文章目录
- 一、论文解读
- 1.1 模型介绍
- 1.2 模型架构
- 1.3 wordpiece
- 二、整体总结
论文:Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
作者:Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, Jeffrey Dean
时间:2016
一、论文解读
Google’s Neural Machine Translation system简称GNMT,是一个深度LSTM网络,其由8层编码器和8层解码器组成;在这个深层LSTM网络中,层与层之间使用残差连接,解码器和编码器使用注意力机制连接;
- 为了提高并行性,从而减少训练时间,注意机制将解码器的底层和编码器的顶层进行连接;
- 为了加速最终的翻译速度,在推理计算中采用了低精度的计算;
- 为了改进对罕见单词的处理,使用
wordpiece进行分词并同时用于输入和输出;
wordpiece在“character”分隔模型的灵活性和“word”分隔模型的效率之间提供了很好的平衡,自然地处理罕见词的翻译,最终提高了系统的整体精度
该结果与与谷歌的之前的翻译系统相比,该模型平均减少了60%的翻译错误;我想这就是是谷歌抛弃传统翻译方法拥抱神经网络的最主要的原因之一吧;
1.1 模型介绍
神经机器翻译的架构通常由两个递归神经网络组成,(2017年的Transformer就打你的脸;),一个用于输入文本,一个用于输出文本;通常存在以下几个问题:训练和推理速度较慢(Transformer),无法处理罕见的单词无效,有时无法翻译源句中的所有单词(wordpiece);
For parallelism, we connect the attention from the bottom layer of the decoder network to the top layer of the encoder network. To improve inference time, we employ low-precision arithmetic for inference, which is further accelerated by special hardware (Google’s Tensor Processing Unit, or TPU). To effectively deal with rare words, we use sub-word units (also known as “wordpieces”) for inputs and outputs in our system. Using wordpieces gives a good balance between the flexibility of single characters and the efficiency of full words for decoding, and also sidesteps the need for special treatment of unknown words. Our beam search technique includes a length normalization procedure to deal efficiently with the problem of comparing hypotheses of different lengths during decoding, and a coverage penalty to encourage the model to translate all of the provided input.
- 为了提高并行性,从而减少训练时间,注意机制将解码器的底层和编码器的顶层进行连接;
- 为了加速最终的翻译速度,在推理计算中采用了低精度的计算;
- 为了改进对罕见单词的处理,使用
wordpiece进行分词并同时用于输入和输出;
传统的翻译系统基本都是基于Statistical Machine Translation (SMT)统计机器翻译,主要的应用都是 在翻译短文本上;在神经网络出现优势之前,统计机器翻译就集合了神经机器翻译,直到后来的一篇论文Addressing the rare word problem in neural machine translation中发现使用某架构的神经机器翻译模型的效果要好于传统机器翻译,神经机器翻译迎来了许多的新技术;
1.2 模型架构
模型架构如图所示:
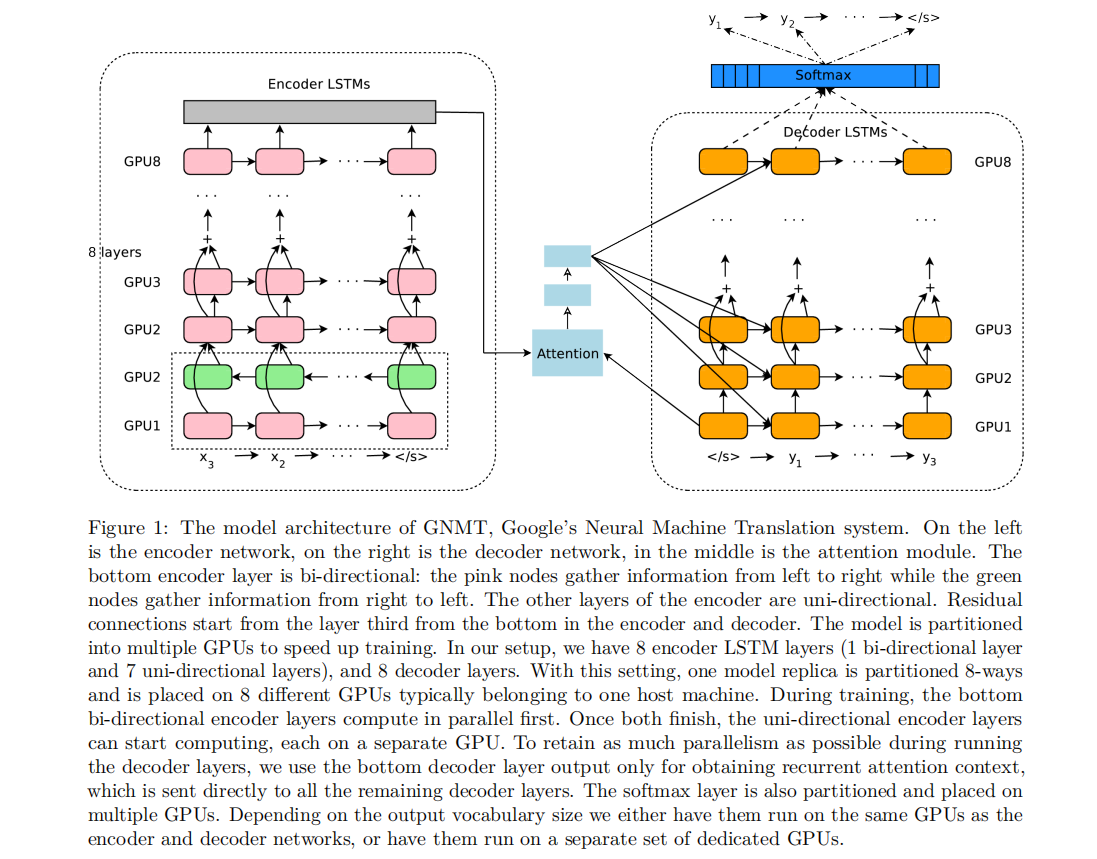
其结构由解码器和编码器结合注意力机制构成,解码器和编码器都是8层的LSTM;循环网络的并行化不好处理,这里采用的是8个GPU结合并行处理的方式进行训练和推理;
模型中注意力模块和decoder模块结合的计算如图所示:

在层与层之间,采取了残差连接的方法:
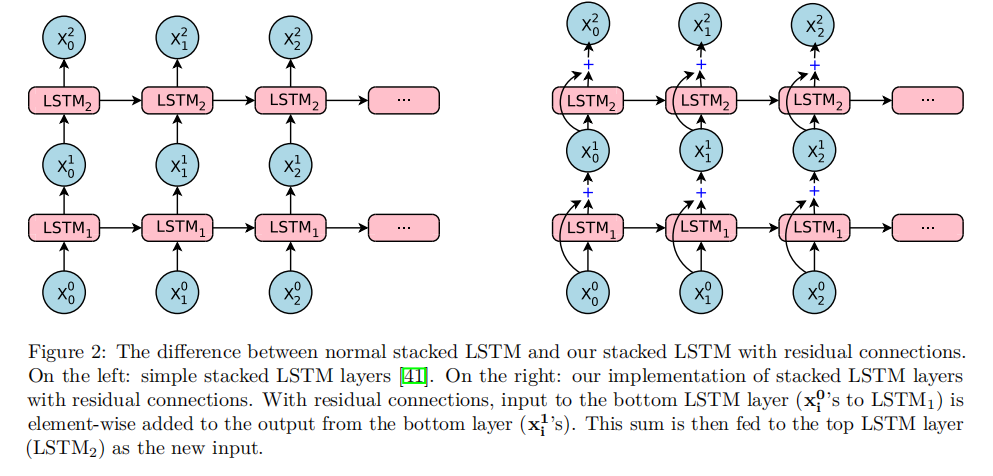
每一层也不闲着,搞一搞双向RNN网络:
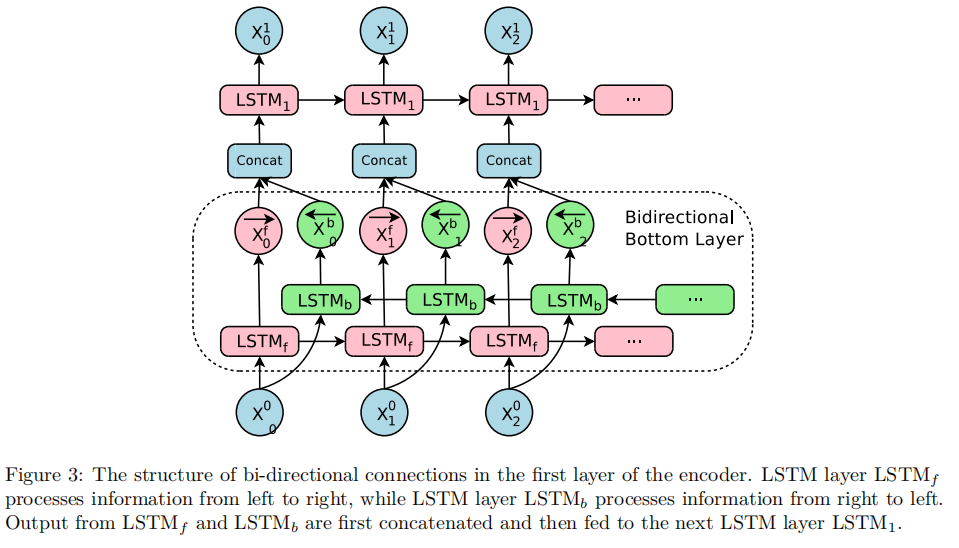
这就是模型的基本架构;
1.3 wordpiece
一般来说对于OOV词有两种方法:一种方法是简单的复制OOV,从输入到输出,就是不翻译的意思;另一种就是论文的重点,使用wordpiece方法,这是一个data-driven方法,可以把任何的字符进行分割;论文中特别提到wordpiece在字符的灵活性和单词的效率之间达到了平衡;
wordpiece是BPE的一种变体,BPE找的是频数最高的字符对,其采取的策略是直接进行合并,wordpiece是根据
L
o
s
s
=
l
o
g
p
(
z
)
p
(
x
)
p
(
y
)
Loss = log\frac{p(z)}{p(x)p(y)}
Loss=logp(x)p(y)p(z) 来判断的,其中
p
(
i
)
p(i)
p(i)表示
i
i
i这个词出现的概率,这里可以采取的方式有很多种,这里举例常见的几种:
- 设定一个
k
k
k值,和
BPE一样去寻找频数最高的字符对,判断 L o s s Loss Loss是否大于 k k k,若大于则合并; - 遍历所有的字符对,合并 L o s s Loss Loss最大的字符对;
原文表述如下:









![[CAD]接下来导出一张高清大图](https://img-blog.csdnimg.cn/direct/b33e3bba0fb848b28b8b1a98482cdbbc.png)