制作一个简单的C语言词法分析程序_用c语言编写词法分析程序-CSDN博客文章浏览阅读378次。C语言的程序中,有很单词多符号和保留字。一些单词符号还有对应的左线性文法。所以我们需要先做出一个单词字符表,给出对应的识别码,然后跟据对应的表格来写出程序。_用c语言编写词法分析程序https://blog.csdn.net/lijj0304/article/details/134078944前置程序词法分析器参考这个帖子⬆️
1.程序目标
算符优先语法分析程序,程序可以识别实验1的输出文件中的二元序列,然后通过已经构造好的优先关系矩阵,分析算式是否是正确的,并且能够返回错误的位置。算式的语法如下:
G[E]:E→E+T∣E-T∣T
T→T*F∣T/F∣F
F→(E)∣i
2.程序设计
算符优先部分是通过构造一个二维数组实现,数组中存储了关系矩阵相关的信息。-1表示移进操作,1表示规约操作,0表示先移进后规约。矩阵当中的2表示算符优先矩阵中不存在这个两者关系,程序识别到这个位置时应当返回错误。程序中还用到了栈的数据结构来辅助运算。其中移进时需要实现入栈操作,而规约时需要实现出栈操作,且最后栈为空时则是识别成功。
3.算符优先分析
1. 首先我根据给定的语法,计算处所需要用到的firstvt集和lastvt集
firstvt(E) = {+, -, *, /, (, i}
firstvt(T) = {*, /, (, i}
firstvt(F) = {(, i}
lastvt(E) = {+, -, *, /, }, i}
lastvt(T) = {*, /, ), i}
lastvt(F) = {), i}
2. 接着可以计算出这个语法的算符优先表
| + | - | * | / | ( | ) | i | # | |
|---|---|---|---|---|---|---|---|---|
| + | > | > | < | < | < | > | < | > |
| - | > | > | < | < | < | > | < | > |
| * | > | > | > | > | < | > | < | > |
| / | > | > | > | > | < | > | < | > |
| ( | < | < | < | < | < | = | < | |
| ) | > | > | > | > | > | > | ||
| i | > | > | > | > | > | > | ||
| # | < | < | < | < | < | < | = |
3. 再得到关系矩阵
| + | - | * | / | ( | ) | i | # | |
|---|---|---|---|---|---|---|---|---|
| + | 1 | 1 | -1 | -1 | -1 | 1 | -1 | 1 |
| - | 1 | 1 | -1 | -1 | -1 | 1 | -1 | 1 |
| * | 1 | 1 | 1 | 1 | -1 | 1 | -1 | 1 |
| / | 1 | 1 | 1 | 1 | -1 | 1 | -1 | 1 |
| ( | -1 | -1 | -1 | -1 | -1 | 0 | -1 | -2 |
| ) | 1 | 1 | 1 | 1 | -2 | 1 | -2 | 1 |
| i | 1 | 1 | 1 | 1 | -2 | 1 | -2 | 1 |
| # | -1 | -1 | -1 | -1 | -1 | -2 | -1 | 0 |
4.完整程序
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#define MAX_LEN 1000
char str[MAX_LEN];
char stack[MAX_LEN];
int top = 0;
//+, -, *, /, (, ), i, #
int table[8][8] = {{ 1, 1,-1,-1,-1, 1,-1, 1}, // +
{ 1, 1,-1,-1,-1, 1,-1, 1}, // -
{ 1, 1, 1, 1,-1, 1,-1, 1}, // *
{ 1, 1, 1, 1,-1, 1,-1, 1}, // /
{-1,-1,-1,-1,-1, 0,-1,-2}, // (
{ 1, 1, 1, 1,-2, 1,-2, 1}, // )
{ 1, 1, 1, 1,-2, 1,-2, 1}, // i
{-1,-1,-1,-1,-1,-2,-1, 0}};// #
int getindex(char ch) {
switch(ch) {
case '+': return 0;
case '-': return 1;
case '*': return 2;
case '/': return 3;
case '(': return 4;
case ')': return 5;
case 'i': return 6;
case '#': return 7;
default: return -1;
}
}
int OPG(char *str, char *stack) {
int i = 0;
while(i < strlen(str)) {
if(top < 0) return 0;
int x = getindex(stack[top]);
int y = getindex(str[i]);
if(x == -1 || y == -1) {
return 0;
}
if(table[x][y] == -1) {
stack[++top] = str[i];
printf("%c -> ", str[i++]);
}
else if(table[x][y] == 1) {
top--;
}
else if(table[x][y] == 0) {
top--;
printf("%c -> ", str[i++]);
}
else if(table[x][y] == -2) {
return 0;
}
}
if(top+1 == 0) return 1;
else return 0;
}
int main() {
for(int m = 5; m <= 8; m++) {
printf("test%d:\n", m);
char txt[] = "./lexical/analyze";
char num[6];
sprintf(num, "%d.txt", m);
strcat(txt, num);
FILE *fp = fopen(txt, "r");
char buf[MAX_LEN] = "";
char input[MAX_LEN] = "";
fgets(buf, MAX_LEN, fp);
int i = 0, j = 0;
for(int k = 0; k < strlen(buf); k++) {
if(buf[k] == '1' && buf[k+1] == ',') {
str[i++] = 'i';
k += 3;
while(1) {
if(buf[k] == ')' && buf[k+1] == ' ')
break;
input[j++] = buf[k++];
}
continue;
}
if(buf[k] == ',' && buf[k+1] == ' ') {
k += 2;
while(1) {
if(buf[k] == ')' && buf[k+1] == ' ')
break;
str[i++] = buf[k];
input[j++] = buf[k++];
}
}
}
printf("Input scentence: %s\n", input);
str[i] = '#';
printf("str: %s\n", str);
fclose(fp);
stack[0] = '#', top = 0;
if(OPG(str, stack)) {
printf("end\n");
printf("Gramma legal: %s\n", str);
}
else {
printf("error\n");
printf("Gramma illegal\n");
}
}
return 0;
}5.测试程序
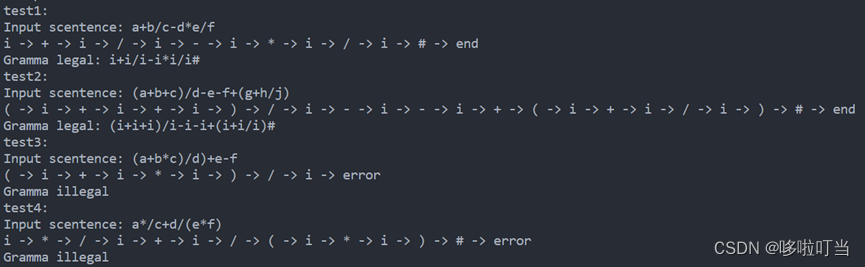
tets1:a+b/c-d*e/f
test2:(a+b+c)/d-e-f+(g+h/j)
test3:(a+b*c)/d)+e-f
test4:a*/c+d/(e*f)
程序1分析结果:
analyze1:
(1, a) (44, +) (1, b) (38, /) (1, c) (47, -) (1, d) (50, *) (1, e) (38, /) (1, f)
analyze2:
(16, () (1, a) (44, +) (1, b) (44, +) (1, c) (17, )) (38, /) (1, d) (47, -) (1, e) (47, -) (1, f) (44, +) (16, () (1, g) (44, +) (1, h) (38, /) (1, j) (17, ))
analyze3:
(16, () (1, a) (44, +) (1, b) (50, *) (1, c) (17, )) (38, /) (1, d) (17, )) (44, +) (1, e) (47, -) (1, f)
analyze4:
(1, a) (50, *) (38, /) (1, c) (44, +) (1, d) (38, /) (16, () (1, e) (50, *) (1, f) (17, ))
程序3运行结果