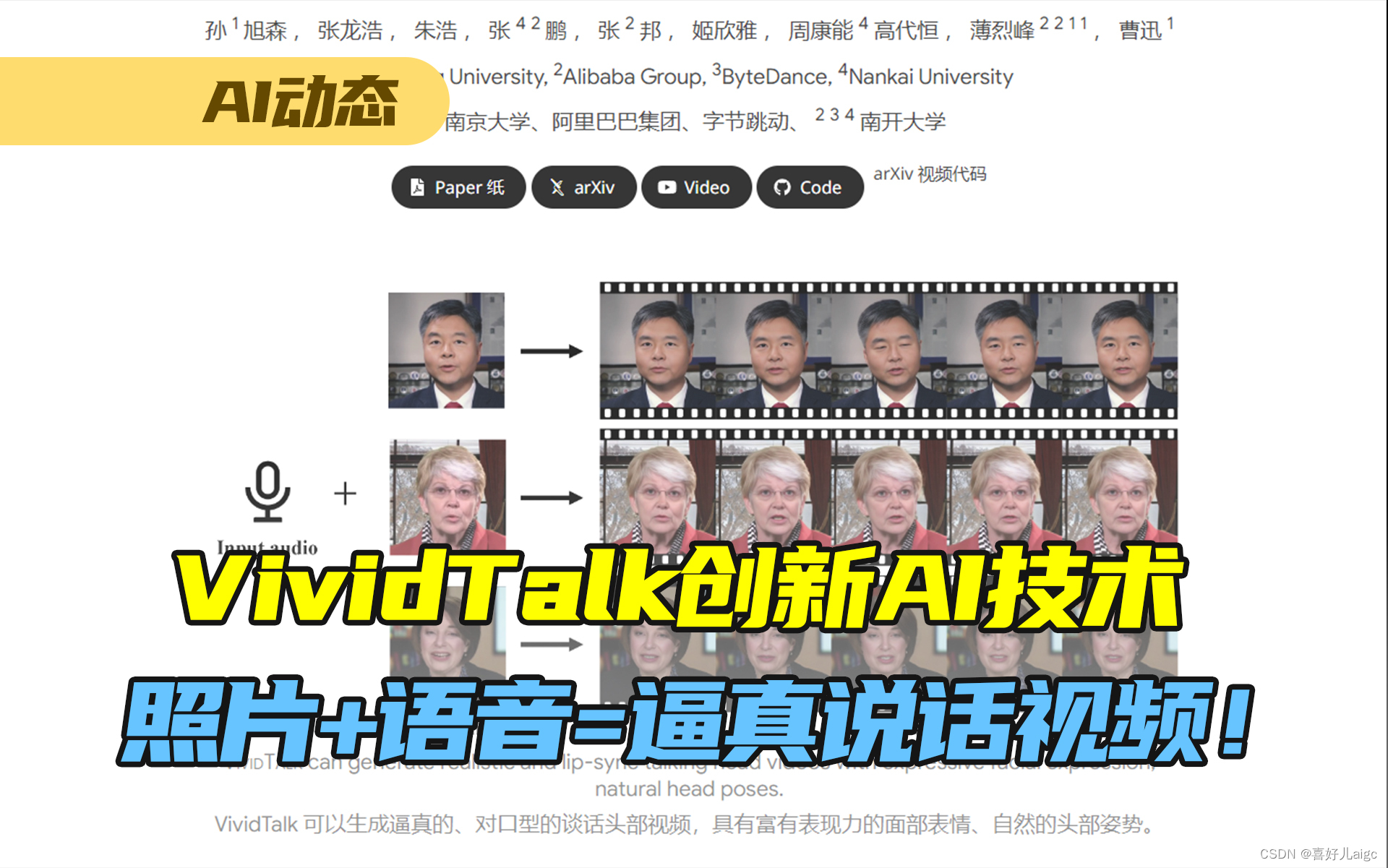
VividTalk是一个由南京大学、阿里巴巴、字节跳动和南开大学共同开发的项目工具。它通过先进的音频到3D网格映射技术和网格到视频的转换技术,实现了高质量、逼真的音频驱动的说话头像视频生成。这一创新技术使得只需提供一张人物的静态照片和一段语音录音,VividTalk即可将它们结合起来,制作出一个看起来像是实际说话的人物的视频。
这个系统不仅能够同步口型,还支持多种语言和不同的风格,包括真实风格和卡通风格等。通过精准的面部表情和头部动作的模拟,VividTalk创造出一种令人印象深刻的沉浸式体验,使得生成的视频看起来非常自然。这种技术的应用范围广泛,可以用于各种场景,包括虚拟助手、在线教育、娱乐内容制作等领域。目前没有试用平台。
其工作原理的详细说明:
- 音频到网格的映射(第一阶段):
首先,在VividTalk的音频到网格映射的初始阶段,系统通过学习两种关键运动类型来实现这一复杂的转换。这包括非刚性表情运动和刚性头部运动。为了最大程度地捕捉模型的表现能力,采用了混合形状和顶点作为中间表示。混合形状提供了全局范围内的整体运动,而顶点的微调则更加细致地描述了嘴唇等部位的运动。对于自然的头部运动,VividTalk引入了一种创新的学习型头部姿势代码本,经过两阶段训练机制的优化,以更准确地捕捉和再现头部动作的复杂性。 - 网格到视频的转换(第二阶段):
进入第二阶段,VividTalk采用了双分支运动-VAE(变分自编码器)和生成器,将经过学习的3D网格运动转化为密集的运动,并且基于这些运动逐帧地生成高质量的视频。这一过程包括将3D网格的运动信息转变为2D密集运动,然后将其输入到生成器中,从而合成出令人印象深刻的视频帧。 - 高视觉质量和真实感:
VividTalk所生成的视频呈现出卓越的视觉质量,包括逼真的面部表情、多样的头部姿势,并在嘴唇同步方面取得显著的进展。通过这种前沿的技术手段,VividTalk成功地创造出与输入音频高度同步的逼真说话头像视频,从而显著提升了视频的真实感和动态性。这一方法在提供引人入胜的用户体验的同时,为视频生成领域注入了更为先进和创新的元素。