用语言连接数据库
- 前言
- 正式开始
- 创建一个等会专门演示语言连接的库和用户
- 连接mysql要用到的动静态库以及头文件
- 手动下载mysql官方提供的库(可以跳过不看)
- 下载MySQL时自动安装的库
- 用C连接数据库
- 官方文档
- 对于编译链接的解释
- 对库的操作
- 函数接口介绍
- mysql_init()
- mysql_close()
- mysql_real_connect()
- select 查找
- 正常的使用方式
- 仅查找
- 仅插入
- mysql图形化界面
- Mysql连接池原理

前言
在我讲第一篇MySQL的博客中我就说过,MySQL是一个网络服务,学过网络的同学应该是懂的,我们想要获取到MySQL的服务,必须要连接mysql的服务器,我们在下载MySQL的时候有两个程序很重要,一个是mysqld,就是MySQL的服务器,一个是mysql,就是MySQL的客户端。
当我们启动MySQL服务器后,用netstat可以查看到我们主机中的mysql服务器:

我这里就不把我的mysqld的端口暴露出来了,这里也不建议你将你自己mysql服务器的端口暴露到网络中。
刚下载好的默认端口是3306,我这里修改了。如果你也想修改你的端口,只需要修改一下/etc/my.cnf配置文件就行:

这里改好之后记得用systemctl restart mysqld来重启你的服务器:

前面博客中一直是用mysql客户端连接数据库,并以命令行的方式来获取MySQL的服务,我前面也演示过远端连接其他主机的MySQL服务器。
那么这一篇就用语言来连接mysql服务器,本篇是用C语言演示的,不过学会这一个其他语言也就会了。
正式开始
创建一个等会专门演示语言连接的库和用户
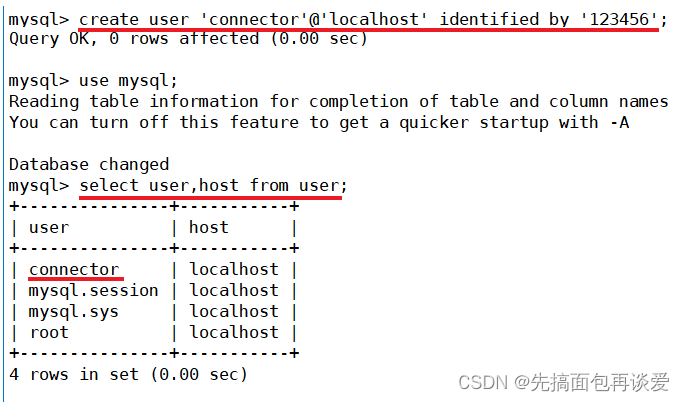
我这里先来创建一个专门用来演示进行连接的用户:
关于用户管理的内容我前一篇已经讲过了,本篇不再细说,不懂的同学可以看看我前一篇。
再专门建一个库,给这个用户赋权:
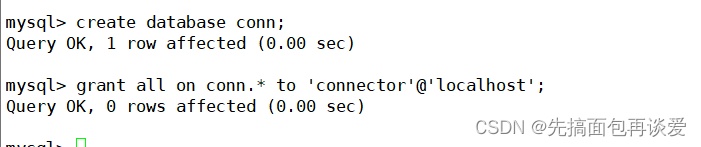
用这个用户登录并查看权限:
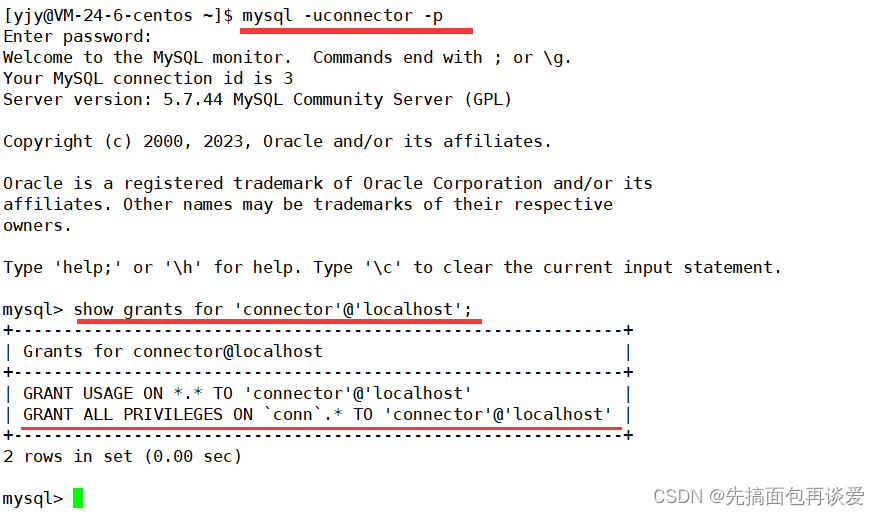
正常。
连接mysql要用到的动静态库以及头文件
手动下载mysql官方提供的库(可以跳过不看)
我这里先介绍一下mysql官方所提供的库,其实我们在下载MySQL的时候已经将改装的库都装好了,不过这里只是介绍一下这些库都在什么地方。
MySQL的官方:MySQL
上面这个是中文官方页面,也有英文的:MySQL
进去之后点击下载(或者英文页面中的download):
进去之后往下翻,有个MySQL Community(GPL) Downloads:
点进去之后选择Download Archives:
本篇用C语言连接,所以用的是C API,点开之后是这样:
点中间的MySQL Connector/C,进去之后可以选择你对应mysql的版本:
不过可以看到下面提供的mysql版本是6.几的,你可以先查看一下你的mysql版本:

我的是5.几的,其实高版本是兼容我的版本的,所以这里很多的历史版本都没有,直接用新的就行:
再选择你os的版本,我等会是用Linux来演示,所以os版本选的是Linux的:
我这里下载好后并发送到我Linux上就是这样的:
用tar -xvzf进行解压:
然后会形成一个同名目录:

如果你嫌目录名太长了可以用mv命令来重命名:

里面文件有:
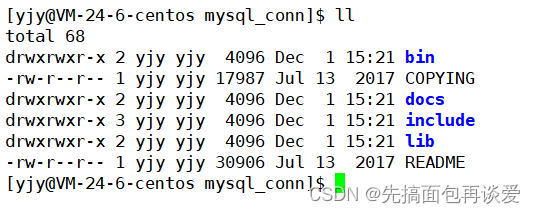
就两个比较重要,一个是include,表示包含头文件的目录:
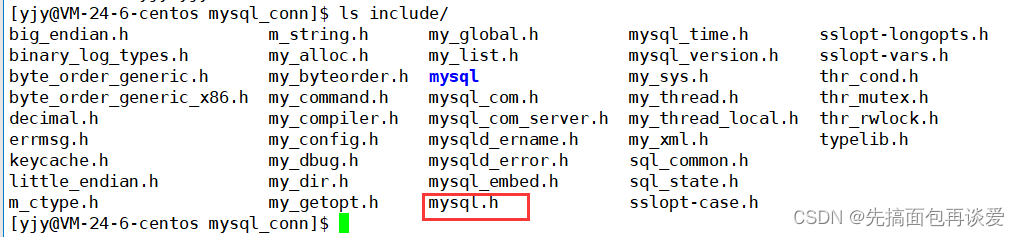
其中mysql.h最重要,等会引的时候只需要引这个文件就行了。
一个lib,表示包含库文件的目录:

.a的为静态库,.so的为动态库。
这个手动下载库就到这,下面来说下载好MySQL就自带的库。
下载MySQL时自动安装的库
其实我们用yum install -y mysql-devel就可以把所有该下载的库都下好:
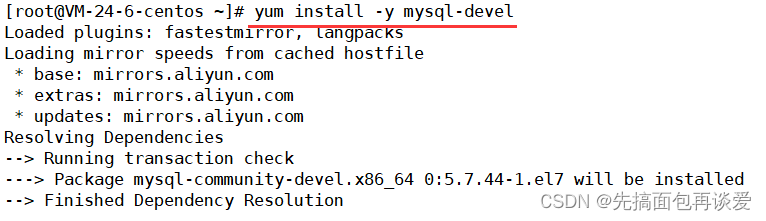
然后就会在/user/include下产生一个mysql目录:
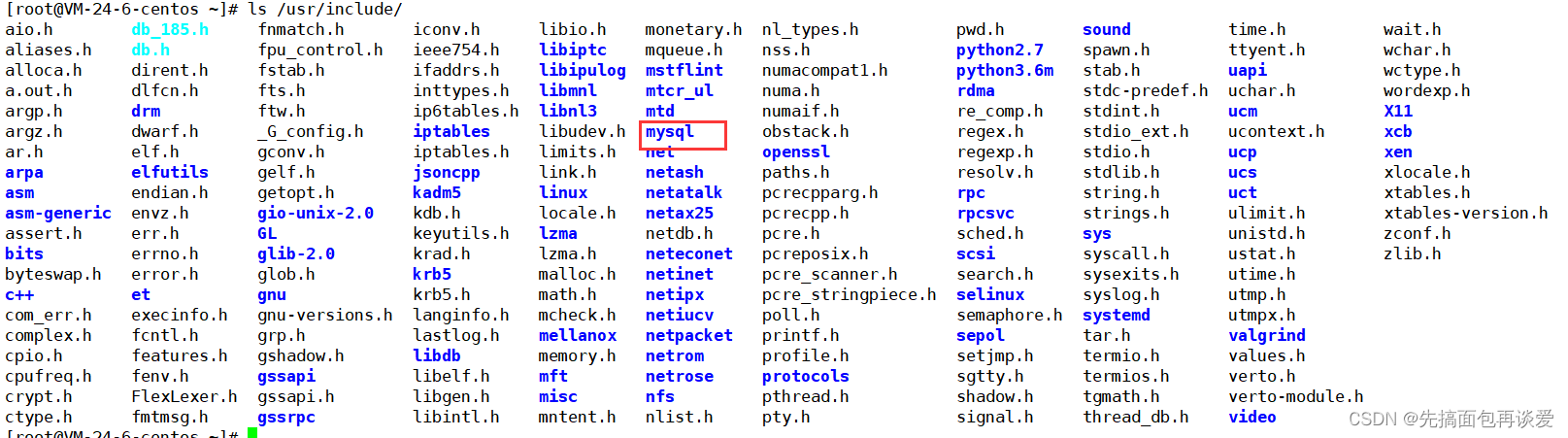
这个目录下中保存的就是要用的头文件:

还有/lib64下也会生成一个mysql目录:
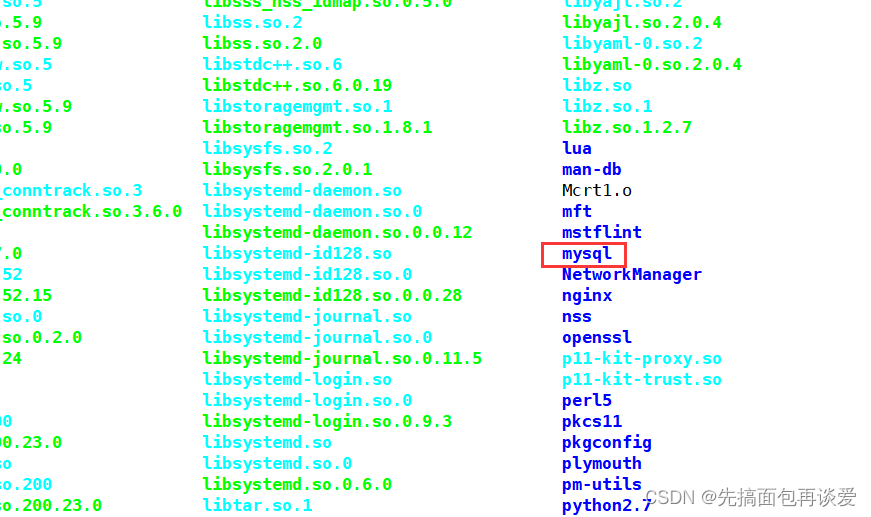
这个目录下保存的是需要用到的库文件:
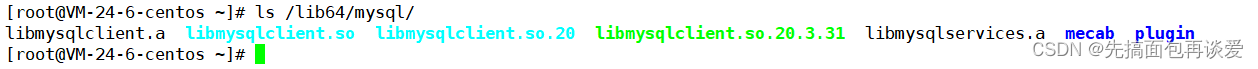
这些东西搞好了之后就可以测试一下能不能连接上数据库了。
用C连接数据库
官方文档
mysql官方为我们提供的这些库,里面有很多的接口,不同的语言不一样,这些接口需要我们自己摸索着用,所以用语言连接数据库并发送相关的命令是需要我们再学习的,官网中也给我们提供了相关的文档介绍,这里我来简单介绍点接口。
进入官网之后先点击documentation:
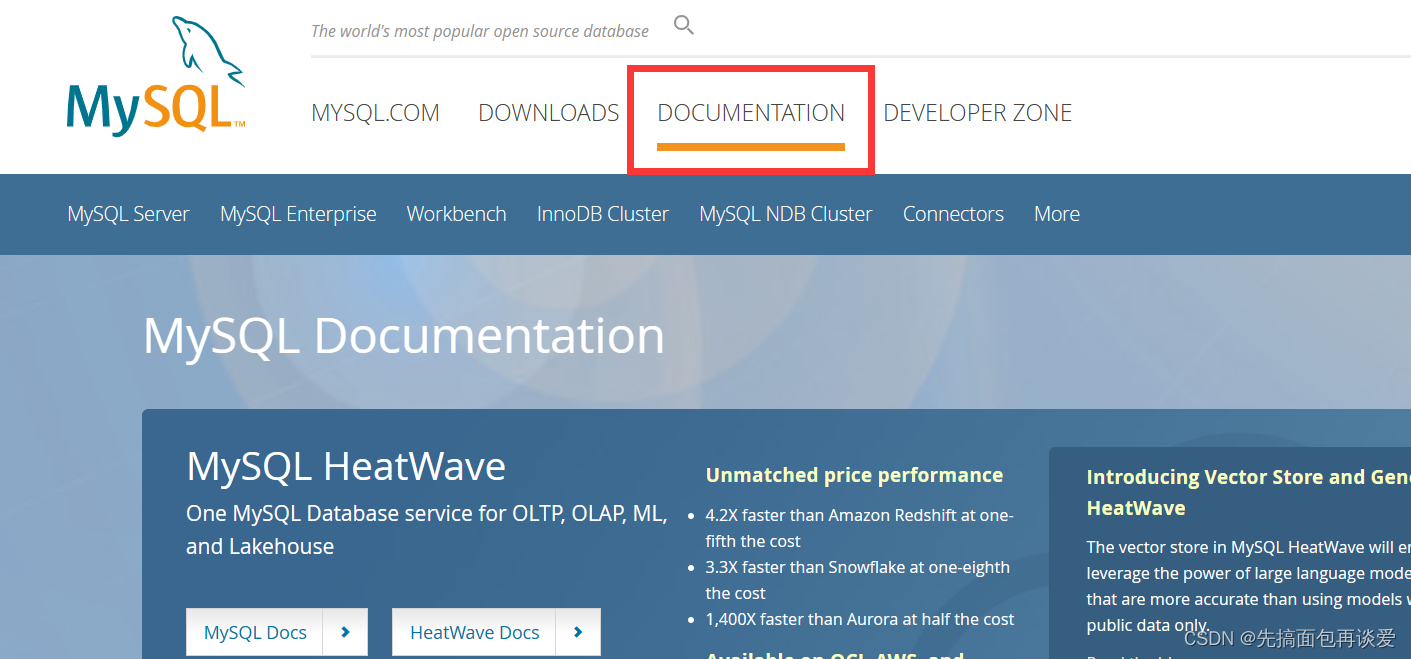
然后往下稍微翻一点,有一个connector & APIS:
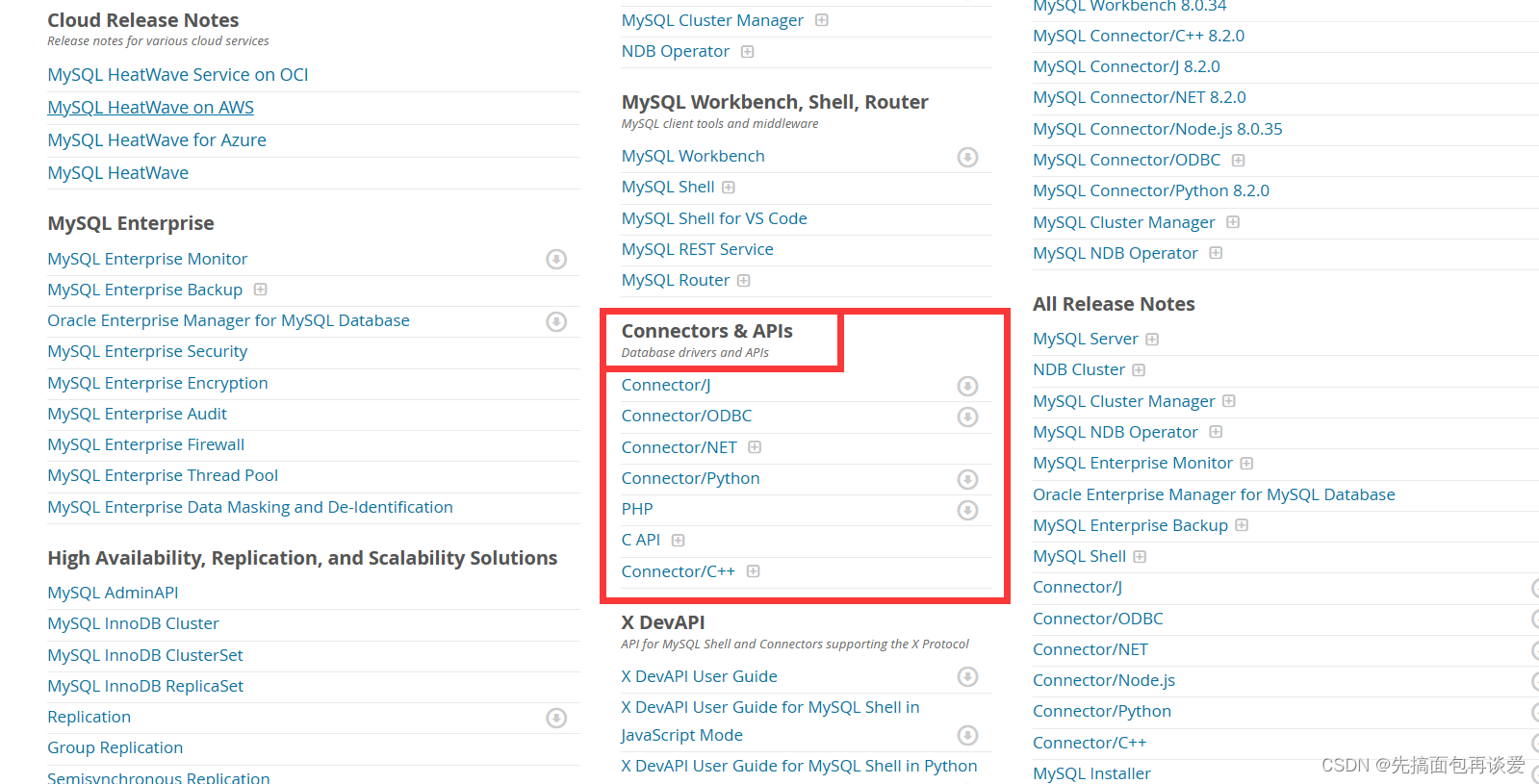
选择你想查看的语言对应的接口介绍,这里我用的是C,那我就选的是C API,后面带加号的表示还要选择不同版本:

我的mysql是5.7的,所以我选的是这个:
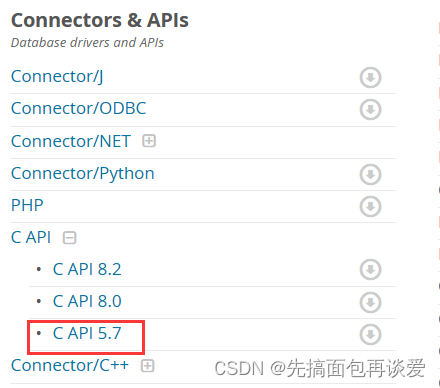
进去之后选择:

就可以查看所有函数的介绍了:
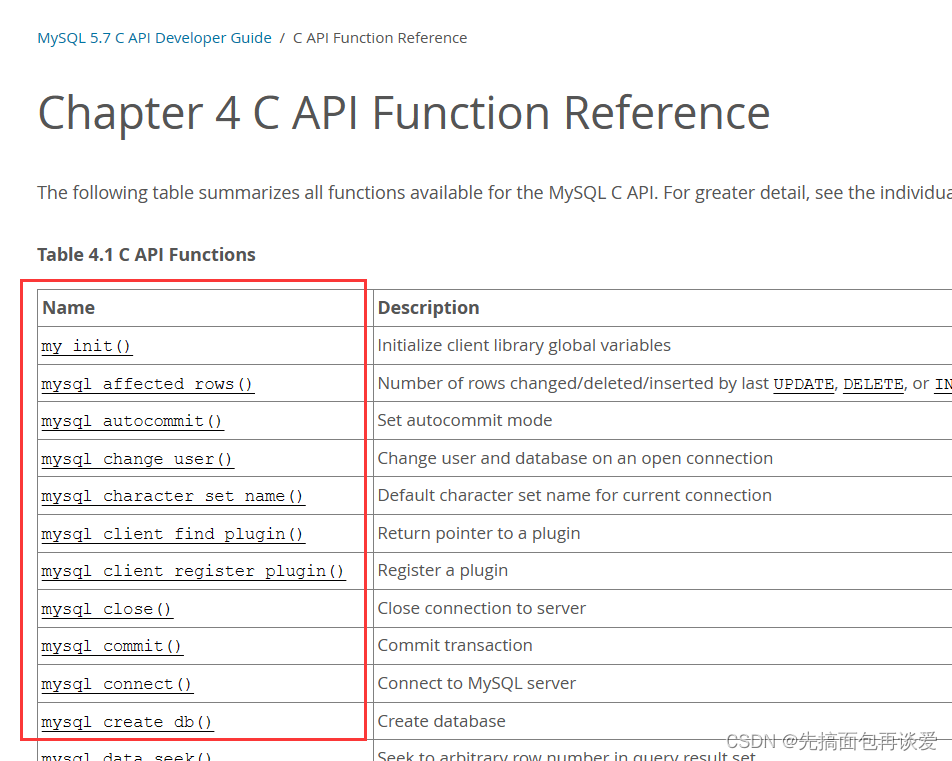
mysql官方提供了很多函数,我这里只截取了一部分。
虽然有很多函数,但是常用的还是那么些。
里面有个mysql_get_client_info函数,先用这个函数测试一下:
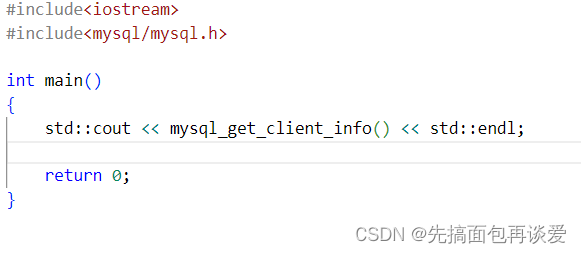
mysql官方里面是有这些函数的介绍的:
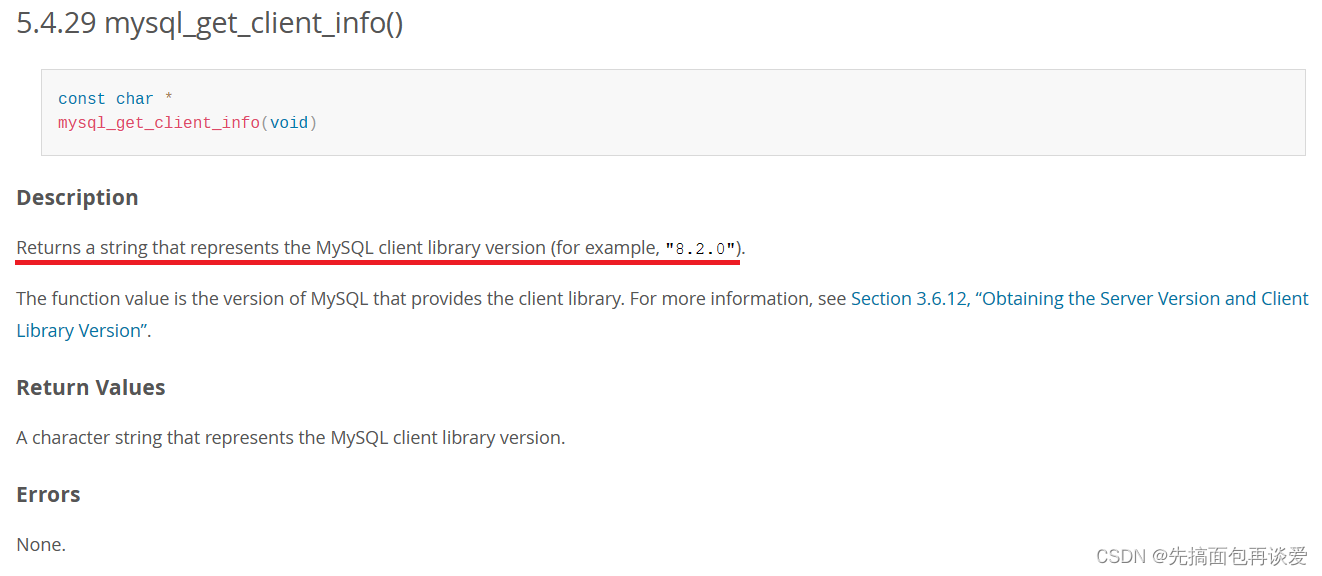
这个函数返回客户端对应的库版本。
对于编译链接的解释
上面的代码如果我直接进行简单的g++会报错的:
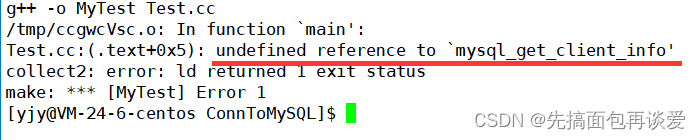
这里说mysql_get_client_info没有定义,并不是没有定义。
mysql为我们提供的库是第三方库,g++在进行编译的时候只会去找C++的库,其中会找一个路径,就是刚刚提到的/lib64下面,虽然刚刚看到了库的目录mysql放到了这个/lib64目录下,但是编译的时候是不会自动去/lib64/mysql中去找的。所以我们在编译的时候要手动加上连接的库以及库对应的目录:
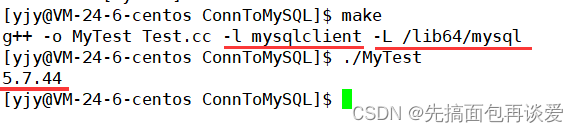
关于这一点我在前面文件IO的博客讲过,不懂的同学可以看看:看动静态库的制作和使用。
如果你编译出来后运行失败,可能是因为你动态库没有连接上,可以ldd一下:
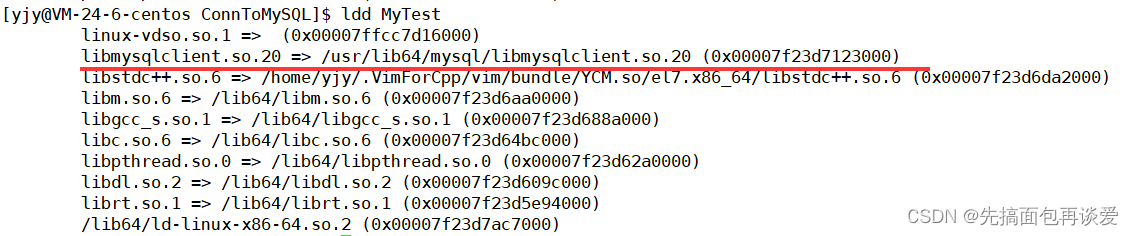
如果你是动态库没连上,那箭头右边就是not found,我这里给两种方法:
-
在/etc/ld.so.conf.d/目录下将动态库的路径添加到系统配置文件中:

在这个路径下面加上一个.conf文件,文件中放的是库文件所在的路径就行:
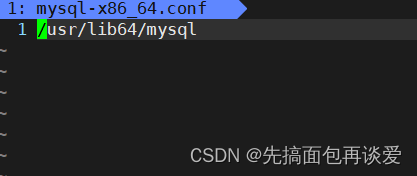
-
将库路径放在环境变量中,这里就不说了,在我那篇博客中详细说了
还有一个-I(这里不是l(L),而是I(i)),-I是指明头文件位置的,不过这里不用加,因为我们在引用头文件的时候是#include <mysql/mysql.h>的,刚刚也看到了/usr/include下是有mysql头文件目录的,搜索的时候会到include目录下面搜索,在搜索头文件的时候是指明了头文件所在目录的,也就是mysql目录,所以会直接进入该目录中找mysql目录下的mysql.h。如果这段话你听不懂,可以去看刚刚给的博客。
如果我是直接#include<mysql.h>,那么就要指明mysql.h所在的路径:
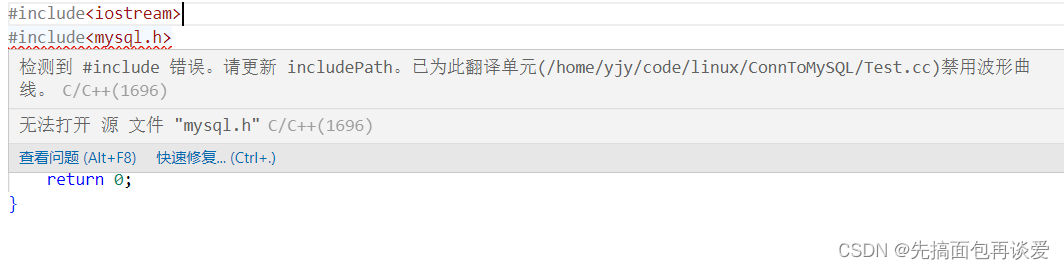
这里vscode自动报错了。
编译的时候加上-I选项:
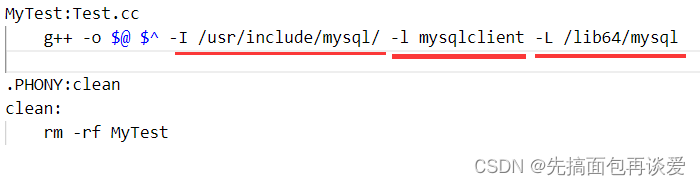
编译:
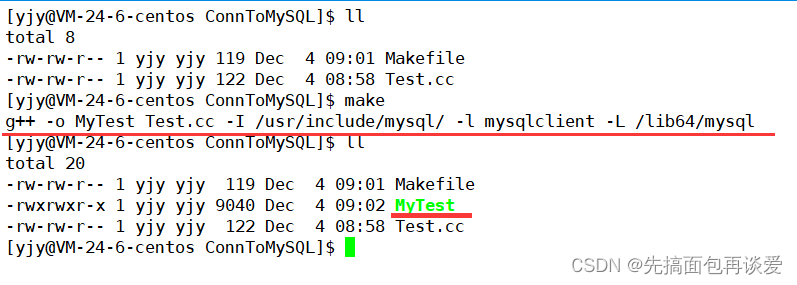
成功。
所以小总结一下:
#include指明引用哪个头文件
-I(i)指明头文件位置
-l指明链接哪个库文件
-L指明库文件的位置
对库的操作
C/C++对库的操作,要在官网中查看有哪些函数接口。
库中会有很多的数据结构:
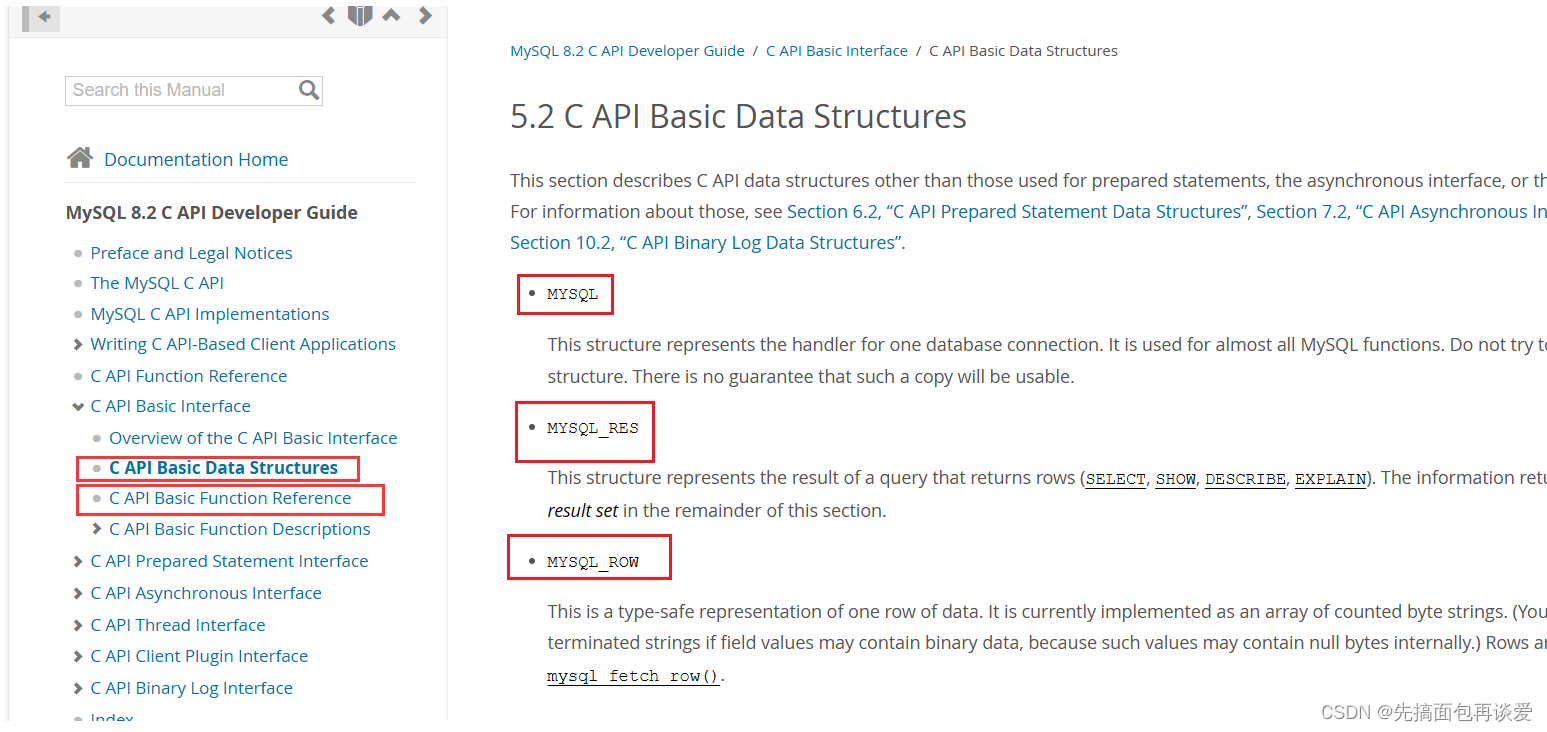 这里有很多数据结构,不过最常用的就前几个。
这里有很多数据结构,不过最常用的就前几个。
函数接口介绍
在进行mysql的操作前一定要先连接上mysql服务器,而连接前还要创建一下mysql提供的一些基础数据结构。
mysql_init()
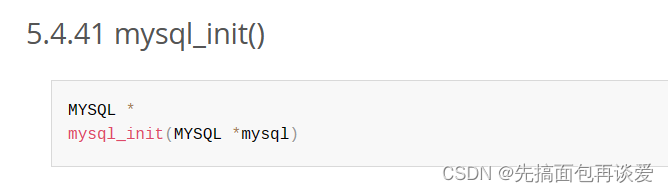
这个函数会帮我们创建一个MYSQL类型的对象,MYSQL就是一个结构体:
typedef struct st_mysql
{
NET net; /* Communication parameters */
unsigned char *connector_fd; /* ConnectorFd for SSL */
char *host,*user,*passwd,*unix_socket,*server_version,*host_info;
char *info, *db;
struct charset_info_st *charset;
MYSQL_FIELD *fields;
MEM_ROOT field_alloc;
my_ulonglong affected_rows;
my_ulonglong insert_id; /* id if insert on table with NEXTNR */
my_ulonglong extra_info; /* Not used */
unsigned long thread_id; /* Id for connection in server */
unsigned long packet_length;
unsigned int port;
unsigned long client_flag,server_capabilities;
unsigned int protocol_version;
unsigned int field_count;
unsigned int server_status;
unsigned int server_language;
unsigned int warning_count;
struct st_mysql_options options;
enum mysql_status status;
my_bool free_me; /* If free in mysql_close */
my_bool reconnect; /* set to 1 if automatic reconnect */
/* session-wide random string */
char scramble[SCRAMBLE_LENGTH+1];
my_bool unused1;
void *unused2, *unused3, *unused4, *unused5;
LIST *stmts; /* list of all statements */
const struct st_mysql_methods *methods;
void *thd;
/*
Points to boolean flag in MYSQL_RES or MYSQL_STMT. We set this flag
from mysql_stmt_close if close had to cancel result set of this object.
*/
my_bool *unbuffered_fetch_owner;
/* needed for embedded server - no net buffer to store the 'info' */
char *info_buffer;
void *extension;
} MYSQL;
这个MYSQL结构体有很多保存连接的字段,用来标识MySQL客户端相关的资源,就像C中的FILE、系统中的fd一样,都是用来唯一标识某些资源的,都可以被称为句柄。
mysql_init()调用成功会返回一个MYSQL对象,失败了会返回空。
传参的时候给一个nullptr就会直接创建新对象。
mysql_close()
这里的MYSQL就像C中的FILE一样,创建好了之后在最后还要关闭,关闭的函数就是mysql_close:
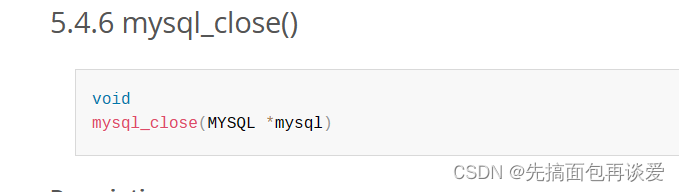
传入的就是mysql_init()创建出来的MYSQL对象指针,用来关闭连接,释放资源等。
来写写代码:

mysql_real_connect()

第一个参数就是刚刚创建出来的my。
host就是主机是哪台,本篇就测试本地中的mysql服务器,所以等会传localhost或者127.0.0.1就行。
user为连接服务器所用的用户,就是root或普通用户啥的。
paswd就是用户对应的密码。
db就是你在以user身份登录的时候要选择哪个数据库。等会就是用最开始创建的那个conn库来演示,不过这个库是空的,等会演示的时候再创建表。
port即mysql服务器的端口号(这里根据自己设定的端口来定,你可以用netstat -nltp来查看你的端口是啥)。
mysql在本地服务时采用域间套接的方式,类似于管道那样直接和mysql服务端通信,不走网络的那一套。这里不管是域间套接还是网络,后面两个参数设置为nullptr和0就行。
mysql_real_connect调用成功就返回传入的my,失败就返回空,有点像strcpy,成功了就返回原串。
写写代码:
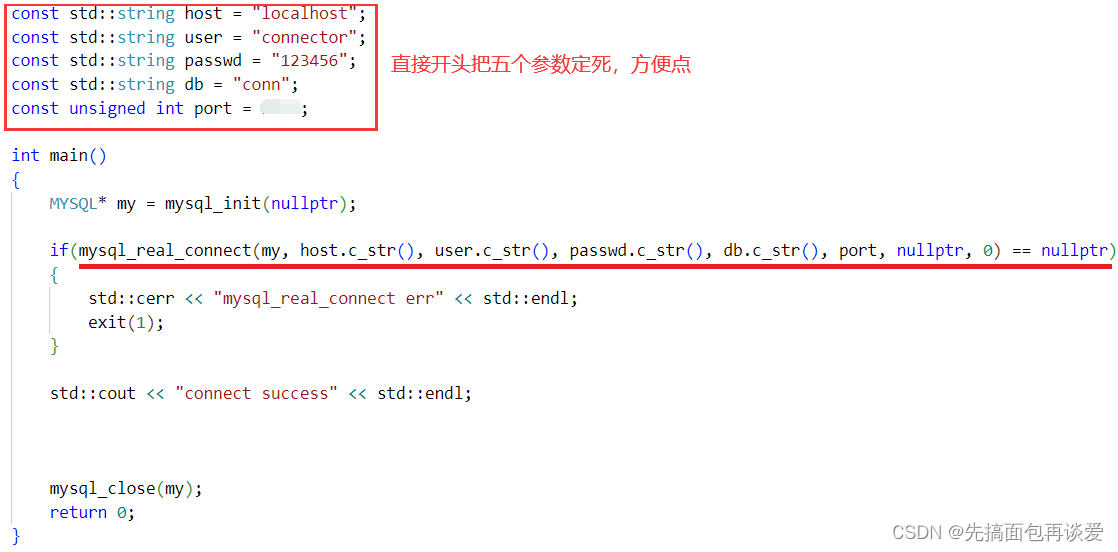
这样就可以连接数据库了。
这里我加上sleep来测试一下:

运行,用processlist查看连接的用户信息:
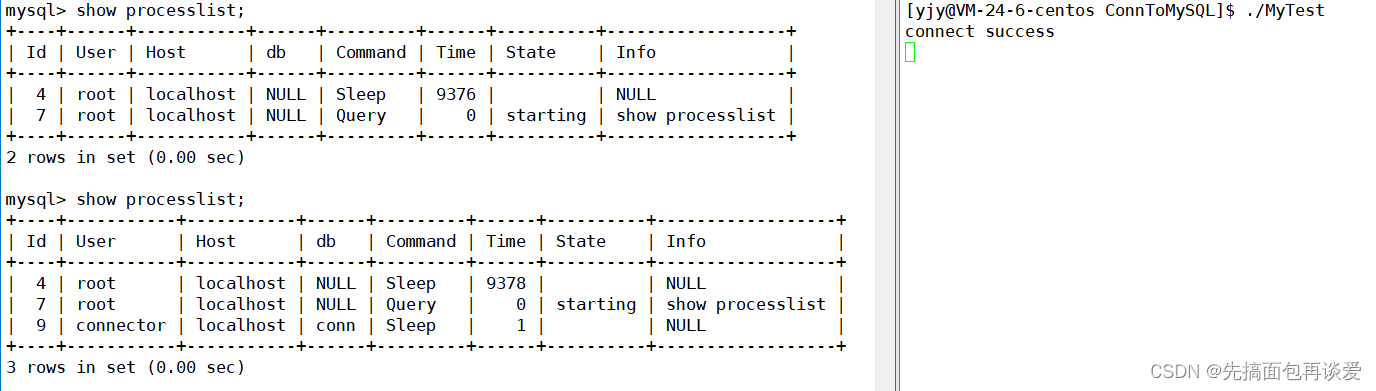
10s后:
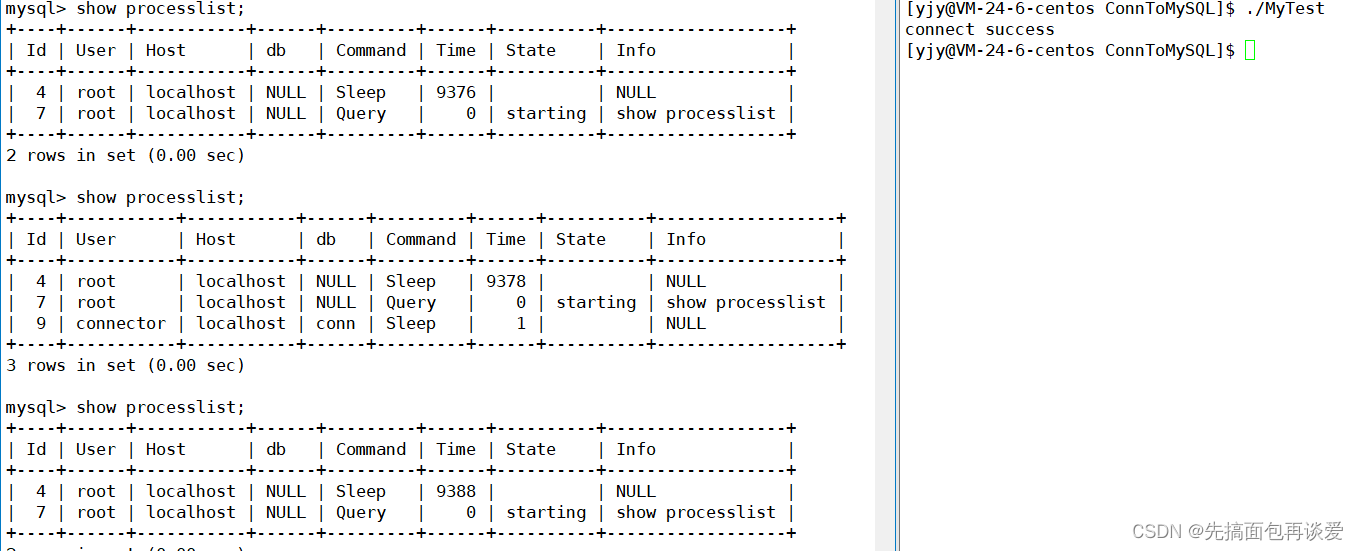
可以看到很成功。
有一个mysql_query:
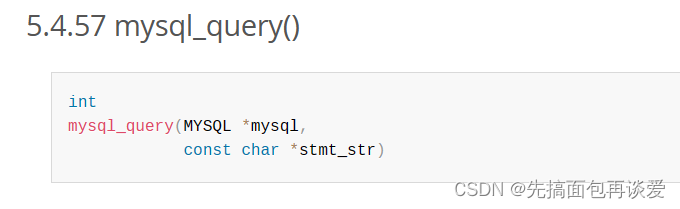
这个函数会将我们传入的stmt_str作为一条sql语句去执行。
执行成功返回0,失败返回非零值。
来写一个创建表的语句:
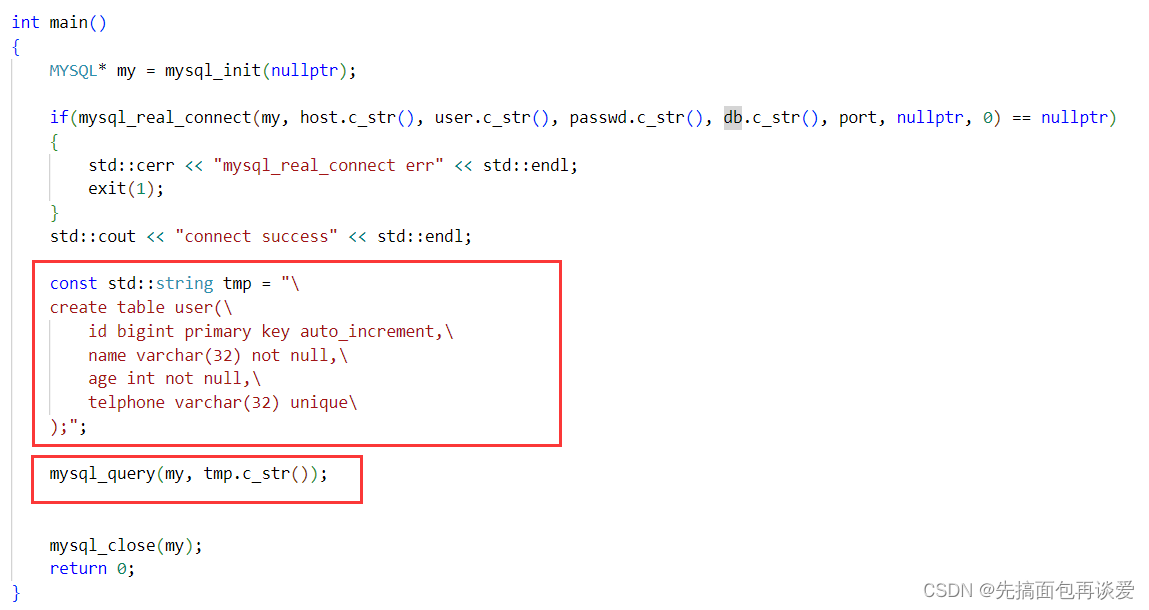
这里是可以执行的:
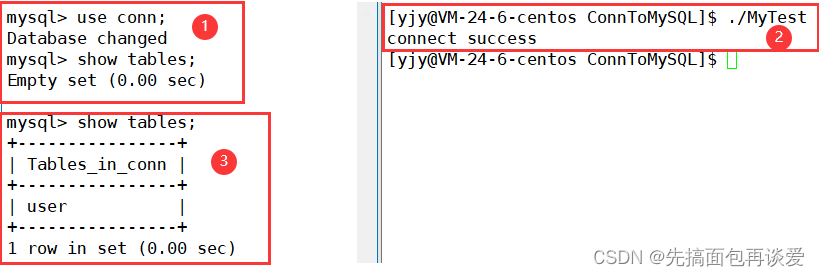
desc:
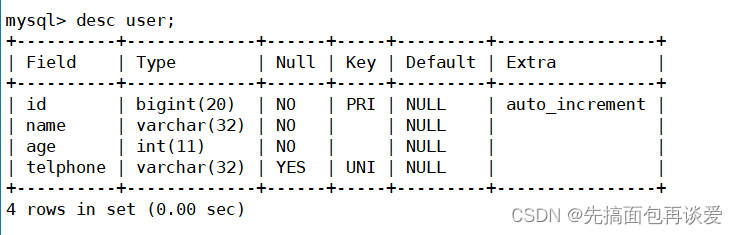
mysql_query的时候传入的sql不需要加分号或者\G。
其实我们完全可以根据mysql_query来写一个我们自己的mysql客户端,不过这样做意义不大,但还是演示一下吧。
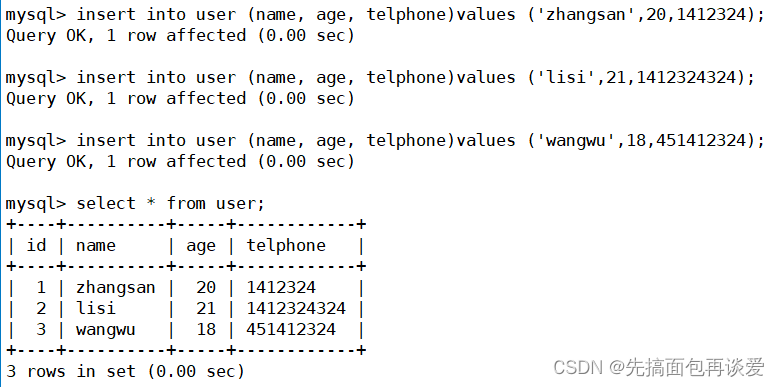
我这里先用mysql客户端插入几条记录:
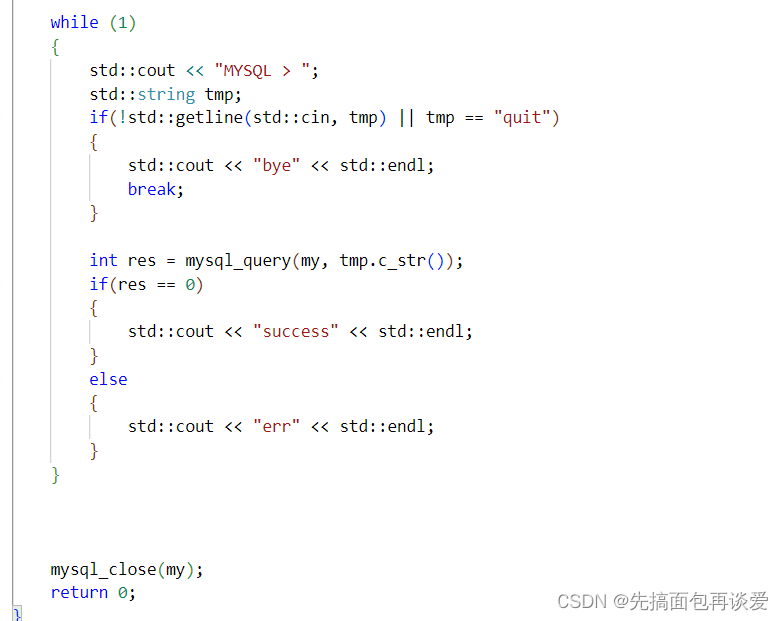
然后再来改改代码:
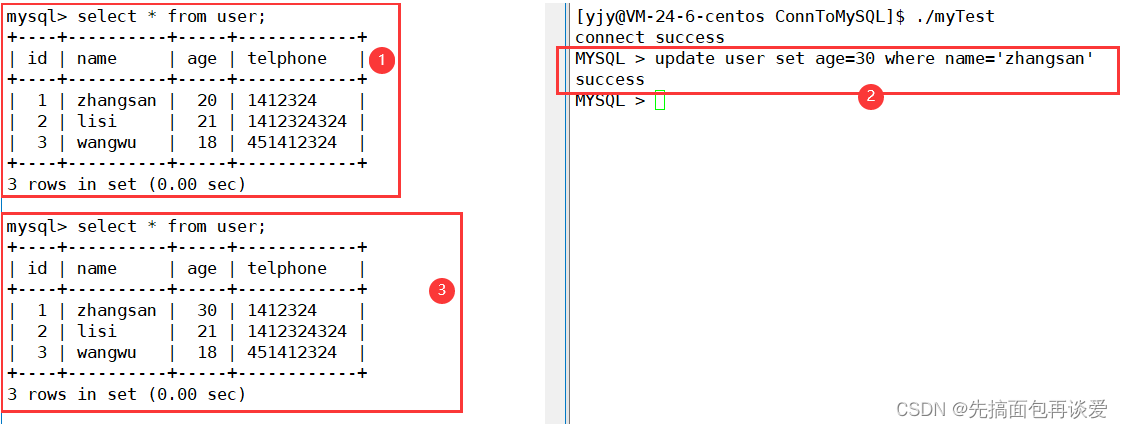
更新:
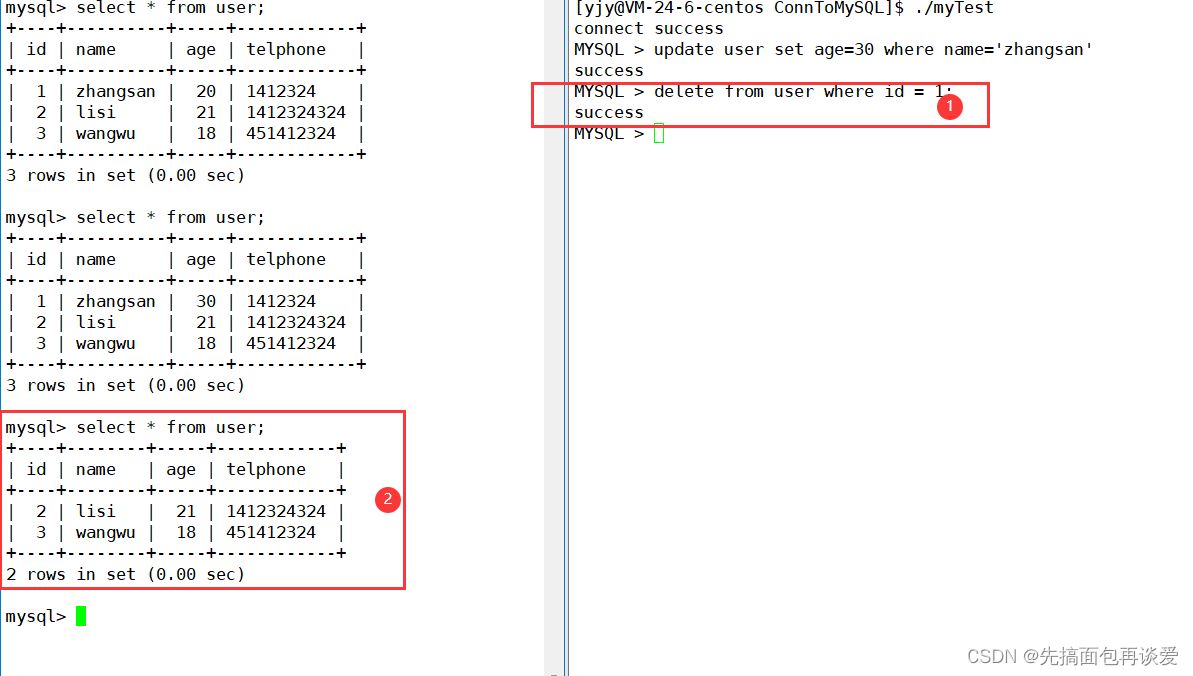
删除:
插入:
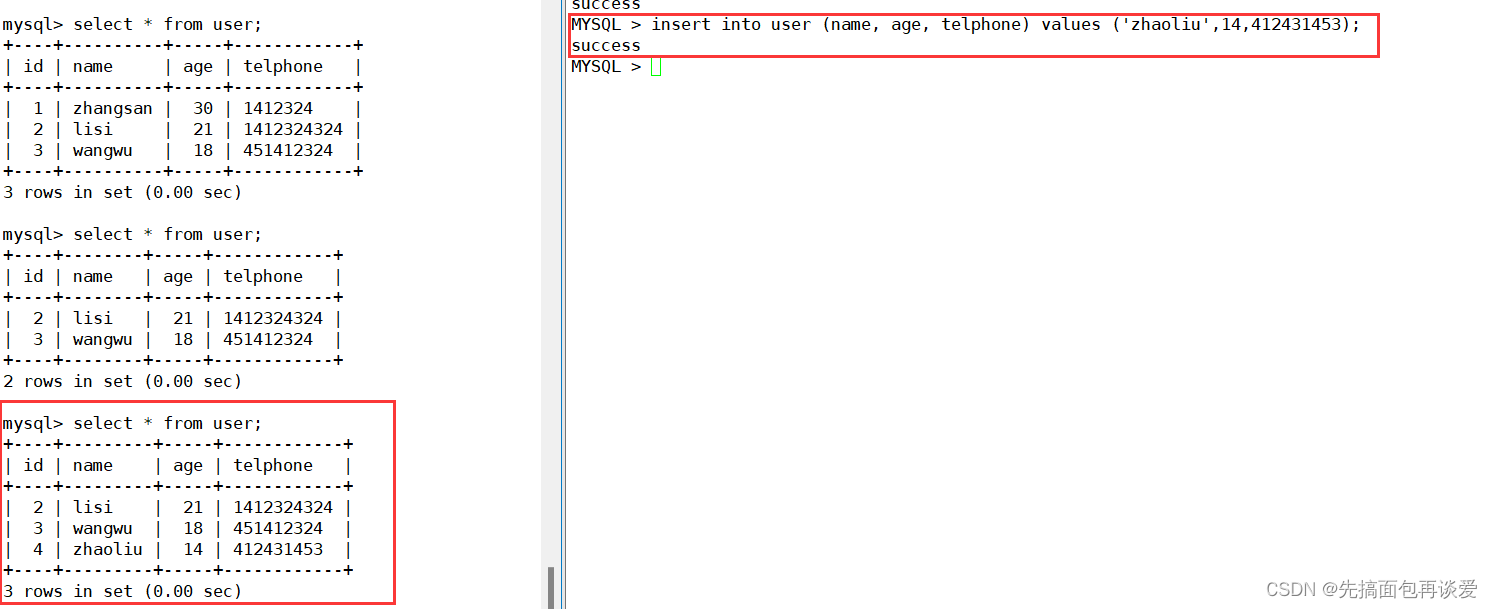
前面我都是可以的在插入英文,如果我现在插入一个中文:
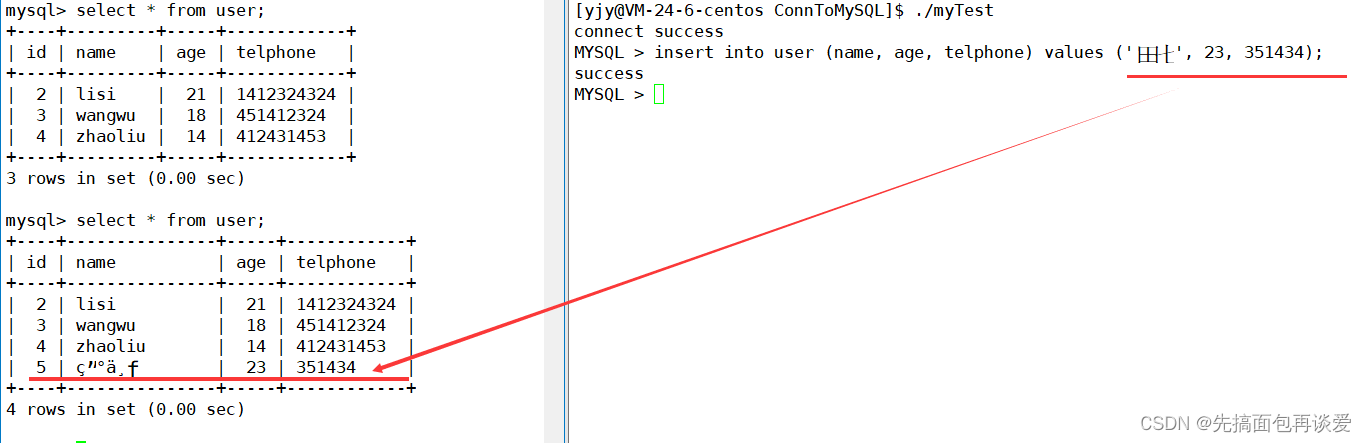
可以看到乱码了。
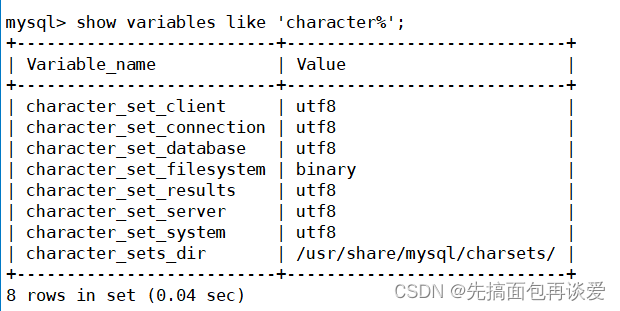
这里写的这个相当于是我自己的客户端,就和mysql客户端是一个性质的东西,我这里设置了mysql客户端的默认编码就是UTF8,和服务端一样:
但是我手写的这个简易客户端并没有设置,可以用mysql_get_character_set_info这个接口来查看当我们手写的这个客户端当前的编码:
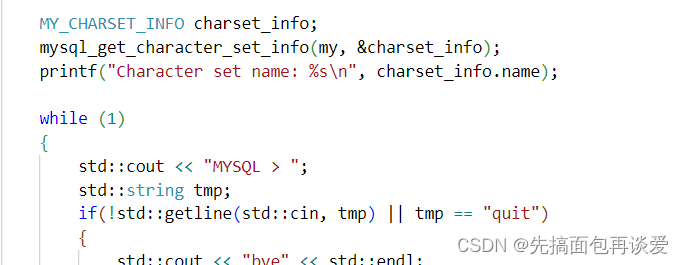
运行:
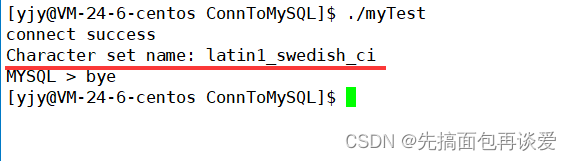
或者直接用mysql_character_set_name:


可以看到是拉丁的编码,肯定和我们服务端UTF8的编码不匹配,所以我们要手动设置一下我们这个客户端的编码,用mysql_set_charcter_set函数:

运行:
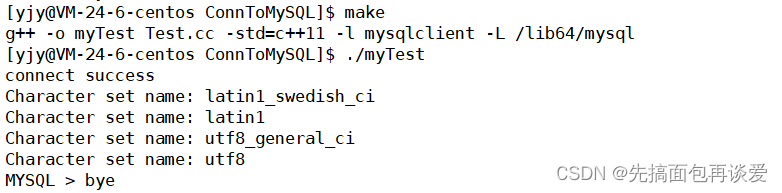
这样将编码修改后,就可以插入中文了:
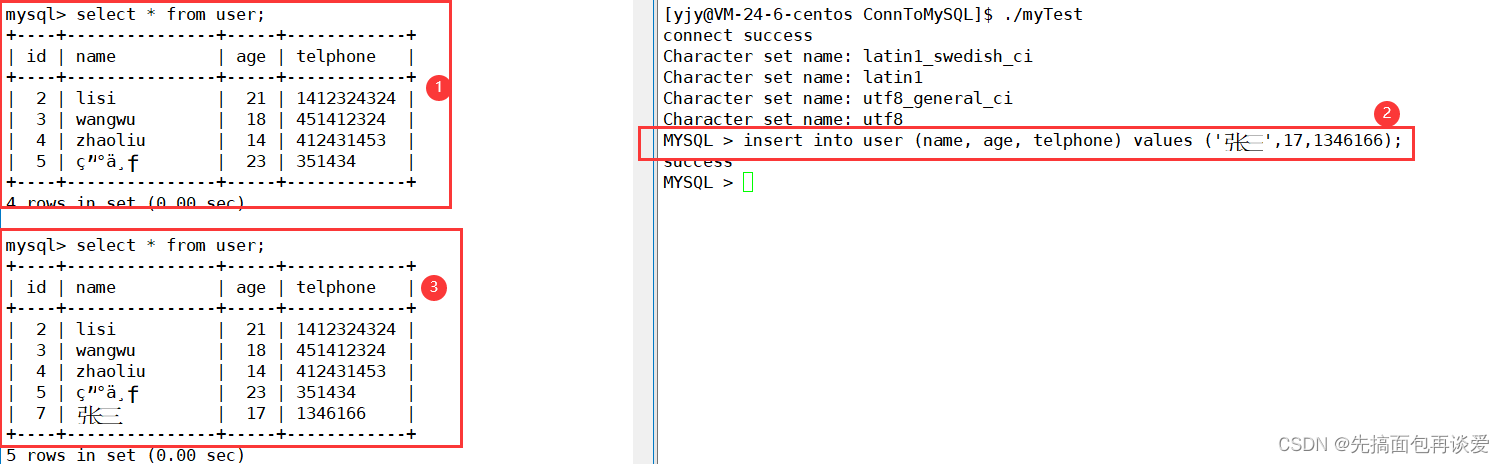
成功。
再来演示一下退出:
执行ctrl + d试试:
正常退出。
输入quit:
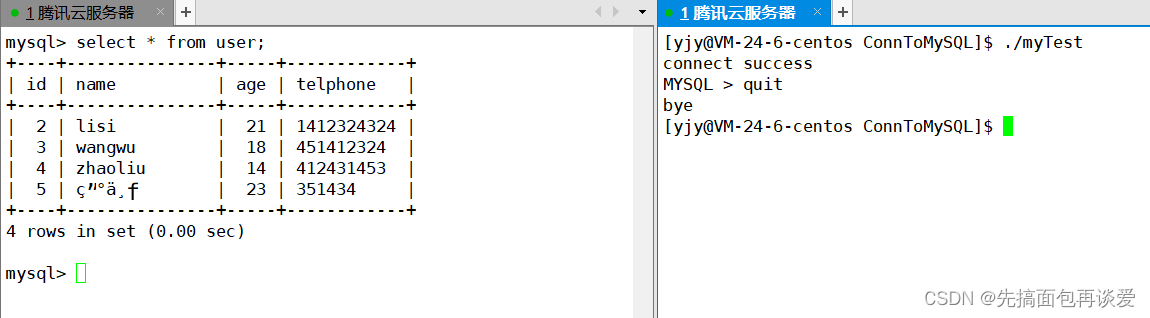
也是正常退出。
select 查找
前面的这三个增删改都能成功,但是查找还不行:
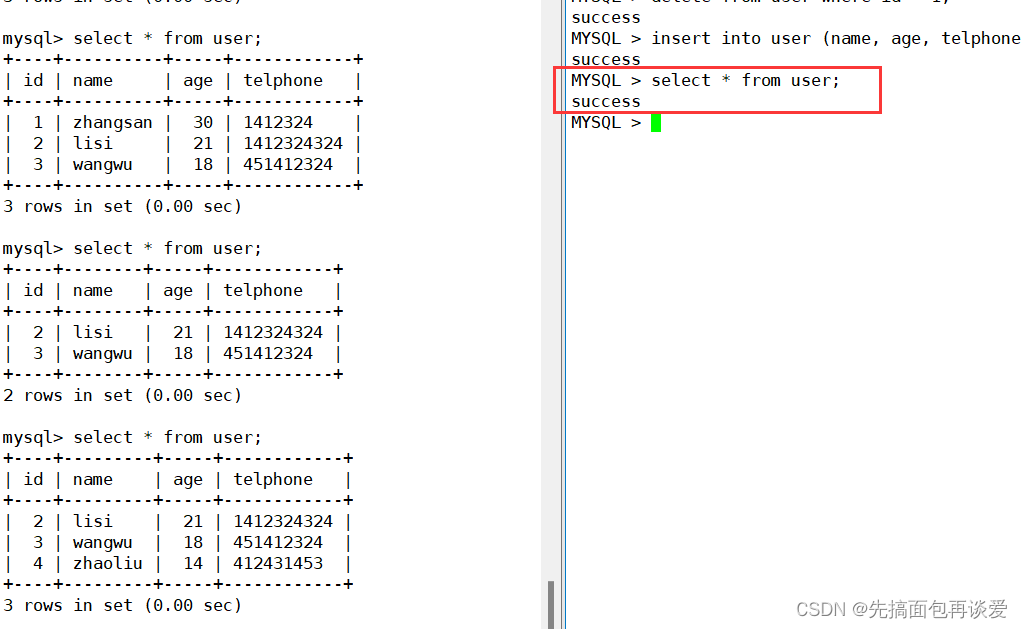
因为查找的结果需要我们自己提取。这里mysql_query只是执行以下sql而已,结果并没有返回,不过单次执行的结果会放到刚刚最开始创建出来的my对象中,我们需要将其中的返回结果手动提取出来。
用mysql_store_result函数:
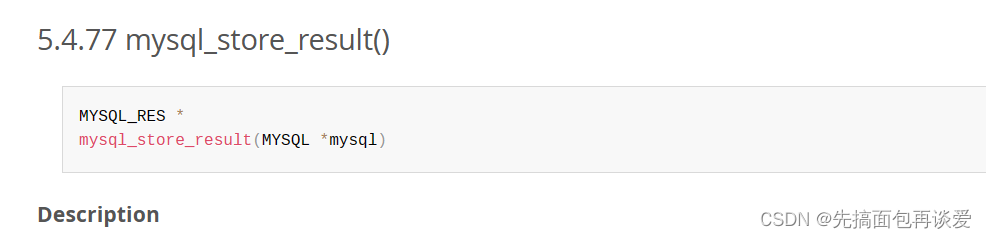
可以看到这个函数参数就是刚刚的my,返回一个MYSQL_RES结构体的指针,来看看这个结构体中有什么:
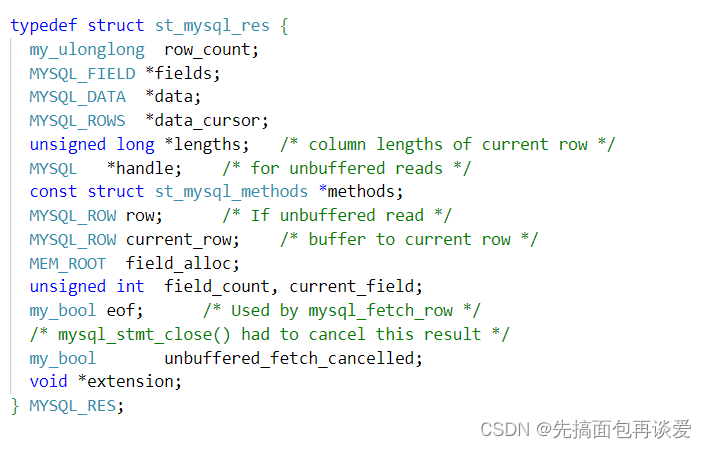
很多字段。
从这里开始的代码,就和前面的创建的my对象没有什么关系了,后面只用这个MYSQL_RES的对象。
函数返回nullptr的时候有两种情况,一种是执行了非select语句的(比如update、delete、insert),这种不需要什么返回结果,只需要mysql_query的返回值就够了。一种是直接出错了,所以如果是返回空的时候要用其他函数来检查一下,具体我就不说了,看官方的文档介绍:

我们用select查找出来的结果中可能会有多条记录,而且多条记录中还会有很多不同列的字段,比如说用mysql客户端查找出来的表格:
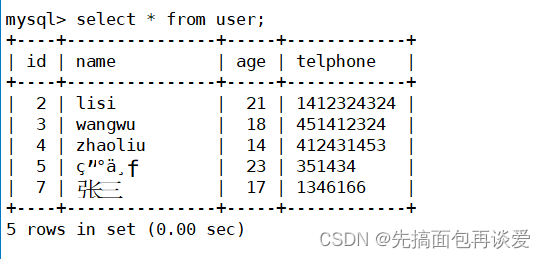
把其中的格子去掉:

当我用我自己写的这个简易客户端执行select语句后,上面的这些数据就会全部被保存在MYSQL_RES这个结构体中。
不管库中的数据是以什么类型存放的,读取出来的时候都是当做字符串来看的。也就是说上面去掉框框的这些数据都是拿出来之后都是字符串,以字符串的形式保存在MYSQL_RES中的。
来搞一个全是元素为char*的二位数组:

对应的,将这个数组中的char*指针指向上面的所有数据:
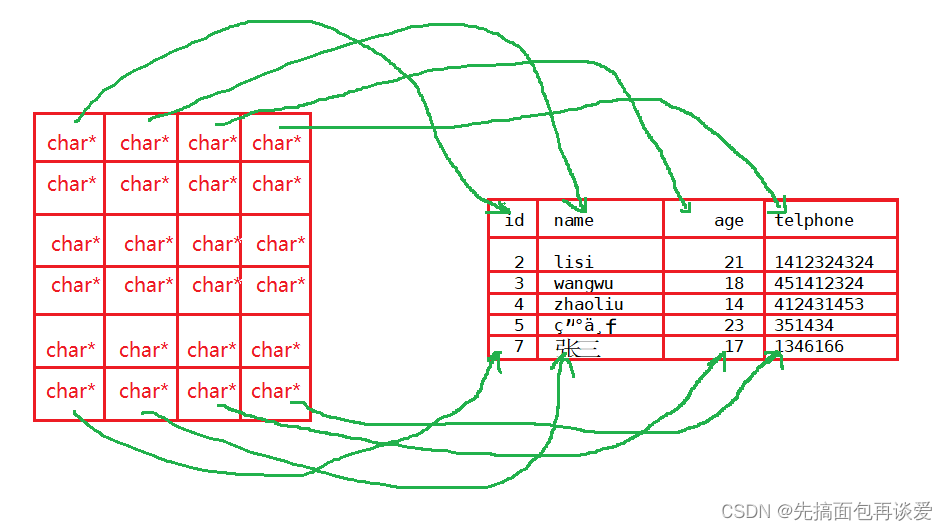
中间的没有画,我怕一下子给画乱了,反正你懂我意思就行,就是一个char*指向一个字符串,一一对应。
所以其实可以把MYSQL_RES这个结构体当做二位数组来看。
我们可以通过mysql_num_rows来获取表的行数,用mysql_num_fields来获取表的列数:

但是如果不是select函数就会返回空,那么就不会有这些结果:
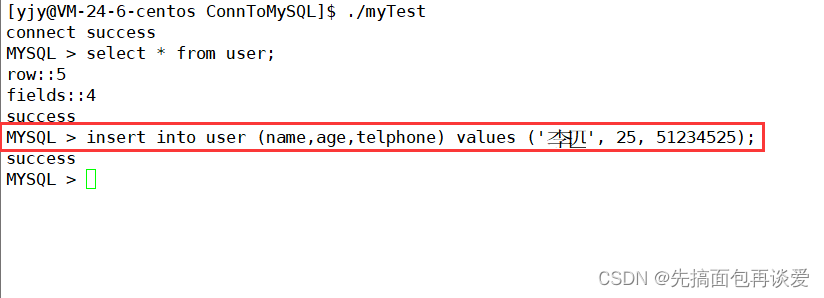

但是我们不仅要知道有多少列,重要的是获取出来其中的结果,所以要想办法遍历结果集,就像遍历上面的那个元素为char*的二维数组一样,把每一个元素所指向的字符串搞出来,mysql为了支持我们进行遍历,内部提供了MYSQL_ROW类型,可以获取到二维数组中的每一行,
其实这个类型就是char**:

其实也很好理解,假如说上面的二维数组为char* arr[x][y],第一个元素类型为char*,如果想要找到第一个元素的地址,那么就是char** ,这样就等于是一整行的地址就找到了。但是有很多行,底层就会类似这样的方式来找对应行:
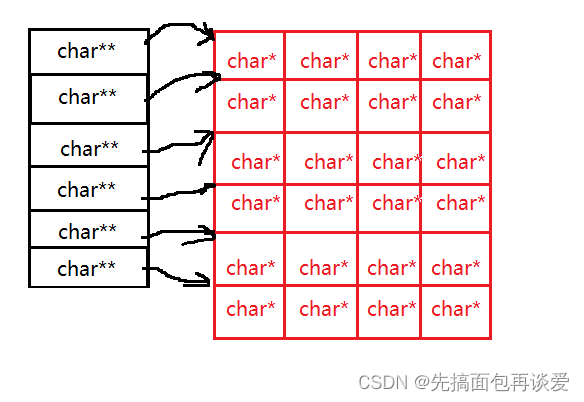
我们通过mysql_fetch_row函数来获取每一行:
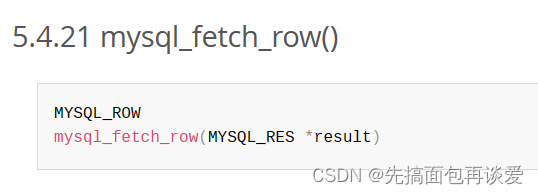
这个传入res,返回一个char**,而且调用这个函数会自动帮我们提取到下一行,就像范围for一样,自动迭代。
拿到一个MYSQL_ROW对象之后就可直接向数组一样用就行。
代码如下:
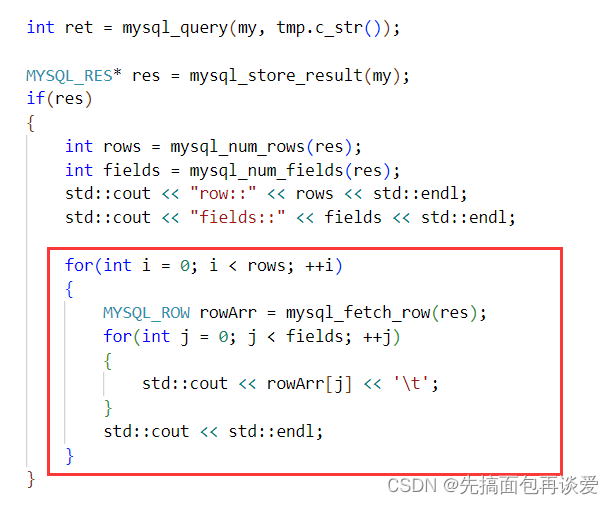
运行:
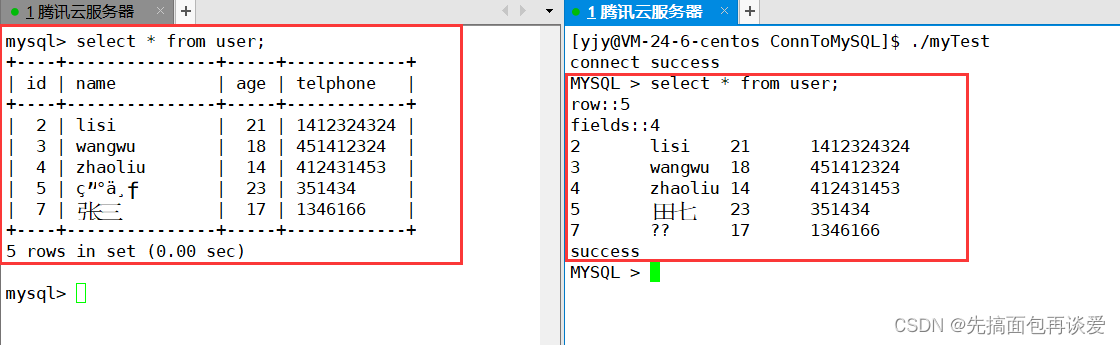
这样就能查到所有的数据了。
不过没有拿到每一列的列类型,要用另一种数据结构MYSQL_FIELD,也是个结构体:

里面字段很多,倒数第二个字段type,类型为enum_filed_types,这个类型要说一下:
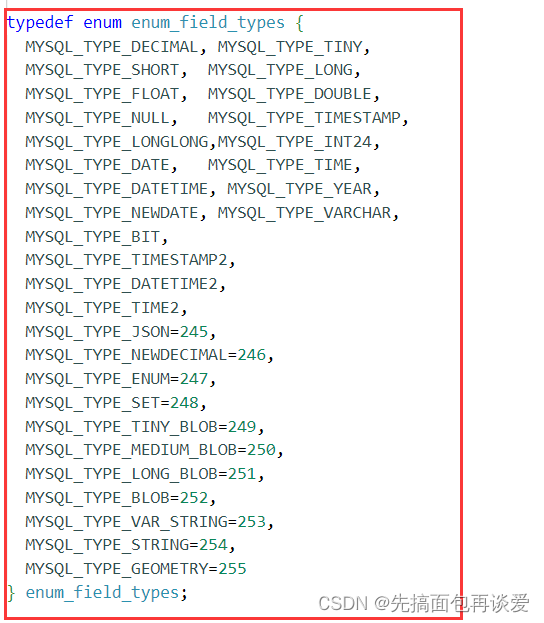
其中就是所有的数据类型,当我们拿到了全是字符串的数据后,想要转回原来的数据类型,就可以根据type字段来提取。
调用mysql_fetch_fields:
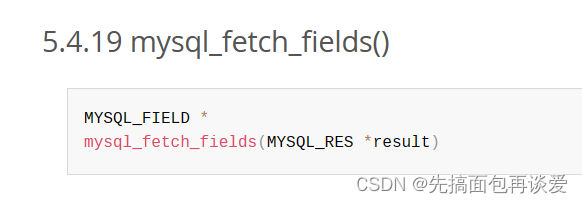
返回值为MYSQL_FIELD类型的指针。用的时候也可以像刚刚的MYSQL_ROW的对象一样:
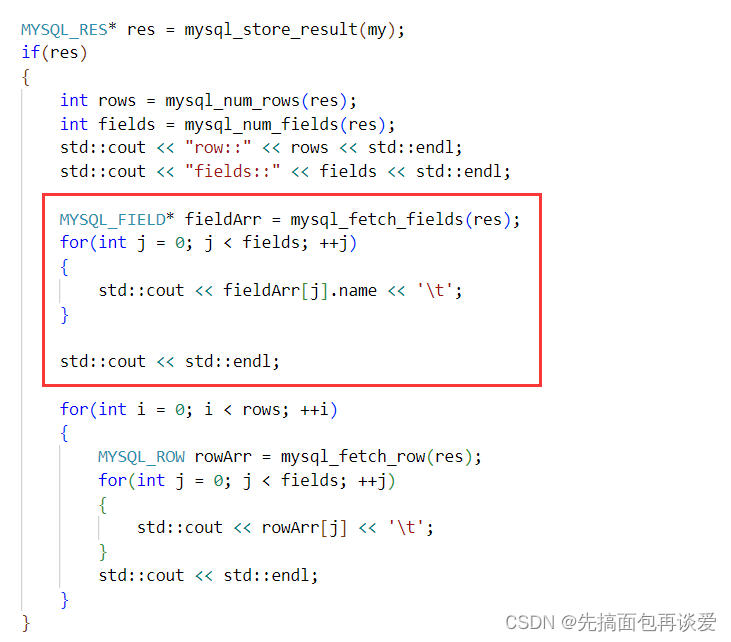
运行:
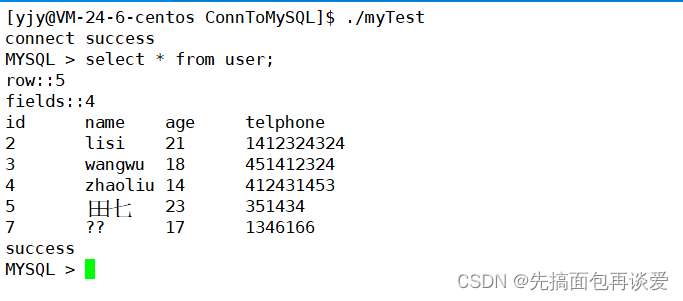
就和mysql客户端打印出来的结果是一样的。
MYSQL_FIELD中还有很多字段,比如说db表示当前选中了哪个数据库,table表示当前是哪一张表:
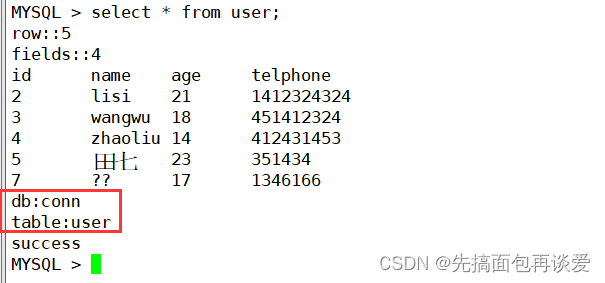
所以其实我们就可以控制一下打印格式,加上那些框框啥的,就和mysql客户端一样了,不过这样做没啥意义。
记得用完这个MYSQL_RES的结构体的对象后要释放掉对应的空间,这个结构体字段很多,占用空间还是不小的,用mysql_free_result就可以:
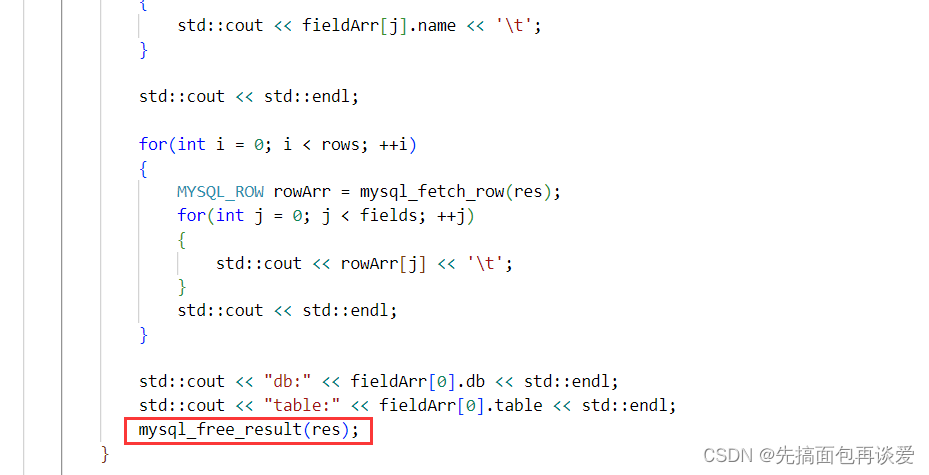
其实前面的res可以直接写到if的判断里面:
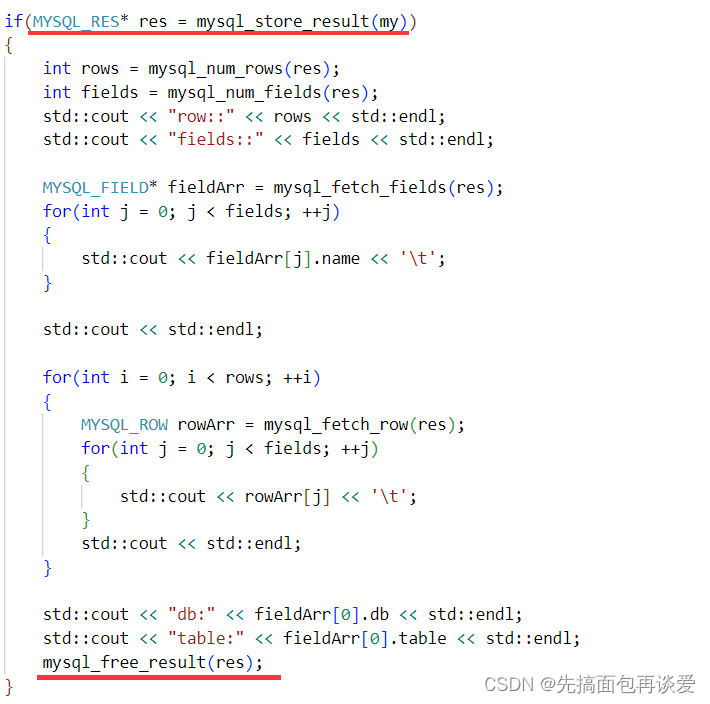
这样就可以根据res来分成一个模块,正好。
正常的使用方式
仅查找
我们平时用语言连接上数据库之后不是这样写一个死循环,然后再输入得到结果,要是这样的话不如直接用mysql客户端,一般都是针对于某一个功能只执行一条语句,比如说我只想要查询,那就只执行查询的sql,不加循环:
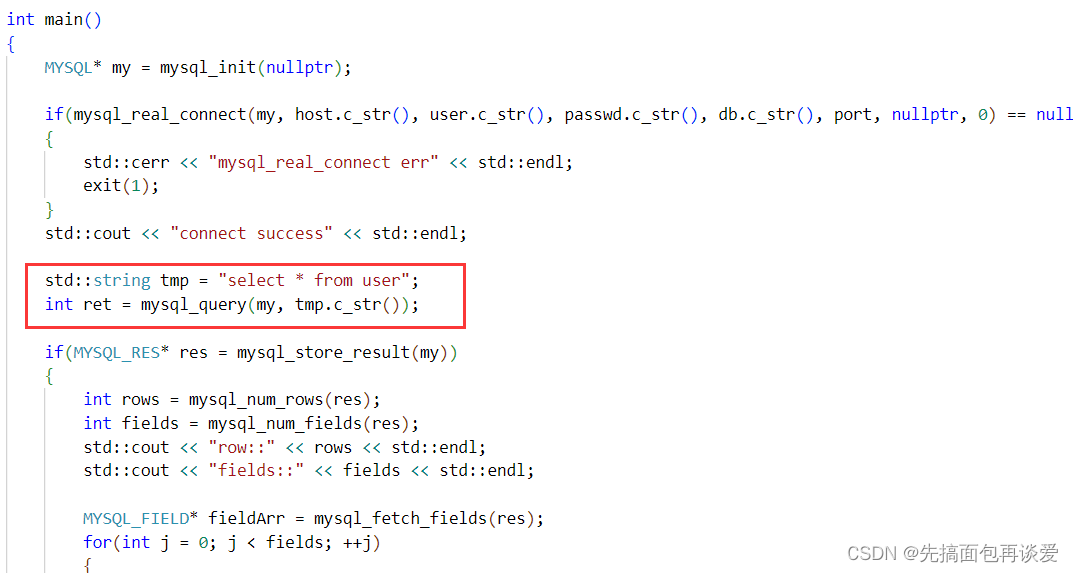
直接运行就是结果:
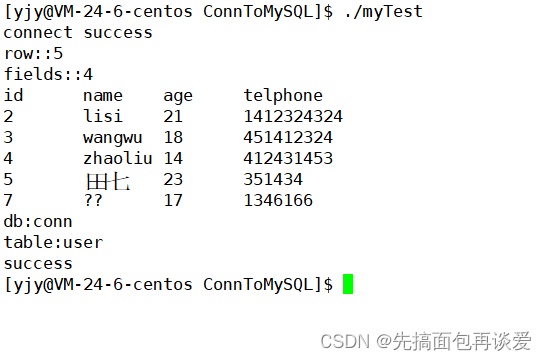
去除掉杂七杂八的打印:
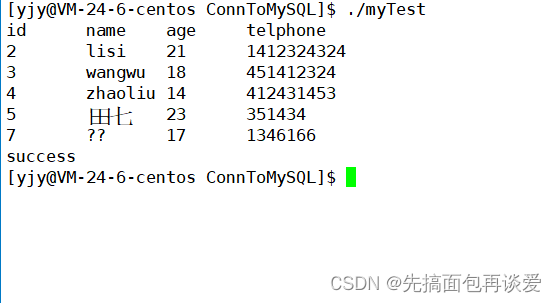
这样就能打印成功。
仅插入
光是一个插入的,那就更简单了,都不需要MYSQL_RES了。
代码:
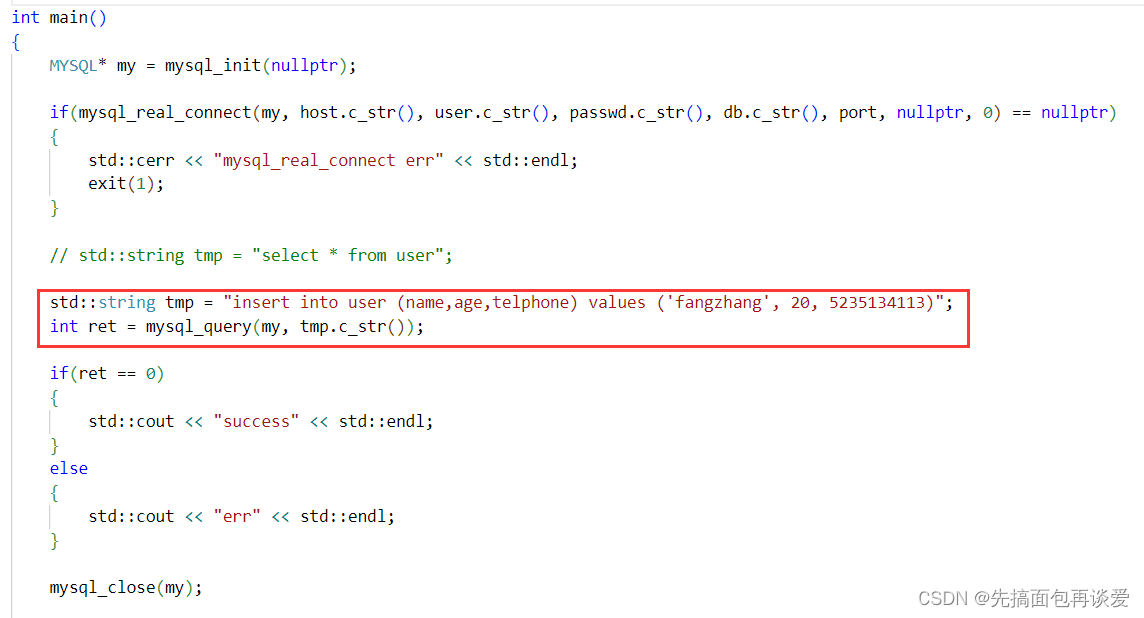
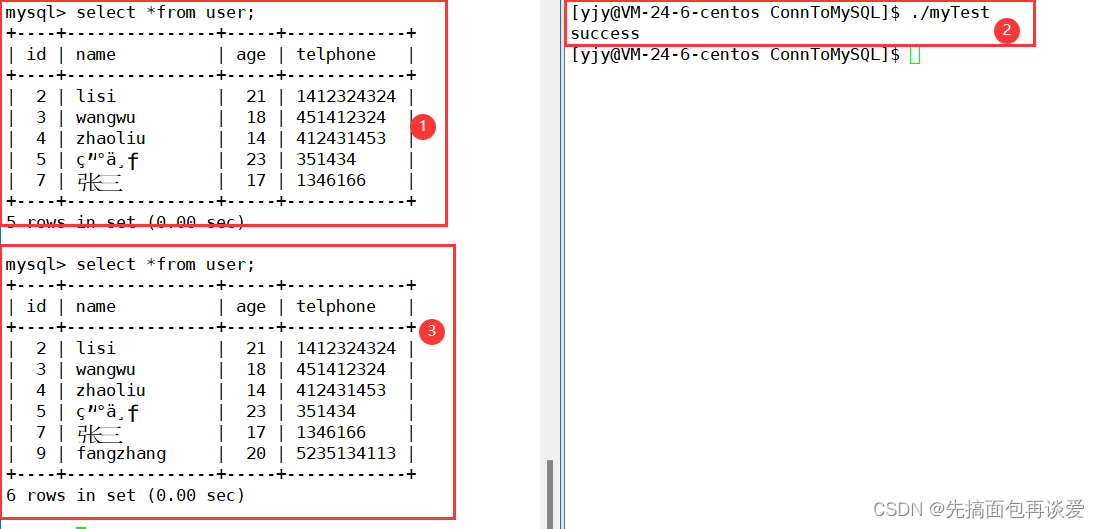
运行:
mysql图形化界面
mysql的图形化界面有不少,像Navicat、SQLyog都是比较好用的,不过二者要收费,你可以用破解版的,不过我这里就不说怎么搞了,感兴趣的老铁自行百度。
介绍一下MYSQL Workbench,这是个MYSQL官方提供的图形化界面,不过用起来没有上面的Navicat和SQLyog爽。
下载MYSQL Workbench,直接进MYSQL官网就行,跟着我步骤来:
往下翻:
进去之后:
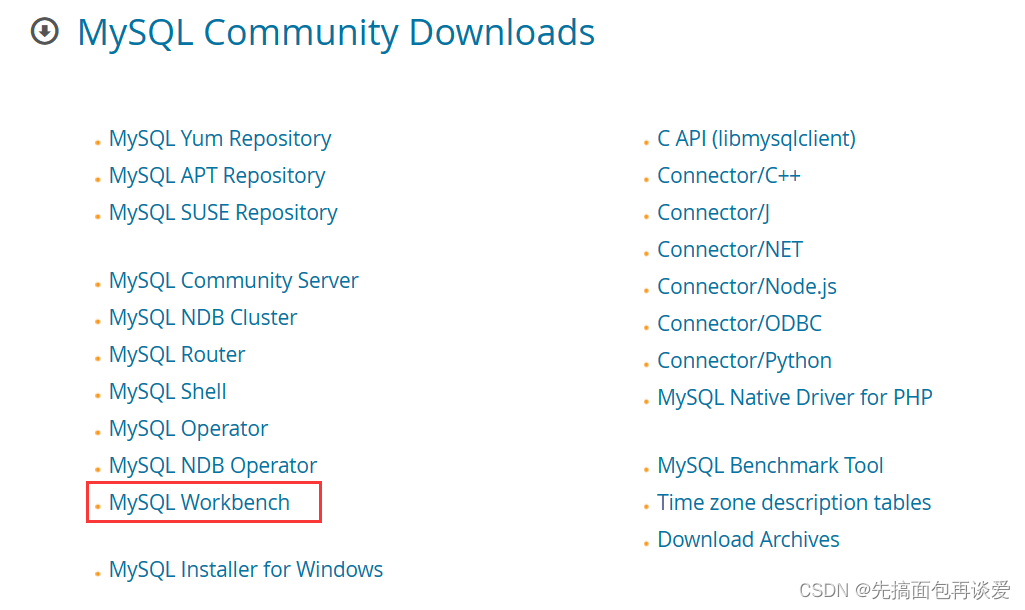
进去后:
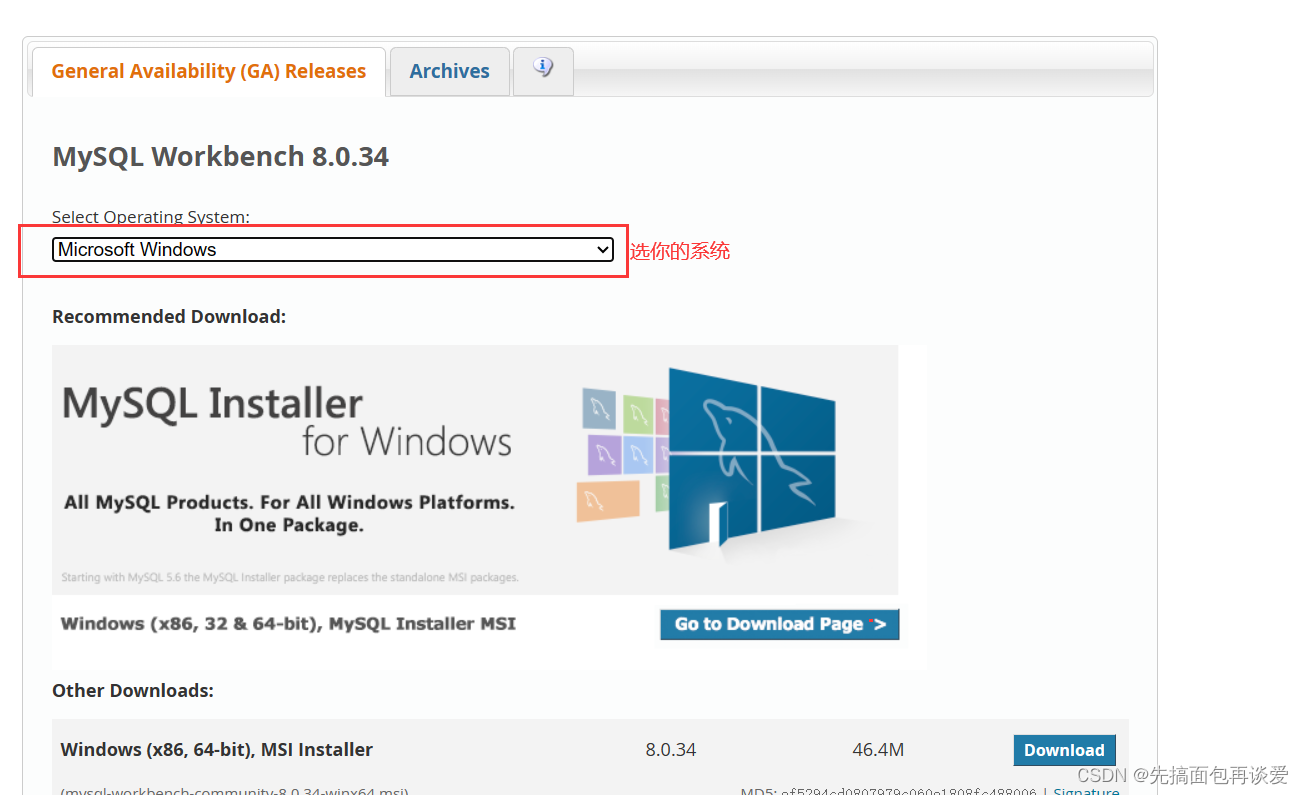
win下就一个版本,直接下就行。
不过下载时,你要有一个Oracle的账户,登陆之后选择一下你的身份信息啥的就能直接下载安装包了。
安装的时候一路next就行(你可以换一下安装路径)。
安装好之后长这样:
图形化界面本质上也是一个客户端,但我这里没有加上我Linux下的远端MYSQL服务端,我先专门新建一个用户:
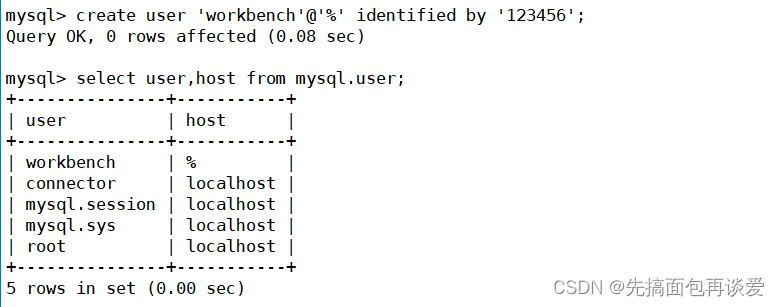
然后再将conn库的权限给这个用户:
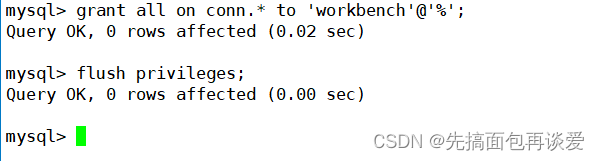
下面给我的workbench添加一个远端登录的用户:
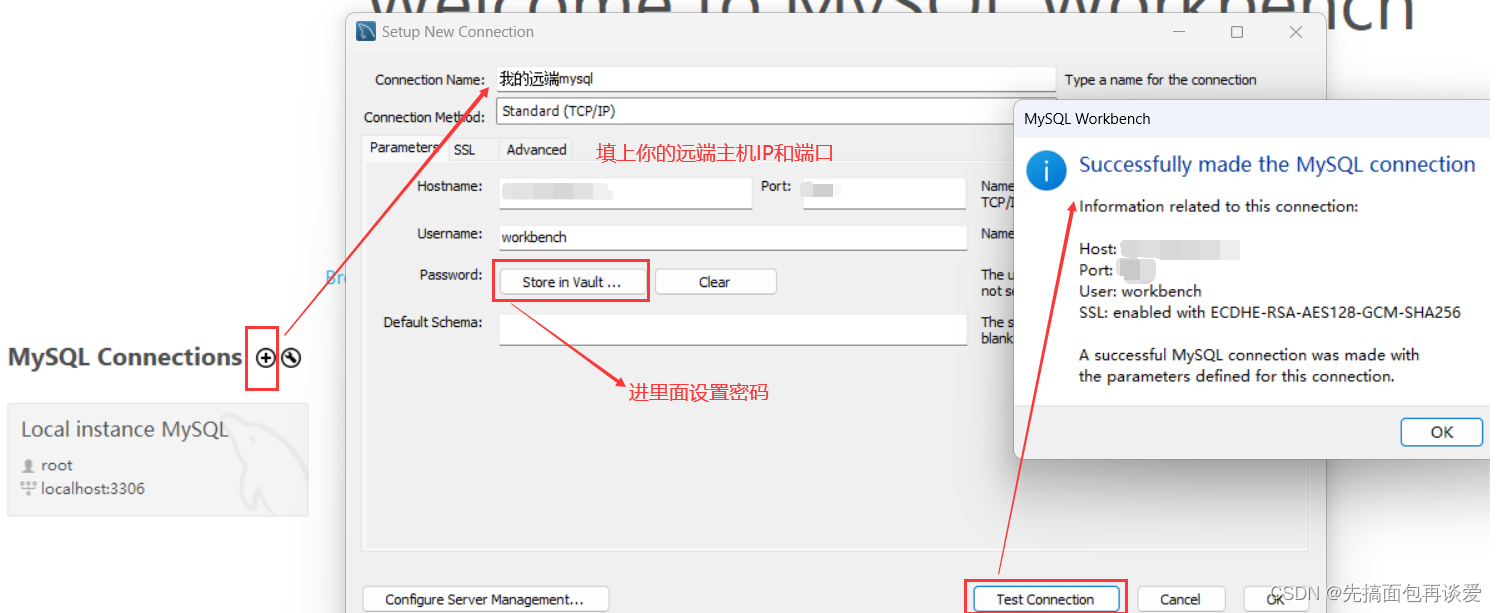
然后就会有对应的连接:
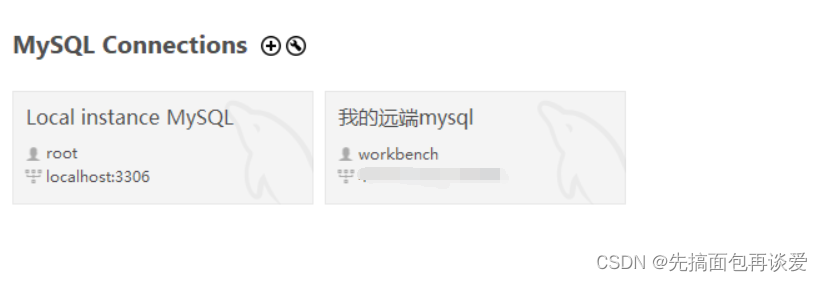
登录:
左侧能选择表:
里面可以输入sql:
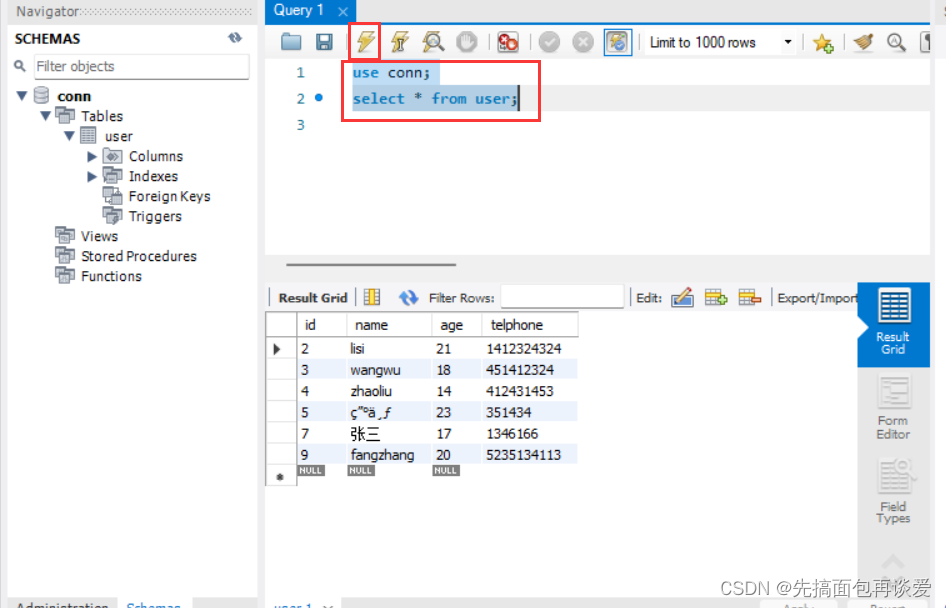
选中输入的sql然后按那个闪电就可以运行,还会有语法提示。
一些按键,比如说删除:
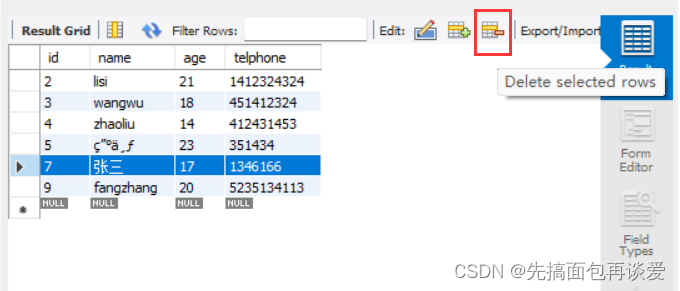
点一下就删了,很方便:
也可以手动插入:
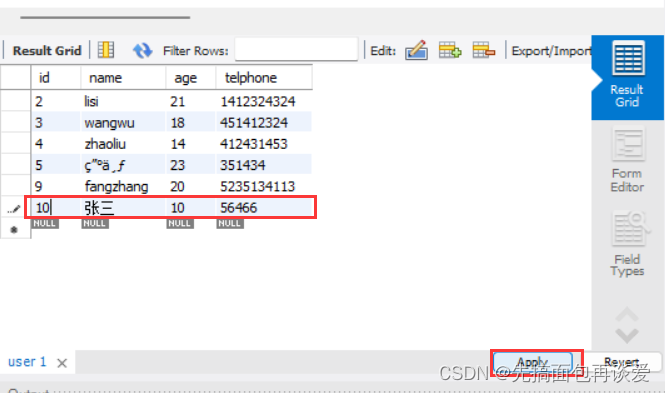
点击红色框住的Apply就可以查看对应的sql:
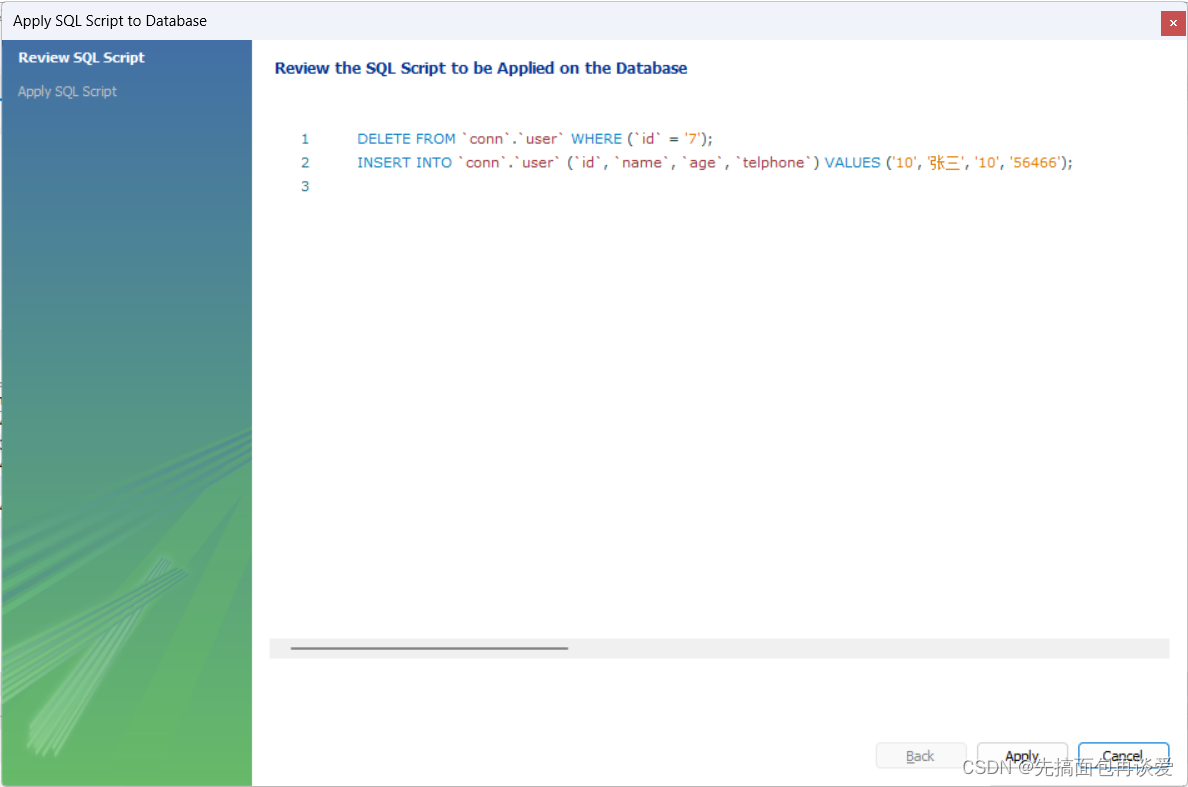
再按一下Apply就执行了:
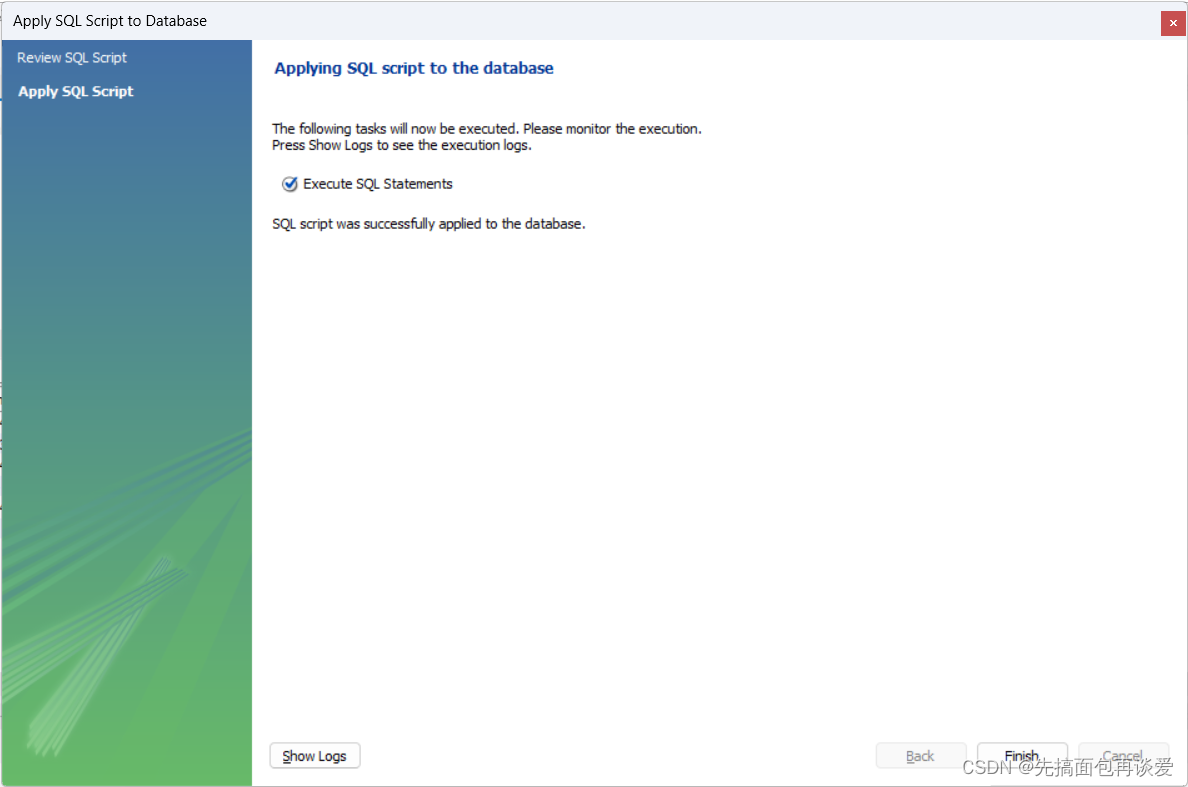
对应的远端也能看到:

就介绍到这,想要深入了解的同学可以自行学学。
Mysql连接池原理
像刚刚那样,连接一个客户端后发送一个sql就直接关闭连接,其实这样做挺浪费资源的,不如搞一个线程池,池中每个线程都连接数据库服务器,并维护一个任务队列,当有任务时就让线程拿任务,没有任务就让线程等待。
具体做法就不细说了,不懂的同学可以看看我线程池的那篇博客。
前面完整代码:
#include<iostream>
#include<mysql/mysql.h>
#include<unistd.h>
#include<string>
const std::string host = "localhost";
const std::string user = "connector";
const std::string passwd = "123456";
const std::string db = "conn";
const unsigned int port = xxxx; // 端口就不给了
int main()
{
MYSQL* my = mysql_init(nullptr);
if(mysql_real_connect(my, host.c_str(), user.c_str(), passwd.c_str(), db.c_str(), port, nullptr, 0) == nullptr)
{
std::cerr << "mysql_real_connect err" << std::endl;
exit(1);
}
// std::string tmp = "select * from user";
std::string tmp = "insert into user (name,age,telphone) values ('fangzhang', 20, 5235134113)";
int ret = mysql_query(my, tmp.c_str());
if(ret == 0)
{
std::cout << "success" << std::endl;
}
else
{
std::cout << "err" << std::endl;
}
mysql_close(my);
// if(MYSQL_RES* res = mysql_store_result(my))
// {
// int rows = mysql_num_rows(res);
// int fields = mysql_num_fields(res);
// MYSQL_FIELD* fieldArr = mysql_fetch_fields(res);
// for(int j = 0; j < fields; ++j)
// {
// std::cout << fieldArr[j].name << '\t';
// }
// std::cout << std::endl;
// for(int i = 0; i < rows; ++i)
// {
// MYSQL_ROW rowArr = mysql_fetch_row(res);
// for(int j = 0; j < fields; ++j)
// {
// std::cout << rowArr[j] << '\t';
// }
// std::cout << std::endl;
// }
// mysql_free_result(res);
// }
// 建个表
// const std::string tmp = "\
// create table user(\
// id bigint primary key auto_increment,\
// name varchar(32) not null,\
// age int not null,\
// telphone varchar(32) unique\
// );";
// 编码
// MY_CHARSET_INFO charset_info;
// mysql_get_character_set_info(my, &charset_info);
// printf("Character set name: %s\n", charset_info.name);
// printf("Character set name: %s\n", mysql_character_set_name(my));
//
// mysql_set_character_set(my, "utf8");
//
// mysql_get_character_set_info(my, &charset_info);
// printf("Character set name: %s\n", charset_info.name);
// printf("Character set name: %s\n", mysql_character_set_name(my));
// 循环的客户端
// while (1)
// {
// std::cout << "MYSQL > ";
// std::string tmp;
// if(!std::getline(std::cin, tmp) || tmp == "quit")
// {
// std::cout << "bye" << std::endl;
// break;
// }
// int ret = mysql_query(my, tmp.c_str());
// if(MYSQL_RES* res = mysql_store_result(my))
// {
// int rows = mysql_num_rows(res);
// int fields = mysql_num_fields(res);
// std::cout << "row::" << rows << std::endl;
// std::cout << "fields::" << fields << std::endl;
// MYSQL_FIELD* fieldArr = mysql_fetch_fields(res);
// for(int j = 0; j < fields; ++j)
// {
// std::cout << fieldArr[j].name << '\t';
// }
// std::cout << std::endl;
// for(int i = 0; i < rows; ++i)
// {
// MYSQL_ROW rowArr = mysql_fetch_row(res);
// for(int j = 0; j < fields; ++j)
// {
// std::cout << rowArr[j] << '\t';
// }
// std::cout << std::endl;
// }
// std::cout << "db:" << fieldArr[0].db << std::endl;
// std::cout << "table:" << fieldArr[0].table << std::endl;
// mysql_free_result(res);
// }
// if(ret == 0)
// {
// std::cout << "success" << std::endl;
// }
// else
// {
// std::cout << "err" << std::endl;
// }
// }
return 0;
}
到此结束。。。