文章目录
- 一,什么是内存池
- 二,进程地址空间中是如何解决内存碎片问题的
- 三,malloc的实现原理
- 四,STL中空间配置器的实现原理
- 五,高并发内存池
- 该内存池的优势在哪里
- 内存池的设计框架
- 内存申请流程
- ThreadCache层
- CentreCache层
- PageCache层
- 内存释放流程
- 项目中的细节处理
- 锁的应用
- 项目优化
- 项目中遇到的问题
一,什么是内存池
内存池就是先向系统要一定量的内存资源,放在我们自己的结构中,自己进行管理,以备不时之需,要是我们每次都直接向系统申请资源,对系统的开销是很大的,所以内存池主要目的就是提高我们的性能。当程序需要申请内存时,从我们事先做好的内存池中直接拿,程序要释放内存时,再放回到我们的内存池中。只有程序完全退出时,再将内存池中的资源归还给系统。
内存池可以解决两个主要问题:
一,提高效率
二,解决内存碎片问题
什么是内存碎片呢?
内存碎片分为外部碎片和内部碎片
外部碎片就是:我们在申请内存时,给我们的内存在进程地址空间上是连续的,我们申请65字节,128字节,64字节,43字节的内存,当我们将65,43字节的内存释放后,此时我们若在想申请108字节的内存是申请不下来的。因为其不是一段连续的空间。有了内存池后我们可以减少这样的问题,申请一大块内存放到池子中,在对其进行切割成不同大小的块,以备不同的需求。
内部碎片就是:我们将这大块内存进行切割后,不可能将所有大小的块都切割一遍,管理这些块也是需要成本的,所以就有了我需要6字节的内存,由于没切割6字节的块,只能分给你8字节大小的块。
二,进程地址空间中是如何解决内存碎片问题的
我们都知道我们程序中的地址都是虚拟地址,并非真正的物理地址,这是因为我们希望我们的OS上,可以跑多个进程,若是使用物理地址,则会发生冲突,所以我们要为每一个进程都引入其独立的一套虚拟地址,将虚拟地址与物理地址进行映射。
那么OS是如何管理虚拟地址和物理地址之间的关系呢?
通过内存分段和内存分页。
我们先来看看内存分段,这也是较早提出的一种管理方式。
我们的程序中,不同的变量可能有不同的属性,就像全部变量,局部变量等。。其属性是不一样的,所以对齐的访问权限也是不同的,为了方便管理内存,也是方便让程序可以进行定位,段地址+偏移量的方式还能够使得我们访问到所有的内存。
虚拟地址通过段表与物理内存进行映射每个段在段表中都有一个项,段表里还保存了这个段的的基地址,界限和特权等级。
分段会产生外部内存碎片,每个段的长度不固定,多个段未必能够恰好使用完所有的内存空间,所以会产生多个不连续的小物理内存,为了解决外部内存碎片我们就需要进行内存交换,就是将某一程序的一段所占的空间,通过磁盘,交换到内存中的其他地方,使得内存碎片形成的小块内存,空出更大的连续空间。
看似是解决了内存碎片,但是效率 却变得非常低,我们在进行内存置换时,一次要将一大段数据进行交换,磁盘的访问速度又比内存慢的很多,所以为了解决这个问题就又出现了分页。
要解决内存碎片就要进行分页,但我们却要一次将很大一块连续空间进行交换,效率变得非常低下,那么我们能不能每一次让内存交换时,交换的数据少一些呢?内存分页将虚拟和物理内存都切割长一段段的固定尺寸大小,我们称作页,Linux下,一页为4kb,此时虚拟地址和物理地址之间通过页表来映射,页表存储在内存中,MMU将虚拟地址转换为物理地址,当进程去访问某个虚拟地址时,该地址在页表中查不到,系统就会产生一个缺页中断,这时才进行物理内存的分配,由于页与页之间,不像段与段之间一样会产生间隙,所以采用分页就不会有外部内存碎片,并且,当内存不足时,OS会把其他在运行的进程中最近没有使用的页换出到磁盘上,需要时再进行加载,这样,一次写出磁盘的只有几页也就不会花太多的时间,效率就比较高。分页机制下,虚拟地址通过页号和页内偏移和物理地址进行映射。
这样内存转换就变为了三步:
1.将虚拟内存地址,切分成页号和偏移量
2.根据页号,在页表中查询物理页号
3.物理页号+偏移量就得到了物理内存。
简单的分页是有缺陷的,我们的32位系统有4G大小的内存,一页是4KB,就有大约100万页,每页需要4字节来存储,进行管理,那么一个进程就需要4mb,100个进程就需要400MB,这样光花费在页表上的内存就太多了,因此就有了多级页表,我们将一级页表分为1024个二级页表,每个二级页表中包含1024个表项,这样看似是占用的内存更大了,但并非所有的空间我们都会使用,我们只让一级页表可以覆盖整个空间,二级页表只有需要这一页的时候在进行创建。
TLB,又叫块表,其将常用的几个页表项放到访问速度更快的硬件,从而提高速率。
再回到内存池,我们的内存池解决的是一个进程内部的碎片问题(或者说就是对于页内部碎片问题再进行优化),而,段页式分配机制解决的是整个内存的碎片问题。
三,malloc的实现原理
我们的常用的malloc也是一个内存池,其通过维护一个链表来管理需要分配的内存块,其实现也有很多中,我们以C 标准库中提供的 GNU malloc 为例,其使用的是分离适配法。
在分配时,先找到合适大小的块所对应的空闲链表,遍历该链表,若有能够分配的块,则在该块的首部填上该块的信息(如大小,属于哪一页等),返回首部后的地址;若该链表中没有,则向更大的块查找,进行切割,然后将切割的块重新挂到相应的位置,如果还找不到合适的块,则查找下一个更大的大小类的空闲链表,以此类推,直到找到或者向操作系统申请额外的堆内存。在释放一个块时,合并前后相邻的空闲块,并将结果放到相应的空闲链表中。
这中实现方法,一定程度上减少了外部内存碎片的问题。
malloc 分配的空间中包含一个首部来记录控制信息,因此它分配的空间要比实际需要的空间大一些。这个首部对用户而言是透明的,malloc 返回的是紧跟在首部后面的地址,即可用空间的起始地址。
malloc 分配的函数应该是字对齐的。在 32 位模式中,malloc 返回的块总是 8 的倍数。在 64 位模式中,该地址总是 16
的倍数。最简单的方式是先让堆的起始位置字对齐,然后始终分配字大小倍数的内存。 malloc
只分配几种固定大小的内存块,可以减少外部碎片,简化对齐实现,降低管理成本。 free
只需要传递一个指针就可以释放内存,空间大小可以从首部读取。
四,STL中空间配置器的实现原理
SGI版本的空间配置器有两级,一级用来处理128字节以上的内存申请需求,另一级则是用来处理128字节以下的内存申请需求。
128字节以上的需求则是通过直接malloc来获取的。
128字节以下则是通过自由链表来获取的,自由链表中挂的是一个个哈希桶,并且将用户申请的内存块对齐到了8的整数倍,这也与其结点的设计有关,因为其采用联合体的结构,若还没有分配该块,则该块中的头存储的是下一个结点的指针,分配出去后该头部可以被覆盖,这节省了空间的消耗。64位下指针大小为8,所以其以8为对齐数。
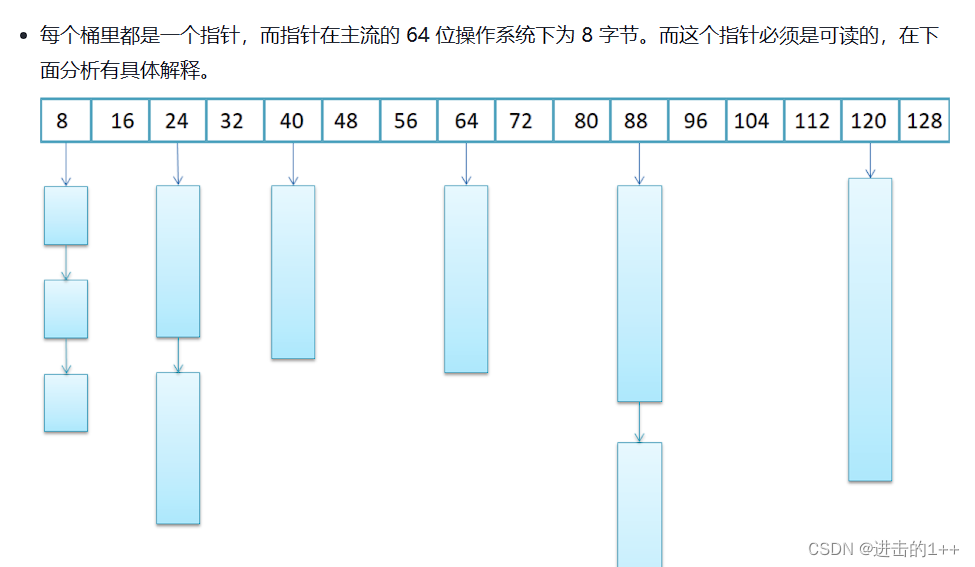
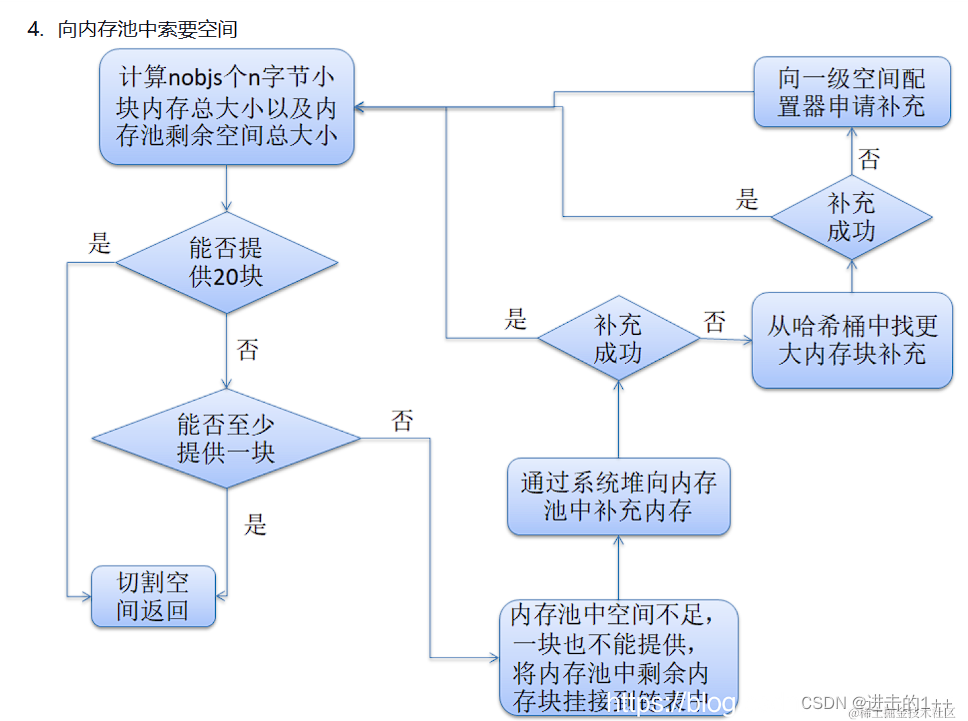
用户申请128字节以下的内存,分配时,先找到用户申请内存大小对齐后的内存块所在链表,若有,则返回,没有则向一个专门的内存池中申请20块,不够20,则有多少返回多少,返回给用户一块后,将剩余的挂起来,若一块都没有,则该内存池直接通过brk或sbrk向系统申请,若系统中也没有,则会去哈希桶中找更大快内存进行补充,若哈希桶中也没有了,则取向一级配置器取申请,(因为一级是直接调用malloc,其本质也是一个内存池)。若一级也没有,则会抛异常。
内存进行释放时,若大于128,则调用free,否则,将该内存块挂到相应的哈希桶中。
五,高并发内存池
该内存池是谷歌的一个开源项目tcmalloc。主要是解决多线程下的锁竞争等问题。
我们将tcmalloc的核心提取出来,从而实现了一个我们自己的内存池。
该内存池的优势在哪里
正如我们前面所提到的malloc,STL空间配置器等内存池,其功能都已经很强大,并且各有优势,那么我们的内存池的优势在哪里呢?
正如其名一样,我们的内存池所解决的主要问题就是多线程下锁竞争的问题,因为内存申请等操作都是非原子的,可能因为时序问题,而导致在申请内存时出现一些错误。
在解决锁竞争的同时,也解决了外部内存碎片的问题
下面我们就来看看这个内存池具体是如何实现的。
内存池的设计框架
该内存池有三层。
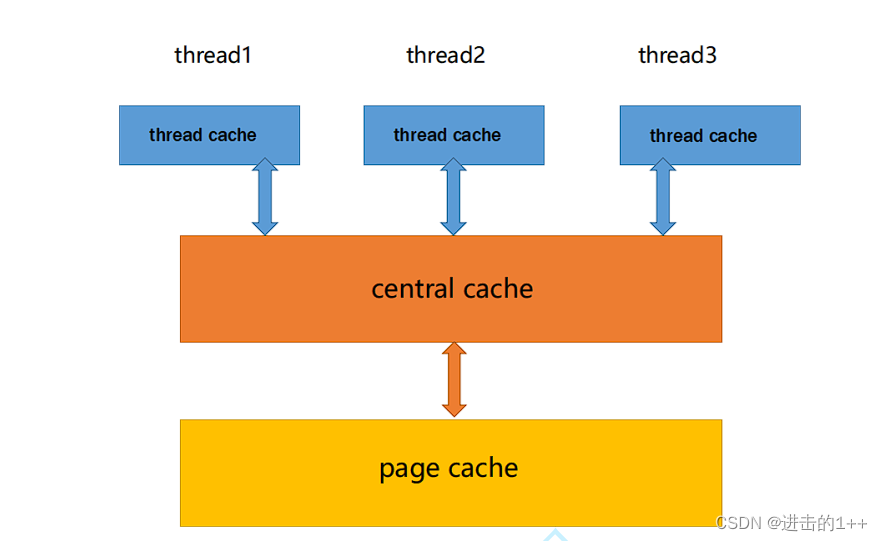
其中第一层是每个线程独有的(TLS),这也是其减少锁竞争的关键,剩下的两层,为线程共享,所以在进行访问时需要加锁。
线程局部存储(TLS),是一种变量的存储方法,这个变量在它所在的线程内是全局可访问的,但是不能被其他线程访问到,这样就保持了数据的线程独立性。而熟知的全局变量,是所有线程都可以访问的,这样就不可避免需要锁来控制,增加了控制成本和代码复杂度。
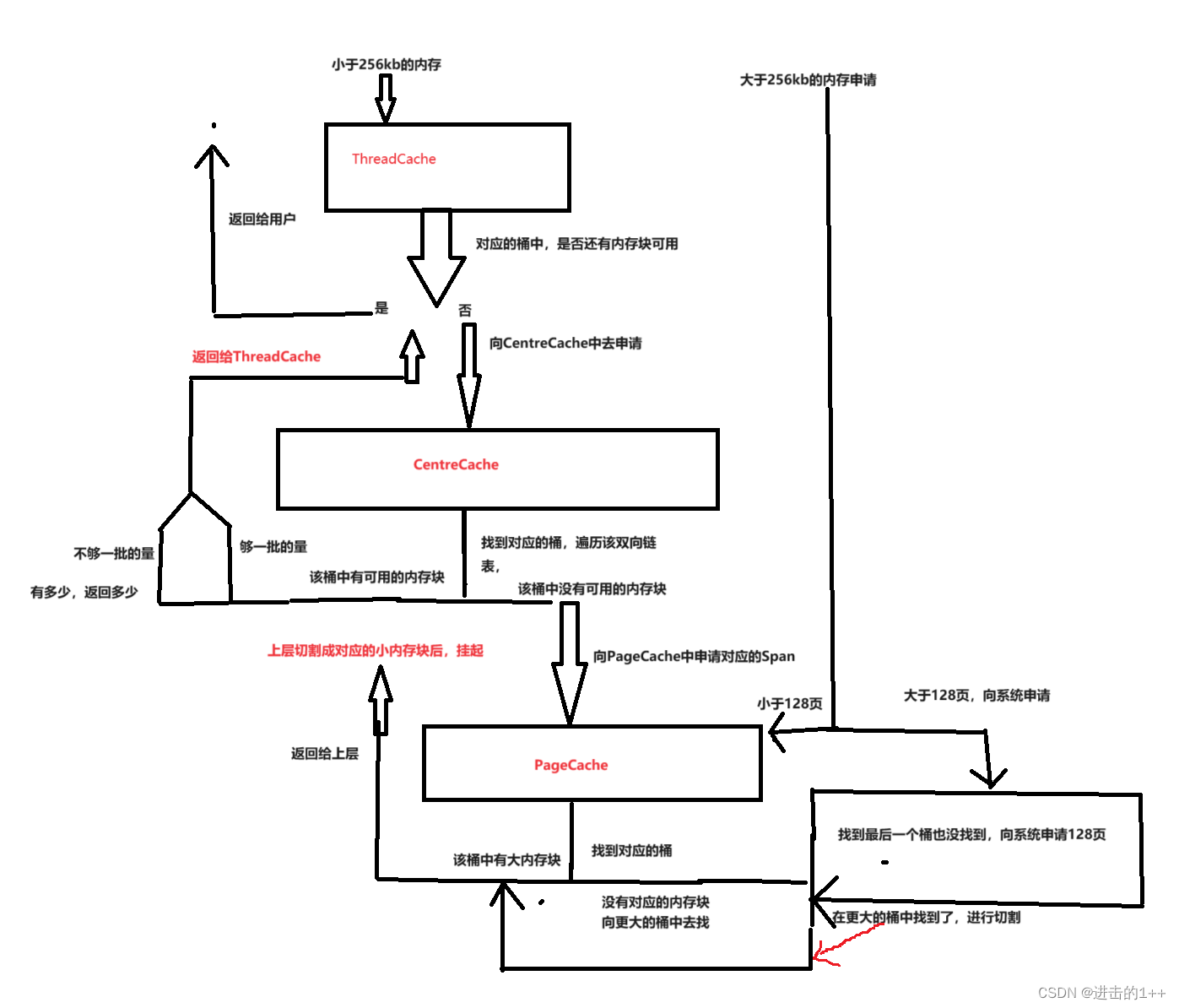
内存申请流程
ThreadCache层
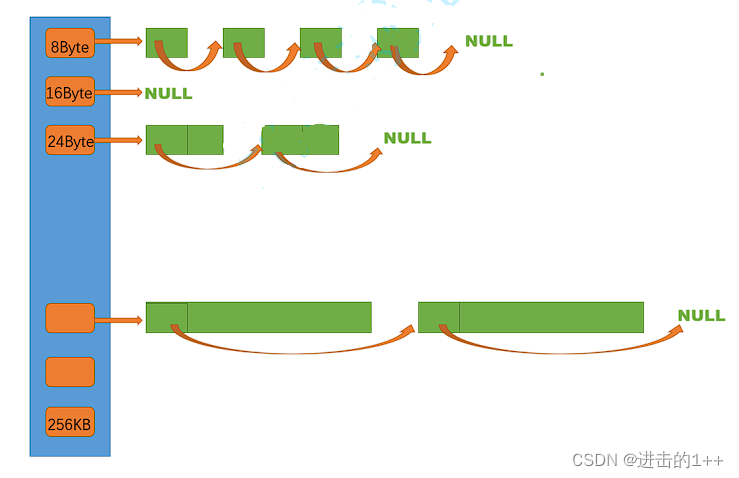
这一层我们使用哈希桶的结构,其挂着的内存块的大小至少为8,这是因为我们在将内存块链接起来时,其头部存储的是下一个内存块的地址,64位下指针大小位8。因为我们没法将1byte-256kb所有大小的块都搞一个桶挂着,因为维持桶和链表本身也要消耗资源,所以原本要6字节,我们就只能分一块8字节出去,会造成内部内存碎片,为了减少内部内存碎片的浪费,我们以下面这样的结构进行对齐。
[1,128] 8byte对齐 freelist[0,16) [128+1,1024] 16byte对齐
freelist[16,72) [1024+1,81024] 128byte对齐 freelist[72,128)
[81024+1,641024] 1024byte对齐 freelist[128,184)
[641024+1,2561024] 81024byte对齐 freelist[184,208)
其大概能造成10%左右的内存的浪费。
在这一层,若申请的空间小于256kb,则直接从相应的桶中去取,若桶中也没有,则向第二层CentreCache中去要,返回一个内存块,将剩下的挂起来;大于256kb则直接取第三层PageCache中去要。
CentreCache层
这一层为所有线程所共享,所以在访问时,需要进行加锁。
当上一层哈希桶中的内存块不够时,便向这一层来申请一定量的内存块。
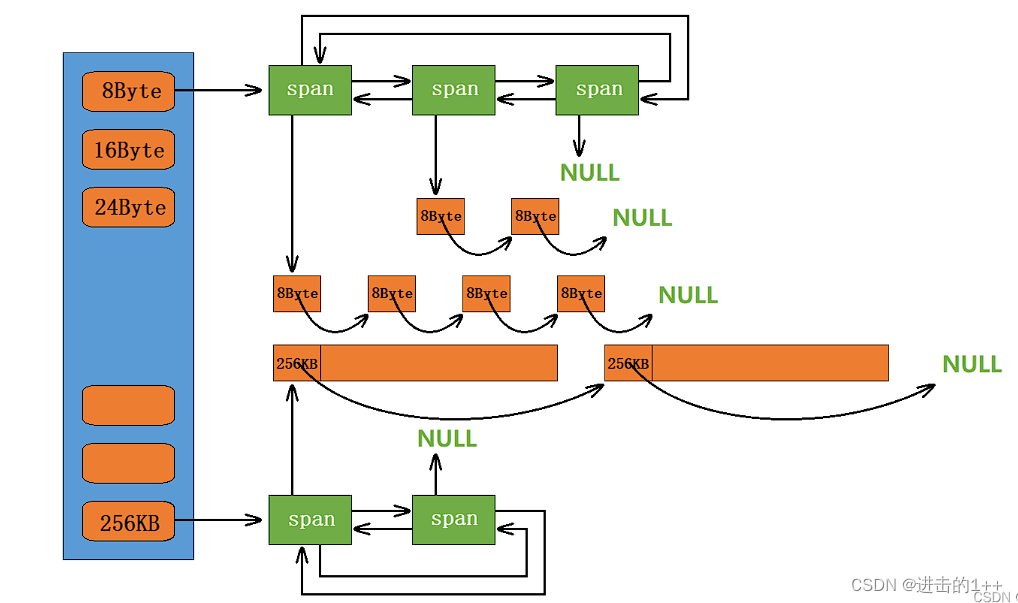
这一层也是哈希桶的结构,只不过每个桶是一个带头双向链表,链表中的每个节点下又挂着自由链表,该自由链表中其本质为一段连续的空间,根据桶的不同,将其切割成了不同大小。
当上一层向该层申请内存块时,先找到对应的桶,然后遍历该桶,返回一Span下的自由链表中一定量的内存块,返回的内存块的数量也是有讲究的。(Span以页为单位)
tcmalloc采用慢增长的方式,限制给上层的内存块的数量。
其有自己独特的分配策略。


我们以8字节的桶为例,当第一此问CentreCache要时,给分一个,第二次要时给分2个,。。。。直到到达设定的一次给的数量的最大值(这个值与内存块的大小有关,越大,这个值越小)。若这个桶中挂接的内存块的个数不够(至少为1),则返回实际的数量;要是桶中一个也没有了则向PageCache层中去申请。
PageCache层
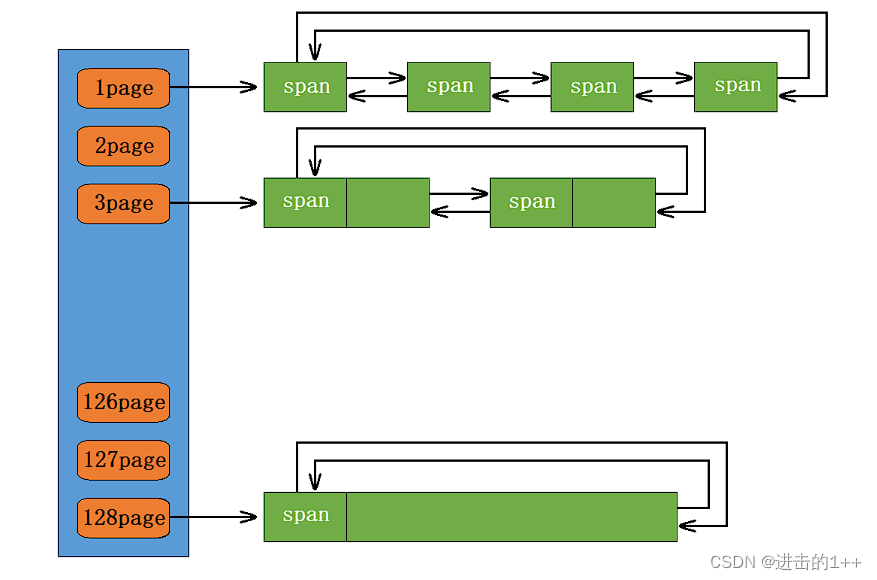
这一层也是哈希桶的结构,桶中挂着的是一个个大的Span,以页为单位。通过保存页号和页数来挂接这个大内存块,我们的虚拟地址,通过除以页的大小,就可以计算处其页号。
CentreCache向这层的哪个桶去要Span也是有说法的。

至少给1页。
当第二层向我们申请Span时,先计算处其需要申请多大的Span,再找到该对应的桶,将该Span返回给上一层,并且进行切割后挂在上一层的自由链表中;若该桶没有,则取更大的桶中去找,找到后,进行切割,将另一块切割剩下的Span挂到其对应的桶中。直到找到128号桶还没有,则向系统申请,一次申请128页大小的内存,然后重复上述步骤。
我们申请的内存大于256kb时,也是直接向PageCache层申请,直接返回对应的Span;若大于128页时,则直接向系统进行申请。
内存释放流程
当释放的内存小于256kb时,回收到ThreadCache层中对应的桶中。若该桶的长度大于当前一批量给的长度时,则将其回收到CentreCache中其各小块对应的Span中,Span中会有一个use_count来记录这个Span中分配出去的内存块的数量,当Span中的use_count为0时,则说明,该Span中分配出去的所有内存块都回来了,则会到PageCache层中进行前后页的合并,合并出一个更大的页,一定程度上解决了内存碎片的问题。
哪么分配出去的每一块内存,怎么直到其是属于哪一个Span呢?
我们在分配之初就将页号与其对应的Span进行了映射,而通过地址又可以计算出其属于哪一页,,所以自然就可以找到其对应哪一个Span 。
free的接口只需要传一个指针参数,就可以将内存块挂到对应的桶中,原因是内存块的其头部存储了该块的大小等信息。而我们也希望能够向free一样,因此我们在Span中又加入了记录该Span所维持的自由链表中内存块大小的变量objsize,我们也是通过指针找到对应的页,从而找到对应的Span,最后访问其中的objsize。
大于256kb的内存释放,在PageCache中处理,若其小于等于128页,则直接挂接到PageCache中对应的桶中,并尝试前后页的合并,若大于128页,则直接归还给系统。
项目中的细节处理
锁的应用
在项目中,第二,第三层都是共享的所以都会涉及到锁的问题,如何加锁解锁,才能让其整体效率最高,是我们要解决的问题。
在第二层中,由于其各个桶之间是独立的,相互不影响,所以我们在加锁时选择的是给单个的桶进行加锁,当不对这个桶进行操作时就马上解锁:例如,向CentreCache中申请内存块时,若这个桶中没有,则需要去PageCache中去拿,此时就可以将这个桶锁解锁,使得当有对应的内存归还到该桶时,不受影响。待拿到申请到的Span后,要进行切割时在加锁。
因为第三层涉及到了切割和合并,所以要对整个结构进行加锁。
在进行内存的释放时也是同样的原理。
项目优化
我们对项目用gprof进行性能分析后发现,其映射Span和页号的结构对性能的降低较大,分析原因,是由于我们采用的是unordered_map,其在结构在发生变化:哈希表的扩容,桶的结点的增加等,所以我们在访问时,必须要进行加锁访问。为了避免锁竞争带来的消耗,我们采用一种一种提前确定的机构,即每个Span以及其对应的页号都确定好位置,且该位置只属于它,这类似于我们的页表,我们是在32为的环境下开发的该程序,所以我们提前为其每一页开好空间,4G空间,消耗4mb的空间,若是64位下,则我们可以采用类似多级页表的方式,并且在需要时再对齐开辟相应的空间。
上述结构本质上就是一个哈希表,由于其结构是固定的,一个萝卜一个坑,所以我们再进行读时,就不需要担心其正在写会改变结构,从而导致读到的数据有问题。
最终经过测试,我们的内存池的效率是要比malloc的效率高的。
项目中遇到的问题
由于该项目细节较多,并且调试时不方便观察,因此调式难度较大。
在进行该项目的开发时,写完每一个模块进行编译,观察期是否有语法错误,当申请内存的流程走完后,进行单个流程的调式,在调式过程中,有出现bug的情况,出现段错误的情况,由于为报具体是在哪里出错,我现实进行单步debug,找到报错位置,通过条件断点,进行打断点调式,我通过观察断点处的值,发现其某些值与预想的不一致,从而缩小范围,最后找到了问题所在。
整个流程都进行完后,我进行了简单测试,发现其没有错误出现,当在进行性能测试时,却出现了bug,我先是通过单步调试,将流程走了一遍,找到报错的地点(出现在内存释放流程中),然后通过调用堆栈和观察变量,并没有发现问题,接着,我为了缩小范围,进行单个流程的测试,即申请和释放分开测试,发现申请没有问题,接着就去释放流程中查找,经过调试发现,其在进行释放是,挂接到通中的块的数量,要比实际数量少,所以对空地址进行了赋值,引起了错误,然后就觉得可能是在内存申请时切割有问题,一查果然是在切割完后将为结点的指针的值=nullptr,写为了==nullptr。





![[JavaScript前端开发及实例教程]计算器井字棋游戏的实现](https://img-blog.csdnimg.cn/direct/804b8bb6e4b24943902549628f13f05a.png)