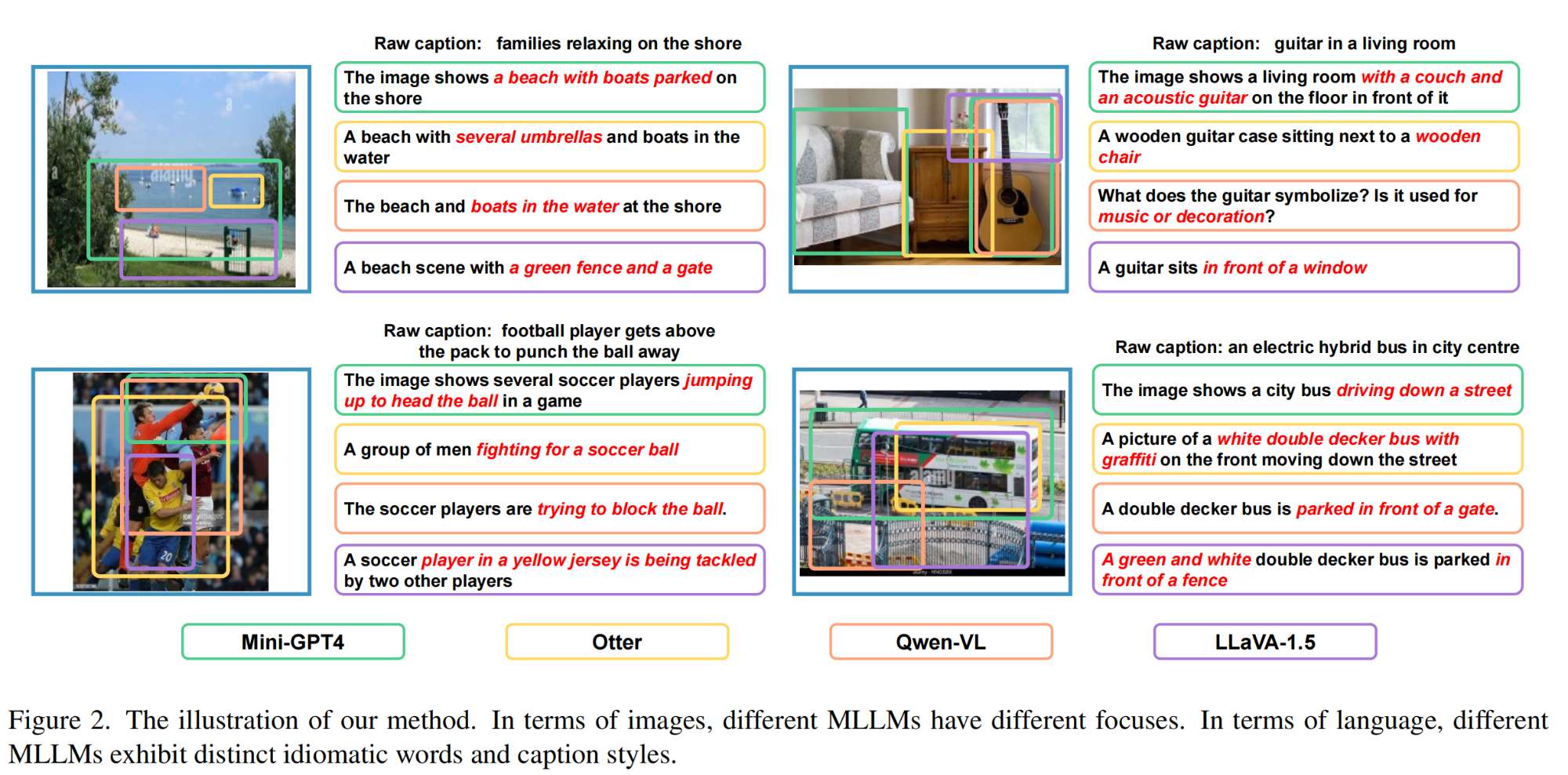
12.【多模态】MLLMs-Augmented Visual-Language Representation Learning
-
论文地址:https://arxiv.org//pdf/2311.18765
-
开源代码(即将开源):GitHub - lyq312318224/MLLMs-Augmented: The official implementation of 《MLLMs-Augmented Visual-Language Representation Learning》
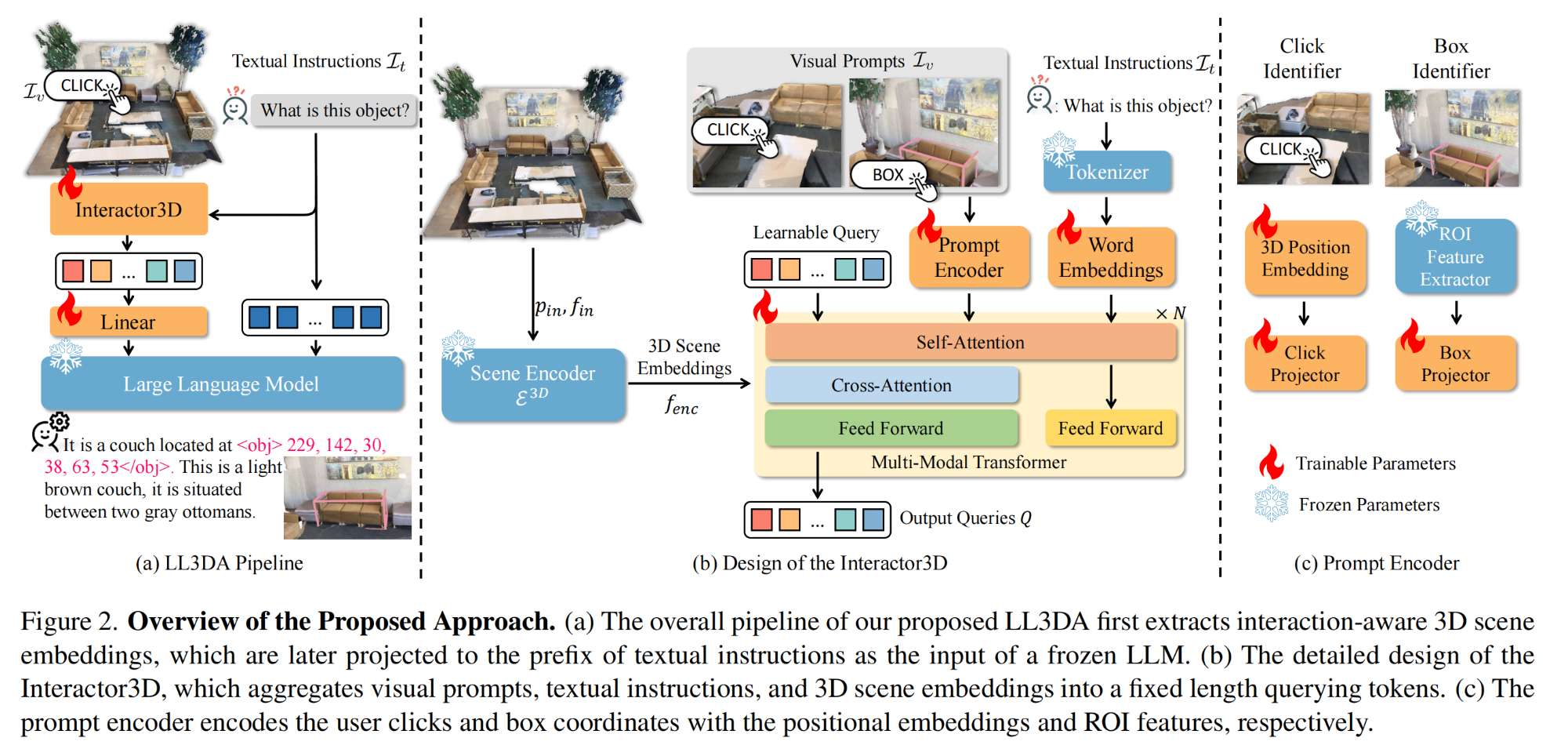
13.【多模态】LL3DA: Visual Interactive Instruction Tuning for Omni-3D Understanding, Reasoning, and Planning
-
论文地址:https://arxiv.org//pdf/2311.18651
-
开源代码(即将开源):GitHub - Open3DA/LL3DA: LL3DA: a Large Language 3D Assistant responding to both textual and visual interactions in complex 3D environments.
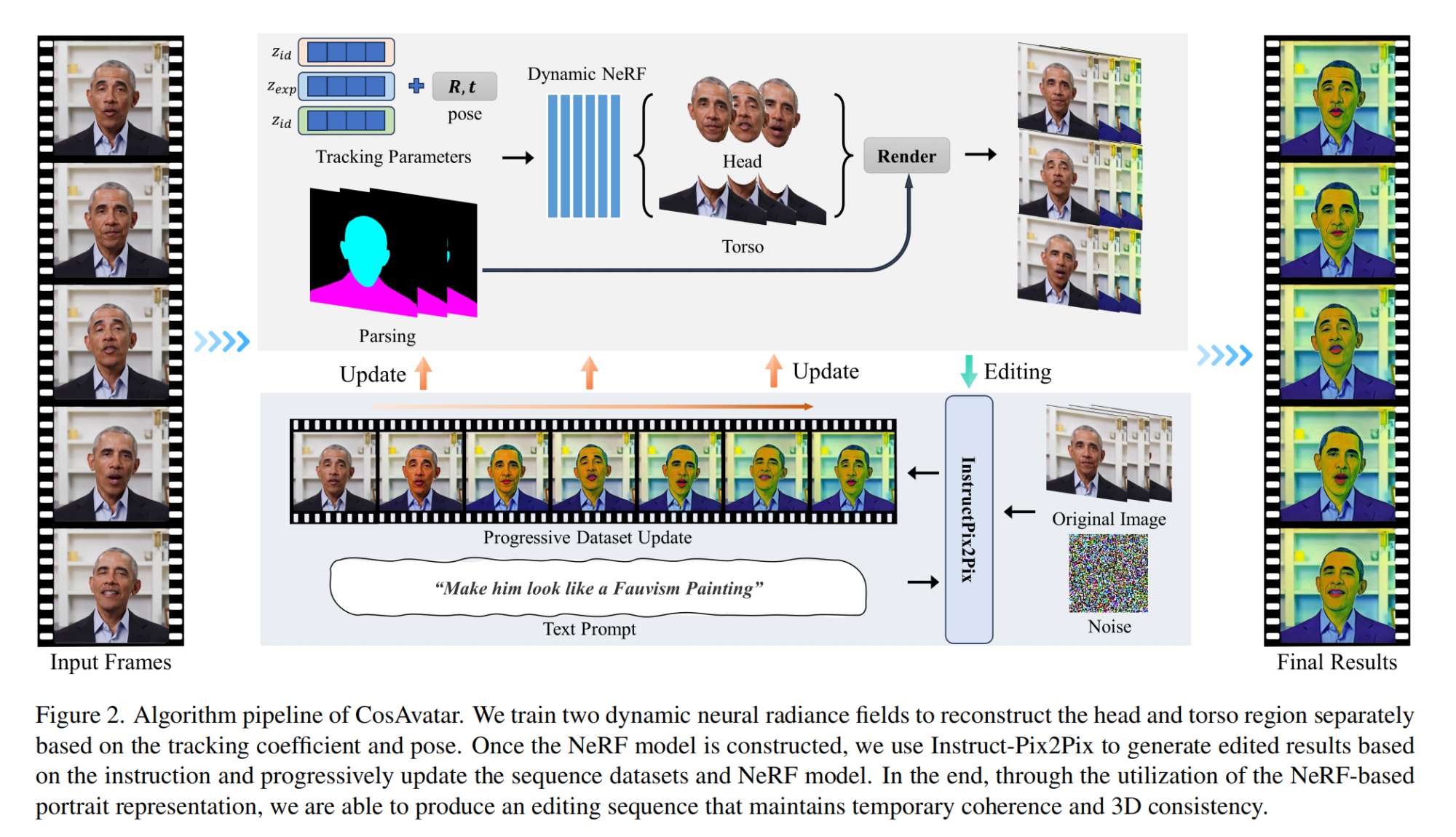
14.【多模态】CosAvatar: Consistent and Animatable Portrait Video Tuning with Text Prompt
-
论文地址:https://arxiv.org//pdf/2311.18288
-
工程主页:CosAvatar
-
代码即将开源
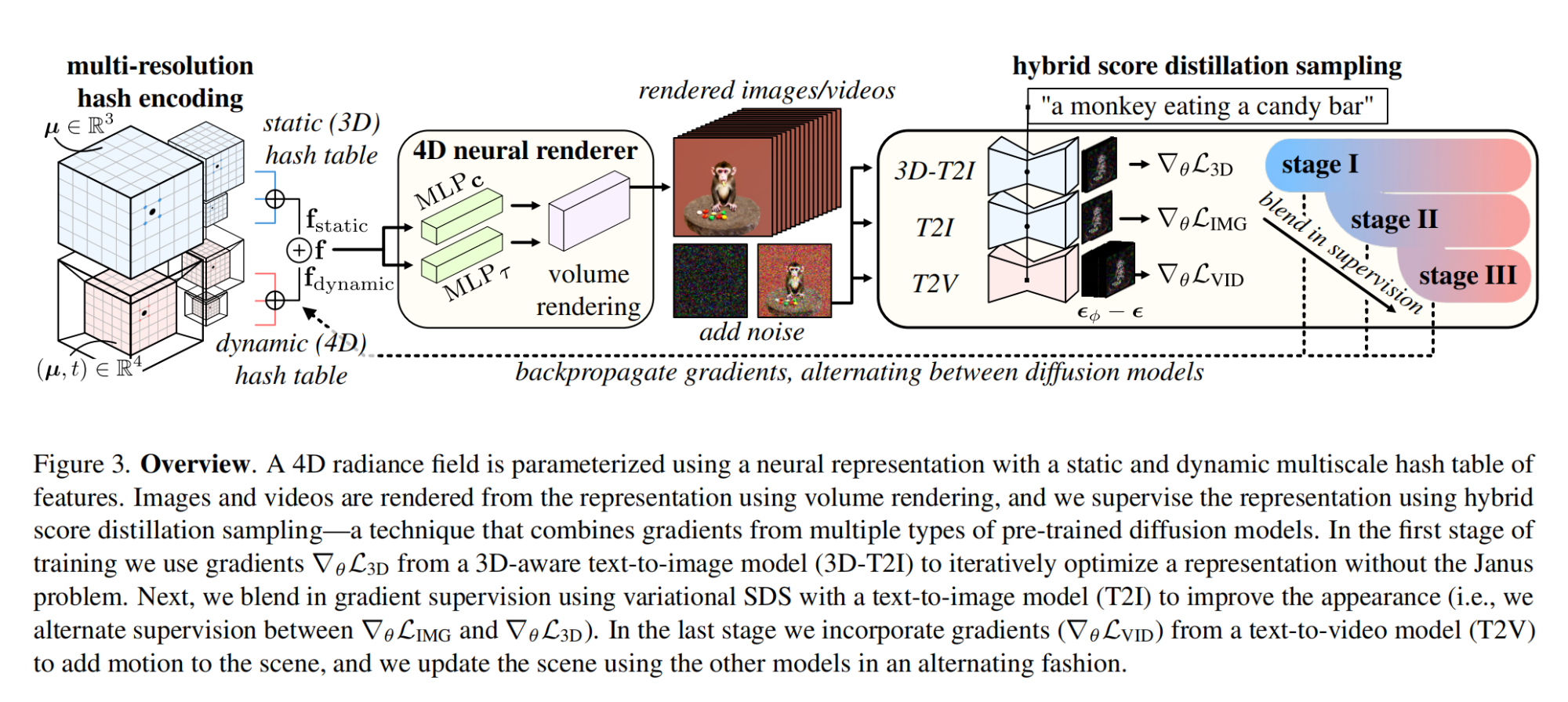
15.【多模态】4D-fy: Text-to-4D Generation Using Hybrid Score Distillation Sampling
-
论文地址:https://arxiv.org//pdf/2311.17984
-
工程主页:4D-fy: Text-to-4D Generation Using Hybrid Score Distillation Sampling
-
开源代码:GitHub - sherwinbahmani/4dfy: 4D-fy: Text-to-4D Generation Using Hybrid Score Distillation Sampling
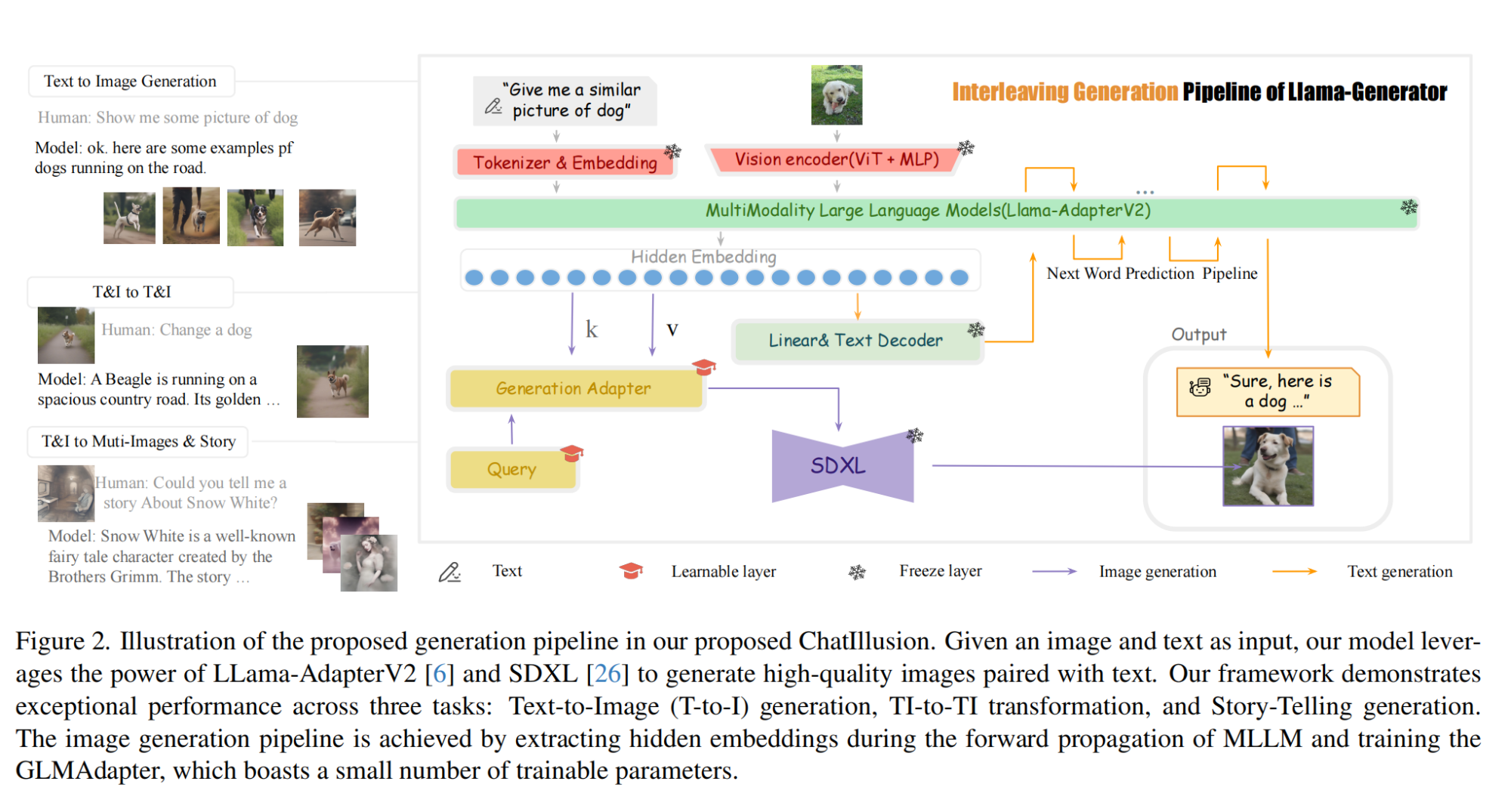
16.【多模态】ChatIllusion: Efficient-Aligning Interleaved Generation ability with Visual Instruction Model
-
论文地址:https://arxiv.org//pdf/2311.17963
-
开源代码(即将开源):GitHub - litwellchi/ChatIllusion
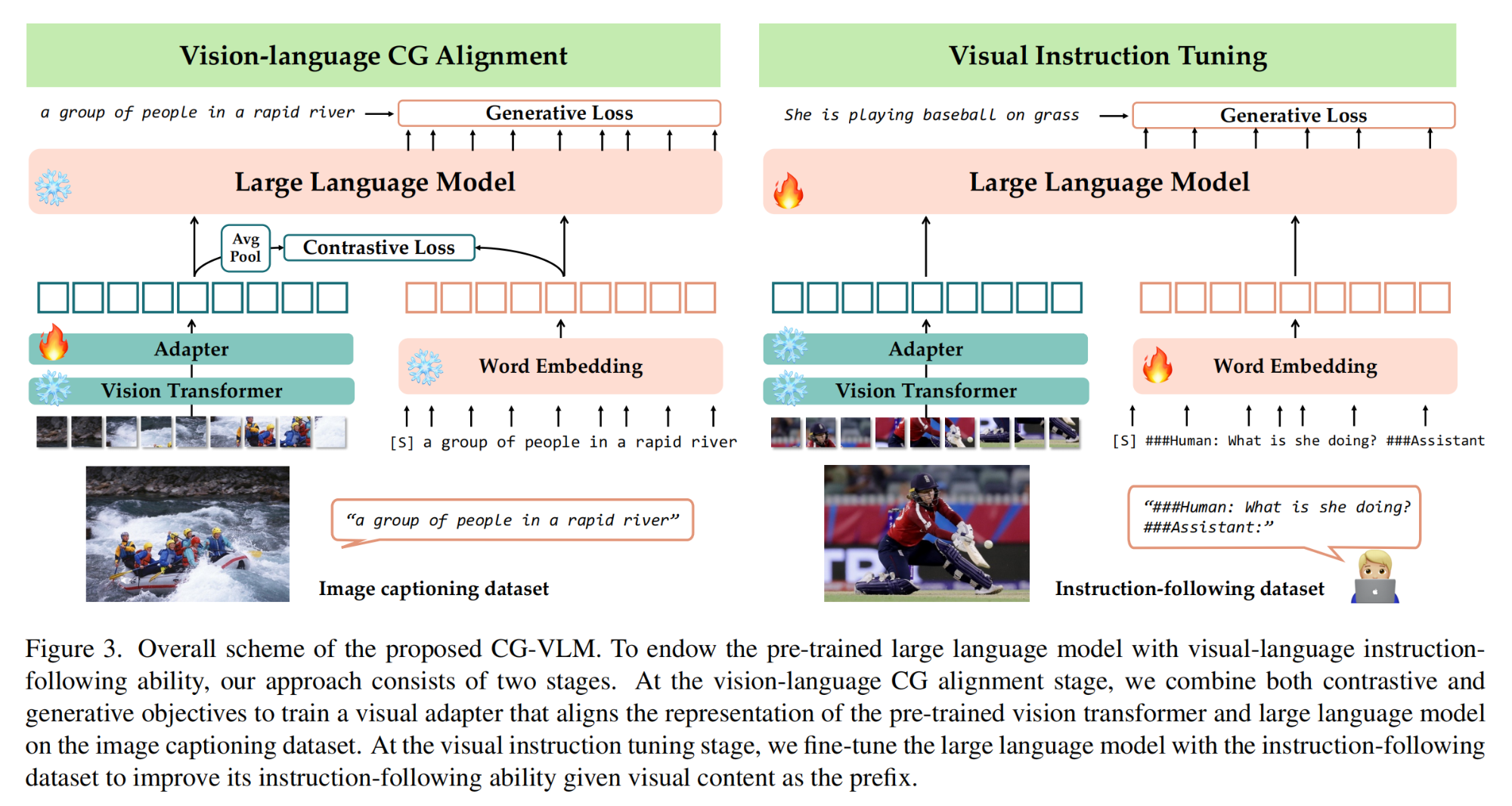
17.【多模态】Contrastive Vision-Language Alignment Makes Efficient Instruction Learner
-
论文地址:https://arxiv.org//pdf/2311.17945
-
开源代码(即将开源):GitHub - lizhaoliu-Lec/CG-VLM: This is the official repo for Contrastive Vision-Language Alignment Makes Efficient Instruction Learner.
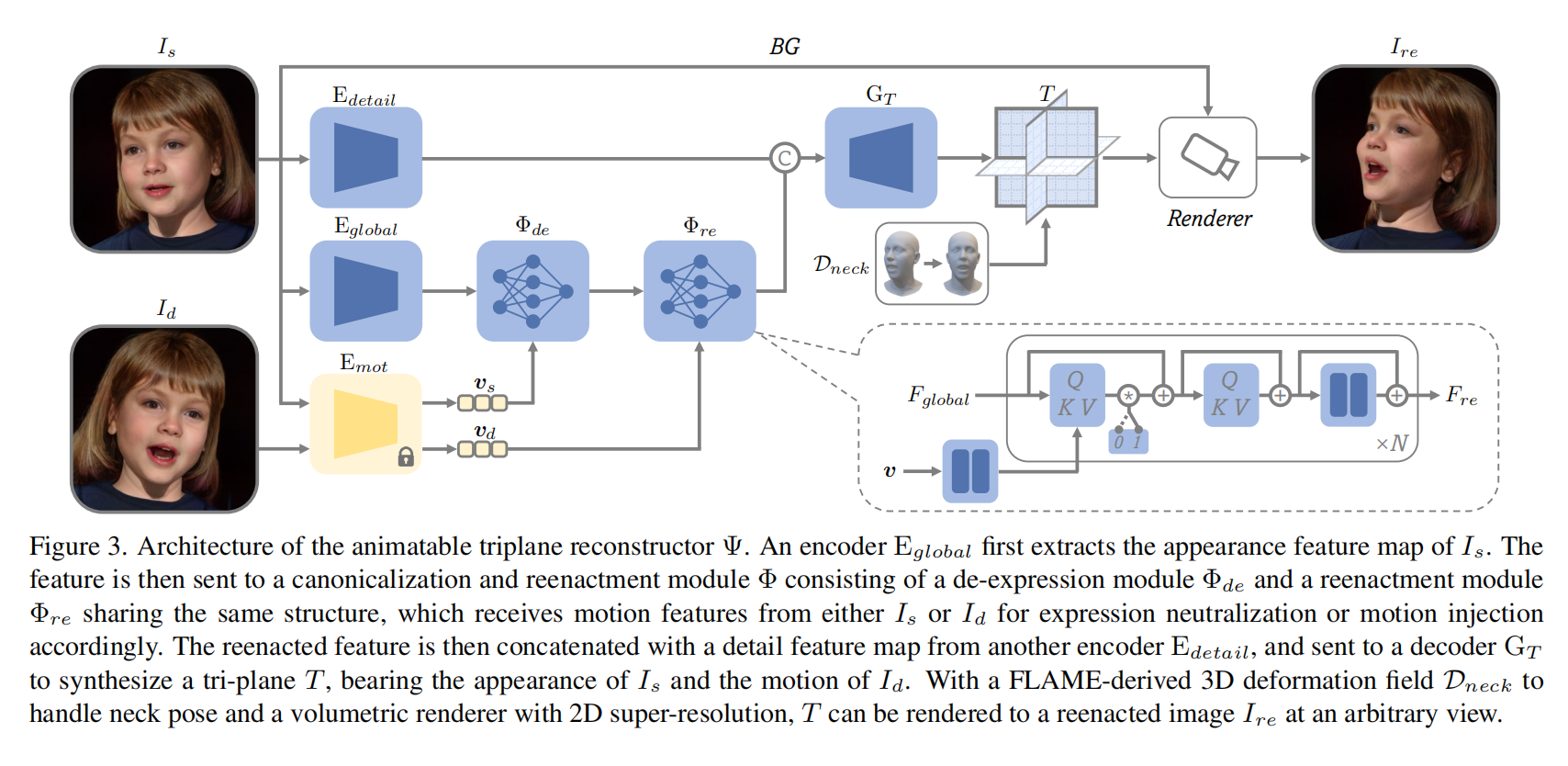
18.【数字人】Learning One-Shot 4D Head Avatar Synthesis using Synthetic Data
-
论文地址:https://arxiv.org//pdf/2311.18729
-
工程主页:Portrait4D: Learning One-Shot 4D Head Avatar Synthesis using Synthetic Data
-
开源代码(即将开源):GitHub - YuDeng/Portrait-4D: Portrait4D: Learning One-Shot 4D Head Avatar Synthesis using Synthetic Data
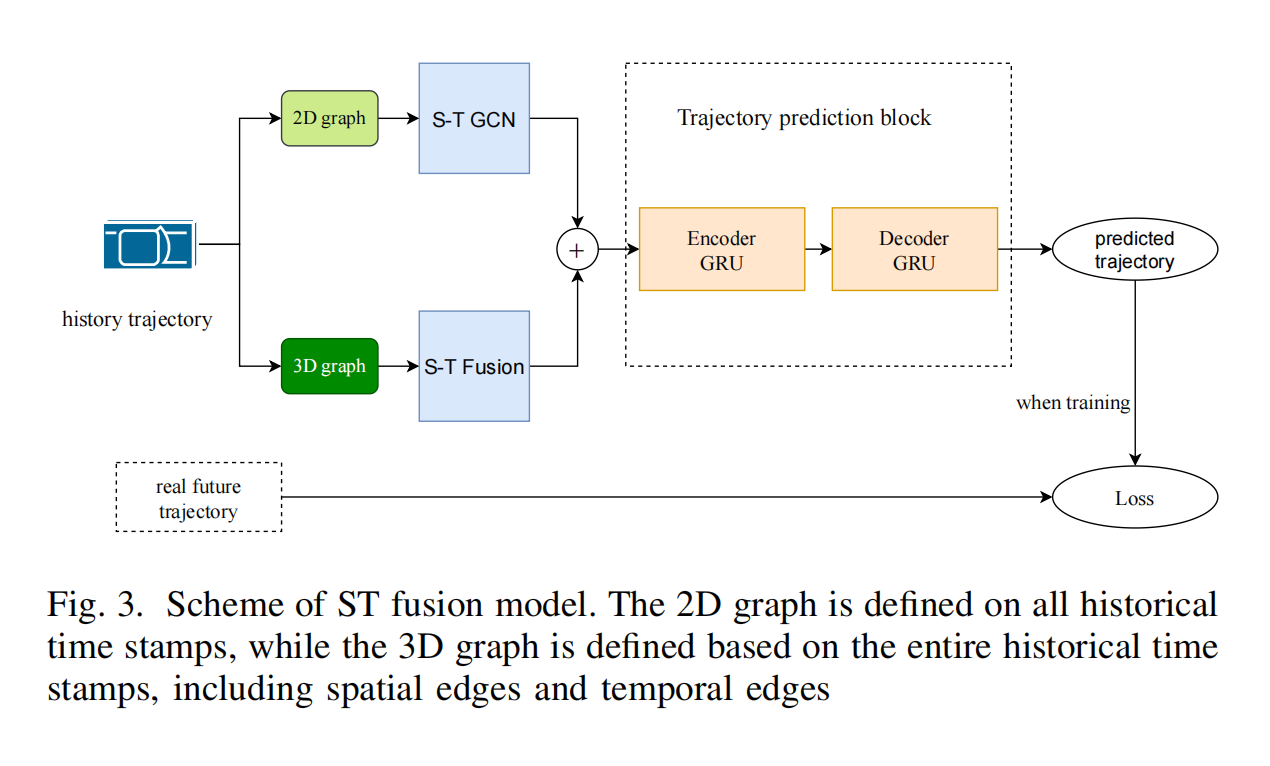
19.【轨迹预测】STF: Spatial Temporal Fusion for Trajectory Prediction
-
论文地址:https://arxiv.org//pdf/2311.18149
-
开源代码:GitHub - pengqianhan/STF-Spatial-Temporal-Fusion-for-Trajectory-Prediction
20.【Diffusion】Exploiting Diffusion Prior for Generalizable Pixel-Level Semantic Prediction
-
论文地址:https://arxiv.org//pdf/2311.18832
-
开源代码(即将开源):GitHub - shinying/dmp: Exploiting Diffusion Prior for Generalizable Pixel-Level Semantic Prediction

21.【Diffusion】CAT-DM: Controllable Accelerated Virtual Try-on with Diffusion Model
-
论文地址:https://arxiv.org//pdf/2311.18405
-
开源代码(即将开源):GitHub - zengjianhao/CAT-DM: CAT-DM: Controllable Accelerated Virtual Try-on with Diffusion Model

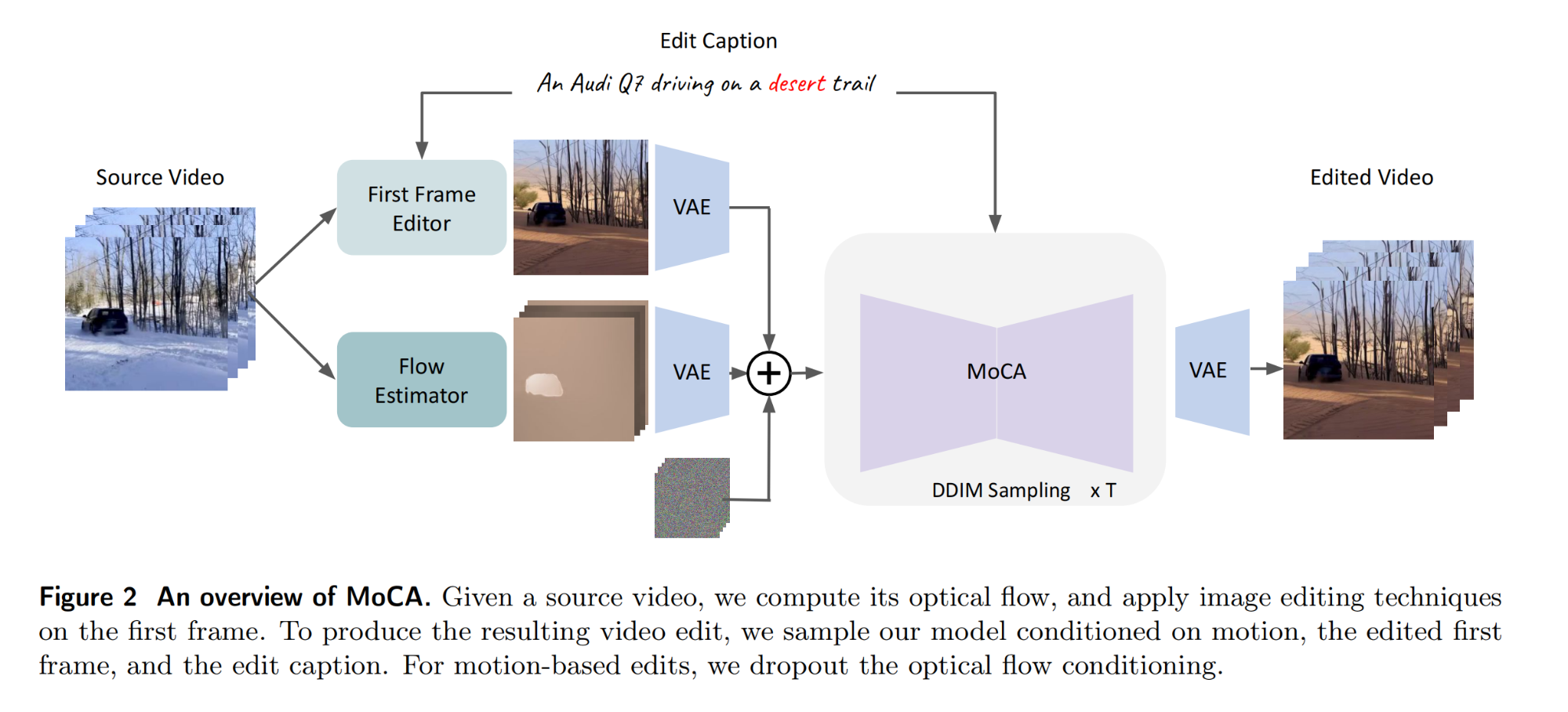
22.【视频编辑】Motion-Conditioned Image Animation for Video Editing
-
论文地址:https://arxiv.org//pdf/2311.18827
-
工程主页:Motion-Conditioned Image Animation for Video Editing
-
开源代码:GitHub - facebookresearch/MoCA: Motion-conditional image animation for video editing
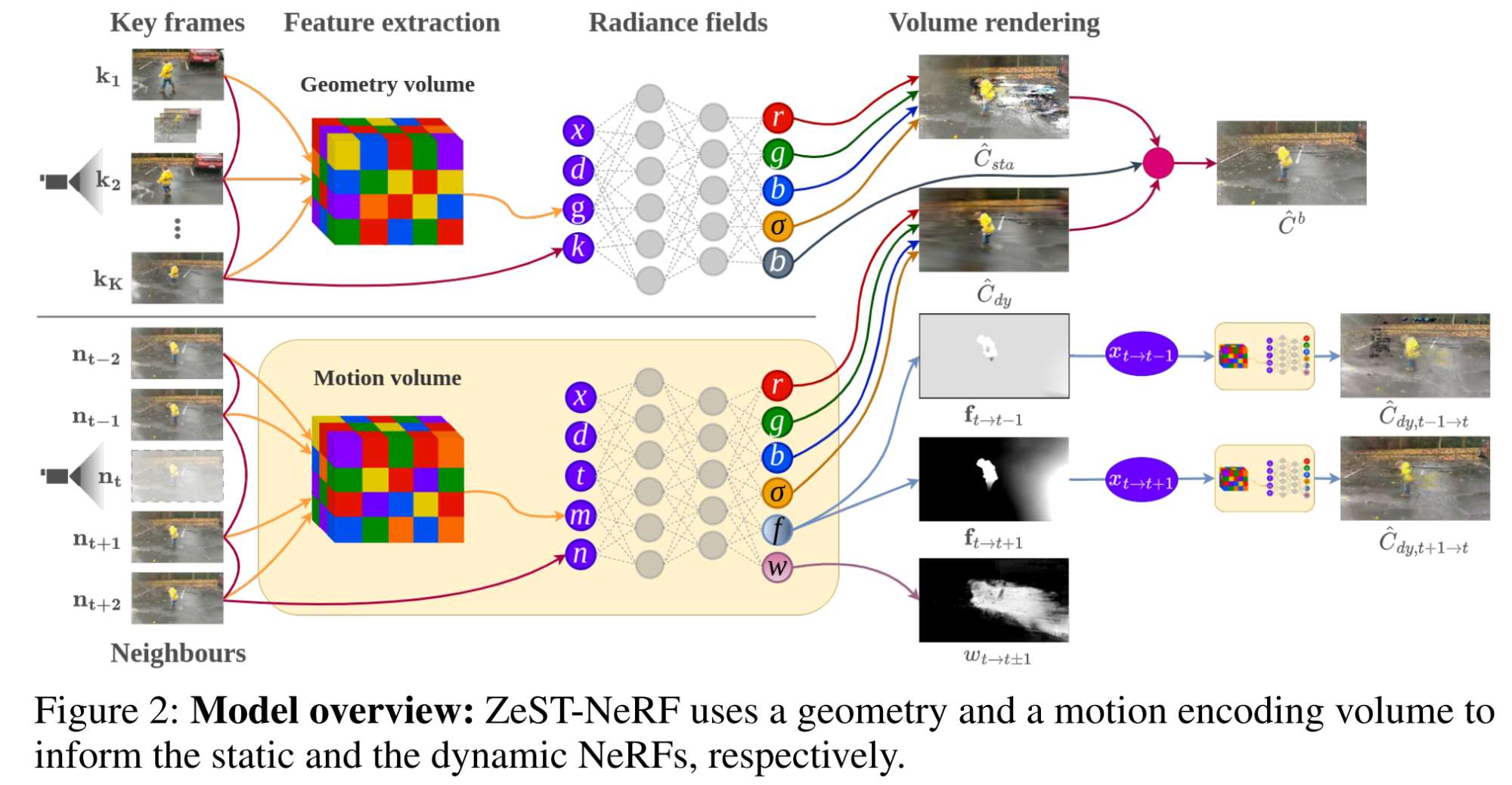
23.【NeRF】ZeST-NeRF: Using temporal aggregation for Zero-Shot Temporal NeRFs
-
论文地址:https://arxiv.org//pdf/2311.18491
-
开源代码(即将开源):https://github.com/violetamenendez/zest-nerf
24.【图像合成】ElasticDiffusion: Training-free Arbitrary Size Image Generation
-
论文地址:https://arxiv.org//pdf/2311.18822
-
开源代码(即将开源):GitHub - MoayedHajiAli/ElasticDiffusion-official: The official Pytorch Implementation for ElasticDiffusion: Training-free Arbitrary Size Image Generation

25.【视频生成】VBench: Comprehensive Benchmark Suite for Video Generative Models
-
论文地址:https://arxiv.org//pdf/2311.17982
-
工程主页:VBench: Comprehensive Benchmark Suite for Video Generative Models
-
开源代码:GitHub - Vchitect/VBench: VBench: Comprehensive Benchmark Suite for Video Generative Models

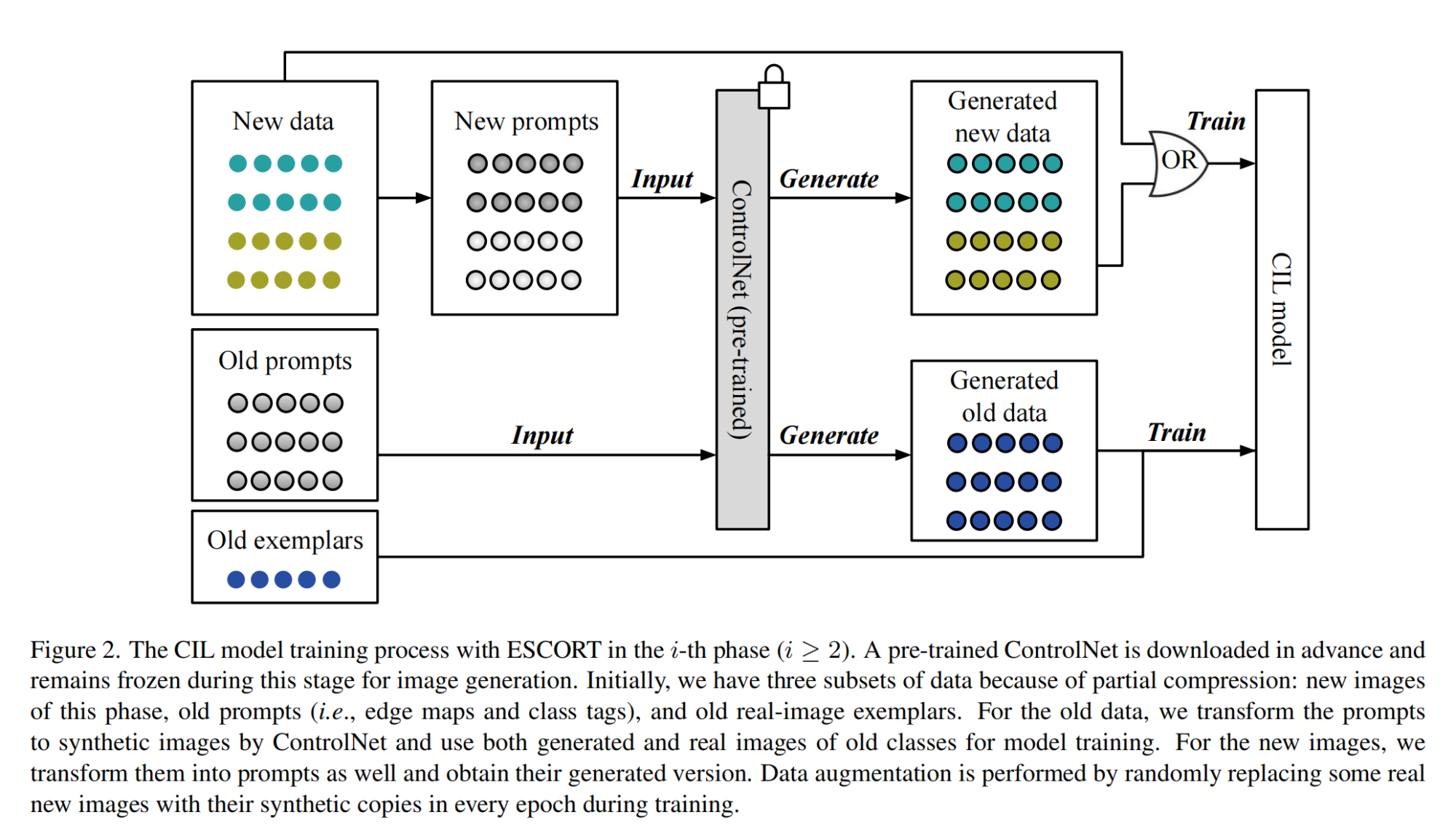
26.【类别增量学习】Prompt-Based Exemplar Super-Compression and Regeneration for Class-Incremental Learning
-
论文地址:https://arxiv.org//pdf/2311.18266
-
开源代码:GitHub - KerryDRX/ESCORT: Official implementation of Prompt-Based Exemplar Super-Compression and Regeneration for Class-Incremental Learning.
论文已打包,下载链接
CV计算机视觉交流群
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,不定期分享技术知识、面试技巧和内推招聘信息。
想进群的同学请添加微信号联系管理员:PingShanHai666。添加好友时请备注:学校/公司+研究方向+昵称。
推荐阅读:
CV计算机视觉每日开源代码Paper with code速览-2023.12.1
CV计算机视觉每日开源代码Paper with code速览-2023.11.30
CV计算机视觉每日开源代码Paper with code速览-2023.11.29
CV计算机视觉每日开源代码Paper with code速览-2023.11.28
CV计算机视觉每日开源代码Paper with code速览-2023.11.27
CV计算机视觉每日开源代码Paper with code速览-2023.11.23