异质性是多模态研究中最重要的关注点
文章目录
- Abstract
- 1. Introduction
- 2. Related Work
-
- 2.1 多模态假新闻检测 **以往的研究方法**
- 2.2 GNNs在多模态研究中的地位
- 3. 方法论
- 3.1 视觉和文本特征编码器
- 3.2 共享多模态空间和多模态图构建
- 3.3 图注意层
- 3.4 假新闻检测器
- 4. 实验与结果
-
- 4.1 数据集
- 4.2 实现细节
- 4.3多模态的baseline总结
- 4.4 实验结果
- 4.5 消融研究
- 5. 总结
- 参考文献
- 代码注解
-
- 文本单模态Graph
- 文本单模态评估结果
1、梯度裁剪+dropout实现梯度爆炸问题
2、全连接图的问题:如果使用多模态的是全连接,那经过GAT以后的每个结点的特征是不是都一样了,这样GAME-ON是如何解决的{看代码~}
Abstract
社交媒体在当今时代有着越来越大的影响力。在这些平台上传播的假新闻对我们的生活产生了破坏性和破坏性的影响。此外,由于多媒体内容比文本数据更能提高帖子的可见性,因此已经观察到多媒体经常被用于创建虚假内容。大量以前的多模态工作试图解决在识别虚假内容时对异构模态进行建模的问题。然而,这些工作有以下局限性:
(1)在模型的后期阶段,通过在模态上使用简单的连接运算符来对模态间关系进行低效编码,这可能导致信息丢失;(2)在小而复杂的现实生活中的多模态数据集上训练具有非常深的神经网络,且它具有不成比例数量的参数,这导致过拟合的可能性更高。
为了解决这些局限性,我们提出了GAME-ON,这是一种基于图神经网络的端到端可训练框架,允许不同模态内和跨模态的粒度交互,以学习更强大的数据表示,用于多模态假新闻检测。我们使用两个公开的假新闻数据集,Twitter和微博,进行评估。我们的模型在Twitter上的表现平均优于11%,在微博上保持了2.6%的竞争力,同时使用的参数比最佳可比的最先进baseline少65%。
1. Introduction
多模态的重要性
无论新闻的真实性 ,社交媒体的快速发展为信息的传播创造了一个完美的环境。然而,如果对传播的信息没有任何质量控制,假新闻会产生深远的后果**[Zhao et al.,2015年]。例如,2016年美国总统大选期间假新闻的影响[Bovet and Makse,2019],众多“神话”的传播,以及关于COVID-19大流行的误导性信息[Melki et al.,2021; Sharma等人,2021年]。特别是假新闻发起者,使用在文本中添加视觉信息的策略来制作更具吸引力和争议性的帖子来欺骗用户[Verstraete等人,2021年]。因此,在考虑多模态数据的同时检测假新闻至关重要。
先前采用方法:迁移学习、交叉注意力网络融合不同模态
最近,研究人员对多模态假新闻检测领域的兴趣越来越大。已经提出了各种基于深度学习的架构[Khattar等人,2019; Wang等人,2018年]。此外,迁移学习策略在识别假新闻方面越来越受欢迎[Singhal et al.,2019; Singhal等人,2020年]。研究人员还专注于通过以复杂模型为代价使用交叉注意力网络融合不同模态 来进行模态间交互[Wu et al.,2021 a; Qian等人,2021年]。
先前工作方法的缺点:1、简单concat导致信息丢失;2、无法明确多模态数据中出现的异质性差距;3、复杂模型导致的过拟合问题
【对于异质性差距的说明:摘自论文《Deep Multimodal Representation Learning: A Survey》:由于来自不同模式的特征向量最初位于不相等的子空间中,与相似语义相关联的向量表示将是完全不同的。这种现象被称为异质性差距—>多模态特征值及其规模的差异】
以前的工作的缺点是使用复杂的模型的不同模态的融合效率低下。在模型中的稍后点使用简单的连接来融合模态,特别地,可能导致信息丢失。此外,以前利用级联运算符对多式的concat关系进行编码的工作未能明确解决多模态数据中出现的异质性差距[Peng和Qi,2019]。即使是试图解决上述问题的研究也使用了具有大量参数的复杂模型[Qian等人,2021],这可能会导致更高的过拟合几率。
使用Graphs背后的动机:
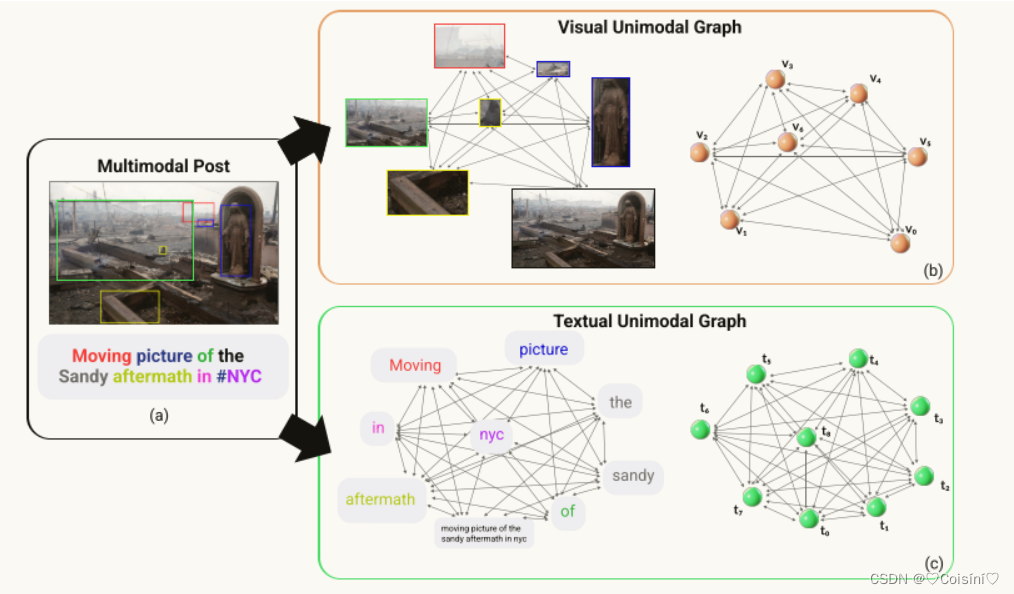
图1:GAME-On框架的图构造pipline概述。(A)给定一个多模式帖子(新闻样本),取自Twitter数据集,我们为两种模式提取单独的完全连通图。(B)从图像中找到目标并提取其特征表示vi。( C )对于文本图,我们首先对文本进行标记化,并提取其特征表示ti。
考虑一个包含文本和视觉内容的多模态帖子(见图1)。在文本的情况下(图1(c)),由于每个单词都很重要,并且为了检测假新闻而与其他单词相连,我们创建了一个文本单模态的图。具体来说,节点表示每个词的embedding,其中包括语义(文本作为一个整体)和语法级(单词作为一个整体)表示,而图中的边表示embedding之间的关系。从而,表示单个文本(模态)的多个节点。所有节点之间存在连接,以 避免任何信息丢失。类似地,在图像的情况下(图1(B)),很明显,图像中的每个提取对象都与另一个对象相连接,覆盖图像的语义(图像作为一个整体)和细粒度(对象级)表示。因此, (i)为每个模态(节点)提取细粒度和全局表示有助于模型以图的方式更有效地学习真实世界数据中模态内和模态之间的复杂关系(边),以及 (ii)通过不同模态节点之间的直接和间接连接增加交互的实例有助于减少由不同模态节点的分布不一致引起的异质性差距,语义相似的模式。
图神经网络的发展
图神经网络(GNN)已经彻底改变了许多领域,包括网络科学,语义取证,健康,视觉对话,并在许多任务上取得了优异的性能。此外,在当代多模态表示学习工作中,只有少数人采用了这些强大的GNN技术[Mai et al.,2020; Chen和Zhang,2020; Han等人,2020; Sabir等人,2021; Jiang等人,2020; Arya等人,2019年]。然而,这些作品要么引入对离群值敏感的基于张量分解的方法,要么利用单独的阶段进行模态间和模态内编码。因此,与我们提出的框架不同,前者引入了不必要的复杂性,而后者不能同时建模模态间和模态内的关系。虽然我们的论文重点是多模态假新闻检测作为其应用,我们的框架也可以推广到其他多媒体任务。
【离群值的定义:离群点是指一个数据与其他数据相比,其数值过高或过低。例如,在一个高中班级里,几乎所有的学生都在18岁左右,然而有一个学生的年龄是35岁。离群值会扭曲模型,导致训练时间延长,准确性降低,性能变差。例如,RMSE损失函数对离群值很敏感,在有离群值的情况下会大得多,所以损失函数会试图根据这些离群值来调整模型,甚至牺牲其他样本。】

【张量分解的定义:张量通常是动态增长的,它的增长通常可以用三种形式来实现:1、维度的增长;2、维度中数据的增长;3、观测数据的增长;现实情况下,往往由于采集数据工具(如采集交通数据的传感器)的故障以及其他异常情况导致数据中往往存在部分缺失值,对这些缺失值的修补称之为“补全”,张量领域的缺失值修复即张量补全。张量补全是根据已有数据对缺失值的影响和低秩假设实现缺失值补全,主要分为两类方法:一种是基于张量补全中给定的秩和更新因子;一种是直接最小化张量秩并更新低秩张量】
基于以前文献中关于多模态假新闻检测的空白和GNN最近的成功,我们工作的主要贡献如下:
模型框架

![竞赛选题 题目:基于深度学习的图像风格迁移 - [ 卷积神经网络 机器视觉 ]](https://img-blog.csdnimg.cn/b72d9a37c238426c81819f44f6a73419.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBARGFuQ2hlbmctc3R1ZGlv,size_16,color_FFFFFF,t_70,g_se,x_16)





![15.Servlet [一篇通]](https://img-blog.csdnimg.cn/img_convert/28917748a025a9dd480412a1b70920c6.png)