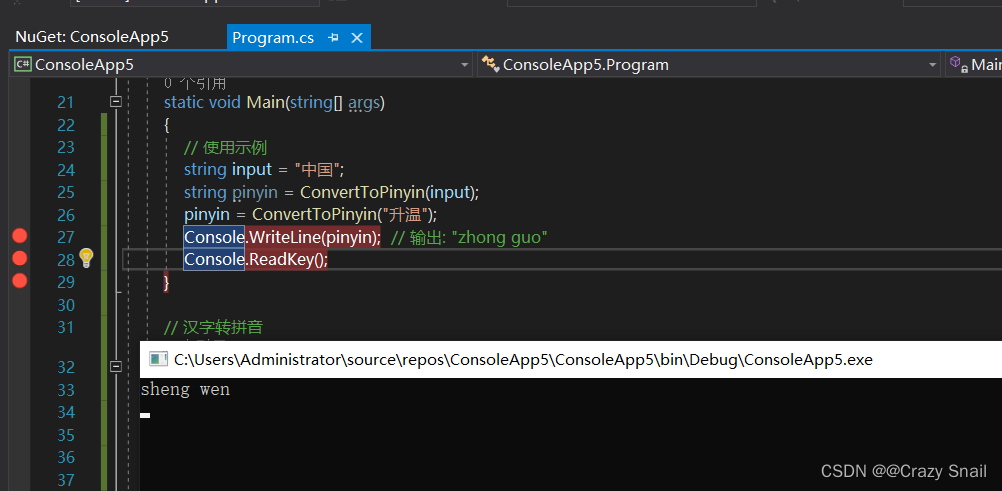
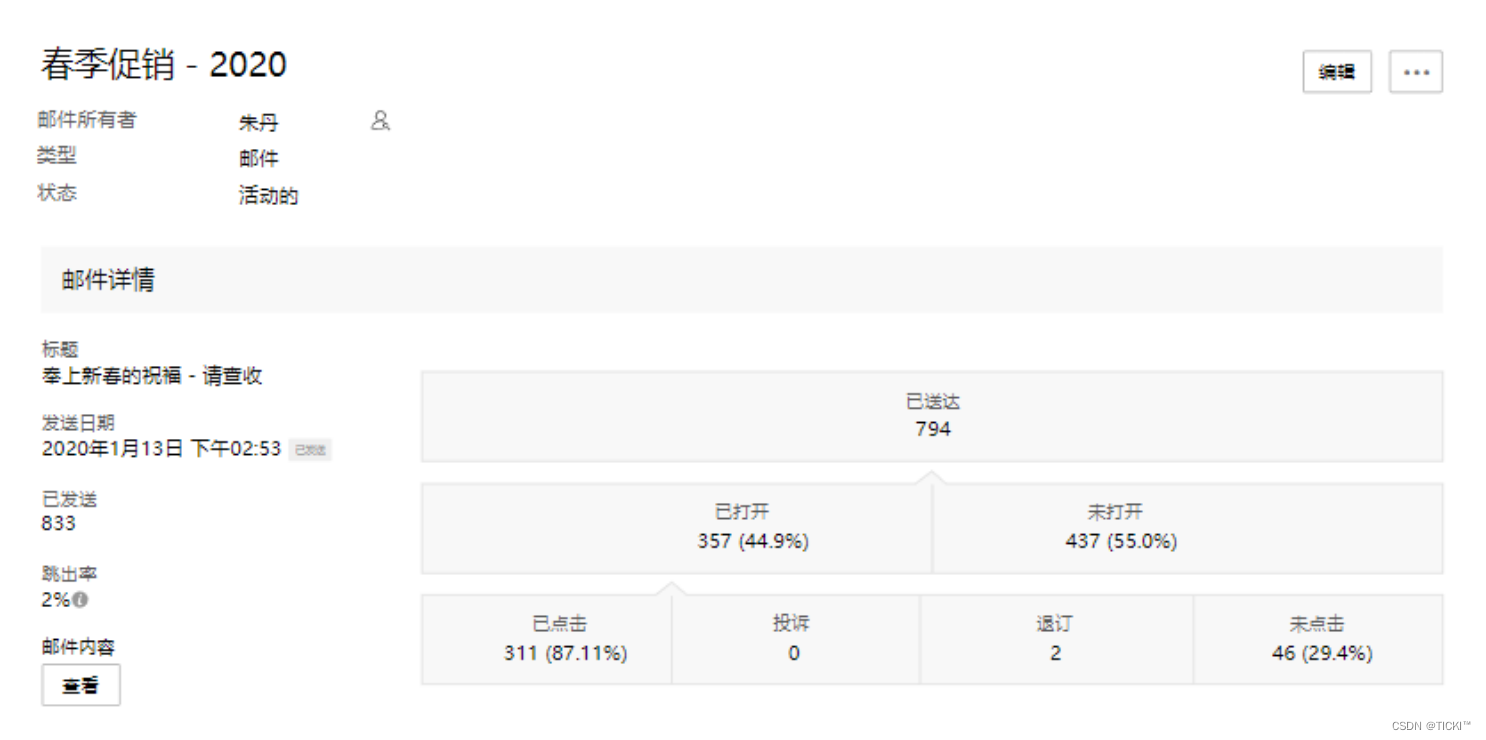
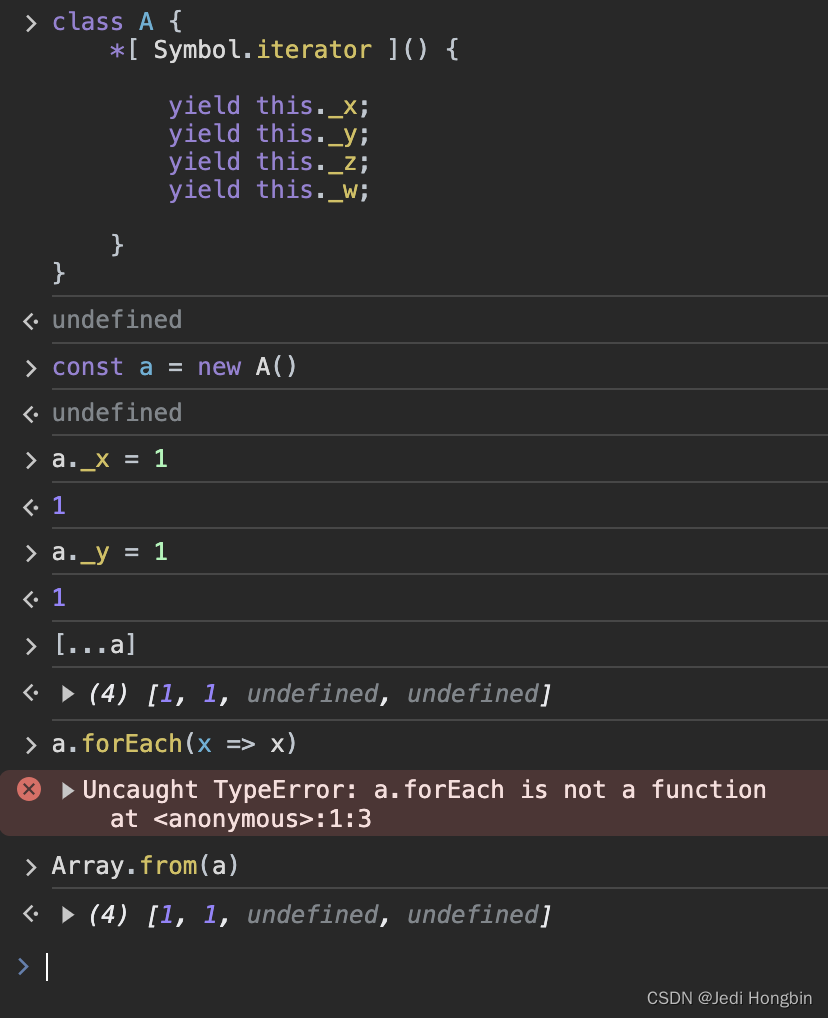
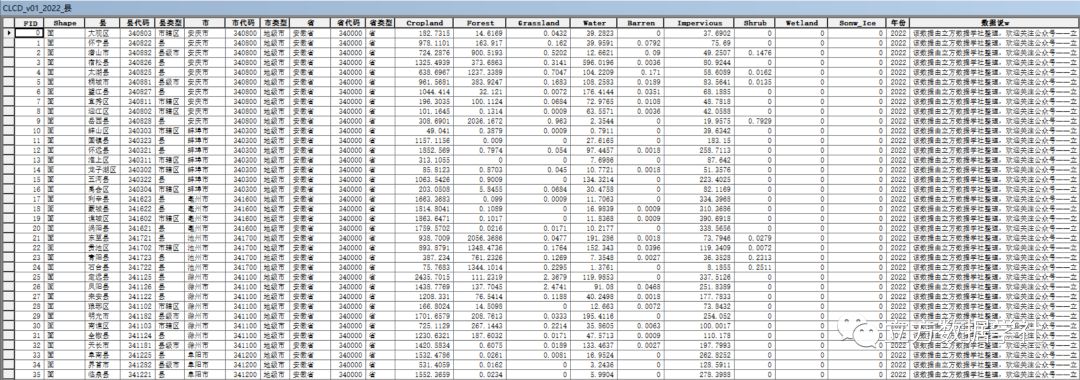
随着人工智能和深度学习技术的不断发展,手写识别OCR软件的技术也在不断进步。目前,市场上已经有一些基于深度学习的手写识别OCR软件,可以对手写文字进行自动识别和转换。
随着人工智能和深度学习技术的不断发展,手写识别OCR软件的技术也在不断进步。目前,市场上已经有一些基于深度学习的手写识别OCR软件,可以对手写文字进行自动识别和转换。
首先,我们来介绍一下基于深度学习的手写识别OCR软件的基本原理。手写识别OCR软件通过分析手写文字的形状、笔画、结构等信息,将其转化为计算机可读的文本。深度学习技术可以通过学习大量的手写文字数据,自动提取手写文字的特征,并优化模型参数,以提高软件的识别准确率和稳定性。
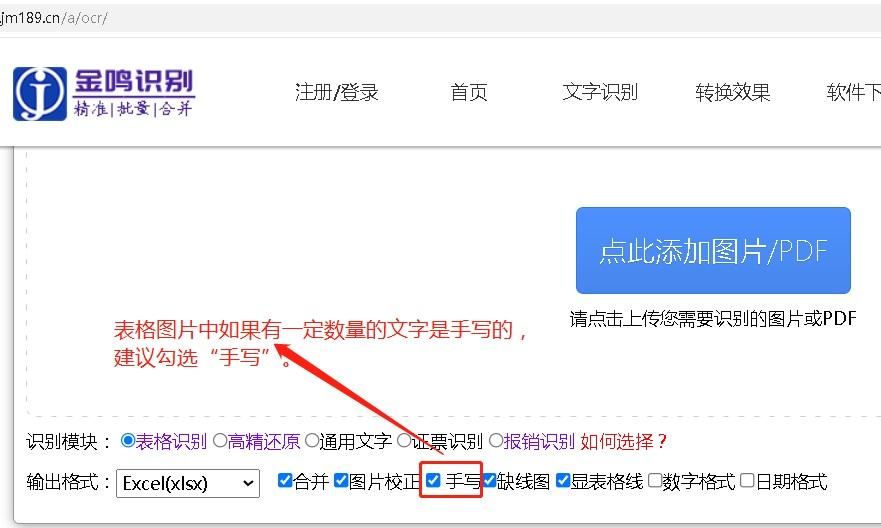
目前市场上的手写识别OCR软件主要分为两类:一种是通用型OCR软件,如Google的Tesseract OCR,金鸣科技旗下的金鸣表格文字识别系统等;另一种是专业领域OCR软件,如医疗、金融、保险等行业领域的OCR软件。这些软件都采用了深度学习技术,可以对手写文字进行高精度的识别和转换。
对于通用型OCR软件,它们通常需要处理各种场景下的手写文字,因此需要具备较高的泛化性能。这些软件通常会采用多种深度学习模型,如卷积神经网络(CNN)、循环神经网络(RNN)等,以实现对手写文字的多层次特征提取和识别。此外,为了提高识别准确率,通用型OCR软件还会不断优化模型参数和训练过程,例如使用迁移学习等技术。
 #百家帮扶计划#而对于专业领域OCR软件,它们通常需要处理特定场景下的手写文字,因此需要具备较高的针对性。这些软件通常会采用专门针对特定场景设计的深度学习模型,例如针对医疗影像分析的卷积神经网络模型等。同时,为了满足特定领域的需求,专业领域OCR软件还会增加许多其他功能,例如对输入图像进行预处理、对识别结果进行后处理等。
#百家帮扶计划#而对于专业领域OCR软件,它们通常需要处理特定场景下的手写文字,因此需要具备较高的针对性。这些软件通常会采用专门针对特定场景设计的深度学习模型,例如针对医疗影像分析的卷积神经网络模型等。同时,为了满足特定领域的需求,专业领域OCR软件还会增加许多其他功能,例如对输入图像进行预处理、对识别结果进行后处理等。
总的来说,基于深度学习的手写识别OCR软件已经取得了很大的进展,可以广泛应用于各种场景中。未来随着技术的不断进步和应用需求的不断增长,手写识别OCR软件将会继续优化和改进,进一步提高识别准确率和稳定性,为人们的生活和工作带来更多的便利。