每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/
在自然语言处理(NLP)领域,大型语言模型(LLM),比如GPT-3和BERT,彻底改变了机器理解和生成人类语言的方式。这些模型的核心理念是QKV(Query、Key、Value)和多头注意力机制。一开始听起来很神秘,我也花了几周时间才弄明白。
以下是论文中的解释。
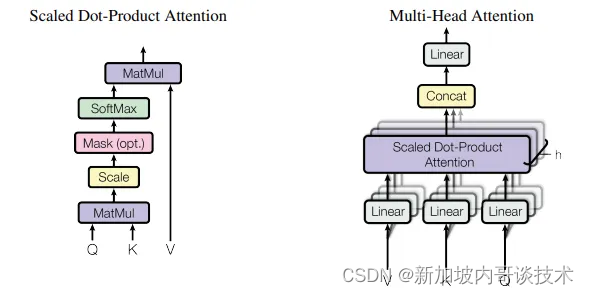
查询(Q): 代表模型当前关注的项目。 在序列中,查询就像对特定元素提出问题。 键(K): 代表序列中模型可能关注的所有项目。 键是查询用来比较的对象,以确定应该给予多少注意力。 值(V): 每个键都与一个值相关联。 一旦模型确定了哪些键是重要的(基于查询),就会使用相应的值来构建输出。 嗯,这还是有点难以理解。我们来看个例子。
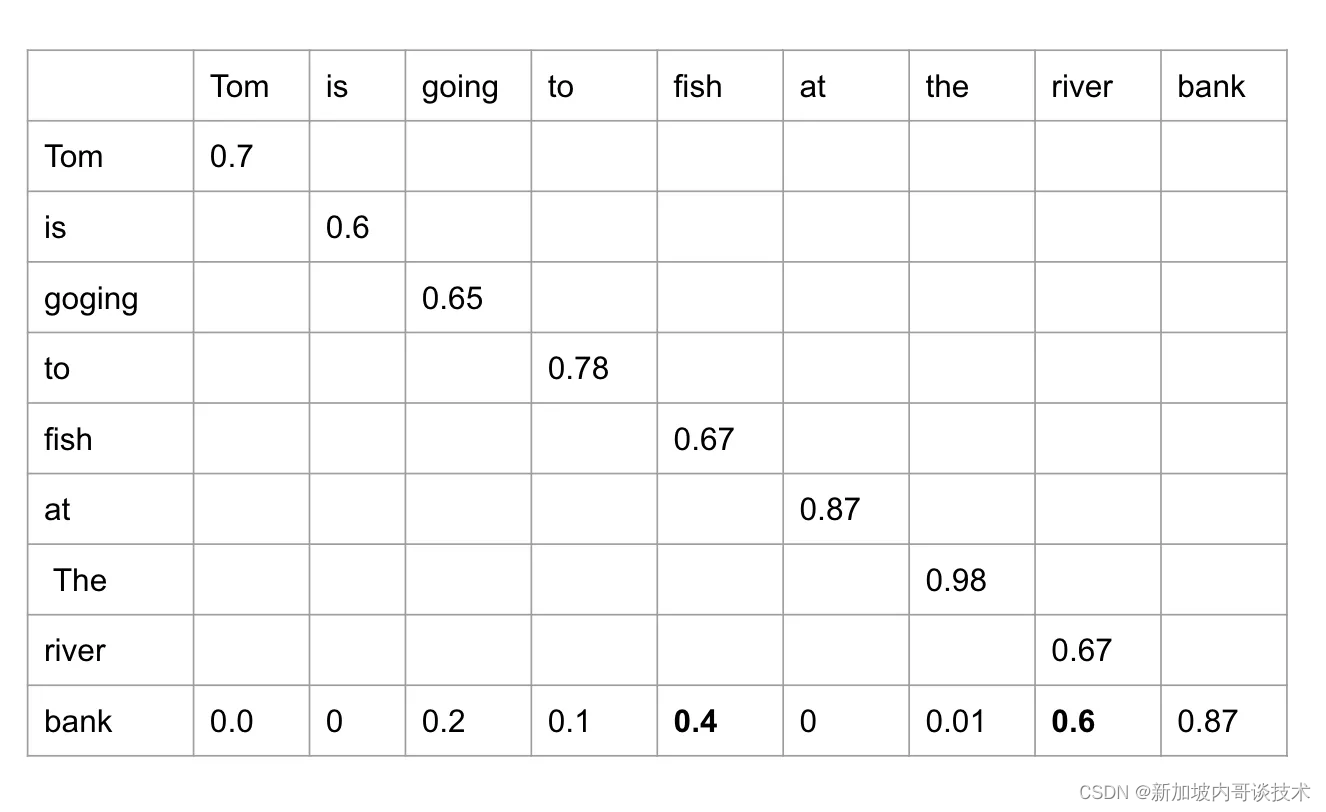
对我们来说,“Tom is going to fish at the river bank”这句话很容易理解。为了让计算机理解它,我们需要将每个词编码成数字,这叫做词嵌入。假设在一个简单的六维空间中,单词“River”可以表示为词嵌入[-0.9, 0.9,-0.2, 0.4, 0.2, 0.6]。那些“相似度”较高的词会彼此靠近。例如,第1组)River、Fish和Fishman,第2组)Hospital、PostOffice和Restaurant。当我们尝试确定“Bank”这个词的位置时,就变得有趣了。它是一个多义词,可以根据所在句子的上下文有不同的解释。它应该更接近第1组还是第2组呢?
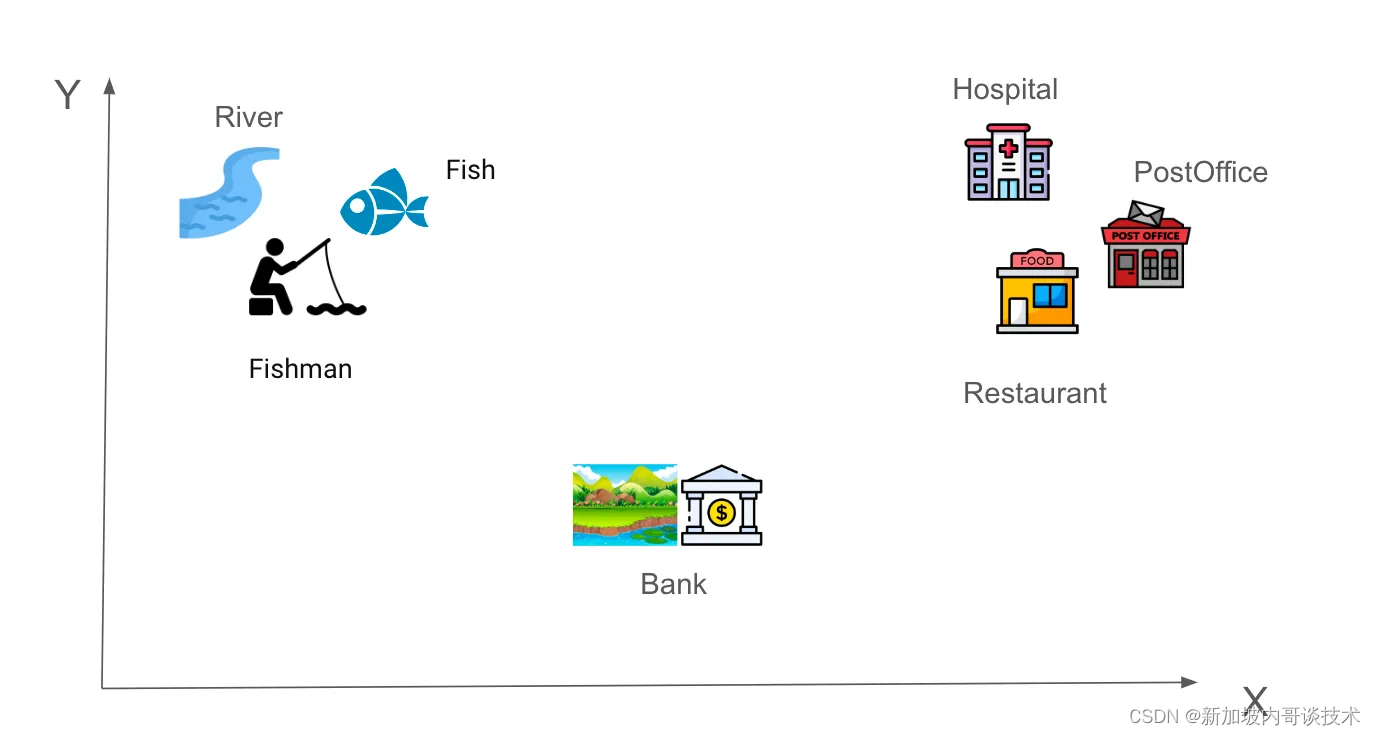
现在,我们再看看这句话,
Tom is going to fish at the river bank.
当我们读到它时,我们知道“bank”不可能是取钱的地方。为什么呢?好吧,单词“River”和“Fish”的存在对我们理解上下文的贡献更大,相比之下其他词的贡献较小。因此,它们应该有较高的注意力分数,并且与“bank”更接近。

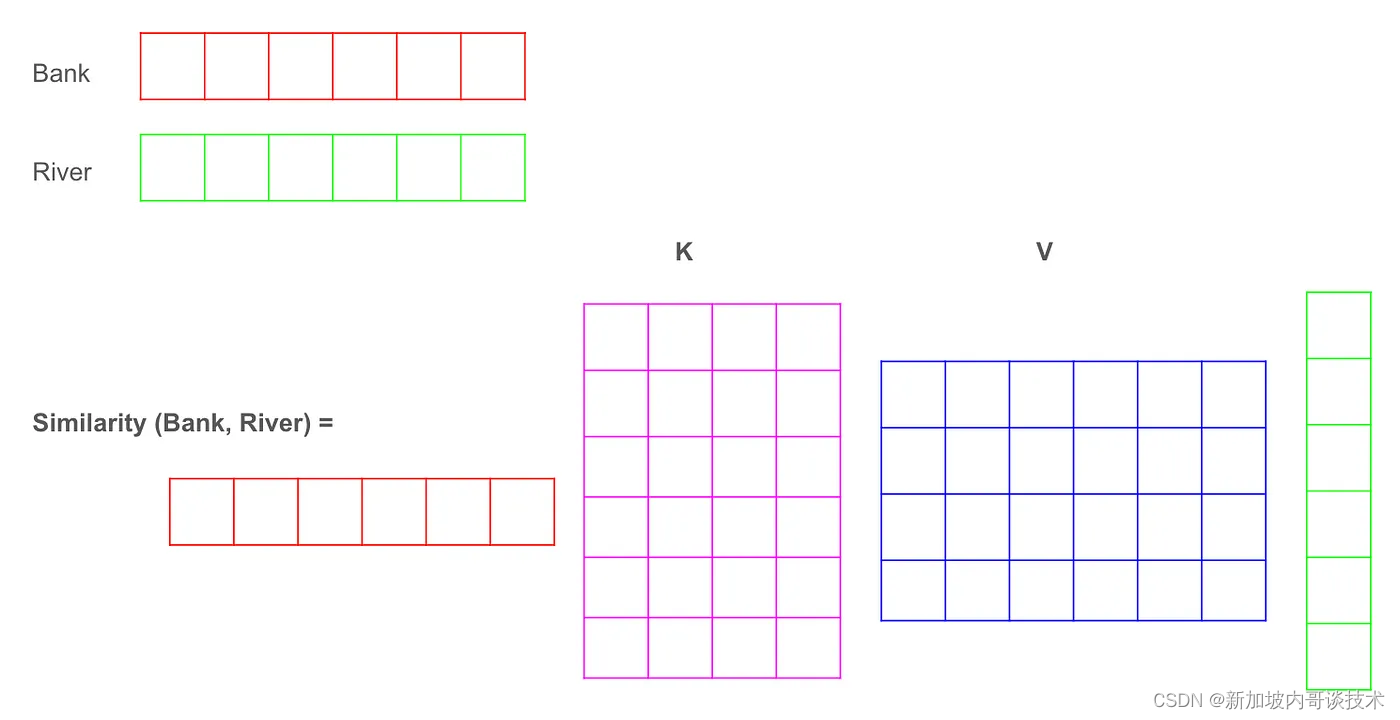
计算机如何确定应该更多地关注“River”和“Fish”而不是其他词呢?这就是Q(Query)和K(Key)的用武之地。它们是两种线性变换,帮助回答这个问题:在这个句子中,词语之间的相似度分数是多少?
首先,它们的输入都是相同的输入嵌入(我们先不考虑位置嵌入),假设有6个维度,如下图所示。

输入嵌入 对输入嵌入应用K和Q的线性变换,
输出经过MatMul、Scale、Mask和SoftMax的步骤,得到注意力权重,然后与V进行MatMul。然后我们得到最终输出,即值的加权和,其中权重由每个键与查询匹配的程度决定。因此,与原始嵌入相比,新的嵌入更多地捕捉了上下文关系。

例如,单词“bank”与“bank”、“river”和“fish”有最高的注意力分数。因此,模型会更多地关注这些输入词。
为什么我们要经历这个复杂的QKV转换呢?

如果我们被要求描述图片中的内容,我们的大脑不会从左上角一个像素一个像素地扫描,而是会立即关注场景中最突出的元素,比如画面中的男孩。这个过程既高效又有效,展示了注意力的力量。
如果你把QKV视为一组线性投影,代表所谓的注意力头,那么多头注意力就是拥有多组QKV并将输出串联起来。拥有多个头的好处是,它允许我们找到不同的相似性方面。例如,一个头可能专注于附近的名词,而另一个可能关注动宾关系。回到上面的图片,一个“头”可能检测到男孩,另一个看到球。
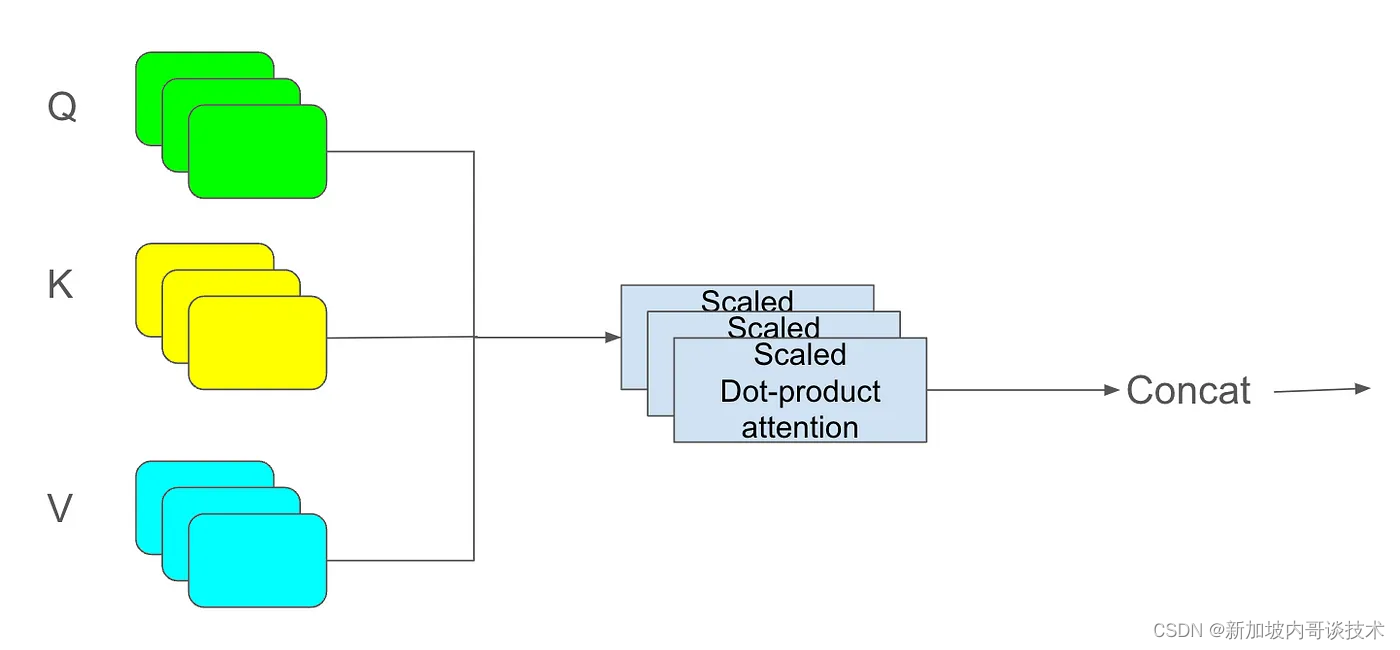
这就是QKV和多头注意力的直观解释。如果你想了解它的数学部分,“Attention Is All You Need”这篇原始论文是一个很好的起点。祝你学习愉快!


![[CAD]接下来导出一张高清大图](https://img-blog.csdnimg.cn/direct/b33e3bba0fb848b28b8b1a98482cdbbc.png)



![[组合数学]LeetCode:2954:统计感冒序列的数目](https://img-blog.csdnimg.cn/f95ddae62a4e43a68295601c723f92fb.gif#pic_center)

![[足式机器人]Part2 Dr. CAN学习笔记-数学基础Ch0-3线性化Linearization](https://img-blog.csdnimg.cn/direct/272e51ba6b694e7da6bb320e03bf6620.png)