目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- Python环境
- TensorFlow 环境
- Jupyter Notebook环境
- Pycharm 环境
- 微信开发者工具
- OneNET云平台
- 模块实现
- 1. 数据预处理
- 1)爬取功能
- 2)下载功能
- 2. 创建模型并编译
- 1)定义模型结构
- 2)优化损失函数
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
本项目基于Keras框架,引入CNN进行模型训练,采用Dropout梯度下降算法,按比例丢弃部分神经元,同时利用IOT及微信小程序实现自动化远程监测果实成熟度以及移动端实时监测的功能,为果农提供采摘指导,有利于节约劳动力,提高生产效率,提升经济效益。
本项目基于Keras框架,采用卷积神经网络(CNN)进行模型训练。通过引入Dropout梯度下降算法,实现了对神经元的按比例丢弃,以提高模型的鲁棒性和泛化性能。同时,利用物联网(IoT)技术和微信小程序,项目实现了自动化远程监测果实成熟度,并在移动端实时监测果园状态的功能。这为果农提供了采摘的实时指导,有助于节约劳动力、提高生产效率,从而提升果园经济效益。
首先,项目采用Keras框架构建了一个卷积神经网络,利用深度学习技术对果实成熟度进行准确的识别和预测。
其次,引入Dropout梯度下降算法,通过随机丢弃神经元的方式,防止模型过拟合,提高了对新数据的泛化能力。
接着,项目整合了物联网技术,通过传感器等设备对果园中的果实进行远程监测。这样,果农可以在不同地点远程了解果实的成熟度状况。
同时,通过微信小程序,果农可以实时监测果园状态,了解果实成熟度、采摘时机等信息,从而更加科学地安排采摘工作。
总体来说,该项目不仅在模型训练上引入了先进的深度学习技术,还通过物联网和微信小程序实现了智能化的果园管理系统,为果农提供了更加便捷、高效的农业生产解决方案。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
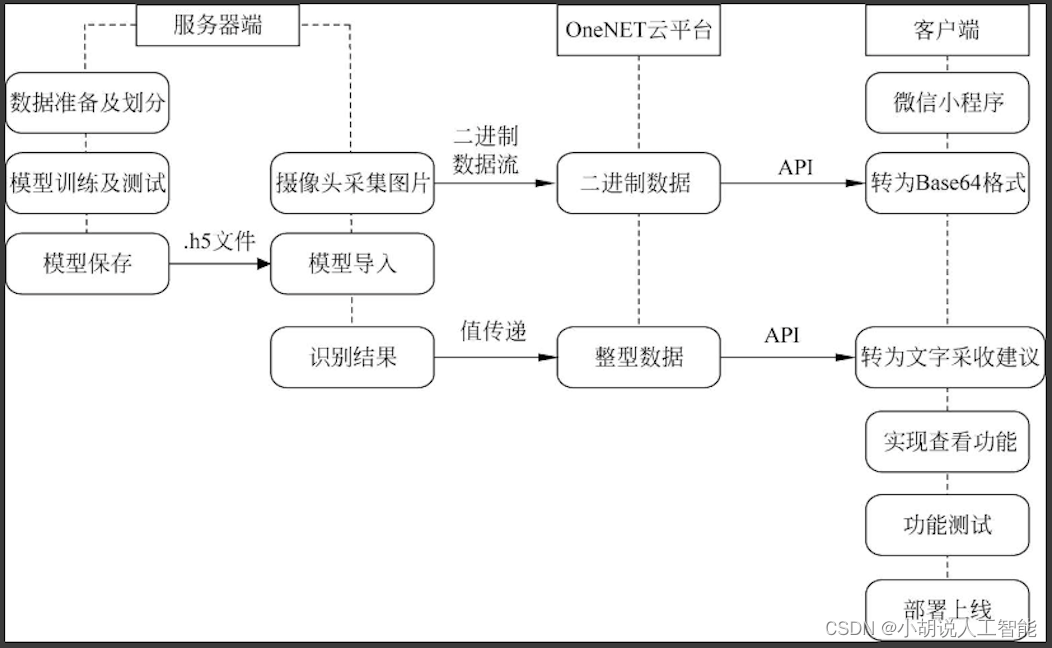
系统整体结构如图所示。
系统流程图
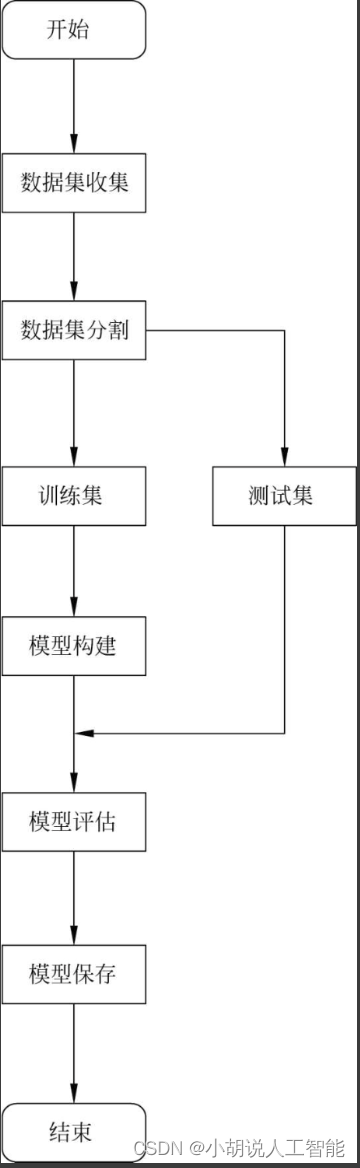
模型训练流程如图所示。
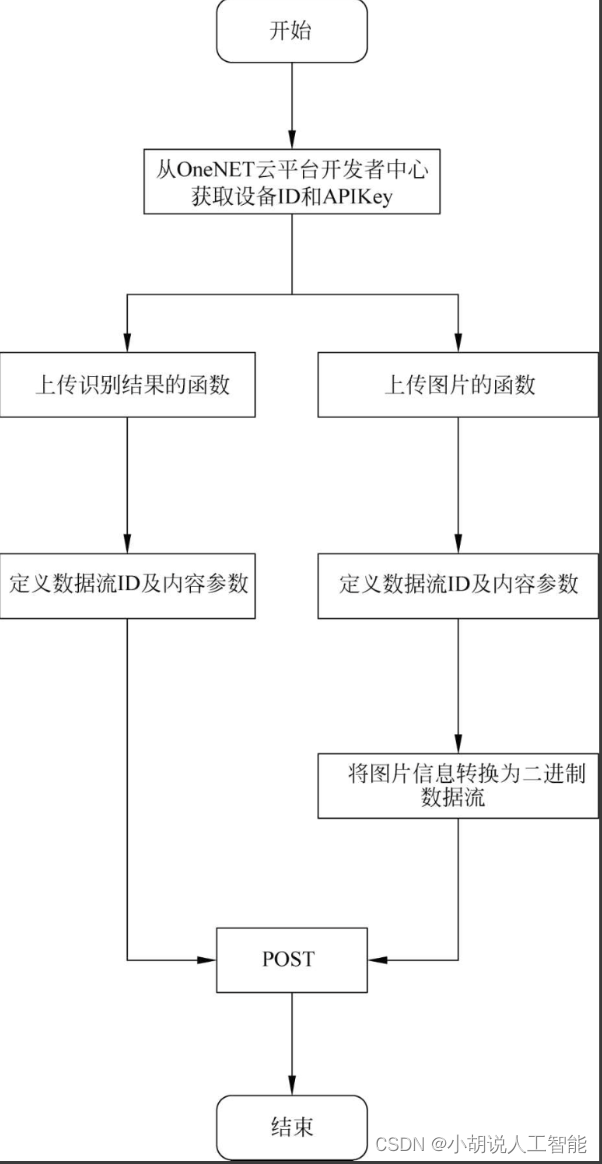
数据上传流程如图所示。
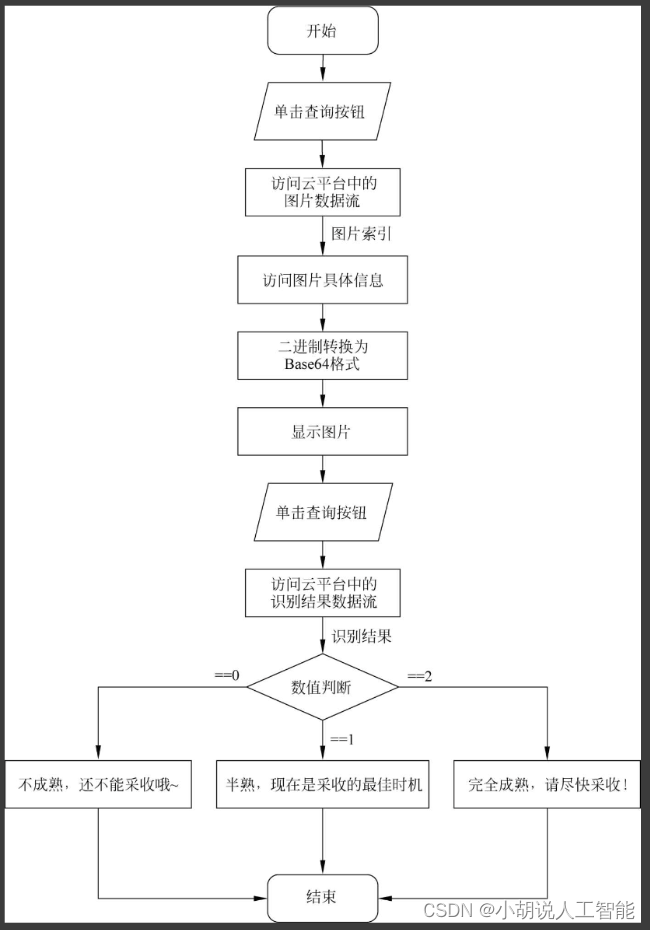
小程序流程如图所示。
运行环境
本部分包括Python环境、TensorFlow环境、JupyterNotebook环境、PyCharm环境、微信开发者工具和OneNET云平台。
Python环境
详见博客。
TensorFlow 环境
详见博客。
Jupyter Notebook环境
详见博客。
Pycharm 环境
详见博客。
微信开发者工具
详见博客。
OneNET云平台
详见博客。
模块实现
本项目包括本项目包括5个模块:数据预处理、创建模型与编译、模型训练及保存、上传结果、小程序开发。下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
以红枣为实验对象,在互联网上爬取1000张图片作为数据集。
1)爬取功能
采用Python语言自定义爬虫程序,相关代码如下:
#定义爬虫函数
def pa():
try:
#对输入的量进行控制,预防程序发生错误
start = 1
end = int(float(name1.get()))
#创建下载目录,可以修改Imgs4成其他的,也可以下载到现有目录
if os.path.exists(file_path.get()) is False:
os.makedirs(file_path.get())
#打开谷歌浏览器
browser = webdriver.Chrome()
browser.get("http://image.baidu.com")
#print(browser.page_source)
find_1=browser.find_element_by_id("kw")
print('----------------------------')
print(find_1)
find_1.send_keys(keyWord.get())
btn=browser.find_element_by_class_name("s_search")
print('----------------------------')
print(btn)
btn.click()
url=browser.find_element_by_name("pn0").get_attribute('href')
browser.get(url)
#设置下载的图片数量
for i in range(start,end + 1):
#获取图片位置
img=browser.find_elements_by_xpath("//img[@class='currentImg']")
for ele in img:
#获取图片链接
target_url = ele.get_attribute("src")
#设置图片名称,以图片链接中的名字为基础选取最后25个字节为图片名称
img_name = target_url.split('/')[-1]
filename = os.path.join(file_path.get(), keyWord.get()+"_"+str(i)+".jpeg")
download(target_url, filename)
#下一页
next_page = browser.find_element_by_class_name("img-next")
next_page.click()
time.sleep(3)
#显示进度
print('%d / %d' % (i, end))
#关闭浏览器
browser.quit()
except ValueError:
tkinter.messagebox.askokcancel("错误提示","你输入的应该是整数")
2)下载功能
使用自动化测试工具获取第一张图片,将下载链接传给下载模块,然后找到下一张图片的按钮并单击,再次获得新图片的下载链接。
#定义下载函数
def download(url, filename):
#检查下载目录是否存在
if os.path.exists(filename):
print('file exists!')
return
try:
#保存下载图片
r = requests.get(url, stream=True, timeout=60)
r.raise_for_status()
with open(filename, 'wb') as f:
for chunk in r.iter_content(chunk_size=1024):
if chunk: #过滤掉保持活动的新块
f.write(chunk)
f.flush()
return filename
except KeyboardInterrupt:
if os.path.exists(filename):
os.remove(filename)
raise KeyboardInterrupt
except Exception:
traceback.print_exc()
if os.path.exists(filename):
os.remove(filename)
#获取目录地址
def selectDir():
global file_path
file_path.set(filedialog.askdirectory())
使用os.file下载路径,获取图片URL,同时按照一定规律命名并进行存储,如图所示。
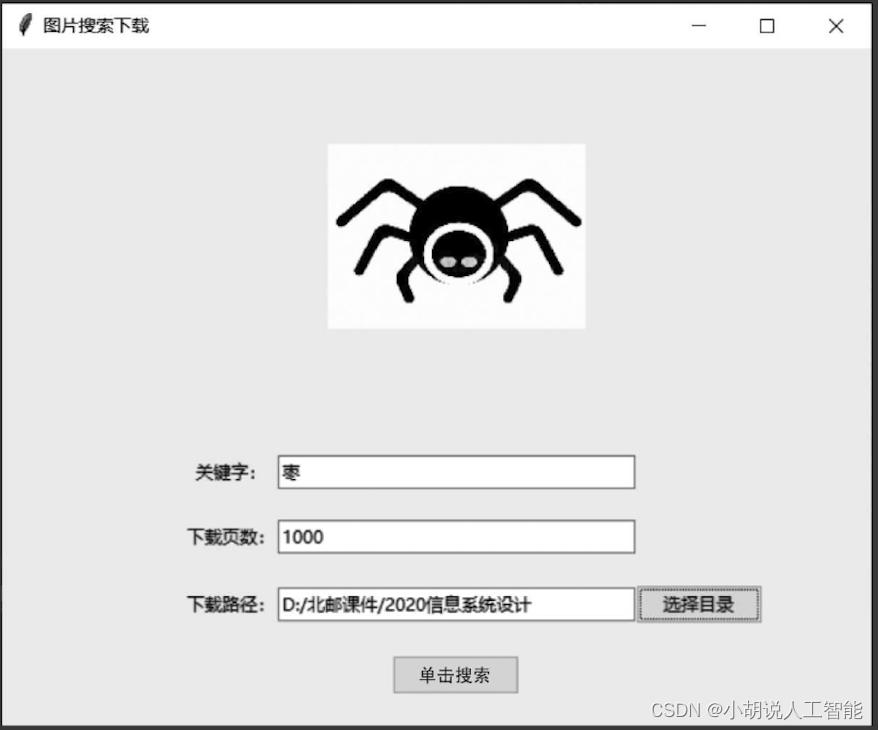
2. 创建模型并编译
数据加载进模型之后,需要定义模型结构并优化损失函数。
1)定义模型结构
定义架构为二个卷积层,在每个卷积层后都连接一个最大池化层及一个全连接层,进行数据的降维。在每个卷积层上都使用L2正则化,并引Dropout和BN算法,用以消除模型的过拟合问题。
#第一层使用L2正则化,正则化系数0.01
X = Conv2D(32, (3, 3), strides = (3, 3), name = 'conv0',kernel_regularizer=regularizers.l2(0.01))(X_input)
X = Dropout(rate=0.05)(X)#梯度下降,rate=5%
#归一化
#BN方法,将该层特征值分布重新拉回标准正态分布
X=BatchNormalization(axis = 3, name = 'bn0')(X)#axis要规范化的轴,通常为特征轴
#非线性激活函数ReLu
X = Activation('relu')(X)
#最大池化层,用来缩减模型的大小,提高计算速度以及提取特征的鲁棒性
X = MaxPooling2D((2, 2), name='max_pool_1')(X)
#第二层
X = Conv2D(4, (3, 3), strides = (3, 3), name = 'conv1',kernel_regularizer=regularizers.l2(0.01))(X)
X = Dropout(rate=0.15)(X)
X = BatchNormalization(axis = 3, name = 'bn1')(X)
X = Activation('relu')(X)
#最大池化
X = MaxPooling2D((2, 2), name='max_pool_2')(X)
X = Flatten()(X)#降维
X = Dense(3, activation='softmax', name='dense')(X)#全连接神经网络层
#使用Keras模型中的API模型
model = Model(inputs = X_input, outputs = X)
2)优化损失函数
确定模型架构后进行编译。Adam是常用的梯度下降算法,使用它来优化模型参数。这是多类别的分类问题,因此需要使用交叉熵作为损失函数。由于所有标签都带有相似的权重,因此使用精确度作为性能指标。
#定义损失函数、优化器以及评估模型在训练和测试时的性能指标
model.compile(optimizer='Adam',loss='categorical_crossentropy',metrics=['accuracy'])
相关其它博客
基于OpenCV+CNN+IOT+微信小程序智能果实采摘指导系统——深度学习算法应用(含pytho、JS工程源码)+数据集+模型(一)
基于OpenCV+CNN+IOT+微信小程序智能果实采摘指导系统——深度学习算法应用(含pytho、JS工程源码)+数据集+模型(二)
基于OpenCV+CNN+IOT+微信小程序智能果实采摘指导系统——深度学习算法应用(含pytho、JS工程源码)+数据集+模型(四)
基于OpenCV+CNN+IOT+微信小程序智能果实采摘指导系统——深度学习算法应用(含pytho、JS工程源码)+数据集+模型(五)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。